
"Padrões" no contexto de C ++ geralmente se refere a construções de linguagem muito específicas. Existem modelos simples que simplificam o trabalho com o mesmo tipo de código - esses são modelos de classe e função. Se um modelo possui um dos parâmetros por si só, pode-se dizer que são modelos de segunda ordem e eles geram outros modelos, dependendo de seus parâmetros. Mas e se seus recursos não forem suficientes e mais fáceis para gerar imediatamente o texto de origem? Muito código fonte?
Os fãs de Python e layouts de HTML estão familiarizados com uma ferramenta (mecanismo, biblioteca) para trabalhar com modelos de texto chamados
Jinja2 . Na entrada, esse mecanismo recebe um arquivo de modelo no qual o texto pode ser misturado com estruturas de controle; a saída é texto limpo, no qual todas as estruturas de controle são substituídas por texto de acordo com os parâmetros especificados de fora (ou de dentro). Grosso modo, isso é algo como páginas ASP (ou C ++ - pré-processador), apenas a linguagem de marcação é diferente.
Até agora, a implementação desse mecanismo era apenas para Python. Agora é para C ++. Sobre como e por que isso aconteceu, e será discutido no artigo.
Por que eu peguei isso
De fato, por que? Afinal, existe o Python para ele - uma excelente implementação, vários recursos, uma especificação completa para a linguagem. Pegue e use! Eu não gosto de Python - você pode pegar
Jinja2CppLight ou
inja , portas Jinja2 parciais em C ++. Você pode, no final, usar a porta C ++ {{
Bigode }}. O diabo, como sempre, nos detalhes. Então, digamos, eu precisava da funcionalidade dos filtros do Jinja2 e dos recursos da construção de extensões, o que permite criar modelos extensíveis (e também macros e inclusão, mas isso posteriormente). E nenhuma das implementações mencionadas suporta isso. Eu poderia ficar sem tudo isso? Também é uma boa pergunta. Julgue por si mesmo. Eu tenho um
projeto cujo objetivo é criar C ++ - para C ++ gerador de código clichê. Esse gerador automático recebe, digamos, um arquivo de cabeçalho escrito manualmente com estruturas ou enumerações e gera com base nele funções de serialização / desserialização ou, por exemplo, conversão de elementos de enumeração em seqüências de caracteres (e vice-versa). Você pode ouvir mais detalhes sobre esse utilitário nos meus relatórios
aqui (eng) ou
aqui (rus).
Portanto, uma tarefa típica resolvida no processo de trabalho no utilitário é a criação de arquivos de cabeçalho, cada um com um cabeçalho (com ifdefs e includes), um corpo com o conteúdo principal e um rodapé. Além disso, o conteúdo principal são as declarações geradas repletas de namespace. Na execução do C ++, o código para criar um arquivo de cabeçalho é semelhante a este (e isso não é tudo):
Muito código C ++void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
Daqui Além disso, esse código muda pouco de arquivo para arquivo. Obviamente, você pode usar o formato clang para formatação. Mas isso não cancela o restante do trabalho manual na geração do texto de origem.
E então, um belo momento, percebi que minha vida deveria ser simplificada. Não considerei a opção de estragar uma linguagem de script completa devido à complexidade do suporte ao resultado final. Mas para encontrar um mecanismo de modelo adequado - por que não? Achei útil pesquisar, achei, depois encontrei a especificação Jinja2 e percebi que era exatamente isso que eu precisava. De acordo com esta especificação, os modelos para gerar cabeçalhos teriam a seguinte aparência:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
Assim .

Havia apenas um problema: nenhum dos mecanismos que encontrei suportava todo o conjunto de recursos que eu precisava. Bem, é claro, todo mundo tinha uma
falha fatal padrão. Pensei um pouco e decidi que outro mundo não pioraria com outra implementação do mecanismo de modelo. Além disso, de acordo com estimativas, a funcionalidade básica não era tão difícil de implementar. Afinal, agora em C ++ existem regexp's!
E assim
surgiu o projeto
Jinja2Cpp . À custa da complexidade de implementar a funcionalidade básica (muito básica), quase adivinhei. No geral, eu perdi exatamente o coeficiente de Pi ao quadrado: levei um pouco menos de três meses para escrever tudo o que precisava. Mas quando tudo estava terminado, terminado e inserido no "Programador Automático" - percebi que não tentei em vão. De fato, o utilitário de geração de código recebeu uma poderosa linguagem de script combinada com modelos, que abriu completamente novas oportunidades de desenvolvimento para ele.
NB: Eu tive uma idéia para fixar Python (ou Lua). Mas nenhum dos mecanismos de script completos existentes resolve problemas "prontos para uso" na geração de texto a partir de modelos. Ou seja, o Python ainda teria que estragar o mesmo Jinja2, mas para Lua, procure algo diferente. Por que eu preciso desse link extra?
Implementação do analisador
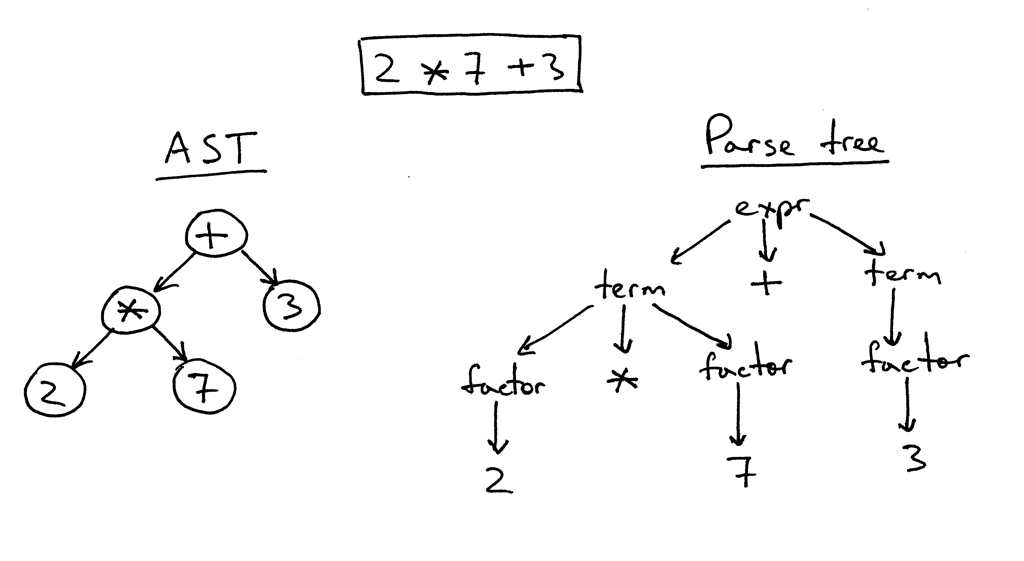
A idéia por trás da estrutura dos modelos Jinja2 é bastante simples. Se houver algo no texto incluído em um par de "{{" / "}}", então isso é "algo" - uma expressão que deve ser avaliada, convertida em uma representação de texto e inserida no resultado final. Dentro do par "{%" / "%}" existem operadores como for, if, set, etc. Bem, em "{#" / "#}" existem comentários. Tendo estudado a implementação do Jinja2CppLight, decidi que tentar encontrar manualmente todas essas estruturas de controle no texto do modelo não era uma boa idéia. Portanto, eu me armava com uma regexp bastante simples: (((\ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n)), com a ajuda da qual ele dividiu o texto nos fragmentos necessários. E chamou de fase áspera da análise. Na fase inicial do trabalho, a ideia mostrou sua eficácia (sim, na verdade, ainda mostra), mas, de uma maneira boa, precisará ser refatorada no futuro, já que agora são impostas pequenas restrições ao texto do modelo: pares de escape "{{" e "}}" no texto também é processado "testa".
Na segunda fase, apenas o que está dentro dos "colchetes" é analisado em detalhes. E aqui eu tive que mexer. Com o inja, com o Jinja2CppLight, o analisador de expressões é bastante simples. No primeiro caso - no mesmo regexp'ah, no segundo - manuscrito, mas suportando apenas designs muito simples. Suporte para filtros, testadores, aritmética complexa ou indexação está fora de questão. E eram precisamente esses recursos do Jinja2 que eu mais queria. Portanto, eu não tinha outra escolha senão plugar um analisador LL (1) completo (em alguns lugares - sensível ao contexto) que implementa a gramática necessária. Cerca de dez a quinze anos atrás, eu provavelmente aceitaria Bison ou ANTLR por isso e implementaria um analisador com sua ajuda. Cerca de sete anos atrás, eu teria tentado o Boost.Spirit. Agora, acabei de implementar o analisador de que preciso, trabalhando pelo método de descida recursiva, sem gerar dependências desnecessárias e aumentar significativamente o tempo de compilação, como aconteceria se utilitários externos ou Boost.Spirit fossem usados. Na saída do analisador, recebo um AST (para expressões ou para operadores), que é salvo como modelo, pronto para renderização subsequente.
Um exemplo de análise de lógica ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
Daqui Fragmento de classes de árvore de expressão AST class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
Daqui Exemplos de classes de operadores de árvore AST struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
Daqui Os nós AST são associados apenas ao texto do modelo e são convertidos em valores totais no momento da renderização, levando em consideração o contexto de renderização atual e seus parâmetros. Isso nos permitiu criar padrões seguros para threads. Mas mais sobre isso em termos de renderização real.
Como o principal tokenizador, escolhi a biblioteca
lexertk . Ele possui a licença necessária e apenas o cabeçalho. É verdade que eu tive que cortar todos os sinos e assobios do cálculo do balanço de colchetes e assim por diante e deixar apenas o próprio tokenizer, que (depois de um pouco de limpeza com um arquivo) aprendeu a trabalhar não apenas com char, mas também com caracteres wchar_t. No topo deste tokenizer, agrupei outra classe que executa três funções principais: a) abstrai o código do analisador do tipo de caracteres com o qual trabalhamos, b) reconhece palavras-chave específicas do Jinja2 ec) fornece uma interface conveniente para trabalhar com o fluxo de token:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
Daqui Portanto, apesar do mecanismo poder funcionar com os modelos char e wchar_t-templates, o código de análise principal não depende do tipo de caractere. Mas mais sobre isso na seção sobre aventuras com tipos de personagens.
Separadamente, tive que mexer com as estruturas de controle. No Jinja2, muitos deles estão emparelhados. Por exemplo, para / endfor, if / endif, block / endblock, etc. Cada elemento do par entra em seus próprios "colchetes" e, entre os elementos, pode haver um monte de tudo: apenas texto sem formatação e outros blocos de controle. Portanto, o algoritmo para analisar o modelo teve que ser feito com base na pilha, para o elemento superior atual do qual todas as construções e instruções recém-encontradas, bem como fragmentos de texto simples entre eles, “se apegam”. Usando a mesma pilha, a ausência de desequilíbrio do tipo if-for-endif-endfor é verificada. Como resultado de tudo isso, o código acabou não sendo tão "compacto" como, por exemplo, Jinja2CppLight (ou inja), onde toda a implementação está em uma fonte (ou cabeçalho). Mas a lógica de análise e, de fato, a gramática no código são mais claramente visíveis, o que simplifica seu suporte e extensão. Pelo menos é o que eu estava buscando. Ainda não é possível minimizar o número de dependências ou a quantidade de código, portanto, você precisa deixar mais claro.
Na
próxima parte, falaremos sobre o processo de renderização de modelos, mas por enquanto - links:
Especificação do Jinja2:
http://jinja.pocoo.org/docs/2.10/templates/Implementação Jinja2Cpp:
https://github.com/flexferrum/Jinja2CppImplementação do Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightImplementação lesionada:
https://github.com/pantor/injaUtilitário para gerar código com base nos modelos Jinja2:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor