Nos dois últimos artigos, falamos sobre o IIoT - a Internet industrial das coisas - construímos uma arquitetura para receber dados dos sensores, soldamos os próprios sensores. A pedra angular das arquiteturas IIoT e de qualquer arquitetura que trabalhe com o BigData é o processamento de fluxo de dados. É baseado no conceito de mensagens e filas. O padrão para trabalhar com mensagens agora se tornou Apache Kafka. No entanto, para entender suas vantagens (e entender suas desvantagens), seria bom entender o básico da operação de sistemas de filas em geral, seus mecanismos de operação, padrões de uso e funcionalidade básica.

Encontramos uma excelente série de artigos que comparam a funcionalidade do Apache Kafka e outro gigante (imerecidamente ignorado) entre os sistemas de filas - o RabbitMQ. Traduzimos esta série de artigos, fornecemos comentários e complementamos. Embora a série tenha sido escrita em dezembro de 2017, o mundo dos sistemas de mensagens (e especialmente o Apache Kafka) está mudando tão rapidamente que, no verão de 2018, algumas coisas mudaram.
Fonte
RabbitMQ vs Kafka
As mensagens são a parte central de muitas arquiteturas, e os dois pilares nessa área são RabbitMQ e Apache Kafka. Até o momento, o Apache Kafka tornou-se um padrão quase industrial no processamento e análise de dados; portanto, nesta série, examinaremos mais de perto o RabbitMQ e o Kafka no contexto de seu uso em infraestruturas em tempo real.
O Apache Kafka agora está em ascensão, mas parece que eles começaram a esquecer o RabbitMQ. Todo o hype focado em Kafka, e isso acontece por razões óbvias, mas o RabbitMQ ainda é uma ótima opção para mensagens. Uma das razões pelas quais o Kafka voltou sua atenção é sua obsessão geral pela escalabilidade, e obviamente o Kafka é mais escalável que o RabbitMQ, mas a maioria de nós não se preocupa com a escala na qual o RabbitMQ tem problemas. A maioria de nós não é o Google ou o Facebook. A maioria de nós lida com volumes diários de mensagens de centenas de milhares a centenas de milhões, e não com volumes de bilhões a trilhões (mas, a propósito, há casos em que as pessoas escalam o RabbitMQ para bilhões de mensagens diárias).
Portanto, em nossa série de artigos, não falaremos sobre casos em que extrema escalabilidade é necessária (e essa é a prerrogativa de Kafka), mas focaremos nas vantagens exclusivas que cada um dos sistemas em consideração oferece. Curiosamente, cada sistema tem suas próprias vantagens, mas ao mesmo tempo são bastante diferentes um do outro. É claro que escrevi muito sobre o RabbitMQ, mas garanto que não dou nenhuma preferência particular a ele. Gosto de coisas bem feitas, e RabbitMQ e Kafka são sistemas de mensagens bastante maduros, confiáveis e, sim, escaláveis.
Começaremos no nível superior e depois começaremos a estudar os vários aspectos dessas duas tecnologias. Esta série de artigos é destinada a profissionais envolvidos na organização de sistemas de mensagens ou arquitetos / engenheiros que desejam entender os detalhes do nível mais baixo e sua aplicação. Não escreveremos código, mas focaremos na funcionalidade oferecida pelos dois sistemas, nos modelos de processo de mensagens que cada um deles oferece e nas decisões que os desenvolvedores e arquitetos de decisão devem tomar.
Nesta parte, veremos o que RabbitMQ e Apache Kafka são e sua abordagem para as mensagens. Ambos os sistemas abordam a arquitetura de mensagens de diferentes ângulos, cada um dos quais possui pontos fortes e fracos. Neste capítulo, não chegaremos a nenhuma conclusão importante; em vez disso, propomos que este artigo seja um manual de tecnologia para iniciantes, para que possamos nos aprofundar nos próximos artigos da série.
Rabbitmq
RabbitMQ é um sistema de gerenciamento de fila de mensagens distribuído. Distribuído, porque geralmente funciona como um cluster de nós, onde as filas são distribuídas entre nós e, opcionalmente, são replicadas para serem resistentes a erros e alta disponibilidade. Regularmente, implementa o AMQP 0.9.1 e oferece outros protocolos, como STOMP, MQTT e HTTP através de módulos adicionais.
O RabbitMQ usa abordagens de mensagens clássicas e inovadoras. Clássico no sentido de focar na fila de mensagens e inovador - na possibilidade de roteamento flexível. Esse recurso de roteamento é sua vantagem exclusiva. Criar um sistema de mensagens distribuído rápido, escalável e confiável é uma conquista em si, mas a funcionalidade de roteamento de mensagens o torna realmente excelente entre muitas tecnologias de mensagens.
Trocas e filas
Revisão super simplificada:
- Editores (editores) enviam mensagens para trocas
- Exchange'i envia mensagens em filas e para outras trocas
- O RabbitMQ envia confirmações aos editores após o recebimento de uma mensagem
- Os destinatários (consumidores) mantêm conexões TCP persistentes com o RabbitMQ e anunciam quais filas que recebem
- RabbitMQ envia mensagens para os destinatários
- Os destinatários enviam confirmações de sucesso / erro
- Após o recebimento bem-sucedido, as mensagens são removidas das filas.
Essa lista contém um grande número de decisões que desenvolvedores e administradores devem tomar para obter as garantias de entrega necessárias, características de desempenho etc., cada uma das quais discutiremos mais adiante.
Vamos ver um exemplo de trabalho com um editor, troca, fila e destinatário:

Fig. 1. Um editor e um destinatário
O que fazer se você tiver vários editores da mesma
mensagens? E se tivermos vários destinatários, cada um dos quais deseja receber todas as mensagens?

Fig. 2. Vários editores, vários destinatários independentes
Como você pode ver, os editores enviam suas mensagens para o mesmo trocador, que envia cada mensagem em três filas, cada uma com um destinatário. No caso do RabbitMQ, as filas permitem que diferentes destinatários recebam todas as mensagens. Compare com a tabela abaixo:
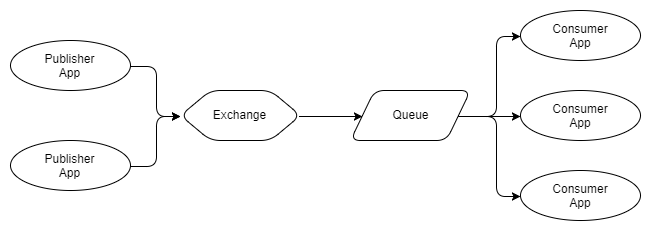
Fig. 3. Vários editores, uma fila com vários destinatários concorrentes
Na Figura 3, vemos três destinatários que usam a mesma fila. Esses são destinatários concorrentes, ou seja, estão competindo para receber mensagens da fila. Assim, pode-se esperar que, em média, cada destinatário receba um terço das mensagens na fila. Usamos destinatários concorrentes para escalar nosso sistema de processamento de mensagens e, usando o RabbitMQ, é muito simples: adicionar ou remover destinatários mediante solicitação. Não importa quantos destinatários concorrentes você tenha, o RabbitMQ entregará apenas mensagens para um destinatário.
Nós podemos combinar arroz. 2 e 3 para receber vários conjuntos de destinatários concorrentes, em que cada conjunto recebe cada mensagem.

Fig. 4. Vários editores, várias filas com destinatários concorrentes
As setas entre trocadores e filas são chamadas de ligações, e falaremos mais sobre elas em mais detalhes.
Garantias
O RabbitMQ oferece garantias de "entrega única" e "pelo menos uma entrega", mas não "exatamente uma entrega".
Nota do tradutor: Antes da versão 0.11 do Kafka, a entrega de mensagens de entrega exatamente uma vez não estava disponível; atualmente, uma funcionalidade semelhante está presente no Kafka.
As mensagens são entregues na ordem em que chegam na fila (afinal, essa é a definição da fila). Isso não garante que a conclusão do processamento de mensagens corresponda à mesma ordem quando houver destinatários concorrentes. Este não é um erro do RabbitMQ, mas a realidade fundamental do processamento paralelo de um conjunto ordenado de mensagens. Esse problema pode ser resolvido usando o Consistent Hashing Exchange, como você verá no próximo capítulo sobre modelos e topologias.
Enviar e pré-buscar destinatários
O RabbitMQ envia mensagens para os destinatários (também existe uma API para receber mensagens do RabbitMQ, mas essa funcionalidade está obsoleta no momento). Isso pode sobrecarregar os destinatários se as mensagens chegarem na fila mais rapidamente do que os destinatários podem processá-las. Para evitar isso, cada destinatário pode definir um limite de pré-busca (também conhecido como limite de QoS). De fato, o limite de QoS é um limite no número de mensagens que não foram reconhecidas pelo destinatário acumulado. Ele age como um fusível quando o receptor começa a ficar lento.
Por que foi decidido que as mensagens na fila são enviadas por push (push) e não descarregadas (pull)? Em primeiro lugar, porque há menos tempo de atraso. Em segundo lugar, idealmente, quando temos destinatários concorrentes da mesma fila, queremos distribuir uniformemente a carga entre eles. Se cada destinatário solicitar / baixar mensagens, dependendo da quantidade solicitada, a distribuição do trabalho poderá se tornar bastante desigual. Quanto mais desigual a distribuição de mensagens, maior o atraso e a perda adicional de ordem das mensagens durante o processamento. Esses fatores orientam a arquitetura RabbitMQ em direção a um mecanismo de envio de uma mensagem por vez. Essa é uma das limitações da escala do RabbitMQ. A limitação é atenuada pelo fato de que as confirmações podem ser agrupadas.
Encaminhamento
As trocas são basicamente roteadores de mensagens para filas e / ou outras trocas. Para que uma mensagem seja movida do Exchange para uma fila ou para outro Exchange, é necessária uma ligação. Trocas diferentes requerem ligações diferentes. Existem quatro tipos de trocas e ligações associadas:
- Fanout Direciona para todas as filas e trocadores vinculados à troca do submodelo Padrão de Pub.
- Direto (direto). Encaminha mensagens com base na chave de roteamento que a mensagem carrega, definida pelo editor. A chave de roteamento é uma sequência curta. Trocadores diretos enviam mensagens para / trocam filas que possuem uma chave de emparelhamento que corresponde exatamente à chave de roteamento.
- Tópico (temático). Encaminha mensagens com base na chave de roteamento, mas permite o uso de correspondência incompleta (curinga).
- Cabeçalho (cabeçalho). O RabbitMQ permite adicionar cabeçalhos de destinatários às mensagens. Trocas de cabeçalho enviam mensagens de acordo com esses valores de cabeçalho. Cada ligação inclui uma correspondência exata dos valores do cabeçalho. Você pode adicionar vários valores à ligação com QUALQUER ou TODOS os valores necessários para corresponder.
- Hashing consistente. Este é um trocador que mistura uma chave de roteamento ou um cabeçalho de mensagem e envia apenas em uma fila. Isso é útil quando você precisa cumprir as garantias da ordem de processamento e ainda conseguir dimensionar os destinatários.

Fig. 5. Exemplo de troca de tópicos
Também consideraremos o roteamento com mais detalhes, mas o exemplo de troca de tópicos é dado acima. Neste exemplo, os editores publicam logs de erro usando o formato da chave de roteamento LEVEL (Nível de erro) .AppName.
A fila 1 receberá todas as mensagens porque usa um número curinga com várias palavras.
A fila 2 receberá qualquer nível de log do aplicativo ECommerce.WebUI. Ele usa curinga *, capturando, assim, o nível de uma única nomeação de tópico (ERROR.Ecommerce.WebUI, NOTICE.ECommerce.WebUI, etc.).
A fila 3 exibirá todas as mensagens de erro de qualquer aplicativo. Ele usa o caractere curinga # para cobrir todos os aplicativos (ERROR.ECommerce.WebUi, ERROR.SomeApp.SomeSublevel, etc.).
Graças a quatro métodos de roteamento de mensagens e com a capacidade de trocar mensagens para enviar mensagens para outras trocas, o RabbitMQ permite que você use um conjunto poderoso e flexível de modelos de troca de mensagens. Além disso, falaremos sobre trocas com trocas de cartas mortas, sobre trocas e filas sem dados (trocas e filas efêmeras), e o RabbitMQ se expandirá para todo o seu potencial.
Troca não entregue
Nota do tradutor: quando as mensagens da fila não podem ser recebidas por um motivo ou outro (energia do consumidor não é suficiente, problemas de rede etc.), elas podem ser atrasadas e processadas separadamente.
Podemos configurar filas para que as mensagens sejam enviadas para troca nas seguintes condições:
- A fila excede o número especificado de mensagens.
- A fila excede o número especificado de bytes.
- O tempo de transmissão da mensagem (TTL) expirou. O editor pode definir o tempo de vida da mensagem e a própria fila também pode ter um TTL especificado para a mensagem. Nesse caso, um TTL mais curto dos dois será usado.
Criamos uma fila vinculada a trocas com mensagens não entregues e essas mensagens são armazenadas lá até que alguma ação seja tomada.
Como muitas funções do RabbitMQ, as trocas com mensagens não entregues tornam possível o uso de modelos que não foram fornecidos originalmente. Podemos usar mensagens TTL e trocas com mensagens não entregues para implementar filas adiadas e filas de repetição.
Trocadores e filas sem dados
Trocas e filas podem ser criadas dinamicamente e você pode definir critérios para a remoção automática. Isso permite o uso de padrões como RPCs baseados em mensagens.
Módulos adicionais
O primeiro plug-in que você provavelmente deseja instalar é o plug-in de gerenciamento, que fornece ao servidor HTTP uma interface da web e uma API REST. É muito fácil de instalar e possui uma interface fácil de usar. A implantação de scripts por meio da API REST também é muito simples.
Além disso:
- Troca de hash consistente, troca de sharding e muito mais
- protocolos como STOMP e MQTT
- ganchos da web
- tipos adicionais de trocadores
- Integração SMTP
Há muitas outras coisas que podem ser ditas sobre o RabbitMQ, mas este é um bom exemplo que permite descrever o que o RabbitMQ pode fazer. Agora, examinamos o Kafka, que usa uma abordagem completamente diferente das mensagens e, ao mesmo tempo, também possui seu próprio conjunto de recursos distintos e interessantes.
Apache kafka
Kafka é um log de confirmação replicado distribuído. Kafka não tem um conceito de filas, o que pode parecer estranho a princípio, uma vez que é usado como um sistema de mensagens. As filas são sinônimo de sistemas de mensagens. Primeiro, vamos ver o que significa um "log de confirmação de alterações replicado e distribuído":
- Distribuído porque o Kafka é implantado como um cluster de nós, tanto para tolerância a erros quanto para dimensionamento
- Replicado, pois as mensagens geralmente são replicadas em vários nós (servidores).
- Um log de confirmação porque as mensagens são armazenadas em logs segmentados, somente anexos, chamados tópicos. Esse conceito de registro é a principal vantagem exclusiva do Kafka.
Compreender o diário (e o tópico) e as partições é a chave para entender o Kafka. Então, como um log particionado difere de um conjunto de filas? Vamos imaginar como é.
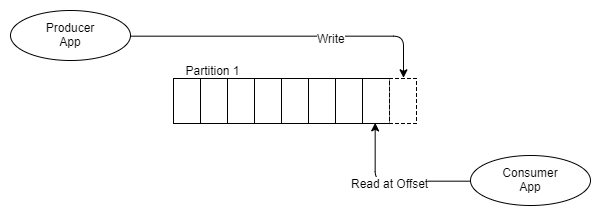
Fig. 6 Um produtor, um segmento, um destinatário
Em vez de colocar mensagens na fila FIFO e monitorar o status dessa mensagem na fila, como o RabbitMQ faz, Kafka simplesmente a adiciona ao log, e isso é tudo.
A mensagem permanece, independentemente de ser recebida uma ou mais vezes. Ele é excluído de acordo com a política de retenção, também chamada de período de janela. Como as informações são tiradas do tópico?
Cada destinatário controla onde está localizado no log: há um ponteiro para a última mensagem recebida e esse ponteiro é chamado de endereço de deslocamento. Os destinatários suportam esse endereço por meio de bibliotecas cliente e, dependendo da versão do Kafka, o endereço é armazenado no ZooKeeper ou no próprio Kafka.
Uma característica distintiva do modelo de registro no diário é que elimina instantaneamente muitas dificuldades em relação ao status da entrega de mensagens e, mais importante para os destinatários, permite que eles retrocedam, retornem e recebam mensagens no endereço relativo anterior. Por exemplo, imagine que você está implantando um serviço que emite faturas que levam em conta os pedidos feitos pelos clientes. O serviço tem um erro e não calcula corretamente todas as contas em 24 horas. Com o RabbitMQ, na melhor das hipóteses, você precisará republicar esses pedidos apenas no serviço de conta. Mas com Kafka, você simplesmente move o endereço relativo desse destinatário 24 horas atrás.
Então, vamos ver como fica quando há um tópico em que há uma partição e dois destinatários, cada um dos quais deve receber cada mensagem.

Fig. 7. Um produtor, uma partição, dois destinatários independentes
Como pode ser visto no diagrama, dois destinatários independentes recebem a mesma partição, mas lidos em diferentes endereços de deslocamento. Talvez o serviço de cobrança demore mais para processar as mensagens do que o serviço de notificação por push. ou talvez o serviço de cobrança não estivesse disponível por algum tempo e tentasse recuperar o atraso mais tarde. Ou talvez tenha havido um erro, e o endereço de deslocamento teve que ser adiado por várias horas.
Agora, suponha que o serviço de cobrança precise ser dividido em três partes, porque não pode acompanhar a velocidade da mensagem. Com o RabbitMQ, simplesmente implantamos mais dois aplicativos de serviço de cobrança que chegam da fila de cobrança. Mas o Kafka não suporta destinatários concorrentes na mesma partição; o bloco de simultaneidade Kafka é a própria partição. Portanto, se precisarmos de três destinatários de contas, precisaremos de pelo menos três partições. Então agora temos:
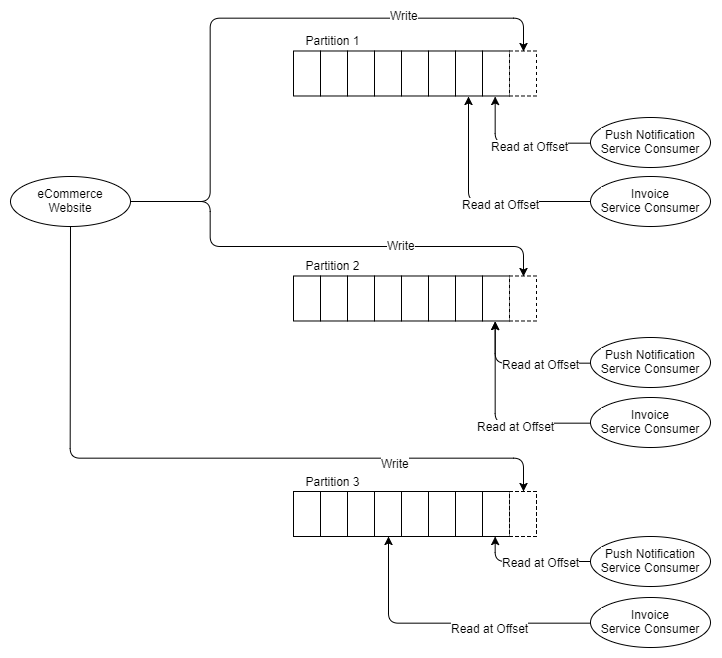
Fig. 8. Três partições e dois grupos de três destinatários
Assim, entende-se que você precisa de pelo menos tantas partições quanto o destinatário horizontal mais dimensionado. Vamos falar um pouco sobre partições.
Partições e grupos de destinatários
Cada partição é um arquivo separado no qual a sequência de mensagens é garantida. É importante lembrar: a ordem das mensagens é garantida em apenas uma partição. No futuro, isso pode levar a alguma contradição entre os requisitos de enfileiramento de mensagens e os requisitos de desempenho, já que o desempenho no Kafka também é dimensionado por partições. A partição não pode suportar destinatários concorrentes, portanto, nosso aplicativo de cobrança pode usar apenas uma parte para cada seção.
As mensagens podem ser redirecionadas para segmentos por um algoritmo cíclico ou por uma função hash: hash (chave da mensagem)% número de partições. , , , , , , . .
RabbitMQ. . , RabbitMQ , . , .
RabbitMQ . Kafka , .
, , Kafka , RabbitMQ — . RabbitMQ , . Kafka , . , , Kafka , .
, , , ( ). , , . , , , .
RabbitMQ — Consistent Hashing exchange, . Kafka' , Kafka , , , , , -. RabbitMQ , , , .
: , , Id 1000 , Id 1000 . , , . , .
(push) (pull)
RabbitMQ (push) , , . RabbitMQ . , Kafka (pull), . , , Kafka long-polling.
(pull) Kafka - . Kafka , , .
RabbitMQ, , , , . Kafka , .
Kafka /» , , . , .
Fig. 9.
, , Kafka :
. 10. ,

, :

Fig. 11.
, , .
, , , , .

Fig. 12.
. .

:
, . , , .
Kafka – , , , , , . . , . , , .
— . , 50 . – . , , , .
, , . , , . , . , , , .
. , , .
, RabbitMQ, Kafka, Kafka . RabbitMQ , , ZooKeeper Consul.
RabbitMQ , Kafka. RabbitMQ, , . : .
. , . . , . . . , , - .
, Kafka, . . , , .
, . RabbitMQ , Kafka .
Conclusões
RabbitMQ , . , , . , . , , .
Kafka . , . Kafka , RabbitMQ . , Kafka , RabbitMQ, , .
RabbitMQ.
, , IoT , . : t.me/justiothings