Habr, olá! Esta é uma transcrição do relatório de Artyom ximaera Gavrichenkov, que ele leu no BackendConf 2018 como parte do festival RIT ++.

Olá!
O título do relatório contém uma longa lista de protocolos; passaremos por ele gradualmente, mas vamos começar com o que não está no título.
Este (sob o corte) do cabeçalho de um dos blogs, na Internet, você pode ver muitos desses títulos. Nesse post está escrito que o HTTP / 2 não é um futuro distante, é o nosso presente; Este é um protocolo moderno desenvolvido pelo Google e centenas de profissionais de muitas empresas avançadas, lançado pela IETF como RFC em 2015, ou seja, já há 3 anos.
Os padrões da IETF são aceitos pela indústria, como documentos de concreto armado, como uma lápide, de fato.

Está planejado que eles determinem o desenvolvimento da Internet e levem em consideração todos os cenários de uso possíveis. Ou seja, se tivéssemos uma versão antiga do protocolo e, em seguida, uma nova aparecesse, ele definitivamente mantém a compatibilidade com todos os casos de usuários anteriores e, além disso, resolve vários problemas, otimiza o trabalho e assim por diante.
O HTTP / 2 teve que ser adaptado para a Web avançada, pronto para uso em serviços e aplicativos modernos; de fato, seria
um substituto para as versões mais antigas do protocolo HTTP. Era para aumentar o desempenho do site e reduzir a carga de back-end.

Até os SEOs disseram que precisavam de HTTP / 2.

E parecia ser muito fácil de apoiar. Em particular, Neil Craig, da BBC, escreveu em seu blog que bastava "apenas ativá-lo" no servidor. Você ainda pode encontrar muitas apresentações em que diz que o HTTP / 2 está incluído da seguinte maneira: se você tiver o Nginx, poderá corrigir a configuração em um único local; se não houver HTTPS, você também precisará colocar um certificado; mas, em princípio, é uma questão de um token no arquivo de configuração.
E, é claro, depois de registrar esse token, você imediatamente começa a receber bônus por aumento de produtividade, novos recursos disponíveis, oportunidades - em geral, tudo se torna maravilhoso.
 Links do slide:
Links do slide:
1. medium.com/@DarkDrag0nite/how-http-2-reduces-server-cpu-and-bandwidth-10dbb8458feb
2.www.cloudflare.com/website-optimization/http2A história adicional é baseada em eventos reais. A empresa possui algum serviço online que processa cerca de 500-1000 solicitações HTTP por segundo. Este serviço está sob proteção DDoS do Cloudflare.
Existem muitos parâmetros de referência que confirmam que a mudança para HTTP / 2 reduz a carga no servidor devido ao fato de que, ao mudar para HTTP / 2, o navegador estabelece não 7 conexões, mas uma de acordo com o plano. Esperava-se que, ao alternar para HTTP / 2, a memória usada se tornasse menor e o processador menos carregado.
Além disso, o blog Cloudflare e o site Cloudflare sugerem a ativação do HTTP / 2 com apenas um clique. Pergunta: Por que não fazer isso?

Em 1 de fevereiro de 2018, a empresa inclui HTTP / 2 com este botão no Cloudflare e no Nginx local também o inclui. Os dados do mês são coletados. Em 1º de março, os recursos consumidos são medidos e, em seguida, os sysops analisam o número de solicitações nos logs enviados via HTTP / 2 para o servidor atrás do Cloudflare. O próximo slide será a porcentagem de solicitações que chegaram ao servidor via HTTP / 2. Levante as mãos, quem sabe qual será esse percentual?
[Da platéia: "1-2%!"]
Zero. Por que razão?
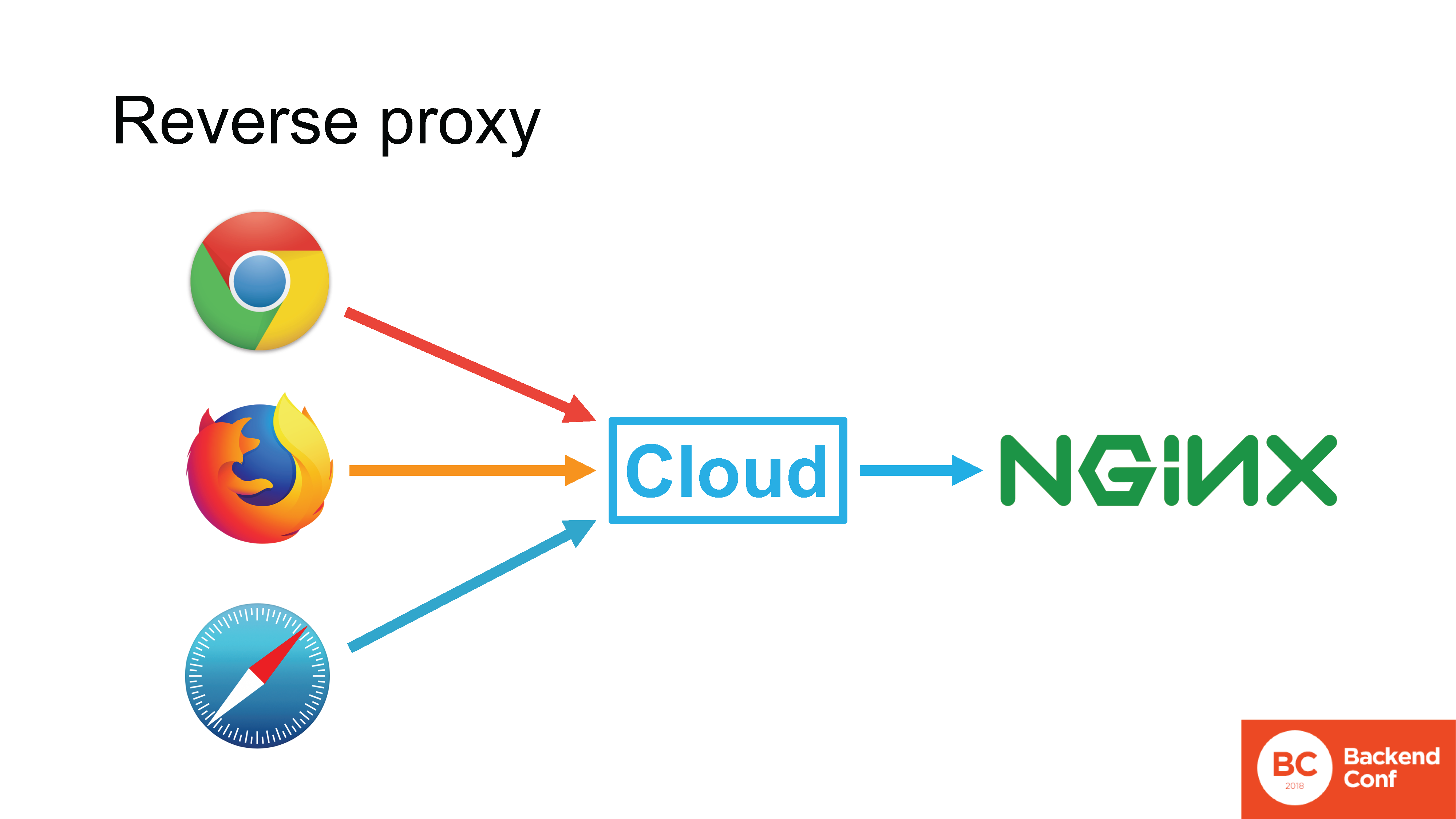
O Cloudflare, bem como outros serviços de proteção contra ataques, MSSP e serviços em nuvem, operam no modo
proxy reverso . Se em uma situação normal o navegador se conectar diretamente ao seu Nginx, ou seja, a conexão for diretamente do navegador ao seu servidor HTTP, você poderá usar o protocolo que o navegador suporta.
Se houver uma nuvem entre o navegador e o servidor, a conexão TCP de entrada será encerrada na nuvem, o TLS também será encerrado lá e a solicitação HTTP primeiro será direcionada para a nuvem, e a nuvem realmente processará essa solicitação.
A nuvem possui seu próprio servidor HTTP, na maioria dos casos o mesmo Nginx; em casos raros, é um servidor "auto-escrito". Este servidor analisa a solicitação, de alguma forma a processa, consulta com caches e, por fim, forma uma nova solicitação e a envia já para o servidor usando o protocolo que ele suporta.
Todas as nuvens existentes que pretendem oferecer suporte a HTTP / 2 oferecem suporte a HTTP / 2 na lateral do navegador. Mas não o apoie do lado olhando para você.
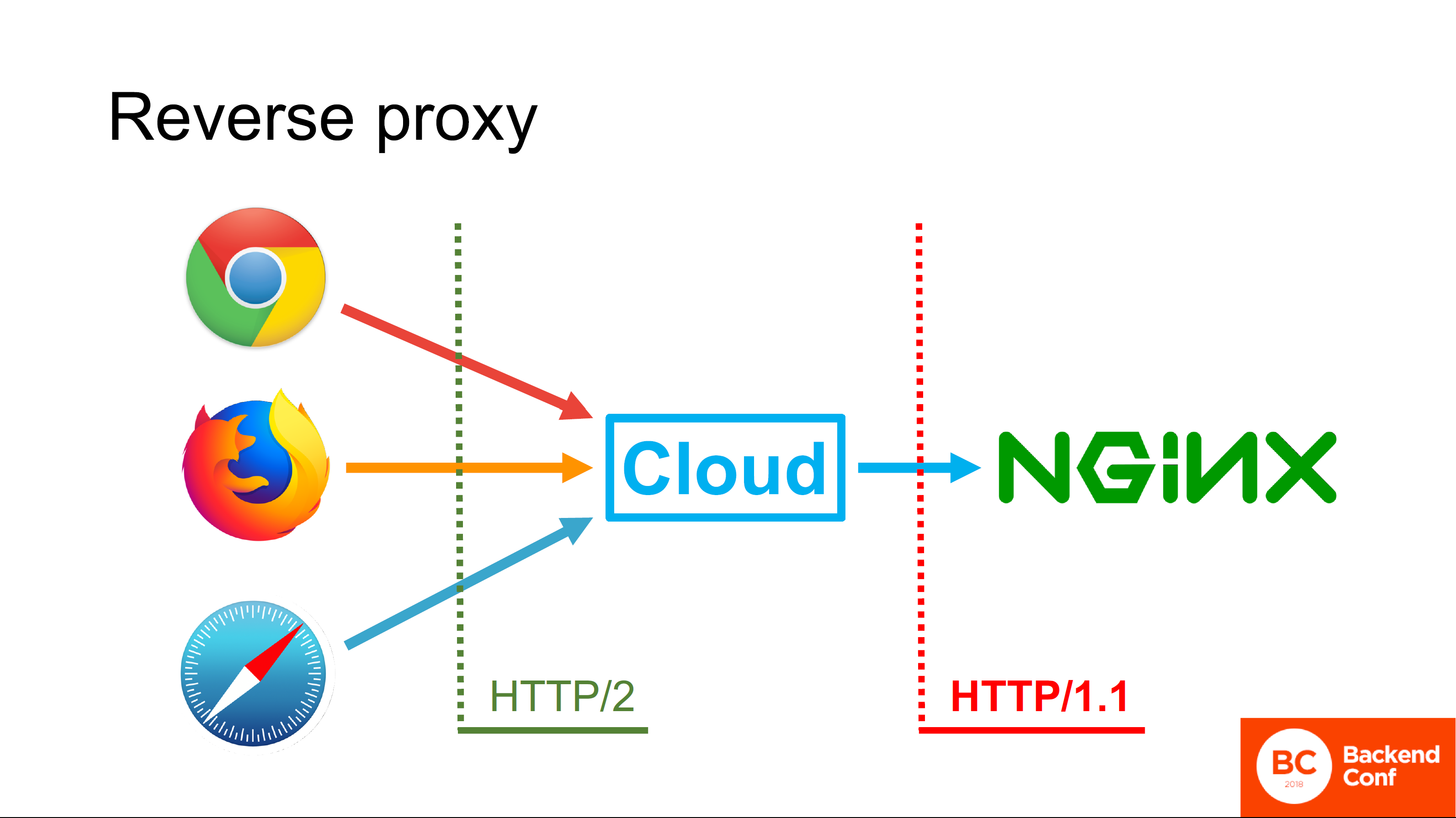
Porque
Uma resposta simples e não totalmente correta: "Como na maioria dos casos eles têm o Nginx implantado, o Nginx não pode passar o HTTP / 2 para o upstream". Ok, bem, esta resposta está
correta , mas não
completa .

A resposta completa nos é dada pelos engenheiros do Cloudflare. O fato é que o foco da especificação HTTP / 2, escrita e lançada em 2015, era aumentar o desempenho do navegador em casos de uso específicos, por exemplo, para o Google.
O Google usa suas próprias tecnologias, não usa proxy reverso na frente de seus servidores de produção; portanto, ninguém pensou em proxy reverso, e é por isso que o HTTP / 2 da nuvem para o upstream não é usado. De fato, há pouco lucro, porque no modo proxy reverso, do que é descrito no protocolo HTTP / 2, por exemplo, o Server Push não é suportado, porque não está claro como ele deve funcionar se tivermos pipelining.
O fato de o HTTP / 2 salvar conexões é legal, mas apenas o proxy reverso as salva porque não abre uma conexão por usuário. Há pouco sentido em oferecer suporte ao HTTP / 2 aqui, e a sobrecarga e os problemas associados a isso são grandes.

O que é importante: o proxy reverso é uma tecnologia que começou a ser usada ativamente há cerca de 13 anos. Ou seja, esta é a tecnologia de meados dos anos 2000: eu fui para a escola enquanto ela já estava em uso. Não é mencionado no padrão emitido em 2015, não é suportado e o trabalho para apoiá-lo atualmente não é realizado no grupo de trabalho httpbis na IETF.
Este é um exemplo dos problemas que surgem quando as pessoas começam a implementar o HTTP / 2. De fato, quando você conversa com pessoas que já implantaram e já têm alguma experiência com isso, ouve constantemente as mesmas palavras.

Eles foram melhor formulados por Maxim Matyukhin, do Badoo,
em um post no Habré, onde ele falou sobre como o HTTP / 2 Server Push funciona. Ele escreveu que ficou muito surpreso com o quão diferente era a interação dessa funcionalidade específica com os navegadores,
porque ele pensava que era um recurso totalmente desenvolvido, pronto para uso na produção . Já ouvi essa frase em relação ao HTTP / 2 muitas vezes: pensávamos que era um protocolo de substituição drop-in - ou seja, você a ativa e está tudo bem - por que tudo é tão complicado na prática, de onde vêm todos esses problemas e falhas?
Vamos descobrir.
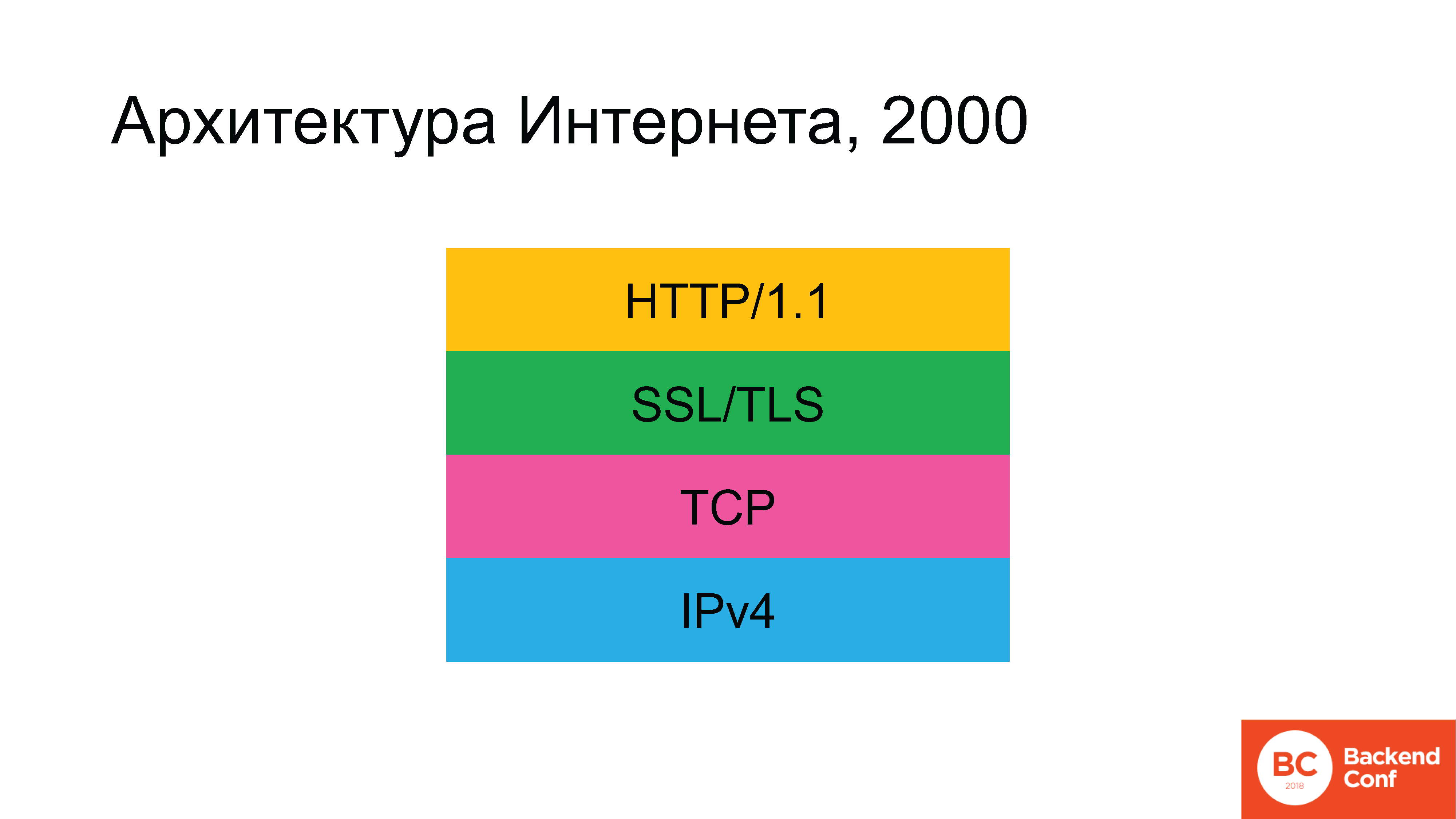
Historicamente, nos tempos antigos, a arquitetura da Internet era algo assim. Não havia retângulo verde em algum momento, mas ele apareceu.
Os seguintes protocolos foram utilizados: como estamos falando da Internet e não da rede local, no nível inferior, começamos com o IPv4. Acima dele, o protocolo TCP ou UDP foi usado, mas em 90% dos casos (uma vez que 80-90% do tráfego na Internet é a Web), o TCP foi o próximo, o SSL (o qual foi substituído pelo TLS) e, acima, o hipertexto HTTP . Gradualmente, surgiu a situação de que, de acordo com o plano, até 2020 a arquitetura da Internet deveria ter mudado radicalmente.

O IPv6 está conosco há muito tempo. O TLS foi atualizado recentemente, ainda discutiremos como isso aconteceu. E o protocolo HTTP / 2 também foi atualizado.
O maravilhoso escritor de ficção científica nacional Vadim Panov, no ciclo dos Enclaves, tinha uma
frase tão
maravilhosa : “Você estava esperando o futuro. Você quer um futuro? Chegou. Você não o queria? Chegou assim mesmo. A única coisa que permaneceu praticamente intocada - há alguns anos - é o protocolo TCP.
As pessoas envolvidas no design da Internet não puderam passar por uma flagrante injustiça e decidiram lançar o protocolo TCP também.
Ok, isso é, claro, uma piada. O problema não é apenas que o protocolo seja muito antigo. Existem falhas no TCP. Para muitos, foi especialmente preocupante o fato de o protocolo HTTP / 2 já estar escrito, o padrão de 2015 já estar sendo implementado, mas nem sempre ele estava trabalhando especificamente com o TCP, e seria bom colocar outro transporte sob ele, mais adequado para o que antes chamado SPDY quando essas conversas foram e, em seguida, para HTTP / 2.

O protocolo decidiu ligar para o QUIC. O QUIC é um protocolo atualmente sendo desenvolvido para transporte. É baseado em UDP, ou seja, é um protocolo de
datagrama . O primeiro rascunho do padrão foi lançado em julho de 2016 e a versão de rascunho atual ...
[Alto-falante verifica e-mails no telefone]"... sim, ainda o dia 12".
No momento, o QUIC ainda não é um padrão - ele está escrito ativamente. Se não me engano - não escrevi no slide porque tinha medo de cometer um erro - mas na IETF 101 em Londres, foi dito que em novembro de 2018 estava planejado lançá-lo como um documento final. É o próprio padrão QUIC, porque há
mais oito documentos no grupo de trabalho.

Ou seja, ainda não existe um padrão, mas o hype ativo já está em andamento. Listei apenas as conferências em que estive nos últimos seis meses, nas quais houve pelo menos uma apresentação sobre o QUIC. Sobre "como é legal", "como precisamos mudar para ele", "o que fazer para os operadores", "pare de filtrar o UDP - o QUIC funcionará agora". Todo esse hype vem acontecendo há algum tempo - eu já vi muitos artigos que instavam a indústria de jogos a mudar para o QUIC em vez do UDP usual.
 Links do slide:
Links do slide:
1. conferences.sigcomm.org/imc/2017/papers/imc17-final39.pdf
2. blog.apnic.net/2018/01/29/measuring-quic-vs-tcp-mobile-desktopEm novembro de 2017, o seguinte link apareceu na lista de discussão do grupo de trabalho QUIC: o principal do whitepaper e o inferior para aqueles que acham difícil ler o whitepaper - este é um link para o blog da APNIC com um resumo.
Os pesquisadores decidiram comparar o desempenho do TCP e do QUIC em sua forma atual. Para comparação, para não lidar com quem é o culpado e onde o Windows pode ser culpado, no lado do cliente, eles usaram o Chrome para Ubuntu e também usaram dois dispositivos móveis: um Nexus e outro Samsung
(nota do editor: Nexus 6 e MotoG) com as versões Android 4 e 6 e também lançaram o Chrome.
No lado do servidor, eles instalaram o Apache para ver como o servidor TCP funciona e, para monitorar o QUIC, extraem uma parte do código-fonte aberto que está no projeto Chromium. Os resultados de benchmark mostraram que, embora em todas as condições de efeito estufa o QUIC realmente supere o TCP, existem algumas pedras angulares que ele perde.

Por exemplo, a implementação QUIC do Google funciona significativamente pior que o TCP se a reordenação de pacotes ocorrer na rede, ou seja, os pacotes chegarem na ordem errada em que foram enviados pelo servidor. Em 2017-2018, na era das redes móveis e sem fio, geralmente não há garantia de que o pacote voe em princípio, sem mencionar em que ordem. O QUIC funciona muito bem em uma rede com fio, mas quem usa uma rede com fio agora?

Em geral, os desenvolvedores desse código no Google, aparentemente, realmente não gostam de telefones celulares.
QUIC é um protocolo implementado sobre o UDP no espaço do usuário. E também em dispositivos móveis, no espaço do usuário. De acordo com os resultados da medição, em uma situação normal, ou seja, ao trabalhar através de uma rede sem fio, a implementação do protocolo QUIC passa 58% do tempo no Android no estado "Application Limited". O que é essa condição? É o estado em que enviamos alguns dados e aguardamos confirmação. Para comparação, em desktops, houve um valor de cerca de 7%.
Apenas dois casos de uso: o primeiro é uma rede sem fio, o segundo é um dispositivo móvel; e o QUIC funciona como TCP ou substancialmente pior. Naturalmente, isso acabou no grupo de trabalho da IETF dedicado ao QUIC e, naturalmente, o Google reagiu a isso. A resposta do Google foi a seguinte:
 mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGE
mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGEBem, nós rimos, mas na verdade é absolutamente lógico.
Porque Porque o design do QUIC - apesar de já estarmos falando sobre implementação na produção, mas - de fato, é o experimento mais selvagem.
Aqui está, digamos, um modelo ISO / OSI de sete níveis. Quem se lembra dela aqui? Lembre-se dos níveis: físico, canal, rede, transporte, algumas bobagens, algumas bobagens e aplicação, certo?
Sim, foi desenvolvido há muito tempo e, de alguma forma, vivíamos com esse modelo de nível. QUIC é um experimento para eliminar o próprio sistema de camadas da rede. Combina criptografia, transporte e entrega confiável de dados. Tudo isso não está na estrutura de camadas, mas na combinação, onde cada componente tem acesso à API de outros componentes.
 Citando um dos projetistas do
Citando um dos projetistas do protocolo QUIC, Christian Guitem: "Uma das principais vantagens do QUIC, do ponto de vista arquitetônico, é a falta de uma estrutura de níveis". Temos reconhecimento, controle de fluxo, criptografia e toda a criptografia - tudo isso em um só transporte, e nossas inovações em transporte implicam acesso a tudo isso diretamente à API da rede, portanto, não queremos uma arquitetura em camadas no QUIC.

A conversa no grupo de trabalho sobre isso começou devido ao fato de que, no início de março, outro projetista de protocolo QUIC, chamado Eric Rescorla, decidiu propor para discussão uma variante na qual toda a criptografia é removida do QUIC, em geral. Tudo o que resta é uma função de transporte executada sobre o DTLS. O DTLS, por sua vez, é TLS sobre UDP; no total, verifica-se: QUIC sobre TLS sobre UDP.
De onde veio essa oferta? A propósito, o Rescorla escreveu um documento grande, mas não se tornou um padrão - era um assunto para discussão, porque no processo de projetar a arquitetura QUIC, no processo de testar a interoperabilidade e a implementação, muitos problemas surgiram. Principalmente relacionado ao "fluxo 0".
O que é o fluxo 0 no QUIC? É a mesma idéia que no HTTP / 2: temos uma conexão; dentro dela, temos vários fluxos multiplexados. Por design QUIC, eu me lembro, a criptografia é fornecida pelo mesmo protocolo. Isso foi feito da seguinte maneira: um fluxo "mágico" número 0 é aberto, responsável por estabelecer uma conexão, agitando as mãos e a criptografia, após o que esse fluxo 0 é criptografado e todos os outros também são criptografados. Com isso muitos problemas surgiram, eles estão listados na lista de discussão, existem 10 itens, eu não pararei em cada um. Vou destacar apenas um que eu realmente gosto.
 www.ietf.org/mail-archive/web/quic/current/msg03498.html
www.ietf.org/mail-archive/web/quic/current/msg03498.htmlO problema com o segmento 0, um dos quais, é que, se estamos perdendo pacotes, precisamos reenviá-los. E, ao mesmo tempo, por exemplo, no lado do servidor, a conexão já pode ser marcada como criptografada e o pacote perdido remonta ao momento em que não foi criptografado. Nesse caso, ao encaminhar, a implementação pode criptografar aleatoriamente pacotes.
Mais uma vez:
 Criptografar aleatoriamente pacotes.
Criptografar aleatoriamente pacotes.Isso é bastante difícil de comentar, além de dizer como tudo isso foi realmente projetado. O desenvolvimento do QUIC realmente usa a abordagem ersatz-ágil. Ou seja, não é que alguém tenha escrito um padrão de concreto reforçado que possa ser lançado oficialmente após algumas iterações. Não.

O trabalho é o seguinte:
1. O rascunho da norma inicia, por exemplo, o número 5;
2. Nas listas de discussão, bem como nas reuniões da IETF - três partes por ano - é realizada uma discussão, em seguida, a implementação é realizada em hackathons, testes de interoperabilidade e coleta de feedback;
3. O Google implementa algumas das alterações no Chrome, em sua própria infraestrutura, analisa as consequências e, em seguida, o contador é incrementado e o padrão 6 é exibido.
Agora, eu lembro, versão 12.
Nota Ed.: Em 10 de julho de 2018, já é o 13º.O que é importante aqui?
Em primeiro lugar, acabamos de ver os contras, mas há vantagens. De fato, você pode participar desse processo. O feedback é coletado de todas as partes envolvidas: se você está envolvido em jogos, se acha que na indústria de jogos pode simplesmente mudar e alterar o UDP, configure o QUIC e tudo funcionará - não, não funcionará. Mas, no momento em que você pode influenciá-lo, de alguma forma pode trabalhar com ele.

E isso é, de fato, uma história comum. O seu feedback é esperado, todo mundo quer vê-lo.
O Google está desenvolvendo um protocolo, colocando algumas idéias nele - para seus próprios propósitos. Empresas que fazem outras coisas (se isso não é típico da Web, jogos ou aplicativos móveis, SEO é o mesmo), eles não podem, por padrão, esperar que o protocolo leve em consideração seus interesses: não apenas porque não interessa a ninguém, mas porque ninguém sabe sobre esses interesses.
Aliás, é uma confissão. Obviamente, a pergunta é para mim por que nós, como
Qrator Labs , em particular, não participamos do desenvolvimento do protocolo HTTP / 2 e não falamos a ninguém sobre proxy reverso. Mas o mesmo Cloudflare e Nginx também não participaram lá.
Embora a indústria não esteja envolvida nisso, Google, Facebook, algumas outras empresas e
acadêmicos estão se desenvolvendo. Para que você saiba, no partido próximo à IETF, a palavra "acadêmico" não é, digamos, louvável. Soa como os epítetos "esquizofrênico" e "hipocondríaco". As pessoas costumam chegar sem objetivos práticos, sem entender as tarefas reais, mas se encaixam, porque é mais fácil obter uma dissertação de doutorado.
Obviamente, é preciso participar disso e não há outras opções.

Voltando ao QUIC: então, o protocolo é implementado no espaço do usuário, em dispositivos móveis há ... Blá blá. "Implementado no espaço do usuário." Vamos conversar sobre isso.
Como geralmente organizamos o transporte antes de criarmos o QUIC? Como funciona agora na produção? Existe um protocolo TCP se estivermos falando sobre a Web.
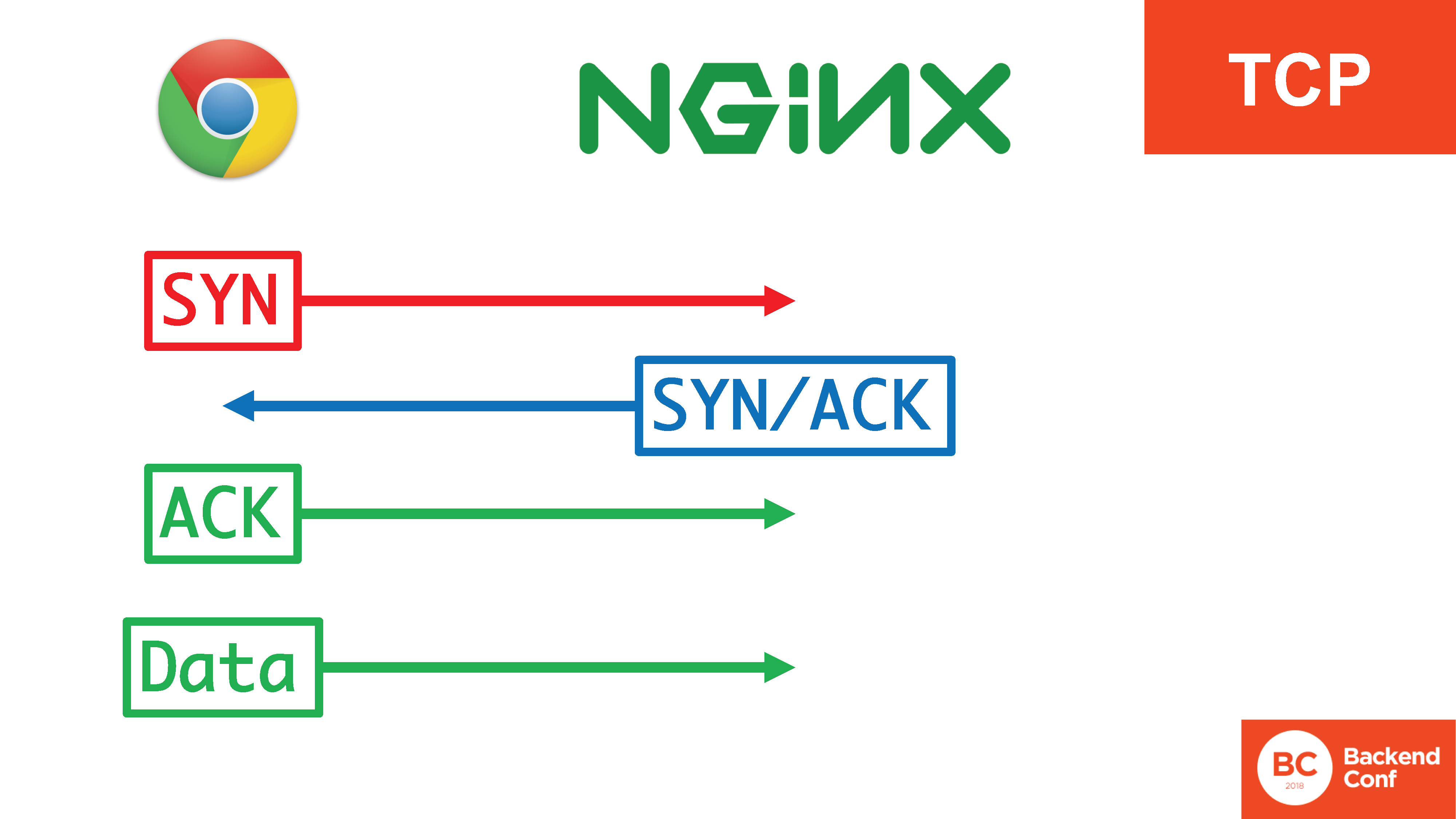
No TCP, existe um
aperto de mão triplo : SYN, SYN / ACK, ACK. É necessário para várias coisas: impedir que o servidor seja usado para atacar outras pessoas, filtrar com êxito determinados ataques no protocolo TCP, como
inundação SYN . Somente após a passagem de três segmentos do handshake triplo, começamos a enviar dados.
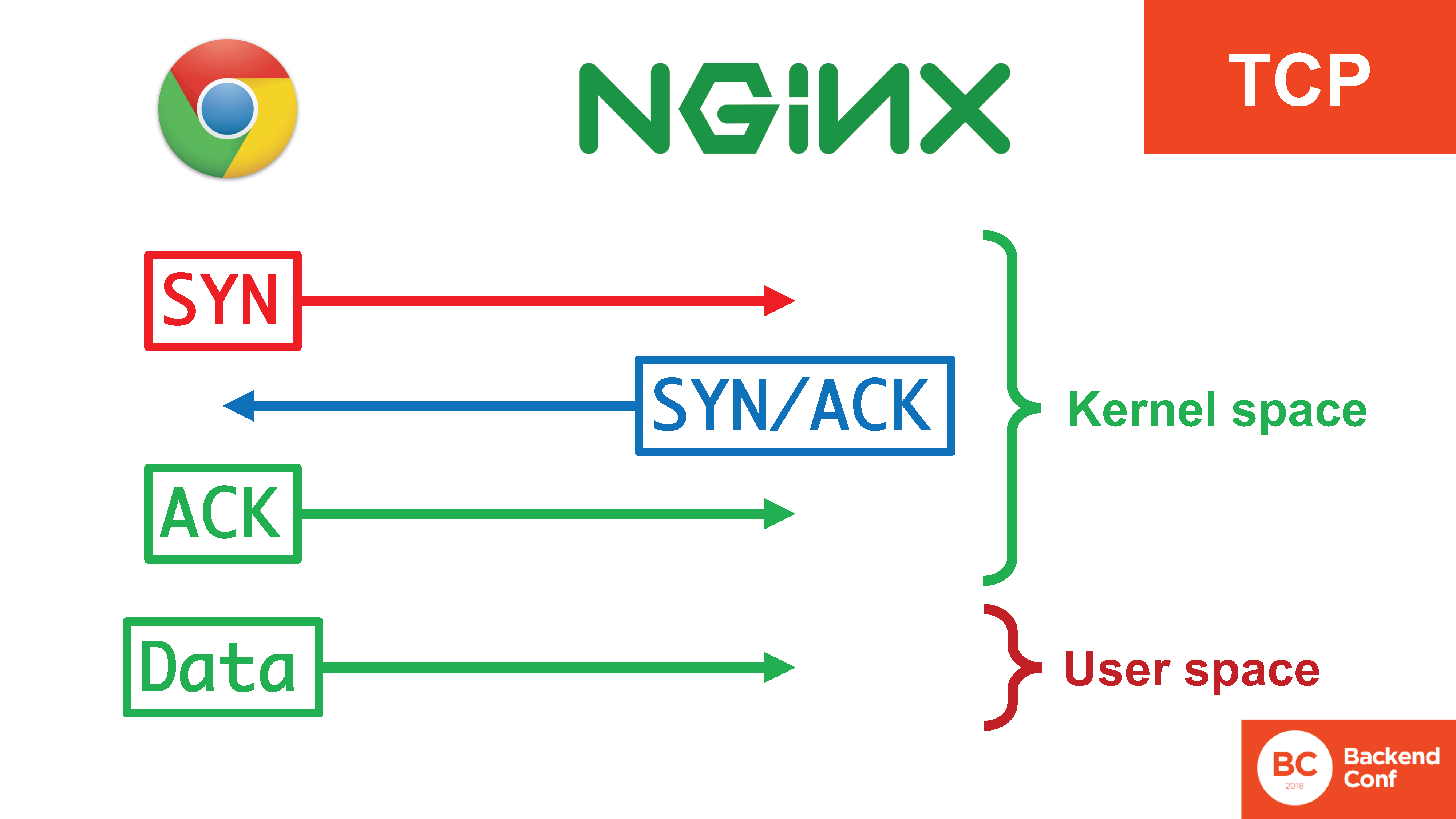
Ao mesmo tempo, existem 4 ações, 3 das quais ocorrem no kernel, elas ocorrem com bastante eficiência e os dados já entram no espaço do usuário quando a conexão é estabelecida.
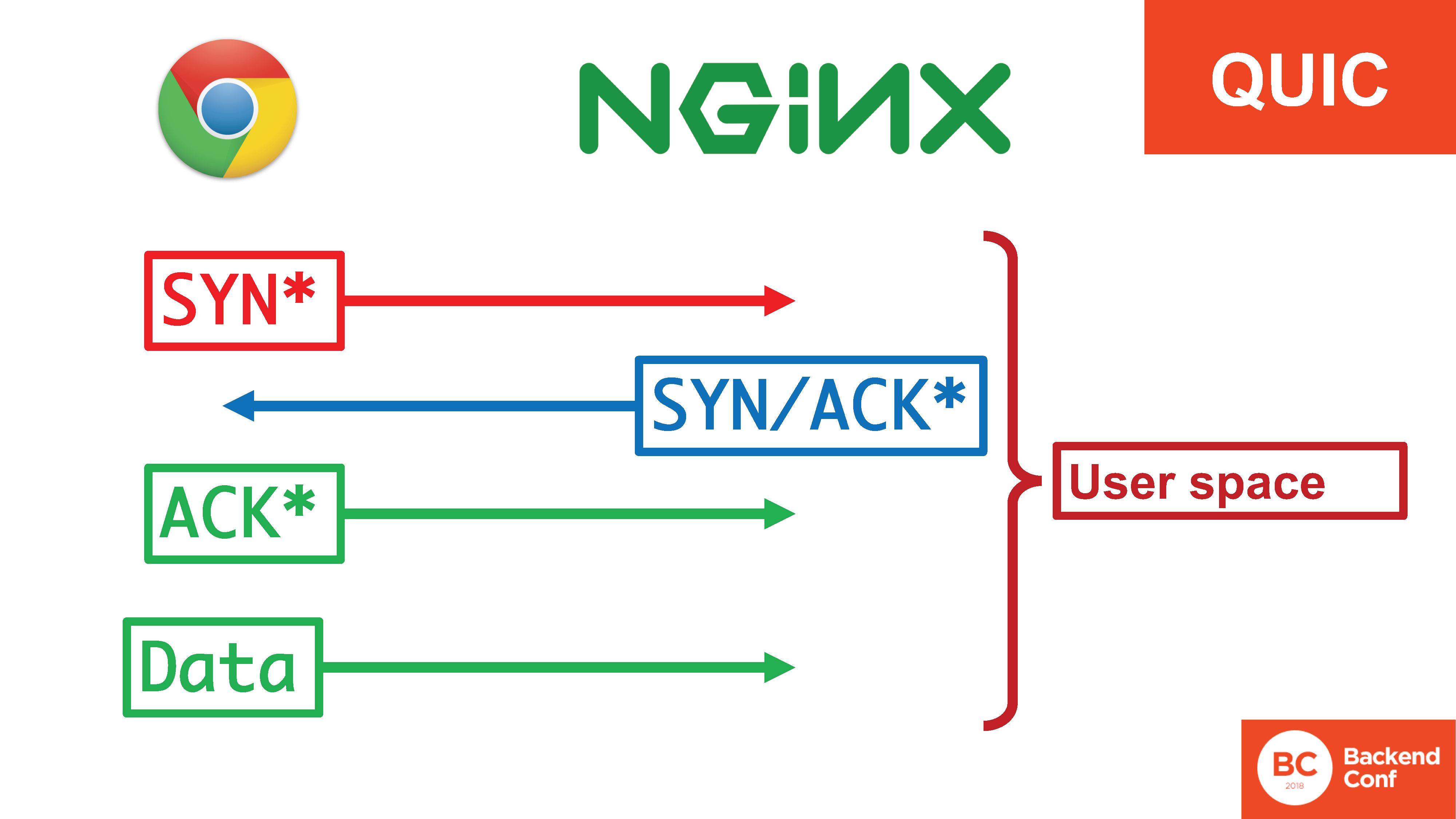
Na situação com QUIC, toda essa felicidade está no espaço do usuário.
Existe um asterisco aqui, porque a terminologia não é exatamente “SYN, SYN / ACK”, mas, de fato, esse é o mesmo handshake, apenas movido completamente para o espaço do usuário. Se 20 Gbit / s de flooding voam e antes no TCP, eles poderiam ser processados no kernel com cookies SYN , agora eles precisam ser processados no espaço do usuário, pois passam pelo kernel inteiro por todas as alternâncias de contexto. E aí eles precisam ser apoiados de alguma forma.Por que isso é feito? Por que o QUIC é um protocolo de espaço do usuário? Embora o transporte, ao que parece, seja o próprio lugar para ele em algum lugar no nível do sistema. Porque, novamente, esse é o interesse do Google e de outros membros da equipe. Eles querem ver o novo protocolo implementado, não querem esperar até que todos os sistemas operacionais no distrito sejam atualizados. Se for implementado no espaço do usuário, poderá ser usado (em particular, no navegador, mas não apenas) agora.O fato de você precisar gastar muitos recursos no lado do servidor não é um problema para o Google. Em algum lugar, havia um bom ditado: para resolver a maioria dos problemas de desempenho no back-end da Internet moderna, o Google só precisa confiscar metade dos servidores (e de preferência três quartos). O que não deixa de ter bom senso, porque o Google, de fato, não é trocado por essas ninharias.
Porque, novamente, esse é o interesse do Google e de outros membros da equipe. Eles querem ver o novo protocolo implementado, não querem esperar até que todos os sistemas operacionais no distrito sejam atualizados. Se for implementado no espaço do usuário, poderá ser usado (em particular, no navegador, mas não apenas) agora.O fato de você precisar gastar muitos recursos no lado do servidor não é um problema para o Google. Em algum lugar, havia um bom ditado: para resolver a maioria dos problemas de desempenho no back-end da Internet moderna, o Google só precisa confiscar metade dos servidores (e de preferência três quartos). O que não deixa de ter bom senso, porque o Google, de fato, não é trocado por essas ninharias. www.ietf.org/mail-archive/web/quic/current/msg03736.htmlNa tela, há uma citação literal da lista de discussão QUIC, onde a discussão era sobre apenas que o protocolo está planejado para implementação no espaço do usuário. Esta é uma citação literal: “Queremos implantar o QUIC em qualquer máquina sem o suporte do sistema operacional. Se alguém tiver problemas de desempenho, levará tudo ao essencial. ” O QUIC já é tão flexível que é assustador levar isso ao núcleo com criptografia e tudo mais, mas o grupo de trabalho sobre esse assunto também não está particularmente preocupado.
www.ietf.org/mail-archive/web/quic/current/msg03736.htmlNa tela, há uma citação literal da lista de discussão QUIC, onde a discussão era sobre apenas que o protocolo está planejado para implementação no espaço do usuário. Esta é uma citação literal: “Queremos implantar o QUIC em qualquer máquina sem o suporte do sistema operacional. Se alguém tiver problemas de desempenho, levará tudo ao essencial. ” O QUIC já é tão flexível que é assustador levar isso ao núcleo com criptografia e tudo mais, mas o grupo de trabalho sobre esse assunto também não está particularmente preocupado. E por que essa abordagem é usada no lado do cliente - eu posso entender. Mas a mesma abordagem é usada no lado do servidor. Teoricamente, nesse caso, o QUIC realmente valeria a pena ser levado ao cerne, mas, novamente, o trabalho sobre isso não está em andamento e, quando terminar, teremos cabelos grisalhos na melhor das hipóteses, e não pretendo viver para sempre. E quando isso acontece - não é muito claro.Falando sobre o kernel Linux, não se pode deixar de mencionar que uma das principais razões para a existência do QUIC foi que ele foi implementado sobre o protocolo UDP leve e, por isso, funciona com mais eficiência, rapidez ... e, em geral, por que precisamos do TCP, que é tão grande e volumoso.
E por que essa abordagem é usada no lado do cliente - eu posso entender. Mas a mesma abordagem é usada no lado do servidor. Teoricamente, nesse caso, o QUIC realmente valeria a pena ser levado ao cerne, mas, novamente, o trabalho sobre isso não está em andamento e, quando terminar, teremos cabelos grisalhos na melhor das hipóteses, e não pretendo viver para sempre. E quando isso acontece - não é muito claro.Falando sobre o kernel Linux, não se pode deixar de mencionar que uma das principais razões para a existência do QUIC foi que ele foi implementado sobre o protocolo UDP leve e, por isso, funciona com mais eficiência, rapidez ... e, em geral, por que precisamos do TCP, que é tão grande e volumoso. vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdfAqui está outro link para o benchmark. Acontece que enviar datagramas UDP para Linux é mais caro do que enviar um fluxo TCP, muito mais caro, muito mais caro. Existem 2 pontos principais (ou seja, muitos pontos, mas apenas dois pontos principais):1. A pesquisa na tabela de roteamento leva mais tempo no caso de um datagrama UDP;2. Uma peça chamada "descarga de grande segmento". No TCP, podemos simplesmente fazer upload de um grande fluxo de dados na transmissão, não precisamos dividi-lo em segmentos na CPU, enquanto no UDP precisamos preparar cada datagrama, não temos um fluxo. No momento, os desenvolvedores do kernel pensam no que fazer com ele, mas, em geral, o TCP trabalha no envio de grandes dados que não cabem em um pacote, mais eficientes que o UDP, no qual o QUIC é baseado.
vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdfAqui está outro link para o benchmark. Acontece que enviar datagramas UDP para Linux é mais caro do que enviar um fluxo TCP, muito mais caro, muito mais caro. Existem 2 pontos principais (ou seja, muitos pontos, mas apenas dois pontos principais):1. A pesquisa na tabela de roteamento leva mais tempo no caso de um datagrama UDP;2. Uma peça chamada "descarga de grande segmento". No TCP, podemos simplesmente fazer upload de um grande fluxo de dados na transmissão, não precisamos dividi-lo em segmentos na CPU, enquanto no UDP precisamos preparar cada datagrama, não temos um fluxo. No momento, os desenvolvedores do kernel pensam no que fazer com ele, mas, em geral, o TCP trabalha no envio de grandes dados que não cabem em um pacote, mais eficientes que o UDP, no qual o QUIC é baseado. www.ietf.org/mail-archive/web/quic/current/msg03720.htmlEsta é novamente uma citação de um funcionário do Google, em particular eu também fiz essa pergunta. Afinal, podemos apenas culpar o Linux, dizer que no Windows, talvez tudo não seja tão ruim, mas não. Alega-se que em qualquer plataforma na qual o Google implantou o QUIC, há um problema com o aumento do custo (do ponto de vista do processador central) do envio de um pacote UDP contra um fluxo TCP. Ou seja, não é apenas o Linux assim, mas uma abordagem geral.
www.ietf.org/mail-archive/web/quic/current/msg03720.htmlEsta é novamente uma citação de um funcionário do Google, em particular eu também fiz essa pergunta. Afinal, podemos apenas culpar o Linux, dizer que no Windows, talvez tudo não seja tão ruim, mas não. Alega-se que em qualquer plataforma na qual o Google implantou o QUIC, há um problema com o aumento do custo (do ponto de vista do processador central) do envio de um pacote UDP contra um fluxo TCP. Ou seja, não é apenas o Linux assim, mas uma abordagem geral. O que nos leva a um pensamento simples.Pare de falar sobre o QUIC. Chega. A idéia simples de sair daqui é que antes de implementar qualquer novo protocolo em vez do antigo: HTTP / 2 vs. HTTP / 1.1, QUIC em vez de TCP, criptografia DNS, IPv6 em vez de IPv4 ... a primeira coisa a fazer antes de decidir e definir na produção é, obviamente, benchmarking.Não acredite em ninguém que diga que o protocolo “você pode simplesmente mudar / ativar / pressionar o botão” - não ! Isso nunca vai acontecer - e nunca foi e nunca será no futuro, e ninguém garante isso.Portanto, apenas uma referência e, é claro, que se você não fizer isso, mas simplesmente implantar algo, então, é claro, ninguém fornecerá a você uma garantia de trabalho de qualidade.
O que nos leva a um pensamento simples.Pare de falar sobre o QUIC. Chega. A idéia simples de sair daqui é que antes de implementar qualquer novo protocolo em vez do antigo: HTTP / 2 vs. HTTP / 1.1, QUIC em vez de TCP, criptografia DNS, IPv6 em vez de IPv4 ... a primeira coisa a fazer antes de decidir e definir na produção é, obviamente, benchmarking.Não acredite em ninguém que diga que o protocolo “você pode simplesmente mudar / ativar / pressionar o botão” - não ! Isso nunca vai acontecer - e nunca foi e nunca será no futuro, e ninguém garante isso.Portanto, apenas uma referência e, é claro, que se você não fizer isso, mas simplesmente implantar algo, então, é claro, ninguém fornecerá a você uma garantia de trabalho de qualidade. A propósito, sobre IPv6. O fato é que nos dias do IPv6, quando foi desenvolvido, os protocolos foram desenvolvidos de uma maneira um pouco mais direta, ou seja, sem tecnologias ágeis. Mas a adaptação deles na Internet ainda levou um tempo substancial muito grande. E, no momento, ainda está em andamento, e ainda está pendendo de 10 a 20% no caso do IPv6. Além disso, dependendo do país, porque na Rússia é ainda mais baixo.No caminho para implementar o IPv6, muitos problemas foram resolvidos. Quem sabe o que são os globos oculares felizes? Em geral, havia muitos problemas associados ao IPv6, além disso, quando os usuários ativos reclamavam. Digamos que você feche seu laptop, saia de casa onde você tem IPv6, vá ao café onde não há IPv6, abra o laptop - nada funciona, porque os caches do navegador e do sistema operacional continuam a olhar para o IPv6, mas não há conectividade local .Uma abordagem chamada “Happy Eyeballs” (também um padrão emitido pela IETF) foi inventada : se em 0,3 segundos não encontrarmos conectividade IPv6, não conseguiremos conectar, reverteremos para o IPv4.Uma muleta, mas parece funcionar quase sempre, mas! Problemas místicos com a implementação surgem constantemente. Em particular, por algum motivo, um dos problemas mais populares foi com o iPad, que passou do IPv6 para o IPv4 e volta muito mais devagar do que em 0,3 segundos: cerca de 1 segundo ou até 1 minuto.Mesmo em algum momento, uma oferta maluca surgiu na IETF 99 em Praga: "Deixe o Happy Eyeballs estar em cada rede via syslog para um servidor centralizado, se os problemas enviarem alguma coisa". Colete o syslog de todos os dispositivos conectados - é claro, ninguém concordou com isso. Mas isso é um indicador de que existem muitos problemas.Outros problemas são a luta contra todos os tipos de atividades maliciosas, porque a rede local no IPv6 é / 64 e existem muitos endereços pelos quais um invasor pode começar a classificar, a proteção precisa agregá-los a tempo e tudo mais. É necessário lidar de alguma forma com isso, tudo isso deve ser realizado.Como resultado, ainda temos problemas de implementação, que não são apenas expressos no fato de alguém estar implementando lentamente o IPv6. Não, eles começaram a desligá-lo novamente. Volte para o IPv4. Porque mesmo sem problemas, era difícil justificar os benefícios da transição para o gerenciamento, mas se, após a ativação, os usuários também começaram a reclamar, isso é tudo. Esse é um exemplo quando mesmo um protocolo desenvolvido com vista à implementação ainda causa os problemas mais graves da implementação, expressos em uma lavagem de cabeça ao departamento técnico.Imagine o que acontecerá ao implementar protocolos que não foram projetados para implementação em larga escala em seus respectivos casos de uso.
A propósito, sobre IPv6. O fato é que nos dias do IPv6, quando foi desenvolvido, os protocolos foram desenvolvidos de uma maneira um pouco mais direta, ou seja, sem tecnologias ágeis. Mas a adaptação deles na Internet ainda levou um tempo substancial muito grande. E, no momento, ainda está em andamento, e ainda está pendendo de 10 a 20% no caso do IPv6. Além disso, dependendo do país, porque na Rússia é ainda mais baixo.No caminho para implementar o IPv6, muitos problemas foram resolvidos. Quem sabe o que são os globos oculares felizes? Em geral, havia muitos problemas associados ao IPv6, além disso, quando os usuários ativos reclamavam. Digamos que você feche seu laptop, saia de casa onde você tem IPv6, vá ao café onde não há IPv6, abra o laptop - nada funciona, porque os caches do navegador e do sistema operacional continuam a olhar para o IPv6, mas não há conectividade local .Uma abordagem chamada “Happy Eyeballs” (também um padrão emitido pela IETF) foi inventada : se em 0,3 segundos não encontrarmos conectividade IPv6, não conseguiremos conectar, reverteremos para o IPv4.Uma muleta, mas parece funcionar quase sempre, mas! Problemas místicos com a implementação surgem constantemente. Em particular, por algum motivo, um dos problemas mais populares foi com o iPad, que passou do IPv6 para o IPv4 e volta muito mais devagar do que em 0,3 segundos: cerca de 1 segundo ou até 1 minuto.Mesmo em algum momento, uma oferta maluca surgiu na IETF 99 em Praga: "Deixe o Happy Eyeballs estar em cada rede via syslog para um servidor centralizado, se os problemas enviarem alguma coisa". Colete o syslog de todos os dispositivos conectados - é claro, ninguém concordou com isso. Mas isso é um indicador de que existem muitos problemas.Outros problemas são a luta contra todos os tipos de atividades maliciosas, porque a rede local no IPv6 é / 64 e existem muitos endereços pelos quais um invasor pode começar a classificar, a proteção precisa agregá-los a tempo e tudo mais. É necessário lidar de alguma forma com isso, tudo isso deve ser realizado.Como resultado, ainda temos problemas de implementação, que não são apenas expressos no fato de alguém estar implementando lentamente o IPv6. Não, eles começaram a desligá-lo novamente. Volte para o IPv4. Porque mesmo sem problemas, era difícil justificar os benefícios da transição para o gerenciamento, mas se, após a ativação, os usuários também começaram a reclamar, isso é tudo. Esse é um exemplo quando mesmo um protocolo desenvolvido com vista à implementação ainda causa os problemas mais graves da implementação, expressos em uma lavagem de cabeça ao departamento técnico.Imagine o que acontecerá ao implementar protocolos que não foram projetados para implementação em larga escala em seus respectivos casos de uso.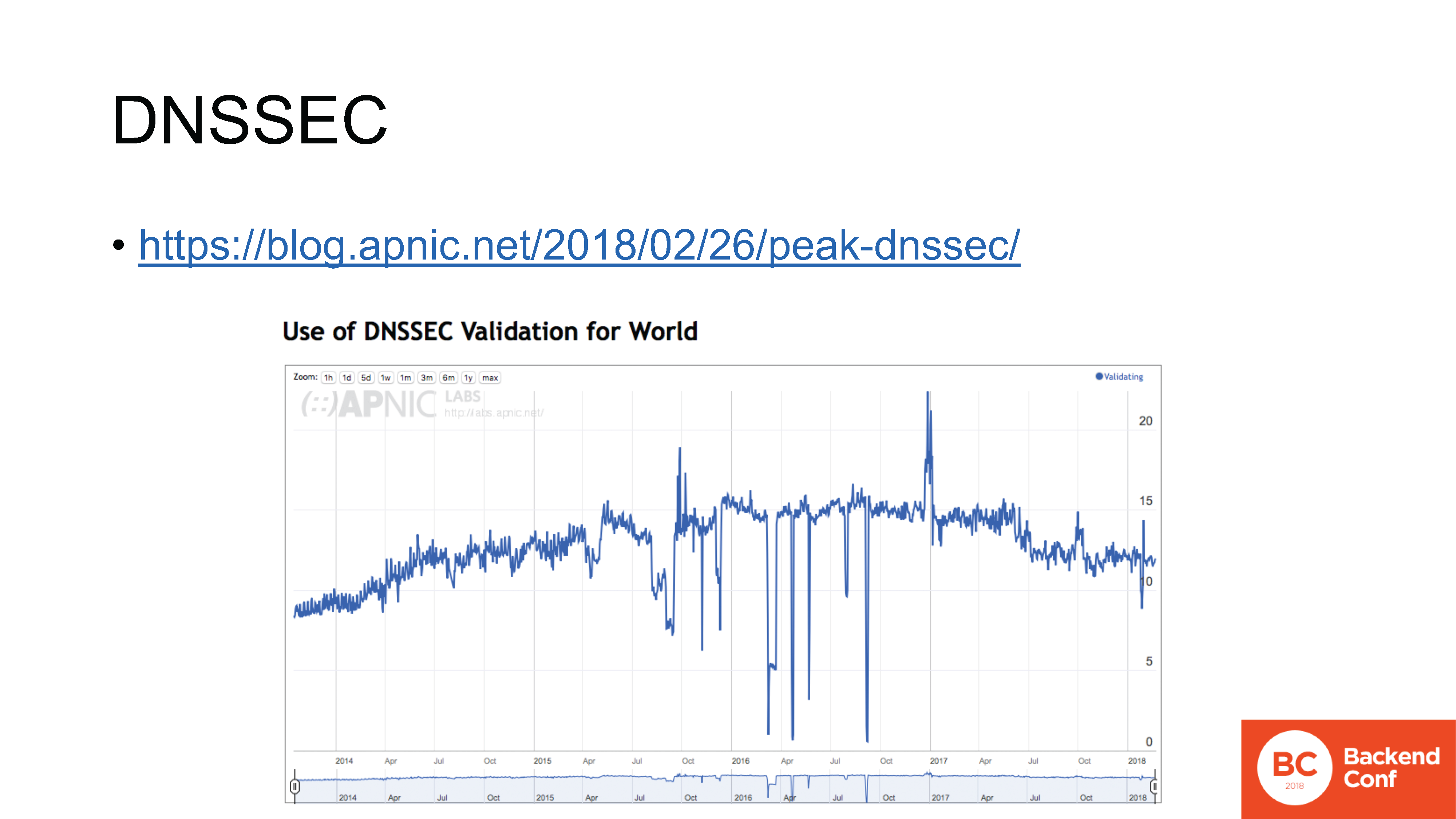 blog.apnic.net/2018/02/26/peak-dnssecOutro exemplo sobre este tópico é DNSSEC. Não pedirei que levante a mão para descobrir quem a possui, porque sei que ninguém a possui.A implantação do IPv6, por um lado, está desenvolvendo, por outro lado, há problemas, mas pelo menos está chegando. Desde o final do ano passado, a implementação do DNSSEC no mundo diminuiu e foi na direção oposta.Neste gráfico, vemos o número diário de usuários da Internet (medido pelo APNIC Labs) usando resolvedores que validam o DNSSEC. Uma tendência de baixa é muito claramente visível aqui: aqui começa após o último pico, e este pico é em outubro de 2016. ODNSSEC tem um objetivo, tem as tarefas corretas, mas sua implantação realmente parou e algum tipo de processo reverso foi iniciado e continua a ser investigado. de onde veio esse processo.
blog.apnic.net/2018/02/26/peak-dnssecOutro exemplo sobre este tópico é DNSSEC. Não pedirei que levante a mão para descobrir quem a possui, porque sei que ninguém a possui.A implantação do IPv6, por um lado, está desenvolvendo, por outro lado, há problemas, mas pelo menos está chegando. Desde o final do ano passado, a implementação do DNSSEC no mundo diminuiu e foi na direção oposta.Neste gráfico, vemos o número diário de usuários da Internet (medido pelo APNIC Labs) usando resolvedores que validam o DNSSEC. Uma tendência de baixa é muito claramente visível aqui: aqui começa após o último pico, e este pico é em outubro de 2016. ODNSSEC tem um objetivo, tem as tarefas corretas, mas sua implantação realmente parou e algum tipo de processo reverso foi iniciado e continua a ser investigado. de onde veio esse processo. datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01Em geral, há muitos problemas com o DNS. O grupo de trabalho dnsop da IETF agora tem 3 presidentes, 15 rascunhos do que é chamado de "em voo" : eles estão se preparando para o lançamento como uma RFC.O DNS, em particular, aprendeu a transferir em cima de tudo. Além do TCP, funcionou por muito tempo (mas as pessoas ainda precisam mostrar como fazê-lo corretamente ). Agora eles começaram a executá-lo por TLS , HTTPS e QUIC .Tudo isso parecia absolutamente maravilhoso até que as pessoas começaram a perceber isso e não começaram a doer no quinto ponto. Em março de 2017, os desenvolvedores do OpenDNS trouxeram uma apresentação chamada “DNS Camel” para a IETFou "camel dns". A apresentação se resume ao seguinte pensamento: quanto mais podemos carregar esse camelo (também conhecido como protocolo DNS) antes que o próximo galho quebre sua espinha?Essa é uma abordagem geral de como vemos o design agora. Recursos são adicionados, existem muitos recursos, eles interferem entre si de maneiras diferentes. E nem sempre de uma maneira previsível, e nem sempre os autores da implementação compreendem todos os possíveis pontos de interferência. Implementação de cada um desses novos recursos, implementação, implementação na produção - adicione um conjunto de pontos de falha em potencial em todos os lugares em que essa interferência ocorre. Sem uma referência, sem monitoramento - em lugar nenhum.
datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01Em geral, há muitos problemas com o DNS. O grupo de trabalho dnsop da IETF agora tem 3 presidentes, 15 rascunhos do que é chamado de "em voo" : eles estão se preparando para o lançamento como uma RFC.O DNS, em particular, aprendeu a transferir em cima de tudo. Além do TCP, funcionou por muito tempo (mas as pessoas ainda precisam mostrar como fazê-lo corretamente ). Agora eles começaram a executá-lo por TLS , HTTPS e QUIC .Tudo isso parecia absolutamente maravilhoso até que as pessoas começaram a perceber isso e não começaram a doer no quinto ponto. Em março de 2017, os desenvolvedores do OpenDNS trouxeram uma apresentação chamada “DNS Camel” para a IETFou "camel dns". A apresentação se resume ao seguinte pensamento: quanto mais podemos carregar esse camelo (também conhecido como protocolo DNS) antes que o próximo galho quebre sua espinha?Essa é uma abordagem geral de como vemos o design agora. Recursos são adicionados, existem muitos recursos, eles interferem entre si de maneiras diferentes. E nem sempre de uma maneira previsível, e nem sempre os autores da implementação compreendem todos os possíveis pontos de interferência. Implementação de cada um desses novos recursos, implementação, implementação na produção - adicione um conjunto de pontos de falha em potencial em todos os lugares em que essa interferência ocorre. Sem uma referência, sem monitoramento - em lugar nenhum.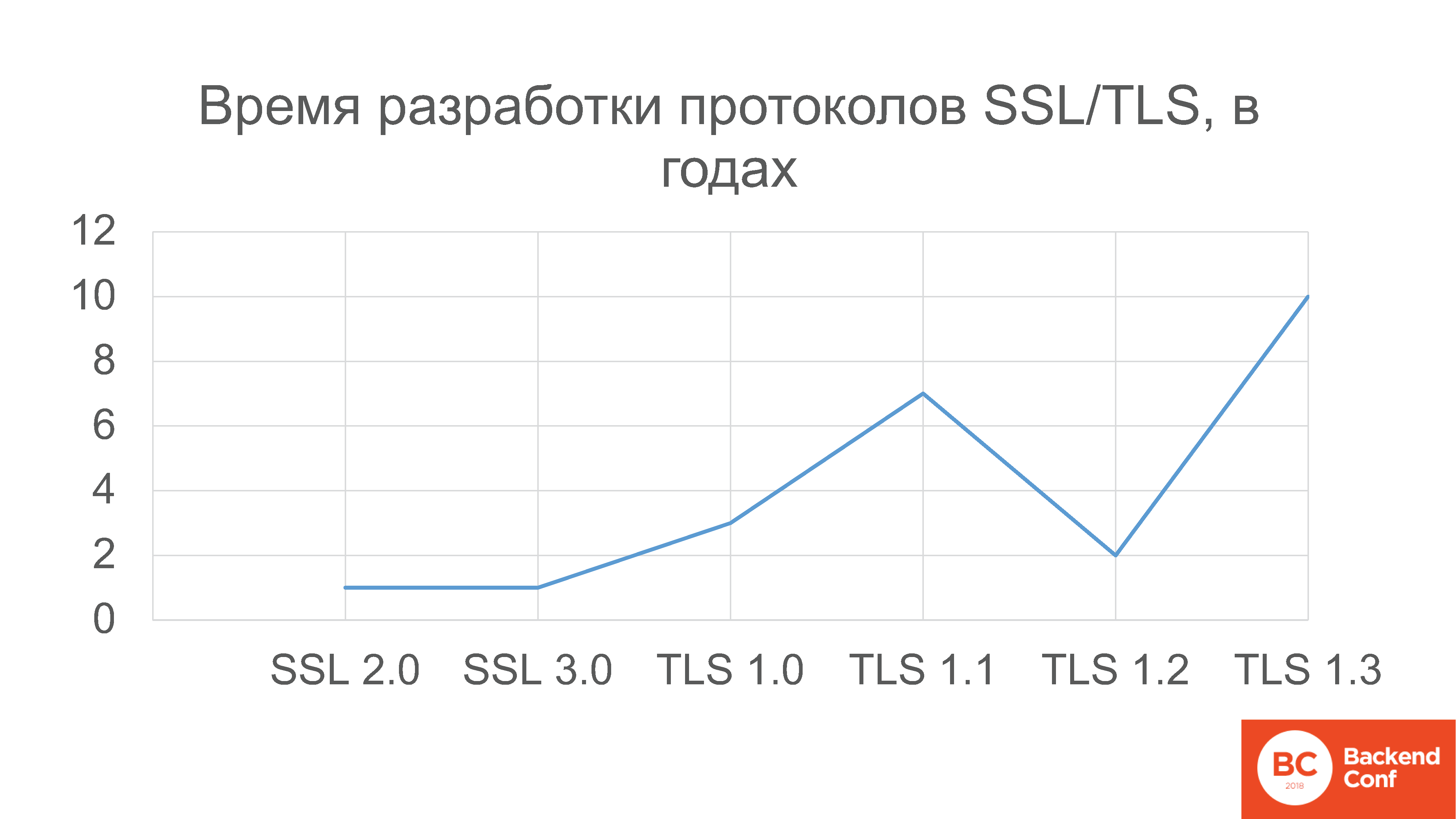 Por que é importante participar de todo esse processo? Porque o padrão IETF - "RFC" - ainda é um padrão. Existem estatísticas tão boas: cronogramas de desenvolvimento para várias versões dos protocolos de criptografia SSL e TLS.Observe que o versionamento do SSL começa no número 2, porque as versões 0.9 e 1.0 nunca foram lançadas na produção, eram mais vazias do que o Netscape podia dar ao luxo de lançar. Portanto, a história começou com o protocolo SSL 2.0, que foi desenvolvido por ano. Em seguida, o SSL 3.0 foi desenvolvido mais um ano.Em seguida, o TLS 1.0 foi desenvolvido por 3 anos; versão 1.1 - 7 anos; 1.2 foi desenvolvido apenas 2 anos, porque não houve grandes mudanças; mas a última versão, lançada em março deste ano - a 27ª versão, a propósito - foi desenvolvida 10 anos .No grupo de trabalho correspondente, em algum momento houve um grande pânico nesse tópico, porque o TLS 1.3 estava quebrando muitos casos de uso, principalmente em organizações financeiras, com monitoramento e firewalls. Mas mesmo grandes empresas como o US Bank não puderam mudar isso, tendo chegado a uma conclusão já na fase do décimo oitavo rascunho. Eles não tiveram tempo para fazer nada a respeito, porque quando você chega à festa no momento em que todos já recebem a conta, você não pode esperar que sua proposta de continuar a diversão seja tratada com compreensão .Portanto, se em algum protocolo - isso é novamente uma questão de feedback - houver / haverá / houver recursos que não lhe convêm, a única opção é rastrear isso no tempo e intervir no tempo, porque, caso contrário, será liberado e tem que construir muletas em torno disso.
Por que é importante participar de todo esse processo? Porque o padrão IETF - "RFC" - ainda é um padrão. Existem estatísticas tão boas: cronogramas de desenvolvimento para várias versões dos protocolos de criptografia SSL e TLS.Observe que o versionamento do SSL começa no número 2, porque as versões 0.9 e 1.0 nunca foram lançadas na produção, eram mais vazias do que o Netscape podia dar ao luxo de lançar. Portanto, a história começou com o protocolo SSL 2.0, que foi desenvolvido por ano. Em seguida, o SSL 3.0 foi desenvolvido mais um ano.Em seguida, o TLS 1.0 foi desenvolvido por 3 anos; versão 1.1 - 7 anos; 1.2 foi desenvolvido apenas 2 anos, porque não houve grandes mudanças; mas a última versão, lançada em março deste ano - a 27ª versão, a propósito - foi desenvolvida 10 anos .No grupo de trabalho correspondente, em algum momento houve um grande pânico nesse tópico, porque o TLS 1.3 estava quebrando muitos casos de uso, principalmente em organizações financeiras, com monitoramento e firewalls. Mas mesmo grandes empresas como o US Bank não puderam mudar isso, tendo chegado a uma conclusão já na fase do décimo oitavo rascunho. Eles não tiveram tempo para fazer nada a respeito, porque quando você chega à festa no momento em que todos já recebem a conta, você não pode esperar que sua proposta de continuar a diversão seja tratada com compreensão .Portanto, se em algum protocolo - isso é novamente uma questão de feedback - houver / haverá / houver recursos que não lhe convêm, a única opção é rastrear isso no tempo e intervir no tempo, porque, caso contrário, será liberado e tem que construir muletas em torno disso. Aqui no slide, de fato, há três conclusões principais de todo o processo.Primeiro: como eu disse, a introdução de um novo protocolo não é fácil na configuração "tweak something". Este é um plano de implementação planejado, uma avaliação de adequação com referências obrigatórias, pois, na realidade, tudo se comportará.Ponto número dois: os protocolos não são desenvolvidos por alienígenas, eles não nos são fornecidos de cima, você pode e deve participar desse processo, porque ninguém promoverá seus casos de usuário para você.E a terceira, realmente: é necessário feedback . O mais importante é que o próprio Google, não é mau, apenas persegue seus próprios objetivos, não tem tarefa de desenvolver um protocolo para você e para você, apenas você pode fazê-lo.Portanto, no caso geral, a introdução de algo novo em vez de antigo, apesar do número de artigos elogiosos em blogs, começa com o fato de que você precisa investir não apenas na implantação, mas no processo de design do protocolo, veja como ele funciona, e só então tome uma decisão informada.
Aqui no slide, de fato, há três conclusões principais de todo o processo.Primeiro: como eu disse, a introdução de um novo protocolo não é fácil na configuração "tweak something". Este é um plano de implementação planejado, uma avaliação de adequação com referências obrigatórias, pois, na realidade, tudo se comportará.Ponto número dois: os protocolos não são desenvolvidos por alienígenas, eles não nos são fornecidos de cima, você pode e deve participar desse processo, porque ninguém promoverá seus casos de usuário para você.E a terceira, realmente: é necessário feedback . O mais importante é que o próprio Google, não é mau, apenas persegue seus próprios objetivos, não tem tarefa de desenvolver um protocolo para você e para você, apenas você pode fazê-lo.Portanto, no caso geral, a introdução de algo novo em vez de antigo, apesar do número de artigos elogiosos em blogs, começa com o fato de que você precisa investir não apenas na implantação, mas no processo de design do protocolo, veja como ele funciona, e só então tome uma decisão informada.Obrigada