Comentários em uma publicação recente “Quão bom é o ecossistema de código aberto do R para resolver problemas de negócios?” Quanto aos downloads no Excel, eles levaram à ideia de que faz sentido gastar tempo e descrever uma das abordagens possíveis comprovadas que podem ser implementadas sem sair da R.
A situação é bastante típica. A empresa sempre possui N métodos pelos quais os gerentes tentam criar relatórios manualmente no Excel. Mesmo que sejam automatizados, sempre existe uma situação em que é urgente fazer algum novo corte arbitrário ou fazer uma apresentação para um determinado gerente de uma forma específica.
E há vários dicionários do Excel com suporte manual para transformar a apresentação de dados em relatórios e amostras na terminologia correta.
Devido ao fato de que nenhuma ferramenta adequada (a massa de nuances adicionais será menor) não foi encontrada, tive que empilhar o "construtor universal" em Shiny + R. Devido à universalidade e parametrização das configurações, esse construtor pode ser facilmente plantado em praticamente qualquer sistema em qualquer área.
É uma continuação de publicações anteriores .
Breve declaração do problema
- Como fonte de dados técnicos, existe um armazenamento principal do tipo OLAP (focamos no Clickhouse), vários adicionais (Postgre, MS SQL, API REST) e referências manuais xml, json, xlsx. Devido ao fato de serem necessárias análises ad-hoc, incluindo o cálculo de valores exclusivos, é necessário trabalhar apenas com os dados de origem e não com agregados.
- Registros no banco de dados - centenas de bilhões de linhas por centenas de colunas (eventos de tempo), é aconselhável fazer a análise em um modo medido não mais do que várias dezenas de segundos, as consultas podem ser completamente imprevisíveis, os dados são armazenados em formato técnico (abreviações em inglês, número de entradas no dicionário etc.) ) No estado de destino, são esperados ~ 200 TB de dados brutos.
- Os eventos acumulados têm especificações de versão, ou seja, À medida que o sistema funciona, informações de diferentes versões e liberações de fontes que se reportam de várias maneiras acumulam-se nele.
- Os gerentes funcionam bem no excel, mas não devem conhecer (e fisicamente não podem) o componente técnico do sistema.
Como resolver o problema
O cenário geral do trabalho é bastante simples. O gerente recebeu uma tarefa urgente da seção analítica - o gerente abre o aplicativo, forma amostras arbitrárias em termos de área de assunto - olha e torce o resultado tabular - descarrega o resultado arranjado no excel - desenha uma imagem para o gerenciamento. Conveniência e simplicidade da interface do usuário foram escolhidas como ponto zero.
- Tudo foi projetado como um aplicativo brilhante de tela única, com menus de navegação e favoritos.
- Todos os controles são divididos em 3 partes:
- filtros (globais e privados). Limite a área de seleção, existem 4 tipos: lista suspensa-dicionário, datas, fragmentos de texto, alcance digital.
- 3 níveis de aninhamento de grupos de consulta
- lista de quantidades agregadas (nomeadamente quantidades).
- Devido ao fato de existirem muitos campos na fonte original (cerca de 2.500), mas você precisa exibir tudo, os elementos de controle são agrupados em blocos temáticos.
Exemplo de interface
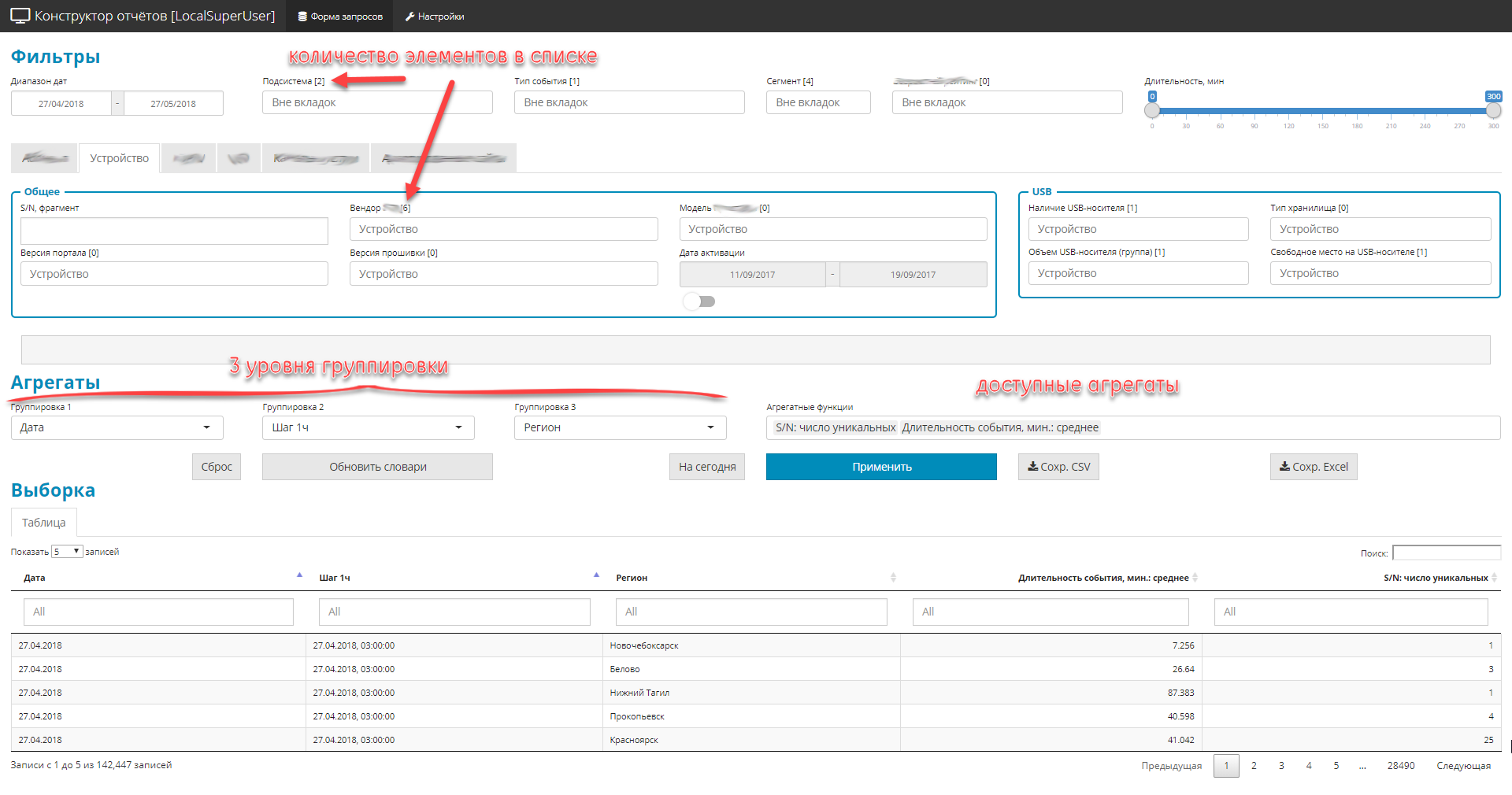
Arquivo de exemplo com informações meta
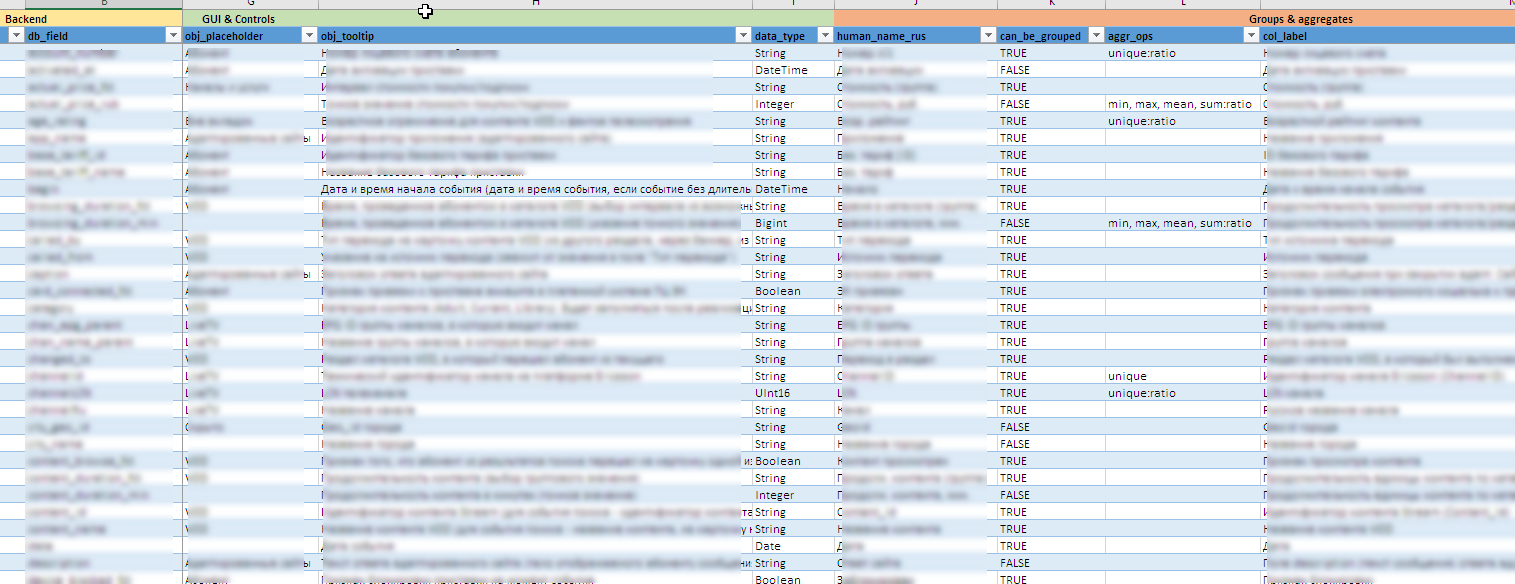
Úteis "fichas" nos bastidores:
- À medida que as fontes de dados evoluem, toda a configuração da interface, incluindo a criação de controles, dicas de ferramentas, o conteúdo de agrupamentos e agregados disponíveis, regras de exportação no Excel, etc. decorado como um metamodelo na forma de um arquivo excel. Isso permite que você modifique rapidamente o "designer" para novos campos ou unidades de cálculo sem alterações significativas (ou nenhuma alteração) no código-fonte.
- É difícil dizer com antecedência quais valores podem ocorrer em um campo específico e encontrar um, não sei o que, é ainda mais difícil. A manutenção manual de todos os 90 controles dinâmicos é quase impossível. Em algumas listas, o vocabulário inclui várias centenas de significados. Portanto, as entradas de dicionário para controles são atualizadas em segundo plano com base nos dados acumulados no back-end.
- Os gerentes precisam ver todos os campos e conteúdos em russo. E nas fontes, esses dados podem ser armazenados em um formulário oficial. Portanto, é usada uma combinação de tecnologias de dicionário Clickhouse e pós-processamento bidirecional de valores de campo no nível Shiny. Ele fornece imediatamente o processamento de todos os tipos de exceções às regras e nuances versionadas do conteúdo dos campos.
- Para proteger contra seleções incorretas, foi feita uma conexão cruzada entre listas para agrupamento. O nível 2 pode ser selecionado apenas se o nível 1 estiver definido e o nível 3, apenas se o nível 2. E as listas de valores disponíveis são reduzidas dinamicamente, levando em consideração os já selecionados.
- Um elemento importante é o controle sobre a exibição da seleção na tela e durante o upload subsequente para o Excel. Aqui também existem vários recursos no pós-processamento que visam a conveniência da ferramenta para o gerente:
- suporte organizado para a “matriz de visibilidade” na forma de um arquivo excel. Essa matriz determina a exibição ou ocultação de determinados campos na seleção, dependendo dos filtros instalados.
- modificação dinâmica linha a linha do conteúdo da amostra. Dependendo do conteúdo de vários campos, o conteúdo de outro campo pode ser alterado (por exemplo, se 0 for especificado no campo "quantidade do pedido", uma linha vazia será exibida no campo "tipo de pedido".
- gestão da exibição de dados pessoais. dependendo dos direitos de acesso à função configurados pers. os dados podem ser exibidos e parcialmente mascarados com
* . - gerenciamento de precisão. só para mencionar. mostre 10 casas decimais - Moveton, mas há situações em que a precisão de 2 casas decimais não é suficiente. 80% dos objetos, por exemplo, têm uma porcentagem de
0.00% - você precisa aumentar os caracteres significativos ao arredondar, para que a diferença entre as linhas seja visível. E a quantia na descarga no Excel deve convergir (a quantia em todas as linhas da coluna fracionária é razoavelmente esperada na região de 100%). - fornecendo acesso à função no nível dos controles de conteúdo disponíveis. Os direitos de acesso são controlados pelo arquivo de configuração json.
- Controle dinâmico da profundidade da solicitação. No caso em que nenhum agrupamento e agregação são especificados (o estudo está em andamento e você só precisa retornar dados brutos que se enquadram nos filtros instalados), a proteção contra sobrecarga de back-end é ativada. O usuário pode definir o intervalo de tempo para a pesquisa em 1 ano, mas realmente precisa dos últimos 1000 registros da seleção. Sabendo que milhões de registros chegam diariamente, uma solicitação de teste para profundidade reduzida é realizada pela primeira vez (há 3 a 7 dias). Se o número recebido de linhas não for suficiente (condições de filtragem rigorosas), uma consulta completa será lançada por todo o período.
- Descarregando as amostras recebidas no formato excel. Tudo está formatado, tudo em russo, é acompanhado por uma planilha separada, com a fixação de todos os parâmetros da amostra, para que você possa entender facilmente como esse ou aquele resultado foi obtido.
- Um registro detalhado é mantido no aplicativo, para que você possa ter uma idéia das ações do usuário e da operação da mecânica do compartimento do motor.
Antecipando possíveis comentários sobre a "bicicleta", se houver 100%, sugiro imediatamente escrevê-los com uma indicação do produto de código aberto que você conhece. Ficarei feliz em novas descobertas.
Naturalmente, um link para o produto deve ser fornecido levando em consideração toda a gama de requisitos avançados. Bem, de preferência imediatamente com a avaliação da infraestrutura necessária. Para essa opção, dois ou três servidores de capacidade média (64-128Gb; núcleo da CPU 12-20, com base na quantidade de dados) são suficientes para todo o complexo. O ELK não se encaixou, porque a tarefa principal é a análise numérica e não funciona com texto.
Conjunto de requisitos detalhados
Abaixo, para obter informações, é fornecida uma lista detalhada de requisitos para a unidade analítica na parte das interfaces máquina-máquina e homem-máquina (o "designer de relatórios" é apenas uma parte).
Importar \ Exportar \ Ambiente
- Os arquivos de log são padronizados e estruturados apenas em termos de timestamps, módulos e subsistemas. O sistema deve processar arquivos de log com conteúdo arbitrário do conteúdo da mensagem (corpo do registro da gravação), suportando o corpo de log estruturado e não estruturado da gravação.
- Para enriquecer dados, o Sistema deve ter adaptadores de importação para pelo menos os seguintes tipos de fontes de dados:
- arquivos simples (csv, txt)
- arquivos estruturados xml, json, xlsx
- fontes compatíveis com odbc, em particular MS SQL, MySQL, PostgreSQL
- dados fornecidos por meio da API REST.
- O sistema deve suportar a importação automática e a importação a pedido do usuário. Ao importar dados do usuário, o Sistema deve fornecer:
- a possibilidade de validação técnica de dados importados (a exatidão do número de campos, seus tipos, integridade, presença de valores
- a possibilidade de validação lógica (conteúdo dos campos, validação, validação cruzada, ...)
- a capacidade de configurar parâmetros de validação (de qualquer forma) de acordo com a lógica do procedimento de importação;
- Um relatório detalhado sobre erros técnicos e lógicos detectados, permitindo que o operador localize e elimine rapidamente falhas nos dados importados.
- O sistema deve suportar a exportação de resultados, pelo menos, nos seguintes formatos:
- exportação de dados para arquivos simples csv, txt
- exportar dados para arquivos xml, json, xlsx estruturados
- exportação de dados para fontes compatíveis com odbc, em particular, MS SQL, MySQL, PostgreSQL
- fornecendo acesso aos dados por meio do protocolo API REST
- O sistema deve ter a funcionalidade de gerar relatórios impressos:
- uma combinação coesa de texto, representações tabulares e representações gráficas em um único documento, de acordo com um modelo pré-formado (narrativa);
- a formação de todos os elementos calculados (tabelas, gráficos) no momento da geração do formulário de impressão;
- o uso de fontes e diretórios externos necessários na preparação de um relatório em tempo real, de acordo com os protocolos mencionados acima, sem integração e duplicação de dados
- exportação de relatórios gerados nos formatos html, docx, pdf
- a formação de representações impressas deve ser apoiada sob demanda e em segundo plano, de acordo com um cronograma.
- O sistema deve manter um registro detalhado dos cálculos, ações ativas do usuário ou interação com sistemas externos.
- O sistema deve ser instalado no local.
- A instalação e a operação subsequente devem ser realizadas com o isolamento completo do sistema da Internet.
Cálculos
- O sistema deve suportar o cálculo de métricas agregadas (mínimo, máximo, média, mediana, quartis) por um intervalo de tempo arbitrário em um modo em um modo próximo ao tempo real.
- O sistema deve suportar o cálculo de métricas básicas (número de valores, número de valores exclusivos) por um intervalo de tempo arbitrário em um modo próximo ao tempo real.
- Ao calcular dados agregados, os períodos de agregação devem ser determinados pelo usuário a partir de intervalos predefinidos: 5 minutos, 10 minutos, 15 minutos, 20 minutos, 30 minutos, 1 hora, 2 horas, 24 horas, 1 semana, 1 mês
- O sistema deve incluir um construtor para formar amostras arbitrárias. A composição de possíveis operações deve ser determinada por um metamodelo de dados predefinido. O construtor deve suportar as seguintes configurações mínimas:
- Suporte de filtro para datas: [início do período do relatório - final do período do relatório]
- Suporte de filtro (listas suspensas) com seleção múltipla para campos enumerados (por exemplo, cidades: Moscou, São Petersburgo, ...)
- Formação automática do conteúdo de listas suspensas para filtros de campos enumeráveis com base em diretórios externos dinâmicos ou dados acumulados.
- suporte para pelo menos três níveis de agrupamento seqüencial de dados na amostra solicitada; os parâmetros para agrupar-se são definidos pelo usuário na lista de conjuntos de dados disponíveis no nível do metamodelo.
- restrição dos campos disponíveis para agrupamento em um ou outro nível, levando em consideração os campos selecionados em níveis mais altos de agrupamento (por exemplo, se “cidade” foi escolhida no 1º nível, esse parâmetro não deve estar disponível no 2º ou 3º m níveis de agrupamento)
- a possibilidade de agrupar por parâmetros de tempo aumentados: dia da semana, grupo de horas (11-12; 12-13), semana
- suporte para agregados calculados básicos: (mínimo, máximo, média, mediana, quantidade, número de únicos);
- suporte para filtros de teste para fornecer pesquisa de texto completo na seleção;
- suporte no estágio de exibição do enriquecimento e transformação de dados obtidos mediante solicitação, com base em dados de diretórios ou fontes externas.
- O sistema deve ter mecanismos para calcular métricas em coordenadas espaciais (sp = ponto espacial) para apoiar a geoanalítica.
- Para métricas de tempo (transações, operações, consultas, ...), o sistema deve calcular e exibir a densidade da distribuição do tempo de execução da consulta.
- Todos os indicadores calculados devem ser executados para todos os objetos como um todo, bem como para as subamostras definidas pelo usuário usando filtros
- O sistema deve realizar todos os cálculos na memória.
- Todos os eventos têm um carimbo de data / hora, portanto, o sistema deve suportar o trabalho com séries temporais equidistantes e arbitrárias.
- O sistema deve suportar a capacidade de configurar e ativar mecanismos para restaurar dados perdidos em séries temporais (vários algoritmos), determinar anomalias, prever séries temporais, classificação / agrupamento.
Parte da interface
- Toda a interface do usuário, incluindo o conteúdo dos elementos gráficos e da tabela, deve ser localizada.
- Para controles e colunas de representações tabulares, a possibilidade de formar dicas de ferramentas com uma descrição detalhada (dica de foco), formada de maneira estática e dinâmica (por exemplo, na dica de ferramenta podem ser os parâmetros usados para calcular), deve ser apoiada.
- A interface do local de trabalho deve ser construída apenas com o uso de tecnologias HTML, CSS, JS, sem o uso de tecnologias desatualizadas, dependentes da plataforma ou não portáveis, como Adobe Flash, MS Silverlight, etc.
- A hora nos gráficos deve ser exibida em um formato de 24 horas.
- Os parâmetros para exibição de dados nos eixos devem suportar a escala automática (frequência de etiquetas e formato de exibição), dependendo da faixa de valores. Um exemplo típico é a exibição de horas com uma faixa de medição em um dia, a exibição de dias com uma faixa de medição em uma semana.
- O sistema deve, no mínimo, suportar os seguintes formatos de exibição gráfica atômica:
- Histograma (bar)
- Spot
- Linear
- Mapa de calor
- Contornos (contornos)
- Gráficos de pizza
- O sistema deve suportar a capacidade de colocar automaticamente marcadores de forma inteligente (por exemplo, valores) de um determinado subconjunto de pontos com uma sobreposição mínima desses marcadores.
- O sistema deve suportar a possibilidade de combinar uma representação gráfica de dados obtidos de diferentes fontes de dados. A capacidade de especificar diferentes formatos de exibição gráfica atômica para cada fonte de dados deve ser suportada, desde que os eixos de coordenadas e o tipo de sistema de coordenadas correspondam.
- O sistema deve suportar a distribuição faceta (particionamento de gráficos na grade M x N) de gráficos atômicos para uma dada variável de parametrização. Na exibição de faceta, para cada gráfico, a escala independente do eixo X e do eixo Y deve ser possível.
- Os gráficos devem suportar a parametrização das seguintes características:
- Cor
- Tipo de linha ou ponto
- A espessura da linha ou contorno do ponto
- Tamanho do ponto
- Transparência
- Para as tarefas de geoanálise de dados, o sistema deve suportar o trabalho com shapefiles, incluindo importação, exibição, coloração parametrizada por área e garantir que vários elementos gráficos e indicadores calculados sejam sobrepostos no geopod gerado.
- Os controles da interface do usuário (listas, campos, painéis etc.) devem suportar a alteração dinâmica de seu conteúdo, dependendo do estado de outros elementos. Por exemplo, ao escolher uma determinada região, o conteúdo do elemento de seleção da cidade deve ser limitado à lista de cidades incluídas na região.
- O modelo de acesso a aplicativos de relatório deve ser suportado:
- suporte ao metamodelo de dados para fornecer acesso à função no nível da URL (possível / impossível)
- suporte para um metamodelo de dados para fornecer acesso baseado em função no nível do conteúdo de um elemento de controle (por exemplo, a lista de objetos disponíveis nas listas suspensas é determinada pela responsabilidade regional do gerente)
- suporte ao metamodelo de dados para garantir o acesso baseado em função no nível da visualização de dados pessoais (por exemplo, mascarando “*” de uma determinada parte dos números de email ou outros campos)
Conclusão
O principal objetivo da publicação é mostrar que as possibilidades de R se estendem muito além dos limites da estatística clássica. Ele é verificado praticamente, não é necessário sacrificar a qualidade ou a funcionalidade.
Post anterior - “Quão bom é o ecossistema de código aberto do R para resolver problemas de negócios?” .