Uma das notícias mais populares e discutidas nos últimos anos é quem adicionou inteligência artificial a onde e quais hackers quebraram o que e onde. Combinando esses tópicos, estudos muito interessantes aparecem e já havia vários artigos no hub que foram capazes de enganar os modelos de aprendizado de máquina, por exemplo: um artigo sobre as limitações do aprendizado profundo , sobre como atrair redes neurais . Além disso, gostaria de considerar esse tópico com mais detalhes do ponto de vista da segurança do computador:

Considere os seguintes problemas:
- Termos importantes.
- O que é aprendizado de máquina, se de repente você ainda não sabia.
- O que a segurança do computador tem a ver com isso ?!
- É possível manipular o modelo de aprendizado de máquina para realizar um ataque direcionado?
- O desempenho do sistema pode ser prejudicado?
- Posso tirar proveito das limitações dos modelos de aprendizado de máquina?
- Categorização de ataques.
- Maneiras de proteção.
- Possíveis consequências.
1. A primeira coisa que gostaria de começar é a terminologia.
Essa possível declaração pode causar um grande holivar por parte das comunidades científica e profissional, devido aos vários artigos já escritos em russo, mas eu gostaria de observar que o termo "inteligência antagônica" é traduzido como "inteligência inimiga". E a palavra “adversário” em si deve ser traduzida não pelo termo legal “adversário”, mas por um termo mais adequado de segurança “malicioso” (não há queixas sobre a tradução do nome da arquitetura da rede neural). Então, todos os termos relacionados em russo assumem um significado muito mais brilhante, como "exemplo contraditório" - uma instância maliciosa de dados, "configurações contraditórias" - um ambiente malicioso. E a própria área que consideraremos "aprendizado de máquina adversário" é aprendizado de máquina mal-intencionado.
Pelo menos na estrutura deste artigo, esses termos em russo serão usados. Espero que seja possível mostrar que este tópico é muito mais sobre segurança, a fim de usar os termos dessa área de maneira justa, em vez do primeiro exemplo de um tradutor.
Então, agora que estamos prontos para falar o mesmo idioma, podemos começar essencialmente :)
2. O que é aprendizado de máquina, se de repente você ainda não sabia
Bem, ainda já nos conhecemosPor métodos de aprendizado de máquina, geralmente queremos dizer métodos para construir algoritmos capazes de aprender e agir sem programar explicitamente seu comportamento em dados pré-selecionados. Por dados, podemos significar qualquer coisa, se pudermos descrevê-lo com alguns sinais ou medi-lo. Se houver algum sinal desconhecido para alguns dados, mas realmente precisarmos dele, usamos métodos de aprendizado de máquina para restaurar ou prever esse sinal com base em dados já conhecidos.
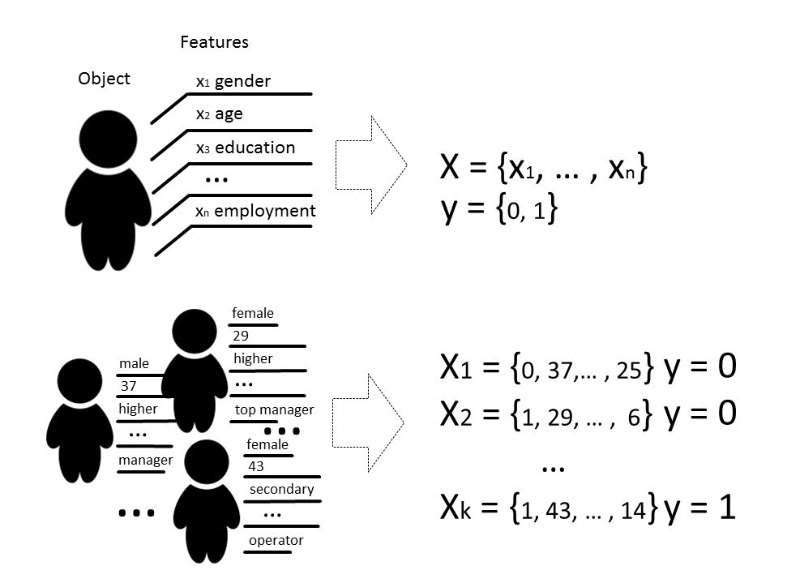
Existem vários tipos de problemas que podem ser resolvidos com a ajuda do aprendizado de máquina, mas falaremos principalmente sobre o problema de classificação.
Classicamente, o objetivo do estágio de treinamento do modelo classificador é selecionar um relacionamento (função) que mostre a correspondência entre os recursos de um objeto específico e uma das classes conhecidas. Em um caso mais complexo, é necessária uma previsão da probabilidade de pertencer a uma categoria específica.
Ou seja, a tarefa de classificação é construir um hiperplano que divida o espaço, onde, em regra, sua dimensão é o tamanho do vetor de característica, para que objetos de classes diferentes fiquem em lados opostos desse hiperplano.
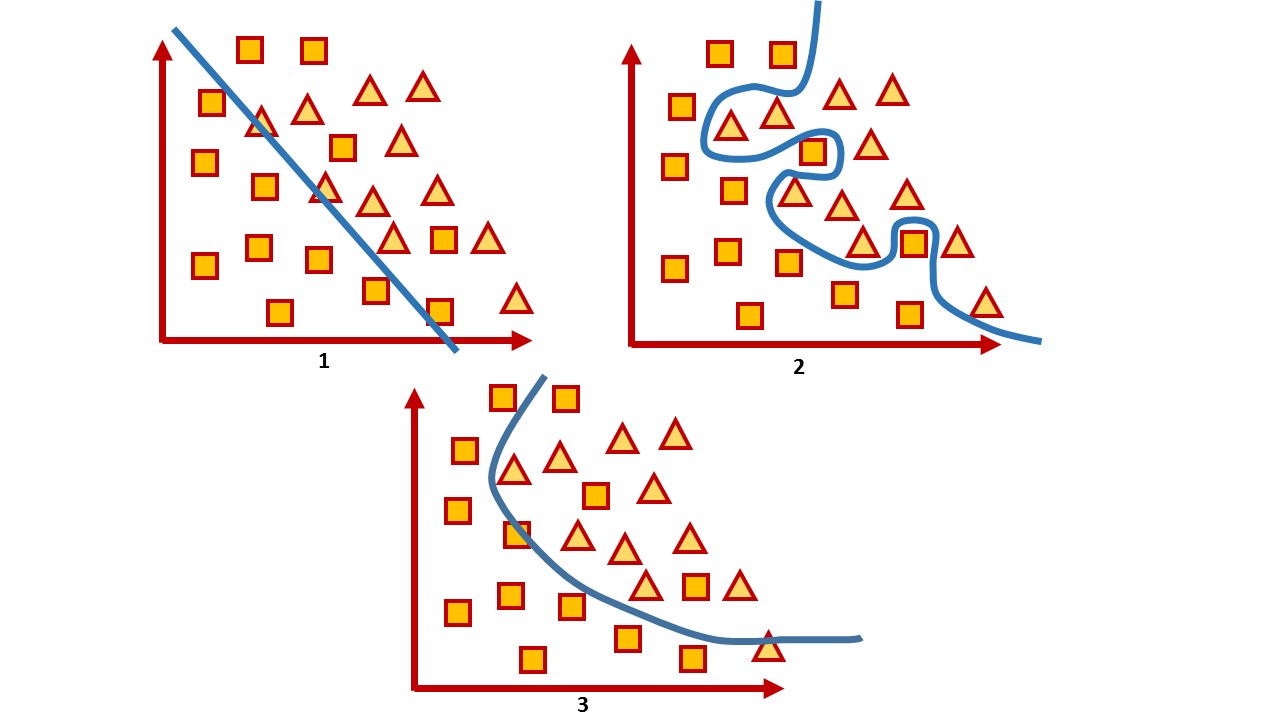
Para um espaço bidimensional, esse hiperplano é uma linha. Considere um exemplo simples:

Na figura você pode ver duas classes, quadrados e triângulos. É impossível encontrar a dependência e dividi-la com mais precisão por uma função linear. Portanto, com a ajuda do aprendizado de máquina, pode-se escolher uma função não linear que melhor distinga entre esses dois conjuntos.
A tarefa de classificação é uma tarefa de ensino bastante típica com um professor. Para treinar o modelo, esse conjunto de dados é necessário para que seja possível distinguir os recursos do objeto e sua classe.
3. O que a segurança do computador tem a ver com isso ?!
Em segurança de computadores, vários métodos de aprendizado de máquina são utilizados há muito tempo na filtragem de spam, análise de tráfego e detecção de fraude ou malware.
E, de certa forma, este é um jogo em que, após fazer um movimento, você espera que o inimigo reaja. Portanto, ao jogar este jogo, você constantemente precisa ajustar os modelos, ensinar novos dados ou alterá-los completamente, levando em consideração as mais recentes conquistas da ciência.
Por exemplo, embora os antivírus usem análise de assinatura, heurísticas manuais e regras que são bastante difíceis de manter e estender, o setor de segurança ainda está discutindo sobre os reais benefícios do antivírus e muitos consideram que os antivírus são um produto morto. Os atacantes contornam todas essas regras, por exemplo, com a ajuda de ofuscação e polimorfismo. Como resultado, é dada preferência a ferramentas que usam técnicas mais inteligentes, por exemplo, métodos de aprendizado de máquina que selecionam automaticamente recursos (mesmo aqueles que não são interpretados por seres humanos), podem processar rapidamente grandes quantidades de informações, generalizá-las e tomar decisões rapidamente.
Ou seja, por um lado, o aprendizado de máquina é usado como uma ferramenta de proteção. Por outro lado, essa ferramenta também é usada para ataques mais inteligentes.
Vamos ver se essa ferramenta pode ser vulnerável?
Para qualquer algoritmo, não apenas a seleção de parâmetros é muito importante, mas também os dados nos quais o algoritmo é treinado. Obviamente, em uma situação ideal, é necessário que haja dados suficientes para o treinamento, as aulas sejam equilibradas e o tempo para o treinamento passe despercebido, o que é praticamente impossível na vida real.
A qualidade de um modelo treinado é geralmente entendida como a precisão da classificação nos dados que o modelo ainda não “viu”, no caso geral, como uma certa proporção de cópias de dados classificados corretamente para a quantidade total de dados que transmitimos ao modelo.
Em geral, todas as avaliações de qualidade estão diretamente relacionadas a premissas sobre a distribuição esperada dos dados de entrada do sistema e não levam em consideração as condições ambientais nocivas ( configurações contraditórias ), que geralmente vão além da distribuição esperada dos dados de entrada. Um ambiente malicioso é entendido como um ambiente em que é possível confrontar ou interagir com o sistema. Exemplos típicos desses ambientes são aqueles que usam filtros de spam, algoritmos de detecção de fraude e sistemas de análise de malware.
Assim, a precisão pode ser considerada como uma medida do desempenho médio do sistema em seu uso médio, enquanto a avaliação de segurança está interessada em sua pior implementação.
Ou seja, geralmente os modelos de aprendizado de máquina são testados em um ambiente bastante estático, onde a precisão depende da quantidade de dados para cada classe em particular, mas, na realidade, a mesma distribuição não pode ser garantida. E estamos interessados em errar o modelo. Consequentemente, nossa tarefa é encontrar o maior número possível de vetores que dêem o resultado errado.
Quando falam sobre a segurança de um sistema ou serviço, geralmente significam que é impossível violar uma política de segurança em um determinado modelo de ameaça em hardware ou software, tentando verificar o sistema tanto no estágio de desenvolvimento quanto no estágio de teste. Hoje, porém, um grande número de serviços opera com base em algoritmos de análise de dados; portanto, os riscos não estão apenas na funcionalidade vulnerável, mas também nos próprios dados, com base nos quais o sistema pode tomar decisões.
Ninguém fica parado, e os hackers também estão dominando algo novo. E os métodos que ajudam a estudar algoritmos de aprendizado de máquina quanto à possibilidade de comprometimento por um invasor que pode usar o conhecimento de como o modelo funciona são chamados de aprendizado de máquina adversário ou, em russo, ainda é aprendizado de máquina mal-intencionado .
Se falamos sobre a segurança dos modelos de aprendizado de máquina do ponto de vista da segurança da informação, conceitualmente, eu gostaria de considerar várias questões.
4. É possível manipular o modelo de aprendizado de máquina para realizar um ataque direcionado?
Aqui está um bom exemplo com a otimização de mecanismos de pesquisa. As pessoas estudam como os algoritmos de mecanismo de pesquisa inteligentes funcionam e manipulam os dados em seus sites para serem mais altos no ranking de pesquisa. A questão da segurança de um sistema assim, neste caso, não é tão aguda até comprometer alguns dados ou causar sérios danos.
Como exemplo desse sistema, podemos citar serviços que usam basicamente o treinamento on-line do modelo, ou seja, o treinamento no qual o modelo recebe dados em uma ordem seqüencial para atualizar os parâmetros atuais. Sabendo como o sistema é treinado, você pode planejar o ataque e fornecer ao sistema dados pré-preparados.
Por exemplo, dessa forma, os sistemas biométricos são enganados , que gradualmente atualizam seus parâmetros à medida que pequenas alterações na aparência de uma pessoa ocorrem , por exemplo, com uma mudança natural na idade , o que é absolutamente natural e a funcionalidade necessária do serviço nesse caso. Usando essa propriedade do sistema, você pode preparar os dados e enviá-los ao sistema biométrico, atualizando o modelo até que ele atualize os parâmetros para outra pessoa. Assim, o atacante treinará novamente o modelo e poderá se identificar em vez da vítima.

Esse problema surge naturalmente do fato de o modelo de aprendizado de máquina ser frequentemente testado em um ambiente bastante estático, e sua qualidade é avaliada pela distribuição de dados nos quais o modelo foi treinado. Ao mesmo tempo, muitas vezes perguntas muito específicas são feitas a especialistas em análise de dados, às quais o modelo precisa responder:
- O arquivo é malicioso?
- Esta transação pertence a fraude?
- O tráfego atual é legítimo?
E espera-se que o algoritmo não seja 100% exato, apenas com alguma probabilidade atribua o objeto a alguma classe; portanto, precisamos procurar comprometimentos no caso de erros do primeiro e do segundo tipo, quando o algoritmo não puder ter certeza absoluta. em sua escolha e ainda errado.
Pegue um sistema que muitas vezes produz erros do primeiro e do segundo tipo. Por exemplo, o antivírus bloqueou seu arquivo porque o considerou malicioso (embora não seja o caso) ou o antivírus pulou um arquivo que era malicioso. Nesse caso, o usuário do sistema considera ineficaz e geralmente o desativa, embora seja provável que um conjunto desses dados tenha sido capturado.
E o conjunto de dados no qual o modelo mostra o pior resultado sempre existe. E a tarefa do invasor é procurar esses dados para desativá-lo. Tais situações são bastante desagradáveis e, é claro, o modelo deve evitá-las. E você pode imaginar a escala das conseqüências das investigações de todos os incidentes falsos!
Erros do primeiro tipo são percebidos como uma perda de tempo, enquanto erros do segundo tipo são percebidos como uma oportunidade perdida. Embora, de fato, o custo desses tipos de erros para cada sistema específico possa ser diferente. Se um antivírus pode ser mais barato, um erro do primeiro tipo pode ser cometido, porque é melhor jogar com segurança e dizer que o arquivo é malicioso, e se o cliente encerrar o sistema e o arquivo realmente for malicioso, o antivírus "como foi avisado" e a responsabilidade permanece com o usuário. Se tomarmos, por exemplo, um sistema para diagnóstico médico, os dois erros serão bastante caros, porque, em qualquer caso, o paciente corre o risco de tratamento incorreto e risco à saúde.
6. Um invasor pode usar as propriedades de um método de aprendizado de máquina para interromper o sistema? Ou seja, sem interferir no processo de aprendizagem, encontre essas limitações do modelo que obviamente dão previsões incorretas.
Parece que os sistemas de aprendizado profundo estão praticamente protegidos da intervenção humana na seleção de sinais, portanto seria possível dizer que não há fator humano na tomada de decisões pelo modelo. Todo o encanto da aprendizagem profunda é que basta fornecer dados de entrada quase "brutos" do modelo, e o próprio modelo, por meio de múltiplas transformações lineares, destaca os recursos que "considera" os mais significativos e toma uma decisão. No entanto, é realmente tão bom?
Existem trabalhos que descrevem os métodos para preparar exemplos maliciosos no modelo de aprendizado profundo, que o sistema classifica incorretamente. Um dos poucos exemplos, porém populares, é um artigo sobre ataques físicos eficazes a modelos de aprendizado profundo.
Os autores realizaram experimentos e propuseram métodos para contornar modelos baseados na restrição de aprendizado profundo que enganam o sistema de "visão", usando o exemplo do reconhecimento de sinais de trânsito. Para um resultado positivo, basta que os atacantes encontrem essas áreas no objeto que mais derrubam o classificador, e isso está errado. Os experimentos foram realizados na marca “STOP”, que, devido a mudanças nos pesquisadores, qualificou o modelo como marca “SPEED LIMIT 45”. Eles testaram sua abordagem em outros sinais e obtiveram um resultado positivo.
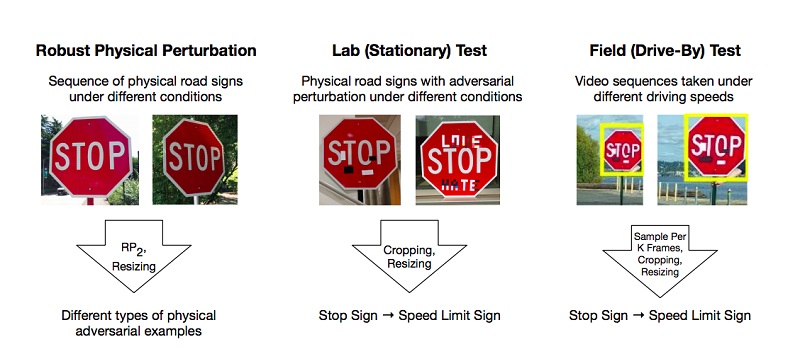
Como resultado, os autores propuseram duas maneiras pelas quais se pode enganar o sistema de aprendizado de máquina: Ataque de impressão de pôsteres, que implica uma série de pequenas alterações em todo o perímetro da marca, chamado camuflagem, e Ataques de adesivos, quando alguns adesivos foram colocados na marca em determinadas áreas.
Mas essas são situações bastante vitais - quando o sinal está na sujeira da poeira da estrada ou quando jovens talentos abandonam seu trabalho nele. É provável que a inteligência artificial e a arte não tenham lugar em um mundo.

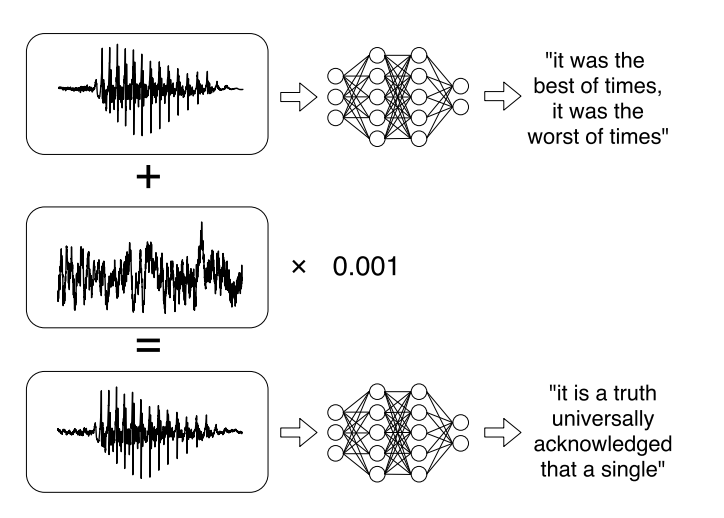
Ou pesquisas recentes sobre ataques direcionados a sistemas de reconhecimento automático de fala . As mensagens de voz se tornaram uma tendência bastante na moda nas comunicações nas redes sociais, mas nem sempre é conveniente ouvi-las. Portanto, existem serviços que permitem transmitir uma gravação de áudio em texto. Os autores do trabalho aprenderam a analisar o áudio original, levar em conta o sinal sonoro e, em seguida, aprenderam a criar outro sinal sonoro, que é 99% semelhante ao original, adicionando uma pequena alteração a ele. Como resultado, o classificador descriptografa o registro conforme o invasor deseja.
7. Nesse sentido, seria possível categorizar os ataques existentes de várias maneiras :
Pelo método de exposição (influência):
- Os ataques causativos afetam o treinamento do modelo por interferência no conjunto de treinamento.
- Ataques exploratórios usam erros de classificação sem afetar o conjunto de treinamento.
Violação de segurança:
- Os ataques de integridade comprometem o sistema por meio de erros do segundo tipo.
- Os ataques de disponibilidade causam o desligamento do sistema, geralmente com base em erros do primeiro tipo.
Especificidade:
- Ataque direcionado (ataque direcionado) visa alterar a previsão do classificador para uma classe específica.
- O ataque em massa (ataque indiscriminado) visa alterar a resposta do classificador para qualquer classe, exceto a correta.
O objetivo da segurança é proteger os recursos de um invasor e a conformidade com os requisitos, cujas violações levam ao comprometimento parcial ou total de um recurso.
Vários modelos de aprendizado de máquina são usados para segurança. Por exemplo, os sistemas de detecção de vírus visam reduzir a vulnerabilidade a vírus, detectando-os antes que o sistema seja infectado ou detectando um existente para remoção. Outro exemplo é o sistema de detecção de intrusões (IDS), que detecta que um sistema foi comprometido pela detecção de tráfego malicioso ou comportamento suspeito no sistema. Outra tarefa próxima é o sistema de prevenção de intrusões (IPS), que detecta tentativas de invasão e evita invasões no sistema.
No contexto de problemas de segurança, o objetivo dos modelos de aprendizado de máquina é, em geral, separar eventos maliciosos e impedir que eles interfiram no sistema.
Em geral, o objetivo pode ser dividido em dois:
integridade : impedir que um invasor acesse os recursos do sistema
acessibilidade : evite que um invasor interfira na operação normal.
Há uma conexão clara entre erros de segundo tipo e violações de integridade: instâncias maliciosas que passam para o sistema podem ser prejudiciais. Assim como os erros do primeiro tipo geralmente violam a acessibilidade, porque o próprio sistema rejeita cópias confiáveis dos dados.
8. Quais são as formas de proteção contra cibercriminosos que manipulam modelos de aprendizado de máquina?
No momento, proteger um modelo de aprendizado de máquina contra ataques maliciosos é mais difícil do que atacá-lo. Só porque não importa o quanto treinamos o modelo, sempre haverá um conjunto de dados no qual ele funcionará melhor.
E hoje não há maneiras suficientemente eficazes de fazer o modelo funcionar com 100% de precisão. Mas existem algumas dicas que podem tornar o modelo mais resistente a exemplos maliciosos.
Aqui está o principal: se é possível não usar modelos de aprendizado de máquina em um ambiente malicioso, é melhor não usá-los. Não faz sentido recusar o aprendizado de máquina se você se deparar com a tarefa de classificar imagens ou gerar memes. Dificilmente é possível infligir qualquer dano significativo que levaria a consequências sociais ou economicamente significativas no caso de um ataque deliberado. , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?