Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3 Você pode me dizer qual é a falta de uma abordagem de segurança que use uma
página de proteção ?
Público: leva mais tempo!
Professor: exatamente! Então, imagine que essa pilha seja muito, muito pequena, mas selecionei uma página inteira para garantir que essa coisinha não fosse atacada por um ponteiro. Esse é um processo muito intensivo em termos espaciais e as pessoas não implantam algo assim em um ambiente de trabalho. Isso pode ser útil para testar "bugs", mas você nunca faria isso para um programa real. Acho que agora você entende o que é um depurador de memória de
cerca elétrica .
Público: Por que a
página de proteção deve ser tão grande?
Professor: O motivo é que eles geralmente dependem de hardware, como proteção no nível da página, para determinar o tamanho da página. Para a maioria dos computadores, 2 páginas de 4 KB de tamanho são alocadas para cada buffer alocado, totalizando 8 KB. Como o heap consiste em objetos, uma página separada é alocada para cada função do
malloc . Em alguns modos, esse depurador não retorna o espaço reservado ao programa, portanto, a
cerca elétrica é muito voraz em termos de memória e não deve ser compilada com o código em funcionamento.
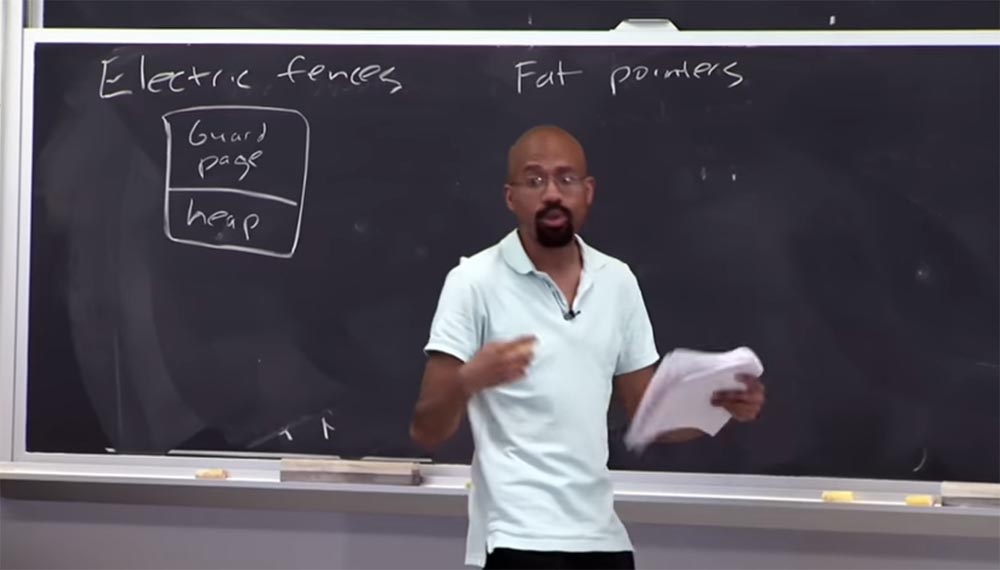
Outra abordagem de segurança que vale a pena dar uma olhada é chamada
ponteiros de gordura , ou "ponteiros grossos". Nesse caso, o termo “grosso” significa que uma grande quantidade de dados é anexada ao ponteiro. Nesse caso, a idéia é que queremos alterar a própria representação do ponteiro para incluir informações sobre os limites em sua composição.
Um ponteiro regular de 32 bits consiste em 32 bits e os endereços estão localizados dentro dele. Se considerarmos o "ponteiro grosso", ele consiste em 3 partes. A primeira parte é uma base de 4 bytes, à qual também está anexado um final de 4 bytes. Na primeira parte, o objeto começa, na segunda termina e, na terceira, também com 4 bytes, o endereço
cur é incluído. E dentro desses limites comuns há um ponteiro.

Portanto, quando o compilador gera um código de acesso para esse "ponteiro espesso", ele atualiza o conteúdo da última parte do
endereço cur e verifica simultaneamente o conteúdo das duas primeiras partes para garantir que nada de ruim tenha acontecido com o ponteiro durante o processo de atualização.
Imagine que eu tenho esse código:
int * ptr = malloc (8) , este é um ponteiro para o qual 8 bytes são alocados. Em seguida, tenho um
loop while que está prestes a atribuir algum valor ao ponteiro e, a seguir, o incremento do ponteiro
ptr ++ . Cada vez que esse código é executado no endereço atual do ponteiro de endereço atual, ele verifica se o ponteiro está dentro dos limites especificados na primeira e na segunda partes.
Este é o caso no novo código que o compilador gera. Um grupo on-line geralmente levanta a questão do que é "código de ferramenta". Este é o código que o compilador gera. Você, como programador, vê apenas o que é mostrado à direita - essas 4 linhas. Porém, antes dessa operação, o compilador insere um novo código C no
endereço atual , atribui um valor ao ponteiro e verifica os limites a cada vez.

E se, ao usar o novo código, o valor ultrapassar os limites, a função será interrompida. Isso é chamado de "código da ferramenta". Isso significa que você pega o código-fonte usando um programa C, adiciona o novo código-fonte C e compila o novo programa. Portanto, a idéia básica por trás dos
indicadores Fat é bastante simples.
Existem algumas desvantagens nessa abordagem. A maior desvantagem é o tamanho grande do ponteiro. E isso significa que você não pode simplesmente pegar o "ponteiro grosso" e passá-lo inalterado, para fora da biblioteca de shell. Porque pode haver uma expectativa de que o ponteiro tenha um tamanho padrão e o programa forneça esse tamanho, no qual ele "não se encaixa", por causa do qual tudo explodirá. Também existem problemas se você deseja incluir ponteiros desse tipo em uma
estrutura ou algo parecido, porque eles podem redimensionar a
estrutura .
Portanto, uma coisa muito popular no código C é pegar algo do tamanho de uma
estrutura e, em seguida, fazer algo com base nesse tamanho - reservar espaço em disco para estruturas desse tamanho e assim por diante.
E uma coisa mais delicada é que esses indicadores, como regra, não podem ser atualizados de maneira atômica. Para arquiteturas de 32 bits, é típico escrever uma variável de 32 bits atômica. Mas “ponteiros grossos” contêm 3 tamanhos
inteiros ; portanto, se você tiver um código que espere que o ponteiro tenha um valor atômico, poderá ter problemas. Porque, para fazer algumas dessas verificações, é necessário examinar o endereço atual e, em seguida, os tamanhos, e talvez seja necessário aumentá-los, e assim por diante. Portanto, isso pode causar erros muito sutis se você usar código que tenta desenhar paralelos entre ponteiros regulares e grossos. Assim, você pode usar
ponteiros de gordura em alguns casos, como
cercas Electroc , mas os efeitos colaterais de seu uso são tão significativos que, na prática normal, essas abordagens não são usadas.
E agora falaremos sobre a verificação de limites em relação à estrutura dos dados de sombra. A idéia principal da estrutura é que você saiba o tamanho de cada objeto que você vai colocar, ou seja, o tamanho que você precisa reservar para esse objeto. Portanto, por exemplo, se você tiver um ponteiro que chame com a função
malloc , precisará especificar o tamanho do objeto:
char xp = malloc (size) .

Se você tem algo parecido com uma variável estática como este
char p [256] , o compilador pode descobrir automaticamente quais devem ser os limites para sua localização.
Portanto, para cada um desses ponteiros, é necessário inserir duas operações. Isso é principalmente aritmético, como
q = p + 7 , ou algo semelhante. Essa inserção é feita desreferenciando um link do tipo
deref * q = 'q' . Você pode se perguntar por que não pode confiar no link ao colar? Por que precisamos fazer essas aritméticas? O fato é que, ao usar C e c ++, você tem um ponteiro apontando para uma passagem para o final válido do objeto à direita, após o qual é usado como uma condição de parada. Então, você vai para o objeto e, assim que alcança esse ponteiro final, na verdade para o loop ou interrompe a operação.
Portanto, se ignorarmos a aritmética, sempre causamos um erro grave, no qual o ponteiro vai além dos limites, o que pode realmente atrapalhar o trabalho de muitas aplicações. Portanto, não podemos simplesmente inserir o link, porque como você sabe que isso acontece fora dos limites estabelecidos? A aritmética nos permite dizer se é ou não, e aqui tudo será legal e correto. Como essa cunha usando aritmética permite rastrear onde o ponteiro está localizado em relação à sua linha de base original.
Portanto, a próxima pergunta é: como realmente implementamos a validação de borda? Porque precisamos de alguma forma corresponder o endereço específico do ponteiro com algum tipo de informação de limite para esse ponteiro. E, portanto, muitas de suas decisões anteriores usam coisas como, por exemplo, uma tabela de hash ou uma árvore, o que permite realizar a pesquisa correta. Portanto, dado o endereço do ponteiro, faço algumas pesquisas nessa estrutura de dados e descubro quais limites ele possui. Dadas essas fronteiras, decido se posso deixar a ação acontecer ou não. O problema é que essa é uma pesquisa lenta, porque essas estruturas de dados estão se ramificando e, ao examinar uma árvore, você precisa examinar várias dessas ramificações até encontrar o valor certo. E mesmo que seja uma tabela de hash, você deve seguir as cadeias de código e assim por diante. Portanto, precisamos definir uma estrutura de dados muito eficaz que rastreie seus limites, uma que tornaria essa verificação muito simples e clara. Então, vamos ao que interessa agora.
Mas, antes de fazer isso, deixe-me falar brevemente sobre como a abordagem de
alocação de memória de amigos funciona. Porque essa é uma das coisas que costumamos fazer.
A alocação de memória de amigos divide a memória em partições com um poder múltiplo de 2 e tenta alocar solicitações de memória nelas. Vamos ver como isso funciona. No início, a
alocação de amigos trata a memória não alocada como um grande bloco - esse é o retângulo superior de 128 bits. Em seguida, quando você solicita um bloco menor para alocação dinâmica, ele tenta dividir esse espaço de endereço em partes em incrementos de 2 até encontrar um bloco suficiente para suas necessidades.
Suponha que uma solicitação do tipo
a = malloc (28) chegou, ou seja, uma solicitação para alocar 28 bytes. Temos um bloco de 128 bytes que é desperdício demais para ser alocado para esta solicitação. Portanto, nosso bloco é dividido em dois blocos de 64 bytes - de 0 a 64 bytes e de 64 bytes a 128 bytes. E esse tamanho também é grande para nossa solicitação, portanto, o
buddy divide novamente um bloco de 64 bytes em 2 partes e recebe 2 blocos de 32 bytes.

Menos é impossível, porque 28 bytes não cabem e 32 é o tamanho mínimo mais adequado. Então agora esse bloco de 32 bytes será alocado para o nosso endereço a. Suponha que tenhamos outra consulta para
b = malloc (50) .
O amigo verifica os blocos selecionados e, como 50 é maior que a metade de 64, mas menor que 64, coloca o valor b no bloco mais à direita.
Finalmente, temos outra solicitação de 20 bytes:
c = malloc (20) , esse valor é colocado no bloco do meio.
 O Buddy
O Buddy tem uma propriedade interessante: quando você libera memória em um bloco e ao lado dele é um bloco do mesmo tamanho, após liberar os dois blocos, o
buddy combina dois blocos vizinhos vazios em um.

Por exemplo, quando dermos o comando
free © ,
liberaremos o bloco
do meio, mas a união não ocorrerá; portanto, o bloco ao lado ainda estará ocupado. Porém, após liberar o primeiro bloco usando o comando
free (a) , os dois blocos serão mesclados em um. Então, se liberarmos o valor de b, os blocos vizinhos serão mesclados novamente e obteremos um bloco inteiro de 128 bytes de tamanho, como era no começo. A vantagem dessa abordagem é que você pode encontrar facilmente onde está o amigo através de uma aritmética simples e determinar os limites da memória. É assim que a alocação de memória funciona com a abordagem de
alocação de memória do
Buddy .
Todas as minhas palestras costumam ser feitas, não é uma abordagem tão inútil? Imagine que, no início, eu tinha um pedido de 65 bytes, teria que alocar todo o bloco de 128 bytes para ele. Sim, isso é um desperdício, na verdade você não possui memória dinâmica e não pode mais alocar recursos no mesmo bloco. Mas, novamente, isso é um compromisso, porque é muito fácil fazer um cálculo, como fazer uma fusão e coisas assim. Portanto, se você quiser uma alocação de memória mais precisa, precisará usar uma abordagem diferente.
Então, o que o
sistema de verificação de rejeição de buggy (BBC) faz?

Ela realiza vários truques, um dos quais é a separação do bloco de memória em duas partes, uma das quais contém um objeto e a segunda é uma adição a ele. Assim, temos 2 tipos de limites - os limites do objeto e os limites da distribuição da memória. A vantagem é que não há necessidade de armazenar o endereço base, e é possível uma pesquisa rápida usando uma tabela de linhas.
Todos os nossos tamanhos de distribuição são 2 à potência de
n , onde
n é um número inteiro. Esse princípio
2n é chamado de
potência de dois . Portanto, não precisamos de muitos bits para imaginar o tamanho de um determinado tamanho de distribuição. Por exemplo, se o tamanho do cluster for 16, basta selecionar 4 bits - este é o conceito de um logaritmo, ou seja, 4 é um expoente de
n , no qual você precisa aumentar o número 2 para obter 16.
Essa é uma abordagem bastante econômica para alocação de memória, porque o número mínimo de bytes é usado, mas deve ser um múltiplo de 2, ou seja, você pode ter 16 ou 32, mas não 33 bytes. Além disso, a
verificação de rejeição do Buggy permite armazenar informações sobre valores de limite em uma matriz linear (1 byte por registro) e permite alocar memória em 1 slot com um tamanho de 16 bytes. alocar memória com granularidade de slot. O que isso significa?

Se tivermos um slot de 16 bytes onde colocaremos o valor
p = malloc (16) , o valor na tabela será semelhante à
tabela [p / slot.size] = 4 .

Suponha que agora precisamos colocar um valor de 32 bytes no tamanho
p = malloc (32) . Precisamos atualizar a tabela de borda para corresponder ao novo tamanho. E isso é feito duas vezes: primeiro como
tabela [p / slot.size] = 5 e, em seguida, como
tabela [(p / slot.size) + 1] = 5 - a primeira vez no primeiro slot, que está alocado para essa memória, e o segundo vezes - para o segundo slot. Assim, alocamos 32 bytes de memória. É assim que o log de distribuição de tamanho se parece. Portanto, para dois slots de alocação de memória, a tabela de limites é atualizada duas vezes. Isso está claro? Este exemplo é destinado a pessoas que duvidam que logs e tabelas tenham um significado ou não. Como as tabelas são multiplicadas toda vez que ocorre a alocação de memória.
Vamos ver o que acontece com a tabela de borda. Suponha que tenhamos um código C que se parece com isso:
p '= p + i , ou seja, o ponteiro
p' é obtido de
p adicionando alguma variável
i . Então, como obtemos o tamanho da memória alocado para
p ? Para fazer isso, você olha para a tabela usando as seguintes condições lógicas:
size = 1 << tabela [p >> log de slot_size]
À direita, temos o tamanho dos dados alocados para
p , que deve ser 1. Em seguida, você os move para a esquerda e olha para a tabela, pega esse tamanho de ponteiro e depois para a direita, onde está localizado o log da tabela de tamanho de slot. Se a aritmética funcionar, vincularemos corretamente o ponteiro à tabela de borda. Ou seja, o tamanho do ponteiro deve ser maior que 1, mas menor que o tamanho do slot. À esquerda, temos o valor, e à direita - o tamanho do slot e o valor do ponteiro está localizado entre eles.
Suponha que o tamanho do ponteiro seja 32 bytes e, na tabela, dentro dos colchetes, teremos o número 5.
Suponha que desejemos encontrar a palavra-chave base desse ponteiro:
base = p & n (tamanho - 1) . O que vamos fazer nos dá uma certa massa, e essa massa nos permitirá restaurar a
base localizada aqui. Imagine que nosso tamanho é 16, em binário é 16 = ... 0010000. As reticências significam que ainda existem muitos zeros, mas estamos interessados nesta unidade e nos zeros atrás dela. Se considerarmos (16 -1), será algo assim: (16 - 1) = ... 0001111. No código binário, o inverso disso será assim: ~ (16-1) ... 1110000.
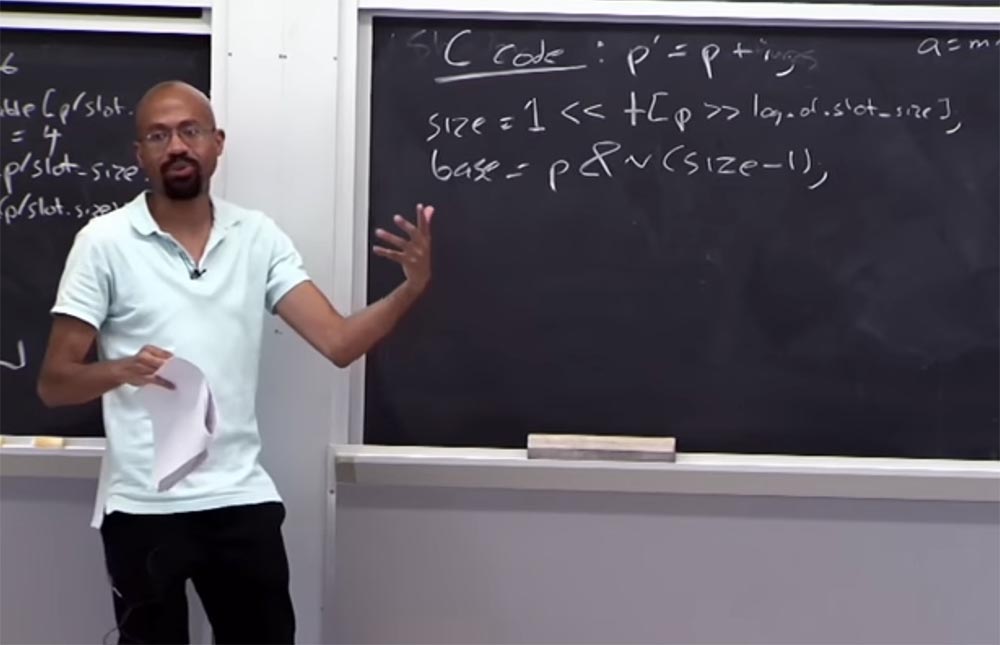

Assim, isso nos permite limpar basicamente o bit, que será essencialmente renderizado a partir do ponteiro atual e nos dará sua
base . Graças a isso, será muito simples verificar se esse ponteiro está dentro dos limites. Portanto, podemos simplesmente verificar se
(p ')> = base e se o valor (
p' - base) é menor que o tamanho selecionado.

É uma coisa bastante simples de descobrir se o ponteiro está dentro dos limites de memória. Não vou entrar em detalhes, basta dizer que toda aritmética binária é resolvida da mesma maneira. Esses truques permitem evitar cálculos mais complexos.
Há mais uma quinta propriedade da
verificação de rejeição do
Buggy - ela usa um sistema de memória virtual para evitar ultrapassar os limites definidos para o ponteiro. A idéia principal é que, se tivermos uma aritmética para o ponteiro com a qual determinamos a saída, podemos definir um bit de ordem superior para o ponteiro.

Ao fazer isso, garantimos que a exclusão da referência do ponteiro não causará problemas de hardware. Definir o
bit de ordem alta por si só não causa problemas; a desreferenciação do ponteiro pode causar um problema.
A versão completa do curso está disponível
aqui .
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?