O que é mais desagradável do que o "teste vermelho"? O teste é verde ou vermelho, e não está claro o porquê. Em nossa conferência Heisenbug 2017 em Moscou,
Andrei Solntsev (Codeborne) falou sobre por que eles podem surgir e como reduzir seu número. Exemplos no relatório dele são tais que você sente a dor diretamente na pele quando colide com eles. E as dicas são úteis - e vale a pena conhecer testadores e desenvolvedores. Há algo inesperado: você pode descobrir como às vezes pode descobrir um problema se se afastar da tela e jogar cubos com sua filha.
Como resultado, o público apreciou o relatório, e decidimos não apenas publicar o vídeo, mas também fazer uma versão em texto do relatório para Habr.
Na minha opinião, testes esquisitos são o tópico mais relevante no mundo da automação. Porque a pergunta "o que está sendo feito no mundo, como você está fazendo com a automação?" todas respondem: “Não há estabilidade! Nossos testes caem periodicamente. ”
Você fez um teste em sua casa, é verde, outros dois dias verdes e, uma vez e de repente, caiu sobre Jenkins. Você tenta repeti-lo, iniciá-lo e fica verde novamente. E no final, você nunca sabe: é um bug ou é apenas um teste de glucana? E toda vez que você precisa entender.
Muitas vezes, após o lançamento noturno de testes no Jenkins, o testador vê pela primeira vez "30 testes caíram, você precisa estudar", mas todos sabem o que acontece a seguir ...

Você, claro, adivinhou qual palavra indecente disfarçava: "Vou reiniciar". Como "hoje não há relutância em entender ..." É assim que geralmente acontece e é um verdadeiro desastre.
Não há estatísticas exatas, mas muitas vezes ouvi de pessoas diferentes que elas têm cerca de 30% dos testes - escamosos. Grosso modo, eles lançam mil, dos quais 300 são periodicamente vermelhos e depois checam com as mãos se realmente caíram.
O Google publicou
um artigo há alguns anos: ele diz que eles têm 1,5% por cento de testes inadequados e conta como eles lutam para reduzir seu número. Posso me gabar um pouco e dizer que meu projeto em Codeborne agora é de 0,1%. Mas, de fato, tudo isso é ruim, mesmo 0,1%. Porque
Tome 1,5%, esse número parece pequeno, mas o que isso significa na prática? Digamos que haja mil testes em um projeto. Isso pode significar que 15 testes caíram em uma versão, os próximos 12 e depois 18. E isso é muito ruim, porque nesse caso quase todas as versões são vermelhas e você precisa verificar constantemente com as mãos se é verdade ou não.
E até o nosso 1 ppm (0,1%) ainda é ruim. Suponha que tenhamos 1000 testes e, em seguida, 0,1% significa que regularmente uma em cada dez quedas cai com 1-2 testes em vermelho. Aqui está a imagem real do nosso Jenkins, e acontece que: com uma corrida, um teste escamoso caiu, com outro começo outro.
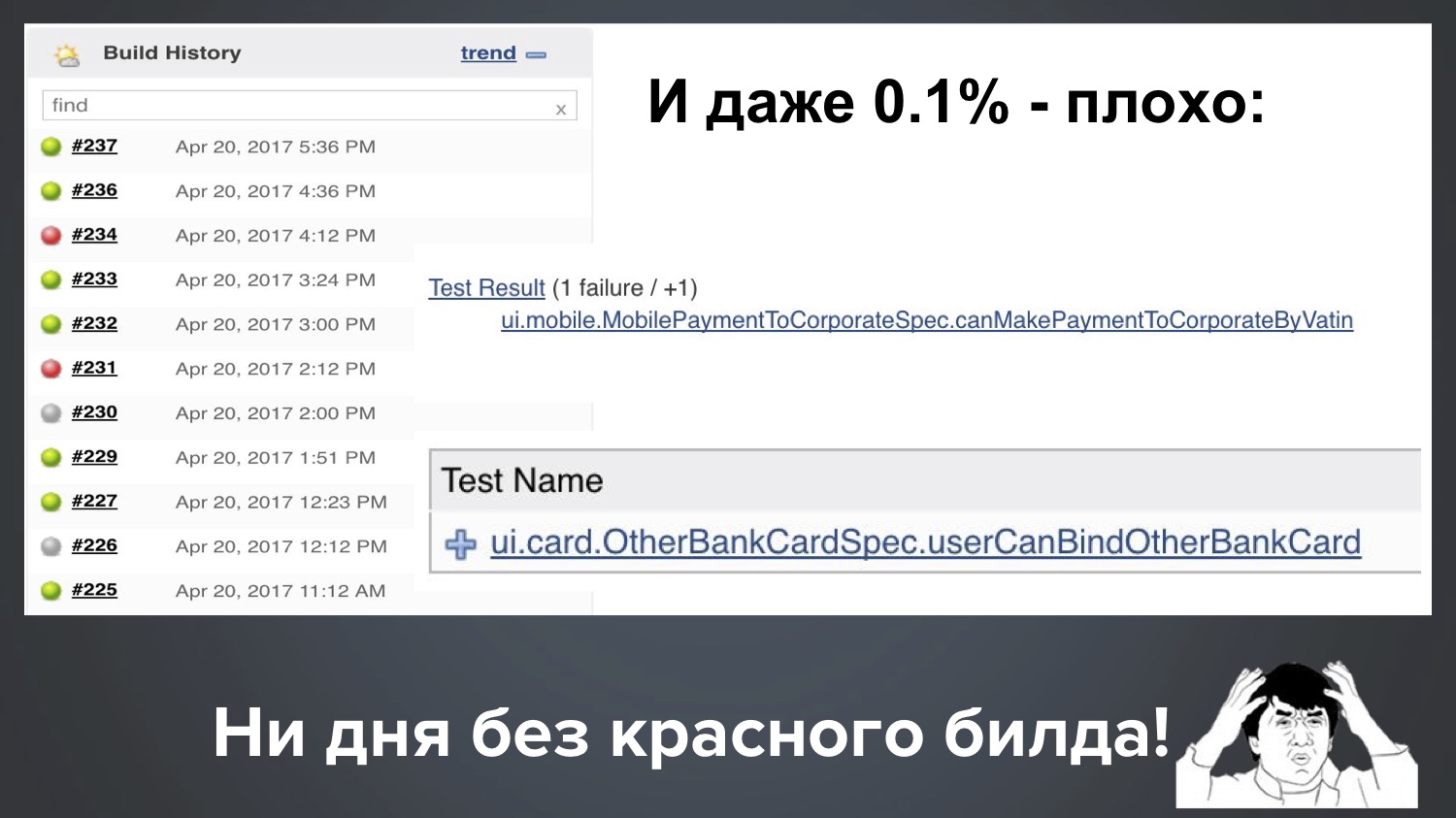
Acontece que não temos um dia sem uma construção vermelha. Como há muito verde, tudo parece estar bem, mas o cliente tem o direito de nos perguntar: "Pessoal, pagamos dinheiro e você sempre nos fornece vermelho!" O que você está fazendo?
Eu ficaria insatisfeito no local do cliente, e explicar "em geral, isso é normal no setor, tudo é vermelho para todos" não é bom, certo? Portanto, na minha opinião, esse é um problema muito urgente, e vamos entender juntos como lidar com isso.
O plano é este:
- Minha coleção de testes instáveis (da minha prática, casos absolutamente reais, histórias de detetive complexas e interessantes)
- Causas de instabilidade (alguns até levaram anos para pesquisar)
- Como lidar com eles? (espero que seja a parte mais útil)
Então, vamos começar com minha coleção, que eu valorizo muito: me custou muitas horas noturnas de vida e depuração. Vamos começar com um exemplo simples.
Exemplo 1: clássico
Para sementes - o clássico script Selenium:
driver.navigate().to("https://www.google.com/"); driver.findElement(By.name("q")).sendKeys("selenide"); driver.findElement(By.name("btnK")).click(); assertEquals(9, driver.findElements(By.cssSelector("#ires .g")).size());
- Abrimos o WebDriver;
- Encontre o elemento q, dirija na palavra para pesquisar lá;
- Encontre o elemento "Button" e clique;
- Verifique se a resposta é nove resultados.
Pergunta: qual linha pode quebrar aqui?
É isso mesmo, todos sabemos bem que qualquer um! Qualquer linha pode quebrar, por razões completamente diferentes:
A primeira linha é a Internet lenta, o serviço travou, os administradores não configuraram nada.
A segunda linha - o elemento ainda não teve tempo para renderizar se for desenhado dinamicamente.
O que poderia quebrar na terceira linha? Aqui foi inesperado para mim: escrevi este teste para a conferência, executei-o localmente e caiu na terceira linha com este erro:

Isso indica que o elemento neste momento não é clicável. Parece um simples formulário básico do Google. O segredo acabou sendo o de que atingimos a palavra na segunda linha e, enquanto a inseríamos, o Google já encontrou os primeiros resultados, mostrou os primeiros resultados em um pop-up e eles fecharam o botão seguinte. E isso não acontece em todos os navegadores e nem sempre. Isso aconteceu comigo com esse script uma vez em cada cinco.
A quarta linha pode cair, por exemplo, porque esse elemento é desenhado dinamicamente e ainda não teve tempo para desenhar.
Neste exemplo, quero dizer que, na minha experiência, 90% dos testes de falhas são baseados nos mesmos motivos:
- Velocidade de solicitação do Ajax: às vezes eles correm mais devagar;
- A ordem dos pedidos do Ajax;
- Velocidade js.
Felizmente, há uma cura por esses motivos!
Selenida resolve esses problemas. Como isso decide? Reescrevemos nosso teste do Google no Selenide - quase tudo se parece, apenas os sinais de $ são usados:
@Test public void userCanLogin() { open(“http:
Este teste sempre passa. Devido ao fato de os métodos setValue (), click () e shouldHave () serem inteligentes: se algo não tiver tempo para ser aplicado, eles esperam um pouco e tentam novamente (isso é chamado de "expectativas inteligentes").
Se você olhar um pouco mais detalhadamente, todos esses métodos deveriam * são inteligentes:

Eles podem esperar, se necessário. Por padrão, eles esperam até 4 segundos, e esse tempo limite, é claro, é configurável, você pode especificar qualquer outro. Por exemplo, assim: mvn -Dselenide.timeout = 8000.
Exemplo 2: nbob
Assim, 90% dos problemas com testes escamosos são resolvidos com Selenide. Mas 10% dos casos muito mais sofisticados permanecem com razões complexas e confusas. É precisamente sobre eles que quero falar hoje, porque é uma "área cinzenta". Deixe-me dar um exemplo: um teste superficial, que me deparei imediatamente em um novo projeto. À primeira vista, isso simplesmente não pode acontecer, mas isso é algo interessante.
Testamos o aplicativo do teclado para login em quiosques. O teste queria efetuar login como o usuário "bob", ou seja, digite três letras no campo "login": bob. Para isso, foram utilizados os botões na tela. Como regra, isso funcionava, mas às vezes o teste falhava e o valor "nbob" permanecia no campo "login":

Naturalmente, você está lutando para pesquisar pelo código onde poderíamos ter escrito "nbob" - mas em todo o projeto isso não é de todo (nem no banco de dados, nem no código, nem nos arquivos do Excel). Como isso é possível?
Examinamos o código com mais detalhes - parece que tudo é simples, sem enigmas:
@Test public void loginKiosk() { open(“http:
Começamos a debater mais, passo a passo e com esse método conseguimos entender: esse erro às vezes aparece após a linha $ ("body"). Clique em (). Ou seja, nesta etapa, "n" aparece no campo "login" e, em seguida, "bob" é adicionado nas etapas subsequentes. Quem já adivinhou de onde vem "n"?
Aconteceu que a letra N estava no meio da tela e a função click () pelo menos no Chrome funciona assim: calcula a coordenada central de um elemento e clica nele. Como corpo é um elemento grande, ela clicou no centro de toda a tela.
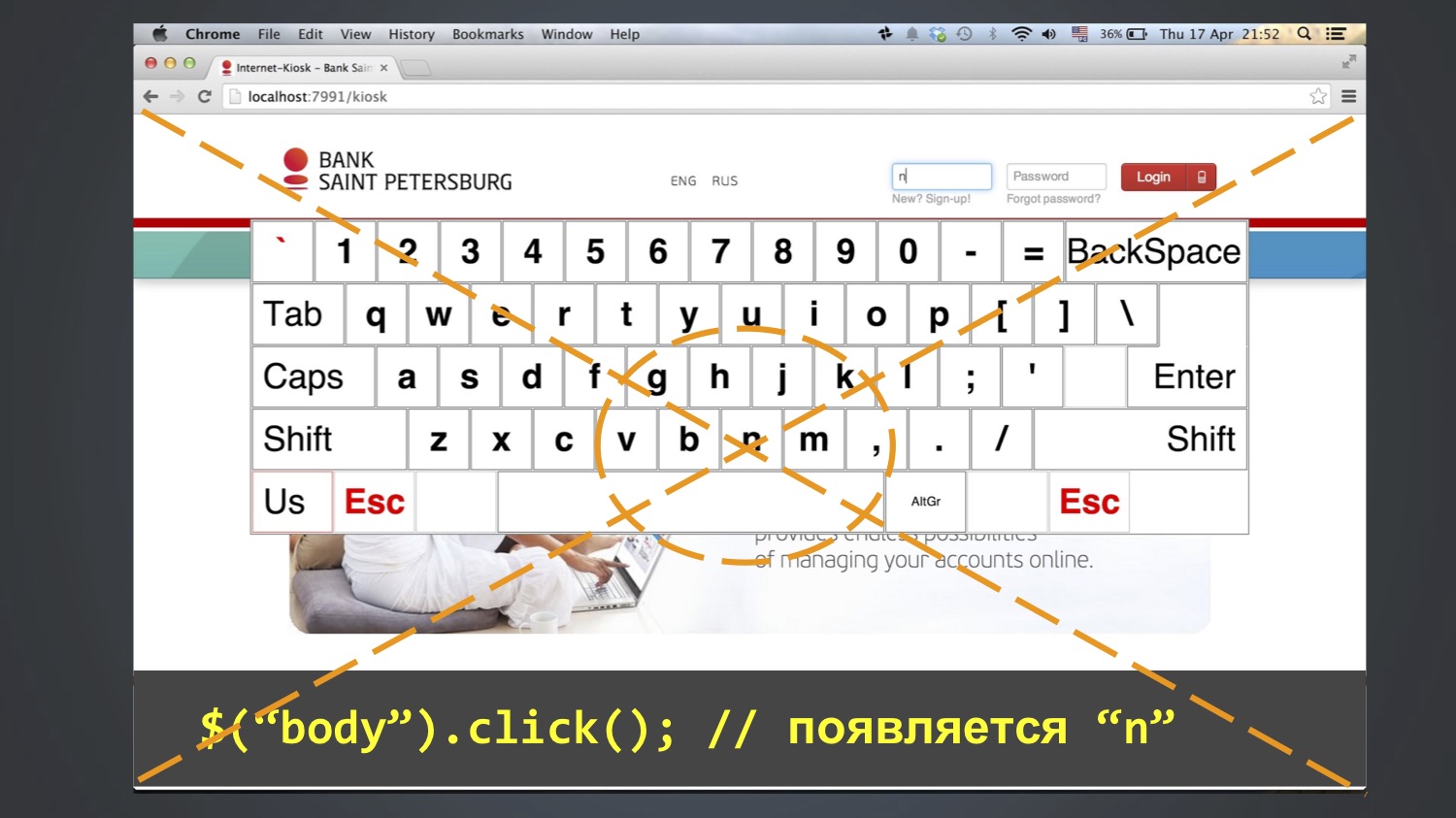
E isso nem sempre caiu. Quem sabe porque? De fato, eu mesmo não sei completamente. Talvez devido ao fato de a janela do navegador ser aberta o tempo todo em tamanhos diferentes, e isso nem sempre cair na letra N.
Você provavelmente tem uma pergunta: por que alguém ganhou $ ("body")? Clique em ()? Também não sei até o fim, mas suponho remover o foco do campo. Existe um problema no Selenium que é clicar em (), mas desmarcar () não. Se houver um foco no campo, ele não poderá ser removido a partir daí, você poderá clicar apenas em qualquer outro elemento. E como não havia outros elementos razoáveis, eles clicaram no corpo e obtiveram esse efeito.
Daí a moral: não insira nada que entre no <corpo>. Em outras palavras, você não precisa fazer nenhum movimento extra em pânico. De fato, isso geralmente acontece: desde que eu lido com o Selenide, muitas vezes recebo reclamações de que "algo não funciona" e, em seguida, verifica-se que em algum lugar nos métodos de configuração havia 15 linhas extras que não fazem nada útil e interferem . Não há necessidade de mexer e inserir de qualquer maneira em testes como "de repente será mais confiável".
Como resultado, expandimos a lista de razões para testes instáveis:
- Velocidade de solicitação do Ajax;
- A ordem dos pedidos do Ajax;
- Velocidade js;
- Tamanho da janela do navegador;
- Vaidade!
E, ao mesmo tempo, minha recomendação é: não execute testes de forma maximizada (ou seja, não abra o navegador em uma janela completa). Como regra, todo mundo faz isso, e no Selenide era por padrão (ou ainda é). Em vez disso, aconselho que você sempre inicie um navegador com uma resolução de tela estritamente definida, porque esse fator aleatório é excluído. E aconselho que você defina o tamanho mínimo que seu aplicativo suporta, de acordo com a especificação.
Exemplo 3: contas fantasmas
Um exemplo é interessante, pois tudo o que só pode coincidir imediatamente coincide.
Houve um teste que verificou se deveria haver 5 contas nessa tela.

Como regra geral, era verde, mas às vezes não estava claro em que condições ele caiu e disse que não havia cinco, mas seis contagens na tela.
Comecei a pesquisar de onde vem a conta extra. Absolutamente incompreensível. Surgiu a pergunta: talvez tenhamos outro teste, que durante o teste cria uma nova conta? Descobriu-se que sim, existe um LoansTest. E entre ele e o AccountsTest em queda (que espera cinco contas), pode haver um milhão de outros testes.
Estamos tentando entender como é: o LoansTest, que cria a conta, não deve excluí-lo no final? Nós olhamos para o seu código - sim, deveria, no final, há uma função After para isso. Então, em teoria, tudo deve ficar bem, qual é o problema?
Talvez o teste o remova, mas ele permanece em cache em algum lugar? Observamos o código de produção que carrega as contas - ele realmente possui a anotação @CacheFor, ele armazena em cache as contas por cinco minutos.
Surge a pergunta: mas o teste não deveria limpar esse cache? Seria lógico, não pode haver tal batente? Analisamos seu código - sim, ele realmente limpa o cache antes de cada teste. O que houve? Aqui você já está perdido, porque as hipóteses terminaram: o objeto foi excluído, o cache foi limpo, varas de árvores, o que mais poderia ser um problema? Então ele começou a escalar o código, levou algum tempo, talvez até alguns dias. Até que finalmente olhei para essa classe e superclasse e encontrei uma coisa suspeita lá:

Alguém já percebeu, certo? Isso mesmo: na classe filho e na classe pai, existe um método com o mesmo nome e ele não chama super.
E em Java, é muito fácil: pressione Alt + Enter ou Ctrl + Insert no IntelliJ IDEA ou Eclipse; por padrão, ele cria o método setUp () para você e você não percebe que ele substitui o método na superclasse. Ou seja, o cache ainda não foi chamado. Quando vi isso, fiquei com muita raiva. É alegre para mim agora.
Daí a moral:
- Nos testes, é muito importante monitorar o código limpo. Se no código de produção todos estão atentos a isso, eles realizam uma revisão de código e, em seguida, nos testes - nem sempre.
- Se o código de produção for verificado por testes, quem testará os testes? Portanto, é especialmente importante usar verificações no IDE.
Após esse incidente, encontrei na IDEA uma inspeção desse tipo, desativada por padrão, que verifica: se o método for substituído em algum lugar, mas não houver anotação @ Overrid, isso marca isso como um erro. Agora eu sempre marquei histericamente esta caixa.
Vamos resumir novamente: como isso aconteceu, por que o teste falhou nem sempre? Primeiro, dependia da ordem desses dois testes; eles sempre são executados em ordem aleatória. Outro teste dependia de quanto tempo passou entre eles. As contas são armazenadas em cache por cinco minutos; se mais foram aprovadas, o teste ficou verde e, se menos, caiu, e isso raramente aconteceu.
Expandimos a lista de por que os testes podem ser instáveis:
- Velocidade de solicitação do Ajax;
- A ordem dos pedidos do Ajax;
- Velocidade js;
- Tamanho da janela do navegador;
- Cache de aplicativos;
- Dados de testes anteriores;
- Hora.
Exemplo 4: Hora do Java
Houve um teste que funcionou em todos os nossos computadores e no nosso Jenkins, mas às vezes trava em um cliente Jenkins. Nós olhamos para o teste, entendemos o porquê. Acontece que estava caindo, porque ao verificar "a data do pagamento deveria ser agora ou no passado", acabou sendo "no futuro".
assert payment.time <= new Date();
Observamos o código, de repente, sob algumas condições, podemos definir uma data no futuro? Não podemos: no único local em que a hora do pagamento é inicializada, nova data () é usada e essa é sempre a hora atual (em casos extremos, pode ser no passado se o teste for muito lento). Como isso é possível? Eles bateram de cabeça por um longo tempo, eles não conseguiram entender.
E uma vez que eles examinaram o log do aplicativo. Daí a primeira moral - é muito útil ao examinar testes para examinar o log do próprio aplicativo. Levante suas mãos, quem faz isso. Em geral, não a maioria, infelizmente. E há informações úteis: por exemplo, o log de solicitações, tal e qual URL foi executado naquele momento, deu tal e tal resposta.

Há algo suspeito aqui, percebe? Observamos o momento: esse pedido foi processado menos três segundos. Como isso pode ser? Eles lutaram por um longo tempo, não conseguiam entender. Finalmente, quando ficamos sem teoria, tomamos uma decisão estúpida: Jenkins escreveu um script simples que registra a hora atual em um ciclo uma vez por segundo. Lançado. No dia seguinte, quando esse teste superficial caiu uma vez à noite, eles começaram a assistir a um trecho desse arquivo para o momento em que ele caiu:

Então: 34 segundos, 35, 36, 37, 35, 39 ... É legal termos encontrado, mas como isso é possível? As teorias terminaram novamente, mais dois dias coçando a cabeça. Este é realmente o caso quando o Matrix está brincando com você, certo?
Até que finalmente uma idéia me atingiu ... E isso acabou sendo. O Linux possui um serviço de sincronização de tempo que é executado em um servidor central e pergunta "quantos milissegundos são agora?" E acontece que dois serviços diferentes foram lançados nesse Jenkins específico. O teste começou a falhar quando o Ubuntu foi atualizado neste servidor.
Lá, um serviço NTP era configurado anteriormente, que acessava um servidor bancário especial e levava tempo a partir daí. E com a nova versão do Ubuntu, um novo serviço leve foi incluído por padrão, por exemplo, systemd-timesyncd. E ambos funcionaram. Ninguém percebeu isso. Por alguma razão, o servidor do banco central e o servidor Ubuntu central emitiram uma resposta com uma diferença de 3 segundos. Naturalmente, esses dois serviços interferiram um no outro. Em algum lugar profundo da documentação do Ubuntu, ele diz que, é claro, não permite essa situação ... Bem, obrigado pela informação :)
A propósito, ao mesmo tempo, aprendi uma nuance interessante de Java, que antes disso, apesar de meus muitos anos de experiência, não conhecia. Um dos métodos mais básicos em Java é chamado System.currentTimeMillis (), com a ajuda do qual normalmente é programado para chamar algo, muitos escreveram esse código:
long start = System.currentTimeMillis();
Esse código está nas bibliotecas Apache Commons, Guava. Ou seja, se você precisar detectar quantos milissegundos foram necessários para chamar alguma coisa, eles geralmente o fazem. E muitos provavelmente ouviram que isso não deveria ser feito. Eu também ouvi, mas não sabia o porquê, e com preguiça de entender. Eu pensei que a pergunta era exatamente porque System.nanoTime () apareceu em alguma versão do Java - é mais preciso, produz nanossegundos que são um milhão de vezes mais precisos. E, como regra, minhas chamadas duram um segundo ou meio segundo, essa precisão não é importante para mim e continuei a usar System.currentTimeMillis (), que vimos no log em que eram -3 segundos. Então, de fato, a maneira correta é essa, e agora eu descobri o porquê:
long start = System.nanoTime();
Na verdade, isso está escrito na documentação dos métodos, mas eu nunca o li. Durante toda a minha vida, pensei que System.currentTimeMillis () e System.nanoTime () são a mesma coisa, mas com uma diferença de um milhão de vezes. Mas aconteceu que essas são coisas fundamentalmente diferentes.
System.currentTimeMillis () retorna a data atual real - quantos milissegundos são agora desde 1º de janeiro de 1970. E System.nanoTime () é um tipo de contador abstrato que não está vinculado ao tempo real: sim, é garantido que ele cresça a cada nanossegundo por unidade, mas não esteja conectado ao horário atual, pode até ser negativo. No início da JVM, um ponto no tempo é de alguma forma selecionado aleatoriamente e começa a crescer. Foi uma surpresa para mim. Para você também? Bem, não foi em vão que ele chegou.
Exemplo 5: A maldição do botão verde
Aqui, nosso teste preenche um determinado formulário, clica no botão verde Confirmar e, às vezes, não vai mais longe. Por que isso não acontece é incompreensível.
Dirigimos quatro zeros e travamos, não vá para a próxima página. Clicar ocorre sem erros. Eu olhei para tudo: solicitações do Ajax, espera, tempo limite, logs de aplicativos, cache - não encontrei nada. A biblioteca do
Gravador de vídeo escrita por Sergey Pirogov ainda não apareceu. Permite, adicionando uma anotação ao código, gravar vídeo. Pude gravar um
vídeo desse teste, assisti-lo em câmera lenta e isso finalmente esclareceu a situação que eu não conseguia resolver por vários meses antes do vídeo.

A barra de progresso bloqueou o botão por uma fração de segundo e o clique funcionou exatamente naquele momento e atingiu essa barra de progresso. Ou seja, a barra de progresso clicou e desapareceu! E não será visível em nenhuma captura de tela, em nenhum log, você nunca saberá o que aconteceu.
Em princípio, isso é, de certa forma, um bug do aplicativo: uma barra de progresso apareceu porque o aplicativo realmente sai da borda da tela e, se você rolar, são muitos dados úteis. Mas os usuários não se queixaram disso, porque tudo se encaixava na tela grande, não se encaixava apenas na tela pequena.
Exemplo 6: por que o Chrome congela?
Uma investigação de detetive de dois anos é um caso absolutamente real. A situação é a seguinte: nossos testes muitas vezes eram escassos e caíam, e nos rastros da pilha ficou claro que o Chrome congela: não o nosso teste, ou seja, o Chrome. Nos logs, era visível "A construção está executando 36 horas ..." Eles começaram a remover despejos de encadeamentos e rastreamentos de pilha - eles mostram que está tudo bem nos testes, a chamada para o Chromedriver trava e, como regra, no momento do fechamento (chamamos o método close, e esse método não faz nada, demora 36 horas). Se interessante, o rastreamento da pilha ficou assim:

Tentamos fazer tudo o que só poderia vir à mente:
- Configure o tempo limite para abrir / fechar o navegador (se você não conseguir abrir / fechar o navegador em 15 segundos, tente novamente após 15 segundos, até três tentativas). Abra e feche o navegador em um thread separado. Resultado: as três tentativas foram suspensas da mesma maneira.
- Mate processos antigos do Chrome. Eles criaram um trabalho separado no 'kill-chrome' de Jenkins, por exemplo, assim, você pode "matar" todos os processos anteriores a uma hora:
killall --older-than 1h cromedriver
killall - mais de 1h de cromo
Isso pelo menos liberou memória, mas não deu uma resposta para a pergunta "o que está acontecendo?". De fato, isso só nos atrasou no momento da decisão. - Habilite os logs do aplicativo de depuração.
- Habilite os logs de depuração do WebDriver.
- Reabra o navegador após cada 20 testes. Pode parecer ridículo, mas o pensamento era: "E se o Chrome congelar porque está cansado?" Bem, um vazamento de memória ou outra coisa.
O resultado da última tentativa foi completamente inesperado: o problema começou a se repetir com mais frequência! Esperávamos que isso ajudasse a estabilizar o Chrome para que funcionasse melhor. Geralmente, esse é um argumento do cérebro. Mas, de fato, quando o problema começa a se repetir com mais frequência, não se deve ficar triste, mas se alegrar! Isso torna possível estudá-lo melhor. Se ela começar a repetir com mais frequência, deve-se apegar a ela: "Sim, sim, agora vou adicionar outra coisa, logs, pontos de interrupção ..."
Estamos tentando repetir o problema: escrevemos um ciclo de 1 a 1000, no ciclo simplesmente abrimos o navegador e fechamos a primeira página em nosso aplicativo. Nós escrevemos esse ciclo, e ... bingo! Resultado: o problema começou a se repetir de forma estável (embora aproximadamente a cada 80 iterações)! Legal! É verdade que essa conquista não deu nada por um longo tempo. Você iniciou, esperou a 80ª iteração, o Chrome travou ... e depois o que fazer? Você olha para rastreamentos de pilha, lixões, logs - não há nada útil lá. As Ferramentas do desenvolvedor no Chrome podem ajudar, mas até setembro de 2017 essas ferramentas não funcionavam com o Selenium (as portas estavam em conflito: você inicia o Chrome a partir do Selenium e o DevTools não abre). Durante muito tempo, não consegui pensar no que fazer.
E aqui nesta história começa um momento fabuloso. Depois que, depois de um número infinito de tentativas, executei esses testes novamente, ele travou novamente em algum tipo de iteração como a 56. Acho que “vamos cavar outra coisa” (embora eu não saiba mais onde colocar o ponto de interrupção ou o que adicione um log). Neste momento, minha filha se oferece para jogar cubos, mas meu teste fica parado aqui. Eu digo: "Espere", ela me disse: "O que você não entende, eu tenho
um b e um aqui!"
O que fazer, infelizmente saiu do computador, foi jogar cubos ... E de repente, depois de cerca de 20 minutos, acidentalmente olho para a tela e vejo uma imagem completamente inesperada:

O que acontece: há uma contagem regressiva, após quantos minutos a sessão expira, e eu construo uma torre de cubos, há dois, um ... a sessão expira, o teste continua, corre até o fim e cai (não há mais nenhum elemento, a sessão expirou).
O que acontece: o Chrome realmente não congelou, como pensávamos durante todo esse tempo, estava esperando por algo o tempo todo. Quando a sessão expirou, esperou, continuou. O que exatamente o Chrome esperava - é completamente incompreensível entender isso, eu tive que vasculhar todo o código usando o método de pesquisa binária: jogar metade do JavaScript e HTML, tentar repetir 80 iterações novamente - não travou, oh, isso significa algum lugar lá fora ... Em geral, entendemos experimentalmente que o problema está aqui:
var timeout = setTimeout(sessionWatcher);
JavaScript — , , . , JavaScript- , : , <script> . , , , , . JavaScript — jQuery, $, function , :
var timeout; $(function() { timeout = setTimeout(...); });
-, , , . , . 1000 , .
, : , , , . , Chrome, . , .
, flaky- , , , . , — , , ( ). , . , : ?
Chrome flaky-: -, , , .
UI- : , . click(), , . , , : click() , . - , ? :)
. , , , . , , , , Docker.
, - , . :
- Ajax-;
- Ajax-;
- JS;
- ;
- ;
- ;
- ;
- ;
- UI-;
- ( ).
flaky- , . , -, : , .
. «» . , flaky- , ID, flaky- . .
, : , , .
, flaky- usability, -, flaky- . .
, , … , , , flaky- security-, . , !
, , flaky-:
— . flaky- , unit- , UI-? , ( ), , flaky.
Selenide .
. (, / ). , « ?». , , .
, .
, . , , , , . : « », , (10 , 20 , — , — ). , flaky - .
, flaky- :
- ;
- ;
- Vídeo
« » , , , : - . «», «» , : flaky-, , flaky. , , . . , Jenkins pipeline, Jenkins :
finally { stage("Reports") { junit 'build/test-results/**/*.xml' artifacts = 'build./reports/**/*,build/test-results/**/*,logs/**/*' archiveArtifacts artifacts: artifacts } }
finally , . : - - . Jenkins , . , Jenkins , . , .
(Selenide , ). flaky-. ,
Video Recorder , :
video — , !
, Docker: TestContainers ( Heisenbug
).
Rule , — Docker , , . .
@Rule public BrowserWebDriverContainer chrome = new BrowserWebDriverContainer() .withRecordingMode(RECORD_ALL, new File("build")) .withDesiredCapabilities(chrome());
.
. , , , , , . flaky- .
, ! , :) . , « , , », , .
— , , , , - . — , … ! :) flaky- — : !
, : 6-7 Heisenbug . , , . (, , ) .