
A
fase de qualificação do DataScienceGame2018, que ocorreu no formato kaggle InClass, terminou recentemente.
DataScienceGame é uma competição internacional de estudantes realizada anualmente. Nossa equipe conseguiu ficar em 3º lugar entre mais de 100 equipes e, ao mesmo tempo, NÃO chega à fase final.
Interação da equipe

Em grandes competições de kaggle, as equipes geralmente são formadas ao longo do caminho por pessoas com uma liderança quase na tabela de líderes (um
exemplo típico de equipe ) e, portanto, representam diferentes cidades e, freqüentemente, diferentes países. Imediatamente, de acordo com os termos da competição, cada equipe deve ser composta por 4 pessoas de uma instituição de ensino (representamos o MIPT). E isso significa que a maioria dos participantes, ao que me parece, todas as discussões ocorreram offline. Por exemplo, tínhamos a equipe inteira morando em um andar do albergue, então apenas nos reuníamos à noite com alguém na sala.
Não tivemos separação de tarefas, planejamento ou formação de equipes. No início da competição, apenas nos sentamos em círculo, discutimos o que podemos fazer no futuro e não o fizemos. O código foi escrito por uma pessoa, e o restante na época simplesmente olhou e deu conselhos. Não gosto muito de escrever código, então gostei dessa interação, apesar de obviamente não ser a melhor. Mas como a fase de qualificação caiu exatamente na sessão da universidade, parte da equipe não conseguiu dedicar muito tempo e eu ainda tinha que escrever o código.
Descrição da tarefa
De acordo com o histórico fornecido pelo BNP, era necessário prever se o usuário estaria interessado em alguma segurança (Isin) na próxima semana ou não. Ao mesmo tempo, “interesse” foi determinado pela coluna TradeStatus, que descreveu o status da transação e possuía os seguintes valores exclusivos:
- A transação foi concluída (ou seja, o usuário comprou / vendeu papel)
- O usuário olhou para o documento, mas não concluiu uma transação
- Usuário reservou papel para compra / venda futura
- A transação não foi concluída devido a razões técnicas.
- Segurando
Portanto, se TradeStatus assume o valor 1) -4), considera-se que o usuário estava interessado neste documento e não estava interessado em todos os outros casos. Ao mesmo tempo, o parágrafo 4) indicou que a linha com esta transação era fictícia e foi feita para relatórios convenientes. Ou seja, no final de cada mês, o status do portfólio de cada usuário foi comparado com o seu estado há um mês e, se, por exemplo, o usuário de alguma forma no portfólio, a quantidade de uma determinada segurança aumentou em 10k, então essa mesma linha marcou "compra" ”E com um valor nominal de 10k. As linhas marcadas como "mantendo" tinham uma variável de destino 0 (o usuário não estava interessado).
Se você pensar bem, pode entender que o conjunto de dados estava da seguinte forma: os usuários estavam ativos no site do banco - procuraram / compraram papéis e todas essas ações foram registradas no banco de dados. Por exemplo, um usuário com id = 15 decidiu adiar papel com id = 7 para compras futuras. Imediatamente no banco de dados apareceu a linha correspondente ao alvo 1 (o usuário ficou interessado)
| ID do usuário | ID de segurança | Tipo de transação | Status da transação | Campos adicionais | Target |
|---|
| 15 | 7 | Compra | Separe para o futuro | ... | 1 |
Além disso, foram adicionados registros mensais com o status de retenção e o objetivo 0. Por exemplo, o usuário 15 aumentou o número de compartilhamentos 93 por algum motivo (talvez ele tenha comprado em outro site), enquanto ele próprio não usou este documento no site do BNP interagiu (não está interessado).
| ID do usuário | ID de segurança | Tipo de transação | Status da transação | Campos adicionais | Target |
|---|
| 15 | 93 | Compra | Segurando | ... | 0 0 |
Mas, obviamente, para o BNP, não há sentido em prever essas mesmas propriedades, porque elas podem ser restauradas sem ambiguidade a partir da base. Isso significa que há outro tipo de tokens que não estão na tabela de treinamento, ou seja, triplica o “usuário - papel - tipo de transação” que não aparece no banco de dados. Ou seja, o usuário NÃO estava interessado em uma determinada ação, o que significa que ele não interage com ele no sistema BNP; portanto, a linha correspondente não aparece no banco de dados, o que significa que deve ter um objetivo de 0. E isso sugere que você precisa gerar essas linhas para se treinar ( consulte a seção “Compilando uma amostra de treinamento”). Tudo isso pode levar a alguma confusão, porque muitos participantes provavelmente pensaram - existe um conjunto de dados, existem zeros e uns - você pode prever. Mas não é tão simples.
Portanto, no trem, há uma tabela com o histórico de transações (ou seja, a interação “usuário - papel - tipo de transação” e algumas informações adicionais sobre elas) e várias outras placas com as características do usuário, estoque, condições do mercado global. No teste, existem apenas triplos "usuário - papel - tipo de transação" e, para cada um desses triplos, é necessário prever se ele será exibido na próxima semana. Por exemplo, você precisa prever se o ID do usuário = 8 estará interessado no ID da ação = 46 com o tipo de transação "venda"?
| ID do usuário | ID de segurança | Tipo de transação | Target |
|---|
| 8 | 46. | Para venda | ? |
Recursos de construção de um conjunto de dados
Como, como eu já disse, no banco de dados real do BNP não havia linhas com zeros "não retidos", os organizadores de alguma forma geraram essas linhas para o teste. E onde há geração artificial de dados, geralmente há rostos e outras informações implícitas que podem melhorar significativamente o resultado sem alterar os modelos / recursos. Esta seção descreve alguns recursos da criação de um conjunto de dados que conseguimos entender, mas que, infelizmente, não nos ajudaram de forma alguma.

Se você observar o "usuário - papel - tipo de transação" triplica na tabela de teste, é fácil notar que o número de transações com os tipos "compra" e "venda" é exatamente o mesmo, e a tabela é estritamente classificada por este atributo: primeiro todas as compras, depois todas vendas. Obviamente, isso não é um acidente e surge a pergunta: como isso pôde acontecer? Por exemplo, desta maneira: os organizadores pegaram todos os registros reais de seu banco de dados durante a semana em que precisamos fazer uma previsão (essas linhas têm um objetivo de 1), de alguma forma geraram novas linhas (seu objetivo é 0), que não coincidem com os descritos acima. Então, saiu uma tabela na qual os tipos de transações (compra / venda) são organizados em ordem aleatória:
| ID do usuário | ID de segurança | Tipo de transação | Target |
|---|
| 8 | 46. | Para venda | 1 |
| 2 | 6 | Compra | 1 |
| 158 | 73 | Compra | 1 |
| 3 | 29 | Para venda | 0 0 |
| 67 | 9 | Compra | 0 0 |
| 17 | 465 | Para venda | 0 0 |
Agora é possível definir o tipo de compra para todas as linhas com o tipo de transação “venda” e, se o destino for um, ele se tornará zero (na maioria dos casos, o usuário estava interessado em algum papel com apenas um status: compra ou venda). Isso resultará na seguinte tabela:
| ID do usuário | ID de segurança | Tipo de transação | Target |
|---|
| 8 | 46. | Compra | 0 0 |
| 2 | 6 | Compra | 1 |
| 158 | 73 | Compra | 1 |
| 3 | 29 | Compra | 0 0 |
| 67 | 9 | Compra | 0 0 |
| 17 | 465 | Compra | 0 0 |
A última etapa permanece: fazer o mesmo, mas substituindo a "compra para venda" e organizando as metas corretas:
| ID do usuário | ID de segurança | Tipo de transação | Target |
|---|
| 8 | 46. | Para venda | 1 |
| 2 | 6 | Para venda | 0 0 |
| 158 | 73 | Para venda | 0 0 |
| 3 | 29 | Para venda | 0 0 |
| 67 | 9 | Para venda | 0 0 |
| 17 | 465 | Para venda | 0 0 |
Concatenando a tabela com "compras" e a tabela com "vendas", obtemos (se éramos os organizadores) uma tabela como nos foi dada no teste. É fácil entender que a primeira e a segunda metade das tabelas construídas dessa maneira têm a mesma ordem de pares de papel do usuário, o que realmente aconteceu na tabela de teste.
Outro recurso foi o fato de existirem muitas linhas no conjunto de dados de treinamento, nas quais o índice do usuário foi repetido várias vezes seguidas, apesar do fato de o conjunto de dados não ter sido classificado por nenhum dos sinais:
| ID do usuário | ID de segurança | Tipo de transação | Target |
|---|
| 8 | 46. | Para venda | ? |
| 8 | 152 | Para venda | ? |
| 8 | 73 | Compra | ? |
O colega de equipe considerou isso normal e o conjunto de dados foi classificado inicialmente pelo ID do usuário, e os organizadores simplesmente estragaram tudo (por exemplo, se o shuffle foi organizado em permutações aleatórias e não havia permutações suficientes). Tentando se certificar disso, ele passou por quatro embaralhamento de diferentes bibliotecas, mas em nenhum lugar essas repetições freqüentes surgiram. O teste também teve esse recurso. Havia uma idéia de que os organizadores não geravam zeros, mas simplesmente pegavam os pares antigos do trem. Para verificar, decidi fazer o seguinte: para cada par “papel do usuário” do teste, compare o número da linha do trem quando esse par se encontrou pela primeira vez e faça um gráfico disso. Ou seja, por exemplo, olhamos para a primeira linha do teste, deixe que ela tenha um ID de usuário = 8 e id = paper = 15. Agora, examinamos a tabela de treinamento de cima para baixo e procuramos quando esse par apareceu pela primeira vez, como, por exemplo, 51ª linha. Fizemos uma comparação: a 1ª linha do teste estava no 51º trem, portanto, traçamos o ponto com as coordenadas (1, 51) no gráfico. Fazemos isso durante todo o teste e obtemos o seguinte gráfico:
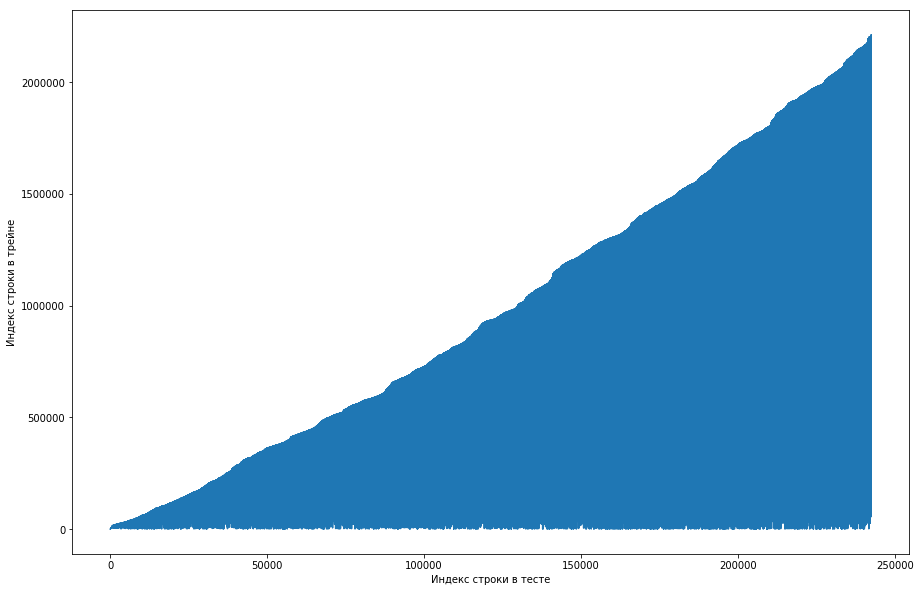
Pode-se ver a partir disso que, basicamente, se um casal já havia se encontrado antes no trem, na tabela de teste sua posição será maior. Mas, ao mesmo tempo, existem alguns valores discrepantes no gráfico (na verdade não existem tantos, mas devido à resolução das telas, parece que existe um triângulo sólido). Além disso, o número de emissões coincidiu aproximadamente com o número esperado de unidades no teste. Obviamente, tentamos marcar as emissões como unidades e enviá-las para a tabela de classificação, mas, infelizmente, não funcionou. Mas ainda me pareceu que poderia haver algum tipo de rosto () e, como capitão da equipe, sugeri que dedicasse mais tempo a entender como isso poderia acontecer, e ainda temos tempo para treinar os modelos e gerar os sinais. Isenção de responsabilidade: passamos muito tempo nisso, mas uma semana antes do final da competição, os organizadores escreveram no fórum que apenas triplos nos últimos 6 meses foram levados para o conjunto de dados de teste, e não todos. Bem, se você executar as operações descritas acima, mas nos últimos 6 meses, e não apenas o conjunto de dados, obterá uma curva monótona plana:
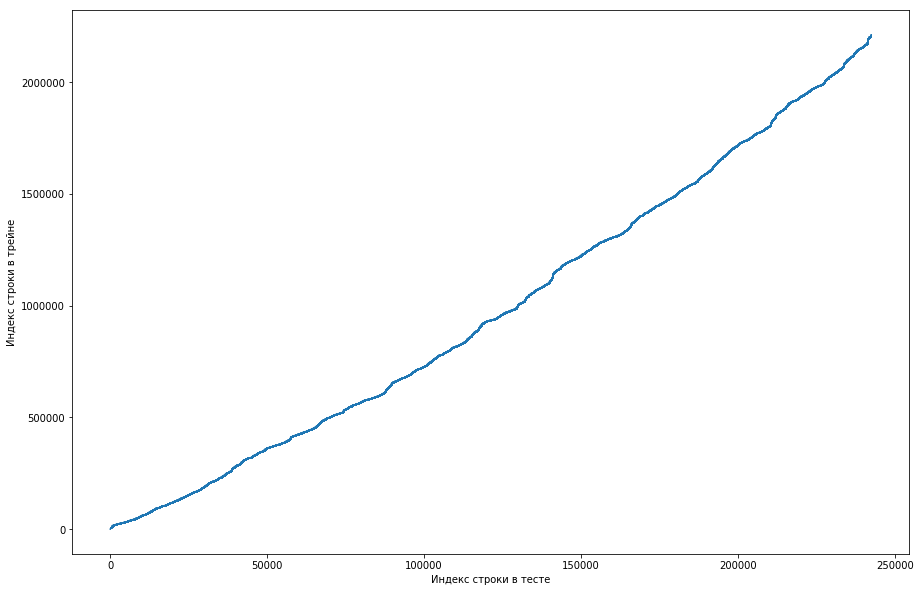
E isso significa que não há rosto aqui e não pode existir.
Configuração de treinamento
Como no teste você precisa fazer uma previsão de triplos por uma semana, dividiremos o conjunto de dados de treinamento em semanas (ao mesmo tempo, a cada semana há uma média de 20 mil triplos de "usuário - papel - tipo de transação"). Agora, para três, podemos dizer se ela se conheceu em uma semana específica ou não. Ao mesmo tempo, já temos triplos positivos (todas essas entradas são desta semana na tabela de trens) e as negativas precisam ser geradas de alguma forma. Existem muitas opções de como fazer isso. Por exemplo, você pode resolver absolutamente todos os triplos que não estavam lá por uma semana específica no conjunto de dados de treinamento. É claro que a amostra ficará altamente desequilibrada, e isso é ruim. Você pode primeiro gerar usuários proporcionalmente à frequência de sua ocorrência no conjunto de dados e, de alguma forma, adicionar promoções a eles. Mas com essa abordagem, haverá várias linhas para as quais estatísticas razoáveis não podem ser calculadas, o que também é ruim. Como fizemos: pegamos todos os tipos de triplos encontrados anteriormente no trem, copiámo-lo, substituindo o buy / sell pelo oposto, e concatenamos essas duas tabelas. É claro que duplicatas poderiam ter ocorrido dessa maneira (por exemplo, se o usuário já tivesse comprado e vendido um estoque), mas havia poucos deles e, após a exclusão, uma tabela de 500 mil triplos únicos foi obtida. Isso é tudo, agora, a cada semana, para cada triplo, você pode dizer se ela se encontrou ou não (e quantas vezes?).
Como, em essência, estamos lidando com séries temporais - um usuário vê um anúncio específico várias vezes por semana, criaremos uma tabela para treinar o classificador de maneira clássica para séries temporais. Nomeadamente, pegaremos a última semana disponível do trem, veremos se cada três “clientes - compram ou vendem” se reuniu nesta semana. Será um alvo. E contaremos várias estatísticas como recursos, por exemplo, nas últimas 6 semanas (mais sobre estatísticas na seção "Sinais"). Agora vamos esquecer a existência da última semana e fazer o mesmo, mas para a penúltima semana e concatenar as tabelas. Isso pode ser feito várias vezes, aumentando assim o trem de “altura”, mas, ao mesmo tempo, o intervalo sobre o qual consideramos estatísticas diminui naturalmente. Repetimos essa operação 10 vezes, porque, se fizéssemos mais, o feriado de Ano Novo e os problemas relacionados seriam direcionados, o que pioraria a qualidade final do modelo. Imagem explicativa:
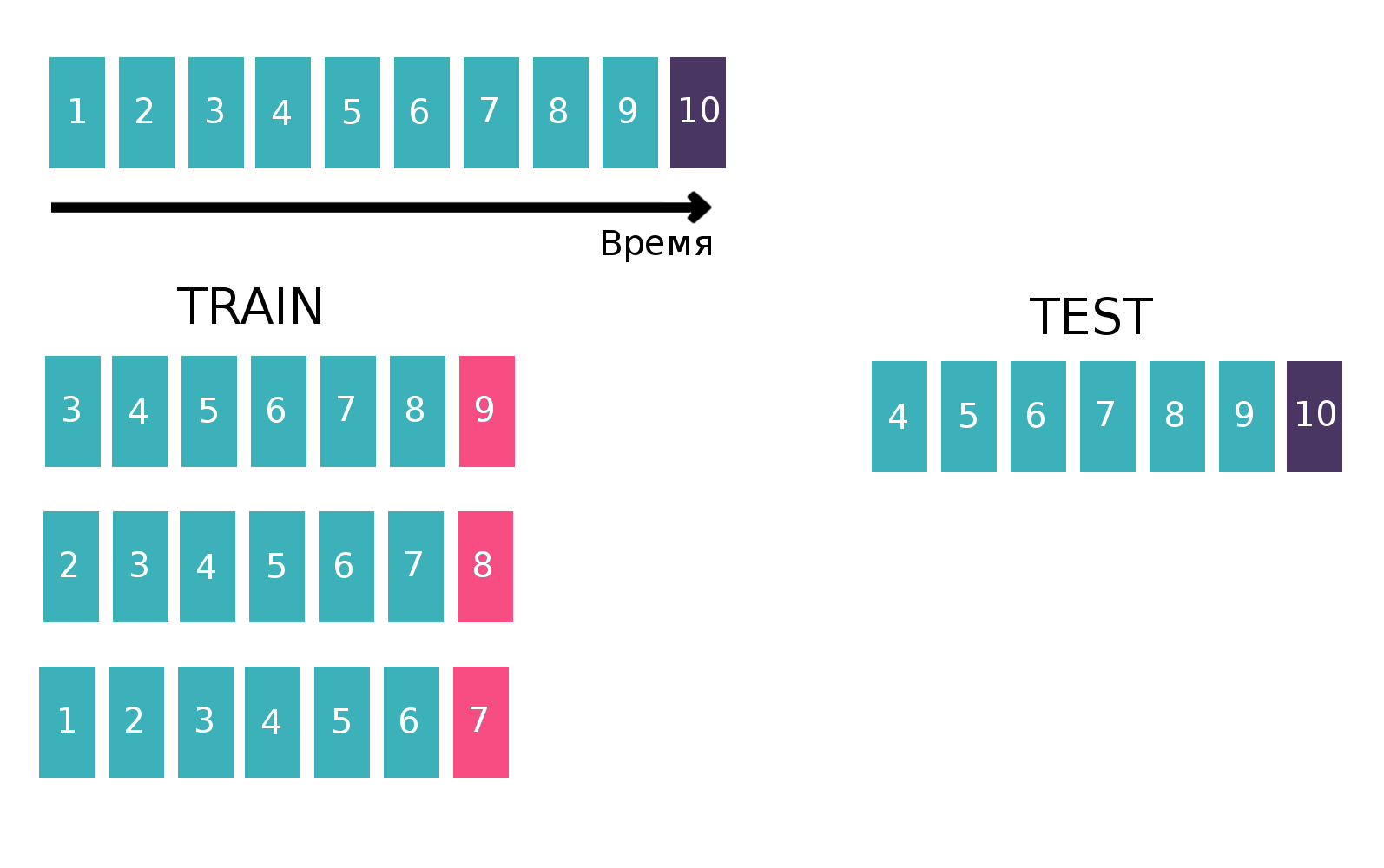
Mais informações sobre séries temporais e validação em séries temporais podem ser encontradas
aqui .
Sinais
Como eu disse, havia muitas tabelas que de alguma forma caracterizavam o usuário, as ações ou as condições do mercado global (principais moedas e alguns indicadores). Mas todos eles quase não melhoraram a qualidade, e os principais sinais foram estatísticas calculadas para os pares "cliente - isin" e tripla "cliente - isin - compre ou venda", por exemplo:
- Com que frequência um casal / três se encontrou nas últimas 1, 2, 5, 20, 100 semanas?
- Estatísticas sobre intervalos de tempo entre reuniões de um par / triplos em um conjunto de dados (média, padrão, max, min)
- A distância no tempo até a primeira / última vez que um casal / três se encontrou
- A proporção de cada valor TradeStatus para um par / triplo
- Estatísticas de quantas vezes por semana ocorre um casal / triplo (média, padrão, máximo, min)
Além disso, no último dia da competição, li no formulário que, para vender uma ação, você deve primeiro comprá-la. Esse conhecimento permite que você crie muitos sinais mais úteis, mas, por alguma razão, para mim não era óbvio.
No código, tudo isso foi expresso por uma função de 200 linhas de comprimento, que gerou sinais semelhantes para cada um dos dez trens (para a parte em que o alvo, por exemplo, semana 7, não devemos usar as informações para os dias 8 e 9). Considerando tabelas adicionais, foram recrutados cerca de 300 sinais. Como eu já disse, geramos 500k triplos únicos e tomamos as últimas 10 semanas como metas, portanto, a tabela de treinamento "alta" era de 500k * 10 = 5kk linhas.
Mais algumas confissões foram descritas na
decisão do segundo lugar . Os caras construíram uma tabela de usuário / papel, em que em cada célula havia uma unidade se o usuário estivesse interessado neste trabalho e zero caso contrário. Ao calcular a distância de cosseno entre usuários nesta tabela, você pode obter a convergência de usuários entre si. Se você aplicar o PCA à tabela de similaridade resultante, obterá um conjunto de recursos que caracterizam o usuário de alguma forma.
Modelos ou brigar por milésimos
Vale a pena notar que por quase três semanas ninguém conseguiu superar a linha de base do BNP, que tinha uma velocidade de 0,794 (ROC AUC) na tabela de classificação, e isso apesar do fato de que a decisão de “simplesmente contar o número de vezes que o casal se conheceu antes” deu 0,71 na tabela de classificação, e alguns os participantes receberam todos os 0,74 sem o uso de aprendizado de máquina.
Além disso, no aprendizado da máquina, no último dia da competição (que coincidentemente coincidiu com o final da sessão), decidimos parar
se você entende o que quero dizer e fazer uma grande mistura de modelos diferentes treinados em diferentes subconjuntos de sinais com diferentes números de semanas em Train. Como eu já disse, nossa amostra de treinamento consistiu em 1.5k linhas, com uma meta entre elas cerca de 150k. O tamanho do teste foi de 400k, enquanto o número estimado de unidades foi de 20k (em média, de fato, existem tantos triplos únicos). Ou seja, a proporção de unidades no teste foi significativamente maior do que no trem. Portanto, em todos os nossos modelos, ajustamos o parâmetro scale_pos_weight, que atribui o peso às classes. Mais informações sobre esse parâmetro podem ser encontradas na
análise da melhor solução de um dos DataScienceGame do ano passado. A matriz de correlação das previsões de nossos modelos é mostrada na figura:
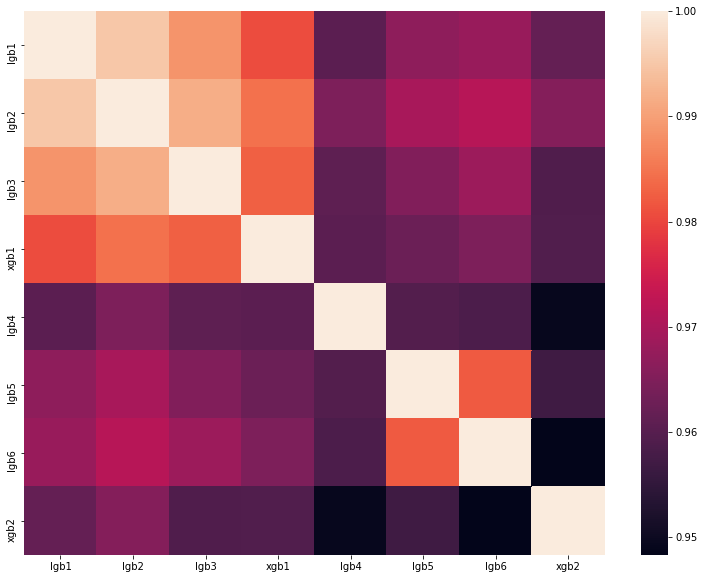
Como você pode ver, tínhamos muitos modelos diferentes, o que nos permitiu obter 0,80204 de velocidade na tabela de classificação.
Por que não vamos à França para a fase final
Como resultado, mostramos um bom resultado e ocupamos o terceiro lugar no ranking da tabela de classificação. Mas os organizadores estabelecem as seguintes regras para a seleção dos finalistas:
- Não mais que 20 melhores equipes
- Não mais do que 5 melhores times do país
- Não mais que 1 equipe de uma instituição educacional
E tudo ficaria bem se outra equipe do Instituto de Física e Tecnologia de Moscou, com a velocidade de 0,80272, não estivesse em segundo lugar. Ou seja, estamos apenas 0,00068 atrasados. É uma pena, mas não há nada a ser feito. Provavelmente, os organizadores fizeram essas regras para que as pessoas de uma universidade não se ajudassem de maneira alguma, mas, no nosso caso, não sabíamos nada sobre a equipe vizinha e não a contatamos de forma alguma.
Sumário
Este ano, em setembro, em Paris, cinco equipes da Rússia, uma da Ucrânia e duas da Alemanha e Finlândia, compostas por estudantes de língua russa, competirão pelo primeiro lugar. Um total de 8 equipes da ru-community, que mais uma vez comprovam o domínio do ru-segmento de data data. E estou sendo
transferido para Sharaga, treino e trabalho comigo mesmo, para que no próximo ano ainda possa superar a fase de qualificação.