Este artigo não abordará os conceitos básicos do hibernate (como definir uma entidade ou consultar critérios de gravação). Aqui vou tentar falar sobre pontos mais interessantes que são realmente úteis no trabalho. Informações sobre as quais não conheci em um só lugar.

Farei uma reserva imediatamente. Tudo o que se segue é verdadeiro no Hibernate 5.2. Erros também são possíveis devido ao fato de eu ter entendido algo errado. Se você encontrar - escreva.
Problemas ao mapear um modelo de objeto em um relacional
Mas vamos começar com o básico do ORM. ORM - mapeamento objeto-relacional - nesse sentido, temos modelos relacionais e de objetos. E ao exibir um ao outro, há problemas que precisamos resolver sozinhos. Vamos separá-los.
Para ilustrar, vamos dar o seguinte exemplo: temos a entidade "Usuário", que pode ser um Jedi ou uma aeronave de ataque. Os Jedi devem ter força e especialização em aeronaves de ataque. Abaixo está um diagrama de classes.
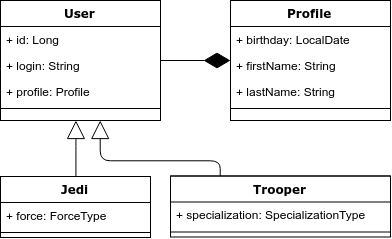
Problema 1. Herança e consultas polimórficas.
Há herança no modelo de objeto, mas não no modelo relacional. Consequentemente, este é o primeiro problema - como mapear corretamente a herança para o modelo relacional.
O Hibernate oferece 3 opções para exibir esse modelo de objeto:
- Todos os herdeiros estão na mesma tabela:
@ Herança (estratégia = InheritanceType.SINGLE_TABLE)

Nesse caso, os campos comuns e os campos dos herdeiros estão em uma tabela. Usando essa estratégia, evitamos junções ao selecionar entidades. Das desvantagens, vale ressaltar que, em primeiro lugar, não podemos definir a restrição “NOT NULL” para a coluna “force” no modelo relacional e, em segundo lugar, perdemos a terceira forma normal. (uma dependência transitiva de atributos não chave aparece: força e disco).
A propósito, inclusive por esse motivo, existem 2 maneiras de especificar uma restrição de campo não nula - NotNull é responsável pela validação; @Column (nullable = true) - responsável pela restrição não nula no banco de dados.
Na minha opinião, esta é a melhor maneira de mapear um modelo de objeto para um modelo relacional.
- Os campos específicos da entidade estão em uma tabela separada.
@ Herança (estratégia = InheritanceType.JOINED)
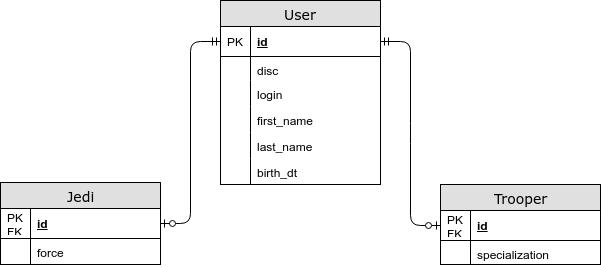
Nesse caso, os campos comuns são armazenados em uma tabela comum e os específicos para entidades filho são armazenados em campos separados. Usando essa estratégia, obtemos um JOIN ao escolher uma entidade, mas agora salvamos o terceiro formulário normal e também podemos especificar uma restrição NOT NULL no banco de dados. - Cada entidade tem sua própria tabela.
@ InheritanceType.TABLE_PER_CLASS
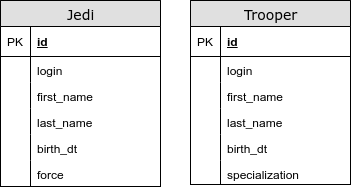
Nesse caso, não temos uma tabela comum. Usando essa estratégia, usamos UNION para consultas polimórficas. Estamos tendo problemas com geradores de chave primária e outras restrições de integridade. Esse tipo de mapeamento de herança é fortemente desencorajado.
Só para mencionar a anotação - @MappedSuperclass. É usado quando você deseja "ocultar" campos comuns para várias entidades do modelo de objeto. Além disso, a própria classe anotada não é considerada uma entidade separada.
Problema 2. Taxa de composição no POO
Voltando ao nosso exemplo, observamos que no modelo de objeto levamos o perfil do usuário para uma entidade separada - Profile. Mas no modelo relacional, não selecionamos uma tabela separada para ele.
A atitude do OneToOne geralmente é uma prática ruim porque em select, temos um JOIN injustificado (mesmo especificando fetchType = LAZY na maioria dos casos, teremos JOIN - discutiremos esse problema mais tarde).
Existem anotações @Embedable e @Embeded para exibir uma composição em uma tabela comum. O primeiro é colocado acima do campo e o segundo acima da classe. Eles são intercambiáveis.
Gerente de Entidade
Cada instância do EntityManager (EM) define uma sessão de interação com o banco de dados. Dentro de uma instância EM, há um cache de primeiro nível. Aqui vou destacar os seguintes pontos significativos:
- Capturando a conexão com o banco de dados
Este é apenas um ponto interessante. O Hibernate não captura o Connection no momento de receber o EM, mas no primeiro acesso ao banco de dados ou na abertura da transação (embora esse problema possa ser resolvido ). Isso é feito para reduzir o tempo de conexão ocupada. Durante o recebimento do EM-a, a presença de uma transação JTA é verificada. - Entidades persistidas sempre têm id
- As entidades que descrevem uma linha no banco de dados são equivalentes por referência
Como mencionado acima, o EM tem um cache de primeiro nível, os objetos nele são comparados por referência. Assim, surge a pergunta - quais campos devem ser usados para substituir iguais e hashcode? Considere as seguintes opções:
- Como funciona a descarga
Liberar - executa inserções, atualizações e exclusões acumuladas no banco de dados. Por padrão, o flush é executado nos casos:
- Antes de executar a consulta (com exceção do em.get), isso é necessário para cumprir o princípio do ACID. Por exemplo: alteramos a data de nascimento da aeronave de ataque e, em seguida, desejamos obter o número de aeronaves de ataque adultas.
Se estivermos falando sobre CriteriaQuery ou JPQL, a liberação será executada se a consulta afetar uma tabela cujas entidades estão no cache do primeiro nível. - Ao cometer uma transação;
- Às vezes, quando persistimos em uma nova entidade - no caso em que podemos obter seu ID apenas através da inserção.
E agora um pequeno teste. Quantas operações UPDATE serão executadas neste caso?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Um recurso interessante de hibernação está oculto sob a operação de liberação - ele está tentando reduzir o tempo necessário para bloquear linhas no banco de dados.
Observe também que existem estratégias diferentes para a operação de descarga. Por exemplo, você pode proibir alterações "mescladas" no banco de dados - ele é chamado MANUAL (também desativa o mecanismo de verificação suja).
- Verificação suja
Dirty Checking é um mecanismo executado durante uma operação de descarga. Seu objetivo é encontrar entidades que foram alteradas e atualizá-las. Para implementar esse mecanismo, o hibernate deve armazenar a cópia original do objeto (com a qual o objeto real será comparado). Para ser mais preciso, o hibernate armazena uma cópia dos campos do objeto, não do próprio objeto.
Vale ressaltar que, se o gráfico de entidades for grande, a operação de verificação suja pode ser cara. Não esqueça que o hibernate armazena 2 cópias de entidades (grosso modo).
Para "reduzir o custo" desse processo, use os seguintes recursos:
- em.detach / em.clear - desanexa entidades do EntityManager
- FlushMode = MANUAL - útil em operações de leitura
- Imutável - também evita operações de verificação sujas
- Transações
Como você sabe, o hibernate permite atualizar entidades apenas dentro de uma transação. As operações de leitura oferecem mais liberdade - podemos executá-las sem abrir explicitamente uma transação. Mas esta é precisamente a questão: vale a pena abrir explicitamente uma transação para operações de leitura?
Vou citar alguns fatos:
- Qualquer instrução é executada no banco de dados dentro da transação. Mesmo se obviamente não o abríssemos. (modo de confirmação automática).
- Como regra, não estamos limitados a uma consulta no banco de dados. Por exemplo: para obter os 10 primeiros registros, você provavelmente deseja retornar o número total de registros. E isso é quase sempre 2 solicitações.
- Se estamos falando de dados de primavera, os métodos do repositório são transacionais por padrão , enquanto os métodos de leitura são somente leitura.
- A anotação @Transactional spring (readOnly = true) também afeta o FlushMode, mais precisamente, o Spring o coloca no status MANUAL, portanto, o hibernate não realiza a verificação suja.
- Testes sintéticos com uma ou duas consultas ao banco de dados mostram que a confirmação automática é mais rápida. Mas no modo de combate, pode não ser assim. ( excelente artigo sobre este assunto , + ver comentários)
Em poucas palavras: é uma boa prática realizar qualquer comunicação com o banco de dados em uma transação.
Geradores
Os geradores são necessários para descrever como as chaves primárias de nossas entidades receberão valores. Vamos analisar rapidamente as opções:
- GenerationType.AUTO - a seleção do gerador é baseada no dialeto. Não é a melhor opção, pois a regra "explícito é melhor que o implícito" se aplica aqui.
- GenerationType.IDENTITY é a maneira mais fácil de configurar um gerador. Ele se baseia na coluna de incremento automático na tabela. Portanto, para obter id com persistência, precisamos inserir. É por isso que elimina a possibilidade de persistência diferida e, portanto, lote.
- GenerationType.SEQUENCE é o caso mais conveniente quando obtemos o ID da sequência.
- GenerationType.TABLE - neste caso, o hibernate emula uma sequência através de uma tabela adicional. Não é a melhor opção, porque nessa solução, o hibernate precisa usar uma transação separada e bloquear por linha.
Vamos falar um pouco mais sobre sequência. Para aumentar a velocidade da operação, o hibernate usa diferentes algoritmos de otimização. Todos eles visam reduzir o número de conversas com o banco de dados (o número de viagens de ida e volta). Vamos dar uma olhada neles com mais detalhes:
- nenhum - sem otimizações. para cada id, puxamos a sequência.
- pooled e pooled-lo - nesse caso, nossa sequência deve aumentar em um determinado intervalo - N no banco de dados (SequenceGenerator.allocationSize). E no aplicativo, temos um determinado pool, os valores dos quais podemos atribuir a novas entidades sem acessar o banco de dados.
- hilo - para gerar um ID, o algoritmo hilo usa 2 números: hi (armazenado no banco de dados - o valor obtido da chamada de sequência) e lo (armazenado somente no aplicativo - SequenceGenerator.allocationSize). Com base nesses números, o intervalo para gerar a identificação é calculado da seguinte forma: [(hi - 1) * lo + 1, hi * lo + 1). Por razões óbvias, esse algoritmo é considerado desatualizado e não é recomendável usá-lo.
Agora vamos ver como o otimizador está selecionado. O Hibernate possui vários geradores de sequência. Estaremos interessados em 2 deles:
- SequenceHiLoGenerator é um gerador antigo que usa o otimizador de hilo. Selecionado por padrão se tivermos a propriedade hibernate.id.new_generator_mappings == false.
- SequenceStyleGenerator - usado por padrão (se a propriedade hibernate.id.new_generator_mappings == true). Este gerador suporta vários otimizadores, mas o padrão é agrupado.
Você também pode configurar a anotação do gerador @GenericGenerator.
Impasse
Vejamos um exemplo de uma situação de pseudo-código que pode levar a um impasse:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Para evitar esses problemas, o hibernate possui um mecanismo que evita conflitos desse tipo - o parâmetro hibernate.order_updates. Nesse caso, todas as atualizações serão ordenadas por ID e executadas. Também mencionarei mais uma vez que o hibernate está tentando "atrasar" a captura da conexão e a execução de insert-s e update-s.
Conjunto, Bolsa, Lista
O Hibernate possui 3 maneiras principais de apresentar a coleção de comunicação OneToMany.
- Conjunto - um conjunto não ordenado de entidades sem repetições;
- Bag - um conjunto não ordenado de entidades;
- Lista é um conjunto ordenado de entidades.
Não há classe para Bag no núcleo java que descreva essa estrutura. Portanto, todas as listas e coleções são agrupadas, a menos que você especifique uma coluna pela qual nossa coleção será classificada (anotação OrderColumn. Não deve ser confundida com SortBy). Eu recomendo não usar a anotação OrderColumn devido à má implementação (em minha opinião) dos recursos - não às consultas sql ideais, aos possíveis NULLs na planilha.
A questão surge, mas o que é melhor usar bolsa ou conjunto? Para começar, ao usar uma bolsa, os seguintes problemas são possíveis:
- Se a sua versão do hibernate for inferior a 5.0.8, haverá um erro bastante sério - HHH-5855 - ao inserir uma entidade filha, é possível duplicar (no caso de cascadType = MERGE e PERSIST);
- Se você usar bag para o relacionamento ManyToMany, o hibernate gera consultas extremamente inadequadas ao excluir uma entidade da coleção - primeiro remove todas as linhas da tabela de junção e, em seguida, executa a inserção;
- O Hibernate não pode buscar várias malas para a mesma entidade ao mesmo tempo.
No caso em que você deseja adicionar outra entidade à conexão @OneToMany, é mais rentável usar o Bag, porque não requer o carregamento de todas as entidades relacionadas para esta operação. Vamos ver um exemplo:
Referências de força
Referência é uma referência a um objeto, que decidimos adiar o carregamento. No caso do relacionamento de ManyToOne com fetchType = LAZY, obtemos essa referência. A inicialização do objeto ocorre no momento do acesso aos campos da entidade, com exceção do id (já que sabemos o valor desse campo).
Vale ressaltar que, no caso do Lazy Loading, a referência sempre se refere a uma linha existente no banco de dados. Por esse motivo, a maioria dos casos de Carregamento Preguiçoso não funciona nos relacionamentos do OneToOne - o hibernate precisa ser JOIN para verificar se a conexão existe e já existe um JOIN, e o hibernate o carrega no modelo de objeto. Se indicarmos nullable = true no OneToOne, o LazyLoad deverá funcionar.
Podemos criar nossa própria referência usando o método em.getReference. É verdade que, neste caso, não há garantia de que a referência se refira a uma linha existente no banco de dados.
Vamos dar um exemplo do uso desse link:
Só por precaução, lembro que obteremos uma LazyInitializationException no caso de um EM fechado ou um link desanexado.
Data e hora
Apesar do java 8 ter uma excelente API para trabalhar com data e hora, a API JDBC ainda permite que você trabalhe apenas com a API antiga. Portanto, analisaremos alguns pontos interessantes.
Primeiro, você precisa entender claramente as diferenças entre LocalDateTime e Instant e ZonedDateTime. (Não esticarei, mas darei excelentes artigos sobre esse assunto: o
primeiro e o
segundo )
Se brevementeLocalDateTime e LocalDate representam uma tupla regular de números. Eles não estão vinculados a um horário específico. I.e. o horário de pouso do avião não pode ser armazenado no LocalDateTime. E a data de nascimento através do LocalDate é bastante normal. Instantâneo representa um ponto no tempo, em relação ao qual podemos obter a hora local em qualquer ponto do planeta.
Um ponto mais interessante e importante é como as datas são armazenadas no banco de dados. Se tivermos o tipo TIMESTAMP WITH TIMEZONE afixado, não haverá problemas, mas se o TIMESTAMP (SEM FUSO HORÁRIO) permanecer, haverá uma chance de que a data seja escrita / lida incorretamente. (excluindo LocalDate e LocalDateTime)
Vamos ver o porquê:
Quando salvamos a data, um método com a seguinte assinatura é usado:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Como você pode ver, a API antiga é usada aqui. O argumento opcional Calendário é necessário para converter o carimbo de data / hora em uma representação de sequência. Ou seja, ele armazena o fuso horário em si. Se o Calendário não for transmitido, o Calendário será usado por padrão com o fuso horário da JVM.
Existem 3 maneiras de resolver esse problema:
- Defina o JVM de fuso horário desejado
- Use o parâmetro hibernate - hibernate.jdbc.time_zone (adicionado em 5.2) - corrigirá apenas ZonedDateTime e OffsetDateTime
- Use o tipo TIMESTAMP WITH TIMEZONE
Uma pergunta interessante, por que LocalDate e LocalDateTime não se enquadram nesse problema?
A respostaPara responder a essa pergunta, você precisa entender a estrutura da classe java.util.Date (java.sql.Date e java.sql.Timestamp, seus herdeiros e suas diferenças nesse caso não nos incomodam). Date armazena a data em milissegundos desde 1970, aproximadamente no UTC, mas o método toString converte a data de acordo com o fuso horário do sistema.
Assim, quando obtemos uma data sem um fuso horário do banco de dados, ela é mapeada para um objeto Timestamp para que o método toString exiba o valor desejado. Ao mesmo tempo, o número de milissegundos desde 1970 pode ser diferente (dependendo do fuso horário). É por isso que apenas a hora local é sempre exibida corretamente.
Também dou um exemplo do código responsável pela conversão de Timesamp em LocalDateTime e Instant:
Lote
Por padrão, as consultas são enviadas ao banco de dados, uma de cada vez. Quando o lote está ativado, o hibernate poderá enviar várias instruções em uma consulta ao banco de dados. (ou seja, o lote reduz o número de viagens de ida e volta ao banco de dados)
Para fazer isso, você deve:
- Ative o lote e defina o número máximo de instruções:
hibernate.jdbc.batch_size (5 a 30 recomendado) - Ative a classificação de inserção e atualização s:
hibernate.order_inserts
hibernate.order_updates
- Se usarmos o controle de versão, também precisamos ativar
hibernate.jdbc.batch_versioned_data - tenha cuidado aqui, você precisa do driver jdbc para poder fornecer o número de linhas afetadas durante a atualização.
Também vou lembrá-lo sobre a eficácia da operação em.clear () - ela desobstrui as entidades, liberando memória e reduzindo o tempo da operação de verificação suja.
Se usarmos o postgres, também podemos dizer hibernar para usar
a inserção multi-raw .
Problema N + 1
Este é um tópico bastante onipresente, portanto, leia-o rapidamente.
Um problema N + 1 é uma situação em que, em vez de uma única solicitação para selecionar N books, ocorrem pelo menos solicitações N + 1.
A maneira mais fácil de resolver o problema N + 1 é buscar tabelas relacionadas. Nesse caso, podemos ter vários outros problemas:
- Paginação. no caso dos relacionamentos OneToMany, o hibernate não poderá especificar deslocamento e limite. Portanto, a paginação ocorrerá na memória.
- O problema de um produto cartesiano é uma situação em que um banco de dados retorna N * M * K linhas para escolher N livros com M capítulos e K autores.
Existem outras maneiras de resolver o problema N + 1.
- FetchMode - permite alterar o algoritmo de carregamento de entidades filhas . No nosso caso, estamos interessados no seguinte:
- FetchType.SUBSELECT - Carrega registros filho em uma solicitação separada. A desvantagem é que toda a complexidade da solicitação principal é repetida na subseleção.
- BATCH (anotação FetchType.SELECT + BatchSize) - também carrega registros como uma solicitação separada, mas, juntamente com a subconsulta, cria uma condição como WHERE parent_id IN (?,?,?, ..., N)
É importante notar que, ao usar a busca na API de critérios, o FetchType é ignorado - JOIN é sempre usado - JPA EntityGraph e Hibernate FetchProfile - permitem criar regras de carregamento de entidades em uma abstração separada - na minha opinião, ambas as implementações são inconvenientes.
Teste
Idealmente, o ambiente de desenvolvimento deve fornecer o máximo de informações úteis possível sobre a operação do hibernate e sobre a interação com o banco de dados. Ou seja:
- Registo
- org.hibernate.SQL: debug
- org.hibernate.type.descriptor.sql: trace
- Estatísticas
- hibernate.generate_statistics
Dos utilitários úteis, é possível distinguir o seguinte:
- DBUnit - permite descrever o estado do banco de dados no formato XML. Às vezes é conveniente. Mas é melhor pensar novamente se você precisar.
- DataSource-proxy
- O p6spy é uma das soluções mais antigas. oferece log de consulta avançado, tempo de execução etc.
- com.vladmihalcea: db-util: 0.0.1 é um utilitário útil para encontrar problemas de N + 1. Também permite registrar consultas. A composição inclui uma anotação interessante Repetir , que tenta novamente a transação no caso de uma OptimisticLockException.
- Sniffy - permite que você faça uma declaração sobre o número de solicitações por meio da anotação. De certa forma, mais elegante que a decisão de Vlad.
Mas mais uma vez repito que isso é apenas para desenvolvimento, não deve ser incluído na produção.
Literatura