Alguns leitores podem ter ouvido falar de Centrifugo antes. Este artigo se concentrará no desenvolvimento da segunda versão do servidor e da nova biblioteca em tempo real para o idioma Go subjacente.
Meu nome é Alexander Emelin. No verão passado, entrei para a equipe do Avito, onde agora estou ajudando a desenvolver o back-end do Avito messenger. O novo trabalho, diretamente relacionado à entrega rápida de mensagens aos usuários, e os novos colegas me inspiraram a continuar trabalhando no projeto Centrifugo de código aberto.

Em poucas palavras - este é um servidor que assume a tarefa de manter conexões constantes dos usuários do seu aplicativo. O polyfill Websocket ou SockJS é usado como transporte, se não for possível estabelecer uma conexão Websocket, trabalhar através da fonte de eventos, streaming XHR, pesquisa longa e outros transportes baseados em HTTP. Os clientes se inscrevem nos canais nos quais o back-end por meio da API do Centrifuge publica novas mensagens à medida que elas surgem - após o que as mensagens são entregues aos usuários inscritos no canal. Em outras palavras, é um servidor PUB / SUB.
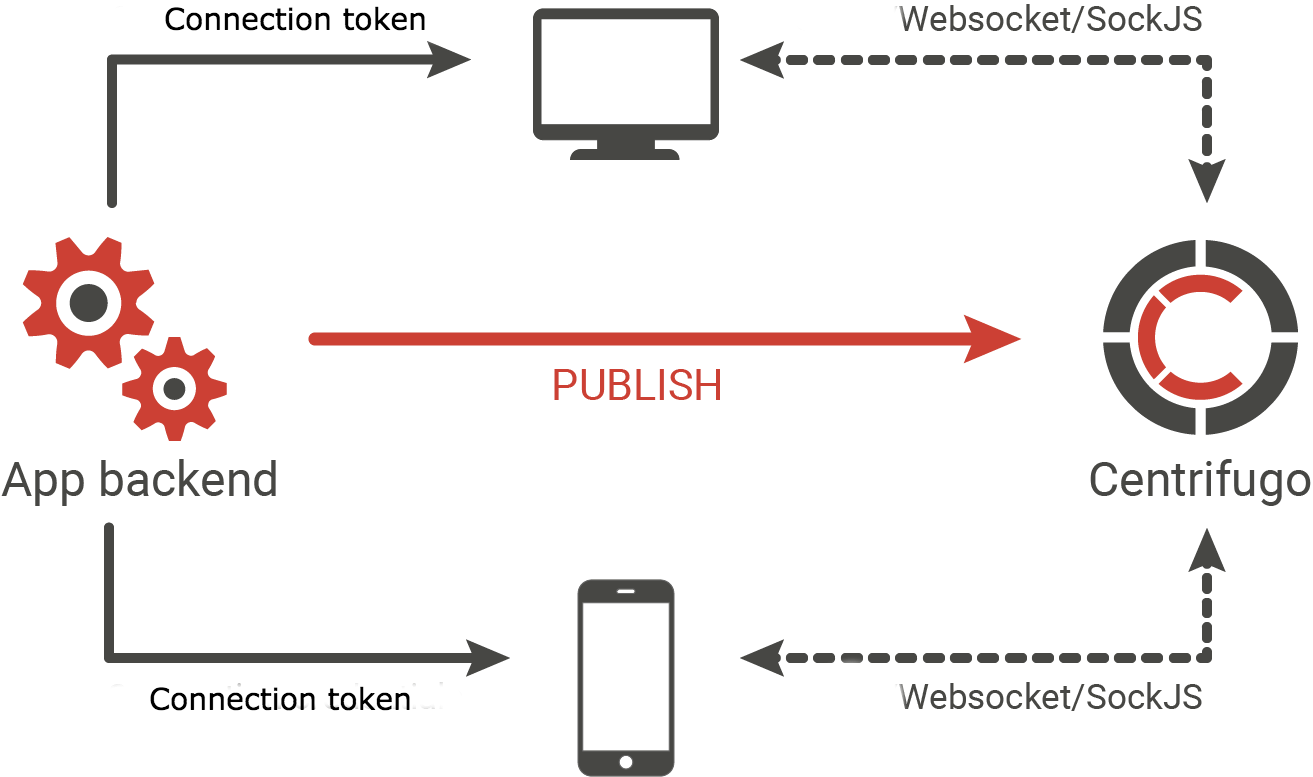
Atualmente, o servidor é usado em um número bastante grande de projetos. Entre eles, por exemplo, estão alguns projetos Mail.Ru (intranet, plataformas de treinamento Technopark / Technosphere, Centro de Certificação, etc.), com o Centrifugo, um belo painel funciona na recepção no escritório do Badoo Moscow, e 350 mil usuários estão conectados simultaneamente ao serviço spot.im para a centrífuga.
Alguns links para artigos anteriores no servidor e seu aplicativo para aqueles que ouviram falar sobre o projeto pela primeira vez:
Comecei a trabalhar na segunda versão em dezembro do ano passado e continuo até hoje. Vamos ver o que acontece. Estou escrevendo este artigo não apenas para popularizar o projeto, mas também para obter um feedback um pouco mais construtivo antes do lançamento do Centrifugo v2 - agora há espaço para manobras e alterações incompatíveis com versões anteriores.
Biblioteca em tempo real para Go
Na comunidade Go, a pergunta surge de tempos em tempos - existem alternativas para o socket.io no Go? Às vezes eu notei como os desenvolvedores em resposta a isso são aconselhados a olhar para o Centrifugo. No entanto, o Centrifugo é um servidor auto-hospedado, não uma biblioteca - a comparação não é justa. Também me perguntaram várias vezes se o código do Centrifugo pode ser reutilizado para escrever aplicativos em tempo real no Go. E a resposta foi: teoricamente possível, mas não pude garantir a compatibilidade com versões anteriores da API de pacotes internos por meu próprio risco. É claro que não há motivo para alguém arriscar, e bifurcação também é uma opção. Além disso, eu não diria que a API para pacotes internos geralmente foi preparada para esse uso.
Portanto, uma das tarefas ambiciosas que eu queria resolver no processo de trabalho na segunda versão do servidor foi tentar separar o núcleo do servidor em uma biblioteca separada no Go. Acredito que isso faz sentido, considerando quantos recursos o Centrifuge possui para se adaptar à produção. Existem muitos recursos disponíveis prontos para ajudar a criar aplicativos escaláveis em tempo real, eliminando a necessidade de desenvolvedores criarem suas próprias soluções. Escrevi sobre esses recursos anteriormente e também descreverei alguns deles abaixo.
Tentarei justificar mais uma vantagem da existência dessa biblioteca. A maioria dos usuários do Centrifugo são desenvolvedores que escrevem um back-end em linguagens / frameworks com suporte fraco à simultaneidade (por exemplo, Django / Flask / Laravel / ...): para trabalhar com muitas conexões persistentes, se possível, de maneira não óbvia ou ineficiente. Consequentemente, nem todos os usuários podem ajudar no desenvolvimento de um servidor escrito em Go (brega por falta de conhecimento da linguagem). Portanto, mesmo uma comunidade muito pequena de desenvolvedores Go da biblioteca poderá ajudar a desenvolver o servidor Centrifugo usando-o.
O resultado é uma biblioteca de centrífuga . Isso ainda é WIP, mas absolutamente todos os recursos descritos na descrição no Github estão implementados e funcionando. Como a biblioteca fornece uma API bastante rica, antes de garantir a compatibilidade com versões anteriores, gostaria de ouvir vários exemplos bem-sucedidos de uso em projetos reais no Go. Ainda não há. Bem como malsucedido :). Não há nenhum.
Entendo que, nomeando a biblioteca da mesma maneira que o servidor, lidarei para sempre com a confusão. Mas acho que essa é a escolha certa, já que os clientes (como centrifugadora-js, centrifugadora-go) trabalham com a biblioteca Centrifuge e o servidor Centrifugo. Além disso, o nome já está firmemente enraizado nas mentes dos usuários, e eu não quero perder essas associações. E, no entanto, para um pouco mais de clareza, vou esclarecer novamente:
- Centrífuga - uma biblioteca para o idioma Go,
- O Centrifugo é uma solução pronta para uso, um serviço separado, que na versão 2 será construído na biblioteca do Centrifuge.
Devido ao seu design, o Centrifugo (um serviço independente que não sabe nada sobre o seu back-end) assume que o fluxo de mensagens via transporte em tempo real passará do servidor para o cliente. Como assim? Se, por exemplo, o usuário gravar uma mensagem no bate-papo, essa mensagem deverá ser enviada primeiro ao back-end do aplicativo (por exemplo, AJAX no navegador), validado no lado do back-end, salvo no banco de dados, se necessário, e enviado à API do Centrifuge. A biblioteca remove essa restrição, permitindo organizar a troca bidirecional de mensagens assíncronas entre o servidor e o cliente, além de chamadas RPC.
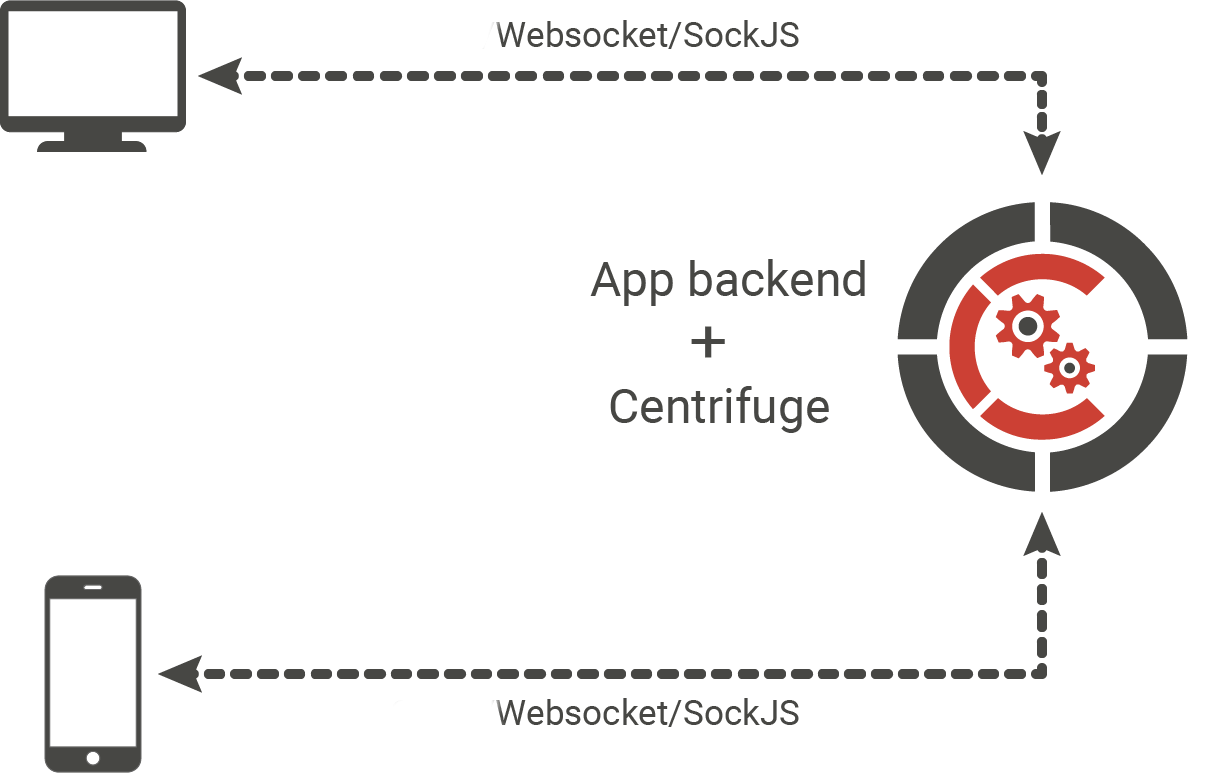
Vejamos um exemplo simples: implementamos um pequeno servidor no Go usando a biblioteca Centrifuge. O servidor receberá mensagens dos clientes do navegador via Websocket, o cliente terá um campo de texto no qual você pode direcionar uma mensagem, pressione Enter - e a mensagem será enviada a todos os usuários inscritos no canal. Ou seja, a versão mais simplificada do chat. Pareceu-me que seria mais conveniente colocar isso na forma de uma essência .
Você pode executar como de costume:
git clone https:
E então vá para http: // localhost: 8000 , abra várias guias do navegador.
Como você pode ver, o ponto de entrada para a lógica comercial do aplicativo ocorre ao desligar as funções de retorno de chamada On().Connect() :
node.On().Connect(func(ctx context.Context, client *centrifuge.Client, e centrifuge.ConnectEvent) centrifuge.ConnectReply { client.On().Disconnect(func(e centrifuge.DisconnectEvent) centrifuge.DisconnectReply { log.Printf("client disconnected") return centrifuge.DisconnectReply{} }) log.Printf("client connected via %s", client.Transport().Name()) return centrifuge.ConnectReply{} })
A abordagem baseada em retorno de chamada me pareceu a mais conveniente para interagir com a biblioteca. Além disso, uma abordagem semelhante, apenas de tipo fraco, é usada na implementação do servidor socket-io no Go . Se, de repente, você pensar em como a API poderia ser feita de maneira mais lingüística - ficarei feliz em ouvir.
Este é um exemplo muito simples que não demonstra todos os recursos da biblioteca. Alguém pode observar que, para tais fins, é mais fácil usar uma biblioteca para trabalhar com o Websocket. Por exemplo, Gorilla Websocket. Isto é realmente verdade. No entanto, mesmo neste caso, você terá que copiar uma parte decente do código do servidor do exemplo no repositório Gorilla Websocket. E se:
- você precisa dimensionar o aplicativo para várias máquinas,
- ou você não precisa de um canal comum, mas vários - e os usuários podem se inscrever e cancelar dinamicamente a partir deles à medida que você navega no aplicativo,
- ou você precisa trabalhar quando a conexão Websocket não pôde ser estabelecida (não há suporte no navegador do cliente, há uma extensão do navegador, algum tipo de proxy no caminho entre o cliente e o servidor corta a conexão),
- ou você precisa restaurar as mensagens perdidas pelo cliente durante pequenos intervalos na conexão com a Internet sem carregar o banco de dados principal,
- ou você precisa controlar a autorização do usuário no canal,
- ou você precisa desconectar a conexão permanente dos usuários desativados no aplicativo,
- ou você precisa de informações sobre quem está atualmente no canal ou sobre eventos nos quais alguém se inscreveu / se desinscreveu no canal,
- ou você precisa de métricas e monitoramento?
A biblioteca do Centrifuge pode ajudá-lo com isso - na verdade, ele herdou todos os recursos básicos anteriormente disponíveis no Centrifugo. Mais exemplos mostrando os pontos mencionados acima podem ser encontrados no Github .
O forte legado de Centrifugo pode ser um sinal negativo, pois a biblioteca adotou toda a mecânica do servidor, que é bastante original e, talvez, possa parecer óbvia ou sobrecarregada com recursos desnecessários para alguém. Tentei organizar o código de maneira que os recursos não utilizados não afetassem o desempenho geral.
Existem algumas otimizações na biblioteca que permitem um uso mais eficiente dos recursos. Isso combina várias mensagens em um quadro Websocket para economizar nas chamadas do sistema Write ou, por exemplo, usando o Gogoprotobuf para serializar mensagens do Protobuf e outras. Falando em Protobuf.
Protocolo Binário Protobuf
Eu realmente queria que o Centrifugo trabalhasse com dados binários ( e não apenas comigo ), então na nova versão eu queria adicionar um protocolo binário além do existente com base no JSON. Agora, todo o protocolo é descrito como um esquema Protobuf . Isso nos permitiu torná-lo mais estruturado, repensar algumas decisões não óbvias no protocolo da primeira versão.
Acho que você não precisa dizer há muito tempo quais são as vantagens do Protobuf sobre o JSON - compacidade, velocidade de serialização, esquema rígido. Existe uma desvantagem na forma de ilegibilidade, mas agora os usuários têm a oportunidade de decidir o que é mais importante para eles em uma situação específica.
Em geral, o tráfego gerado pelo protocolo Centrifugo ao usar o Protobuf em vez do JSON deve diminuir em ~ 2 vezes (excluindo os dados do aplicativo). O consumo de CPU nos meus testes de carga sintética diminuiu as mesmas ~ 2 vezes em comparação com o JSON. Esses números, na verdade, falam pouco sobre o que, na prática, tudo dependerá do perfil de carga de um aplicativo específico.
Por uma questão de interesse, lancei em uma máquina com o benchmark Debian 9.4 e 32 Intel® Xeon® Platinum 8168 CPU a 2.70GHz vCPU, o que nos permitiu comparar a largura de banda da interação cliente-servidor no caso de usar o protocolo JSON e o protocolo Protobuf. Havia 1000 inscritos em 1 canal. Nesse canal, as mensagens foram publicadas em 4 fluxos e entregues a todos os assinantes. O tamanho de cada mensagem era 128 bytes.
Resultados para JSON:
$ go run main.go -s ws:
Resultados para o caso Protobuf:
$ go run main.go -s ws:
Você pode perceber que a taxa de transferência de uma instalação desse tipo é duas vezes maior no caso do Protobuf. O script do cliente pode ser encontrado aqui - este é o script de referência do Nats adaptado às realidades do Centrifuge .
Também é importante notar que o desempenho da serialização JSON no servidor pode ser "aprimorado" usando a mesma abordagem que no gogoprotobuf - buffer pool e geração de código - atualmente o JSON é serializado por um pacote da biblioteca padrão Go construído em refletir. Por exemplo, no Centrifugo, a primeira versão do JSON é serializada manualmente usando uma biblioteca que fornece um buffer pool . Algo semelhante pode ser feito no futuro como parte da segunda versão.
Vale ressaltar que o protobuf também pode ser usado ao se comunicar com o servidor a partir de um navegador. O cliente javascript usa a biblioteca protobuf.js para isso. Como a biblioteca protobufjs é bastante pesada e o número de usuários no formato binário será pequeno, usando o webpack e seu algoritmo de agitação de árvore, geramos duas versões do cliente - uma com suporte apenas ao protocolo JSON e outra com suporte a JSON e protobuf. Para outros ambientes em que o tamanho dos recursos não desempenha um papel tão crítico, os clientes não podem se preocupar com essa separação.
Token da Web JSON (JWT)
Um dos problemas ao usar um servidor autônomo como o Centrifugo é que ele não sabe nada sobre seus usuários e seu método de autenticação, e que tipo de mecanismo de sessão seu back-end usa. E você precisa autenticar a conexão de alguma forma.
Para fazer isso, na primeira versão do Centrifuge, ao conectar, foi usada a assinatura SHA-256 HMAC, com base em uma chave secreta conhecida apenas pelo back-end e pelo Centrifugador. Isso garantiu que o ID do usuário transmitido pelo cliente realmente pertencesse a ele.
Talvez a transferência correta dos parâmetros de conexão e a geração de um token tenham sido uma das principais dificuldades na integração do Centrifugo no projeto.
Quando a Centrífuga apareceu, o padrão JWT ainda não era tão popular. Agora, alguns anos depois, as bibliotecas para geração JWT estão disponíveis para os idiomas mais populares . A idéia principal do JWT é exatamente o que a centrífuga precisa: confirmação da autenticidade dos dados transmitidos. Na segunda versão do HMAC, uma assinatura gerada manualmente deu lugar ao uso do JWT. Isso tornou possível remover a necessidade de suporte para funções auxiliares para a geração correta de tokens em bibliotecas para diferentes idiomas.
Por exemplo, em Python, um token para conectar-se ao Centrifugo pode ser gerado da seguinte maneira:
import jwt import time token = jwt.encode({"user": "42", "exp": int(time.time()) + 10*60}, "secret").decode() print(token)
É importante observar que, se você usar a biblioteca Centrifuge, poderá autenticar o usuário usando o método Go nativo - dentro do middleware. Exemplos estão no repositório.
GRPC
Durante o desenvolvimento, tentei o fluxo bidirecional GRPC como um transporte para comunicação entre o cliente e o servidor (além dos Websocket e dos fallbacks do SockJS baseados em HTTP). O que posso dizer? Ele trabalhou. No entanto, não encontrei um cenário único em que o streaming GRPC bidirecional fosse melhor que o Websocket. Eu olhei principalmente para as métricas do servidor: tráfego gerado pela interface de rede, consumo de CPU pelo servidor com um grande número de conexões de entrada, consumo de memória por conexão.
GRPC perdido para Websocket em todos os aspectos:
- O GRPC gera 20% mais tráfego em cenários semelhantes,
- O GRPC consome 2-3 vezes mais CPU (dependendo da configuração das conexões - todos são assinados em canais diferentes ou todos são assinados em um canal),
- O GRPC consome 4 vezes mais RAM por conexão. Por exemplo, em conexões de 10k, o servidor Websocket consumia 500Mb de memória e GRPC - 2Gb.
Os resultados foram bastante ... esperados. Em geral, no GRPC, como transporte de cliente, eu não via muito sentido - e excluí o código com a consciência limpa até, talvez, tempos melhores.
No entanto, o GRPC é bom no que foi criado principalmente - para gerar código que permite fazer chamadas de RPC entre serviços usando um esquema predeterminado. Portanto, além da API HTTP, o Centrifuge agora também terá suporte à API baseada em GRPC, por exemplo, para publicar novas mensagens no canal e outros métodos disponíveis da API do servidor.
Dificuldades com os clientes
As alterações feitas na segunda versão, removi o suporte obrigatório de bibliotecas para a API do servidor - ficou mais fácil a integração no lado do servidor, no entanto, o protocolo do cliente no projeto foi alterado e possui um número suficiente de recursos. Isso dificulta bastante a implementação dos clientes. Para a segunda versão, agora temos um cliente para Javascript que funciona em navegadores, que deve funcionar com NodeJS e React-Native. Há um cliente no Go e construído com base e com base nos fichários do projeto gomobile para iOS e Android .
Para uma felicidade completa, não há bibliotecas nativas suficientes para iOS e Android. Para a primeira versão do Centrifugo, eles foram comprados por caras da comunidade de código aberto. Eu quero acreditar que algo assim vai acontecer agora.
Recentemente, tentei a sorte enviando um pedido de concessão do MOSS da Mozilla , com a intenção de investir no desenvolvimento de clientes, mas fui recusado. O motivo é a comunidade insuficientemente ativa no Github. Infelizmente, isso é verdade, mas como você pode ver, estou tomando algumas medidas para melhorar a situação.

Conclusão
Não anunciei todos os recursos que aparecerão no Centrifugo v2 - há mais informações na edição do Github . A liberação do servidor ainda não ocorreu, mas ocorrerá em breve. Ainda existem momentos inacabados, incluindo a necessidade de preencher a documentação. O protótipo da documentação pode ser visto aqui . Se você é um usuário do Centrifugo, agora é a hora certa de influenciar a segunda versão do servidor. Uma época em que não é tão assustador quebrar algo, para depois fazer melhor. Para os interessados: o desenvolvimento está concentrado no ramo c2 .
É difícil para mim avaliar quanta demanda a biblioteca do Centrifuge subjacente ao Centrifugo v2 estará em demanda. No momento, estou satisfeito por ter conseguido trazê-lo ao seu estado atual. O indicador mais importante para mim agora é a resposta para a pergunta "eu mesmo usaria essa biblioteca em meu projeto pessoal?" Minha resposta é sim. No trabalho? Sim Portanto, acredito que outros desenvolvedores irão apreciá-lo.
PS Gostaria de agradecer aos caras que ajudaram no trabalho e nos conselhos - Dmitry Korolkov, Artemy Ryabinkov, Oleg Kuzmin. Seria apertado sem você.