Olá colegas! Lembramos que, há pouco tempo, publicamos um
livro sobre o Spark e, atualmente, um
livro sobre Kafka está passando pela revisão mais recente.
Esperamos que esses livros tenham êxito o suficiente para continuar o tópico - por exemplo, para a tradução e publicação de literatura sobre o Spark Streaming. Queríamos oferecer hoje uma tradução sobre a integração dessa tecnologia ao Kafka.
1. JustificaçãoO Apache Kafka + Spark Streaming é uma das melhores combinações para criar aplicativos em tempo real. Neste artigo, discutiremos em detalhes os detalhes dessa integração. Além disso, veremos um exemplo com o Spark Streaming-Kafka. Em seguida, discutimos a “abordagem de destinatário” e a opção de integração direta do Kafka e Spark Streaming. Então, vamos começar a integrar o Kafka e o Spark Streaming.
 2. Integração do Kafka e Spark Streaming
2. Integração do Kafka e Spark StreamingAo integrar o Apache Kafka e o Spark Streaming, existem duas abordagens possíveis para configurar o Spark Streaming para receber dados do Kafka - ou seja, duas abordagens para integrar o Kafka e o Spark Streaming. Primeiro, você pode usar os destinatários e a API Kafka de alto nível. A segunda abordagem (mais recente) é o trabalho sem destinatários. Existem diferentes modelos de programação para ambas as abordagens, diferindo, por exemplo, em termos de desempenho e garantias semânticas.
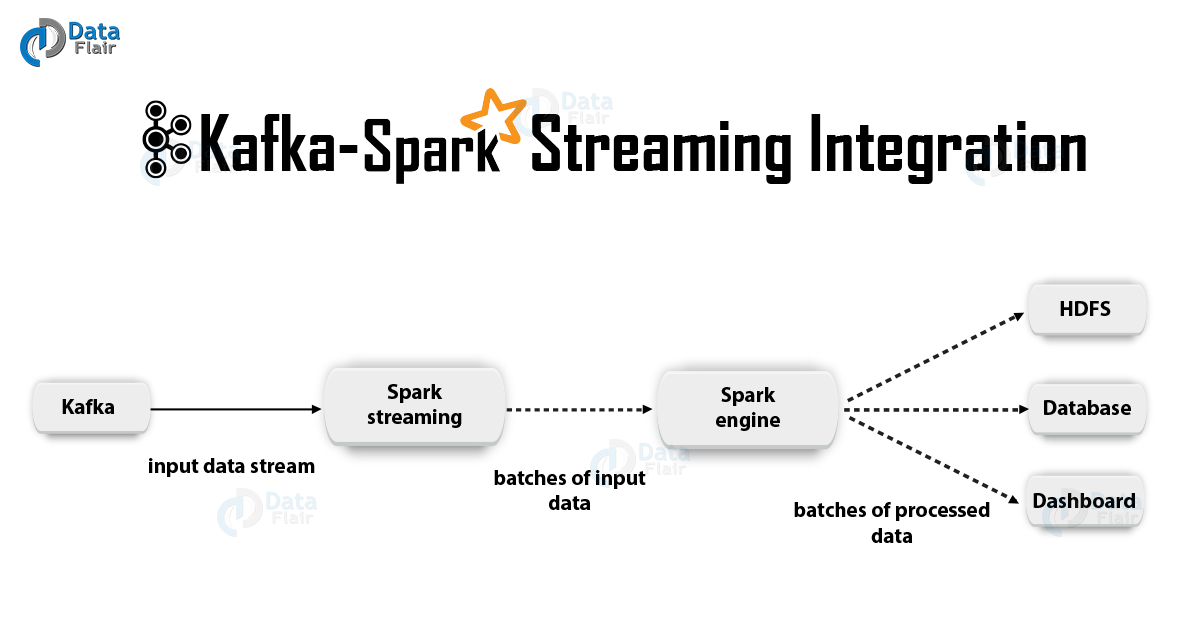
Vamos considerar essas abordagens em mais detalhes.
a. Abordagem Baseada em DestinatárioNesse caso, a recepção de dados é fornecida pelo destinatário. Portanto, usando a API de alto nível de consumo fornecida pela Kafka, implementamos o Destinatário. Além disso, os dados recebidos são armazenados no Spark Artists. Em seguida, os trabalhos são iniciados no Kafka - Spark Streaming, no qual os dados são processados.
No entanto, ao usar essa abordagem, o risco de perda de dados em caso de falha (com a configuração padrão) permanece. Conseqüentemente, será necessário incluir adicionalmente um log write-ahead no Kafka - Spark Streaming para eliminar a perda de dados. Assim, todos os dados recebidos do Kafka são armazenados de forma síncrona no log write-ahead em um sistema de arquivos distribuído. É por isso que, mesmo após uma falha do sistema, todos os dados podem ser restaurados.
A seguir, veremos como usar essa abordagem com os destinatários em um aplicativo com o Kafka - Spark Streaming.
eu EncadernaçãoAgora, conectaremos nosso aplicativo de streaming ao artefato a seguir para aplicativos Scala / Java, usaremos as definições do projeto para o SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
No entanto, ao implantar nosso aplicativo, teremos que adicionar a biblioteca mencionada e suas dependências, isso será necessário para aplicativos Python.
ii. ProgramaçãoEm seguida, crie um fluxo de entrada
KafkaUtils importando
KafkaUtils para o código do aplicativo de fluxo:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
Além disso, usando as opções createStream, você pode especificar classes de chave e classes de valor, bem como as classes correspondentes para sua decodificação.
iii. ImplantaçãoComo em qualquer aplicativo Spark, o comando spark-submit é usado para iniciar. No entanto, os detalhes são ligeiramente diferentes nos aplicativos Scala / Java e nos aplicativos Python.
Além disso, com
–packages você pode adicionar
spark-streaming-Kafka-0-8_2.11 e suas dependências diretamente ao
spark-submit , isso é útil para aplicativos Python em que é impossível gerenciar projetos usando o SBT / Maven.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
Você também pode fazer o download do arquivo JAR do artefato Maven
spark-streaming-Kafka-0-8-assembly no repositório Maven. Em seguida, adicione-o para
spark-submit com -
jars .
b. Abordagem direta (sem destinatários)Após a abordagem usando os destinatários, uma abordagem mais recente foi desenvolvida - a "direta". Ele fornece garantias completas e confiáveis. Nesse caso, perguntamos periodicamente à Kafka sobre as compensações de compensações para cada tópico / seção e não organizamos a entrega de dados pelos destinatários. Além disso, o tamanho do fragmento de leitura é determinado, isto é necessário para o processamento correto de cada pacote. Por fim, uma API de consumo simples é usada para ler intervalos com dados do Kafka com os deslocamentos especificados, especialmente quando os trabalhos de processamento de dados são iniciados. Todo o processo é como ler arquivos de um sistema de arquivos.
Nota: Esse recurso apareceu no Spark 1.3 para Scala e na API Java, bem como no Spark 1.4 para a API Python.
Agora vamos discutir como aplicar essa abordagem em nosso aplicativo de streaming.
A API do consumidor é descrita em mais detalhes no seguinte link:
Consumidor Apache Kafka | Exemplos de Consumidor Kafkaeu Encadernação
É verdade que essa abordagem é suportada apenas em aplicativos Scala / Java. Com o artefato a seguir, construa o projeto SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. ProgramaçãoEm seguida, importe o KafkaUtils e crie um
DStream entrada no código do aplicativo de fluxo:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
Nos parâmetros Kafka, você precisará especificar
metadata.broker.list ou
bootstrap.servers . Portanto, por padrão, consumiremos dados a partir do último deslocamento em cada seção do Kafka. No entanto, se você deseja que a leitura comece no menor fragmento, nos parâmetros Kafka, é necessário definir a opção de configuração
auto.offset.reset .
Além disso, trabalhando com as opções
KafkaUtils.createDirectStream , você pode começar a ler de um deslocamento arbitrário. Em seguida, faremos o seguinte, o que nos permitirá acessar os fragmentos Kafka consumidos em cada pacote.
Se queremos organizar o monitoramento do Kafka com base no Zookeeper usando ferramentas especiais, podemos atualizar o Zookeeper por conta própria com a ajuda deles.
iii. ImplantaçãoO processo de implantação neste caso se assemelha ao processo de implantação na variante com o destinatário.
3. Os benefícios de uma abordagem diretaA segunda abordagem para integrar o Spark Streaming ao Kafka supera a primeira pelos seguintes motivos:
a. Concorrência simplificadaNesse caso, você não precisa criar muitos fluxos de entrada Kafka e combiná-los. No entanto, o Kafka - Spark Streaming criará tantos segmentos RDD quanto haverá segmentos Kafka para consumo. Todos esses dados Kafka serão lidos em paralelo. Portanto, podemos dizer que teremos uma correspondência individual entre os segmentos Kafka e RDD, e esse modelo é mais compreensível e mais fácil de configurar.
b. EficáciaPara eliminar completamente a perda de dados durante a primeira abordagem, as informações precisavam ser armazenadas em um log dos principais registros e, em seguida, replicadas. De fato, isso é ineficiente porque os dados são replicados duas vezes: a primeira vez pelo próprio Kafka e a segunda pelo log de gravação antecipada. Na segunda abordagem, esse problema é eliminado, pois não há destinatário e, portanto, nenhum diário de gravação principal é necessário. Se tivermos um armazenamento de dados suficientemente longo no Kafka, você poderá recuperar mensagens diretamente do Kafka.
s Semântica Exatamente Uma VezBasicamente, usamos a API Kafka de alto nível na primeira abordagem para armazenar fragmentos de leitura consumidos no Zookeeper. No entanto, esse é o costume de consumir dados do Kafka. Embora a perda de dados possa ser eliminada com segurança, há uma pequena chance de que, em algumas falhas, os registros individuais possam ser consumidos duas vezes. O ponto principal é a inconsistência entre o mecanismo confiável de transferência de dados no Kafka - Spark Streaming e a leitura de fragmentos que ocorrem no Zookeeper. Portanto, na segunda abordagem, usamos a API Kafka simples, que não requer recurso ao Zookeeper. Aqui, os fragmentos de leitura são rastreados no Kafka - Spark Streaming, para isso, são utilizados pontos de controle. Nesse caso, a inconsistência entre o Spark Streaming e o Zookeeper / Kafka é eliminada.
Portanto, mesmo em caso de falhas, o Spark Streaming recebe cada registro estritamente uma vez. Aqui, precisamos garantir que nossa operação de saída, na qual os dados são armazenados no armazenamento externo, seja idempotente ou uma transação atômica na qual os resultados e as compensações sejam armazenados. É assim que a semântica exata é alcançada na derivação de nossos resultados.
Embora haja uma desvantagem: as compensações no Zookeeper não são atualizadas. Portanto, as ferramentas de monitoramento do Kafka baseadas no Zookeeper não permitem acompanhar o progresso.
No entanto, ainda podemos nos referir a compensações, se o processamento for organizado dessa maneira - recorremos a cada pacote e atualizamos o Zookeeper.
É tudo o que queremos falar sobre a integração do Apache Kafka e Spark Streaming. Esperamos que você tenha gostado.