Esta é a segunda palestra com J. Subbotnik sobre bancos de dados - a
primeira que publicamos algumas semanas atrás.
O chefe do grupo de DBMS de uso geral Dmitry Sarafannikov falou sobre a evolução do data warehouse no Yandex: como decidimos criar uma interface compatível com S3, por que escolhemos o PostgreSQL, que tipo de rake adotamos e como lidar com eles.
- Olá pessoal! Meu nome é Dima, no Yandex eu faço bancos de dados.
Vou contar como fizemos o S3, como fizemos exatamente o S3 e que tipo de armazenamento era antes. O primeiro deles é o Elliptics, publicado em código aberto, disponível no GitHub. Muitos podem ter se deparado com isso.

Essa é essencialmente uma tabela de hash distribuída com uma chave de 512 bits, o resultado do SHA-512. Forma um chaveiro dividido aleatoriamente entre máquinas. Se você deseja adicionar máquinas lá, as chaves são redistribuídas, ocorre o reequilíbrio. Este repositório tem seus próprios problemas associados, em particular, ao reequilíbrio. Se você tem um número suficientemente grande de chaves, então, com volumes constantemente crescentes, é necessário despejar carros constantemente, e em um número muito grande de chaves, o reequilíbrio pode simplesmente não convergir. Este foi um problema grande o suficiente.
Mas, ao mesmo tempo, esse armazenamento é excelente para dados mais ou menos estáticos, quando você carrega uma grande quantidade de uma só vez e, em seguida, gera uma carga somente leitura. Para tais decisões, ele se encaixa perfeitamente.
Nós estamos indo além. Os problemas com o reequilíbrio eram bastante sérios, portanto o próximo armazenamento apareceu.

Qual é a sua essência? Isso não é armazenamento de valor-chave, é armazenamento de valor. Quando você carrega algum objeto ou arquivo lá, ele responde com uma chave, pela qual você pode pegar esse arquivo. O que isso dá? Teoricamente, cem por cento de acesso de gravação, se você tiver espaço livre no armazenamento. Se você tem uma máquina de escrever, simplesmente escreve para outras pessoas que não estão deitadas, onde há espaço livre, obtém outras chaves e coleta seus dados com calma.
Esse armazenamento é muito fácil de dimensionar, você pode jogá-lo com ferro, ele funcionará. É muito simples, confiável. Sua única desvantagem: o cliente não gerencia a chave e todos os clientes devem armazenar as chaves em algum lugar, armazenar o mapeamento de suas chaves. Isso é inconveniente para todos. De fato, essa é uma tarefa muito semelhante para todos os clientes, e cada uma a resolve à sua maneira em suas metabases, etc. Isso é inconveniente. Mas, ao mesmo tempo, não quero perder a confiabilidade e a simplicidade desse armazenamento, na verdade ele funciona com a velocidade da rede.
Então começamos a olhar para o S3. Este é o armazenamento de valor-chave, o cliente gerencia a chave e todo o armazenamento é dividido nos chamados buckets. Em cada bloco, o espaço da chave é de menos infinito a mais infinito. A chave é algum tipo de sequência de texto. E nos decidimos por essa opção. Por que S3?
Tudo é bem simples. Nesse momento, muitos clientes prontos para várias linguagens de programação já foram gravados, muitas ferramentas prontas para armazenar algo no S3, por exemplo, backups de bancos de dados, já foram gravadas. Andrew
falou sobre um dos exemplos. Já existe uma API razoavelmente bem pensada que circula nos clientes há anos e você não precisa inventar nada lá. A API possui muitos recursos convenientes, como listagens, uploads com várias partes e assim por diante. Portanto, decidimos permanecer nele.
Como fazer o S3 do nosso armazenamento? O que vem à mente? Como os próprios clientes armazenam o mapeamento de chaves, simplesmente pegamos, colocamos o banco de dados ao lado deles e armazenamos o mapeamento dessas chaves nele. Ao ler, apenas encontraremos as chaves e o armazenamento em nosso banco de dados e forneceremos ao cliente o que ele deseja. Se você esboçar isso esquematicamente, como acontece o preenchimento?

Existe uma certa entidade, aqui é chamada Proxy, o chamado back-end. Ele aceita o arquivo, carrega-o no armazenamento, pega a chave de lá e salva no banco de dados.Tudo é bem simples.
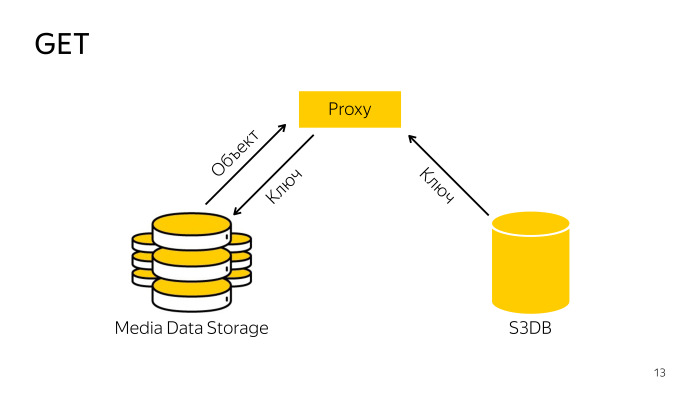
Como está o recibo? O proxy encontra a chave necessária no banco de dados, acompanha a chave para armazenamento, baixa o objeto a partir daí e entrega ao cliente. Tudo é simples também.
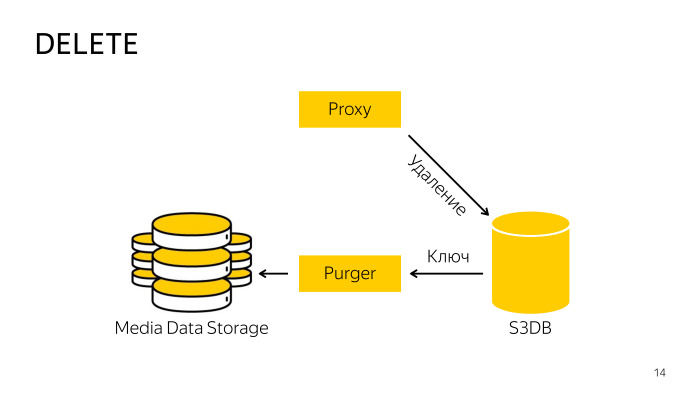
Como é a remoção? Ao excluir diretamente do armazenamento, o proxy não funciona, porque é difícil coordenar o banco de dados e o armazenamento; portanto, ele apenas vai para o banco de dados, informa que esse objeto foi excluído, o objeto é movido para a fila de exclusão e, em segundo plano, um profissional especialmente treinado o robô pega essas chaves e as exclui do armazenamento e do banco de dados. Tudo aqui também é bastante simples.
Escolhemos o PostgreSQL como banco de dados para essa metabase.
Você já sabe que nós o amamos muito. Com a transferência do Yandex.Mail, adquirimos experiência suficiente no PostgreSQL e, quando diferentes serviços de correio foram movidos, desenvolvemos vários padrões de sharding. Um deles caiu bem no S3 com pequenas modificações, mas correu bem lá.
Quais são as opções de sharding? Este é um repositório grande.Em uma escala Yandex, você deve pensar imediatamente que haverá muitos objetos, pensar imediatamente em como dividir tudo. Você pode fragmentar por hash em nome do objeto, é a maneira mais confiável, mas não funcionará aqui, porque o S3 tem, por exemplo, listagens que devem mostrar a lista de chaves na ordem classificada, quando você armazena em cache, todas as classificações desaparecem, é necessário remover todos os objetos para que a saída esteja em conformidade com a especificação da API.
A próxima opção, você pode compartilhar por hash em nome ou ID do bucket. Um bucket pode viver dentro de um shard de banco de dados.
Outra opção é dividir os intervalos de teclas. Dentro do balde, há espaço de menos infinito a mais infinito, podemos dividi-lo em qualquer número de intervalos, chamamos esse intervalo de pedaço, ele pode viver em apenas um fragmento.

Escolhemos a terceira opção, cortando por pedaços, porque, teoricamente, pode haver um número infinito de objetos em um balde, e estupidamente não cabe em um pedaço de ferro. Haverá grandes problemas, por isso vamos cortar e organizar os cacos como quisermos. Só isso.

O que aconteceu? Todo o banco de dados consiste em três componentes. S3 Proxy - um grupo de hosts, também há um banco de dados. O PL / Proxy está sob o balanceador, as solicitações desse back-end voam para lá. Além disso, o S3Meta, um grupo de baixo, que armazena informações sobre baldes e pedaços. E o S3DB, shards onde os objetos são armazenados, uma fila de exclusão. Se representado esquematicamente, fica assim.
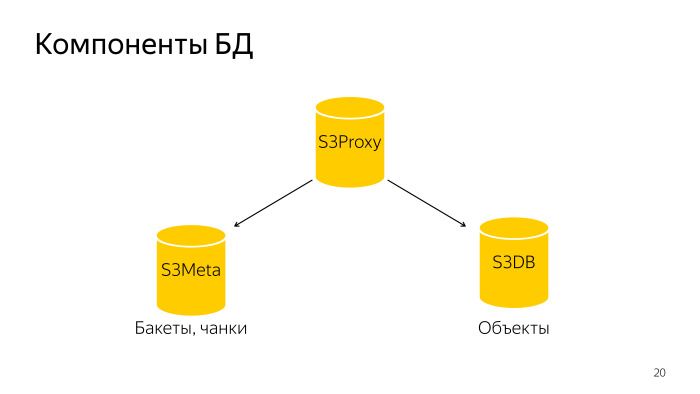
Uma solicitação é enviada ao S3Proxy, é encaminhada ao S3Meta e S3DB e emite informações para o topo.

Vamos considerar em mais detalhes. S3Proxy, funções dentro dele são criadas na linguagem processual PLProxy, é uma linguagem que permite executar procedimentos ou solicitações armazenadas remotamente. É assim que o código da função ObjectInfo se parece, em essência, com uma solicitação Get.
O cluster LProxy possui o operador Cluster, neste caso db_ro. O que isso significa?

Se uma configuração típica de fragmento de banco de dados, há um mestre e duas réplicas. O mestre entra no cluster db_rw, todos os três hosts inserem db-ro; é aqui que você pode enviar apenas uma solicitação de leitura e uma solicitação de gravação é enviada para db_rw. O cluster db_rw inclui todos os mestres de todos os shards.
A próxima instrução RUN ON, aceita o valor all, o que significa executar em todos os shards uma matriz ou algum tipo de shard. Nesse caso, ele recebe o resultado da função get_object_shard como uma entrada; esse é o número do shard no qual o objeto especificado está.
E target - que função chama o shard remoto. Ele chamará essa função e substituirá os argumentos que voaram para essa função.

A função get_object_shard também é gravada em PLProxy, já um cluster meta_ro, a solicitação será direcionada para o shard S3Meta, que retornará essa função get_bucket_meta_shard.
O S3Meta também pode ser fragmentado, nós também o definimos, enquanto isso é irrelevante, mas há uma oportunidade. E chamará a função get_object_shard no S3Meta.

get_bucket_meta_shard é apenas um hash de texto em nome de um bucket, embaralhamos o S3Meta apenas por um hash em nome de um bucket.

Considere o S3Meta o que está acontecendo nele. A informação mais importante que existe é uma tabela com pedaços. Recortei um pouco algumas informações desnecessárias, a coisa mais importante que resta é bucket_id, a chave de início, a chave de término e o fragmento em que esta parte está.

Como seria uma consulta em uma tabela desse tipo, que retornaria para nós a parte em que, por exemplo, está o objeto de teste? Assim. Menos o infinito na forma de texto, nós o apresentamos como um valor nulo; existem pontos sutis que você precisa verificar nas teclas start_key e end_key é Null.

A solicitação não parece muito boa e o plano parece ainda pior. Como uma das opções para um plano para essa solicitação, BitmapOr. E 6.000 ossos valem esse plano.

Como pode ser diferente? Existe uma coisa tão maravilhosa no PostgreSQL como o índice gist, que pode indexar o tipo de intervalo, o intervalo é essencialmente o que precisamos. Nós criamos esse tipo, a função s3.to_keyrange retorna para nós, de fato, o intervalo. Podemos verificar com o operador contains, encontrar o pedaço em que nossa chave está. E, para isso, a restrição de exclusão é criada aqui, o que garante a não interseção desses blocos. Precisamos permitir, de preferência no nível do banco de dados, algumas restrições para garantir que os pedaços não possam se cruzar entre si, para que apenas uma linha seja retornada em resposta à solicitação. Caso contrário, não será o que queríamos. É assim que o plano para essa solicitação é exibido, o index_scan usual. Essa condição se encaixa completamente na condição do índice, e esse plano tem apenas 700 ossos, 10 vezes menos.

O que é a restrição de exclusão?

Vamos criar uma tabela de teste com duas colunas e adicionar duas restrições, uma única que todos conhecem e uma restrição de exclusão, que tem parâmetros iguais para esses operadores. Vamos configurá-lo com dois operadores iguais, essa placa foi construída.

Então tentamos inserir duas linhas idênticas, obtemos o erro de violação da exclusividade da chave na primeira restrição. Se a abandonarmos, já violamos a restrição de exclusão. Este é um caso comum de uma restrição exclusiva.

De fato, uma restrição exclusiva é a mesma restrição de exclusão, com os operadores iguais, mas no caso de restrição de exclusão, é possível criar alguns casos mais gerais.

Nós temos esses índices. Se você olhar atentamente, verá que ambos são índices essenciais e, em geral, são os mesmos. Você provavelmente pergunta por que duplicar esse negócio. Eu vou te contar.

Os índices são uma coisa, especialmente o índice essencial, que a tabela vive sua própria vida, as atualizações ocorrem, são divididas e assim por diante, o índice fica ruim por aí, deixa de ser ideal. E existe essa prática, em particular a extensão pg repack, os índices são reconstruídos periodicamente, de vez em quando são reconstruídos.
Como recriar um índice com uma restrição exclusiva? Crie criar índice atualmente, crie o mesmo índice calmamente próximo a ele sem bloquear e, em seguida, a expressão alterar tabela da restrição user_index é tal e tal. E tudo, tudo é claro e bom aqui, funciona.
No caso de restrição de exclusão, você pode reconstruí-lo apenas através do bloqueio da reindexação, mais precisamente, seu índice será bloqueado exclusivamente e, na verdade, você terá todas as consultas restantes. Isso é inaceitável, o índice de essência pode ser construído por tempo suficiente. Portanto, mantemos o próximo índice, que é menor em volume, ocupa menos espaço, o planador o utiliza e podemos reconstruir esse índice competitivamente sem bloquear.
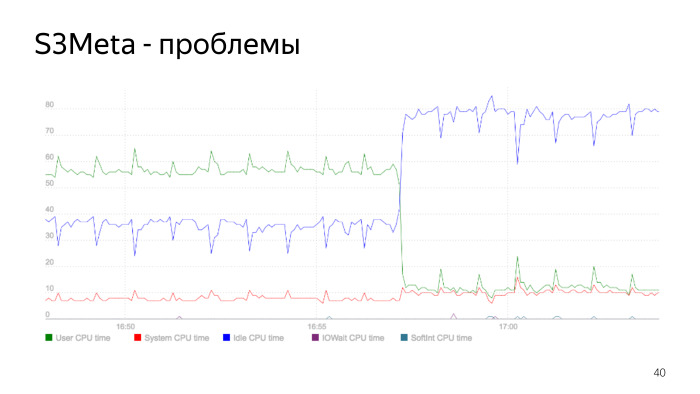
Aqui está um gráfico do consumo do processador. A linha verde é o consumo do processador no espaço do usuário, que salta de 50% para 60%. Neste ponto, o consumo cai acentuadamente, é o momento em que o índice é reconstruído. Nós reconstruímos o índice, excluímos o antigo, nosso consumo de processadores caiu acentuadamente. Este é um problema do índice de essência e é um bom exemplo de como isso pode ser.
Quando fizemos tudo isso, começamos na versão 9.5 S3DB, de acordo com o plano, planejamos empilhar 10 bilhões de objetos em cada shard. Como você sabe, mais de um bilhão e até mesmo problemas anteriores começam quando uma tabela tem muitas linhas, tudo fica muito pior. Existe uma prática de separação. Naquela época, havia duas opções, padrão por herança, mas isso não funciona muito bem, pois existe uma velocidade de seleção de partição linear. E, a julgar pelo número de objetos, precisamos de muitas partições. Os caras do Postgres Pro então cortaram ativamente a extensão pg_pathman.

Escolhemos pg_pathman, não tivemos outra escolha. Mesmo versão 1.4. E como você pode ver, usamos 256 partições. Dividimos a tabela inteira de objetos em 256 partições.
O que faz o pg_pathman? Usando esta expressão, você pode criar 256 partições particionadas por hash na coluna de lances.

Como o pg_pathman funciona?
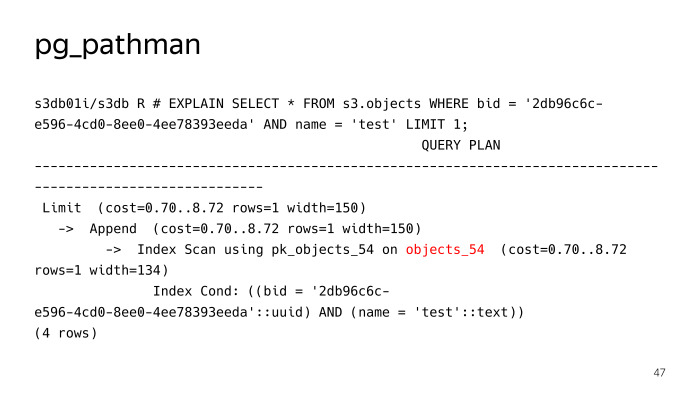
Ele registra seus ganchos no planador e, posteriormente, sob pedidos, substitui, em essência, o plano. Vimos que ele não pesquisou 256 partições para uma consulta de pesquisa regular para um objeto com o teste de nome, mas imediatamente determinou que era necessário subir na tabela objects_54, mas tudo não estava indo bem aqui, pg_pathman tem seus próprios problemas. Em primeiro lugar, havia alguns bugs no início, enquanto ele estava serrando, mas graças aos caras do Postgres Pro, eles rapidamente os consertaram e os consertaram.
O primeiro problema é a dificuldade de atualizá-lo. O segundo problema são declarações preparadas.
Vamos considerar em mais detalhes. Em particular, a atualização. Em que consiste o pg_pathman?

Consiste essencialmente em código C, que é empacotado em uma biblioteca. E consiste em uma parte SQL, todos os tipos de funções para criar partições, e assim por diante. Além disso, interfaces para as funções que estão na biblioteca. Essas duas partes não podem ser atualizadas ao mesmo tempo.
A partir daqui, surgem dificuldades, algo como este algoritmo para atualizar a versão do pg_pathman, primeiro lançamos um novo pacote com uma nova versão, mas o PostgreSQL tem versões antigas carregadas na memória, ele o utiliza. Isso é imediatamente em qualquer caso, a base deve ser reiniciada.
Em seguida, chamamos a função set_enable_parent, ela ativa a função na tabela pai, que é desativada por padrão. Em seguida, desative o pathman, reinicie o banco de dados, diga ALTER EXTENSION UPDATE, neste momento, tudo cai na tabela pai.
Em seguida, ative o pathman e execute a função, que está na extensão, que transfere objetos da tabela pai que os atacou nesse curto período de tempo, os transfere de volta para as tabelas em que deveriam estar. E, em seguida, desative o uso da tabela pai, pesquise nela.

O próximo problema são as declarações preparadas.

Se bloquearmos a mesma solicitação comum, pesquise por lance e chave, tente executá-la. Execute cinco vezes - tudo está bem. Realizamos o sexto - vemos esse plano. E a esse respeito, vemos todas as 256 partições. Se você observar atentamente essas condições, veremos o dólar 1, o dólar 2, este é o chamado plano genérico, o plano geral. As cinco primeiras consultas foram construídas individualmente, os planos individuais foram usados para esses parâmetros, pg_pathman pode determinar imediatamente, porque o parâmetro é conhecido antecipadamente, pode determinar imediatamente a tabela para onde ir. Nesse caso, ele não pode fazer isso. Assim, o plano deve ter todas as 256 partições e, quando o executor faz isso, ele executa um bloqueio compartilhado para todas as 256 partições, e o desempenho dessa solução não é imediato. Ele simplesmente perde todas as suas vantagens e qualquer solicitação é realizada de maneira insanamente longa.

Como saímos dessa situação? Eu tive que agrupar tudo dentro dos procedimentos armazenados em execute, no SQL dinâmico, para que as instruções preparadas não fossem usadas e o plano fosse construído a cada vez. É assim que funciona.
A desvantagem é que você precisa inserir todo o código em estruturas que tocam nessas tabelas. Isso é mais difícil de ler aqui.

Como é a distribuição dos objetos? Em cada fragmento S3DB, os contadores de fragmentos são armazenados, também há informações sobre quais fragmentos estão nesse fragmento e os contadores são armazenados para eles. Para cada operação de mutação em um objeto - adicionando, excluindo, alterando, reescrevendo - esses contadores para a alteração de bloco. Para não atualizar a mesma linha quando houver vazamento ativo nesse bloco, usamos uma técnica bastante padrão quando inserimos um contador delta em uma tabela separada e, a cada minuto, um robô especial passa e agrega tudo isso, atualiza os contadores no bloco .

Além disso, esses contadores são entregues ao S3Meta com algum atraso, já existe uma imagem completa de quantos contadores estão em qual bloco, então você pode ver a distribuição por shards, quantos objetos estão em que shard e, com base nisso, é tomada uma decisão sobre a queda do novo bloco. Quando você cria um bucket, por padrão, um único pedaço é criado de menos infinito a mais infinito, dependendo da distribuição atual de objetos que o S3Meta conhece, ele cai em algum tipo de fragmento.
Quando você coloca dados nesse bucket, todos esses dados são inseridos nesse pedaço. Quando um determinado tamanho é atingido, um robô especial chega e compartilha esse pedaço.

Tornamos esses pedaços pequenos. Fazemos isso para que, nesse caso, esse pequeno pedaço possa ser arrastado para outro fragmento. Como acontece uma divisão de partes? Aqui está um robô comum, ele divide e divide esse pedaço no S3DB com confirmação em duas fases e atualiza as informações no S3Meta.
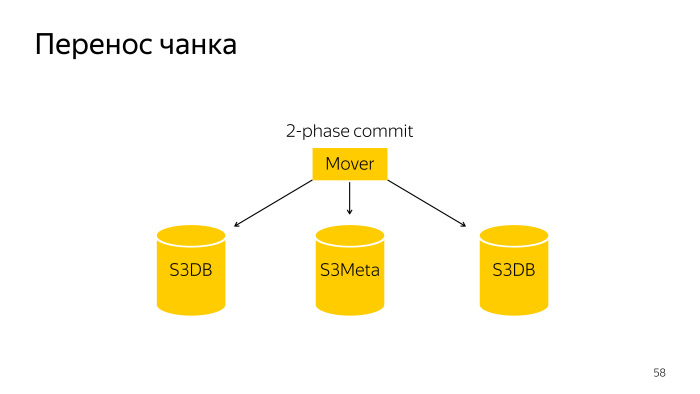
A transferência de chunk é uma operação um pouco mais complicada; é um commit de duas fases em três bases, o S3Meta e dois shards, S3DB, arrastados de um para o outro.

O S3 tem esse recurso como listagens, isso é a coisa mais difícil e também houve problemas. De fato, listagens, você diz S3 - mostre-me os objetos que tenho. O parâmetro destacado em vermelho agora é Nulo. Este parâmetro, delimitador, separador, você pode especificar as listagens com qual separador deseja.
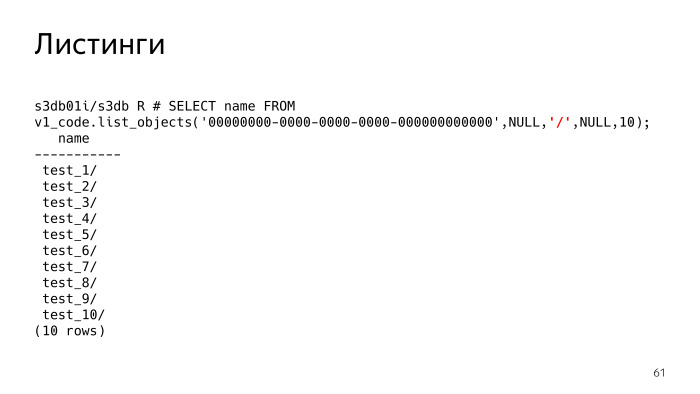
O que isso significa? Se o delímetro não estiver definido, vemos que simplesmente recebemos uma lista de arquivos. Se definirmos o delímetro, em essência, o S3 deve nos mostrar as pastas. Devo entender que existem essas pastas e, de fato, mostra todas as pastas e arquivos na pasta atual. A pasta atual é prefixada, este parâmetro é Nulo. Vemos que existem 10 pastas.
Todas as chaves não são armazenadas em algum tipo de estrutura hierárquica em árvore, como no sistema de arquivos. Cada objeto é armazenado como uma sequência e eles têm um prefixo comum simples. O próprio S3 deve entender que isso é um idiota.

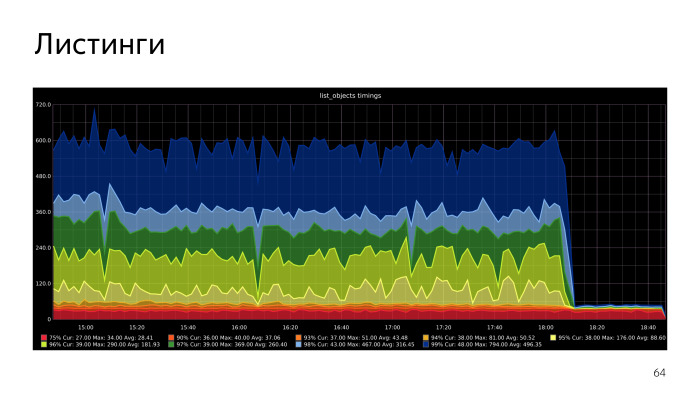
SQL, . , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
, .
. , .
Docker,
Behave Behave
. , , , .
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
Na replicação lógica, há uma série de problemas que iremos resolver, tentaremos empurrá-lo para cima. A segunda opção - você pode recusar o histograma, tente colocar esse intervalo de texto em btree. Este não é um tipo unidimensional e btree funciona apenas com tipos unidimensionais. Mas a condição de que os pedaços não se sobreponham conosco nos permitirá colocar nosso caso em btree. Ontem fizemos um protótipo que funciona. É implementado nas funções PL / pgSQL. Temos uma aceleração perceptível, vamos otimizar nessa direção.