Quando o Dropbox começou, um usuário do Hacker News comentou que ele poderia ser implementado com vários scripts bash usando FTP e Git. Agora, isso não pode ser dito de forma alguma: trata-se de um grande armazenamento de arquivos na nuvem com bilhões de novos arquivos todos os dias, que não são apenas armazenados de alguma forma no banco de dados, mas de maneira que qualquer banco de dados possa ser restaurado em qualquer ponto nos últimos seis dias.
Sob o corte, a transcrição do relatório de
Glory Bakhmutov (
m0sth8 ) no Highload ++ 2017, sobre como os bancos de dados no Dropbox se desenvolveram e como estão organizados agora.
Sobre o palestrante: Glória a Bakhmutov - engenheiro de confiabilidade do site da equipe do Dropbox, ama muito o Go e às vezes aparece no podcast golangshow.com.
Conteúdo
Arquitetura do Dropbox em linguagem simples
O Dropbox apareceu em 2008. Este é essencialmente um armazenamento de arquivos na nuvem. Quando o Dropbox começou, um usuário do Hacker News comentou que ele poderia ser implementado com vários scripts bash usando FTP e Git. Mas, no entanto, o Dropbox está em desenvolvimento e agora é um serviço bastante grande, com mais de 1,5 bilhão de usuários, 200 mil empresas e um grande número (vários bilhões!) De novos arquivos todos os dias.
Como é o Dropbox?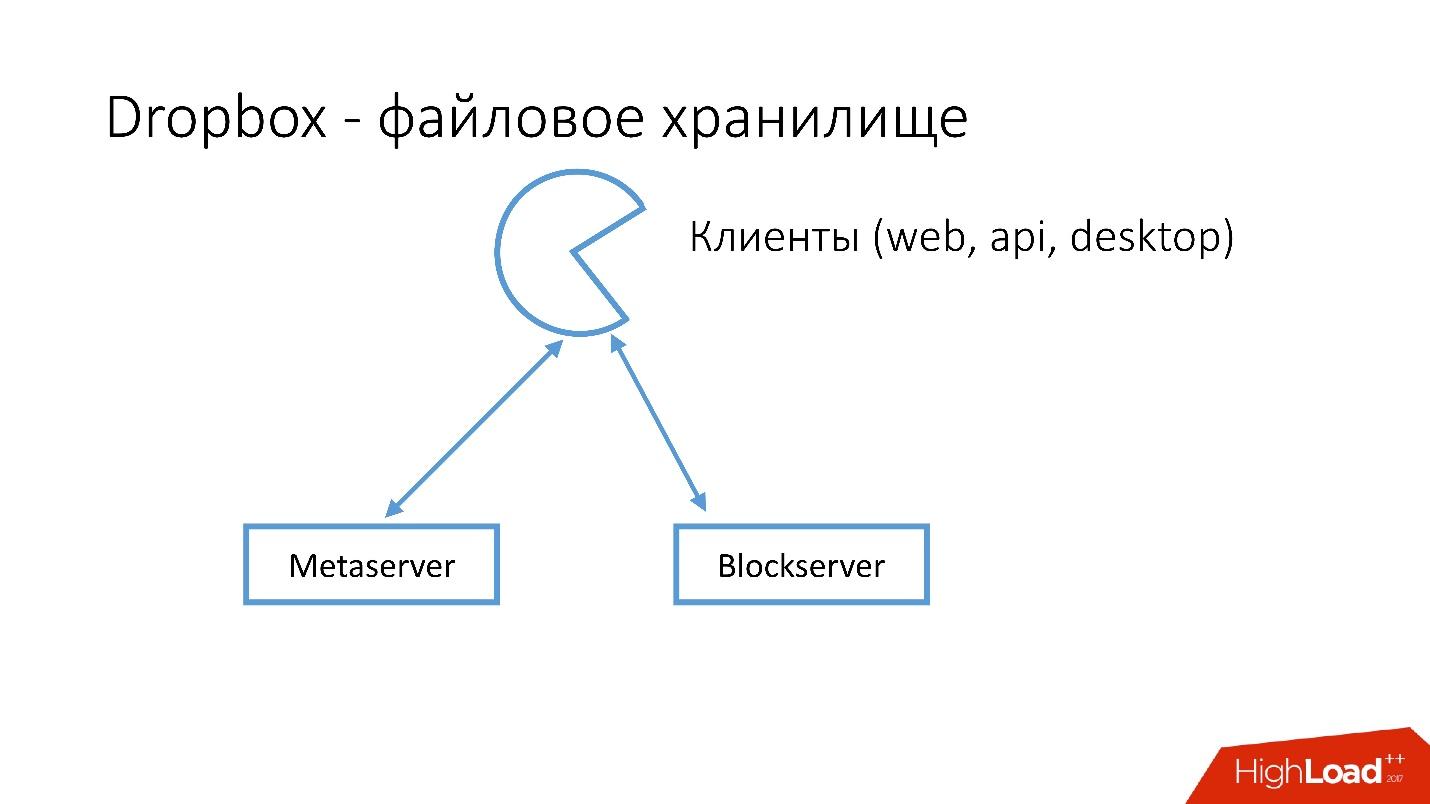
Temos vários clientes (interface da web, API para aplicativos que usam o Dropbox, aplicativos de desktop). Todos esses clientes usam a API e se comunicam com dois grandes serviços que podem ser divididos logicamente em:
- Metaserver
- Blockserver
O Metaserver armazena meta-informações sobre o arquivo: tamanho, comentários, links para este arquivo no Dropbox, etc. O Blockserver armazena apenas informações sobre arquivos: pastas, caminhos, etc.
Como isso funciona?Por exemplo, você tem um arquivo video.avi com algum tipo de vídeo.
 Link do slide
Link do slide- O cliente divide esse arquivo em vários blocos (neste caso, 4 MB cada), calcula a soma de verificação e envia uma solicitação ao Metaserver: "Eu tenho um arquivo * .avi, quero carregá-lo, os valores de hash são assim e assim".
- O Metaserver retorna a resposta: "Eu não tenho esses blocos, vamos fazer o download!" Ou ele pode responder que possui todos ou alguns dos blocos e apenas os demais precisam ser carregados.
 Link do slide
Link do slide- Depois disso, o cliente vai para o Blockserver, envia a quantidade de hash e o próprio bloco de dados, que é armazenado no Blockserver.
- Blockserver confirma a operação.
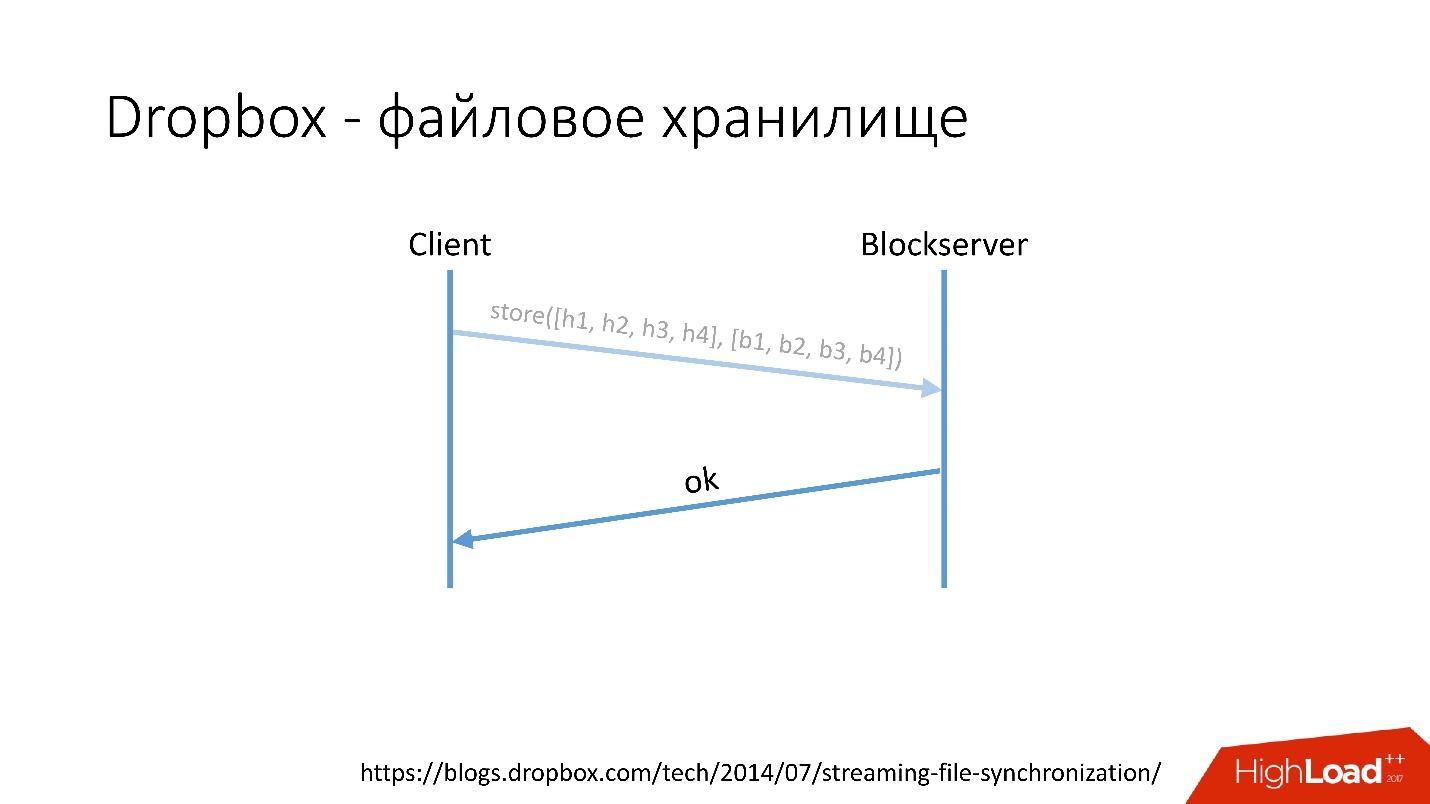 Link do slide
Link do slideObviamente, este é um esquema muito simplificado, o protocolo é muito mais complicado: há sincronização entre clientes na mesma rede, há drivers de kernel, a capacidade de resolver colisões etc. Este é um protocolo bastante complexo, mas funciona assim esquematicamente.

Quando um cliente salva algo no Metaserver, todas as informações vão para o MySQL. O Blockserver também armazena informações sobre os arquivos, como eles são estruturados, em que blocos eles consistem, no MySQL. O Blockserver também armazena os próprios blocos no Block Storage, que, por sua vez, armazena informações sobre onde fica o bloco, em qual servidor e como é processado, também no MYSQL.
Para armazenar exabytes de arquivos do usuário, armazenamos simultaneamente informações adicionais em um banco de dados de várias dezenas de petabytes espalhados por 6 mil servidores.
Histórico de Desenvolvimento de Banco de Dados
Como os bancos de dados evoluíram no Dropbox?

Em 2008, tudo começou com um Metaserver e um banco de dados global. Todas as informações que o Dropbox precisava ser armazenado em algum lugar, ele salvou no único MySQL global. Isso não durou muito, porque o número de usuários cresceu e os bancos de dados e tablets individuais dentro dos bancos de dados aumentaram mais rapidamente do que outros.

Portanto, em 2011, várias tabelas foram enviadas para servidores separados:
- Usuário , com informações sobre usuários, por exemplo, logins e tokens oAuth;
- Host , com informações de arquivo do Blockserver;
- Misc , que não estava envolvido no processamento de solicitações de produção, mas foi usado para funções de utilidade, como tarefas em lote.
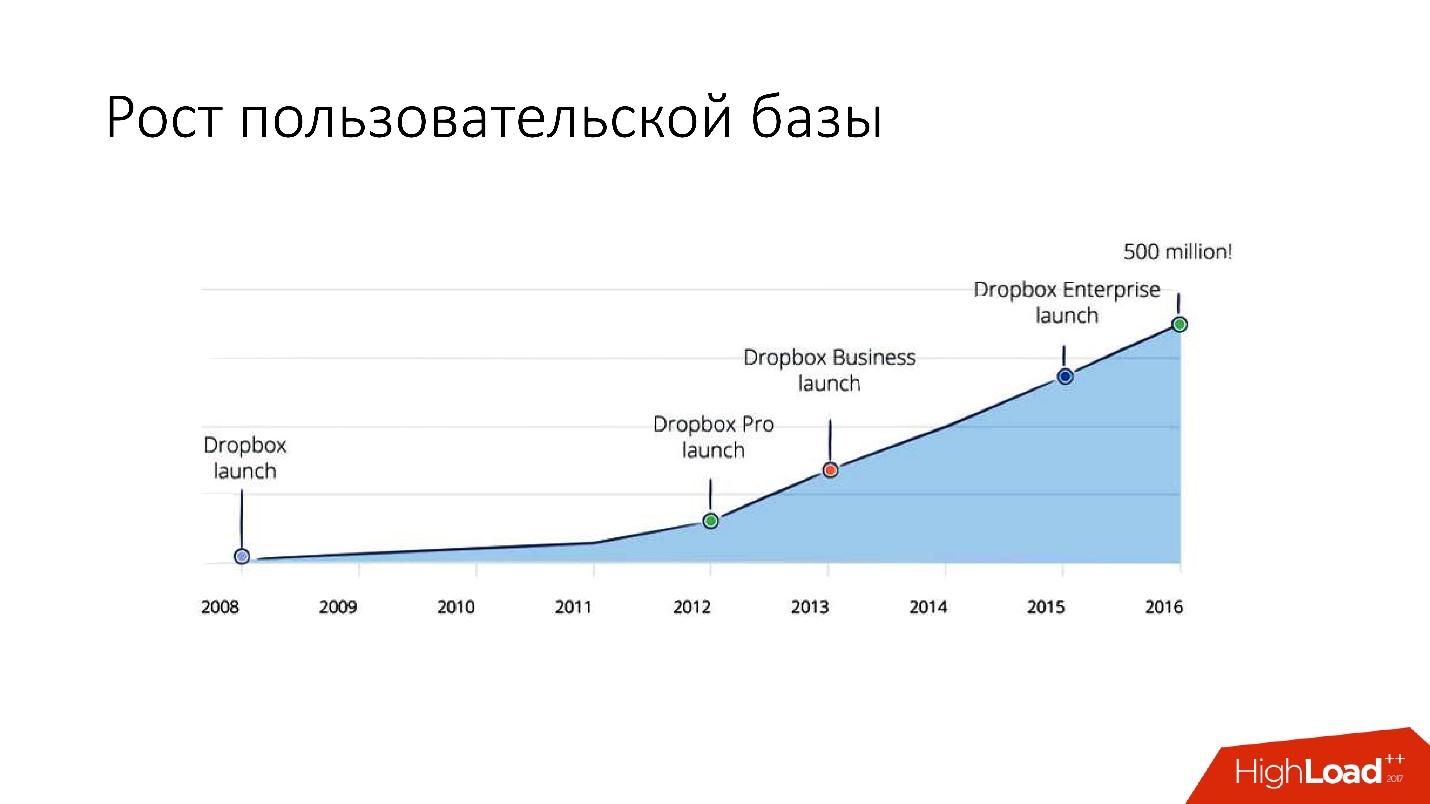
Mas depois de 2012, o Dropbox começou a crescer muito, desde então crescemos
cerca de 100 milhões de usuários por ano .
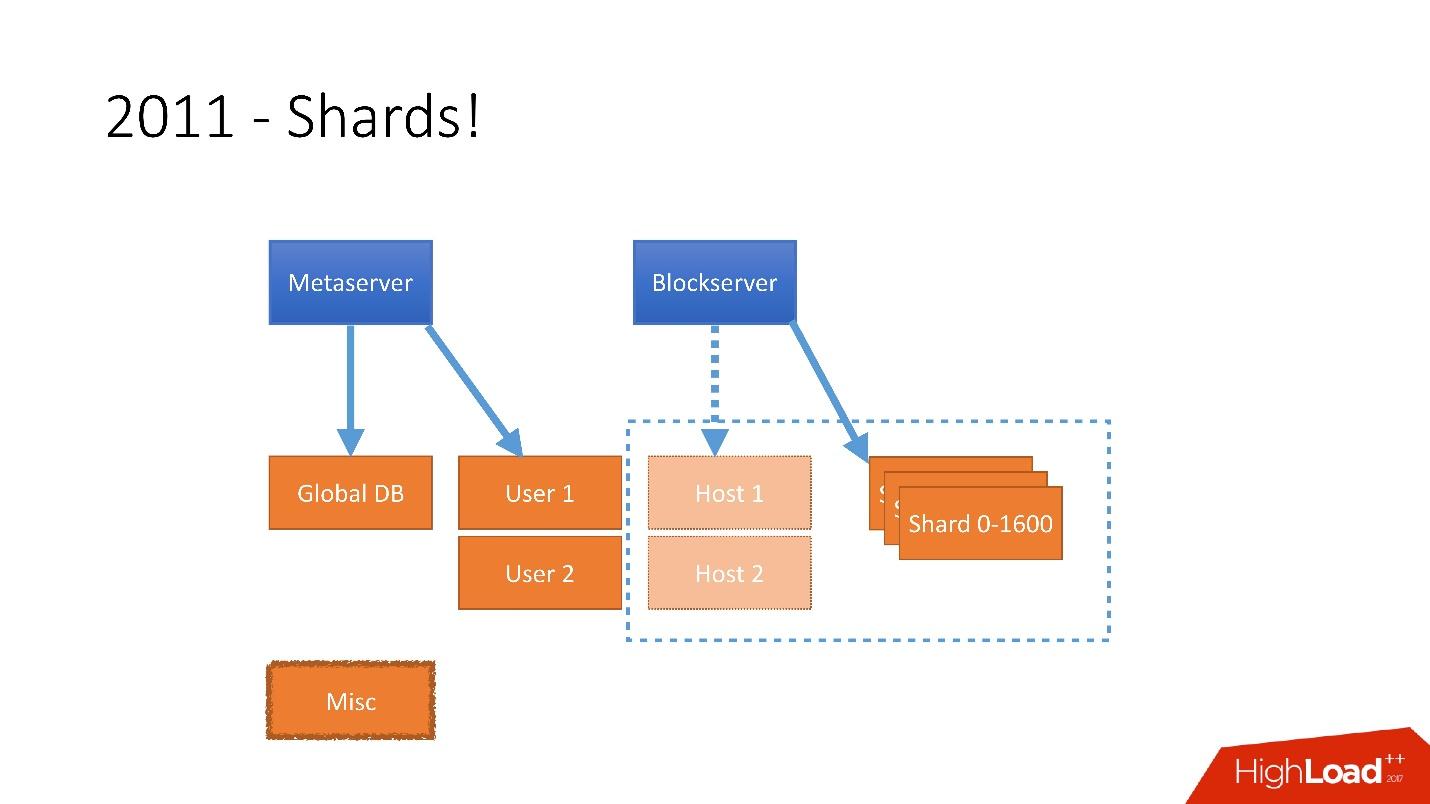
Era necessário levar em consideração um crescimento tão grande e, portanto, no final de 2011, tínhamos shards - uma base composta por 1.600 shards. Inicialmente, apenas 8 servidores com 200 shards cada. Agora são 400 servidores principais com 4 shards em cada um.
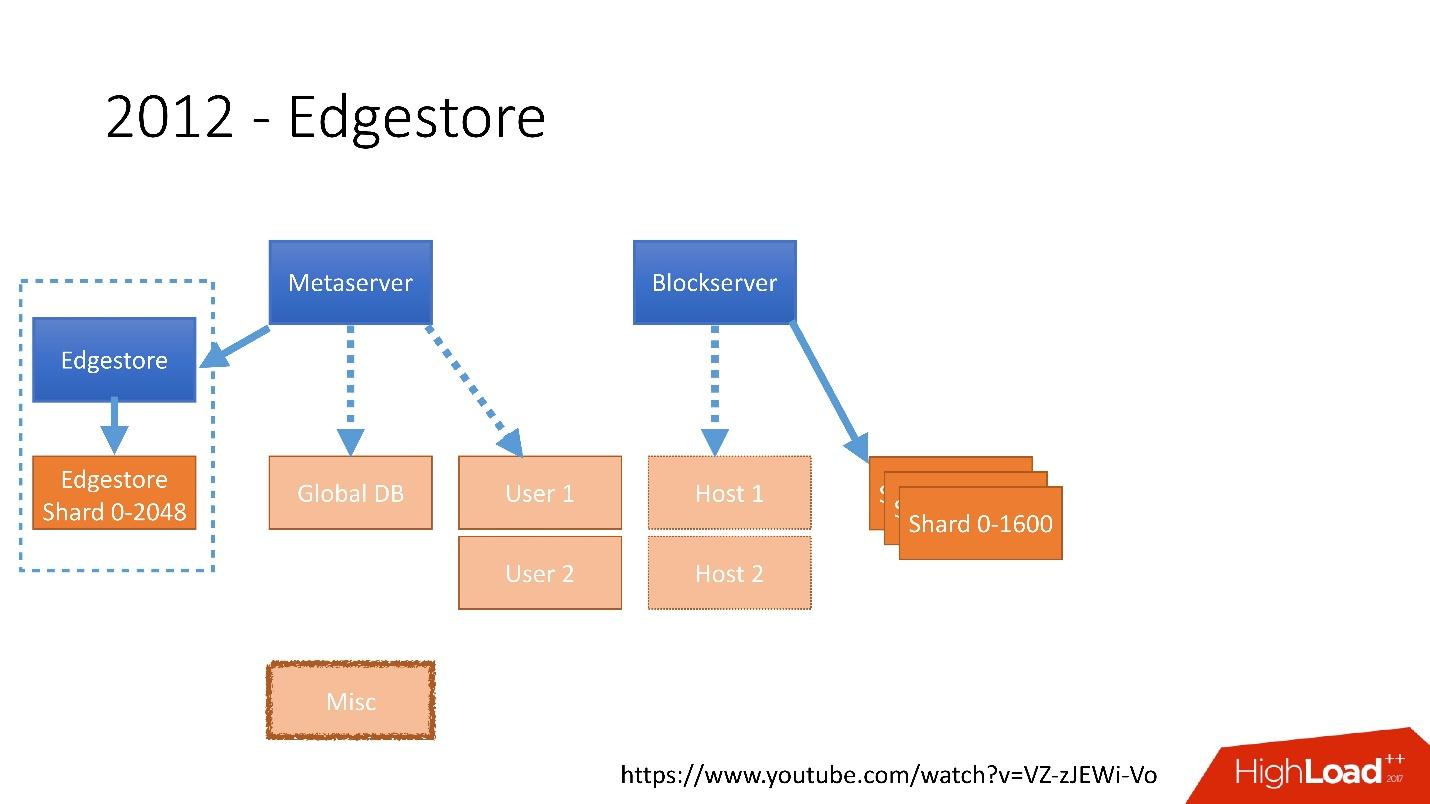 Link do slide
Link do slideEm 2012, percebemos que criar tabelas e atualizá-las no banco de dados para cada lógica de negócios adicionada é muito difícil, sombrio e problemático. Portanto, em 2012, inventamos nosso próprio armazenamento gráfico, que chamamos de
Edgestore , e desde então toda a lógica de negócios e as metainformações que o aplicativo gera são armazenadas no Edgestore.
O Edgestore abstrai essencialmente o MySQL dos clientes. Os clientes têm certas entidades que são interconectadas por links da API do gRPC ao Edgestore Core, que converte esses dados no MySQL e os armazena de alguma forma lá (basicamente, fornece tudo isso a partir do cache).
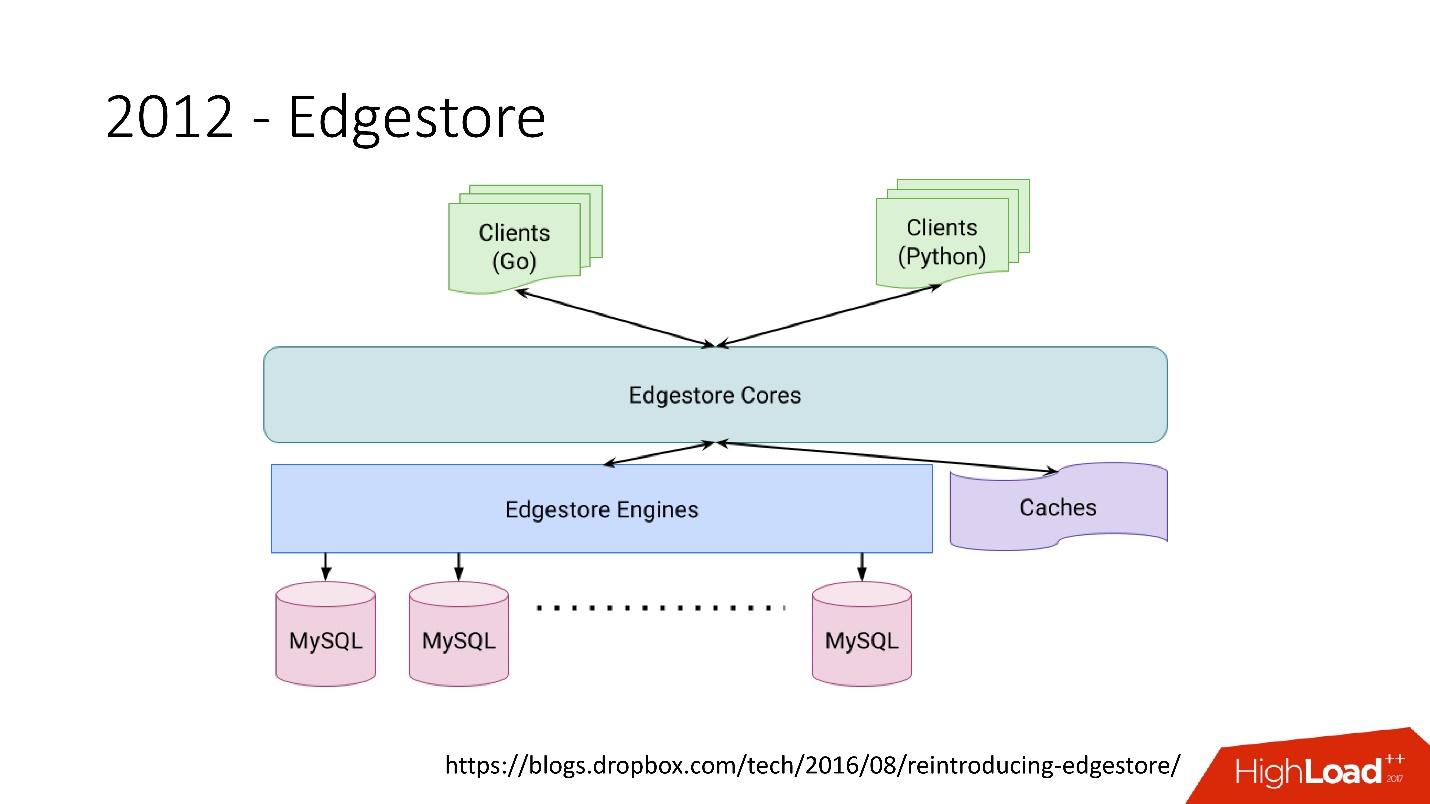 Link do slideEm 2015, saímos do Amazon S3
Link do slideEm 2015, saímos do Amazon S3 , desenvolvemos nosso próprio armazenamento em nuvem chamado Magic Pocket. Ele contém informações sobre onde um arquivo de bloco está localizado, em qual servidor, sobre os movimentos desses blocos entre servidores, armazenados no MySQL.
 Link do slide
Link do slideMas o MySQL é usado de uma maneira muito complicada - em essência, como uma grande tabela de hash distribuída. Essa é uma carga muito diferente, principalmente na leitura de registros aleatórios. 90% da utilização é de E / S.
Arquitetura de banco de dados
Primeiro, identificamos imediatamente alguns princípios pelos quais construímos a arquitetura do nosso banco de dados:
- Confiabilidade e durabilidade . Este é o princípio mais importante e o que os clientes esperam de nós - os dados não devem ser perdidos.
- A otimização da solução é um princípio igualmente importante. Por exemplo, os backups devem ser feitos rapidamente e restaurados rapidamente também.
- Simplicidade da solução - arquiteturalmente e em termos de serviço e suporte adicional ao desenvolvimento.
- Custo de propriedade . Se algo otimiza a solução, mas é muito caro, isso não nos convém. Por exemplo, um escravo que está um dia atrás do mestre é muito conveniente para backups, mas você precisa adicionar mais 1.000 a 6.000 servidores - o custo de propriedade desse escravo é muito alto.
Todos os princípios devem ser
verificáveis e mensuráveis , ou seja, eles devem ter métricas. Se estivermos falando sobre o custo de propriedade, precisamos calcular quantos servidores temos, por exemplo, para bancos de dados, quantos servidores vão para backups e quanto custa para o Dropbox no final. Quando escolhemos uma nova solução, contamos todas as métricas e focamos nelas. Ao escolher qualquer solução, somos totalmente guiados por esses princípios.
Topologia de base
O banco de dados está estruturado da seguinte maneira:
- No data center principal, temos um mestre, no qual todos os registros ocorrem.
- O servidor mestre possui dois servidores escravos nos quais ocorre a replicação semisync. Os servidores geralmente morrem (cerca de 10 por semana), por isso precisamos de dois servidores escravos.
- Servidores escravos estão em clusters separados. Clusters são salas completamente separadas no datacenter que não estão conectadas entre si. Se um quarto queimar, o segundo permanece completamente funcionando.
- Também em outro data center, temos o chamado pseudo mestre (mestre intermediário), que na verdade é apenas um escravo, que tem outro escravo.
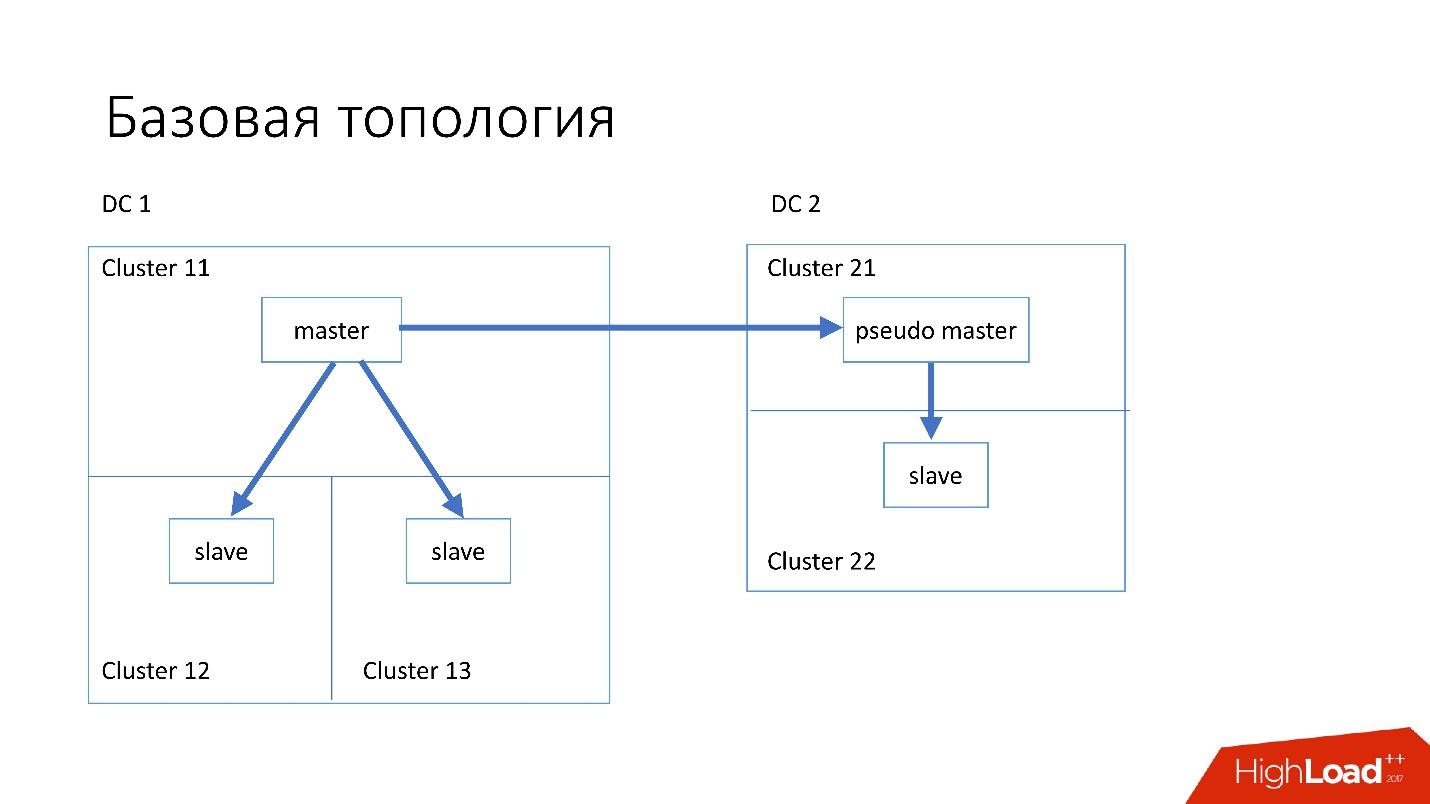
Essa topologia foi escolhida porque, se o primeiro data center morrer repentinamente em nós, no segundo data center, teremos uma
topologia quase completa . Simplesmente alteramos todos os endereços no Discovery, e os clientes podem trabalhar.
Topologias especializadas
Também temos topologias especializadas.
A topologia do
Magic Pocket consiste em um servidor mestre e dois servidores escravos. Isso é feito porque o Magic Pocket duplica os dados entre as zonas. Se ele perder um cluster, poderá restaurar todos os dados de outras zonas através do código de apagamento.

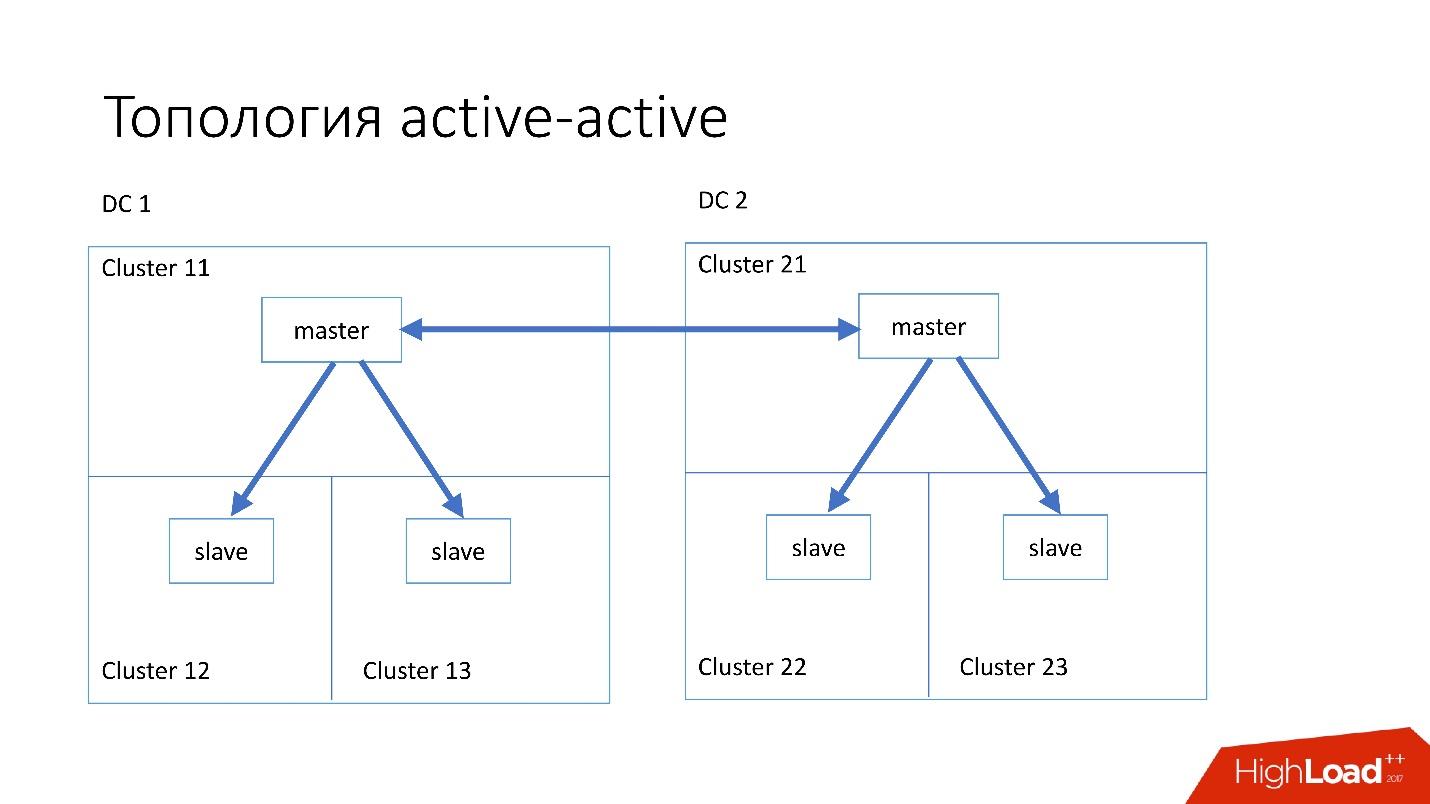
A topologia
ativo-ativo é a topologia customizada usada pelo Edgestore. Ele tem um mestre e dois escravos em cada um dos dois data centers, e eles são escravos um do outro. Esse é um
esquema muito
perigoso , mas o Edgestore, em seu nível, sabe exatamente quais dados em qual mestre e em qual faixa ele pode gravar. Portanto, essa topologia não quebra.
Instância
Instalamos servidores bastante simples com uma configuração de 4-5 anos atrás:
- 2x núcleos Xeon 10;
- 5 TB (8 SSD Raid 0 *);
- 384 GB de memória.
* Raid 0 - porque é mais fácil e muito mais rápido substituir um servidor inteiro do que unidades.
Instância única
Nesse servidor, temos uma instância grande do MySQL na qual vários shards estão localizados. Essa instância do MySQL se aloca imediatamente quase toda a memória. Outros processos também estão em execução no servidor: proxy, coleta de estatísticas, logs etc.
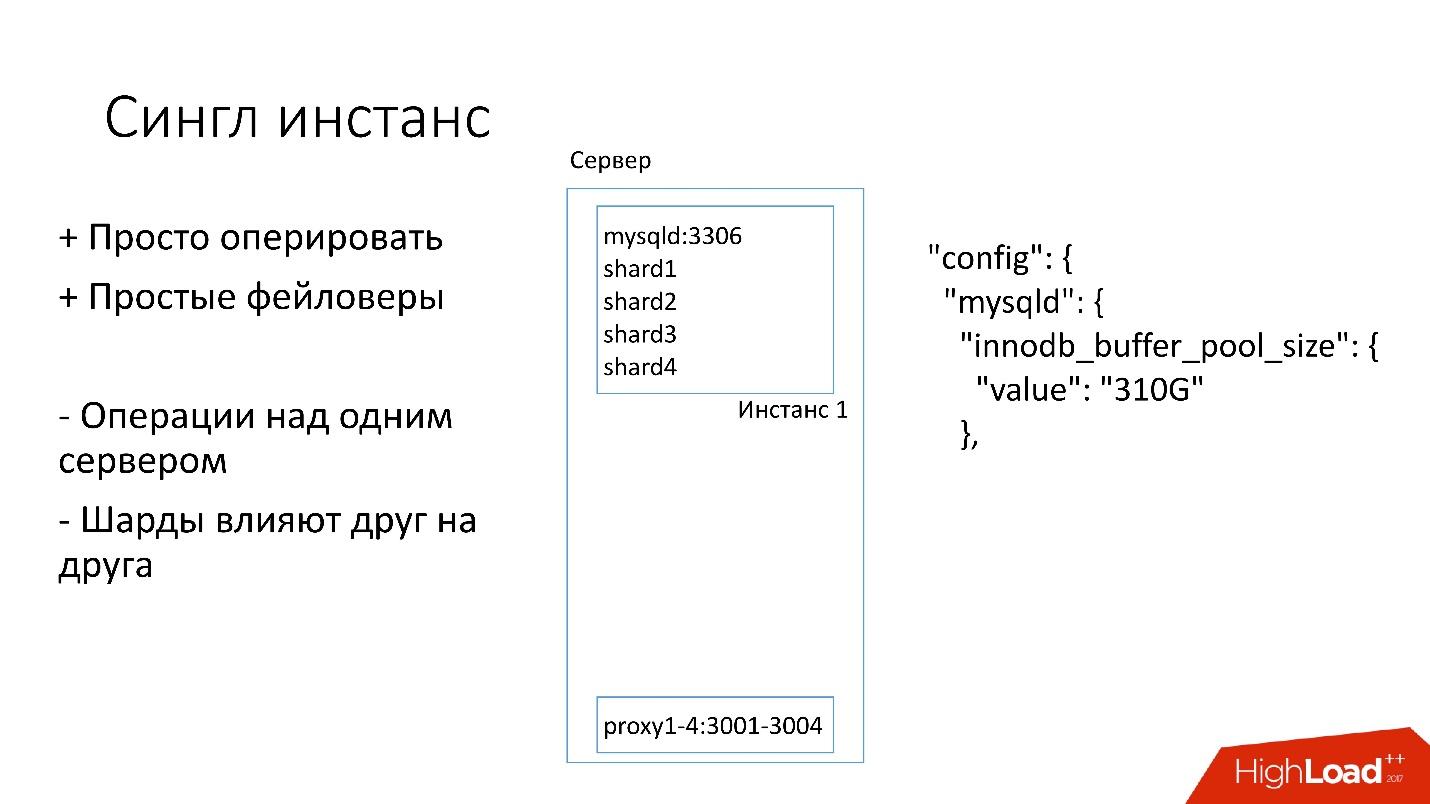
Esta solução é boa em que:
+ É
fácil de gerenciar . Se você precisar substituir a instância do MySQL, basta substituir o servidor.
+
Apenas faça faylovers .
Por outro lado:
- É problemático que qualquer operação ocorra em toda a instância do MySQL e imediatamente em todos os shards. Por exemplo, se você precisar fazer backup, fazemos backup de todos os shards de uma só vez. Se você precisa fazer um faylover, fazemos um faylover de todos os quatro fragmentos de uma só vez. Consequentemente, a acessibilidade sofre 4 vezes mais.
- Problemas com a replicação de um shard afetam outros shards. A replicação do MySQL não é paralela, e todos os shards funcionam em um único thread. Se algo acontecer com um fragmento, o resto também será vítima.
Então agora estamos mudando para uma topologia diferente.
Multi-instância

Na nova versão, várias instâncias do MySQL são iniciadas no servidor ao mesmo tempo, cada uma com um fragmento. O que é melhor?
+ Podemos
realizar operações apenas em um fragmento específico . Ou seja, se você precisar de um faylover, troque apenas um fragmento; se precisar de um backup, fazemos backup de apenas um fragmento. Isso significa que as operações são muito aceleradas - 4 vezes para um servidor de quatro fragmentos.
+ Os
fragmentos quase não se afetam .
+
Melhoria na replicação. Podemos misturar diferentes categorias e classes de bancos de dados. O Edgestore ocupa muito espaço, por exemplo, todos os 4 TB, e o Magic Pocket ocupa apenas 1 TB, mas possui 90% de utilização. Ou seja, podemos combinar diferentes categorias que usam recursos de E / S e da máquina de maneiras diferentes e iniciar quatro fluxos de replicação.
Obviamente, esta solução tem suas desvantagens:
- O maior ponto negativo é que é
muito mais difícil gerenciar tudo isso . Precisamos de um agendador inteligente que entenda para onde ele pode levar essa instância, onde haverá uma carga ideal.
-
Mais difícil que os failovers .
Portanto, apenas agora estamos nos movendo para essa decisão.
Descoberta
De alguma forma, os clientes precisam saber como se conectar ao banco de dados desejado, para que tenhamos o Discovery, que deve:
- Notifique o cliente muito rapidamente sobre alterações na topologia. Se mudarmos de mestre e escravo, os clientes devem aprender quase instantaneamente.
- A topologia não deve depender da topologia de replicação do MySQL, porque em algumas operações alteramos a topologia do MySQL. Por exemplo, quando dividimos, na etapa preparatória do mestre de destino, onde transferiremos parte dos shards, alguns servidores escravos são reconfigurados para esse mestre de destino. Os clientes não precisam saber disso.
- É importante que haja atomicidade das operações e verificação do estado. É impossível que dois servidores diferentes do mesmo banco de dados se tornem mestre no mesmo momento.
Como a descoberta se desenvolveu
No começo, tudo era simples: o endereço do banco de dados no código-fonte na configuração. Quando precisávamos atualizar o endereço, tudo era implantado muito rapidamente.

Infelizmente, isso não funciona se houver muitos servidores.
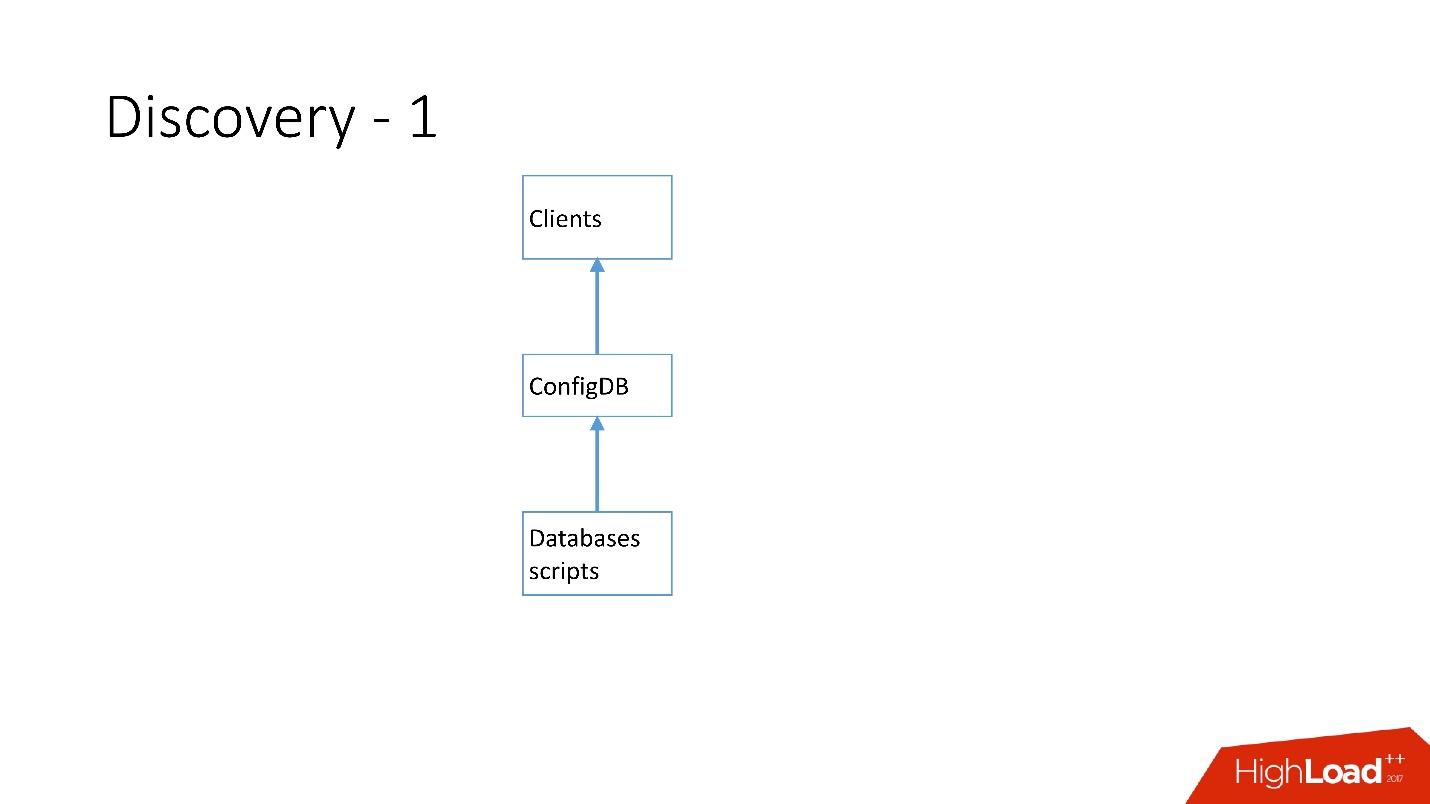
Acima está a primeira descoberta que temos. Havia scripts de banco de dados que alteravam a placa de identificação no ConfigDB - era uma placa de identificação MySQL separada, e os clientes já ouviam esse banco de dados e periodicamente coletavam dados de lá.

A tabela é muito simples, existe uma categoria de banco de dados, uma chave de fragmento, um mestre / escravo de classe de banco de dados, proxy e um endereço de banco de dados. De fato, o cliente solicitou uma categoria, uma classe de banco de dados, uma chave de fragmento e o endereço do MySQL foi retornado para o qual ele já podia estabelecer uma conexão.
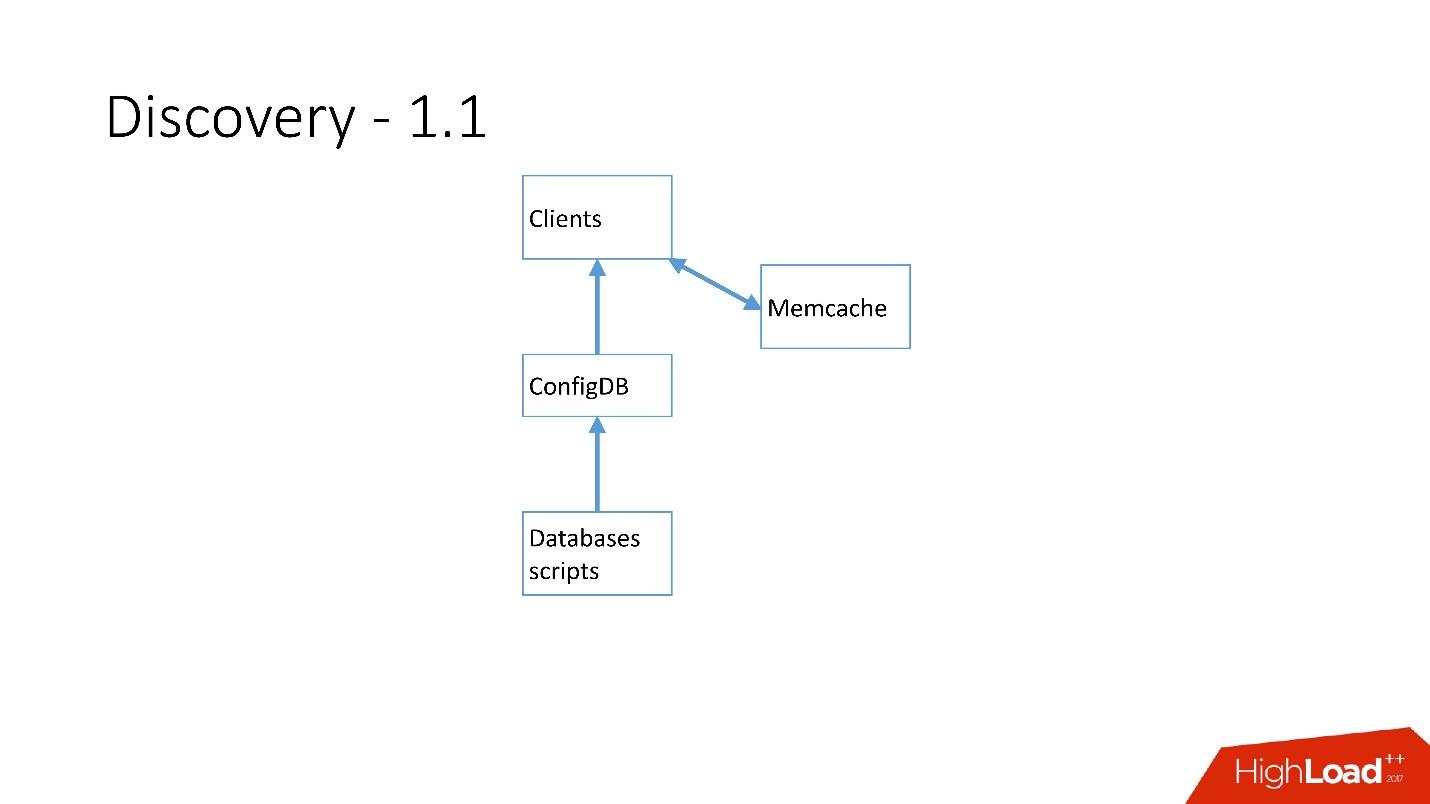
Assim que havia muitos servidores, o Memcache foi adicionado e os clientes começaram a se comunicar com ele.
Mas então nós refizemos isso. Os scripts do MySQL começaram a se comunicar através do gRPC, através de um thin client com um serviço que chamamos de RegisterService. Quando ocorreram algumas alterações, o RegisterService tinha uma fila e ele entendeu como aplicar essas alterações. RegisterService salvou dados no AFS. O AFS é o nosso sistema interno baseado no ZooKeeper.

A segunda solução, que não é mostrada aqui, usava o ZooKeeper diretamente e isso criava problemas porque cada shard era um nó no ZooKeeper. Por exemplo, 100 mil clientes se conectam ao ZooKeeper; se eles morrerem repentinamente devido a algum tipo de bug, 100 mil solicitações ao ZooKeeper serão recebidas imediatamente, o que simplesmente o eliminará e não poderá subir.
Portanto,
o sistema AFS foi desenvolvido
, usado por todo o Dropbox . De fato, ele abstrai o trabalho com o ZooKeeper para todos os clientes. O daemon AFS é executado localmente em cada servidor e fornece uma API de arquivo muito simples do formulário: crie um arquivo, exclua um arquivo, solicite um arquivo, receba uma notificação de alteração de arquivo e compare e troque operações. Ou seja, você pode tentar substituir o arquivo por alguma versão e, se essa versão tiver sido alterada durante a alteração, a operação será cancelada.
Essencialmente, essa abstração no ZooKeeper, na qual existe um algoritmo local de backoff e jitter. O ZooKeeper não trava mais sob carga. Com o AFS, fazemos backups no S3 e no GIT, e o próprio AFS local notifica os clientes que os dados foram alterados.

No AFS, os dados são armazenados como arquivos, ou seja, é uma API do sistema de arquivos. Por exemplo, o acima é o arquivo shard.slave_proxy - o maior, leva cerca de 28 Kb, e quando alteramos a categoria da classe shard e slave_proxy, todos os clientes que assinam esse arquivo recebem uma notificação. Eles releram este arquivo, que contém todas as informações necessárias. Usando a chave shard, eles obtêm uma categoria e reconfiguram o conjunto de conexões com o banco de dados.
Operações
Utilizamos operações muito simples: promoção, clone, backups / recuperação.
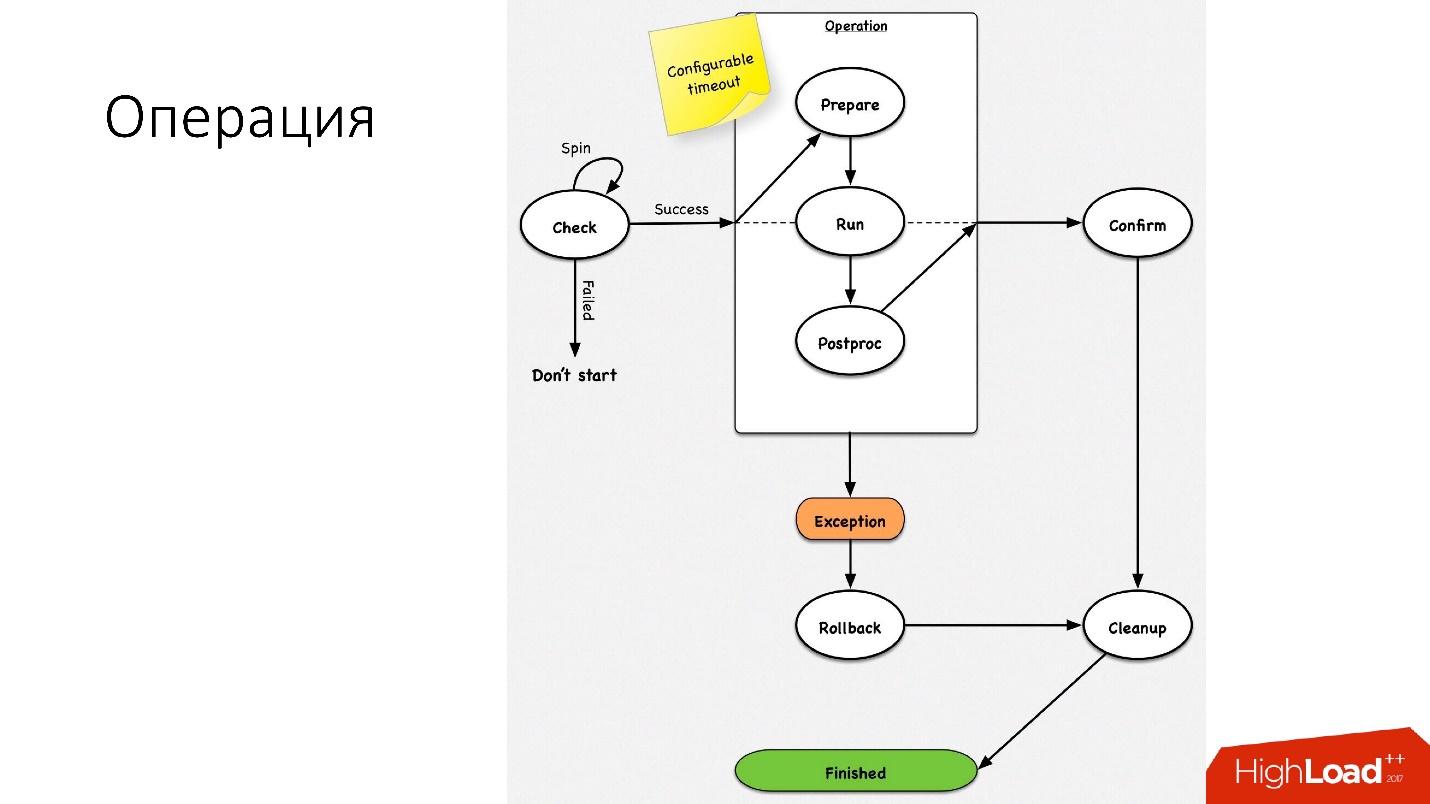 Uma operação é uma máquina de estado simples
Uma operação é uma máquina de estado simples . Quando entramos na operação, realizamos algumas verificações, por exemplo, verificação de rotação, que várias vezes por tempo limite, verificam se podemos executar essa operação. Depois disso, realizamos algumas ações preparatórias que não afetam os sistemas externos. Em seguida, a própria operação.
Todas as etapas em uma operação têm uma
etapa de reversão (desfazer). Se houver um problema com a operação, a operação tentará restaurar o sistema para sua posição original. Se tudo estiver bem, a limpeza ocorre e a operação é concluída.
Temos uma máquina de estado tão simples para qualquer operação.
Promoção (mudança de mestre)
Esta é uma operação muito comum no banco de dados. Havia perguntas sobre como fazer alterações em um servidor mestre quente que funcione - ele terá uma aposta. Só que todas essas operações são executadas em servidores escravos e, em seguida, as mudanças de escravos nos locais principais. Portanto, a
operação de promoção é muito frequente .

Precisamos atualizar o kernel - trocamos, precisamos atualizar a versão do MySQL - atualizamos no slave, mudamos para master, atualizamos lá.

Conseguimos uma promoção muito rápida. Por exemplo,
para quatro fragmentos, agora temos promoção por cerca de 10 a 15 s. O gráfico acima mostra que, com a disponibilidade da promoção, sofreu 0,0003%.
Mas a promoção normal não é tão interessante, porque essas são operações comuns que são realizadas todos os dias. Failovers são interessantes.
Failover (substituição de um mestre danificado)
Um failover significa que o banco de dados está morto.
- Se o servidor realmente morreu, este é apenas um caso ideal.
- De fato, acontece que os servidores estão parcialmente ativos.
- Às vezes, o servidor morre muito lentamente. Os controladores RAID, o sistema de disco falham, alguns pedidos retornam respostas, mas alguns fluxos são bloqueados e não retornam respostas.
- Acontece que o mestre está simplesmente sobrecarregado e não responde ao nosso exame de saúde. Mas se fizermos promoção, o novo mestre também ficará sobrecarregado e só piorará.
A substituição dos servidores principais falecidos ocorre cerca de
2-3 vezes por dia ; esse é um processo totalmente automatizado, sem necessidade de intervenção humana. A seção crítica leva cerca de 30 segundos e possui várias verificações adicionais para verificar se o servidor está realmente ativo ou se ele já morreu.
Abaixo está um exemplo de diagrama de como o faylover funciona.

Na seção selecionada,
reinicializamos o servidor principal . Isso é necessário porque temos o MySQL 5.6 e nele a replicação semi-sincronizada não é sem perdas. Portanto, leituras fantasmas são possíveis, e precisamos desse mestre, mesmo que ele não tenha morrido, mate o mais rápido possível para que os clientes se desconectem. Portanto, fazemos uma reinicialização total via Ipmi - esta é a primeira operação mais importante que devemos realizar. Na versão MySQL 5.7, isso não é tão crítico.
Sincronização de cluster. Por que precisamos de sincronização de cluster?
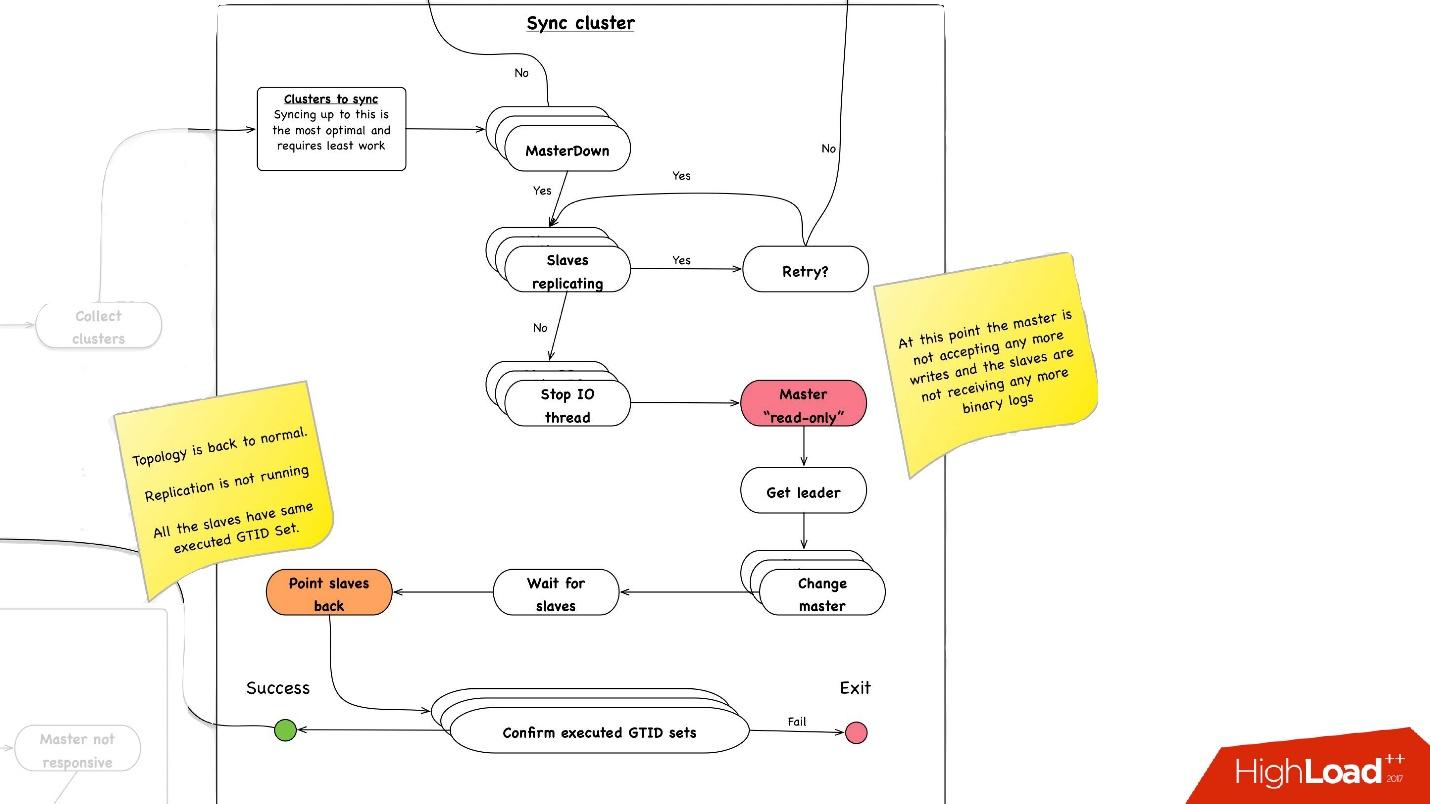
Se recordarmos a figura anterior com nossa topologia, um servidor mestre possui três servidores escravos: dois em um datacenter, um no outro. Com a promoção, precisamos que o mestre esteja no mesmo data center principal. Mas, às vezes, quando os escravos são carregados, com semisync, acontece que um escravo semisync se torna escravo em outro datacenter, porque não está carregado. Portanto, primeiro precisamos sincronizar o cluster inteiro e, em seguida, já promover o escravo no datacenter de que precisamos. Isso é feito de maneira muito simples:
- Paramos todo o encadeamento de E / S em todos os servidores escravos.
- Depois disso, já sabemos ao certo que o mestre é "somente leitura", pois o semisync foi desconectado e ninguém mais pode escrever nada lá.
- Em seguida, selecionamos o escravo com o maior conjunto GTID recuperado / executado, ou seja, com a maior transação que ele baixou ou já aplicou.
- Reconfiguramos todos os servidores escravos para esse escravo selecionado, iniciamos o encadeamento de E / S e eles são sincronizados.
- Esperamos até que sejam sincronizados, após o que todo o cluster se torna sincronizado. , executed GTID set .
—
.
promotion , :
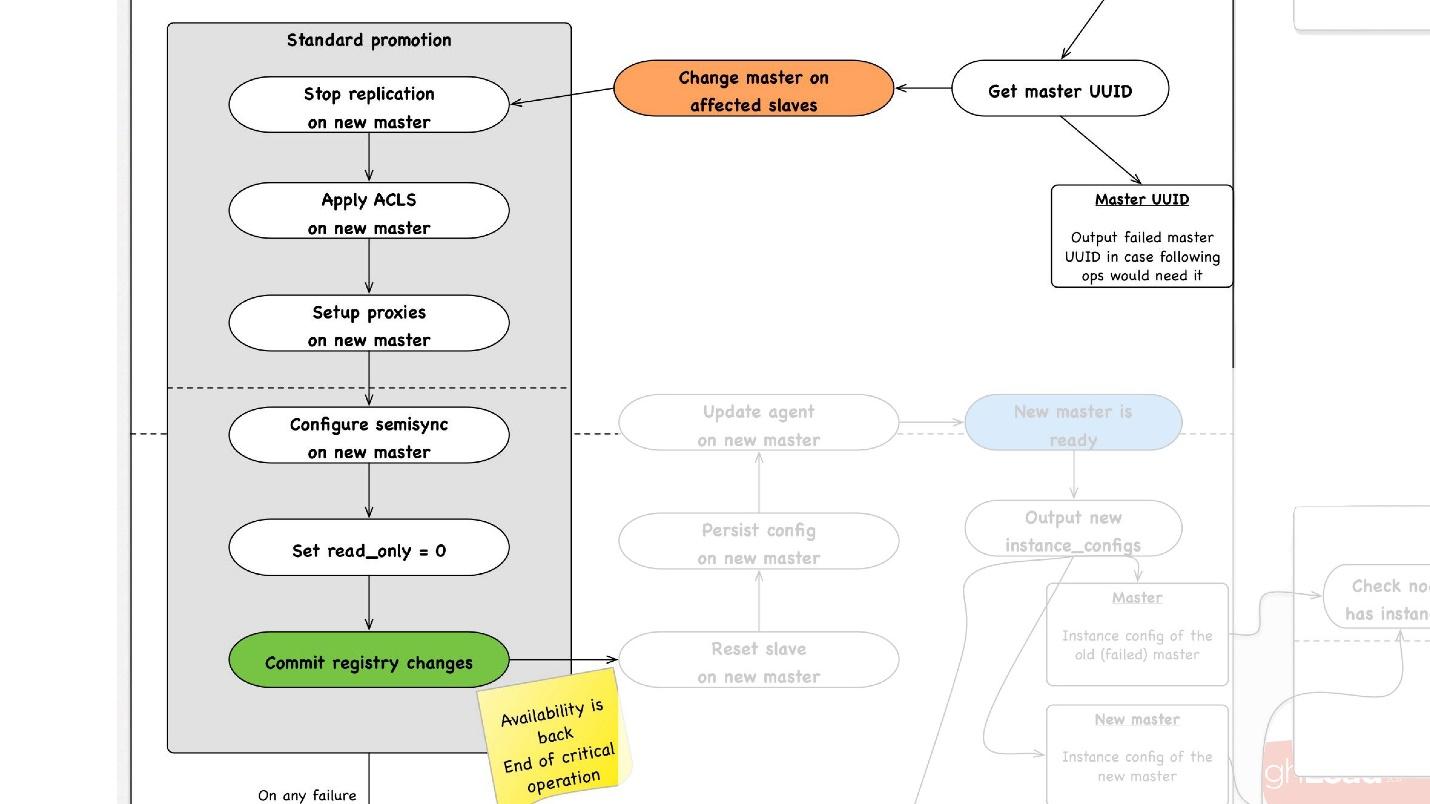
- slave -, , master, promotion.
- slave- master, , ACLs, , - proxy, , - .
- read_only = 0, , master , . master .
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
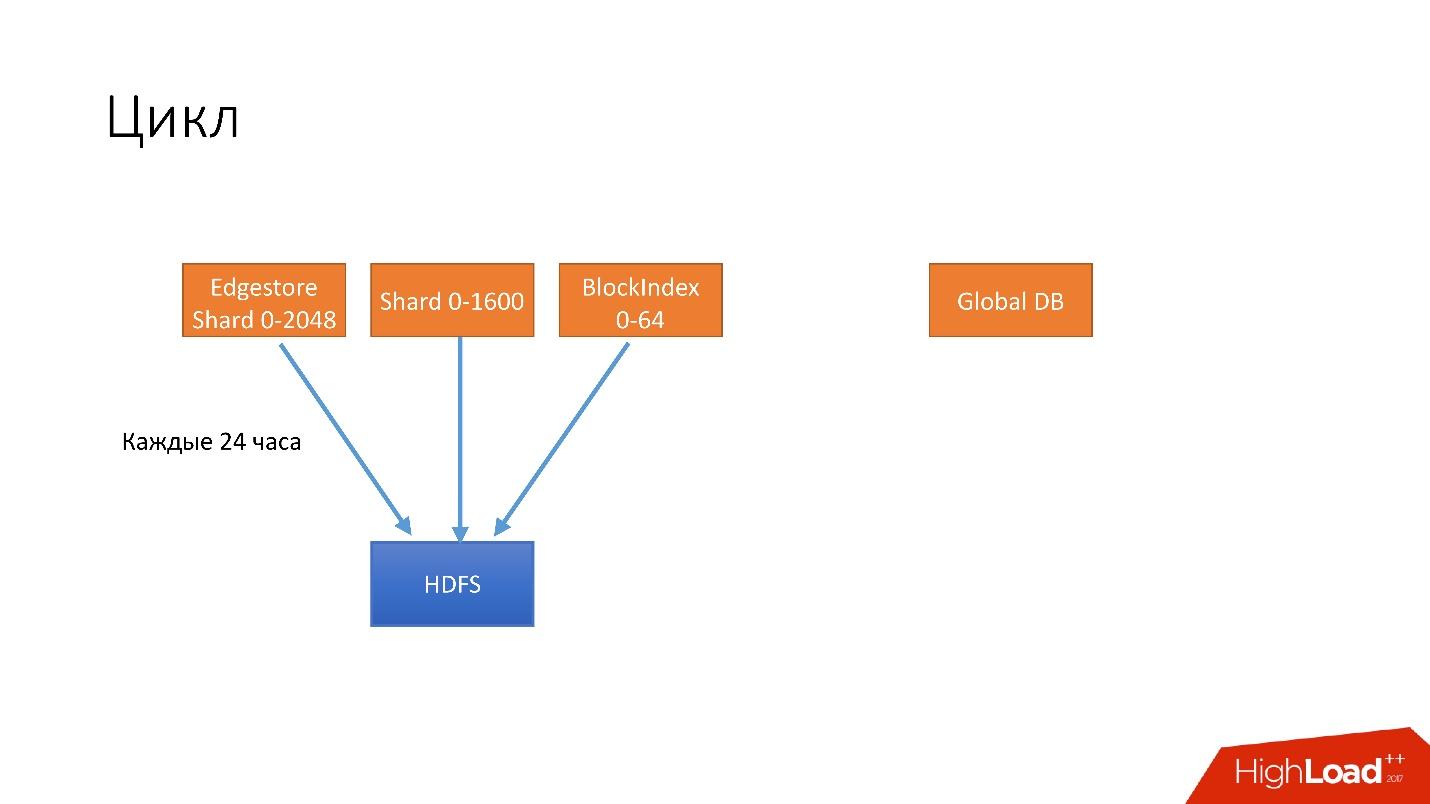
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
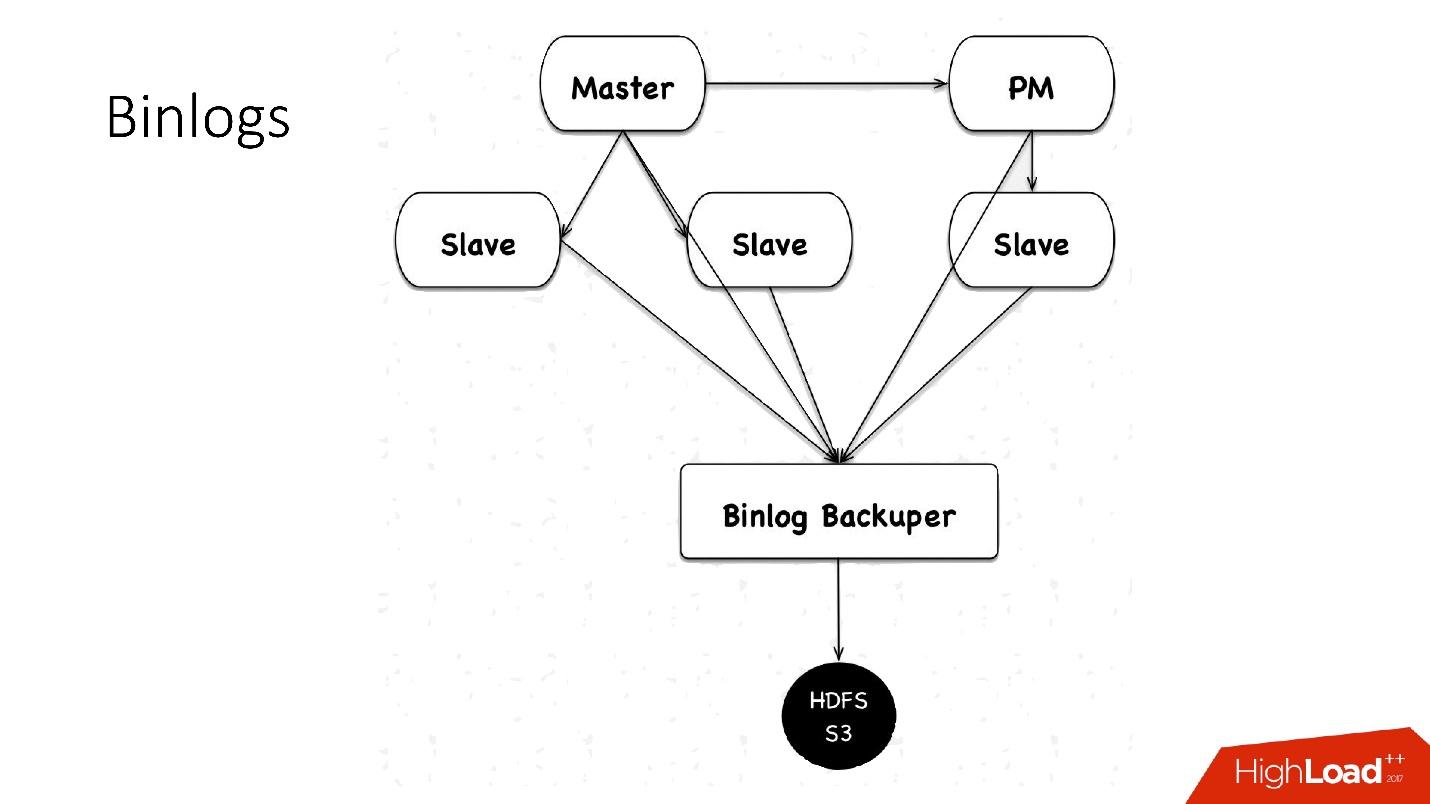
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . .
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
Automação
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
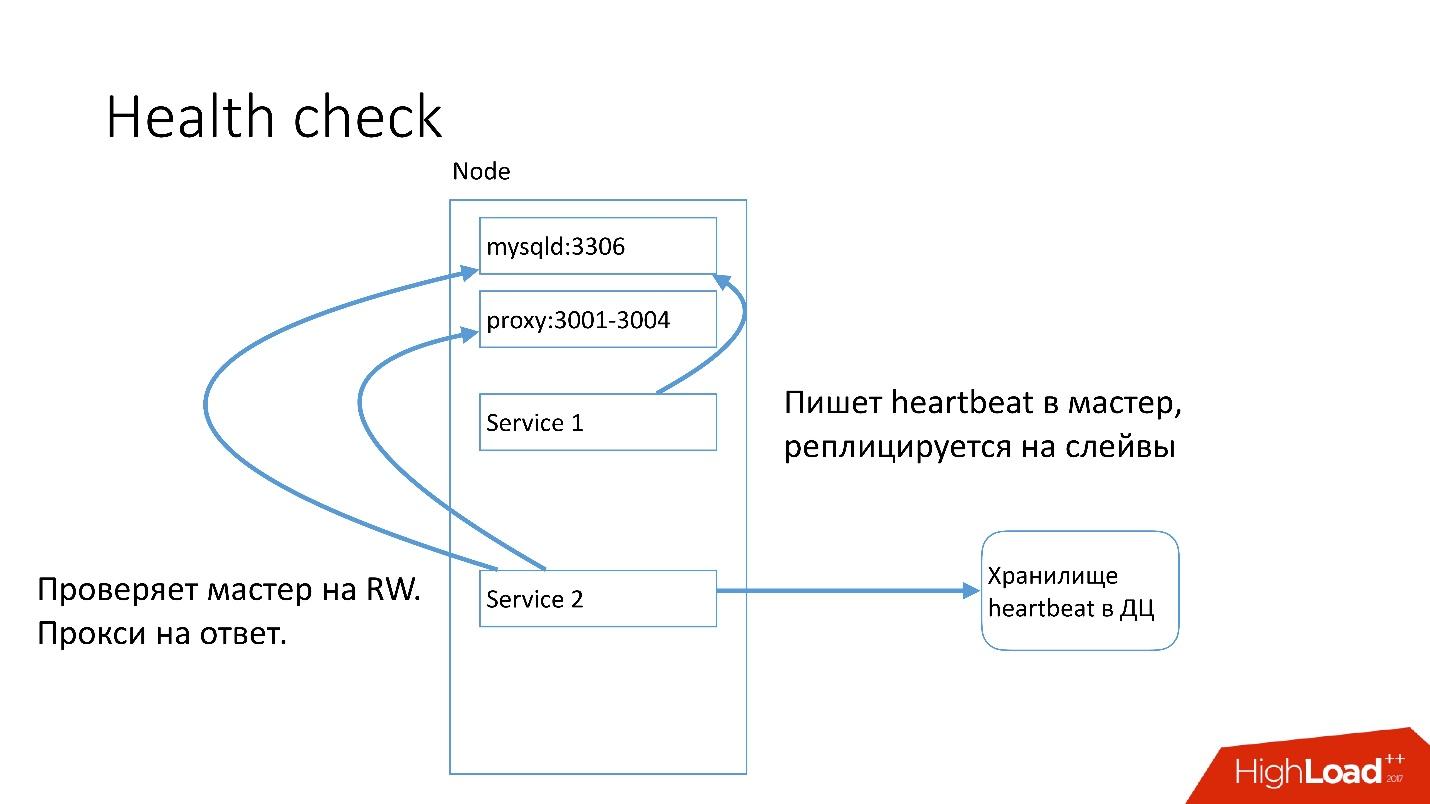
, , , master read-write. heartbeat.
auto-replace , .
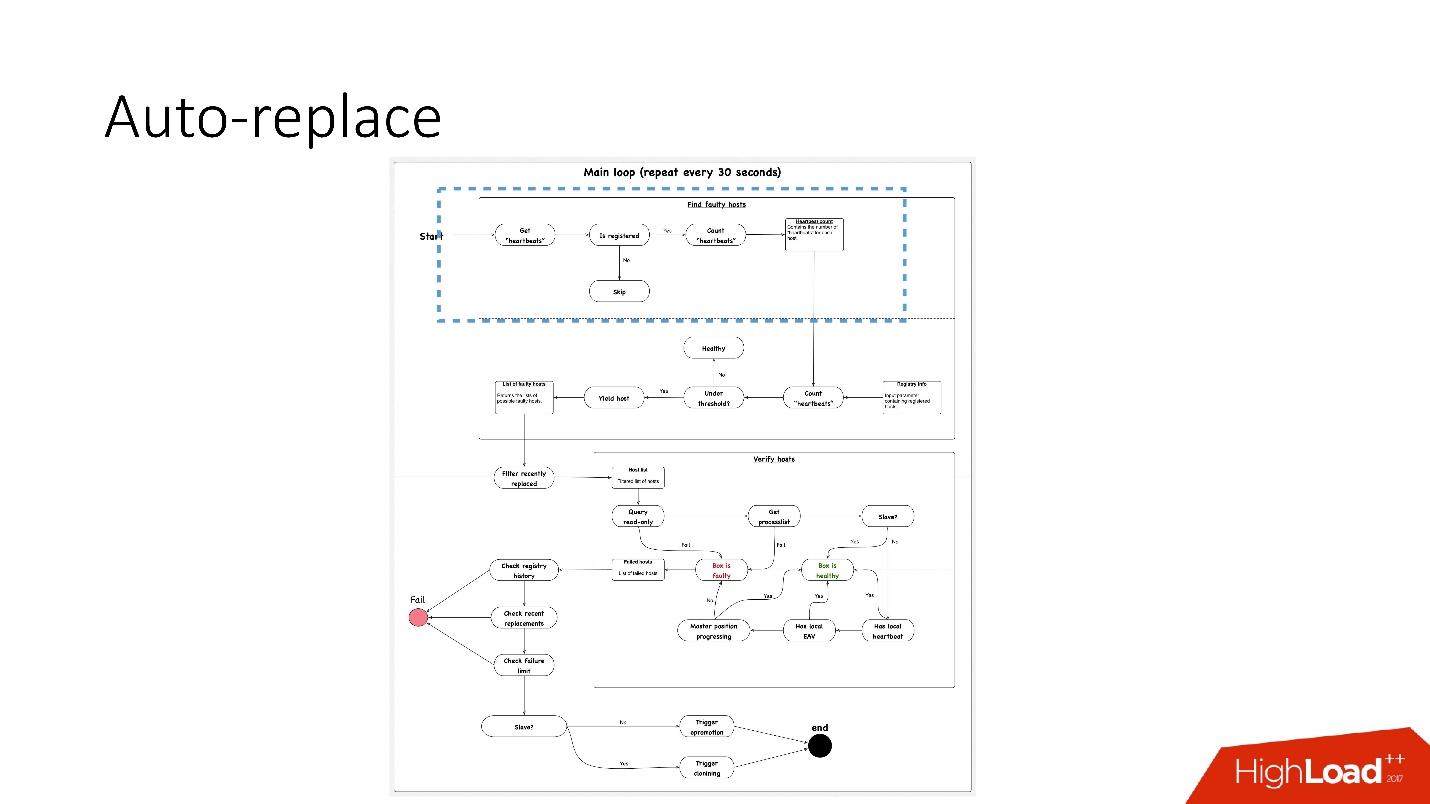 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- A seguir, veja se o número deles atende ao valor limite. Caso contrário, algo está errado com o servidor - pois ele não enviou um batimento cardíaco.
- Depois disso, fazemos uma verificação inversa, apenas por precaução - de repente esses dois serviços morreram, algo está com a rede ou o banco de dados global não pode gravar o batimento cardíaco por algum motivo. Na verificação inversa, nos conectamos a um banco de dados quebrado e verificamos seu status.
- Se tudo mais falhar, verificamos se a posição principal está progredindo ou não, se há registros nela. Se nada acontecer, esse servidor definitivamente não está funcionando.
- O último passo é realmente substituir automaticamente.
A substituição automática é muito conservadora, ele nunca quer fazer muitas operações automáticas.
- Primeiro, verificamos se houve alguma operação de topologia recentemente? Talvez este servidor tenha sido adicionado e algo ainda não esteja sendo executado.
- Verificamos se houve alguma substituição no mesmo cluster a qualquer momento.
- Verifique qual o limite de falhas que temos. Se tivermos muitos problemas ao mesmo tempo - 10, 20 -, não os resolveremos automaticamente automaticamente, pois podemos interromper inadvertidamente a operação de todos os bancos de dados.
Portanto,
resolvemos apenas um problema de cada vez .
Assim, para o servidor escravo, começamos a clonar e simplesmente a removemos da topologia e, se for mestre, lançamos o amante-fey, a chamada promoção de emergência.
DBManager
DBManager é um serviço para gerenciar nossos bancos de dados. Tem:
- agendador de tarefas inteligente que sabe exatamente quando iniciar o trabalho;
- logs e todas as informações: quem, quando e o que foi lançado - essa é a fonte da verdade;
- ponto de sincronização.
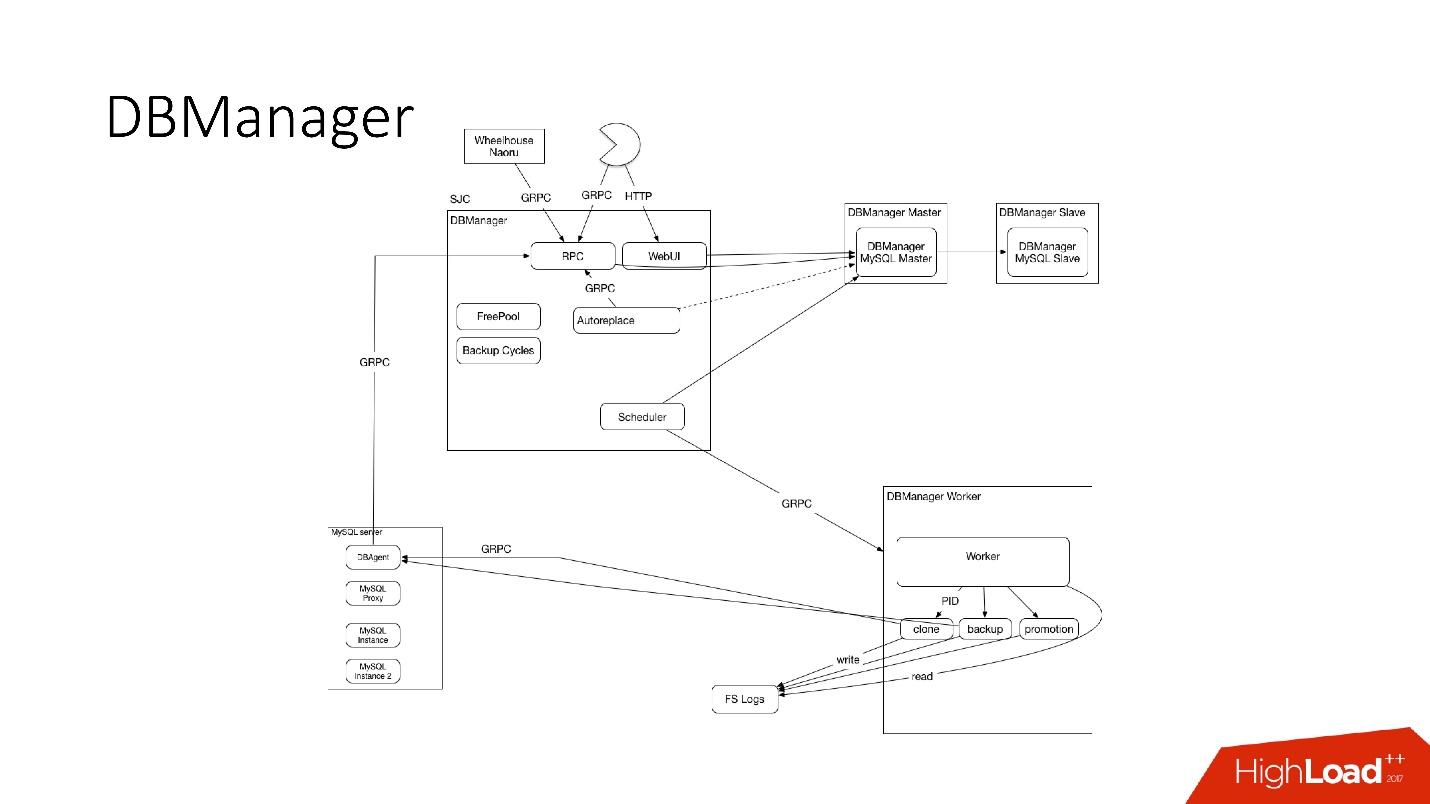
O DBManager é bastante simples em termos de arquitetura.
- Existem clientes, o DBA que faz algo através da interface da Web ou scripts / serviços que criaram o DBA que acessam via gRPC.
- Existem sistemas externos como Wheelhouse e Naoru, que acessam o DBManager via gRPC.
- Há um agendador que entende qual operação, quando e onde ele pode começar.
- Há um trabalhador muito estúpido que, quando uma operação chega a ele, a inicia, verifica pelo PID. O trabalhador pode reiniciar, os processos não são interrompidos. Todos os trabalhadores estão localizados o mais próximo possível dos servidores nos quais as operações ocorrem, de modo que, por exemplo, ao atualizar o ACLS, não precisamos fazer muitas viagens de ida e volta.
- Em cada host SQL, temos um DBAgent - este é um servidor RPC. Quando você precisar executar alguma operação no servidor, enviamos uma solicitação de RPC.
Temos uma interface da web para o DBManager, na qual é possível ver as tarefas atualmente em execução, os registros dessas tarefas, quem a iniciou e quando, quais operações foram executadas para o servidor de um banco de dados específico etc.
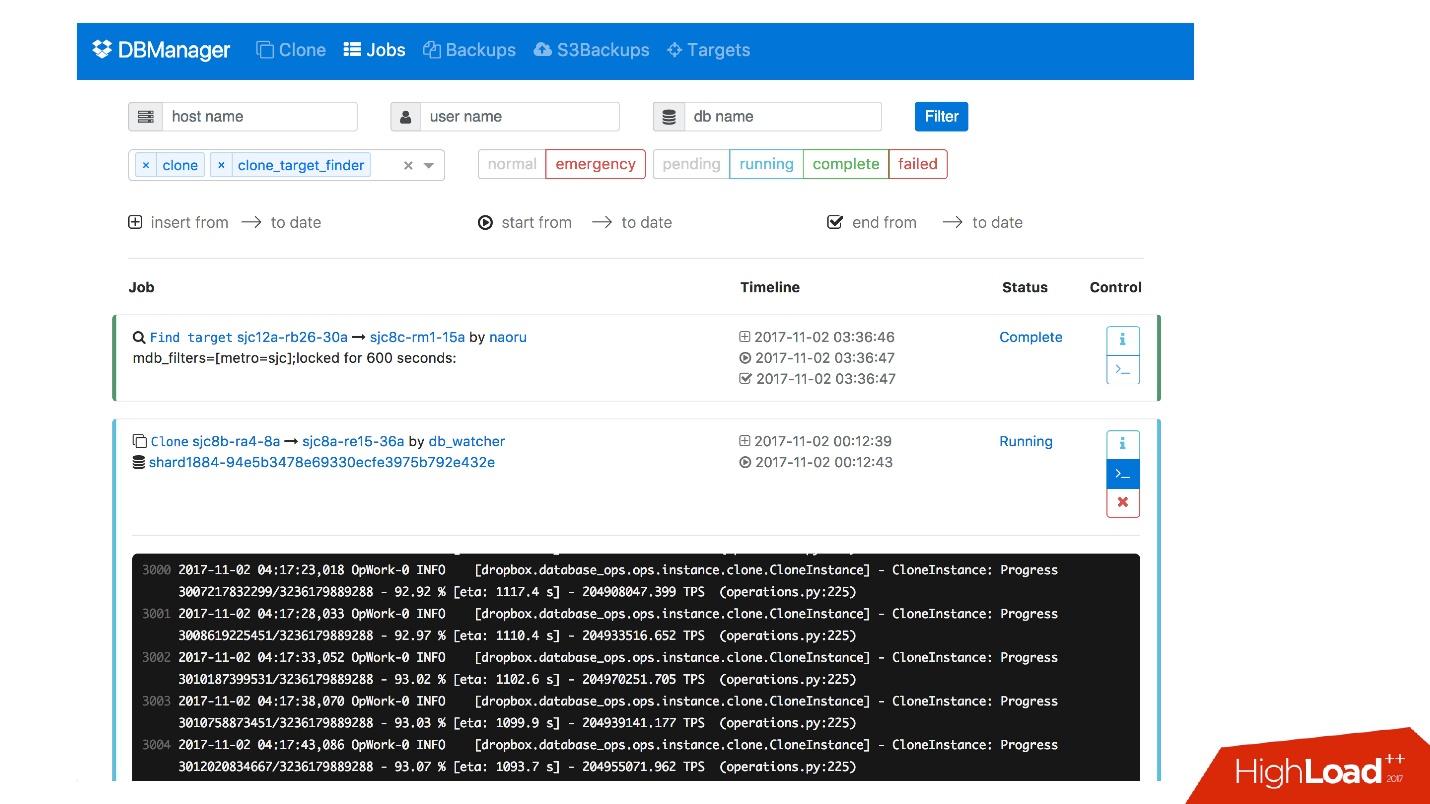
Existe uma interface CLI bastante simples onde você pode executar tarefas e também visualizá-las em visualizações convenientes.
Remediações
Também temos um sistema para responder a problemas. Quando algo está quebrado, por exemplo, a unidade falha ou algum serviço não funciona, o
Naoru funciona
. Este é o sistema que funciona em todo o Dropbox, todo mundo usa e é construído especificamente para tarefas tão pequenas. Eu falei sobre Naoru no meu
relatório em 2016.
O Wheelhouse é baseado em uma máquina de
estado e foi projetado para processos longos. Por exemplo, precisamos atualizar o kernel em todo o MySQL em todo o nosso cluster de 6.000 máquinas. A Wheelhouse faz isso claramente - atualiza no servidor escravo, lança promoção, escravo se torna mestre, atualiza no servidor mestre. Esta operação pode levar um mês ou até dois.
Monitoramento

Isso é muito importante.
Se você não monitorar o sistema, provavelmente não funcionará.
Monitoramos tudo no MySQL - todas as informações que podemos obter do MySQL são armazenadas em algum lugar, podemos acessá-las a tempo. Armazenamos informações no InnoDb, estatísticas sobre solicitações, transações, duração das transações, percentual sobre duração das transações, replicação, rede, tudo em um grande número de métricas.
Alerta
Temos 992 alertas configurados. De fato, ninguém está olhando para métricas, parece-me que não há pessoas que vêm trabalhar e começam a olhar para o gráfico de métricas, há tarefas mais interessantes.

Portanto, existem alertas que funcionam quando determinados valores de limite são atingidos.
Temos 992 alertas, aconteça o que acontecer, descobriremos sobre isso .
Incidentes

Temos o PagerDuty - um serviço através do qual alertas são enviados para pessoas responsáveis que começam a agir.

Nesse caso, ocorreu um erro na promoção de emergência e, imediatamente após isso, um alerta foi registrado, que o mestre caiu. Depois disso, o oficial de serviço verificou o que impedia a promoção de emergência e fez as operações manuais necessárias.
Certamente analisaremos cada incidente que ocorreu; para cada incidente, temos uma tarefa no rastreador de tarefas. Mesmo que esse incidente seja um problema em nossos alertas, também criamos uma tarefa, porque se o problema estiver na lógica e nos limites dos alertas, eles precisarão ser alterados. Os alertas não devem apenas estragar a vida das pessoas. Um alerta é sempre doloroso, especialmente às 4 da manhã.
Teste
Como no monitoramento, tenho certeza de que todos estão testando. Além dos testes de unidade com os quais cobrimos nosso código, temos testes de integração nos quais testamos:
- todas as topologias que temos;
- todas as operações nessas topologias.
Se tivermos operações de promoção, testamos as operações de promoção no teste de integração. Se temos clonagem, fazemos clonagem para todas as topologias que temos.
Exemplo de topologia
Temos topologias para todas as ocasiões: 2 data centers com várias instâncias, com shards, sem shards, com clusters, um datacenter - geralmente quase qualquer topologia - mesmo aqueles que não usamos, apenas para ver.

Neste arquivo, apenas temos as configurações, quais servidores e com o que precisamos aumentar. Por exemplo, precisamos elevar o mestre e dizemos que precisamos fazer isso com tais e tais dados de instância, com tais e tais bancos de dados em tais e em tais portas. Quase tudo está indo junto com o Bazel, que cria uma topologia com base nesses arquivos, inicia o servidor MySQL e o teste é iniciado.

O teste parece muito simples: indicamos qual topologia está sendo usada. Neste teste, testamos auto_replace.
- Criamos o serviço auto_replace, iniciamos.
- Matamos o mestre em nossa topologia, esperamos um pouco e vemos que o escravo-alvo se tornou mestre. Caso contrário, o teste falhou.
Etapas
Os ambientes de palco são os mesmos bancos de dados da produção, mas não há tráfego de usuários, mas há algum tráfego sintético semelhante à produção por meio do Percona Playback, sysbench e sistemas similares.
No Percona Playback, registramos o tráfego e depois o perdemos no ambiente de palco com diferentes intensidades, podemos perder 2-3 vezes mais rápido. Ou seja, é artificial, mas muito próximo da carga real.
Isso é necessário porque nos testes de integração não podemos testar nossa produção. Não podemos testar o alerta ou o fato de as métricas funcionarem. Na fase de teste, testamos alertas, métricas, operações, periodicamente matamos os servidores e vemos que eles são coletados normalmente.
Além disso, testamos toda a automação juntos, porque nos testes de integração, muito provavelmente, uma parte do sistema é testada e, na preparação, todos os sistemas automatizados funcionam simultaneamente. Às vezes, você pensa que o sistema se comportará dessa maneira e não de outra forma, mas pode se comportar de uma maneira completamente diferente.
DRT (teste de recuperação de desastre)
Também realizamos testes de produção - diretamente em bases reais. Isso é chamado de teste de recuperação de falhas. Por que precisamos disso?
● Queremos testar nossas garantias.
Isso é feito por muitas grandes empresas. Por exemplo, o Google tem um serviço que funcionou de forma tão estável - 100% do tempo - que todos os serviços que o utilizaram decidiram que esse serviço é realmente 100% estável e nunca falha. Portanto, o Google teve que abandonar esse serviço de propósito, para que os usuários levassem em conta essa possibilidade.
Então, nós somos - temos uma garantia de que o MySQL funciona - e, às vezes, não funciona! E temos a garantia de que pode não funcionar por um determinado período de tempo; os clientes devem levar isso em consideração. De tempos em tempos, matamos o mestre de produção ou, se queremos fazer um escravo, matamos todos os escravos para ver como se comporta a replicação semisync.
● Os clientes estão preparados para esses erros (substituição e morte do mestre)
Por que isso é bom? Tivemos um caso em que, durante a promoção de 4 fragmentos de 1600, a disponibilidade caiu para 20%. Parece que algo está errado, para 4 fragmentos de 1600 deve haver outros números. Os failovers para esse sistema eram raros, cerca de uma vez por mês, e todos decidiram: "Bem, é um failover, acontece".
Em algum momento, quando mudamos para um novo sistema, uma pessoa decidiu otimizar esses dois serviços de gravação de batimentos cardíacos e combinou-os em um. Este serviço fez outra coisa e, no final, morreu e os batimentos cardíacos pararam de gravar. Aconteceu que, para esse cliente, tínhamos 8 faylovers por dia. Tudo estava - 20% de disponibilidade.
Aconteceu que, neste cliente, o keep-alive é de 6 horas. Assim, assim que o mestre morreu, mantivemos todas as conexões por mais 6 horas. O pool não pôde continuar funcionando - suas conexões são mantidas, são limitadas e não funcionam. Foi consertado.
Fazemos o amor de novo - não mais 20%, mas ainda muito. Algo ainda está errado. Aconteceu que um erro na implementação do pool. Quando solicitado, a piscina virou muitos fragmentos e, em seguida, conectou tudo isso. Se alguns fragmentos estavam febris, alguma condição de corrida ocorreu no código Go, e todo o pool estava entupido. Todos esses fragmentos não podiam mais funcionar.
O teste de recuperação de desastre é muito útil, porque os clientes devem estar preparados para esses erros, eles devem verificar seu código.
● Além disso, o teste de recuperação de desastres é bom porque ocorre durante o horário comercial e tudo está no lugar, menos estresse, as pessoas sabem o que acontecerá agora. Isso não acontece à noite e é ótimo.
Conclusão
1. Tudo precisa ser automatizado, nunca coloque as mãos nele.
Toda vez que alguém entra no sistema com nossas mãos, tudo morre e quebra em nosso sistema - sempre! - mesmo em operações simples. Por exemplo, um escravo morreu, uma pessoa teve que adicionar um segundo, mas decidiu remover o escravo morto com as mãos da topologia. No entanto, em vez do falecido, ele copiou para o comando live - master foi deixado sem escravo. Tais operações não devem ser feitas manualmente.
2. Os testes devem ser contínuos e automatizados (e em produção).
Seu sistema está mudando, sua infraestrutura está mudando. Se você verificou uma vez e pareceu funcionar, isso não significa que funcionará amanhã. Portanto, você precisa fazer testes automatizados constantemente todos os dias, inclusive na produção.
3. Certifique-se de possuir clientes (bibliotecas).
Os usuários podem não saber como os bancos de dados funcionam. Eles podem não entender por que os intervalos são necessários, mantenha-vivos. Portanto, é melhor possuir esses clientes - você ficará mais calmo.
4. É necessário determinar seus princípios para a construção do sistema e suas garantias, e sempre cumpri-los.
Assim, você pode suportar 6 mil servidores de banco de dados.
Nas perguntas após o relatório, e principalmente nas respostas, também há muitas informações úteis.Perguntas e Respostas
- O que acontecerá se houver um desequilíbrio na carga dos shards - algumas meta-informações sobre algum arquivo acabaram sendo mais populares? É possível difundir esse fragmento, ou a carga nos fragmentos não difere em lugar nenhum por ordens de magnitude?
Ela não difere por ordens de magnitude. É quase normalmente distribuído. Temos limitação, ou seja, não podemos sobrecarregar o fragmento, estamos limitando no nível do cliente. Em geral, acontece que alguma estrela envia uma foto e o fragmento praticamente explode. Então banimos esse link
- Você disse que possui 992 alertas. Você poderia elaborar o que é - está pronto ou foi criado? Se criado, é trabalho manual ou algo como aprendizado de máquina?
Tudo isso é criado manualmente. Temos nosso próprio sistema interno chamado Vortex, onde as métricas são armazenadas, os alertas são suportados. Há um arquivo yaml que diz que há uma condição, por exemplo, de que os backups devem ser executados todos os dias e, se essa condição for atendida, o alerta não funcionará. Se não for executado, um alerta será recebido.
Esse é o nosso desenvolvimento interno, porque poucas pessoas podem armazenar quantas métricas forem necessárias.
- Quão fortes devem ser os nervos para fazer DRT? Você caiu, CODERED, não aumenta, com cada minuto de pânico a mais.
Em geral, trabalhar em bancos de dados é realmente uma dor. Se o banco de dados travar, o serviço não funcionará, o Dropbox inteiro não funcionará. Isso é uma verdadeira dor. A DRT é útil na medida em que é um relógio de negócios. Ou seja, estou pronto, estou sentado na minha mesa, tomei café, sou fresco, estou pronto para fazer qualquer coisa.
Pior quando acontece às 4 da manhã, e não é DRT. Por exemplo, a última grande falha que tivemos recentemente. Ao injetar um novo sistema, esquecemos de definir a pontuação do OOM para o nosso MySQL. Havia outro serviço que lia binlog. Em algum momento, nosso operador é manual - novamente manualmente! - executa o comando para excluir algumas informações na tabela de soma de verificação Percona. Apenas uma exclusão simples, uma operação simples, mas essa operação gerou um enorme log de bin. O serviço leu esse binlog na memória, o OOM Killer veio e pensa em quem matar? E esquecemos de definir a pontuação do OOM e isso mata o MySQL!
Temos 40 mestres morrendo às 4 da manhã. Quando 40 mestres morrem, é realmente muito assustador e perigoso. DRT não é assustador nem perigoso. Ficamos deitados por cerca de uma hora.
A propósito, a DRT é uma boa maneira de ensaiar esses momentos, para que saibamos exatamente qual sequência de ações é necessária se algo quebrar em massa.
- Gostaria de saber mais sobre a troca de mestre-mestre. Primeiro, por que um cluster não é usado, por exemplo? Um cluster de banco de dados, ou seja, não um mestre-escravo com comutação, mas um aplicativo mestre-mestre, de modo que, se um deles cair, não será assustador.
Você quer dizer algo como replicação de grupo, cluster galera, etc.? Parece-me que a inscrição em grupo ainda não está pronta para a vida. Infelizmente, ainda não experimentamos o Galera. Isso é ótimo quando um faylover está dentro do seu protocolo, mas, infelizmente, eles têm muitos outros problemas, e não é tão fácil mudar para esta solução.
- Parece que no MySQL 8 existe algo como um cluster InnoDb. Não tentou?
Ainda temos 5,6 no valor. Não sei quando mudaremos para 8. Talvez tentemos.
- Nesse caso, se você tiver um grande mestre, ao alternar de um para outro, a fila se acumula nos servidores escravos com uma carga alta. Se o mestre for extinto, é necessário que a fila chegue, para que o escravo mude para o modo mestre - ou é feito de alguma maneira diferente?
A carga no mestre é regulada por semisync. O Semisync limita a gravação principal ao desempenho do servidor escravo. Obviamente, pode ser que a transação tenha chegado, o semisync funcionou, mas os escravos perderam essa transação por um tempo muito longo. Você deve esperar até que o escravo perca essa transação até o fim.
- Mas então novos dados virão para o domínio, e serão necessários ...
Quando iniciamos o processo de promoção, desabilitamos a E / S. Depois disso, o mestre não pode escrever nada porque a semisync é replicada. Infelizmente, a leitura fantasma pode vir, mas esse já é outro problema.
- Estas são todas máquinas de estado bonitas - em que scripts estão escritos e quão difícil é adicionar uma nova etapa? O que precisa ser feito para a pessoa que escreve este sistema?
Todos os scripts são escritos em Python, todos os serviços são escritos em Go. Esta é a nossa política. Mudar a lógica é fácil - apenas no código Python que gera o diagrama de estado.
- E você pode ler mais sobre testes. Como os testes são gravados, como eles implantam nós em uma máquina virtual - são esses contêineres?
Sim Vamos testar com a ajuda de Bazel. Existem alguns arquivos de configuração (json) e o Bazel seleciona um script que cria a topologia para nosso teste usando esse arquivo de configuração. Diferentes topologias são descritas lá.
Tudo funciona para nós em contêineres de encaixe: funciona no CI ou no Devbox. Temos um sistema Devbox. Todos nós estamos desenvolvendo em algum servidor remoto, e isso pode funcionar, por exemplo. Lá, ele também é executado dentro do Bazel, dentro de um contêiner de encaixe ou na Sandbox do Bazel. Bazel é muito complicado, mas divertido.
- Quando você criou quatro instâncias em um servidor, perdeu em eficiência de memória?
Cada instância se tornou menor. Portanto, quanto menos memória o MySQL opera, mais fácil é para ele viver. Qualquer sistema é mais fácil de operar com uma pequena quantidade de memória. Neste lugar, não perdemos nada. Temos os grupos C mais simples que limitam essas instâncias da memória.
- Se você possui 6.000 servidores que armazenam bancos de dados, pode nomear quantos bilhões de petabytes estão armazenados em seus arquivos?
São dezenas de exabytes, servimos dados da Amazon por um ano.
- Acontece que, inicialmente, você tinha 8 servidores, 200 shards neles, depois 400 servidores com 4 shards cada. Você tem 1600 shards - isso é algum tipo de valor codificado? Você nunca pode fazer isso de novo? Vai doer se você precisar, por exemplo, de 3.200 fragmentos?
Sim, era originalmente 1600. Isso foi feito há menos de 10 anos e ainda vivemos. Mas ainda temos 4 fragmentos - 4 vezes ainda podemos aumentar o espaço.
- Como os servidores morrem, principalmente por quais razões? O que acontece com mais frequência, com menos frequência e é especialmente interessante, ocorrem os carapters de bloqueio espontâneos?
O mais importante é que os discos voem. Temos o RAID 0 - o disco travou, o mestre morreu. Esse é o principal problema, mas é mais fácil substituir esse servidor. Google é mais fácil substituir o data center, ainda temos um servidor. Quase nunca tivemos soma de verificação de corrupção. Para ser sincero, não me lembro quando foi a última vez. Nós frequentemente atualizamos o assistente. O tempo de vida de um mestre é limitado a 60 dias. Não pode durar mais, depois substituí-lo por um novo servidor, porque, por algum motivo, algo está constantemente se acumulando no MySQL e, após 60 dias, vemos que problemas começam a ocorrer. Talvez não no MySQL, talvez no Linux.
, . 60 , . .
— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .