
Nós, no departamento de análise do cinema online Okko, adoramos automatizar o cálculo das taxas de filmes de Alexander Nevsky, tanto quanto possível, e no tempo livre para aprender coisas novas e implementar coisas legais que, por algum motivo, geralmente se traduzem em bots para o telegrama. Por exemplo, antes do início da Copa do Mundo da FIFA 2018, lançamos um bot para o bate-papo de trabalho, que coletava apostas na distribuição dos lugares finais e, após o final, calculávamos os resultados de acordo com uma métrica pré-inventada e determinávamos os vencedores. A Croácia não colocou quatro entre os quatro primeiros.
Tempo livre recente ao compilar as 10 melhores comédias russas que dedicamos à criação de um bot que encontra uma celebridade com a qual o usuário mais se parece. No chat de trabalho, todos gostaram tanto da ideia que decidimos disponibilizar o bot ao público. Neste artigo, relembramos brevemente a teoria, falamos sobre a criação do nosso bot e como fazer você mesmo.
Um pouco de teoria (principalmente em fotos)
Em detalhes sobre como os sistemas de reconhecimento de face são organizados, falei em um dos meus artigos anteriores . Um leitor interessado pode seguir o link e descreverei abaixo apenas os pontos principais.
Então, você tem uma fotografia na qual, talvez, até um rosto seja mostrado e você quer entender de quem é. Para fazer isso, você precisa seguir 4 etapas simples:
- Selecione o retângulo que faz fronteira com a face.
- Destaque os principais pontos do rosto.
- Alinhe e corte seu rosto.
- Converta uma imagem de rosto em alguma representação interpretada por máquina.
- Compare essa visualização com outras que você tem disponível.
Seleção de rosto
Embora as redes neurais convolucionais tenham aprendido recentemente como encontrar rostos em uma imagem não sejam piores que os métodos clássicos, elas ainda são inferiores ao HOG clássico em velocidade e facilidade de uso.
HOG - Histogramas de gradientes orientados. Esse cara associa cada pixel da imagem de origem ao seu gradiente - um vetor na direção em que o brilho dos pixels muda mais. A vantagem dessa abordagem é que ela não se importa com os valores absolutos do brilho dos pixels, apenas sua proporção é suficiente. Portanto, uma face normal, escura, mal iluminada e ruidosa será exibida aproximadamente no mesmo histograma de gradientes.
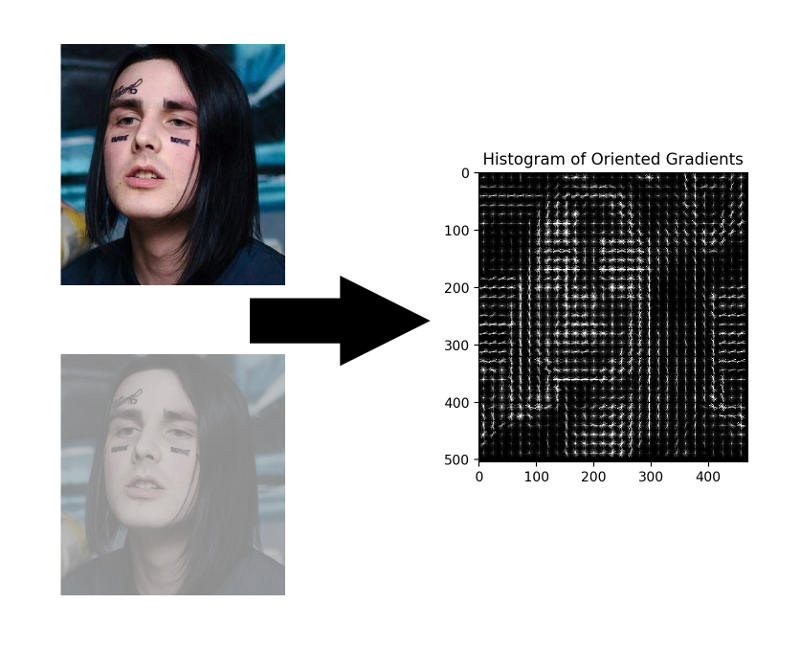
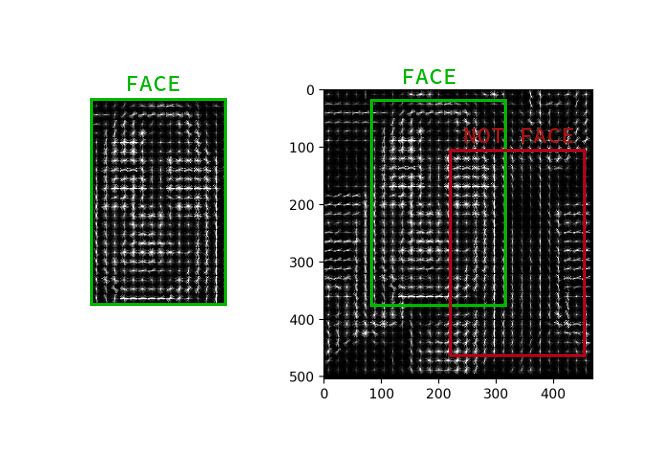
Não é necessário calcular o gradiente para cada pixel, basta calcular o gradiente médio para cada quadrado pequeno n por n . Usando o campo vetorial recebido, você pode passar por algum detector com uma janela e determinar para cada janela qual a probabilidade da face nela. O detector pode ser SVM, uma floresta aleatória ou qualquer outra coisa.
Destaque os principais pontos

Pontos-chave são pontos que ajudam a identificar uma pessoa no espaço. Os cientistas fracos e inseguros geralmente precisam de 68 pontos-chave e, em casos especialmente negligenciados, ainda mais. Garotos normais e autoconfiantes, ganhando 300k por segundo, sempre tiveram o suficiente de cinco: os cantos interno e externo dos olhos e nariz.
Tais pontos podem ser extraídos, por exemplo, por uma cascata de regressores .
Alinhamento da face
Aplicações coladas na infância? Aqui tudo é exatamente o mesmo: você constrói uma transformação afim que traduz três pontos arbitrários em suas posições padrão. O nariz pode ser deixado como está, mas para os olhos contarem seus centros - esses são os três pontos prontos.

Converter imagens de rosto em vetor

Três anos se passaram desde a publicação do artigo sobre o FaceNet . Nesse período, surgiram muitos esquemas interessantes de treinamento e funções de perda, mas é ela quem domina as soluções OpenSource disponíveis. Aparentemente, a coisa toda é uma combinação de facilidade de entendimento, implementação e resultados decentes. Agradecemos pelo menos pelo fato de nos últimos três anos a arquitetura ter sido alterada para ResNet.
O FaceNet aprende com três exemplos: (âncora, positivo, negativo). Exemplos âncora e positivos pertencem a uma pessoa, enquanto negativo é escolhido como o rosto de outra pessoa, o que, por algum motivo, a rede está muito próxima da primeira. A função de perda é projetada de maneira a corrigir esse mal-entendido, reunir os exemplos necessários e mover o desnecessário deles.

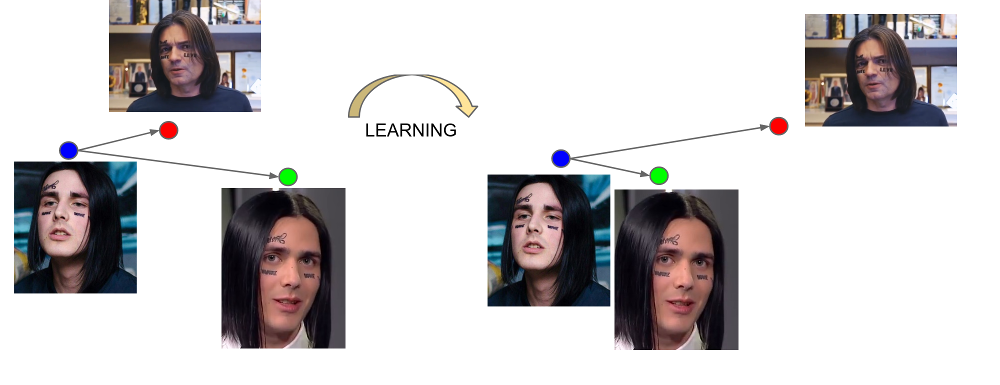
A saída da última camada da rede é chamada de incorporação - uma representação representativa de uma pessoa em um determinado espaço de pequena dimensão (geralmente 128-dimensional).
Comparação de rostos
A beleza de casamentos bem treinados é que os rostos de uma pessoa são exibidos em algum pequeno bairro do espaço, distante das incorporações dos rostos de outras pessoas. Assim, para esse espaço, é possível inserir uma medida de similaridade, a recíproca da distância: euclidiana ou cosseno, dependendo da distância que a rede foi treinada.
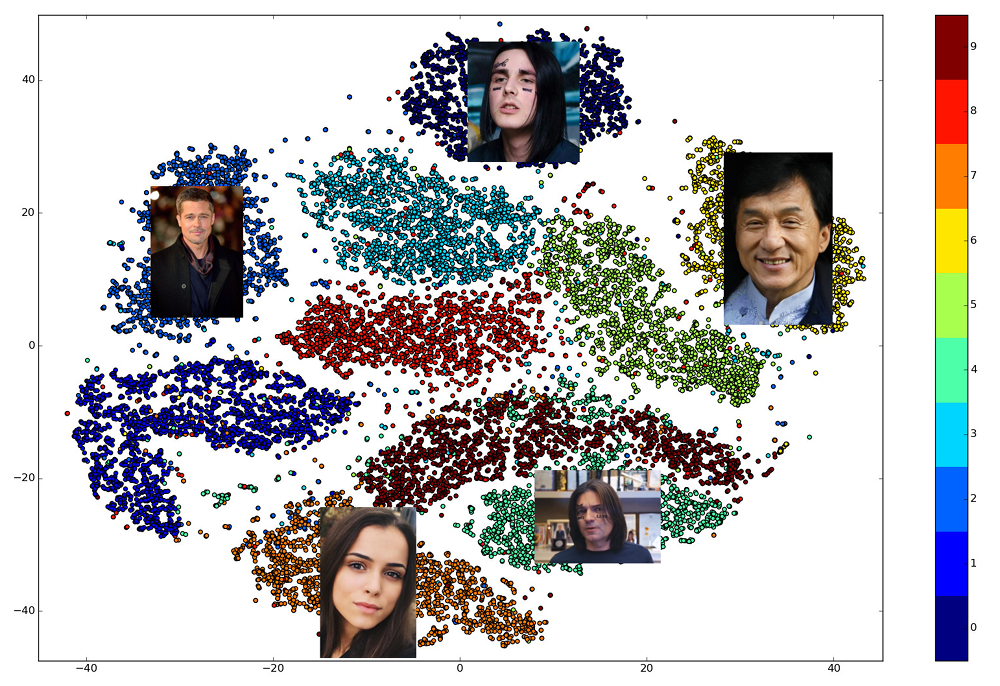
Portanto, com antecedência, precisamos criar incorporações para todas as pessoas entre as quais a pesquisa será realizada e, em cada solicitação, encontrar o vetor mais próximo entre elas. Ou, de outra maneira, resolva o problema de encontrar k vizinhos mais próximos, onde k pode ser igual a um, ou talvez não, se quisermos usar alguma lógica de negócios mais avançada. A pessoa que possui o vetor de resultado será a mais semelhante à pessoa solicitada.

Qual biblioteca usar?
A escolha de bibliotecas abertas que implementam várias partes do pipeline é ótima. dlib e o OpenCV podem encontrar faces e pontos-chave, e versões pré-treinadas de redes podem ser encontradas para qualquer grande estrutura de rede neural. Existe um projeto OpenFace em que você pode escolher a arquitetura para seus requisitos de velocidade e qualidade. Mas apenas uma biblioteca permite implementar todos os 5 pontos de reconhecimento de face nas chamadas para três funções de alto nível: dlib . Ao mesmo tempo, é escrito em C ++ moderno, usa BLAS, possui um wrapper para Python, não requer uma GPU e funciona muito rapidamente em uma CPU. Nossa escolha caiu sobre ela.
Fazendo seu próprio bot
Esta seção já foi descrita em literalmente todos os guias para criação de bots, mas depois que escrevermos o mesmo, teremos que repeti-lo. Escrevemos para @BotFather e pedimos um token para o nosso novo bot.
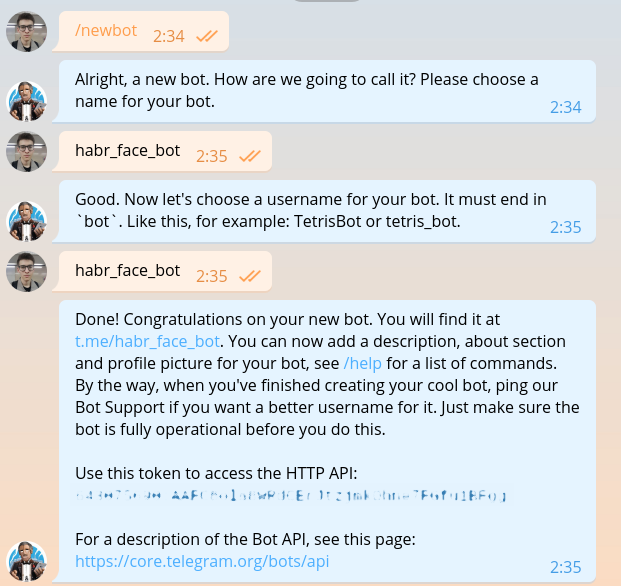
O token é mais ou menos assim: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . É necessário obter autorização em cada solicitação para a API bot do Telegram.
Espero que ninguém nesta fase tenha dúvidas ao escolher uma linguagem de programação. Claro, você tem que escrever em Haskell. Vamos começar com o módulo principal.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
Como você pode ver no código, no futuro usaremos uma DSL especial para gravar bots de telegrama. O código neste DSL é gravado em arquivos separados. Instale o idioma do domínio e tudo o que for necessário.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
Atualmente, o python-telegram-bot é a estrutura mais conveniente para a criação de bots. É fácil de aprender, flexível, escalável, suporta multithreading. Infelizmente, no momento não existe uma única estrutura assíncrona normal e os fios antigos precisam ser usados em vez das corotinas divinas.

Iniciar um bot com python-telegram-bot é fácil. Adicione o seguinte código ao bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Execute o bot. Para fins de depuração, isso pode ser feito com o python bot.py sem executar o código Haskell.
Um bot tão simples é capaz de manter uma conversa mínima e, portanto, pode ser facilmente organizado para funcionar como desenvolvedor front-end.
Mas o frontend dos desenvolvedores já é demais, então o mataremos o mais rápido possível e continuaremos implementando a funcionalidade principal. Por uma questão de simplicidade, nosso bot responderá apenas a mensagens contendo fotos e ignorará outras. Mude o código para o seguinte.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
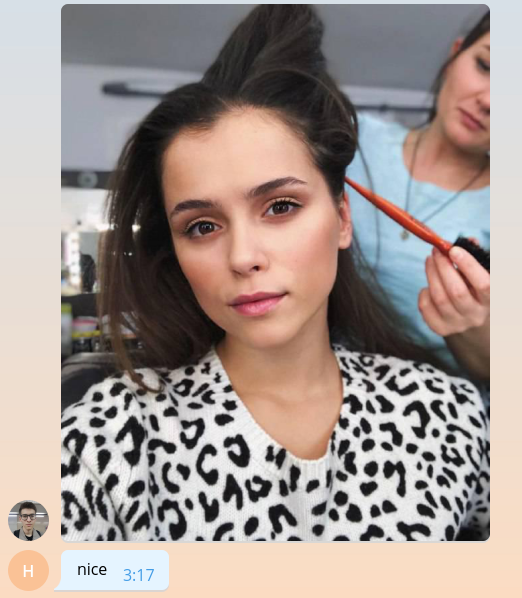
Quando a imagem entra no servidor Telegram, ela é ajustada automaticamente para vários tamanhos predeterminados. O bot, por sua vez, pode baixar uma imagem de qualquer tamanho daquelas contidas na lista message.photo classificada em ordem crescente. A opção mais fácil: tire a maior imagem. Obviamente, em um ambiente de supermercado, você precisa pensar na carga e no tempo de carregamento da rede e escolher uma imagem do tamanho mínimo adequado. Adicione o código de download da imagem na parte superior da função handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
A imagem foi baixada e está na memória. Para interpretá-lo e apresentá-lo na forma de uma matriz de intensidade de pixel, usamos as bibliotecas Pillow e numpy .
from PIL import Image import numpy as np
O código a seguir precisa ser adicionado ao bloco with .
image = Image.open(fd) image.load() image = np.asarray(image)
Chegou a hora dlib. Fora da função, crie um detector de rosto.
import dlib
face_detector = dlib.get_frontal_face_detector()
E dentro da função nós a usamos.
face_detects = face_detector(image, 1)
O segundo parâmetro da função significa a ampliação que deve ser aplicada antes de tentar detectar faces. Quanto maior, menores e mais complexas as faces que o detector poderá detectar, mas mais tempo funcionará. face_detects - uma lista de faces classificadas em ordem decrescente de confiança do detector de que a face está na frente dele. Em uma aplicação real, você provavelmente desejará aplicar alguma lógica de escolha da pessoa principal e, no estudo de caso, nos limitaremos a escolher a primeira.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
Prosseguimos para a próxima etapa - a busca por pontos-chave. Faça o download do modelo treinado e mova sua carga para fora da função.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
Encontre os pontos principais.
landmarks = shape_predictor(image, face)
A única coisa que resta é pequena: para endireitar o rosto, passe-o pelo ResNet e obtenha uma incorporação de 128 dimensões. Felizmente, o dlib permite que você faça tudo isso com uma chamada. Você só precisa fazer o download do modelo pré-treinado .
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
Basta olhar para o momento maravilhoso em que vivemos. Toda a complexidade das redes neurais convolucionais, o método do vetor de suporte e as transformações afins aplicadas ao reconhecimento de face são encapsuladas em três chamadas de biblioteca.
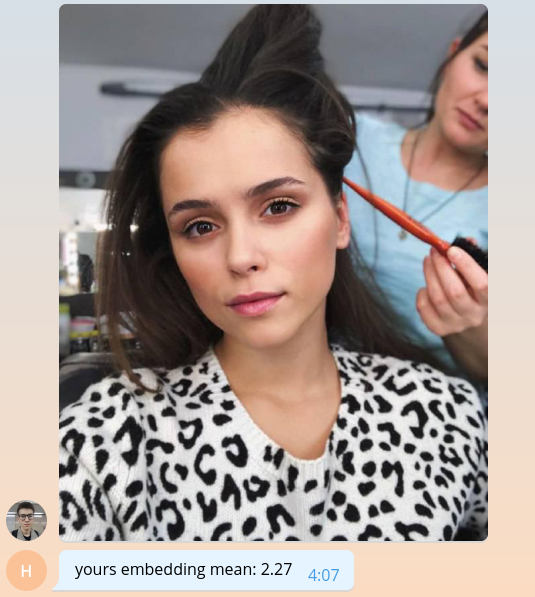
Como ainda não sabemos como fazer algo significativo, vamos retornar ao usuário o valor médio de sua incorporação, multiplicado por mil.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
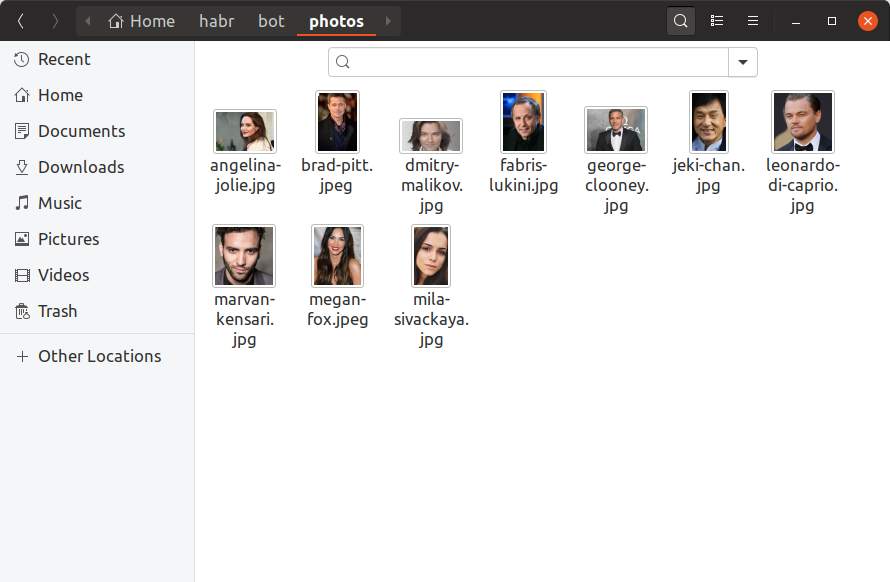
Para que nosso bot possa determinar com quais celebridades os usuários são, agora precisamos encontrar pelo menos uma foto de cada celebridade, criar uma incorporação e salvá-la em algum lugar. Adicionaremos apenas 10 celebridades ao nosso robô de treinamento, localizando suas fotos manualmente e colocando-as no diretório de photos . É assim que deve ser:
Se você deseja ter um milhão de celebridades no banco de dados, tudo ficará exatamente igual, apenas há mais arquivos e é improvável que você possa procurá-los com as mãos. Agora vamos criar o utilitário build_embeddings.py usando as chamadas dlib que já conhecemos e salvar as incorporações de celebridades junto com seus nomes em formato binário.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
Adicione o carregamento incorporado ao nosso código bot.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
E, por uma pesquisa exaustiva, descobriremos quem é o nosso usuário.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
Observe que usamos a distância euclidiana como distância, porque a rede em dlib foi treinada precisamente com a ajuda dela.

É tudo, parabéns! Criamos um bot simples que pode determinar qual celebridade o usuário é. Resta encontrar mais fotos, adicionar marcas, escalabilidade, uma pitada de registro e tudo pode ser lançado na produção. Todos esses tópicos são volumosos demais para falar detalhadamente com imensas listagens de código. Por isso, descreverei os principais pontos no formato de perguntas e respostas na próxima seção.
O código bot completo de treinamento está disponível no GitHub .
Falamos sobre o nosso bot
Quantas celebridades você tem no seu banco de dados? Onde você os encontrou?
A decisão mais lógica ao criar o bot pareceu extrair dados de celebridades de nossa base de conteúdo interna. Ela no formato do gráfico armazena filmes e todas as entidades associadas a filmes, incluindo atores e diretores. Para cada pessoa, sabemos o nome dela, o login e a senha do iCloud, filmes e apelidos relacionados, que podem ser usados para gerar links para o site. Após limpar e extrair apenas as informações necessárias, o arquivo json permanece da seguinte maneira:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
Havia 22.000 dessas entradas no catálogo. A propósito, não um catálogo, mas um catálogo.
Onde encontrar fotos para todas essas pessoas?

Bem, você sabe, aqui e ali . Há, por exemplo, uma biblioteca maravilhosa que permite o upload de resultados da consulta de imagens do Google. 22 mil pessoas - não tantas, usando 56 fluxos que conseguimos baixar fotos em menos de uma hora.
Entre as fotos baixadas, você precisa descartar fotos quebradas e barulhentas no formato errado. Em seguida, deixe apenas aqueles onde há rostos e onde esses rostos satisfazem certas condições: a distância mínima entre os olhos, a inclinação da cabeça. Tudo isso nos deixa com 12.000 fotos.
Das 12 mil celebridades, os usuários encontraram apenas 2. No momento, existem aproximadamente 8 mil celebridades que ainda não são como as outras pessoas. Não deixe assim! Abra telegramas e encontre todos eles.
Como determinar a porcentagem de similaridade para a distância euclidiana?
Ótima pergunta! De fato, a distância euclidiana, em contraste com o cosseno, não é delimitada acima. Portanto, surge uma pergunta razoável: como mostrar ao usuário algo mais significativo do que "Parabéns, a distância entre a incorporação e a incorporação de Angelina Jolie é 0,227635462738"? Um dos membros da nossa equipe propôs a seguinte solução simples e engenhosa. Se você construir a distribuição de distâncias entre as incorporações, será normal. Portanto, para ele, você pode calcular a média e o desvio padrão e, para cada usuário, de acordo com esses parâmetros, considerar quantos por cento das pessoas são menos parecidas com as celebridades do que ele . Isso é equivalente à integração de uma função de densidade de probabilidade de d ao infinito, onde d é a distância entre o usuário e os comícios de celebridades.
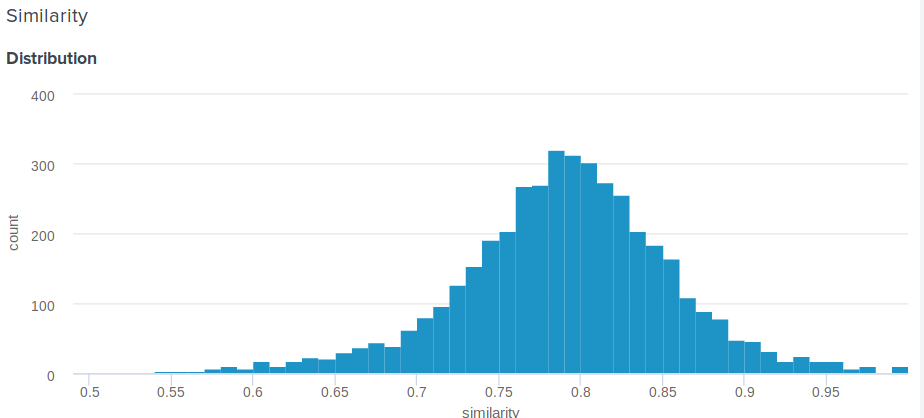
Aqui está a função exata que usamos:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
É realmente necessário percorrer a lista de todos os sindicatos para encontrar uma correspondência?
Claro que não, isso não é o ideal e leva muito tempo. A maneira mais fácil de otimizar cálculos é usar operações de matriz. Em vez de subtrair vetores um do outro, você pode compor uma matriz deles e subtrair um vetor da matriz e, em seguida, calcular a norma L2 em linhas.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
Isso já dá um enorme aumento de produtividade, mas, ao que parece, você pode ainda mais rápido. A pesquisa pode ser significativamente acelerada, perdendo um pouco de precisão usando a biblioteca nmslib . Ele usa o método HNSW para aproximar a busca por k vizinhos mais próximos. Para todos os vetores disponíveis, um índice chamado deve ser construído, no qual uma pesquisa será realizada. Você pode criar e salvar o índice para a distância euclidiana da seguinte maneira:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
Os parâmetros M e efConstruction são descritos em detalhes na documentação e são selecionados experimentalmente com base na precisão necessária, tempo de construção do índice e velocidade de pesquisa. Antes de usar o índice, você deve fazer o download:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
O parâmetro efSearch afeta a precisão e a velocidade das consultas e pode não corresponder ao efConstruction . Agora você pode fazer pedidos.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
No nosso caso, o nmslib é 20 vezes mais rápido que a versão linear vetorizada e uma solicitação é processada em média 0.005 segundos.
Como preparar meu bot para produção?
1. Assincronia
Primeiro, você precisa tornar a função handle_photo assíncrona. Como eu já disse, o python-telegram-bot oferece multithreading para isso e implementa um decorador conveniente.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
Agora, a própria estrutura iniciará seu manipulador em um thread separado em seu pool. O tamanho do pool é definido ao criar o Updater . "Mas em python não há multithreading!" o mais impaciente de vocês já exclamou. E isso não é inteiramente verdade. Por causa do GIL, o código Python comum realmente não pode ser executado em paralelo, mas o GIL é liberado para aguardar todas as operações de E / S e também pode ser liberado pelas bibliotecas que usam extensões C.
Agora analise nossa função handle_photo : consiste apenas em aguardar operações de E / S (carregar uma foto, enviar uma resposta, ler uma foto do disco etc.) e chamar funções das bibliotecas numpy , nmslib e Pillow .
Eu não mencionei dlib por um motivo. A biblioteca que chama o código nativo não é necessária para liberar o GIL e o dlib isso. Ela não precisa dessa trava, ela simplesmente não a deixa ir. O autor diz que aceitará com prazer a solicitação de solicitação apropriada, mas sou muito preguiçoso.
2. Multiprocessamento
A maneira mais fácil de lidar com o dlib é encapsular o modelo em uma entidade separada e executá-lo em um processo separado. E melhor no pool de processos.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. Ferro
Se o seu bot precisar ler constantemente fotos de um disco, verifique se o disco é um SSD. Ou até montá-los na RAM. Ping para servidores de telegrama e qualidade do canal também é importante.
4. Controle de inundação
Os telegramas não permitem que os bots enviem mais de 30 mensagens por segundo. Se o seu bot é popular e muitas pessoas o usam ao mesmo tempo, é muito fácil banir por alguns segundos, o que será uma decepção para a expectativa de muitos usuários. Para resolver esse problema, o python-telegram-bot nos oferece uma fila que não pode enviar mais do que o limite de mensagens especificado por segundo, mantendo intervalos iguais entre o envio.
from telegram.ext.messagequeue import MessageQueue
Para usá-lo, você precisa definir seu próprio bot e substituí-lo ao criar o Updater .
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. Ganchos da Web
Em um ambiente de produto, os Web Hooks sempre devem ser usados em vez de Long Polling como forma de receber atualizações dos servidores de Telegram. Sobre o que é e como usá-lo pode ser lido aqui .
6. Curiosidades
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
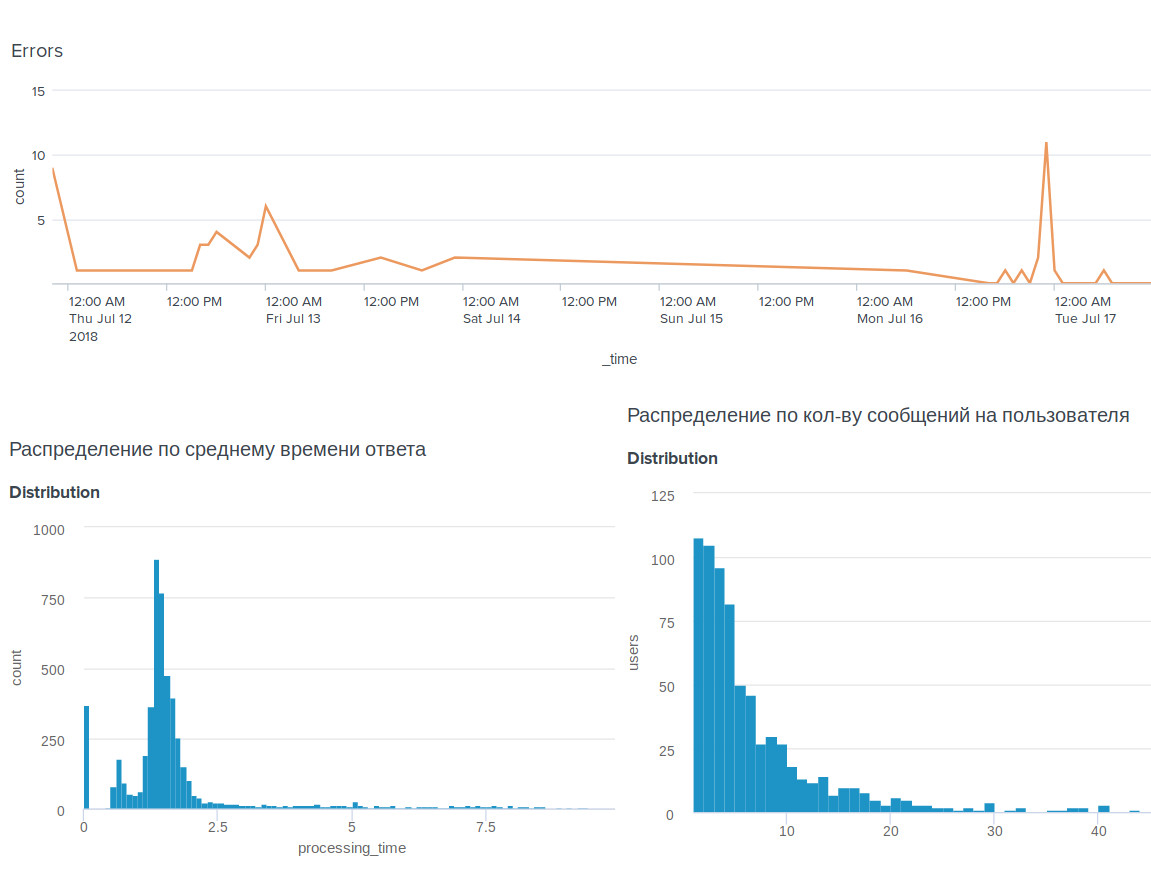
, . , .
, . , : @OkkoFaceBot .