Infelizmente, não vivemos em um mundo ideal, onde todo desenvolvedor tem um nível ideal e equilibrado de produtividade, enquanto nos concentramos nas tarefas e pensamos nelas de um para o outro. A colaboração em equipe também nem sempre é projetada para que todos os membros da equipe trabalhem com a máxima eficiência. Como em muitos problemas em geral, o desenvolvimento inicial da equipe de desenvolvimento economiza recursos, os nervos da gerência e cria uma boa atmosfera de trabalho.
Em uma equipe pequena, o líder da equipe pode tentar julgar tudo o que acontece com base em sentimentos subjetivos, mas quanto maior a empresa, mais importante é usar dados e métricas objetivas.
Alexander Kiselev (
AleksandrKiselev ) e
Sergey Semenov em seu relatório sobre o
TeamLead Conf mostraram como usar os dados que você já acumulou, onde obter dados adicionais e que juntos eles podem ajudar a identificar problemas não óbvios. E mesmo tendo acumulado a experiência de muitos colegas, eles propuseram soluções.
Sobre os palestrantes: Alexander Kiselev e Sergey Semenov, trabalhamos com TI há mais de 8 anos. Ambos passaram de desenvolvedor a líder de equipe e depois a gerente de produto. Agora eles estão trabalhando no serviço analítico GitLean, que coleta automaticamente análises de equipes de desenvolvimento para líderes de equipe e CTO. O objetivo deste serviço é que os gerentes técnicos possam tomar suas decisões com base em dados objetivos.
Declaração do problema
Nós dois trabalhamos como líderes de equipe e frequentemente enfrentamos o problema da incerteza e ambiguidade em nosso trabalho.

Como resultado, muitas vezes era necessário tomar decisões às cegas e, às vezes, não ficava claro se era melhor ou pior. Portanto, analisamos as soluções existentes no mercado, examinamos as metodologias para avaliar o desempenho dos desenvolvedores e percebemos que não havia nenhum serviço que satisfizesse nossas necessidades. Portanto,
decidimos criá-lo nós mesmos .
Hoje falaremos sobre o que você pode informar sobre os dados que você já acumulou, mas provavelmente não os usa.

Isso é necessário em dois casos principais.
A análise de desempenho é um processo bastante complexo e subjetivo. Seria ótimo coletar fatos sobre o trabalho do desenvolvedor automaticamente.
Conversamos com representantes de uma grande empresa alemã com uma grande equipe de desenvolvimento. Cerca de uma vez por ano, eles pararam todo o trabalho de desenvolvimento por duas semanas e somente a empresa inteira fez uma análise de desempenho - os desenvolvedores escreveram denúncias anônimas o dia todo para colegas com quem trabalharam por um ano. Se essa empresa tivesse a oportunidade de coletar fatos automaticamente, economizaria muito tempo.
O segundo aspecto é
monitorar a situação atual da equipe. Quero entender rapidamente os problemas que surgem e responder rapidamente a eles.
Opções de decisão
Pode haver várias soluções.

Primeiro, você
não pode
usar nenhuma análise , mas apenas sua avaliação subjetiva. Isso funciona se você é um líder de equipe em uma equipe pequena. Mas se você já é CTO e tem muitas equipes, não poderá usar sua avaliação subjetiva, porque não sabe tudo. Você precisará recorrer a uma avaliação subjetiva de seus timlids, e isso é um problema, pois muitas vezes os timlids abordam a avaliação subjetiva de maneira bastante diferente.

Esta é a próxima coisa a fazer. Como a avaliação subjetiva geralmente não é suficiente, você pode
ficar confuso e
coletar fatos manualmente .
Por exemplo, um CTO com quem conversamos suspeitou que a equipe estava fazendo uma revisão de código muito lentamente, mas não havia nada para apresentá-los. Como ele tinha apenas um sentimento vago, ele decidiu coletar os fatos, apenas algumas semanas para assistir à equipe. O CTO registrou o tempo que a equipe levou para revisar e o que ele descobriu no final o chocou. Descobriu-se que dois idosos estavam em conflito há muito tempo na revisão de código, embora não o retirassem. Eles se sentavam como ratos, ninguém gritava com ninguém - a equipe não sabia nada. A única coisa que eles fizeram foi periodicamente ir para o refrigerador, se derramar um pouco mais de água e correr para escrever respostas espirituosas em uma revisão de código para o inimigo, mediante solicitação por solicitação.
Quando a CTO descobriu, o problema era tão antigo que era impossível fazer qualquer coisa e, no final, um dos programadores teve que ser demitido.
 As estatísticas do Jira
As estatísticas do Jira são uma opção frequentemente usada. Essa é uma ferramenta muito útil na qual há informações sobre tarefas, mas é de alto nível. Muitas vezes, é difícil entender o que está acontecendo em uma equipe especificamente.
Um exemplo simples - o desenvolvedor no sprint anterior fez 5 tarefas, esta - 10. É possível dizer que ele começou a trabalhar melhor? É impossível, porque as tarefas são completamente diferentes.

A última solução que existe é simplesmente arregaçar as mangas e escrever
seu próprio script para a coleta automática de dados . É dessa maneira que todos os CTOs de grandes empresas chegam mais ou menos. Ele é o mais produtivo, mas, é claro, o mais difícil. É sobre ele que conversaremos hoje.
Solução selecionada
Portanto, a solução escolhida é dividir seus scripts para coletar análises. As principais perguntas são onde obter dados e o que medir.
Fontes de dados
As principais fontes de dados nas quais as informações sobre o trabalho do desenvolvedor são acumuladas são:
- Git - as principais entidades: confirma, ramifica e codifica dentro delas.
- Ferramentas de revisão de código - os serviços de hospedagem git que hospedam revisões de código mantêm informações sobre solicitação de recebimento que podem ser usadas.
- Rastreadores de tarefas - informações sobre tarefas e seu ciclo de vida.
Fontes de dados auxiliares:
- Mensageiros - aí você pode, por exemplo, realizar análises de sentimentos, calcular o tempo médio de resposta do desenvolvedor a uma solicitação de informações.
- Serviços de IC que armazenam informações sobre compilações e liberações.
- Pesquisas de equipe.
Como todas as fontes das quais falei acima são mais ou menos padrão, e a última não é tão padrão, falarei um pouco mais sobre isso.
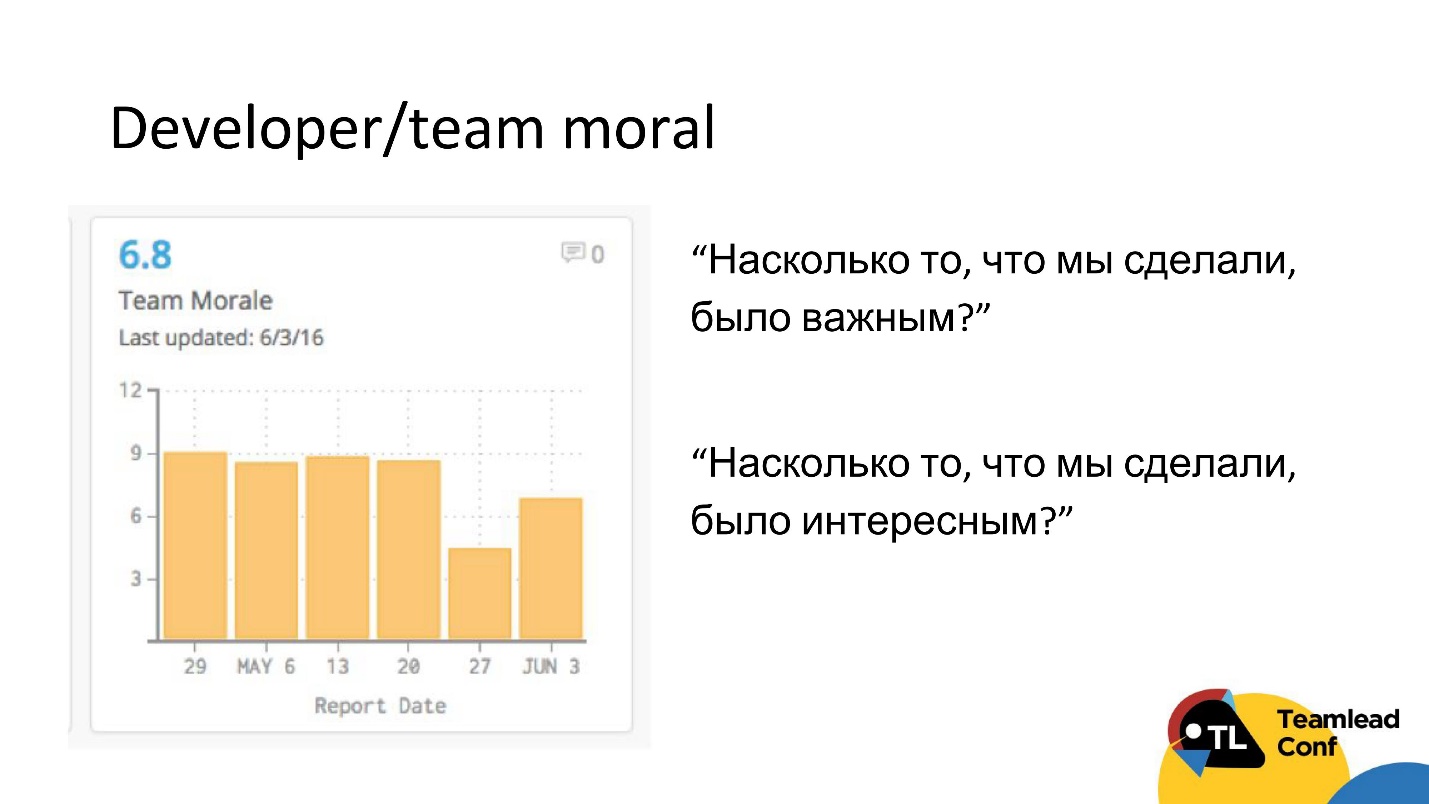
Outro CTO compartilhou esse método conosco. No final de cada iteração, ele enviou à equipe uma pesquisa automaticamente, na qual havia apenas duas perguntas:
- Na sua opinião, qual a importância do que fizemos nessa iteração?
- Você acha que o que estamos fazendo foi interessante?
Essa é uma maneira bastante barata de medir o humor de uma equipe e, talvez, pegar alguns problemas com motivação.
O que e como medir
Primeiro, discutiremos a metodologia de medição. Uma boa métrica deve responder a três perguntas:
- Isso é importante? Só é necessário medir o que sinaliza algo significativo para a empresa.
- Ficou pior / melhor / igual? Por métrica, deve ficar claro se ficou melhor ou pior.
- O que fazer A partir da métrica, deve ficar claro o que fazer para corrigir a situação.
Em geral, vale a pena seguir o princípio:
Meça o que você quer e pode mudar.
Vale ressaltar imediatamente que não existe uma métrica universal e não falaremos sobre uma métrica universal hoje pelos seguintes motivos:
- O desenvolvedor tem muitos aspectos de atividade - ele trabalha com requisitos, escreve código, testa, realiza revisões de código, faz implantações - e é impossível colocar tudo isso em uma única métrica universal. Portanto, é melhor focar em casos individuais que podem ser detectados.
- A segunda razão pela qual não vale a pena fazer a única métrica é que é fácil contornar uma métrica, porque os desenvolvedores são pessoas suficientemente inteligentes e descobrirão como fazer isso sozinhos.

Nova abordagem
Portanto, formulamos uma abordagem na qual passamos de problemas: tentamos identificar problemas específicos e selecionar um conjunto de métricas para eles que os detectem. Um bom desenvolvedor será chamado de desenvolvedor com o menor número de problemas.

Em que se baseia a nossa escolha de problemas? É simples: realizamos uma entrevista com 37 CTOs e líderes de equipe que falaram sobre os problemas que eles têm em suas equipes e como eles resolvem esses problemas.
Na enorme lista resultante, priorizamos e coletamos hacks e métricas de vida para esses problemas. Dividimos todos os problemas em 2 grupos:
- Problemas de um desenvolvedor individual (o desenvolvedor é responsável por esses problemas).

- Problemas de equipe. A equipe é responsável por esses problemas; portanto, para resolvê-los, você precisa trabalhar com a equipe como um todo e alterar as soluções do processo.

Vamos considerar em detalhes cada problema, qual chave das métricas para ele pode ser selecionada. Vamos começar com os problemas mais simples e avançar lentamente ao longo do gradiente de complexidade até o mais difícil de medir.
Problemas do desenvolvedor
Desenvolvedor pouco desempenho

Além disso, "pouco desempenho" geralmente significa que o
desenvolvedor não faz quase nada . Condicionalmente, um ticket está pendurado nele em Jira, de alguma forma é reportado, mas realmente nenhum trabalho está acontecendo. É claro que esse problema surgirá mais cedo ou mais tarde, você o encontrará, mas seria legal fazê-lo automaticamente.
Como isso pode ser medido?A primeira coisa que vem à mente é apenas analisar o
número de dias ativos com o desenvolvedor. O dia ativo será chamado o dia em que o desenvolvedor fez pelo menos uma confirmação. Para os desenvolvedores em período integral, na verdade, o número característico de dias ativos por semana é pelo menos 3. Se menor, começamos a suspeitar que o desenvolvedor não terá muito desempenho.
Obviamente, apenas o número de dias ativos não é suficiente. Um desenvolvedor pode escrever código e não confirmar - escreveu, escreveu e, um dia, cometeu um monte de código.
Portanto, a próxima limitação que impomos é que o desenvolvedor também deve ter um
pouco de código . Como determinar o limite "pequeno código"? Recomendamos que você o coloque pequeno o suficiente para que qualquer pessoa, tanto quanto um desenvolvedor de desempenho, possa superá-lo facilmente. Por exemplo, em nosso serviço para JS, são cerca de 150 linhas de código e, para Clojure - 100 linhas de código.
Por que um limiar tão pequeno? A idéia é que queremos separar desenvolvedores que não são legais dos que trabalham em média, mas aqueles que não fazem quase nada, daqueles que realizam pelo menos uma quantidade razoável de trabalho.
Mas mesmo que o desenvolvedor tenha poucos dias ativos e pouco código, isso não significa que ele não funcionou. Ele poderia, por exemplo, fazer correções de erros que exigem uma pequena quantidade de código. Como resultado, uma pessoa parece ter realizado muitas tarefas, mas pode ter poucos códigos e dias ativos. Ou seja, levamos em conta o
número de tarefas .
A próxima coisa que vale a pena assistir é a
quantidade de revisão de código que ele fez, porque uma pessoa não pode executar tarefas e não escrever código, mas ficar completamente imersa na revisão de código. Isso acontece
Portanto, se for para todas essas métricas - e somente isso! - o desenvolvedor não atinge nenhum limite, você pode suspeitar que ele não tenha um bom desempenho.
O que fazer sobre isso?Primeiro, se você conhece um motivo legítimo, não precisa fazer absolutamente nada - por exemplo, um desenvolvedor é treinado ou tem um dia de folga. Se você não conhece o motivo legítimo, provavelmente vale a pena
conversar com uma pessoa. Se um motivo legítimo não aparecer, vale a pena monitorá-lo ainda mais, e se esse problema continuar repetido algumas vezes, provavelmente vale a pena dizer adeus a esse desenvolvedor.
Este foi o problema mais simples e provocador. Vamos para os mais pesados.
O desenvolvedor recicla

Esta também é uma história comum. Se uma pessoa a processa, ela se queima, acaba desmotivando e, como resultado, pode deixar a empresa. Um dos gerentes técnicos com quem conversamos contou essa história. Ele trabalhou para uma empresa americana na qual a cultura de comícios foi amplamente desenvolvida. Como resultado, todos os desenvolvedores, quando chegaram ao trabalho, fizeram o que reuniram e escreveram o código depois de horas e nos finais de semana. Como resultado, o faturamento anual de desenvolvedores da empresa atingiu 30%, embora a norma do setor seja de 6%.
Como resultado, toda a gestão técnica composta por 30 pessoas foi demitida deste escritório. Para não trazer isso à tona, quero encontrar esse problema a tempo.
Como isso pode ser medido?De fato, nada é muito complicado - vejamos a
quantidade de código que o desenvolvedor escreve depois de horas. Se essa quantidade de código for condicionalmente comparável ou maior do que durante o horário de trabalho, o desenvolvedor a processará explicitamente.
Obviamente, os desenvolvedores não vivem como um único código. Um problema comum é que há tempo suficiente para o código - a tarefa principal -, mas não há mais para a revisão do código. Como resultado, a revisão do código é transferida para as noites ou fins de semana. Isso pode ser rastreado simplesmente pelo
número de comentários na solicitação de recebimento após o
expediente .
O último gatilho explícito é um
grande número de tarefas paralelas . Há alguma limitação razoável de 3-4 tarefas para o desenvolvedor. Você pode rastreá-los por git ou por Jira - como desejar. Funciona muito bem.
O que fazer sobre isso?Se você encontrar um desenvolvedor de reciclagem,
verifique primeiro
o calendário dele para ver se ele está sobrecarregado com comícios inúteis. Se estiver sobrecarregado, é aconselhável reduzi-los e, idealmente, fazer um dia de reunião - um dia dedicado em que o desenvolvedor concentrará a maior parte de suas reuniões mais longas para poder trabalhar normalmente em outros dias.
Se isso não funcionar, é necessário
redistribuir a carga . Esta é realmente uma pergunta bastante complicada - como fazê-lo. Existem muitas maneiras diferentes. Não vamos nos aprofundar, mas observe o
relatório legal sobre o HighLoad 2017 de Anton Potapov, no qual esse tópico foi considerado de perto.
O desenvolvedor não tem foco no lançamento de tarefas
Quero entender quantos desenvolvedores existem em sua equipe e quanto custa com o tempo.

É uma situação bastante comum que um desenvolvedor assume uma tarefa, a leva ao status de revisão, teste - e esquece. Em seguida, ela retorna para revisão e fica pendurada lá, sem saber quanto tempo. Eu próprio tive um desenvolvedor em minha equipe ao mesmo tempo. Subestimei o problema por um longo tempo, até que calculei a quantidade de tempo que, em média, ocupa vários períodos de inatividade. Como resultado, verificou-se que as tarefas desse desenvolvedor, em média, permaneceram ociosas 60% do tempo do lançamento.
Como isso pode ser medido?Primeiro, você precisa medir todo o tempo de inatividade que depende do desenvolvedor. Este é o momento para corrigir
após a revisão e teste do código . Se você tiver entrega contínua, esse é
o tempo limite da liberação. Uma restrição razoável deve ser imposta a cada um desses horários - como não mais que um dia.
O motivo é o seguinte. Quando um desenvolvedor chega ao trabalho pela manhã, seria legal para ele analisar primeiro as tarefas de maior prioridade. As tarefas de maior prioridade, se não houver correções ou algo muito importante, são as tarefas mais próximas de lançamento e lançamento.
Outro gatilho interessante sobre esse tópico é a
quantidade de revisão de código que fica no desenvolvedor, como em um revisor. Se uma pessoa se esquece de suas tarefas, provavelmente ela também se relacionará com as tarefas de seus colegas.
O que fazer sobre isso?Se você encontrar um desenvolvedor assim, claramente vale a pena ir até ele e
dizer : "Olha, são 30 a 40% do seu tempo gasto em tempo de inatividade!" Isso geralmente funciona muito bem. No meu caso, por exemplo, teve um efeito tão grande, que o problema está quase completamente resolvido, se não, você precisa continuar
monitorando , digamos periodicamente, mas o principal aqui não é cair no microgerenciamento, porque será ainda pior.
Portanto, sempre que possível, vale a pena lidar imediatamente com as soluções de processo. Por exemplo, pode haver
limites no número de tarefas ativas ou, se o seu orçamento e o tempo permitir, você pode escrever um bot ou usar um serviço que efetua
ping automaticamente
no desenvolvedor se a tarefa estiver em um determinado status por muito tempo. Esta é provavelmente a solução mais legal aqui.
O desenvolvedor não pensa em tarefas suficientes
Acho que você conhece os sintomas - essas são estimativas incompreensíveis do tempo necessário para concluir as tarefas em que não caímos, os longos prazos no final, o aumento no número de bugs nas tarefas - em geral, nada de bom.
 Como isso pode ser medido?
Como isso pode ser medido?Acho que você conhece os sintomas - essas são estimativas incompreensíveis do tempo necessário para concluir as tarefas em que não caímos, os longos prazos no final, o aumento no número de bugs nas tarefas - em geral, nada de bom.
Como isso pode ser medido?Para fazer isso, precisamos introduzir duas métricas, a primeira das quais é o código Churn.

Churn é uma medida de quanto código um desenvolvedor escreve condicionalmente em vão.
Imagine a situação. Na segunda-feira, o desenvolvedor começou a fazer uma nova tarefa e escreveu 100 linhas de código. Então chegou a terça-feira, ele escreveu outras 100 novas linhas de código nessa tarefa. Mas, infelizmente, aconteceu que 50 linhas de código que foram escritas na segunda-feira, ele exclui e libera a tarefa. Como resultado, 200 linhas de código pareciam ser criadas na tarefa, mas apenas 150 sobreviveram até o lançamento e 50 foram escritas em vão. Chamamos esses 50 de Churn. E assim, neste exemplo, o desenvolvedor Churn foi de 25%.
Em nossa opinião, um
alto nível de Churn é um gatilho interessante que o desenvolvedor não pensou na tarefa.
Há um estudo de uma empresa americana em que eles mediram o nível de rotatividade de 20.000 desenvolvedores e chegaram à conclusão de que um bom código de rotatividade deve estar na faixa de 10 a 20%.
Mas existem duas condições importantes:
- High Churn é bom se, por exemplo, você estiver criando um protótipo ou algum novo projeto. Então pode ser igual a 50-60% por vários meses. Não há com o que se preocupar. , Churn — , .
- Churn — . . - . delivery .

, , , , Fixed Tasks,
. , .
, bug fixes , bug fixes . bug fixes 3 , , . , , , .
—
. , , , - .
?, , ,
. , ,
, estimation ..
CTO, , workflow, , . , , ,
- , .
Churn Fixed Tasks, , :
- commit message, . commit message, , git .
- git-squash commit' , Churn .
- git. merge master, merge , . — , , Churn Fixed Tasks.

, —
, . , , , . , - .
, , - 3-4 . , .
?— - , , .
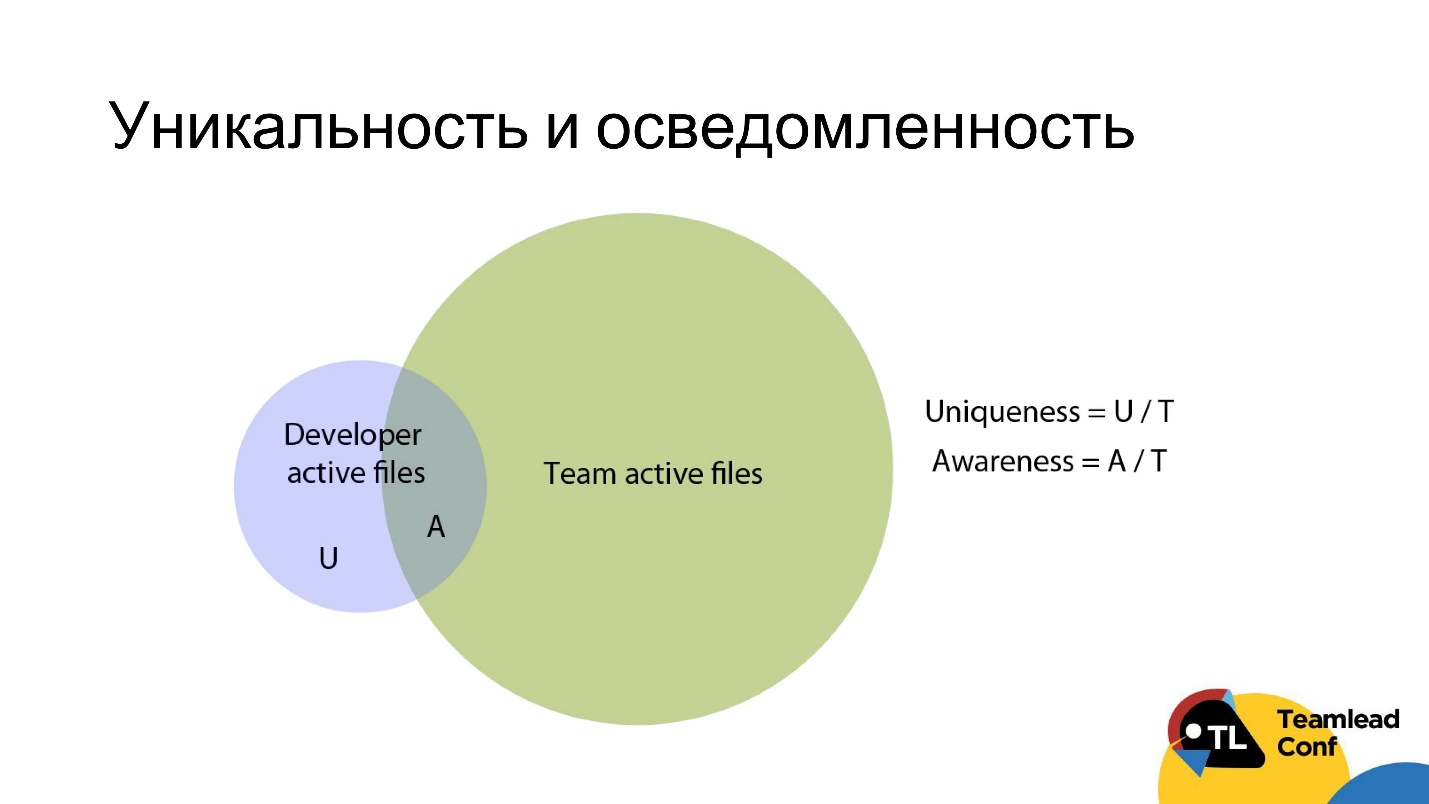
, 3 , , ( ), .
, , . — , .
— ,
— — , , .
?. , , . - , .
— , , . . , , . .
30-50 50-60 %. , .
, , . , , , .
.

, —
. product- , . , , .
?product- , ?
, product- , :
- Churn, ;
- , , estimation;
- in progress product-.
?product- : «, Churn - — ».
« » , 1-2 . , product-, .

. , , .
, , , . , , - , , . , . .
?, , :
?-, , ,
, .
-, , , ,
, , .
— - , . best practise, , , , . 3 , 3 .

, —
. , . - , , -. , , CTO, , 100%. , - .
?,
legacy refactoring . , . . , , , .

,
legacy refactoring , ,
complexity , , .
?, , . , CTO. , .
CTO , , Jira
«» . , - estimation . , — , ..
CTO . , , ,
«Hack». - -, : « Hack — », . grep' «Hack» , .
. .
:
- Algumas coisas ainda não são muito fáceis de medir. Isso se aplica, por exemplo, à rotatividade ou refatoração herdada. Leva algum tempo para aprender a contá-los.
- Os dados precisam ser limpos e ligeiramente ajustados ao comando. Por exemplo, a coisa comum que você encontrará se tentar implementar isso - no git, você verá que várias contas git correspondem à mesma pessoa. Você terá que considerar os dois - este é um exemplo trivial de limpeza de dados que precisa ser feito.
- Você precisa monitorar os valores-limite e escolhê-los com sabedoria, porque eles dependem do estágio da vida da empresa e do tipo de empresa também. O que é bom para um contratante pode não ser muito bom para uma empresa de supermercado.
- A maioria das métricas listadas aqui funciona apenas para desenvolvedores multitempo, porque apenas as atividades dos desenvolvedores multitempo estão bem refletidas nas fontes de dados disponíveis: git, Jira, GitHub, mensageiros instantâneos etc.
Conclusões
Queríamos transmitir a você o seguinte:
- Os desenvolvedores e a equipe podem e devem ser medidos . Pode ser difícil, mas pode ser feito.
- Não há um pequeno conjunto universal de KPI . Para cada problema, você precisa selecionar seu conjunto de métricas altamente especializado. É preciso lembrar que você não deve negligenciar nem mesmo as métricas mais simples. Juntos, eles podem funcionar bem.
- O Git pode dizer muitas coisas interessantes sobre desenvolvimento e desenvolvedores, mas você precisa seguir certas práticas para que os dados possam ser acessados comodamente, incluindo:
- número de tarefas em confirmações;
- sem abóbora;
- Você pode determinar o tempo de liberação: mesclar no mestre, tags.
Links e contatos úteis:- Existem vários problemas e métricas de bônus para eles na apresentação .
- Blog de autores com artigos úteis para gerentes de desenvolvimento
- Contatos do telegrama: @avkiselev (Alexander Kiselev) e sss0791 (Sergey Semenov).
No TeamLead Conf, eles discutem vários problemas diferentes no gerenciamento de uma equipe de desenvolvimento e buscam soluções. Se você já percorreu parte do caminho, preencheu mais de um solavanco, pisou em um ancinho, tentou abordagens diferentes e está pronto para tirar conclusões e compartilhar sua experiência - estamos esperando por você. Você pode se inscrever para uma apresentação até 10 de agosto .
Espera-se também que os participantes se envolvam mais, comece reservando um ingresso e tente formular o que mais o excita - então você pode discutir sua dor e tirar o máximo proveito da conferência.