Antes que o código escrito por nós seja executado, ele percorre um longo caminho.
Andrey Melikhov em seu relatório sobre o RIT ++ 2018 examinou todas as etapas desse caminho usando o exemplo do mecanismo V8. Entre em contato com o gato para descobrir o que nos dá uma compreensão profunda dos princípios do compilador e como tornar o código JavaScript mais produtivo.

Descobriremos se o WASM é um item importante para melhorar o desempenho do código e se as otimizações são sempre justificadas.
Spoiler: "A otimização prematura é a raiz de todos os males", Donald Knuth.
 Sobre o palestrante:
Sobre o palestrante: Andrei Melikhov trabalha no Yandex.Money, escreve ativamente no Node.js e menos no navegador, para que o JavaScript do servidor esteja mais próximo dele. Andrew apoia e desenvolve a comunidade devShacht, então confira o
GitHub ou o
Medium .
Motivação e Glossário
Hoje vamos falar sobre a compilação JIT. Eu acho que isso é interessante para você, pois você está lendo isso. No entanto, vamos esclarecer por que você precisa saber o que é o JIT e como a V8 funciona e por que escrever React em um navegador não é suficiente.
- Permite que você escreva um código mais eficiente , porque nosso idioma é específico.
- Ele revela quebra-cabeças porque nas bibliotecas de outras pessoas o código é escrito dessa maneira, e não de outra forma. Às vezes, encontramos bibliotecas antigas e vemos o que está escrito lá de alguma forma estranho, mas se isso é necessário, não é necessário - não está claro. Quando você sabe como isso funciona, você entende por que isso foi feito.
- Isto é apenas interessante . Além disso, permite entender o que Axel Rauschmeier, Benedict Moyrer e Dan Abramov se comunicam no Twitter.
A Wikipedia diz que o JavaScript é uma linguagem de programação interpretada de alto nível com digitação dinâmica. Lidaremos com esses termos.
Compilação e interpretaçãoCompilação - quando o programa é entregue em código binário e é inicialmente otimizado para o ambiente em que irá funcionar.
Interpretação - quando entregamos o código como está.
O JavaScript é entregue como está - é uma linguagem interpretada, conforme escrito na Wikipedia.
Digitação dinâmica e estáticaA digitação estática e dinâmica é frequentemente confundida com a digitação fraca e forte. Por exemplo, C é um idioma com digitação fraca estática. JavaScript tem digitação dinâmica fraca.
Qual é o melhor? Se o programa compilar, ele será voltado para o ambiente em que será executado, o que significa que funcionará melhor. A digitação estática torna esse código mais eficiente. Em JavaScript, o oposto é verdadeiro.
Mas, ao mesmo tempo, nosso aplicativo está se tornando mais complexo: no cliente e no servidor, grandes clusters aparecem no Node.js, que funcionam bem e substituem aplicativos Java.
Mas como tudo funciona se inicialmente parece ser um perdedor.
O JIT reconciliará todos! Ou pelo menos tente.
Temos um JIT (compilação Just In Time) que acontece em tempo de execução. Vamos conversar sobre ela.
Js engines
- Chakra não amado, localizado no Internet Explorer. Nem funciona com JavaScript, mas com Jscript - existe esse subconjunto.
- Chakra moderno e ChakraCore que funcionam no Edge;
- SpiderMonkey no FireFox;
- JavaScriptCore no WebKit. Também é usado no React Native. Se você possui um aplicativo RN para Android, ele também é executado no JavaScriptCore - o mecanismo é fornecido com o aplicativo.
- V8 é o meu favorito. Não é o melhor, apenas trabalho com o Node.js, no qual é o mecanismo principal, como em todos os navegadores baseados no Chrome.
- Rhino e Nashorn são os mecanismos usados em Java. Com a ajuda deles, você também pode executar o JavaScript lá.
- JerryScript - para dispositivos incorporados;
- e outros ...
Você pode escrever seu próprio mecanismo, mas se você avançar para uma execução efetiva, chegará aproximadamente ao mesmo esquema, que mostrarei mais adiante.
Hoje vamos falar sobre o V8, e sim, é nomeado após o motor de 8 cilindros.
Subimos sob o capô
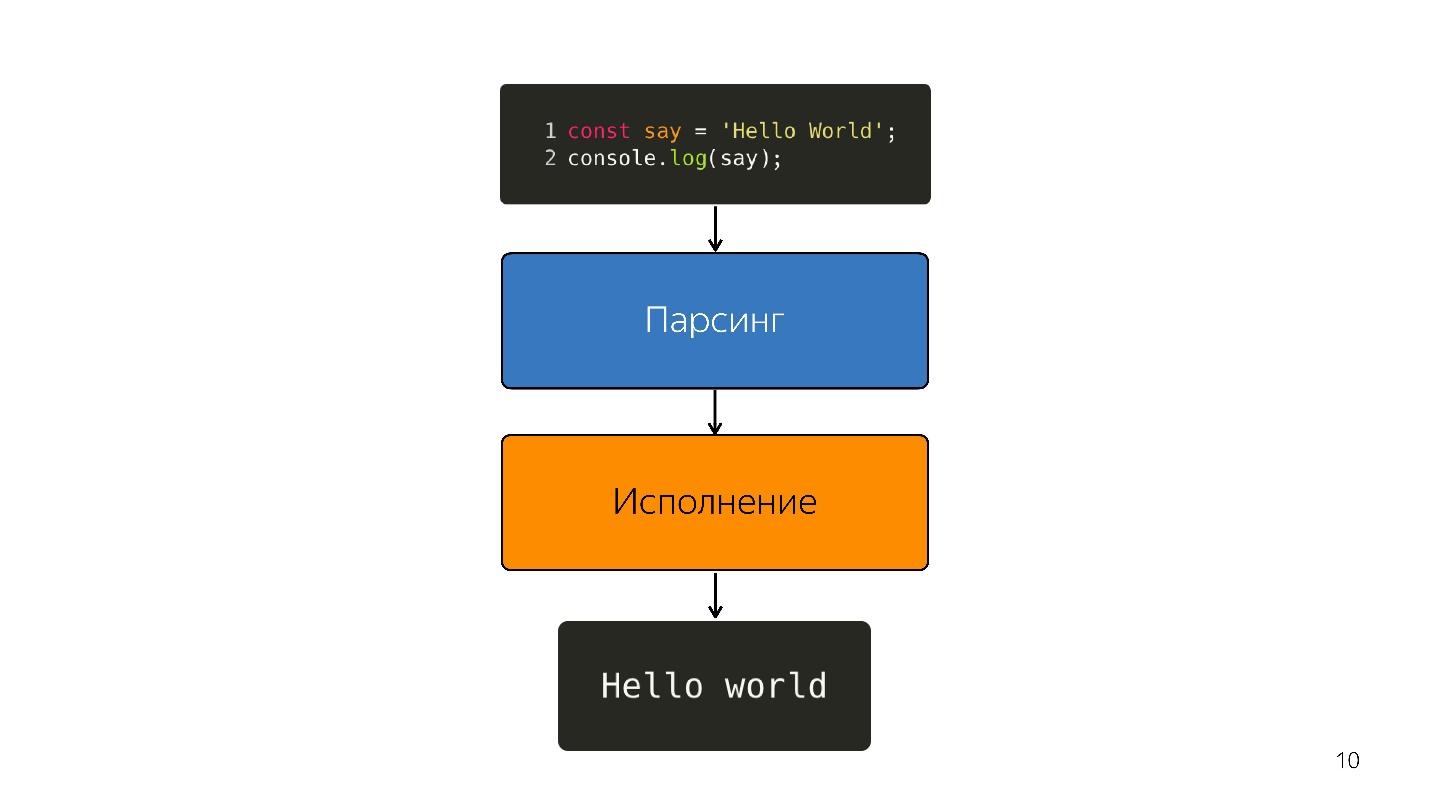
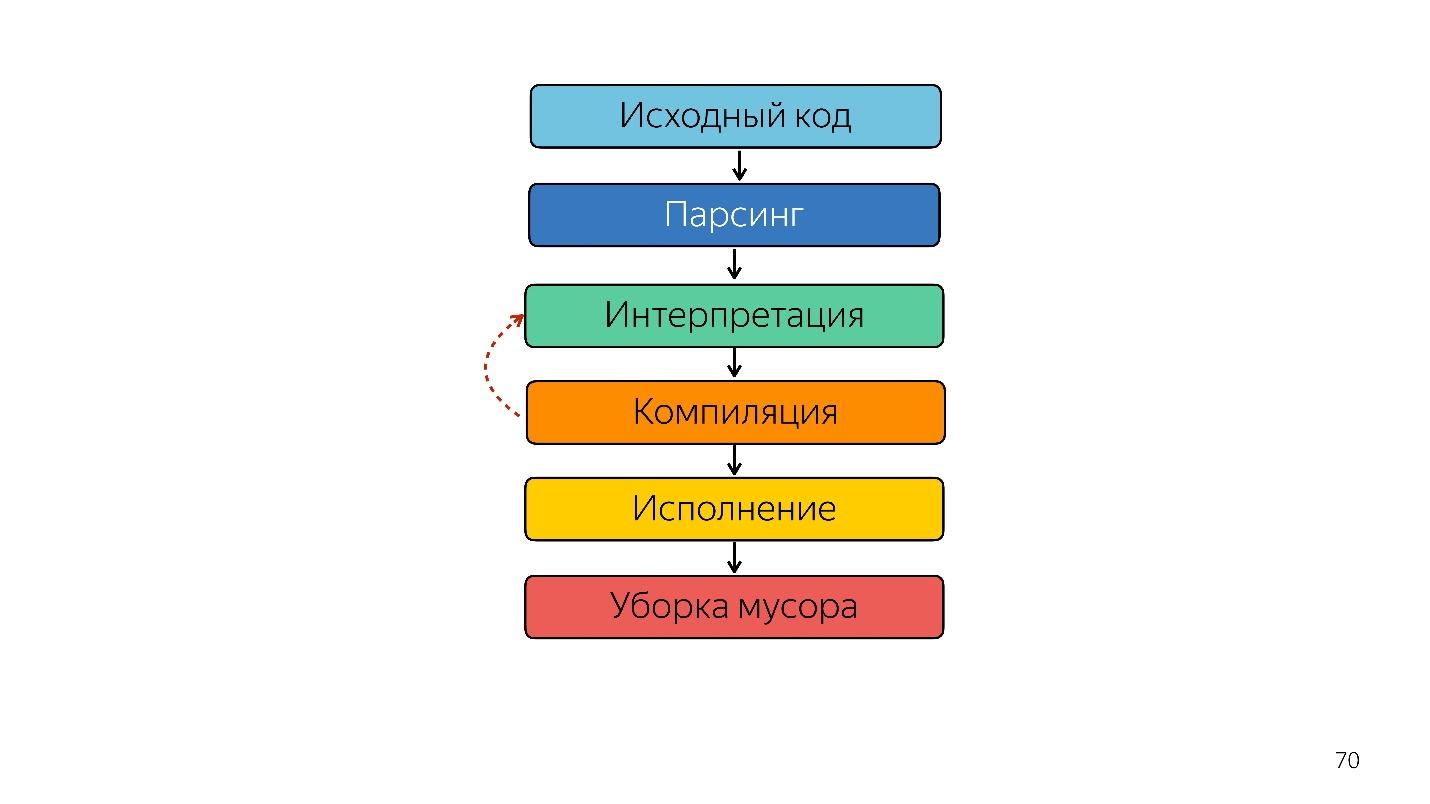
Como o javascript é executado?
- Há código escrito em JavaScript, que é fornecido.
- ele está analisando;
- está sendo executado;
- o resultado é obtido.
A análise transforma o código em uma
árvore de sintaxe abstrata . AST é uma exibição da estrutura sintática do código na forma de uma árvore. Isso é realmente conveniente para o programa, embora seja difícil de ler.
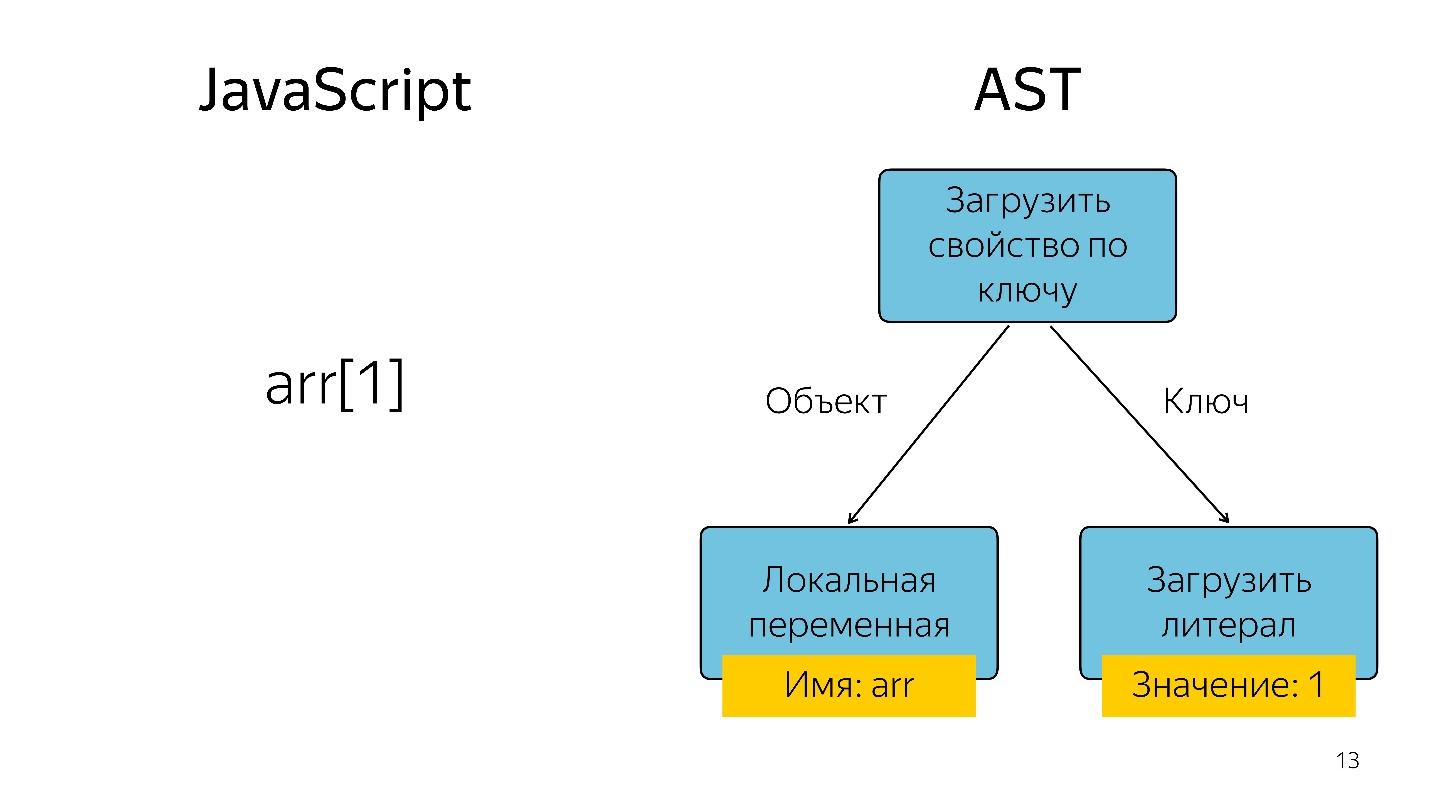
Obter um elemento da matriz com o índice 1 na forma de uma árvore é representado como um operador e dois operandos: carregue a propriedade pela chave e essas chaves.
Onde o AST é usado?
AST não é apenas em motores. Usando o AST, muitos utilitários escrevem extensões, incluindo:
- ESLint;
- Babel;
- Mais bonito
- Jscodeshift.
Por exemplo, a coisa legal Jscodeshift, sobre a qual nem todo mundo sabe ainda, permite escrever transformações. Se você alterar a API de uma função, poderá definir essas transformações nela e fazer alterações em todo o projeto.

Nós seguimos em frente. O processador não entende a árvore de sintaxe abstrata; ele precisa de
código de máquina . Portanto, outras transformações ocorrem através do intérprete, porque a linguagem é interpretada.
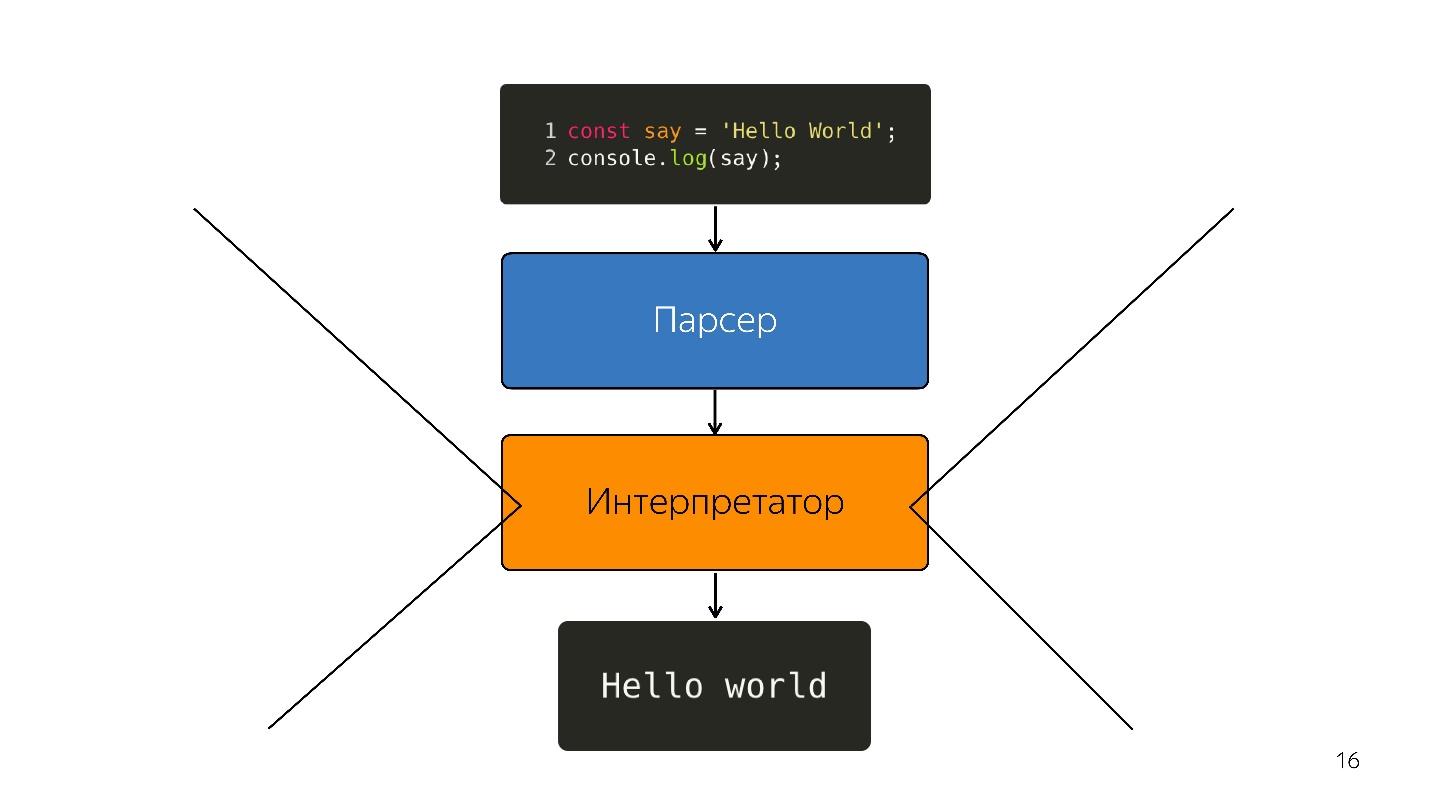
Assim, enquanto os navegadores tinham um pouco de JavaScript - destaque a linha, abra algo, feche. Mas agora temos aplicativos - SPA, Node.js e o
intérprete está se tornando um gargalo .
Otimizando o Compilador JIT
Em vez de um intérprete, um compilador JIT otimizado aparece, ou seja, um compilador Just-in-time. Compiladores antecipados funcionam antes da execução do aplicativo e JIT - durante. Na questão da otimização, o compilador JIT tenta adivinhar como o código será executado, quais tipos serão usados e otimizar o código para que funcione melhor.
Essa otimização é chamada
especulativa , porque especula sobre o conhecimento do que aconteceu com o código antes. Ou seja, se algo com o tipo de número foi chamado 10 vezes, o compilador acha que isso acontecerá o tempo todo e otimiza para esse tipo.
Naturalmente, se Booleano entrar na entrada, a desoptimização ocorre. Considere uma função que adiciona números.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Dobrado uma vez, pela segunda vez. O compilador cria a previsão: "Estes são números, eu tenho uma solução legal para adicionar números!" E você escreve
foo('WTF', 'JS') e passa as linhas para a função - temos JavaScript, podemos adicionar uma linha com um número.
Nesse ponto, a desoptimização ocorre.
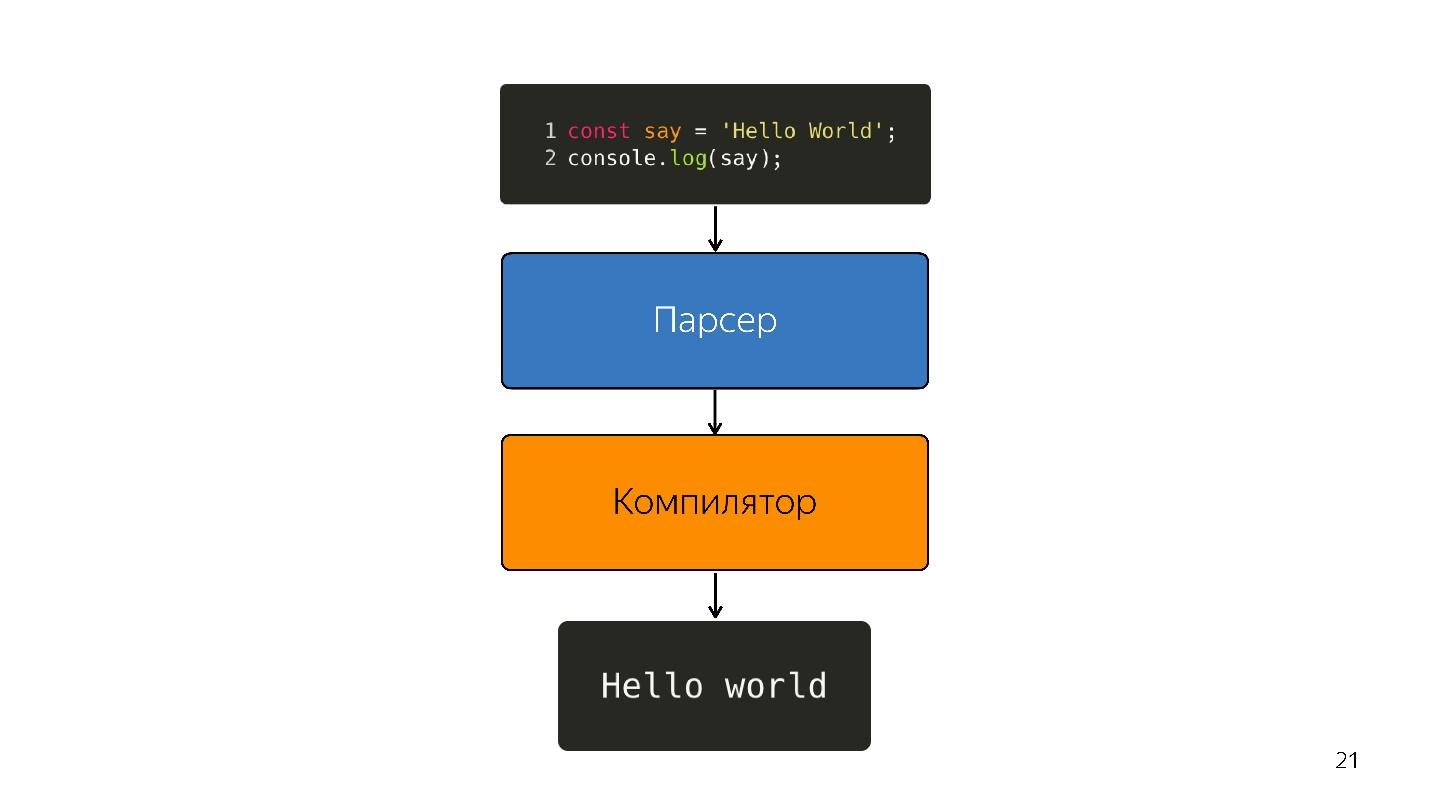
Portanto, o intérprete foi substituído pelo compilador. O diagrama acima parece ter um pipeline muito simples. Na realidade, tudo é um pouco diferente.
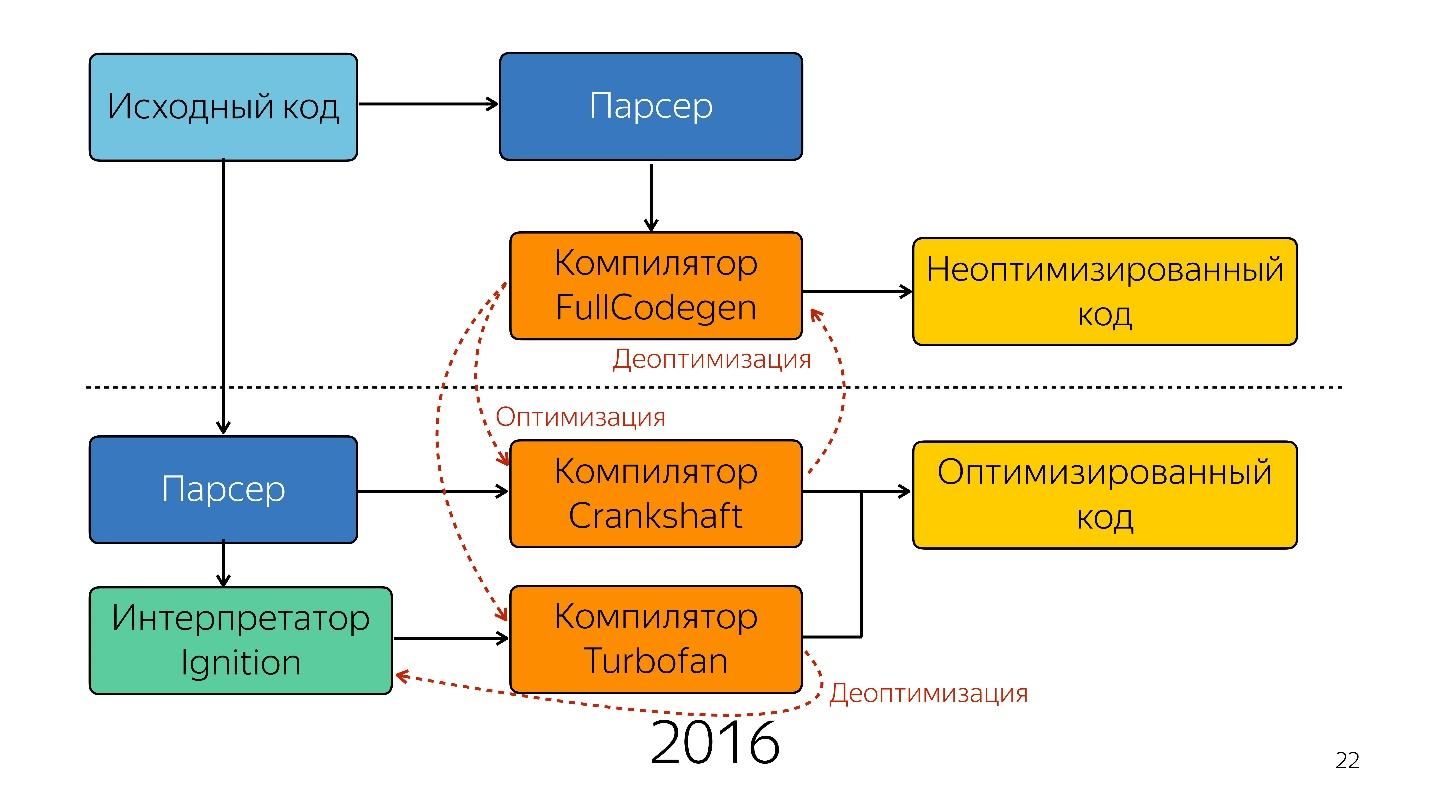
Isso foi até o ano passado. No ano passado, você ouviu muitos relatórios do Google de que eles lançaram um novo pipeline com o TurboFan e agora o esquema parece mais simples.
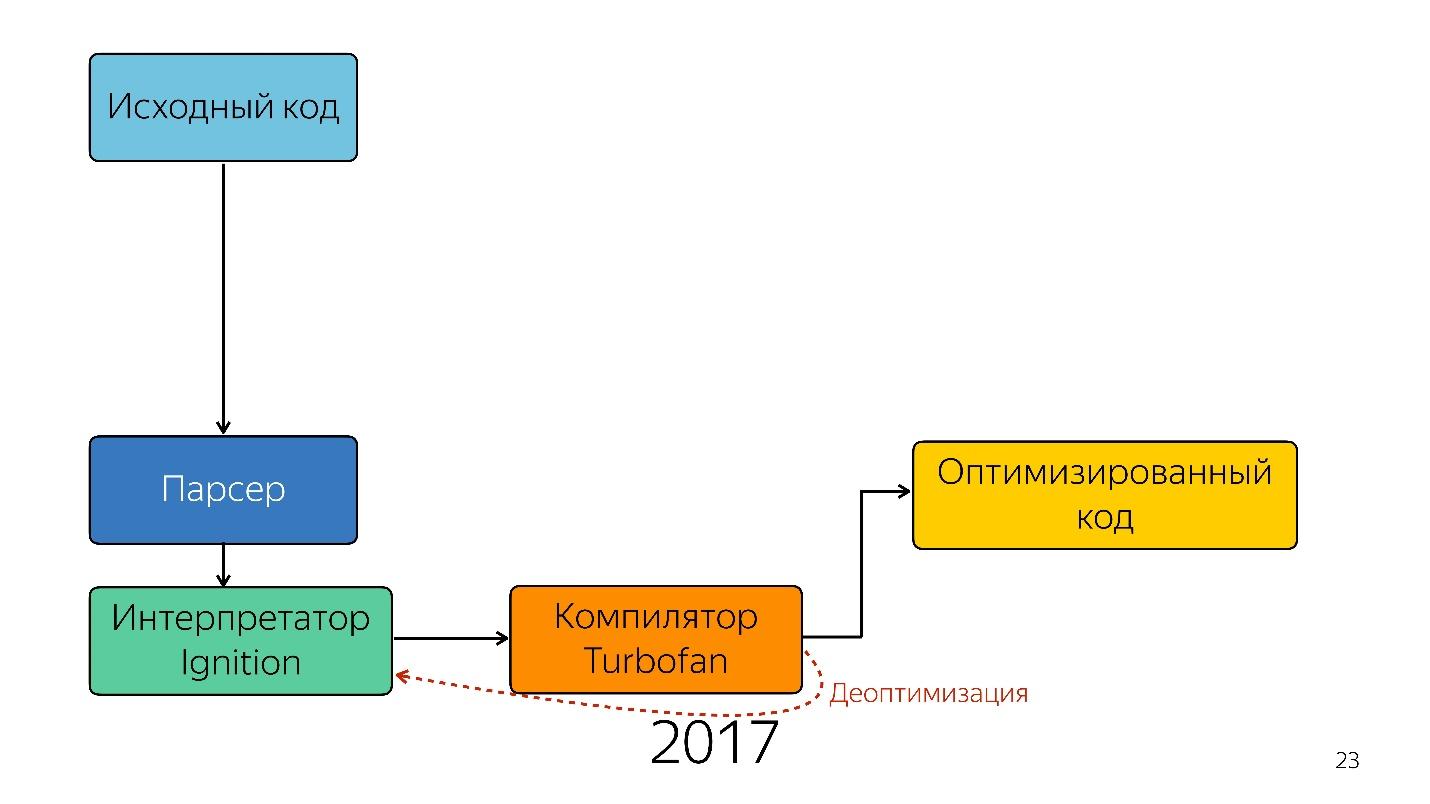
Curiosamente, um intérprete apareceu aqui.
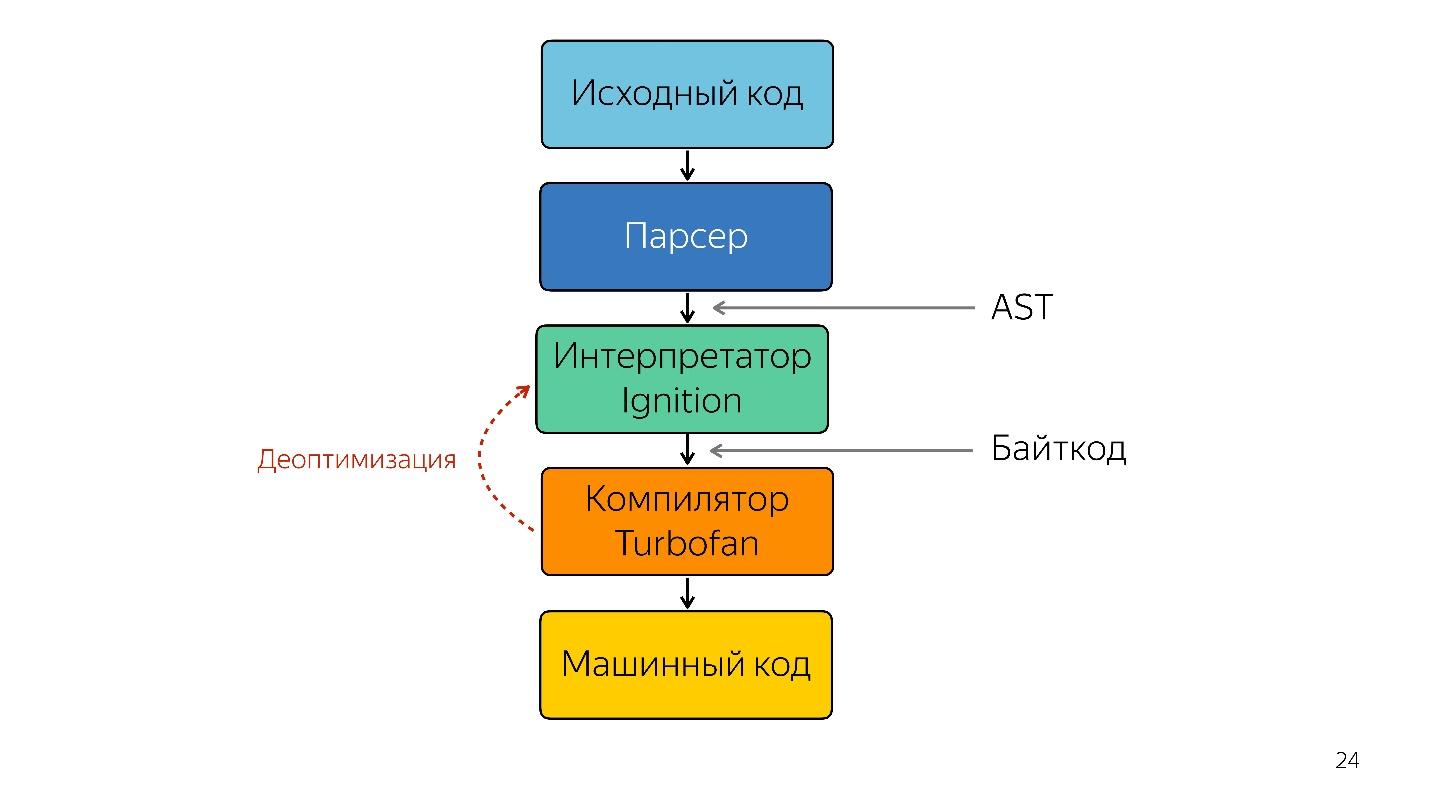
É necessário um intérprete para transformar uma árvore de sintaxe abstrata em um bytecode e passar o bytecode para um compilador. No caso de desoptimização, ele volta ao intérprete.
Ignição de intérpretes
Anteriormente, não havia esquema do interpretador de ignição. O Google disse inicialmente que não é necessário um intérprete - o JavaScript já é compacto e interpretável - não ganharemos nada.
Mas a equipe que trabalhou com aplicativos móveis encontrou o seguinte problema.

Em 2013-2014, as pessoas começaram a usar dispositivos móveis para acessar a Internet com mais frequência do que o desktop. Basicamente, este não é um iPhone, mas de dispositivos mais simples - eles têm pouca memória e um processador fraco.
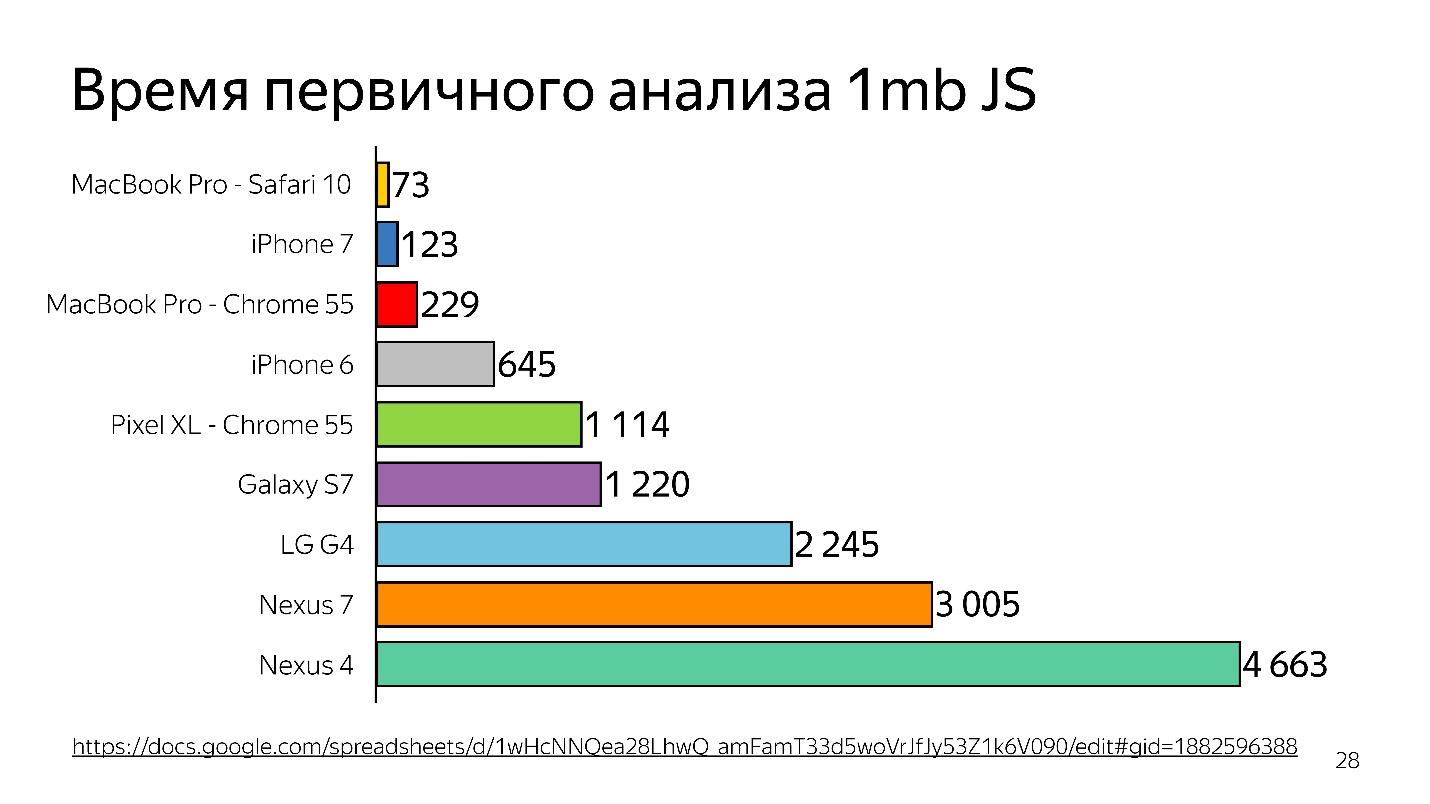
Acima está um gráfico da análise inicial de 1 MB de código antes de iniciar o intérprete. Pode-se ver que a área de trabalho ganha muito. O iPhone também não é ruim, mas tem um mecanismo diferente, e estamos falando do V8, que funciona no Chrome.
Você sabia que se você instalar o Chrome no iPhone, ele ainda funcionará no JavaScriptCore?
Assim, o tempo é desperdiçado - e isso é apenas análise, não execução - seu arquivo foi carregado e está tentando entender o que está escrito nele.
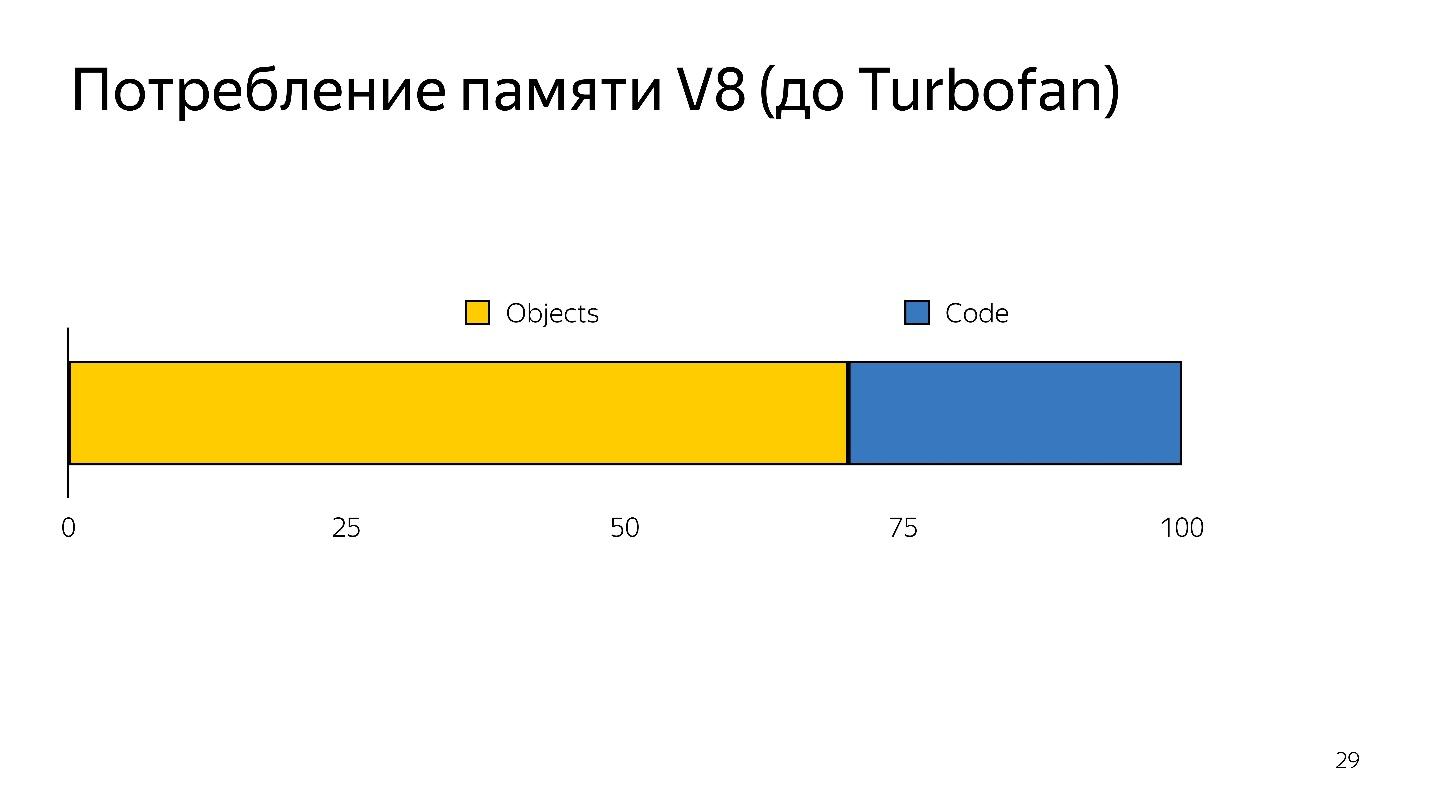
Quando a desoptimização ocorre, você precisa pegar o código fonte novamente, ou seja, ele precisa ser armazenado em algum lugar. Foi preciso muita memória.
Assim, o intérprete teve duas tarefas:
- reduzir a sobrecarga de análise;
- reduza o consumo de memória.
As tarefas foram resolvidas mudando para um intérprete de bytecode.
 O bytecode no Chrome é uma máquina de registro com bateria
O bytecode no Chrome é uma máquina de registro com bateria . O SpiderMonkey possui uma máquina empilhada, todos os dados estão na pilha, mas não há registros. Aqui estão eles.
Não analisaremos completamente como isso funciona, basta olhar para o fragmento de código.

Diz aqui: pegue o valor que está na bateria e adicione-o ao valor que está no registro
a0 , ou seja, na variável
a . Ainda não se sabe nada sobre os tipos aqui. Se fosse um código assembler real, seria escrito com um entendimento de que tipo de turnos existem na memória, o que há nele. Aqui está apenas uma instrução - pegue o que está no registro
a0 e adicione-o ao valor que está na bateria.
Obviamente, o intérprete não pega apenas a árvore de sintaxe abstrata e a traduz em código de bytes.
Também há otimizações, por exemplo, eliminação de código morto.
Se uma seção do código não for chamada, ela será descartada e não será mais armazenada. Se Ignition vê a adição de dois números, ele os adiciona e os deixa de forma a não armazenar informações desnecessárias. Somente depois disso é obtido o bytecode.
Otimização e desoptimização
Recursos frios e quentes
Este é o tópico mais fácil.
Funções frias são aquelas que foram chamadas uma vez ou não foram chamadas, funções quentes são aquelas que foram chamadas várias vezes. É impossível dizer exatamente quantas vezes - a qualquer momento isso pode ser refeito. Mas, em algum momento, a função fica quente e o mecanismo entende que precisa ser otimizado.

O esquema do trabalho.
- A ignição (intérprete) coleta informações. Ele não apenas converte o JavaScript em código de bytes, mas também entende quais tipos entraram, quais funções ficaram quentes e informa o compilador sobre tudo isso.
- Existe uma otimização.
- O compilador executa o código. Tudo funciona bem, mas aqui chega um tipo que ele não esperava, ele não tem código para trabalhar com esse tipo.
- Desoptimização ocorre. O compilador acessa o intérprete do Ignition para esse código.
Este é um ciclo normal que ocorre o tempo todo, mas não é infinito. Em algum momento, o mecanismo diz: "Não, é impossível otimizar" e começa a executar sem otimização. É importante entender que o monomorfismo deve ser observado.
Monomorfismo é quando os mesmos tipos sempre chegam à entrada da sua função. Ou seja, se você recebe string o tempo todo, não precisa passar booleano para lá.
Mas o que fazer com objetos? Objetos são todos objetos. Temos aulas, mas elas não são reais - é apenas açúcar sobre o modelo de protótipo. Mas dentro do mecanismo existem as chamadas classes ocultas.
Classes ocultas
Existem classes ocultas em todos os mecanismos, não apenas no V8. Em todos os lugares em que são chamados de maneira diferente, em termos de V8, é o Mapa.
Todos os objetos que você criou têm classes ocultas. Se você
olhe para o criador de perfil de memória, você verá que existem elementos onde a lista de elementos está armazenada, propriedades onde a propriedade está armazenada e mapa (geralmente o primeiro parâmetro), onde um link para ele é indicado em sua classe oculta.
Mapa descreve a estrutura dos objetos, porque, em princípio, em JavaScript, a digitação é possível apenas estrutural, não nominal. Podemos descrever como nosso objeto se parece, para que serve.
Ao excluir / adicionar propriedades de objetos de classes ocultas, o objeto é alterado, um novo é atribuído. Vamos dar uma olhada no código.
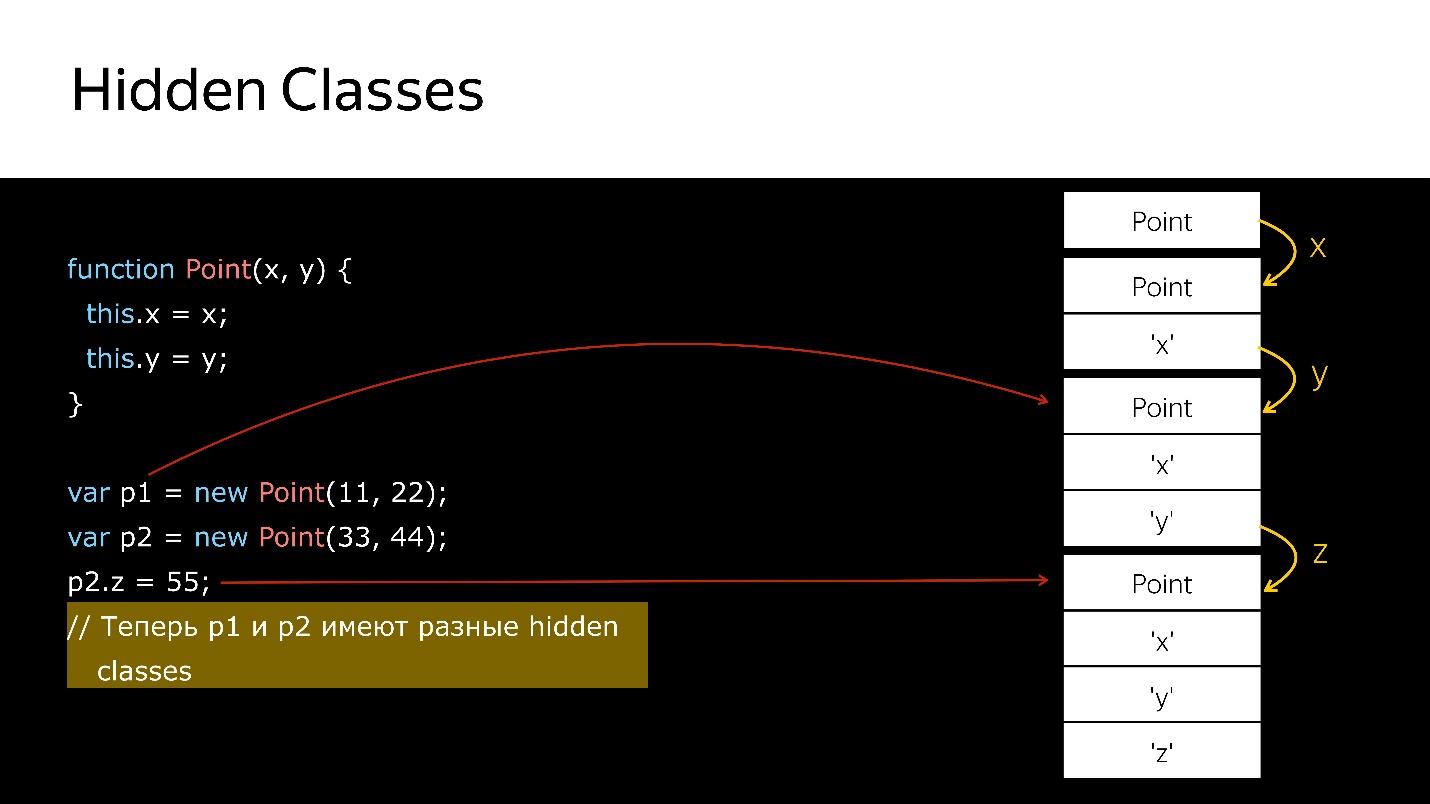
Temos um construtor que cria um novo objeto do tipo Point.
- Crie um objeto.
- Vincule uma classe oculta a ela, que diz que é um objeto do tipo Point.
- Adicionamos o campo x - uma nova classe oculta que diz que é um objeto do tipo Point, no qual o valor x vem primeiro.
- Adicionado y - as novas classes ocultas, nas quais x e, em seguida, y.
- Criou outro objeto - a mesma coisa acontece. Ou seja, ele também liga o que já foi criado. Neste momento, esses dois objetos são do mesmo tipo (via classes ocultas).
- Quando um novo campo é adicionado ao segundo objeto, uma nova classe Oculta é exibida no objeto. Agora, para o mecanismo p1 e p2, esses são objetos de classes diferentes, porque possuem estruturas diferentes
- Se você transferir o primeiro objeto para algum lugar, quando você transferir o segundo para lá, a desoptimização ocorrerá. A primeira se refere a uma classe oculta, a segunda a outra.
Como posso verificar as classes ocultas?No Node.js, você pode executar o nó —allow-natives-syntax. Então você terá a oportunidade de escrever comandos em uma sintaxe especial que, é claro, não pode ser usada na produção. É assim:
%HaveSameMap({'a':1}, {'b':1})
Ninguém garante que amanhã esses comandos funcionem, eles não estão na especificação ECMAScript, isso é tudo para depuração.
O que você acha que será o resultado da chamada da função% HaveSameMap para dois objetos. A resposta correta é falsa, porque uma tem um campo e a outra tem
b . Estes são objetos diferentes. Esse conhecimento pode ser usado para a técnica de caches em linha.
Caches em linha
Chamamos uma função muito simples que retorna um campo de um objeto. Devolver a unidade parece ser muito simples. Mas se você olhar para a especificação ECMAScript, verá que há uma lista enorme do que você precisa fazer para obter o campo do objeto. Porque, se o campo não estiver no objeto, é possível que esteja em seu protótipo. Talvez seja setter, getter e assim por diante. Tudo isso precisa ser verificado.

Nesse caso, o objeto possui um link para o mapa, que diz: para obter o campo
x , você precisa fazer um deslocamento de um e obtemos
x . Você não precisa subir em lugar algum, em nenhum protótipo, tudo está próximo. Caches embutidos usam isso.
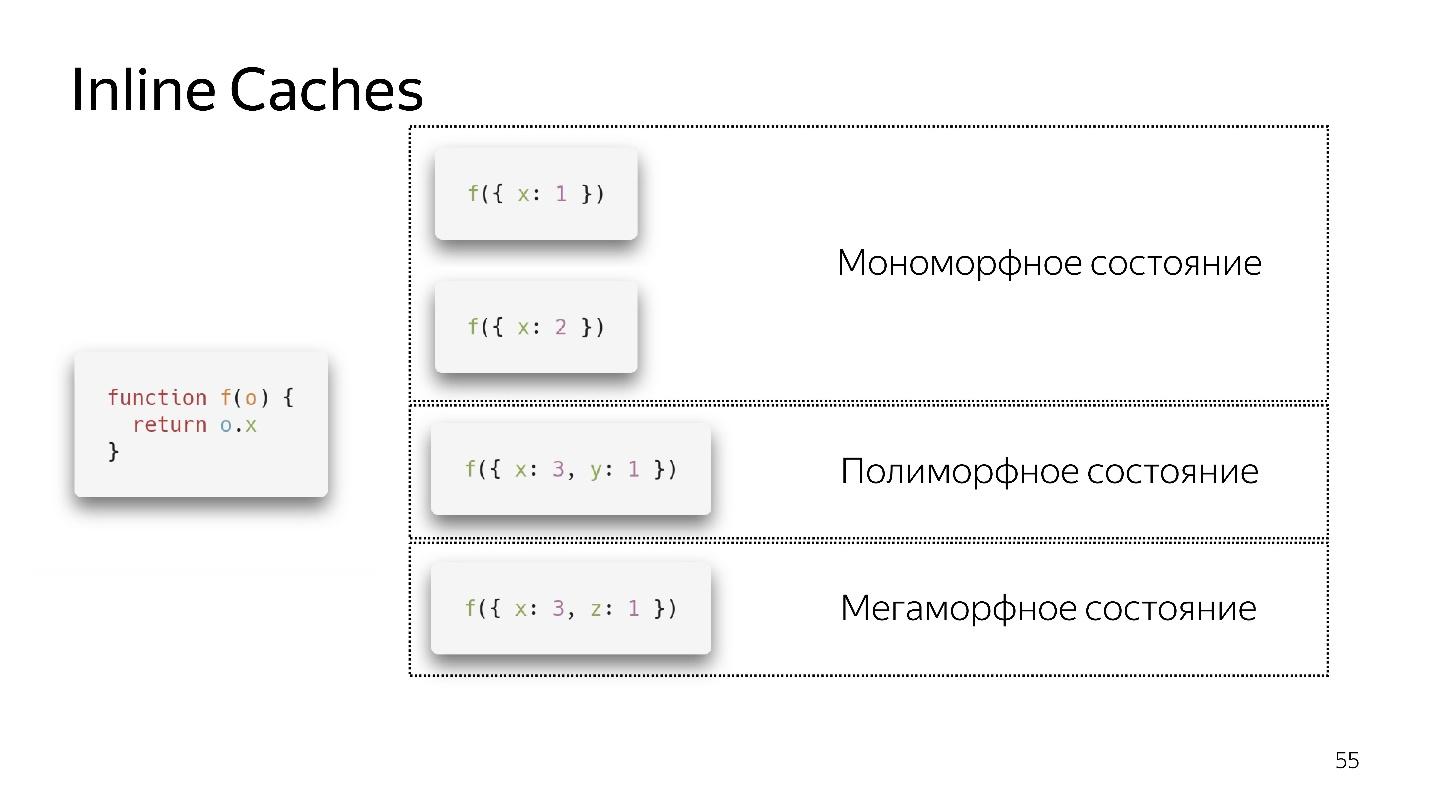
- Se chamarmos a função pela primeira vez, está tudo bem, o intérprete fez a otimização
- Para a segunda chamada, um estado monomórfico é salvo.
- Chamo a função pela terceira vez, passo um objeto ligeiramente diferente {x: 3, y: 1}. A desoptimização ocorre, se aparecer, entramos em um estado polimórfico. Agora, o código que executa essa função sabe que dois tipos diferentes de objetos podem voar nele.
- Se passarmos objetos diferentes várias vezes, ele permanecerá em um estado polimórfico, adicionando novos ifs. Mas em algum momento se rende e entra em um estado megamórfico, ou seja, quando: "Muitos tipos diferentes chegam à entrada - não sei como otimizá-lo!"
Parece que agora quatro estados polimórficos são permitidos, mas amanhã pode haver 8. Isso é decidido pelos desenvolvedores do mecanismo. É melhor ficarmos em um estado monomórfico, em casos extremos, polimórficos. A transição entre estados monomórficos e polimórficos é cara, porque você precisará ir ao intérprete, obter o código novamente e otimizar novamente.
Matrizes
No JavaScript, além das matrizes digitadas específicas, há um tipo
array. Existem 6 deles no mecanismo V8:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS - apenas uma matriz compactada de número inteiro pequeno. Existem otimizações para ele.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS - uma matriz compactada de elementos duplos, também há otimizações para ele, mas são mais lentas.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - um array empacotado no qual existem objetos, strings e tudo mais. Para ele também há otimizações.
Os três tipos a seguir são matrizes do mesmo tipo que os três primeiros, mas com orifícios:
4. [1, / * orifício * /, 2, / * orifício * /, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, / * orifício * /, 2, / * orifício * /, 3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * buraco * /, 'X'] // HOLEY_ELEMENTS
Quando os furos aparecem em suas matrizes, as otimizações se tornam menos eficientes. Eles começam a funcionar mal, porque é impossível passar por essa matriz seguidamente, classificando as iterações. Cada tipo subseqüente é menos otimizado
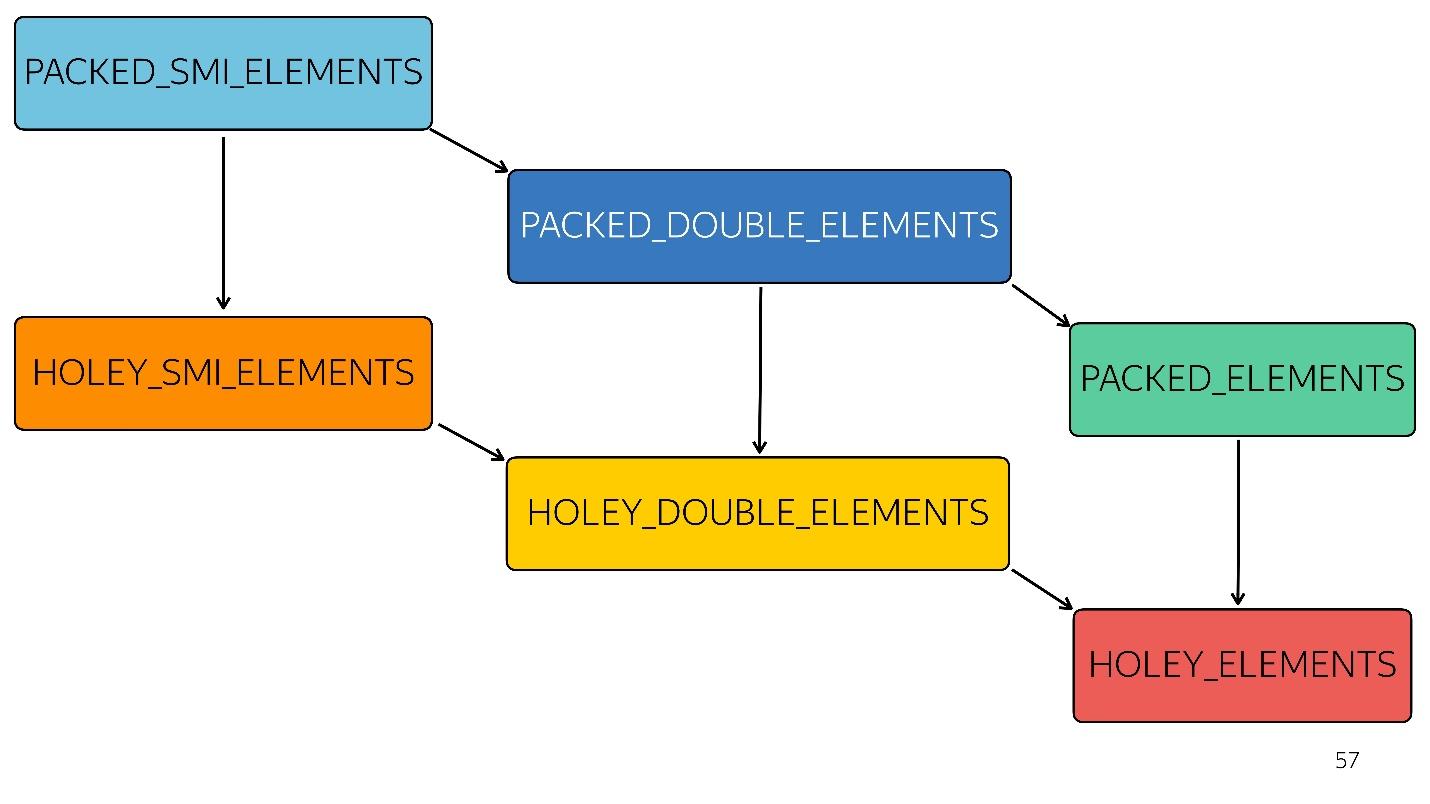
No diagrama, tudo acima é otimizado mais rapidamente. Ou seja, todos os seus métodos nativos - mapear, reduzir, classificar - por dentro são bem otimizados. Mas com cada tipo, a otimização fica pior.
Por exemplo, uma matriz simples [
1 ,
2 ,
3 ] chegou à entrada (número inteiro pequeno compactado). Alteramos levemente esse array adicionando um duplo a ele - entramos no estado PACKED_DOUBLE_ELEMENTS. Adicione um objeto a ele - vá para o próximo estado, o retângulo verde PACKED_ELEMENTS. Adicione furos a ele - vá para o estado HOLEY_ELEMENTS. Queremos restaurá-lo ao seu estado anterior para que se torne "bom" novamente - excluímos tudo o que escrevemos e permanecemos no mesmo estado ... com buracos! Ou seja, HOLEY_ELEMENTS no canto inferior direito do diagrama. Voltar isso não funciona. Suas matrizes só podem piorar, mas não vice-versa.
Objeto parecido com uma matriz
Muitas vezes encontramos objetos semelhantes a matrizes - esses são objetos que parecem matrizes porque têm um sinal de comprimento. De fato, eles são como um gato pirata, ou seja, parecem semelhantes, mas na eficiência do consumo de rum, um gato será pior que um pirata. Da mesma forma, um objeto semelhante a uma matriz é como uma matriz, mas não é eficiente.

Nossos dois objetos favoritos do tipo matriz são argumentos e document.querySelectorAII. Existem coisas funcionais tão bonitas.
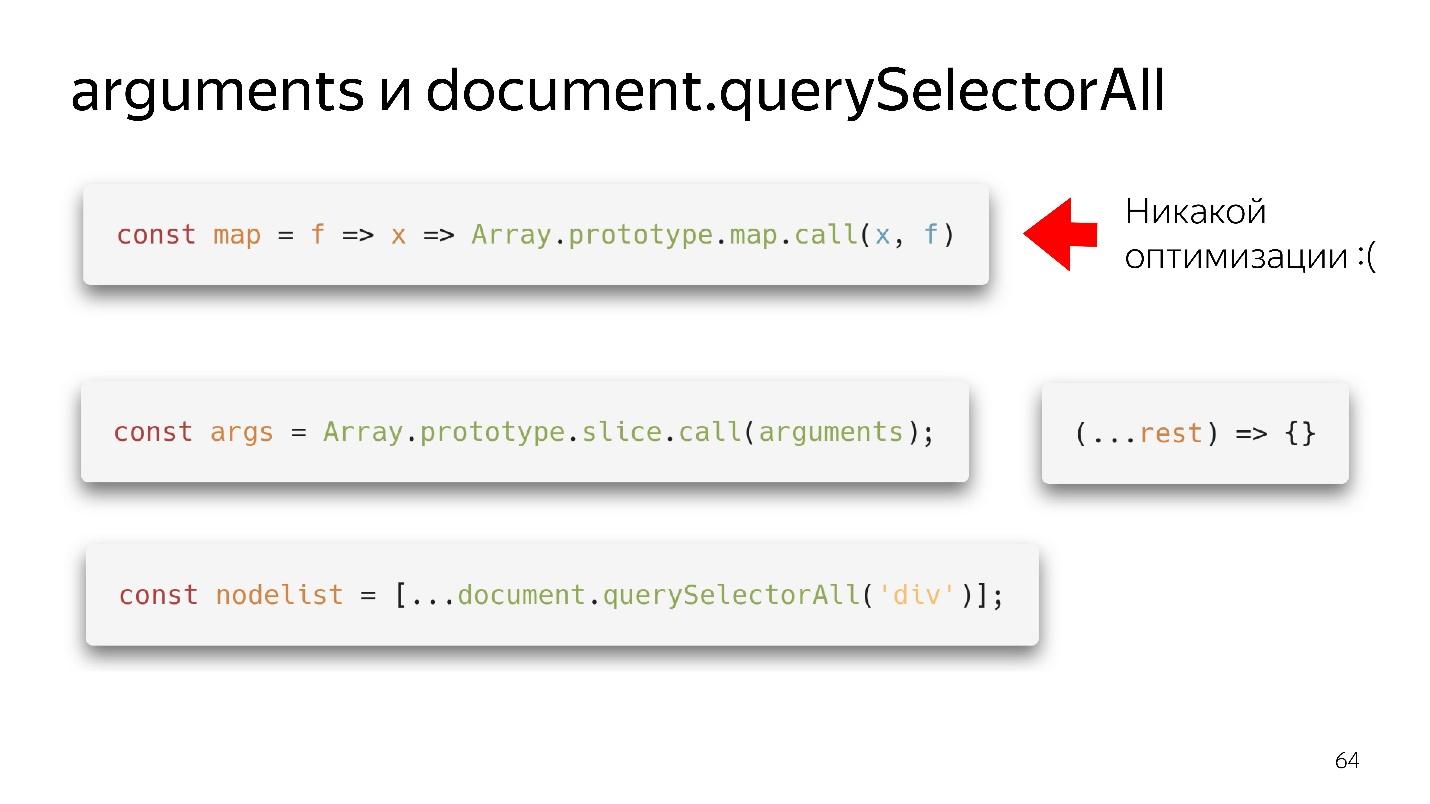
Temos um mapa - nós o arrancamos do protótipo e aparentemente podemos usá-lo. Mas se não houver um array para sua entrada, não haverá otimização. Nosso mecanismo não é capaz de otimizar objetos.
O que precisa ser feito?
- A opção da velha escola - através de slice.call () se transforma em uma matriz real.
- A opção moderna é ainda melhor: escreva (... descanse), obtenha uma matriz limpa - não argumentos - está tudo bem!
Com querySelectorAll a mesma coisa - devido à propagação, podemos transformá-lo em uma matriz completa e trabalhar com todas as otimizações.
Matrizes grandes
Charada: nova matriz (1000) vs matriz = []
Qual opção é melhor: crie imediatamente uma matriz grande e preencha-a com 1000 objetos em um loop ou crie uma vazia e preencha-a gradualmente?
Resposta correta: depende.
Qual a diferença?
- Quando criamos uma matriz da primeira maneira e preenchemos 1000 elementos, criamos 1000 furos. Essa matriz não será otimizada. Mas ele escreverá rapidamente.
- Criando uma matriz de acordo com a segunda variante, um pouco de memória é alocado, escrevemos, por exemplo, 60 elementos, um pouco mais de memória é alocado etc.
Ou seja, no primeiro caso, escrevemos rapidamente - trabalhamos devagar; no segundo, escrevemos devagar - trabalhamos rapidamente.
Coletor de lixo
O coletor de lixo também consome um pouco de tempo e recursos. Sem mergulhar profundamente, darei a base mais comum.

Nosso modelo generativo possui um
espaço de objetos jovens e velhos . O objeto criado cai no espaço de objetos jovens. Após algum tempo, a limpeza começa. Se o objeto não puder ser alcançado pelos links da raiz, ele poderá ser coletado no lixo. Se o objeto ainda estiver em uso, ele se moverá para o espaço de objetos antigos, que são limpos com menos frequência. No entanto, em algum momento, os objetos antigos são excluídos.

É assim que um coletor de lixo automático funciona - ele limpa os objetos com base no fato de que não há links para eles. Estes são dois algoritmos diferentes.
- A limpeza é rápida, mas não eficaz.
- Mark-Sweep é lento, mas eficiente.
Se você começar a criar um perfil do consumo de memória no Node.js, obterá algo assim.

A princípio, cresce abruptamente - este é o trabalho do algoritmo Scavenge. Então ocorre uma queda acentuada - esse algoritmo Mark-Sweep coletou lixo no espaço de objetos antigos. Neste momento, tudo começa a desacelerar um pouco.
Você não pode controlá-lo , porque você não sabe quando isso acontecerá. Você só pode ajustar os tamanhos.
Portanto, o pipeline possui um estágio de coleta de lixo que consome tempo.
Ainda mais rápido?
Vamos olhar para o futuro. O que fazer a seguir, como ser mais rápido?
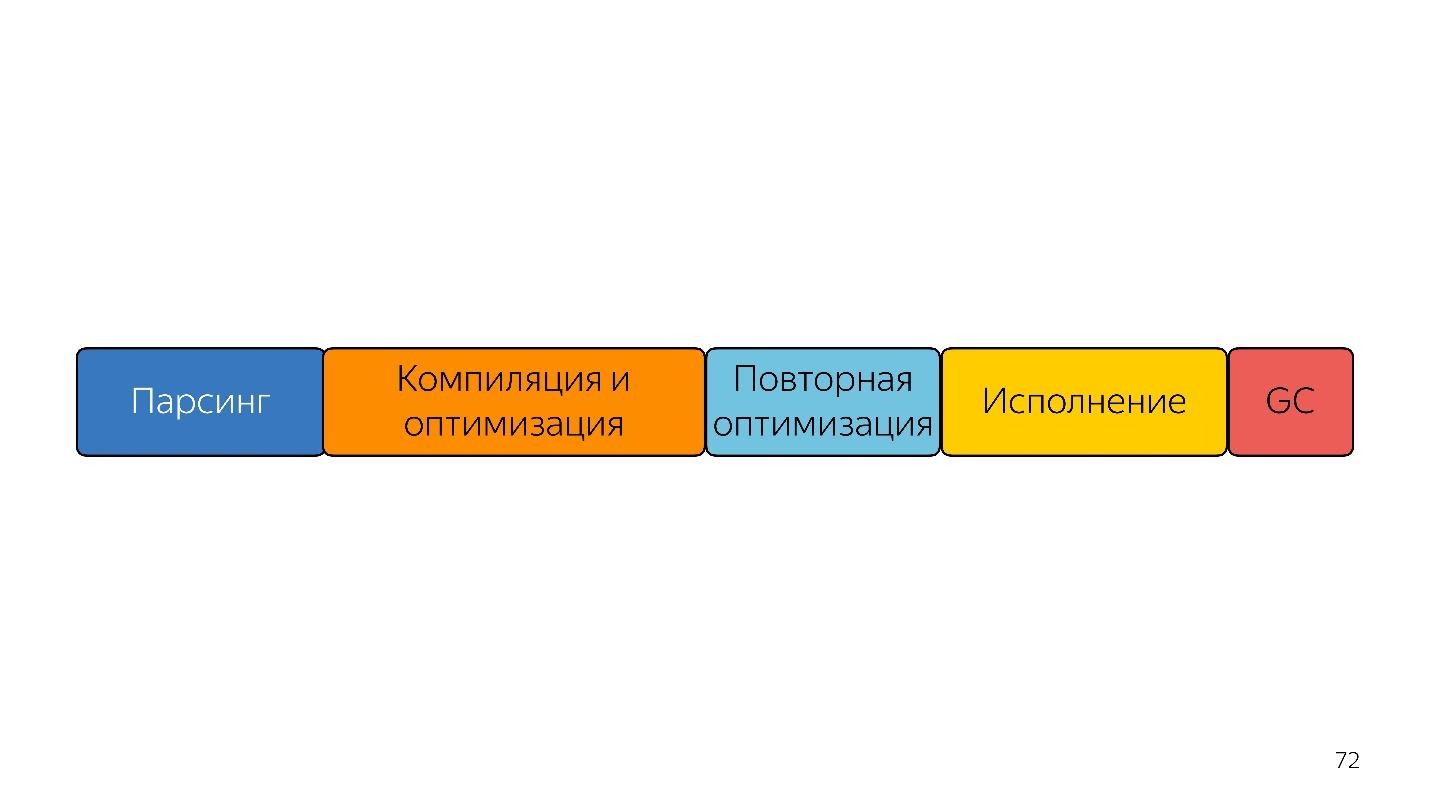
Nesta linha, os tamanhos dos blocos estão aproximadamente relacionados no tempo que leva.
A primeira coisa que vem à mente das pessoas que ouviram falar sobre bytecode - envie imediatamente um bytecode à entrada e decodifique-a, em vez de analisá-la - será mais rápida!

O problema é que o bytecode é diferente agora. Como eu disse: no Safari um, no FireFox outro, no Chrome terceiro. No entanto, desenvolvedores da Mozilla, Bloomberg e Facebook apresentaram essa
proposta , mas este é o futuro.
Há outro problema - compilação, otimização e re-otimização, se o compilador não adivinhar. Imagine que haja uma linguagem de tipo estaticamente na entrada que produza código efetivo, o que significa que a re-otimização não é mais necessária, porque o que obtivemos já é eficiente. Essa entrada só pode ser compilada e otimizada uma vez. O código resultante será mais eficiente e será executado mais rapidamente.
O que mais pode ser feito? Imagine que esse idioma tenha gerenciamento manual de memória. Então não precisa de um coletor de lixo. A linha ficou mais curta e mais rápida.

Adivinha o que parece?
WebAssembly aproximadamente
é assim que funciona: gerenciamento manual de memória, tipicamente estaticamente
idiomas e execução rápida.

O WebAssembly é uma bala de prata?

Não, porque significa JavaScript. O WASM ainda não pode fazer nada. Ele não tem acesso à API DOM. Está dentro do mecanismo JavaScript - dentro do mesmo mecanismo! Ele faz tudo através do JavaScript, portanto o
WASM não acelerará o seu código . Isso pode acelerar cálculos individuais, mas sua troca entre JavaScript e WASM será um gargalo.
Portanto, enquanto a nossa linguagem é JavaScript e apenas ela, e alguma ajuda da caixa preta.
Total
Três tipos de otimização podem ser distinguidos.
●
Otimizações algorítmicasHá um artigo "
Talvez você não precise do Rust para acelerar o seu JS " de Vyacheslav Egorov, que desenvolveu o V8 e agora está desenvolvendo o Dart. Recontar brevemente sua história.
Havia uma biblioteca JavaScript que não funcionava muito rápido. Alguns caras o reescreveram no Rust, compilaram e obtiveram o WebAssembly, e o aplicativo começou a funcionar mais rapidamente. Vyacheslav Egorov, como um desenvolvedor JS experiente, decidiu respondê-los. Ele aplicou otimizações algorítmicas e a solução JavaScript ficou muito mais rápida que a solução Rust. Por sua vez, esses caras viram isso, fizeram as mesmas otimizações e venceram novamente, mas não muito - depende do mecanismo: no Mozilla eles venceram, no Chrome não.
Hoje, não falamos sobre otimizações algorítmicas, e as renderizações de front-end geralmente não falam sobre elas. Isso é muito ruim, porque os
algoritmos também permitem que o código seja executado mais rapidamente . Você simplesmente remove os ciclos que não precisa.
●
Otimizações específicas do idiomaÉ disso que falamos hoje: nossa linguagem é interpretada de forma dinâmica. Compreender como matrizes, objetos e monomorfismo funcionam
permite escrever código eficiente . Isso deve ser conhecido e escrito corretamente.
●
Otimizações específicas do mecanismoEssas são as otimizações mais perigosas. Se o seu desenvolvedor muito inteligente, mas não muito sociável, que aplicou muitas dessas otimizações e não contou a ninguém sobre elas, não escreveu a documentação, se você abrir o código, não verá JavaScript, mas, por exemplo, o Crankshaft Script. Ou seja, o JavaScript foi escrito com uma profunda compreensão de como o motor do virabrequim funcionava há dois anos. Tudo funciona, mas agora não é mais necessário.
Portanto, essas otimizações devem necessariamente ser documentadas, cobertas com testes que comprovem sua eficácia no momento. Eles devem ser monitorados. Você precisa procurá-los apenas no momento em que realmente desacelerou em algum lugar - você não pode ficar sem conhecer dispositivos tão profundos. Portanto, a famosa frase de Donald Knuth parece lógica.

Não há necessidade de tentar implementar qualquer tipo de otimizações rígidas apenas porque você lê críticas positivas sobre elas.
É preciso ter medo dessas otimizações, documentar e deixar métricas. Geralmente sempre colete métricas.
Métricas são importantes!Links úteis:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.