1. Introdução
Há algum tempo, participei de um projeto para desenvolver um produto de software projetado para analisar registros e dados de pacientes sobre seu estado de saúde provenientes de organizações médicas, a fim de criar um registro médico unificado. Por um longo tempo, a equipe não pôde desenvolver uma abordagem para combinar dados do paciente. O ponto de partida foi o estudo dos códigos-fonte da solução Open EMPI (Open Enterprise Master Patient Index), que nos levou a criar algoritmos de análise de similaridade. A partir desse momento, iniciou-se um estudo mais aprofundado dos materiais, o que possibilitou a criação de um layout primeiro e, depois, de uma solução funcional.
Até agora, em vários tipos de apresentações, é preciso ouvir muitas perguntas sobre a lógica do trabalho de tais produtos, das quais concluo que uma revisão dos métodos de vinculação de texto será de interesse de um amplo círculo de leitores.
O material é uma tradução do artigo da Wikipédia " Record linkage " com direitos autorais e adições.
O que é vinculação de texto?
O termo " ligação de registro" descreve o processo de anexar registros de texto de uma fonte de dados a registros de outra, desde que descrevam o mesmo objeto. Na ciência da computação, isso é chamado de "mapeamento de dados" ou "problema de identidade de objeto" . Às vezes, definições alternativas são usadas, como "identificação" , "ligação" , detecção de duplicados " , " desduplicação " , " registros correspondentes " , " identificação de objetos " , que descrevem o mesmo conceito. Essa abundância terminológica levou a uma separação das abordagens de processamento e estruturação de informações - ligação de registros e ligação de dados . Embora ambos determinem a identificação de objetos correspondentes por diferentes conjuntos de parâmetros, o termo "vinculando registros de texto" é comumente usado quando se refere à "essência" de uma pessoa, enquanto "vinculação de dados" significa a possibilidade de vincular qualquer recurso da Web entre conjuntos de dados, usando, respectivamente, o conceito mais amplo de um identificador, ou seja, um URI.
Por que isso é necessário?
Ao desenvolver produtos de software para a construção de sistemas automatizados usados em vários campos relacionados ao processamento de dados pessoais de uma pessoa (assistência médica, histórico, estatísticas, educação etc.), surge a tarefa de identificar dados sobre assuntos contábeis provenientes de várias fontes.
No entanto, ao coletar descrições de um grande número de fontes, surgem problemas que dificultam sua identificação inequívoca. Esses problemas incluem:
- erros de digitação;
- permutações de campo (por exemplo, no primeiro nome);
- o uso de abreviações e abreviações;
- o uso de um formato diferente de identificadores (datas, números de documentos etc.).
- distorção fonética;
- etc.
A qualidade dos dados brutos afeta diretamente o resultado do processo de ligação. Devido a esses problemas, os conjuntos de dados são frequentemente transferidos para o processamento, que, embora descrevam o mesmo objeto, parece que esses registros parecem diferentes. Portanto, por um lado, todos os identificadores de registro transmitidos são avaliados quanto à aplicabilidade para uso no processo de identificação e, por outro lado, os próprios registros são normalizados ou padronizados para trazê-los para um único formato.
Tour histórico
A idéia original de vincular notas foi apresentada por Halbert L. Dunn, que publicou um artigo intitulado "Record Linkage" no American Journal of Public Health em 1946.
Mais tarde, em 1959, em um artigo na Vinculação automática de registros vitais na revista Science, Howard B. Newcombe lançou os fundamentos probabilísticos da moderna teoria das cordas, que foram desenvolvidas e reforçadas em 1969 por Ivan Fellegi e Alan. Santer (Alan Sunter). Seu trabalho "Uma teoria para a ligação de registros" ainda é a base matemática de muitos algoritmos de ligação.
O principal desenvolvimento dos algoritmos foi nos anos 90 do século passado. Então, de várias áreas (estatística, arquivamento, epidemiologia, história e outras), chegaram-nos algoritmos frequentemente usados em produtos de software, como a similaridade (distância) da distância de Jaro-Winkler e a distância de Levenshtein , no entanto, algumas soluções, por exemplo, o algoritmo fonético Soundex, apareceram muito antes - nos anos 20 do século passado.
Algoritmos de comparação de entrada de texto
Distinga entre algoritmos determinísticos e probabilísticos para comparar registros de texto. Os algoritmos determinísticos são baseados na coincidência completa dos atributos do registro. Os algoritmos probabilísticos permitem calcular o grau de correspondência dos atributos do registro e, com base nisso, decidir a possibilidade de seu relacionamento.
Algoritmos determinísticos
A maneira mais fácil de comparar seqüências de caracteres é baseada em regras claras quando links entre objetos são gerados com base no número de correspondências dos atributos dos conjuntos de dados. Ou seja, dois registros correspondem um ao outro através de um algoritmo determinístico se todos ou alguns de seus atributos forem idênticos. Os algoritmos determinísticos são adequados para comparar assuntos descritos por um conjunto de dados que são identificados por um identificador comum (por exemplo, o número de seguro de uma conta pessoal individual no Fundo de Pensões - SNILS) ou têm vários identificadores representativos (data de nascimento, sexo etc.) confiáveis.
Algoritmos determinísticos podem ser aplicados quando conjuntos de dados claramente estruturados (padronizados) são transferidos para o processamento.
Por exemplo, ele tem o seguinte conjunto de entradas de texto:
| Não. | SNILS | Primeiro nome | Data de nascimento | Sexo |
|---|
| A1 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A2 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A3 | 126-029-036 24 | Ilchenko Victor | 01/02/1937 | M |
| A4 | | Novikova Klara | 26.12.1946 | F |
| Não. | SNILS | Primeiro nome | Data de nascimento | Sexo |
|---|
| B1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | M |
| B2 | | Zhivanetsky Mikhail | 03/06/1934 | M |
| B3 | | Zerchaninova Klara | 26.12.1946 | 2 |
Foi dito anteriormente que o algoritmo determinístico mais simples é o uso de um identificador único, que deveria identificar uma pessoa de forma exclusiva. Por exemplo, supomos que todos os registros que possuem o mesmo valor identificador (SNILS) descrevam o mesmo assunto, caso contrário, são assuntos diferentes. A conexão determinística neste caso irá gerar os seguintes pares: A1 e A2, A3 e B1. B2 não será associado a A1 e A2, pois o identificador não importa, embora coincida no conteúdo com os registros especificados.
Essas exceções levam à necessidade de suplementar o algoritmo determinístico com novas regras. Por exemplo, se não houver um identificador exclusivo, você poderá usar outros atributos, como nome, data de nascimento e sexo. No exemplo dado, essa regra adicional novamente não dará correspondência B2 e A1 / A2, porque agora os nomes são diferentes - há uma distorção fonética do sobrenome.
Esse problema pode ser resolvido usando os métodos de análise fonética, mas se você alterar o sobrenome (por exemplo, no caso de casamento), será necessário recorrer à aplicação de uma nova regra, por exemplo, comparar a data de nascimento ou permitir diferenças nos atributos existentes do registro (por exemplo, sexo).
O exemplo ilustra claramente que o algoritmo determinístico é muito sensível à qualidade dos dados, e um aumento no número de atributos de registro pode levar a um aumento substancial no número de regras aplicadas, o que complica bastante o uso de algoritmos determinísticos.
Além disso, o uso de algoritmos determinísticos é possível se houver um conjunto de dados verificado (referência principal) com o qual as informações recebidas são comparadas. No entanto, no caso de reabastecimento constante do próprio diretório mestre, pode ser necessária uma revisão completa dos relacionamentos existentes, o que torna o uso de algoritmos determinísticos demorado ou simplesmente impossível.
Algoritmos Probabilísticos
Os algoritmos probabilísticos para vincular registros de cadeia de caracteres usam um conjunto mais amplo de atributos que os determinísticos, e para cada atributo é calculado um coeficiente de peso que determina a capacidade de influenciar a conexão na avaliação final da probabilidade de conformidade dos registros estimados. Os registros que acumularam o peso total acima de um determinado limite são considerados relacionados, os registros que acumularam o peso total abaixo de um limite são considerados não relacionados. Os pares que obtiveram o valor do peso total no meio da faixa são considerados candidatos à vinculação e podem ser considerados mais tarde (por exemplo, pelo operador), que decidirão sobre sua união (link) ou os deixarão separados. Assim, diferentemente dos algoritmos determinísticos, que são um conjunto de um grande número de regras claras (programadas), os algoritmos probabilísticos podem ser adaptados à qualidade dos dados selecionando valores de limiar e não requerem reprogramação.
Assim, algoritmos probabilísticos atribuem coeficientes de peso ( u e m ) aos atributos do registro, com a ajuda da qual será determinada sua correspondência ou inconsistência entre si.
O coeficiente u determina a probabilidade de que os identificadores de dois registros independentes coincidam aleatoriamente. Por exemplo, a probabilidade de u do mês de nascimento (quando existem doze valores uniformemente distribuídos) é 1 \ 12 = 0,083. Identificadores com valores que não são distribuídos uniformemente terão probabilidades diferentes para valores diferentes (às vezes, incluindo valores ausentes).
O coeficiente m é a probabilidade de que os identificadores nos pares comparados correspondam entre si ou sejam bastante semelhantes - por exemplo, no caso de uma alta probabilidade pelo algoritmo de Jaro-Winkler ou baixa pelo algoritmo de Levenshtein. Se os atributos dos registros forem totalmente consistentes, esse valor deverá ter um valor de 1,0, mas, dada a baixa probabilidade disso, o coeficiente deverá ser avaliado de forma diferente. Essa avaliação pode ser feita com base na análise preliminar do conjunto de dados, por exemplo, "aprendendo" manualmente o algoritmo probabilístico para identificar um grande número de pares correspondentes e incompatíveis ou iniciando iterativamente o algoritmo para selecionar o valor do coeficiente m mais adequado.
Se a probabilidade m for definida como 0,95, os coeficientes de conformidade / não conformidade para o mês de nascimento terão a seguinte aparência:
| Métrica | Partilha de links | Compartilhamento de valores, não referências | Frequência | Peso |
|---|
| Conformidade | m = 0,95 | u = 0,083 | m \ u = 11,4 | ln (m / u) / ln (2) ≈ 3,51 |
| Incompatibilidade | 1-m = 0,05 | 1-u = 0,917 | (1 m) / (1 u) ≈ 0,0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4,20 |
Cálculos semelhantes devem ser feitos para outros identificadores de registro, a fim de determinar seus coeficientes de conformidade e não conformidade. Em seguida, cada identificador de um registro é comparado com o identificador correspondente de outro registro para determinar o peso total do par: o peso do par correspondente é adicionado ao resultado total com um total cumulativo, enquanto o peso do par inadequado é subtraído do resultado total. A quantidade resultante é comparada com os valores limite identificados para determinar se deve ou não emparelhar o par analisado automaticamente ou transferi-lo para o operador para consideração.
Bloqueio
A determinação dos limites de conformidade / não conformidade é um equilíbrio entre a obtenção de sensibilidade aceitável (a parcela de registros relacionados detectados pelo algoritmo) e o valor preditivo do resultado (ou seja, precisão, como uma medida de registros realmente correspondentes vinculados pelo algoritmo). Como definir limites pode ser uma tarefa muito difícil, especialmente para grandes conjuntos de dados, um método conhecido como bloqueio é frequentemente usado para aumentar a eficiência computacional. São feitas tentativas para realizar uma comparação entre registros para os quais é revelada uma discrepância significativa ( discriminação ) nos valores dos atributos básicos. Isso leva a um aumento na precisão devido a uma diminuição na sensibilidade.
Por exemplo, o bloqueio com base na codificação fonética de um sobrenome reduz o número total de comparações necessárias e aumenta a probabilidade de que os relacionamentos entre os registros estejam corretos, pois os dois atributos já são consistentes, mas podem ignorar registros relacionados à mesma pessoa cujo sobrenome alterado (por exemplo, como resultado do casamento). O bloqueio por mês de nascimento é um indicador mais estável que só pode ser ajustado se houver um erro nos dados de origem, mas oferece um benefício mais modesto em valor preditivo positivo e perda de sensibilidade, pois cria doze grupos diferentes de conjuntos de dados extremamente grandes e não leva a um aumento na velocidade computação.
Assim, os sistemas de ligação de entrada de texto mais eficientes costumam usar vários passes de bloqueio para agrupar dados de várias maneiras, a fim de preparar grupos de registros que devem ser submetidos posteriormente para análise.
Aprendizado de máquina
Recentemente, vários métodos de aprendizado de máquina foram usados para vincular registros de texto. Em um artigo de 2011, Randall Wilson mostrou que o algoritmo clássico de vinculação probabilística para registros de texto é equivalente ao ingênuo algoritmo de Bayes e sofre os mesmos problemas com a suposição de que os recursos de classificação são independentes. Para aumentar a precisão da análise, o autor propõe usar um modelo básico de uma rede neural chamada perceptron de camada única, cuja utilização permite exceder significativamente os resultados obtidos usando algoritmos probabilísticos tradicionais.
Codificação fonética
Os algoritmos fonéticos combinam duas palavras pronunciadas da mesma forma com os mesmos códigos, o que permite comparar essas palavras com base em sua similaridade fonética.
A maioria dos algoritmos fonéticos é projetada para analisar palavras em inglês, embora recentemente alguns algoritmos tenham sido modificados para uso em outros idiomas ou tenham sido originalmente criados como soluções nacionais (por exemplo, Caverphone).
Soundex
O algoritmo clássico para comparar duas cordas pelo som é o Soundex (abreviação de Índice de som). Ele define o mesmo código para strings que possuem um som semelhante em inglês. O Soundex foi originalmente usado pela Administração de Arquivos Nacionais dos EUA na década de 1930 para analisar retrospectivamente os censos de 1890 a 1920.
Os autores dos algoritmos são Robert C. Russel e Margaret King Odell, que o patentearam nos anos 20 do século passado. O próprio algoritmo ganhou popularidade na segunda metade do século passado, quando se tornou objeto de vários artigos em revistas científicas populares nos EUA e foi publicado na monografia de D. Knut, “The Art of Programming”.
Daitch-Mokotoff Soundex
Como o Soundex é adequado apenas para o inglês, alguns pesquisadores tentaram modificá-lo. Em 1985, Gary Mokotoff e Randy Daitch propuseram uma variante do algoritmo Soundex, projetada para comparar sobrenomes do Leste Europeu (incluindo russo) com uma qualidade bastante alta.
Nos anos 90, Lawrence Philips (Lawrence Philips) propôs uma versão alternativa do algoritmo Soundex, chamado Metaphone. O novo algoritmo usou um conjunto maior de regras para a pronúncia em inglês, devido à qual era mais preciso. Posteriormente, o algoritmo foi modificado para ser utilizado em outras línguas, com base na transcrição, utilizando letras do alfabeto latino.
Em 2002, a 8ª edição da revista Programmer publicou um artigo de Peter Kankowski falando sobre sua adaptação da versão em inglês do algoritmo Metaphone. Esta versão do algoritmo converte as palavras-fonte de acordo com as regras e normas da língua russa, levando em consideração o som fonético das vogais não estressadas e a possível "fusão" de consoantes na pronúncia.
Em vez de uma conclusão
Como resultado de várias iterações, a equipe de projeto do projeto de desenvolvimento de produto de software, mencionada na introdução, desenvolveu uma solução de arquitetura, cujo esquema é mostrado na figura.
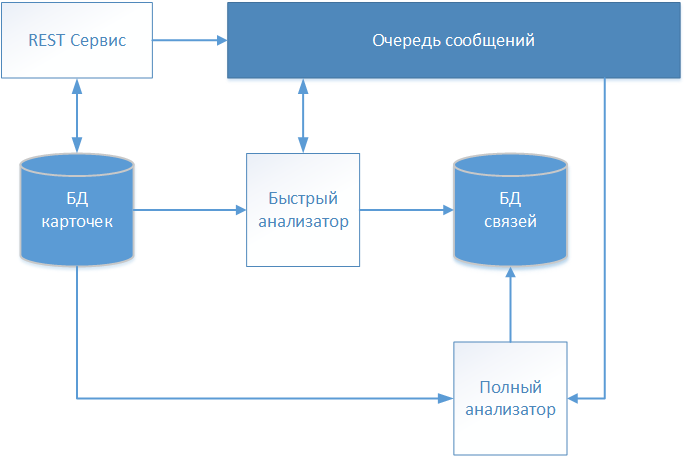
As descrições textuais dos pacientes são aceitas pelo serviço REST e armazenadas no repositório (banco de dados do cartão) sem nenhuma alteração. Como nosso sistema trabalha com dados médicos, o padrão FHIR (Fast Healthcare Interoperability Resources) foi escolhido para troca de informações. As informações sobre o cartão do paciente recebido são transferidas para a fila de mensagens para posterior análise e tomada de decisão sobre o estabelecimento da comunicação.
O primeiro cartão a ser processado é o “Quick Analyzer” operando em um algoritmo determinístico. Se todas as regras do algoritmo determinístico tiverem funcionado, ele cria um registro com um link para o cartão processado em um armazenamento separado (banco de dados de links). O registro contém, além do identificador do cartão analisado, a data do estabelecimento da comunicação e um identificador condicional que identifica o paciente globalmente identificado. Cartões adicionais são ainda referidos ao identificador global especificado, formando assim uma matriz que descreve um indivíduo específico.
Se o algoritmo determinístico não encontrar uma correspondência, as informações do cartão são transmitidas através da fila de mensagens para o “Analisador Completo”.
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .