Poucas pessoas têm um Glaster na Rússia, e qualquer experiência é interessante. Temos grande e industrial e, a julgar pela discussão no
último post , em demanda. Falei sobre o início da experiência de migração de backups do armazenamento corporativo para o Glusterfs.
Isso não é suficientemente explícito. Não paramos e decidimos coletar algo mais sério. Portanto, aqui falaremos sobre coisas como codificação de apagamento, sharding, reequilíbrio e sua otimização, teste de estresse e assim por diante.

- Mais teoria volum / subwolum
- reposição quente
- curar / curar completamente / reequilibrar
- Conclusões após a reinicialização de 3 nós (nunca faça isso)
- Como a gravação em diferentes velocidades de diferentes VMs e on / off do shard afeta a carga do subvolume?
- reequilibrar após a partida do disco
- reequilíbrio rápido
O que voce queria
A tarefa é simples: coletar uma loja barata, mas confiável. O mais barato possível, confiável - para que não seja assustador armazenar nossos próprios arquivos para venda. Tchau. Depois, após longos testes e backups em outro sistema de armazenamento - também no cliente.
Aplicativo (IO sequencial) :
- Backups
- Infraestruturas de teste
- Teste de armazenamento para arquivos de mídia pesados.
Nós estamos aqui.
- Arquivo de batalha e infraestrutura de teste séria
- Armazenamento de dados importantes.
Como na última vez, o principal requisito é a velocidade da rede entre instâncias do Glaster. 10G no começo está bem.
Teoria: o que é volume disperso?
O volume disperso é baseado na tecnologia de apagamento de codificação (EC), que fornece proteção bastante eficaz contra falhas de disco ou servidor. É como RAID 5 ou 6, mas não realmente. Ele armazena o fragmento codificado do arquivo para cada bloco de forma que apenas um subconjunto dos fragmentos armazenados nos briks restantes seja necessário para restaurar o arquivo. O número de tijolos que podem estar indisponíveis sem perda de acesso aos dados é configurado pelo administrador durante a criação do volume.
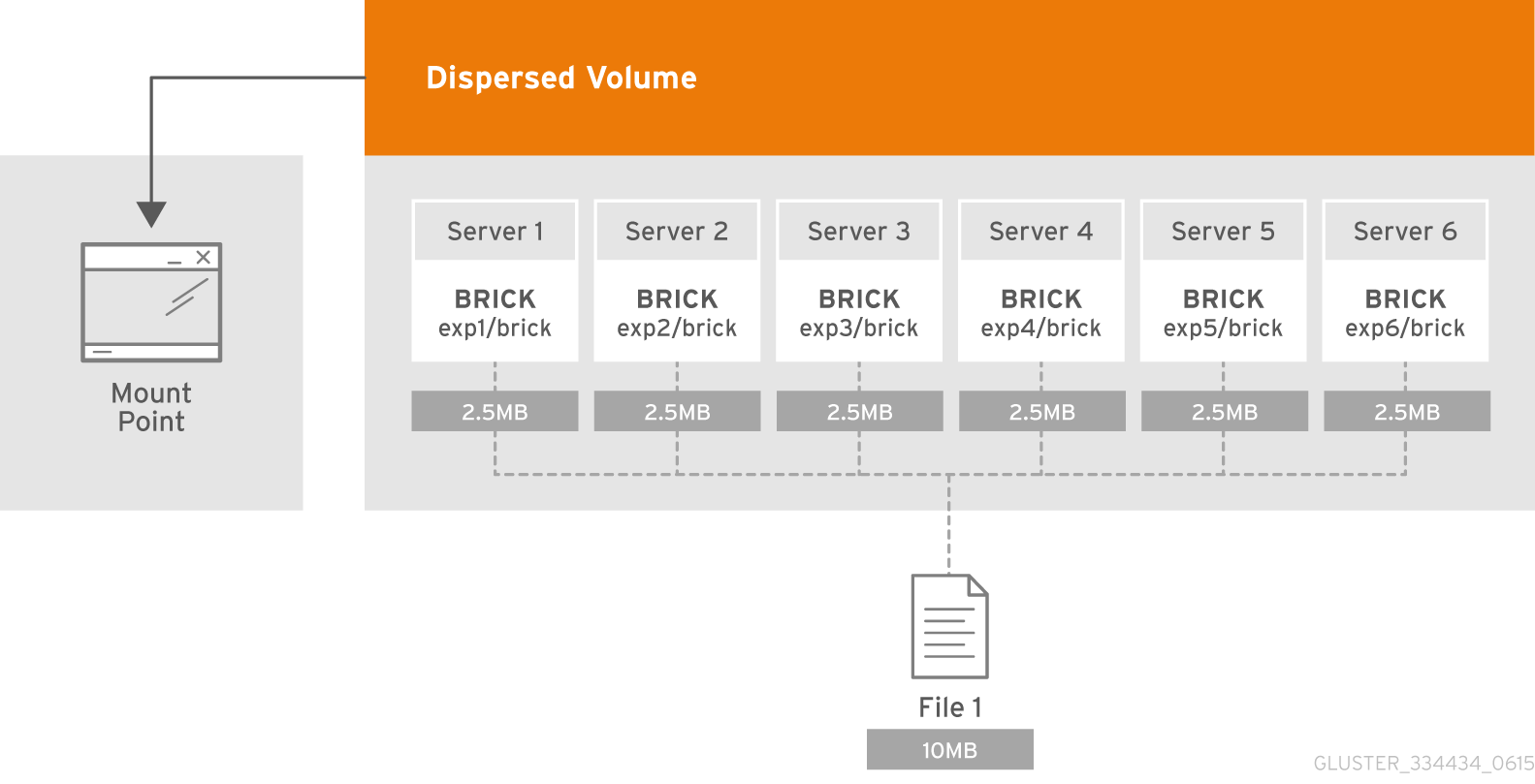
O que é um subvolume?
A essência do subvolume na terminologia do GlusterFS é manifestada juntamente com os volumes distribuídos. No apagamento com dispersão distribuída, a codificação funcionará apenas na estrutura do subwoofer. E no caso, por exemplo, com dados replicados distribuídos serão replicados dentro da estrutura do subwoofer.
Cada um deles é distribuído em servidores diferentes, o que permite que eles percam ou saiam livremente para sincronizar. Na figura, os servidores (físicos) são marcados em verde, os sub-lobos são pontilhados. Cada um deles é apresentado como um disco (volume) para o servidor de aplicativos:

Decidiu-se que a configuração 4 + 2 distribuída em 6 nós parece bastante confiável, podemos perder 2 servidores ou 2 discos em cada subwoofer, enquanto continuamos a ter acesso aos dados.
Tínhamos à disposição 6 DELL PowerEdge R510 antigos com 12 slots de disco e unidades SATA de 48x2TB 3.5. Em princípio, se houver um servidor com 12 slots de disco e com unidades de até 12 TB no mercado, podemos coletar armazenamento de até 576 TB de espaço útil. Mas não esqueça que, embora os tamanhos máximos de HDD continuem a crescer de ano para ano, o desempenho deles permanece parado e a reconstrução de um disco de 10 a 12 TB pode levar uma semana.
 Criação de volume:
Criação de volume:Uma descrição detalhada de como preparar tijolos, você pode ler no meu
post anteriorgluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Criamos, mas não temos pressa de lançar e montar, pois ainda precisamos aplicar vários parâmetros importantes.
O que temos: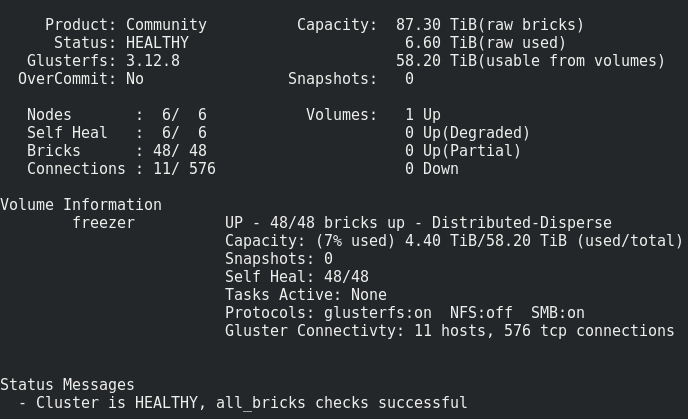
Tudo parece bastante normal, mas há uma ressalva.
Consiste em gravar esse volume nos tijolos:Os arquivos são colocados um a um nos sub-lobos e não são distribuídos uniformemente por eles; portanto, mais cedo ou mais tarde, veremos o tamanho e não o tamanho do volume inteiro. O tamanho máximo do arquivo que podemos colocar neste repositório é o tamanho utilizável do subwoofer menos o espaço já ocupado nele. No meu caso, é <8 Tb.
O que fazer? Como serEsse problema é resolvido com o sharding ou o volume da faixa, mas, como a prática demonstrou, a faixa funciona muito mal.
Portanto, tentaremos sharding.
O que é sharding, em detalhes aqui .
O que é sharding, em suma :
Cada arquivo que você coloca em um volume será dividido em partes (fragmentos), que são organizados de maneira relativamente uniforme em sub-lobos. O tamanho do shard é especificado pelo administrador, o valor padrão é 4 MB.
Ative o sharding após criar um volume, mas antes de iniciar :
gluster volume set freezer features.shard on
Expor tamanho caco (alguns dos melhores Dudes oVirt recomendar 512?): gluster volume set freezer features.shard-block-size 512MB
Empiricamente, verifica-se que o tamanho real do fragmento nos tijolos ao usar o volume disperso 4 + 2 é igual ao tamanho do bloco de fragmento / 4, no nosso caso 512M / 4 = 128M.
Cada fragmento, de acordo com a lógica de codificação do apagamento, é decomposto de acordo com os tijolos da estrutura do submundo com estas peças: 4 * 128M + 2 * 128M
Desenhe os casos de falha que o gluster sobrevive com esta configuração:Nesta configuração, podemos sobreviver à queda de 2 nós ou 2 de qualquer disco no mesmo subvolume.
Para os testes, decidimos colocar o armazenamento resultante em nossa nuvem e executar o fio a partir de máquinas virtuais.
Ativamos a gravação sequencial de 15 VMs e fazemos o seguinte.
Reinicialização do 1º nó:17:09
Parece não crítico (~ 5 segundos de indisponibilidade pelo parâmetro ping.timeout).
17:19
Lançado curar completamente.
O número de entradas de recuperação está apenas aumentando, provavelmente devido ao alto nível de gravação no cluster.
17:32
Foi decidido desativar a gravação da VM.
O número de entradas de cura começou a diminuir.
17:50
curar feito.
Reinicialize 2 nós:Os mesmos resultados são observados como no 1º nó.Reinicialize 3 nós:Ponto de montagem emitido O terminal de transporte não está conectado, as VMs receberam ioerror.
Depois de ligar os nós, o Glaster se restaurou, sem interferência do nosso lado, e o processo de tratamento começou.Mas 4 de 15 VMs não puderam subir. Vi erros no hypervisor:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Pagamento difícil com 3 nós com sharding desativado Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
Também perdemos dados, não é possível restaurar.
Pague gentilmente 3 nós com sharding, haverá corrupção de dados?Há, mas muito menos (coincidência?), Perdi 3 de 30 unidades.
Conclusões:- A cura desses arquivos trava indefinidamente, o reequilíbrio não ajuda. Concluímos que os arquivos para os quais a gravação ativa estava em andamento quando o terceiro nó foi desativado são perdidos para sempre.
- Nunca recarregue mais de 2 nós em uma configuração 4 + 2 em produção!
- Como não perder dados se você realmente deseja reiniciar mais de 3 nós? P Pare a gravação no ponto de montagem e / ou interrompa o volume.
- Nós ou tijolos devem ser substituídos o mais rápido possível. Para isso, é altamente desejável ter, por exemplo, 1-2 a la tijolos hot-spare em cada nó para substituição rápida. E mais um nó sobressalente com tijolos em caso de despejo de nó.
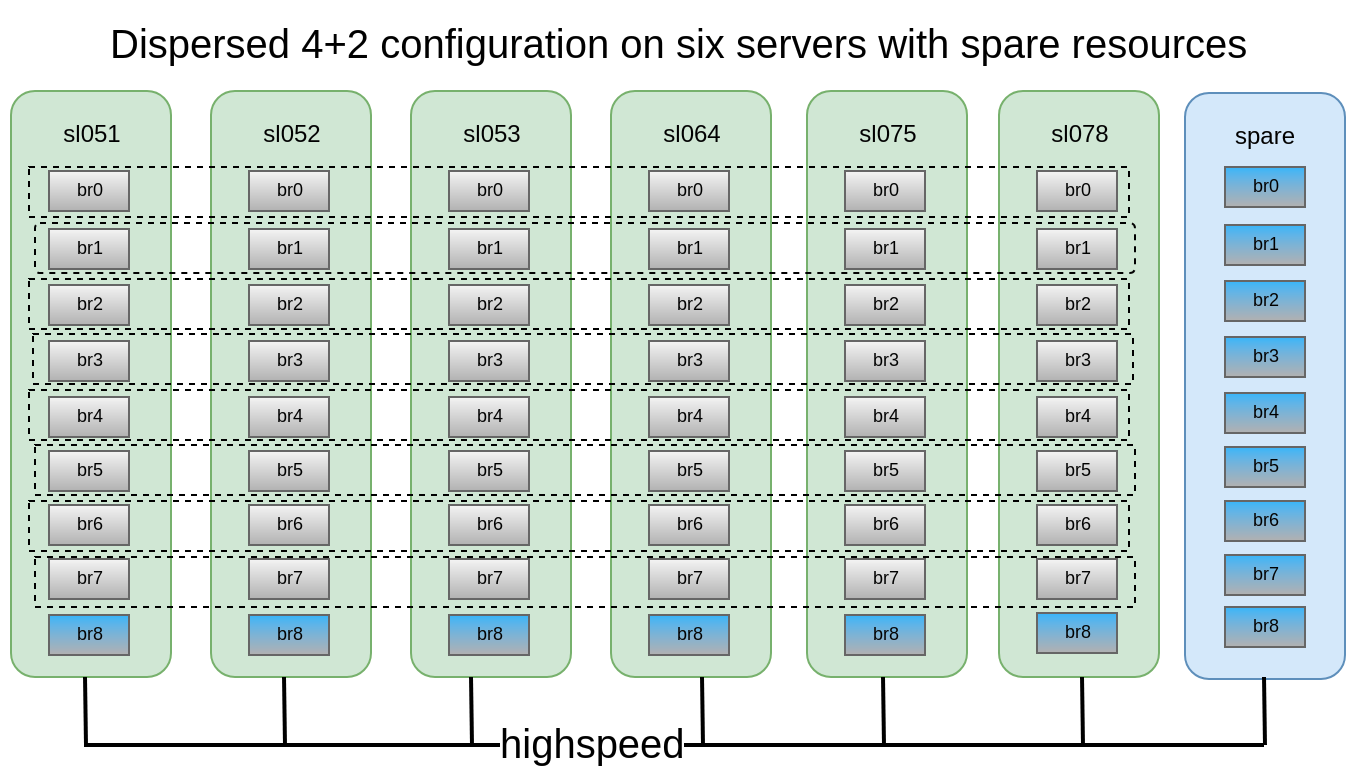
Também é muito importante testar casos de substituição de unidades
Partidas de briks (discos):
17:20Nocauteamos um tijolo:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Você pode ver esse rebaixamento no momento da substituição do bloco (registro de 1 fonte):

O processo de substituição é bastante longo, com um pequeno nível de gravação por cluster e configurações padrão de 1 TB, leva cerca de um dia para se recuperar.
Parâmetros ajustáveis para tratamento: gluster volume set cluster.background-self-heal-count 20
Opção: disperse.background-heals
Valor padrão: 8
Descrição: Esta opção pode ser usada para controlar o número de curas paralelas
Opção: disperse.heal-wait-qlength
Valor padrão: 128
Descrição: esta opção pode ser usada para controlar o número de curas que podem esperar
Opção: disperse.shd-max-threads
Valor padrão: 1
Descrição: número máximo de curas paralelas que o SHD pode realizar por tijolo local. Isso pode reduzir substancialmente os tempos de reparo, mas também pode danificar seus tijolos se você não tiver o hardware de armazenamento para suportar isso.
Opção: disperse.shd-wait-qlength
Valor padrão: 1024
Descrição: esta opção pode ser usada para controlar o número de curas que podem esperar em SHD por subvolume
Opção: disperse.cpu-extensions
Valor padrão: auto
Descrição: força as extensões da CPU a serem usadas para acelerar os cálculos do campo de Galois.
Opção: disperse.self-heal-window-size
Valor padrão: 1
Descrição: número máximo de blocos (128 KB) por arquivo para o qual o processo de recuperação automática seria aplicado simultaneamente.Parou:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
Com novos parâmetros, 1 TB de dados foi concluído em 8 horas (3 vezes mais rápido!)
O momento desagradável é que o resultado é um brik maior do que erafoi: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
tornou-se: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
É necessário entender. Provavelmente a coisa está inflando discos finos. Com a substituição subsequente do tijolo aumentado, o tamanho permaneceu o mesmo.
Rebalanceamento:Depois de expandir ou reduzir (sem migrar dados) um volume (usando os comandos add-brick e remove-brick respectivamente), é necessário reequilibrar os dados entre os servidores. Em um volume não replicado, todos os tijolos devem estar ativos para executar a operação de substituição de tijolos (opção de início). Em um volume replicado, pelo menos um dos tijolos na réplica deve estar ativo.Modelando o reequilíbrio:Opção: cluster.rebal-throttle
Valor padrão: normal
Descrição: define o número máximo de migrações de arquivos paralelos permitidos em um nó durante a operação de reequilíbrio. O valor padrão é normal e permite um máximo de [($ (unidades de processamento) - 4) / 2), 2] arquivos para b
nós migramos de cada vez. O Lazy permitirá que apenas um arquivo seja migrado por vez e o agressivo permitirá no máximo [[$ (unidades de processamento) - 4) / 2), 4]Opção: cluster.lock-migration
Valor padrão: desativado
Descrição: se ativado, esse recurso migrará os bloqueios posix associados a um arquivo durante o reequilíbrioOpção: cluster.weighted-rebalance
Valor padrão: ativado
Descrição: quando ativado, os arquivos serão alocados aos tijolos com uma probabilidade proporcional ao seu tamanho. Caso contrário, todos os tijolos terão a mesma probabilidade (comportamento herdado).Comparação da escrita e da leitura dos mesmos parâmetros do fio (resultados mais detalhados dos testes de desempenho - no PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 Se for interessante, compare a velocidade do rsync com o tráfego com os nós do Glaster:
Se for interessante, compare a velocidade do rsync com o tráfego com os nós do Glaster: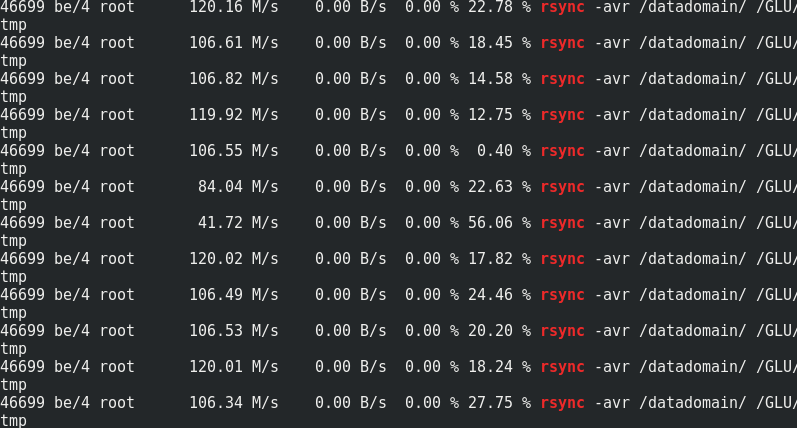
 Pode-se observar que aproximadamente 170 MB / s / tráfego a 110 MB / s / carga útil. Acontece que isso representa 33% do tráfego adicional, além de 1/3 da redundância de Erasure Coding.O consumo de memória no servidor com e sem carga não muda:
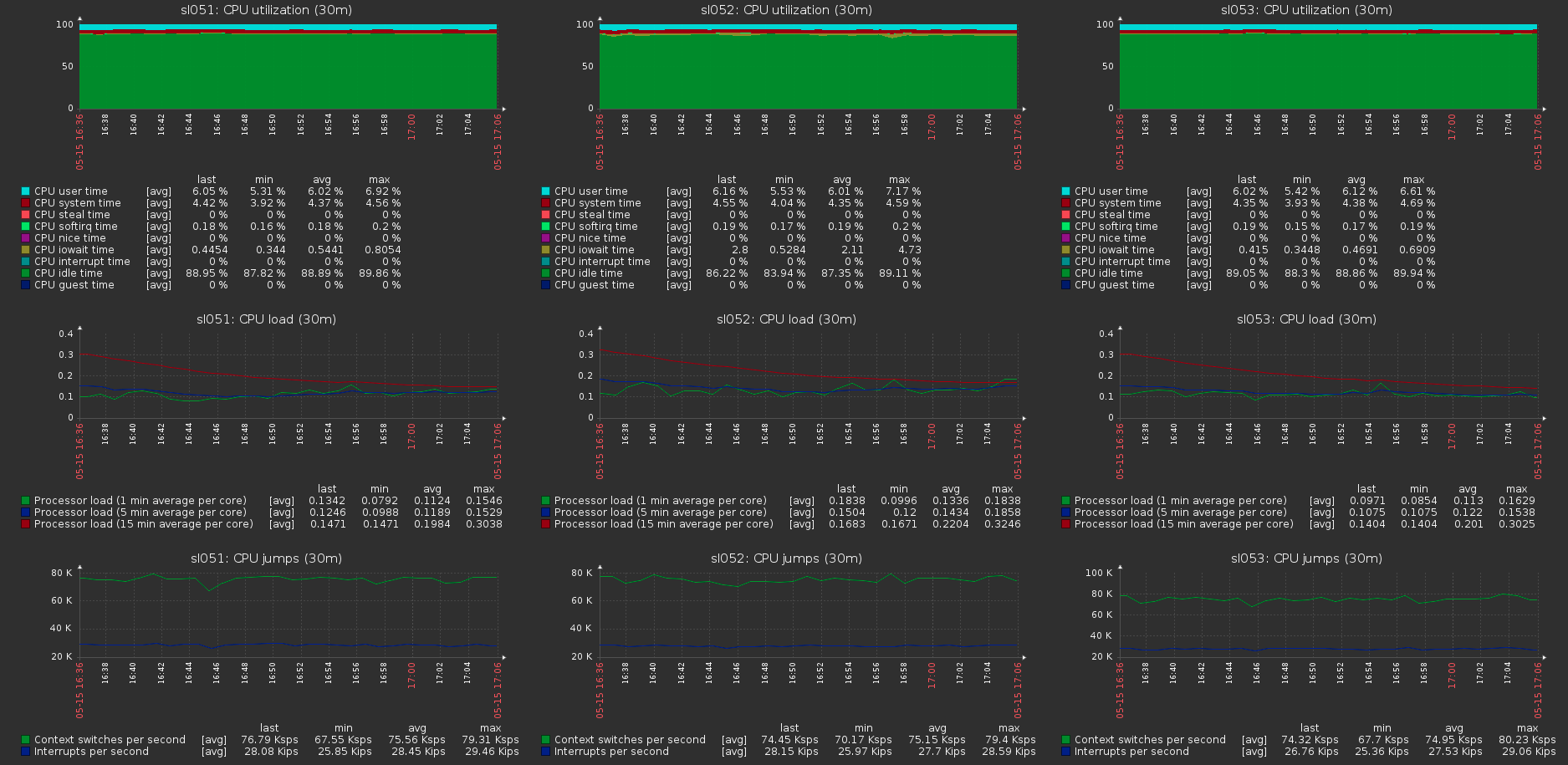
Pode-se observar que aproximadamente 170 MB / s / tráfego a 110 MB / s / carga útil. Acontece que isso representa 33% do tráfego adicional, além de 1/3 da redundância de Erasure Coding.O consumo de memória no servidor com e sem carga não muda: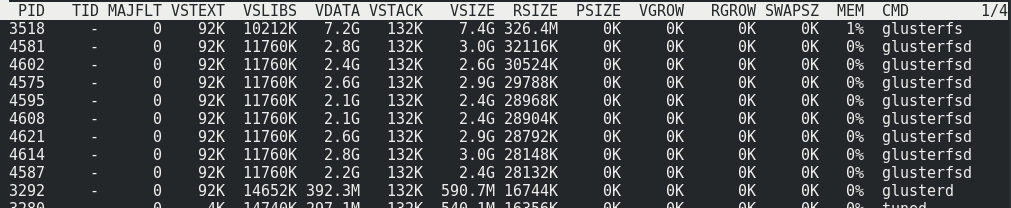 A carga no cluster hospeda com a carga máxima no volume:
A carga no cluster hospeda com a carga máxima no volume: