Olá pessoal! Meu nome é Misha Kamenshchikov, estou envolvido em ciência de dados e no desenvolvimento de microsserviços na equipe de recomendações da Avito. Neste artigo, falarei sobre nossas recomendações para anúncios semelhantes e como podemos melhorá-los com bandidos com várias armas. Fiz uma apresentação sobre esse tópico na conferência Highload ++ Siberia e no evento "Data & Science: Marketing" .

Resumo do artigo
Recomendações sobre Avito
Primeiro, uma breve visão geral de todos os tipos de recomendações que estão no Avito.
Recomendações personalizadas de itens do usuário
As recomendações de itens do usuário são baseadas nas ações do usuário e são projetadas para ajudá-lo a encontrar rapidamente o produto de seu interesse ou mostrar algo potencialmente interessante. Eles podem ser vistos na página principal do site e aplicativos ou em listas de discussão. Para criar essas recomendações, usamos dois tipos de modelos: offline e online.
Os modelos offline são baseados em algoritmos de fatoração de matriz que são treinados em todos os dados em alguns dias e as recomendações são armazenadas em um repositório rápido para distribuição aos usuários. Os modelos on-line consideram recomendações dinamicamente usando o conteúdo de anúncios do histórico do usuário. A vantagem dos modelos offline é que eles fornecem recomendações mais precisas e de alta qualidade, mas não levam em consideração as ações mais recentes do usuário que poderiam ocorrer durante o treinamento do modelo, quando a amostra de treinamento foi corrigida. Os modelos online respondem imediatamente às ações do usuário, e as recomendações podem mudar a cada ação.
Recomendações de partida a frio
Todos os sistemas de recomendação têm o chamado problema de "partida a frio". Seu significado é que os modelos descritos acima não podem dar recomendações a um novo usuário sem um histórico de ações. Nesses casos, é melhor familiarizar o usuário com o que está no site, escolhendo não apenas anúncios aleatórios, mas, por exemplo, anúncios de categorias populares na região do usuário.
Recomendações de pesquisa
Para usuários que costumam usar a pesquisa, criamos atalhos recomendados para a pesquisa - eles enviam o usuário para uma categoria específica e definem filtros. Essas recomendações podem ser encontradas na parte superior da página principal do aplicativo.
Recomendações Item-Item
As recomendações de item a item são apresentadas no site na forma de anúncios semelhantes no cartão do produto. Eles podem ser vistos em todas as plataformas na descrição do anúncio. No momento, o modelo de recomendação é exclusivamente conteúdo e não usa informações sobre ações do usuário, para que possamos escolher imediatamente similares entre anúncios ativos no site para um novo anúncio. Mais adiante neste artigo, falarei sobre esse tipo específico de recomendação.
Mais detalhadamente sobre todos os tipos de recomendações sobre o Avito que já escrevemos em nosso blog. Leia se você estiver interessado.
Anúncios semelhantes
Veja como é um bloco com anúncios semelhantes:

Esse tipo de recomendação apareceu primeiro no site e a lógica foi implementada no mecanismo de pesquisa do Sphinx . De fato, este modelo é uma combinação linear de vários fatores: correspondência de palavras, distância, diferença de preço e outros parâmetros.
Com base nos parâmetros do anúncio de destino, uma solicitação é gerada no Sphinx e os corretores internos são usados para classificação.
Exemplo de solicitação:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
Se você tentar descrever essa abordagem de maneira mais formal, poderá imaginar os corretores na forma de alguns pesos e parâmetros de anúncio (origem é o anúncio original) e (anúncio segmentado). Para cada um dos parâmetros, introduzimos a função de similaridade . Eles podem ser binários (por exemplo, a coincidência da cidade do anúncio), podem ser discretos (a distância entre os anúncios) e contínuos (por exemplo, a diferença relativa de preço). Então, para dois anúncios, a pontuação final será expressa pela fórmula
Usando o mecanismo de pesquisa, você pode ler rapidamente o valor dessa fórmula para um número suficientemente grande de anúncios e classificar a entrega em tempo real.
Essa abordagem mostrou-se muito bem em sua forma original, mas teve desvantagens significativas.
Problemas de abordagem
Em primeiro lugar, os pesos foram selecionados inicialmente de maneira especializada e não estavam em dúvida. Às vezes, houve alterações nos pesos, mas foram feitas com base em um feedback pontual, e não com base em uma análise do comportamento do usuário em geral.
Em segundo lugar, os pesos foram codificados no site, e fazer alterações neles foi muito inconveniente.
Passo em direção à automação
O primeiro passo para melhorar o modelo de recomendação foi a remoção de toda a lógica em um microsserviço separado no Python. Esse serviço já pertencia inteiramente à nossa equipe de recomendações e poderíamos realizar experimentos com bastante frequência.
Cada experimento pode ser caracterizado pela chamada "configuração" - um conjunto de pesos para os corretores. Queremos gerar configurações e escolher a melhor com base nas ações do usuário. Como essas configurações podem ser geradas?
A primeira opção, que foi desde o início, é a geração especializada de configurações. Ou seja, usando o conhecimento da área de assunto, assumimos que, por exemplo, ao procurar um carro, as pessoas estão interessadas em opções próximas ao preço que estão visualizando, e não apenas em modelos semelhantes, que podem custar significativamente mais.
A segunda opção é configurações aleatórias. Definimos algum tipo de distribuição para cada um dos parâmetros e, em seguida, apenas coletamos uma amostra dessa distribuição. Este método é mais rápido porque você não precisa pensar em cada um dos parâmetros para todas as categorias.
Uma opção mais complicada é usar algoritmos genéticos. Sabemos qual das configurações nos dá o melhor efeito em termos de ações do usuário; portanto, a cada iteração, podemos deixá-las e adicionar novas: aleatórias ou especializadas.
Uma opção ainda mais complexa, que requer um longo histórico de experimentos, é o uso de aprendizado de máquina. Podemos representar um conjunto de parâmetros como um vetor de recurso e uma métrica de destino como uma variável de destino. Em seguida, encontraremos um conjunto de parâmetros que, de acordo com a avaliação do modelo, maximizarão nossa métrica alvo.
No nosso caso, decidimos pelas duas primeiras abordagens, bem como pelos algoritmos genéticos da forma mais simples: deixamos o melhor, removemos o pior.
Agora chegamos à parte mais interessante do artigo: podemos gerar configurações, mas como realizar experimentos para que sejam rápidos e eficientes?
Experimentação
O experimento pode ser realizado no formato do teste A / B / .... Para fazer isso, precisamos gerar N configurações, aguardar resultados estatisticamente significativos e, finalmente, selecionar a melhor configuração. Isso pode levar um longo tempo e, durante o teste, um grupo fixo de usuários pode receber recomendações de baixa qualidade - com a geração aleatória de configurações, isso é possível. Além disso, se quisermos adicionar algumas novas configurações ao experimento, teremos que reiniciar o teste novamente. Mas queremos realizar experimentos rapidamente, para poder alterar as condições do experimento. E para que os usuários não sofram de configurações deliberadamente ruins. Bandidos armados nos ajudarão com isso.
Bandidos armados
O nome do método veio dos "bandidos de um braço" - máquinas caça-níqueis em um cassino com uma alavanca para a qual você pode ganhar e ganhar. Imagine que você está em uma sala com uma dúzia dessas máquinas e tem N tentativas gratuitas para jogar em qualquer uma delas. Claro, você quer ganhar mais dinheiro, mas não sabe de antemão qual máquina dá a maior vitória. O problema dos bandidos com muitos braços reside precisamente em encontrar a máquina mais lucrativa com perdas mínimas (jogando em máquinas desfavoráveis).
Se formularmos isso em termos de nossa tarefa de recomendações, as máquinas são configurações, cada tentativa é uma opção para gerar recomendações e o ganho é uma métrica de destino, dependendo do feedback do usuário.
A vantagem dos bandidos sobre os testes A / B / ...
A principal vantagem deles é que eles permitem alterar a quantidade de tráfego, dependendo do sucesso de uma configuração específica. Isso apenas resolve o problema de as pessoas receberem más recomendações ao longo do experimento. Se eles não clicarem nas recomendações, o bandido entenderá rapidamente isso e não escolherá essa configuração. Além disso, sempre podemos adicionar uma nova configuração à experiência ou simplesmente excluir uma das atuais. Todos juntos nos dão flexibilidade para conduzir experimentos e resolver os problemas da abordagem com o teste A / B / ....

Estratégias de gangster
Existem muitas estratégias para resolver o problema dos bandidos com várias armas. A seguir, descreverei várias classes de estratégias fáceis de implementar que tentamos aplicar em nossa tarefa. Mas primeiro você precisa entender como comparar a eficácia das estratégias. Se soubermos antecipadamente qual caneta oferece o ganho máximo, a estratégia ideal será sempre puxar essa caneta. Fixamos o número de etapas e calculamos a recompensa ideal . Para a estratégia, também contaremos a recompensa. e apresentar o conceito :
Estratégias adicionais podem ser comparadas apenas com esse valor. Noto que as estratégias têm natureza de mudança
pode ser diferente, e uma estratégia pode ser melhor para um pequeno número de etapas e outra para uma grande.
Estratégias gananciosas
Como o nome sugere, as estratégias gananciosas são baseadas em um princípio simples - sempre escolha a caneta que, em média, dá a maior recompensa. As estratégias dessa classe diferem na maneira como exploramos o ambiente para determinar exatamente essa caneta. Existem, por exemplo, estratégia. Ela tem um parâmetro - , que determina a probabilidade com a qual escolhemos não a melhor caneta, mas aleatória, explorando nosso ambiente. Você também pode reduzir a probabilidade de pesquisa ao longo do tempo. Essa estratégia é chamada . Estratégias gananciosas são muito fáceis de implementar e compreensíveis, mas nem sempre eficazes.
UCB1
Essa estratégia é completamente determinística - a caneta é determinada exclusivamente a partir das informações atualmente disponíveis. Aqui está a fórmula:
arm = arg \ underset {j} max (\ overline {x_j} + \ sqrt {\ frac {2 \ ln {n}} {n_j})
Parte da fórmula com
significa o meio da j-ésima caneta e é responsável pela exploração, assim como nas estratégias gananciosas. A segunda parte da fórmula é responsável pela exploração,
É o número total de ações
- o número de ações da j-ésima caneta. Existe uma estimativa comprovada para esta estratégia em
. Você pode ler sobre isso
aqui .
Thompson Sampling
Nesta estratégia, atribuímos uma distribuição aleatória a cada caneta e, em cada etapa, amostramos um número dessa distribuição, escolhendo uma caneta de acordo com o máximo. Com base no feedback, atualizamos os parâmetros de distribuição para que as melhores canetas correspondam a uma distribuição com uma grande média e sua dispersão diminua com o número de ações. Mais detalhes podem ser encontrados em grande sobre esta estratégia de papel .
Comparação de estratégia
Vamos simular as estratégias descritas acima em um ambiente artificial com três alças, cada uma das quais corresponde a uma distribuição de Bernoulli com um parâmetro em conformidade. Nossas estratégias:
- com ;
- UCB1;
- Amostragem Beta Thompson
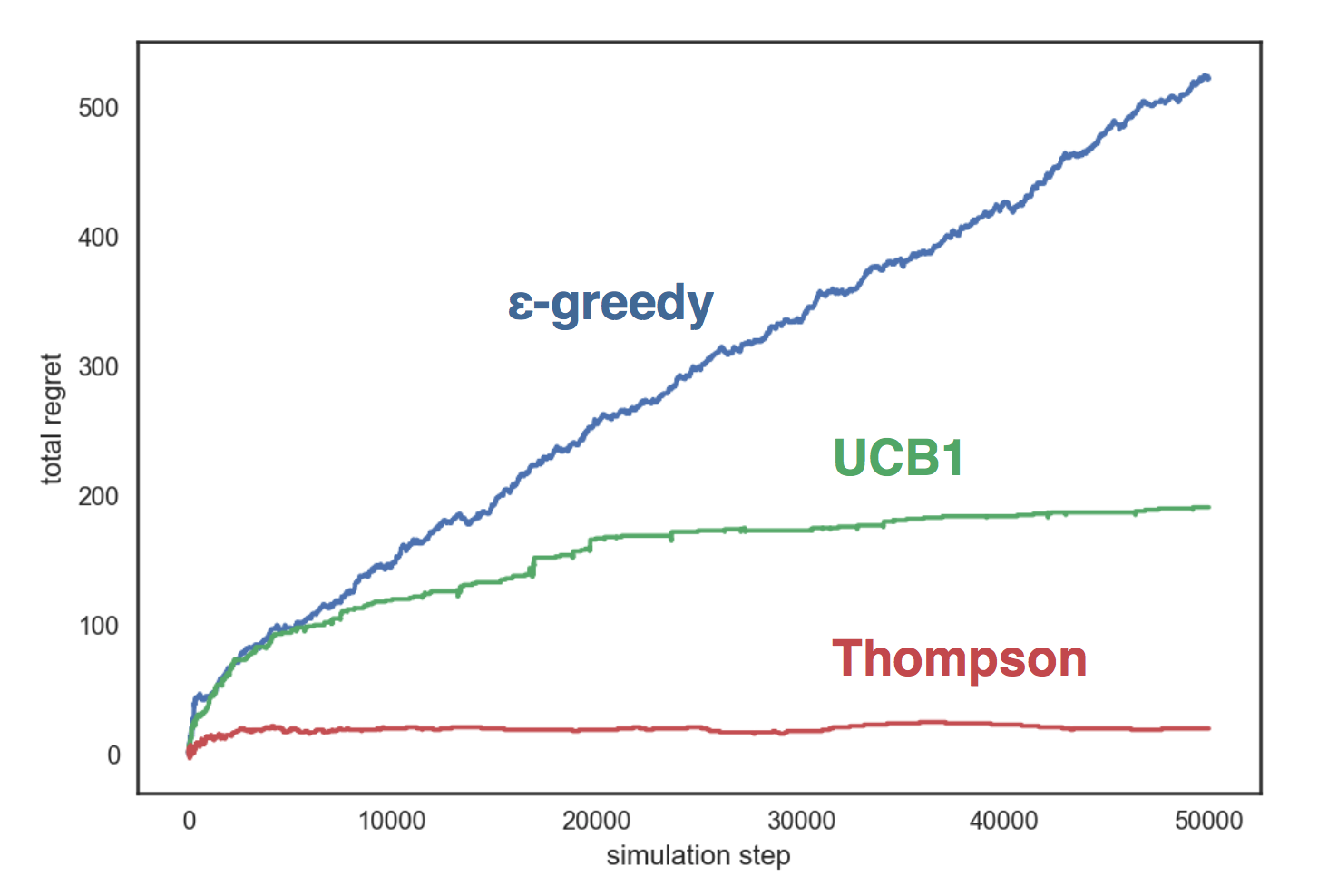
O gráfico mostra que a estratégia gananciosa cresce linearmente e nas outras duas estratégias - logaritmicamente, e a amostragem de Thompson se mostra muito melhor do que as outras quase não cresce com o número de etapas.
O código de comparação está disponível no GitHub .
Apresentei-lhe bandidos com várias armas e agora posso contar como os usamos.
Bandidos armados em Avito
Portanto, temos várias configurações (conjuntos de parâmetros) e queremos escolher a melhor delas com a ajuda de bandidos com várias armas. Para os bandidos aprenderem, precisamos de um detalhe importante - o feedback do usuário. Ao mesmo tempo, a escolha das ações nas quais somos treinados deve corresponder aos nossos objetivos - quero que os usuários façam mais transações com melhores recomendações.
Escolha ações de destino
A primeira abordagem para a seleção de ações direcionadas foi bastante simples e ingênua. Como métrica alvo, escolhemos o número de visualizações, e os bandidos aprenderam a otimizar bem essa métrica. Mas havia um problema: mais visualizações nem sempre são boas. Por exemplo, na categoria "Automático", conseguimos aumentar o número de visualizações em 15%, mas, ao mesmo tempo, o número de solicitações de contato caiu aproximadamente na mesma quantidade. Após uma análise mais detalhada, os bandidos escolheram uma caneta na qual o filtro por região foi desativado. Portanto, o bloco mostrou anúncios de toda a Rússia, onde a escolha de anúncios semelhantes, é claro, é maior. Isso causou um aumento no número de visualizações: externamente, as recomendações pareciam ser de melhor qualidade, mas quando elas entraram no cartão do produto, as pessoas perceberam que o carro estava muito longe delas e não fizeram uma solicitação de contato.
A segunda abordagem é aprender como converter a exibição de um bloco em uma solicitação de contato. Essa abordagem parecia melhor do que a anterior, apenas porque essa métrica é quase diretamente responsável pela qualidade das recomendações. Mas outro problema apareceu - sazonalidade diária. Dependendo da hora do dia, os valores de conversão podem diferir em quatro (!) Vezes (isso geralmente é mais do que o efeito de uma configuração melhor), e a caneta que teve a sorte de ser selecionada no primeiro período com uma alta conversão continuou sendo selecionada com mais frequência do que outras.
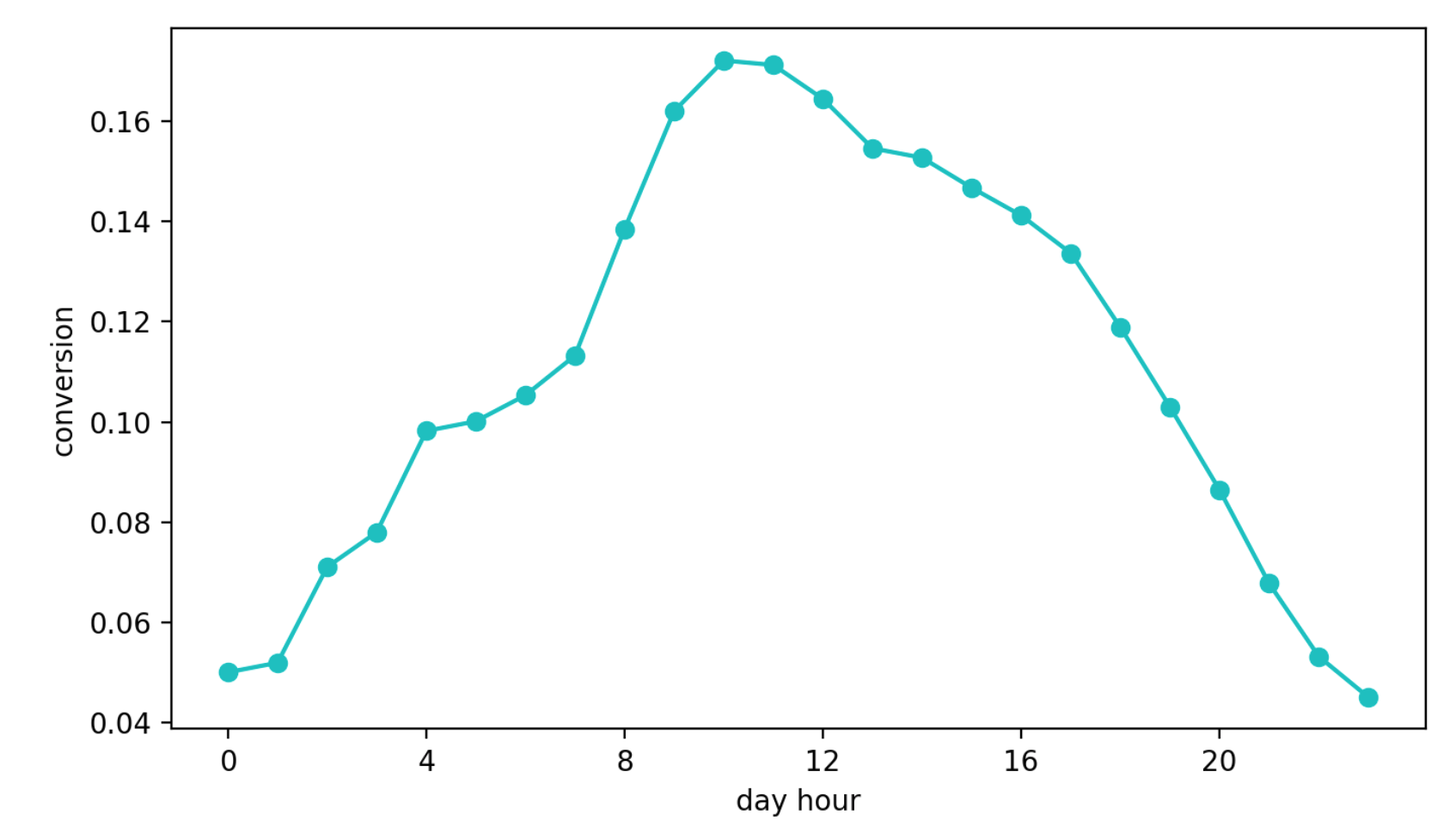
Dinâmica de conversão diária (valores do eixo Y alterados)
Finalmente, a terceira abordagem. Nós o usamos agora. Destacamos o grupo de referência, que sempre recebe recomendações sobre o mesmo algoritmo e não está sujeito à influência de bandidos. A seguir, analisamos o número absoluto de contatos em nosso grupo-alvo e referência. O relacionamento deles não está sujeito à sazonalidade, já que selecionamos o grupo de referência aleatoriamente, e essa abordagem se baseia convenientemente na amostragem de Thompson.
Nossa estratégia
Distinguimos os grupos de referência e alvo, conforme descrito acima. Em seguida, inicialize N identificadores (cada um deles corresponde a uma configuração) com distribuição beta
A cada passo:
- para cada caneta, amostramos um número da distribuição correspondente e selecionamos a caneta de acordo com o máximo;
- conte o número de ações em grupos e por um determinado quantum de tempo (no nosso caso, são 10 segundos) e atualize os parâmetros de distribuição da caneta selecionada: , .
Usando essa estratégia, otimizamos a métrica necessária, o número de solicitações de contato no grupo-alvo e evitamos os problemas que descrevi acima. Além disso, no teste A / B global, essa abordagem mostrou os melhores resultados.
Resultados
O teste A / B global foi organizado da seguinte forma: todos os anúncios são divididos aleatoriamente em dois grupos. Aos anúncios de um deles, mostramos recomendações com a ajuda de bandidos, e ao outro - com o antigo algoritmo especialista. Em seguida, medimos o número de solicitações de contato de conversão em cada um dos grupos (solicitações feitas após a mudança para anúncios do bloco semelhante). Em média, em todas as categorias, um grupo com bandidos recebe cerca de 10% mais ações direcionadas que o controle, mas em algumas categorias essa diferença pode chegar a 30%.
E a plataforma criada permite alterar rapidamente a lógica, adicionar configurações aos bandidos e validar hipóteses.
Se você tiver dúvidas sobre nosso serviço de recomendação ou bandidos com várias armas, pergunte nos comentários. Ficarei feliz em responder.