Até recentemente, em Odnoklassniki, cerca de 50 TB de dados em tempo real eram armazenados no SQL Server. Para esse volume, é quase impossível fornecer acesso rápido, confiável e até seguro ao data center usando o SQL DBMS. Geralmente, nesses casos, eles usam um dos repositórios NoSQL, mas nem tudo pode ser transferido para o NoSQL: algumas entidades exigem garantias de transações ACID.
Isso nos levou a usar o armazenamento NewSQL, ou seja, um DBMS que fornece tolerância a falhas, escalabilidade e desempenho dos sistemas NoSQL, mas ao mesmo tempo preserva as garantias ACID familiares aos sistemas clássicos. Como existem poucos sistemas industriais em funcionamento nessa nova classe, implementamos esse sistema e o colocamos em operação comercial.
Como funciona e o que aconteceu - leia abaixo do corte.
Hoje, o público mensal de Odnoklassniki é de mais de 70 milhões de visitantes únicos. Estamos
entre as cinco maiores redes sociais do mundo e os vinte sites em que os usuários passam mais tempo. A infraestrutura "OK" lida com cargas muito altas: mais de um milhão de solicitações HTTP / s nas frentes. Partes da frota de servidores de mais de 8000 estão localizadas próximas umas das outras - em quatro data centers de Moscou, o que permite uma latência de rede inferior a 1 ms entre elas.
Estamos usando o Cassandra desde 2010, começando com a versão 0.6. Hoje, várias dezenas de clusters estão em operação. O cluster mais rápido processa mais de 4 milhões de operações por segundo e as maiores armazenam 260 TB.
No entanto, todos esses são clusters NoSQL comuns usados para armazenar dados
fracamente consistentes . Mas queríamos substituir o principal armazenamento consistente, o Microsoft SQL Server, usado desde a fundação do Odnoklassniki. O armazenamento consistia em mais de 300 máquinas SQL Server Standard Edition, que continham 50 TB de entidades de negócios de dados. Esses dados são modificados como parte das transações ACID e requerem
alta consistência .
Para distribuir dados entre nós do SQL Server, usamos o
particionamento vertical e horizontal (sharding). Historicamente, usamos um esquema simples de compartilhamento de dados: cada entidade foi associada a um token - uma função do ID da entidade. As entidades com o mesmo token foram colocadas no mesmo servidor SQL. O relacionamento do tipo mestre-detalhe foi implementado para que os tokens dos registros principais e gerados sempre coincidissem e estivessem no mesmo servidor. Em uma rede social, quase todos os registros são gerados em nome de um usuário - o que significa que todos os dados do usuário em um subsistema funcional são armazenados em um servidor. Ou seja, as tabelas de um servidor SQL quase sempre participavam de uma transação comercial, o que tornava possível garantir a consistência dos dados usando transações ACID locais, sem a necessidade de transações ACID distribuídas
lentas e não confiáveis .
Graças ao sharding e para acelerar o SQL:
- Não usamos restrições de chave estrangeira, pois ao compartilhar, o ID da entidade pode estar em outro servidor.
- Não usamos procedimentos e gatilhos armazenados devido à carga adicional na CPU do DBMS.
- Não usamos JOINs devido a todas as opções acima e muitas leituras aleatórias do disco.
- Fora de uma transação, para reduzir conflitos, usamos o nível de isolamento Read Uncommitted.
- Realizamos apenas transações curtas (em média, menores que 100 ms).
- Não usamos UPDATE e DELETE com várias linhas devido ao grande número de deadlocks - atualizamos apenas um registro.
- Sempre executamos consultas apenas por índices - uma consulta com um plano para uma verificação completa da tabela para nós significa sobrecarga do banco de dados e sua falha.
Essas etapas tornaram possível extrair o desempenho quase máximo dos servidores SQL. No entanto, os problemas se tornaram cada vez mais. Vamos olhar para eles.
Problemas de SQL
- Como usamos o sharding proprietário, os administradores adicionaram manualmente novos shards. Todo esse tempo, réplicas de dados escaláveis não atendiam solicitações.
- À medida que o número de registros na tabela aumenta, a velocidade de inserção e modificação diminui. Ao adicionar índices a uma tabela existente, a velocidade cai várias vezes, a criação e recriação de índices ocorre com o tempo de inatividade.
- Ter poucos Windows para SQL Server em produção dificulta o gerenciamento de sua infraestrutura
Mas o principal problema é
Tolerância a falhas
O SQL Server clássico tem pouca tolerância a falhas. Suponha que você tenha apenas um servidor de banco de dados e ele falhe a cada três anos. No momento, o site não funciona por 20 minutos, isso é aceitável. Se você tiver 64 servidores, o site não funcionará uma vez a cada três semanas. E se você tiver 200 servidores, o site não funcionará toda semana. Isso é um problema.
O que pode ser feito para melhorar a resiliência do SQL Server? A Wikipedia nos oferece a construção de um
cluster altamente acessível : onde, em caso de falha de qualquer um dos componentes, existe um duplicado.
Isso requer uma frota de equipamentos caros: redundância múltipla, fibra, armazenamento compartilhado e a inclusão de uma reserva não funciona de maneira confiável: cerca de 10% das inclusões falham com um nó de backup do mecanismo atrás do nó principal.
Mas a principal desvantagem de um cluster tão acessível é a disponibilidade zero em caso de falha do datacenter em que ele se encontra. Odnoklassniki possui quatro centros de dados e precisamos fornecer trabalho em caso de acidente completo em um deles.
Para fazer isso, você pode usar
a replicação multimestre incorporada ao SQL Server. Essa solução é muito mais cara devido ao custo do software e sofre de problemas conhecidos com a replicação - atrasos imprevisíveis nas transações durante a replicação síncrona e atrasos na aplicação de replicações (e, como resultado, modificações perdidas) durante as assinaturas. A
resolução manual implícita
de conflitos torna essa opção completamente inaplicável para nós.
Todos esses problemas exigiram uma solução radical e procedemos a uma análise detalhada deles. Aqui, precisamos nos familiarizar com o que o SQL Server basicamente faz - as transações.
Transação simples
Considere a transação mais simples, do ponto de vista de um programador SQL aplicado,: adicionar uma foto a um álbum. Álbuns e fotos são armazenados em diferentes pratos. O álbum tem um contador de fotos público. Em seguida, essa transação é dividida nas seguintes etapas:
- Bloqueamos o álbum por chave.
- Crie uma entrada na tabela de fotos.
- Se a foto tiver um status público, encerraremos o contador de fotos públicas no álbum, atualizaremos o registro e confirmaremos a transação.
Ou na forma de pseudo-código:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
Vemos que o cenário de transação comercial mais comum é ler dados do banco de dados na memória do servidor de aplicativos, alterar alguma coisa e salvar os novos valores novamente no banco de dados. Normalmente, nessa transação, atualizamos várias entidades, várias tabelas.
Ao executar uma transação, podem ocorrer modificações competitivas dos mesmos dados de outro sistema. Por exemplo, o Antispam pode decidir que o usuário é suspeito e, portanto, todas as fotos do usuário não devem mais ser públicas, devem ser enviadas com moderação, o que significa alterar photo.status para outro valor e desaparafusar os contadores correspondentes. Obviamente, se esta operação ocorrer sem garantias de atomicidade de aplicação e isolamento de modificações concorrentes, como no
ACID , o resultado não será o necessário - o contador de fotos exibirá o valor errado ou nem todas as fotos serão enviadas com moderação.
Há muitos códigos semelhantes que manipulam várias entidades comerciais dentro da estrutura de uma transação durante toda a existência do Odnoklassniki. A partir da experiência de migrar para o NoSQL com
consistência eventual, sabemos que as maiores dificuldades (e custos de tempo) são a necessidade de desenvolver código destinado a manter a consistência dos dados. Portanto, consideramos o principal requisito para um novo repositório fornecer transações ACID lógicas reais para a lógica do aplicativo.
Outros requisitos igualmente importantes foram:
- Se o datacenter falhar, a leitura e a gravação no novo armazenamento deverão estar disponíveis.
- Mantendo a velocidade atual de desenvolvimento. Ou seja, ao trabalhar com um novo repositório, a quantidade de código deve ser aproximadamente a mesma, não há necessidade de adicionar algo ao repositório, desenvolver algoritmos para resolver conflitos, manter índices secundários etc.
- A velocidade do novo armazenamento deve ser alta o suficiente, tanto na leitura de dados quanto no processamento de transações, o que efetivamente significa a inaplicabilidade de soluções academicamente rigorosas, universais, mas lentas, como, por exemplo, confirmações de duas fases .
- Escalonamento automático em tempo real.
- Usando servidores baratos comuns, sem a necessidade de comprar peças exóticas de ferro.
- Oportunidade de desenvolver armazenamento pelos desenvolvedores da empresa. Em outras palavras, foi dada prioridade a soluções próprias ou baseadas em código aberto, preferencialmente em Java.
Decisões, Decisões
Analisando possíveis soluções, chegamos a duas opções possíveis de arquitetura:
O primeiro é pegar qualquer servidor SQL e implementar a tolerância a falhas necessária, mecanismo de dimensionamento, cluster de failover, resolução de conflitos e transações ACID distribuídas, confiáveis e rápidas. Classificamos esta opção como altamente não trivial e demorada.
A segunda opção é usar um repositório NoSQL pronto com escala implementada, um cluster de failover, resolução de conflitos e implementar transações e SQL. À primeira vista, mesmo a tarefa de implementar o SQL, para não mencionar as transações ACID, parece uma tarefa há anos. Mas então percebemos que o conjunto de recursos SQL que usamos na prática está tão longe do ANSI SQL quanto o
Cassandra CQL está longe do ANSI SQL. Examinando de perto o CQL, percebemos que ele estava próximo o suficiente do que precisávamos.
Cassandra e CQL
Então, o que é interessante sobre Cassandra, que recursos ele possui?
Em primeiro lugar, aqui você pode criar tabelas com suporte para vários tipos de dados, você pode fazer SELECT ou UPDATE na chave primária.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
Para garantir dados de réplica consistentes, Cassandra usa uma
abordagem de quorum . No caso mais simples, isso significa que, quando três réplicas da mesma linha são colocadas em nós diferentes do cluster, o registro é considerado bem-sucedido se a maioria dos nós (ou seja, dois em três) confirmar o sucesso dessa operação de gravação. Os dados de uma série são considerados consistentes se, ao ler, a maioria dos nós tiver sido interrogada e confirmada. Assim, com a presença de três réplicas, a consistência total e instantânea dos dados é garantida em caso de falha de um nó. Essa abordagem nos permitiu implementar um esquema ainda mais confiável: sempre envie solicitações para as três réplicas, aguardando uma resposta das duas mais rápidas. A resposta tardia da terceira réplica é então descartada. Um nó que está atrasado com uma resposta pode ter sérios problemas - freios, coleta de lixo na JVM, recuperação direta de memória no kernel do linux, falha de hardware, desconexão da rede. No entanto, isso não afeta as operações ou os dados do cliente.
A abordagem quando passamos para três nós e obtemos uma resposta de dois é chamada
especulação : uma solicitação de comentários extras é enviada antes mesmo de "cair".
Outra vantagem do Cassandra é o Batchlog - um mecanismo que garante a aplicação completa ou a não aplicação completa do pacote de alterações que você faz. Isso nos permite resolver A no ACID - atomicidade fora da caixa.
O mais próximo às transações com Cassandra - são os chamados "
uma Transações leves ". Mas eles estão longe de transações ACID "reais": na verdade, é uma oportunidade de gerar
CAS em dados de apenas um registro, usando consenso no protocolo pesado Paxos. Portanto, a velocidade de tais transações é baixa.
O que perdemos em Cassandra
Então, tivemos que implementar transações ACID reais no Cassandra. Usando o qual poderíamos facilmente implementar dois outros recursos convenientes do DBMS clássico: índices rápidos consistentes, que nos permitiriam realizar amostragem de dados não apenas na chave primária e no gerador usual de IDs de auto incremento monótonos.
C * one
Assim, o novo
C * One DBMS nasceu, consistindo em três tipos de nós do servidor:
- Armazenamento - os servidores Cassandra (quase) padrão responsáveis pelo armazenamento de dados em unidades locais. À medida que a carga e a quantidade de dados aumentam, seu número pode ser facilmente dimensionado para dezenas ou centenas.
- Coordenadores de transação - permite a execução da transação.
- Clientes são servidores de aplicativos que implementam operações de negócios e iniciam transações. Pode haver milhares desses clientes.
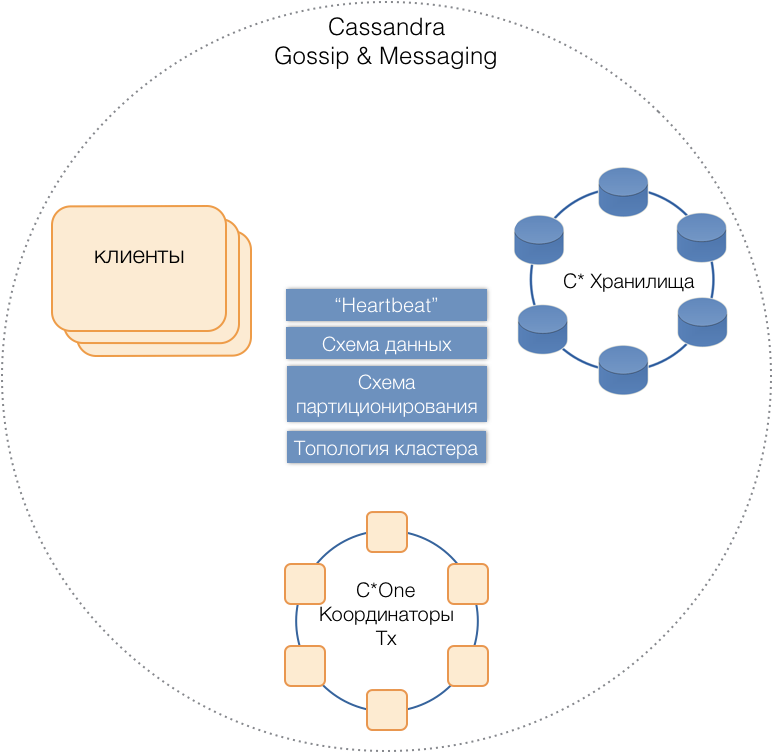
Todos os tipos de servidores estão em um cluster comum, use o protocolo de mensagens interno do Cassandra para se comunicar e
fofocar para trocar informações do cluster. Com a ajuda do Heartbeat, os servidores aprendem sobre falhas mútuas, suportam um único esquema de dados - tabelas, sua estrutura e replicação; esquema de particionamento, topologia de cluster etc.
Clientes
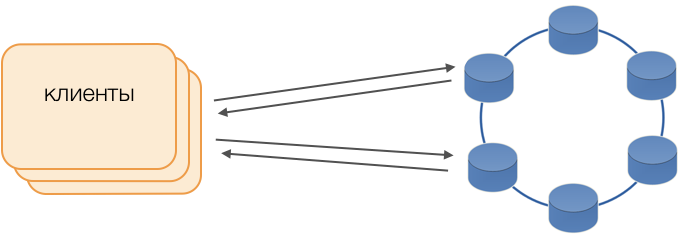
Em vez de drivers padrão, o modo Fat Client é usado. Esse nó não armazena dados, mas pode atuar como coordenador da execução da consulta, ou seja, o próprio cliente desempenha a função de coordenador de suas solicitações: pesquisa repositórios de réplicas e resolve conflitos. Isso não é apenas mais confiável e rápido do que um driver padrão que requer comunicação com um coordenador remoto, mas também permite controlar a transferência de solicitações. Fora de uma transação aberta no cliente, as solicitações são enviadas para o armazenamento. Se o cliente abriu a transação, todas as solicitações dentro da transação são enviadas ao coordenador da transação.

C * One Transaction Coordinator
O coordenador é o que implementamos para o C * One do zero. Ele é responsável por gerenciar transações, bloqueios e a ordem em que as transações são aplicadas.
Para cada transação que está sendo atendida, o coordenador gera um carimbo de data / hora: cada subsequente é maior que a transação anterior. Como o sistema de resolução de conflitos no Cassandra é baseado em registros de data e hora (de dois registros conflitantes, o atual com o último registro de data e hora é considerado relevante), o conflito sempre será resolvido em favor da transação subsequente. Assim, implementamos os
relógios Lamport - uma maneira barata de resolver conflitos em um sistema distribuído.
Fechaduras
Para garantir o isolamento, decidimos usar o método mais simples - bloqueios pessimistas na chave primária do registro. Em outras palavras, em uma transação, o registro deve primeiro ser bloqueado, só então ler, modificar e salvar. Somente após uma confirmação bem-sucedida um registro pode ser desbloqueado para que as transações concorrentes possam usá-lo.
A implementação desse bloqueio é simples em um ambiente não alocado. Há duas maneiras principais em um sistema distribuído: implementar o bloqueio distribuído no cluster ou distribuir transações para que as transações que envolvam um único registro sejam sempre atendidas pelo mesmo coordenador.
Como, no nosso caso, os dados já estão distribuídos por grupos de transações locais no SQL, foi decidido atribuir grupos de transações locais aos coordenadores: um coordenador executa todas as transações com um token de 0 a 9, o segundo com um token de 10 a 19 e assim por diante. Como resultado, cada uma das instâncias do coordenador se torna um mestre do grupo de transações.
Em seguida, os bloqueios podem ser implementados como um HashMap banal na memória do coordenador.
Falhas do coordenador
Como um coordenador atende exclusivamente a um grupo de transações, é muito importante determinar rapidamente o fato de sua falha, para que uma tentativa repetida de executar a transação seja atingida. Para torná-lo rápido e confiável, aplicamos um protocolo de quorum hearbeat totalmente conectado:
Cada data center tem pelo menos dois nós coordenadores. Periodicamente, cada coordenador envia uma mensagem de pulsação para os outros coordenadores e informa sobre seu funcionamento, bem como as mensagens de pulsação das quais coordenadores no cluster pela última vez.

Tendo recebido informações semelhantes dos outros na composição de suas mensagens de pulsação, cada coordenador decide por si mesmo quais nós do cluster funcionam e quais não são, guiados pelo princípio do quorum: se o nó X recebeu informações da maioria dos nós no cluster sobre o recebimento normal de mensagens do nó Y, Y trabalha. Por outro lado, assim que a maioria relatar a perda de mensagens do nó Y, Y falhará. É curioso que, se um quorum disser ao nó X que não recebe mais mensagens dele, o próprio nó X considerará que falhou.
As mensagens de pulsação são enviadas em alta frequência, cerca de 20 vezes por segundo, com um período de 50 ms. Em Java, é difícil garantir uma resposta do aplicativo de 50 ms devido ao comprimento comparável de pausas causadas pelo coletor de lixo. Conseguimos atingir esse tempo de resposta usando o coletor de lixo G1, o que nos permite especificar o destino para a duração das pausas do GC. No entanto, às vezes, muito raramente, a pausa do coletor ultrapassa 50 ms, o que pode levar a uma falsa detecção de falha. Para evitar isso, o coordenador não relata a falha do nó remoto quando a primeira mensagem de pulsação desaparece dele, apenas se várias desaparecerem consecutivamente.Portanto, conseguimos detectar a falha do nó do coordenador em 200 ms.
Mas não basta entender rapidamente qual nó parou de funcionar. Você precisa fazer algo sobre isso.
Reserva
O esquema clássico pressupõe, no caso de recusa de um mestre, iniciar a eleição de um novo usando um dos algoritmos
universais da
moda . No entanto, esses algoritmos têm problemas bem conhecidos com a convergência do tempo e a duração do próprio processo eleitoral. Conseguimos evitar atrasos adicionais usando o circuito equivalente de coordenadores em uma rede totalmente conectada:
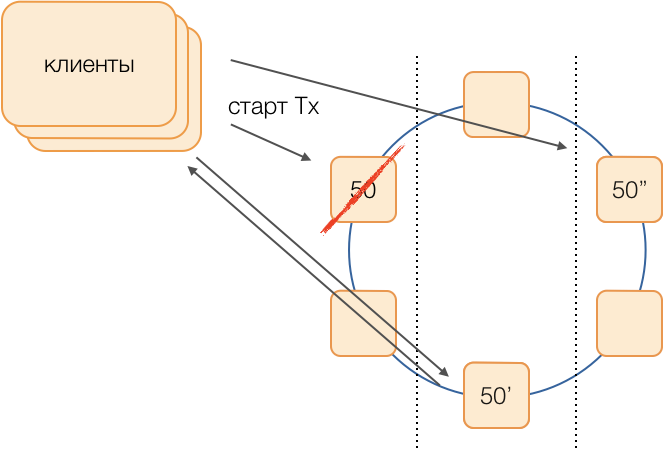
Suponha que desejemos executar uma transação no grupo 50. Determinaremos antecipadamente um esquema de substituição, ou seja, quais nós executarão as transações do grupo 50 no caso de uma falha do coordenador principal. Nosso objetivo é manter o sistema operacional em caso de falha no data center. Determinamos que a primeira reserva será um nó de outro datacenter e a segunda reserva será um nó do terceiro. Esse esquema é selecionado uma vez e não muda até que a topologia do cluster seja alterada, ou seja, até que novos nós o entrem (o que acontece muito raramente). O procedimento para escolher um novo mestre ativo em caso de falha do antigo será sempre este: a primeira reserva se tornará o mestre ativo e, se deixar de funcionar, a segunda reserva se tornará.
Esse esquema é mais confiável que o algoritmo universal, pois para ativar um novo mestre é suficiente determinar o fato de falha do antigo.
Mas como os clientes entenderão qual dos mestres está trabalhando agora? Por 50 ms, não é possível enviar informações para milhares de clientes. Uma situação é possível quando um cliente envia uma solicitação para abrir uma transação, ainda não sabendo que esse assistente não está mais funcionando, e a solicitação fica paralisada. Para impedir que isso aconteça, os clientes enviam especulativamente uma solicitação para abrir uma transação imediatamente para o mestre do grupo e suas duas reservas, mas apenas quem é o mestre ativo no momento responderá a essa solicitação. O cliente executará toda a comunicação subsequente dentro da transação apenas com o mestre ativo.
Os mestres de backup recebem solicitações de transações não próprias na fila de transações não nascidas, onde são armazenadas por algum tempo. Se o mestre ativo morre, o novo mestre processa solicitações para abrir transações da fila e responde ao cliente. Se o cliente já conseguiu abrir uma transação com o antigo mestre, a segunda resposta será ignorada (e, obviamente, essa transação não será concluída e será repetida pelo cliente).
Como uma transação funciona
Suponha que um cliente enviou a um coordenador uma solicitação para abrir uma transação para uma entidade com essa chave primária. O coordenador bloqueia essa entidade e a coloca na tabela de bloqueios na memória. Se necessário, o coordenador lê essa entidade da loja e armazena os dados recebidos em um estado de transação na memória do coordenador.
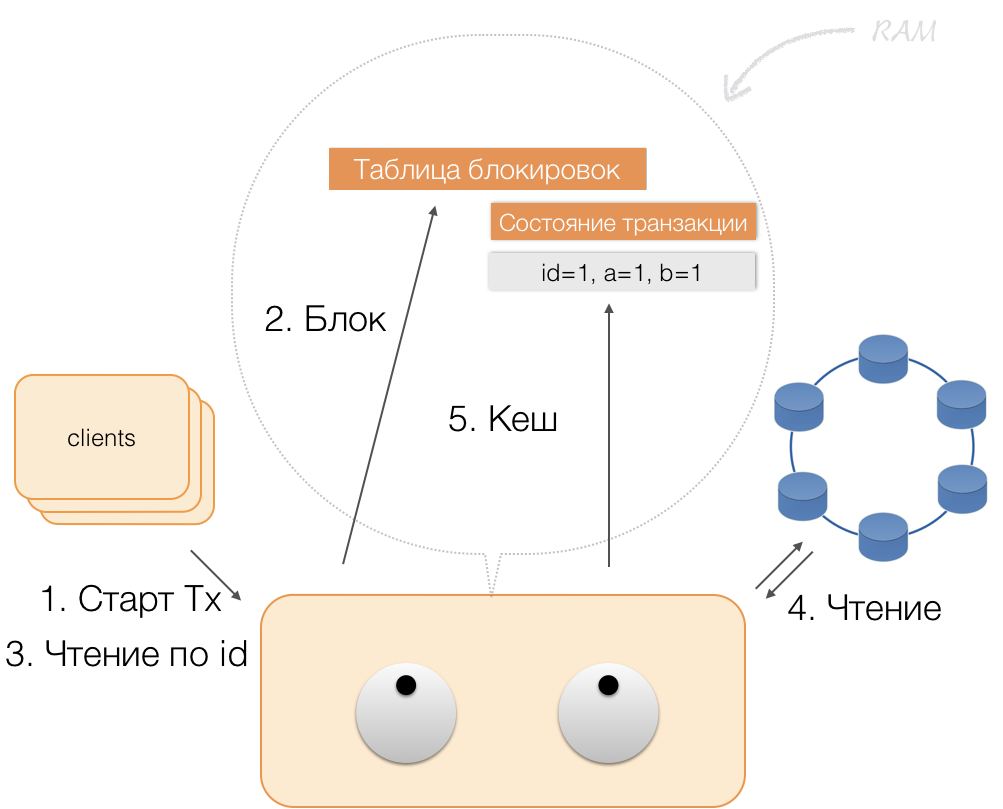
Quando o cliente deseja alterar os dados na transação, ele envia ao coordenador uma solicitação para atualizar a entidade e coloca os novos dados na tabela de status da transação na memória. Isso completa a gravação - a gravação não é realizada no repositório.
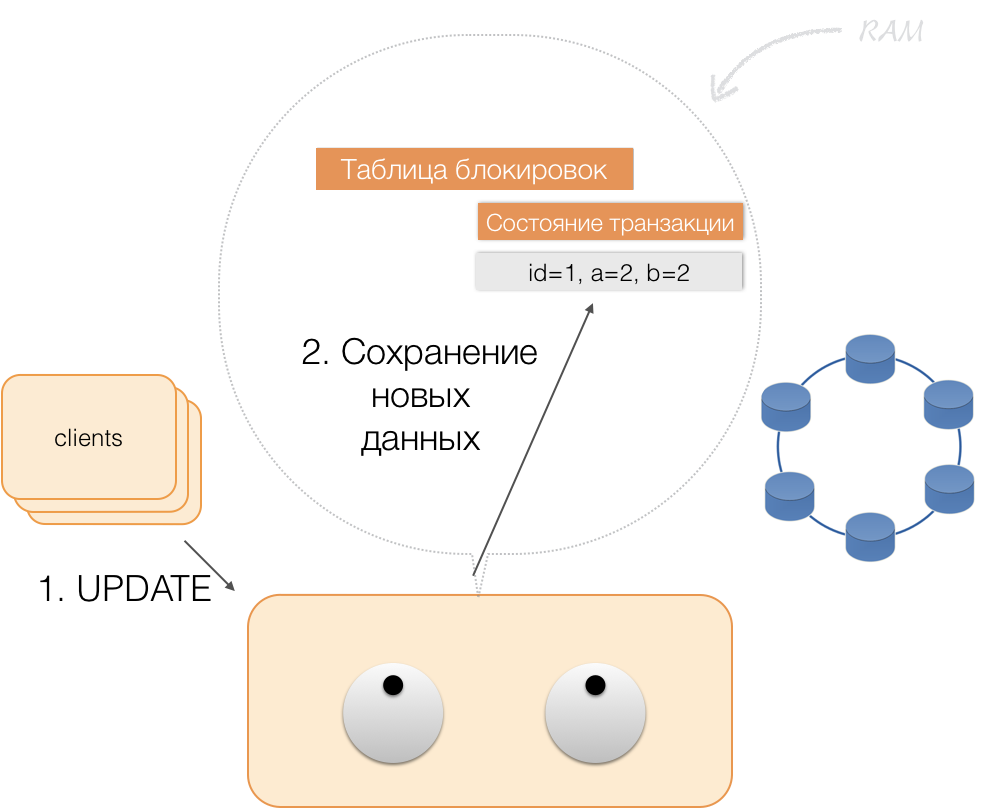
Quando um cliente solicita, dentro da estrutura de uma transação ativa, seus próprios dados alterados, o coordenador age assim:
- se o ID já estiver na transação, os dados serão retirados da memória;
- se não houver um ID na memória, os dados ausentes serão lidos nos nós de armazenamento, combinados com os que já estão na memória, e o resultado será retornado ao cliente.
Assim, o cliente pode ler suas próprias alterações, enquanto outros não as veem, porque são armazenadas apenas na memória do coordenador e ainda não estão nos nós do Cassandra.
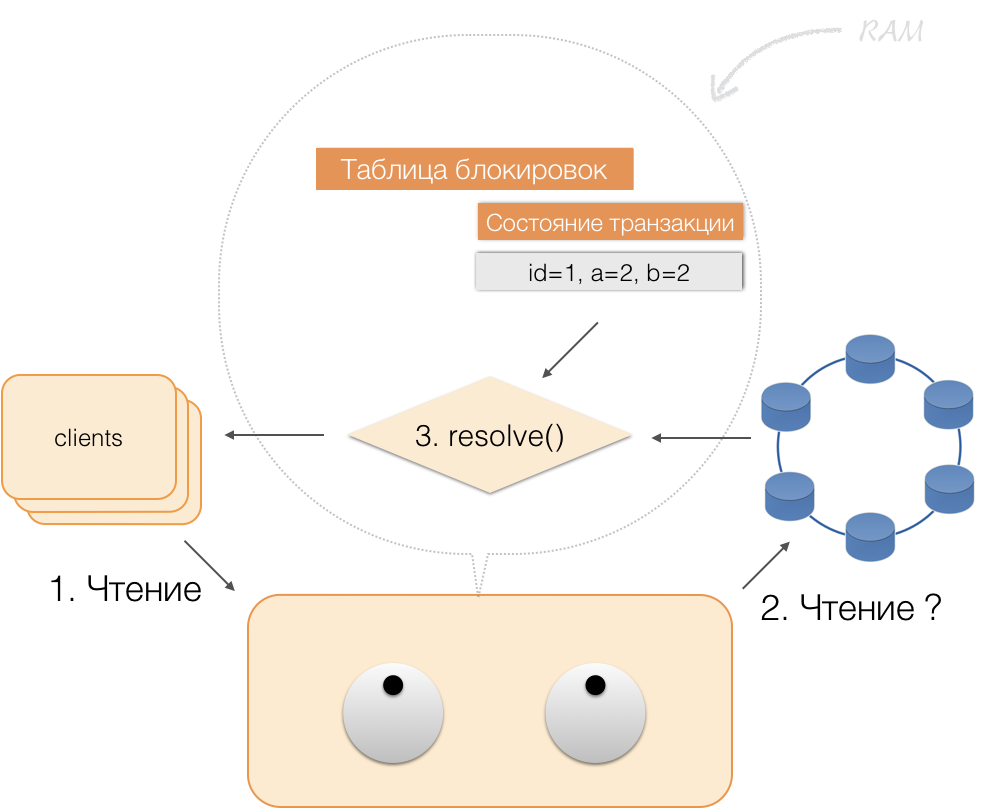
Quando o cliente envia uma confirmação, o estado na memória do serviço é salvo pelo coordenador no lote registrado e, já na forma de um lote registrado, é enviado aos repositórios do Cassandra. Os repositórios fazem todo o necessário para que este pacote seja aplicado atomicamente (totalmente) e retornam uma resposta ao coordenador, que libera os bloqueios e confirma o sucesso da transação para o cliente.

E para reverter para o coordenador, basta liberar a memória ocupada pelo estado da transação.
Como resultado das melhorias acima, implementamos os princípios do ACID:
- Atomicidade . É uma garantia de que nenhuma transação será parcialmente comprometida com o sistema, todas as suas suboperações serão concluídas ou nenhuma delas será executada. Cumprimos esse princípio devido ao lote registrado no Cassandra.
- Coerência . Cada transação bem-sucedida, por definição, captura apenas resultados aceitáveis. Se, após abrir uma transação e executar parte das operações, for constatado que o resultado não é válido, uma reversão será realizada.
- Isolamento . Quando uma transação é executada, transações paralelas não devem afetar seu resultado. As transações concorrentes são isoladas usando bloqueios pessimistas no coordenador. Para leituras fora da transação, o princípio de isolamento no nível Read Committed é respeitado.
- Sustentabilidade . Independentemente dos problemas nos níveis mais baixos (desenergização do sistema, falha de hardware), as alterações feitas por uma transação concluída com êxito devem permanecer salvas após a retomada da operação.
Leitura de índice
Tome uma tabela simples:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
Ela tem um ID (chave primária), proprietário e data da mudança. Você precisa fazer uma solicitação muito simples: selecione os dados do proprietário com a data da alteração "para o último dia".
SELECT * WHERE owner=? AND modified>?
Para que essa consulta funcione rapidamente, no DBMS clássico do SQL, você precisa criar um índice por colunas (proprietário, modificado). Podemos fazer isso de maneira simples, já que agora temos garantias ACID!
Índices em C * One
Há uma tabela de origem com fotos, na qual o ID do registro é a chave primária.

Para o índice C *, o One cria uma nova tabela, que é uma cópia do original. A chave corresponde à expressão do índice e também inclui a chave primária do registro da tabela de origem:
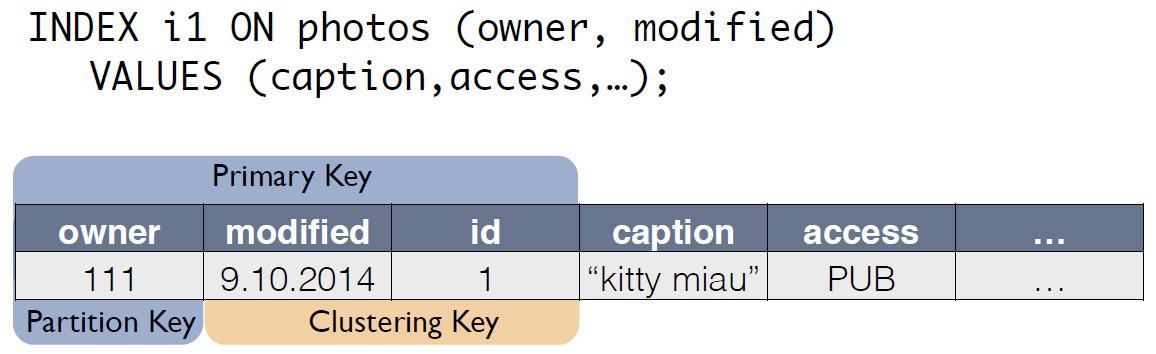
Agora, a solicitação do "proprietário do último dia" pode ser reescrita como seleção de outra tabela:
SELECT * FROM i1_test WHERE owner=? AND modified>?
A consistência dos dados da tabela de fotos original e o índice i1 é mantida automaticamente pelo coordenador. Com base apenas no esquema de dados, quando a alteração é recebida, o coordenador gera e se lembra da alteração não apenas na tabela principal, mas também nas alterações de cópia. Nenhuma ação adicional é executada com a tabela de índice, os logs não são lidos, os bloqueios não são usados. Ou seja, adicionar índices quase não consome recursos e praticamente não afeta a velocidade da aplicação de modificações.
Usando o ACID, conseguimos implementar índices "como no SQL". Eles têm consistência, podem ser dimensionados, funcionam rapidamente, podem ser compostos e incorporados à linguagem de consulta CQL.
Para oferecer suporte a índices, você não precisa fazer alterações no código do aplicativo. Tudo é simples, como no SQL. E o mais importante, os índices não afetam a velocidade de execução das modificações na tabela de transações original.O que aconteceu
Desenvolvemos o C * One há três anos e o colocamos em operação comercial.O que conseguimos no final? Vamos avaliar isso usando o exemplo de um subsistema para processar e armazenar fotos, um dos tipos mais importantes de dados em uma rede social. Não se trata dos corpos das próprias fotos, mas de todos os tipos de meta-informações. Agora, em Odnoklassniki, existem cerca de 20 bilhões de registros, o sistema processa 80 mil solicitações de leitura por segundo, até 8 mil transações ACID por segundo associadas à modificação de dados.Quando usamos o SQL com fator de replicação = 1 (mas no RAID 10), as meta-informações da foto foram armazenadas em um cluster altamente acessível de 32 máquinas com o Microsoft SQL Server (mais 11 backup). Também alocou 10 servidores para armazenar backups. Um total de 50 carros caros. Ao mesmo tempo, o sistema trabalhava com carga nominal, sem reserva.Após a migração para o novo sistema, obtivemos o fator de replicação = 3 - uma cópia em cada data center. O sistema consiste em 63 nós de armazenamento Cassandra e 6 máquinas coordenadoras, totalizando 69 servidores. Mas essas máquinas são muito mais baratas, seu custo total é de cerca de 30% do custo do sistema em SQL. Nesse caso, a carga é mantida em 30%.Com a introdução do C * One, os atrasos também diminuíram: no SQL, a operação de gravação levou cerca de 4,5 ms. Em C * One - cerca de 1,6 ms. A duração da transação é em média inferior a 40 ms, a confirmação é realizada em 2 ms, a duração de leitura e gravação é em média 2 ms. O 99º percentil - apenas 3-3,1 ms, o número de tempos limite diminuiu 100 vezes - tudo devido ao uso generalizado da especulação.Até o momento, a maioria dos nós do SQL Server foi desativada; novos produtos são desenvolvidos apenas usando o C * One. Adaptamos o C * One para trabalhar em uma nuvem única , o que nos permitiu acelerar a implantação de novos clusters, simplificar a configuração e automatizar a operação. Sem o código fonte, seria muito mais difícil e complicado.Agora, estamos trabalhando para transferir nossas outras instalações de armazenamento para a nuvem - mas essa é uma história completamente diferente.