Quais requisitos o armazenamento de metadados para um serviço em nuvem atende? Sim, não o mais comum, mas para empresas com suporte para data centers geograficamente distribuídos e Active-Active. Obviamente, o sistema deve ter uma boa escala,
tolerância a falhas e gostaria de poder implementar consistência personalizável das operações.Somente Cassandra é adequado para todos esses requisitos e nada mais é adequado. Note-se que Cassandra é muito legal, mas trabalhar com ele se parece com uma montanha-russa.
Em um relatório do Highload ++ 2017,
Andrei Smirnov (
smira ) decidiu que não era interessante falar sobre o bem, mas falou detalhadamente sobre todos os problemas que tinha que enfrentar: sobre perda e corrupção de dados, sobre zumbis e perda de desempenho. Essas histórias são realmente uma reminiscência de montanha-russa, mas para todos os problemas há uma solução, para a qual você é bem-vindo ao gato.
Sobre o palestrante: Andrey Smirnov trabalha para a Virtustream, uma empresa que implementa armazenamento em nuvem para empresas. A ideia é que a Amazon condicionalmente faça a nuvem para todos, e a Virtustream faça as coisas específicas que uma grande empresa precisa.
Algumas palavras sobre Virtustream
Trabalhamos em uma equipe pequena completamente remota e estamos envolvidos em uma das soluções em nuvem da Virtustream. Esta é uma nuvem de armazenamento de dados.

Falando de maneira muito simples, essa é uma API compatível com S3 na qual você pode armazenar objetos. Para quem não sabe o que é o S3, é apenas uma API HTTP com a qual você pode enviar objetos para a nuvem em algum lugar, recuperá-los, excluí-los, obter uma lista de objetos etc. Além disso - recursos mais complexos com base nessas operações simples.
Temos alguns recursos distintos que a Amazon não possui. Uma delas são as chamadas georregiões. Na situação usual, quando você cria um repositório e diz que armazenará objetos na nuvem, você deve selecionar uma região. Uma região é essencialmente um data center e seus objetos nunca sairão desse data center. Se algo acontecer com ele, seus objetos não estarão mais disponíveis.
Oferecemos regiões geográficas nas quais os dados estão localizados simultaneamente em vários data centers (DC), pelo menos em dois, como na figura. O cliente pode entrar em contato com qualquer data center, para ele é transparente. Os dados entre eles são replicados, ou seja, trabalhamos no modo ativo-ativo e constantemente. Isso fornece ao cliente recursos adicionais, incluindo:
- maior confiabilidade de armazenamento, leitura e gravação em caso de falha de DC ou perda de conectividade;
- disponibilidade de dados, mesmo se um dos controladores de domínio falhar;
- redirecionando as operações para o CD “mais próximo”.
Essa é uma oportunidade interessante - mesmo que esses CDs estejam geograficamente distantes, alguns deles podem estar mais próximos do cliente em diferentes momentos. E acessar os dados no CD mais próximo é simplesmente mais rápido.
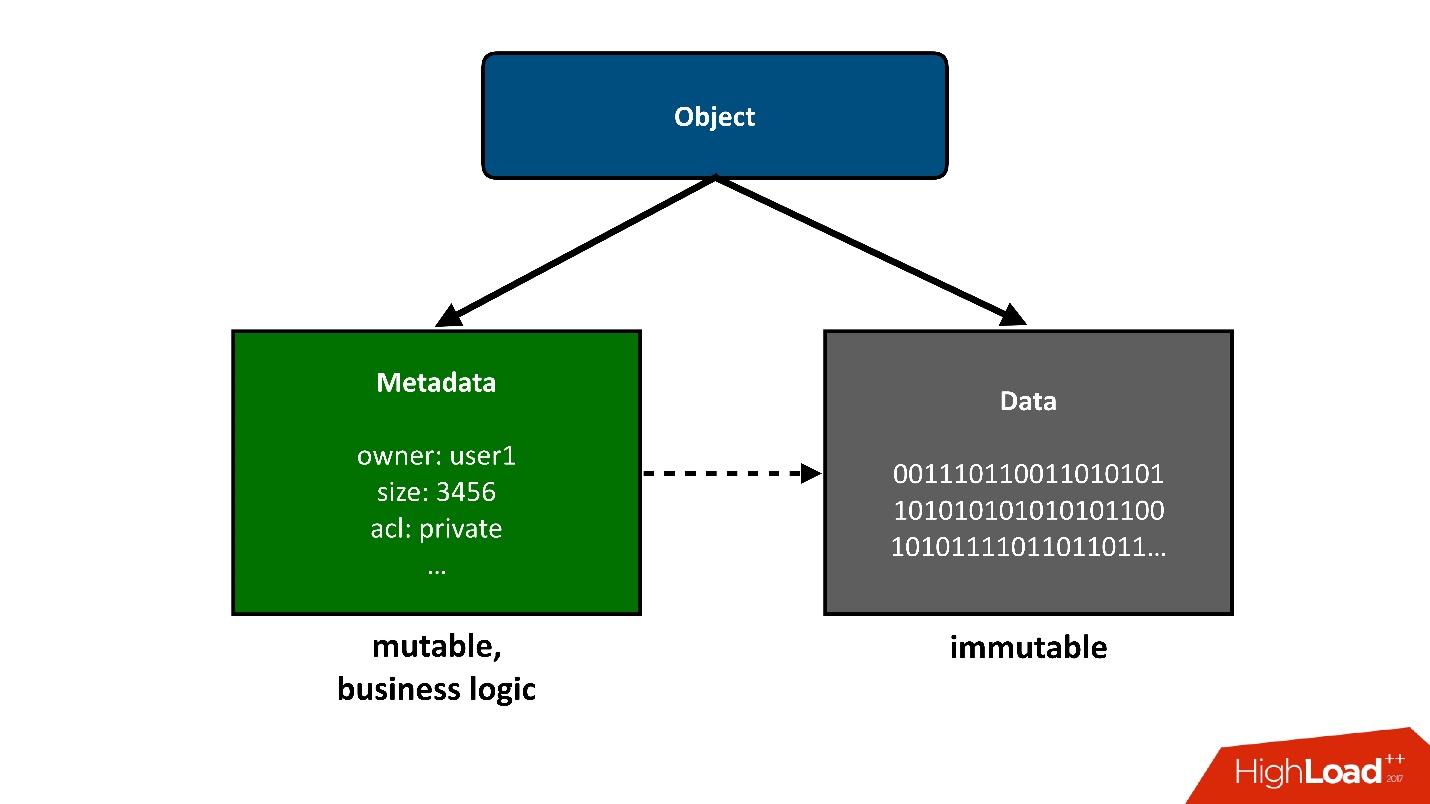
Para dividir a construção sobre a qual falaremos em partes, apresentarei os objetos armazenados na nuvem em duas partes grandes:
1. A primeira parte simples de um objeto são
dados . Eles permanecem inalterados, foram baixados uma vez e é tudo. A única coisa que pode acontecer com eles mais tarde é que podemos removê-los se não forem mais necessários.
Nosso projeto anterior estava relacionado ao armazenamento de exabytes de dados, portanto, não tivemos problemas com o armazenamento de dados. Essa já era uma tarefa resolvida para nós.
2.
Metadados . Toda a lógica de negócios, mais interessante, relacionada à concorrência: acesso, registros, reescritas - na área de metadados.
Os metadados sobre o objeto levam em si a maior complexidade do projeto, os metadados armazenam um ponteiro para o bloco de dados armazenados do objeto.
Do ponto de vista do usuário, esse é um objeto único, mas podemos dividi-lo em duas partes. Hoje vou falar
apenas sobre metadados .
Figuras
- Dados : 4 bytes.
- Clusters de metadados : 3.
- Objetos : 40 bilhões.
- Tamanho dos metadados : 160 TB (incluindo replicação).
- Taxa de variação (metadados): 3000 objetos / s.
Se você observar esses indicadores com atenção, a primeira coisa que chama sua atenção é o tamanho médio muito pequeno do objeto armazenado. Temos muitos metadados por unidade de volume de dados mestre. Para nós, não foi menos uma surpresa do que talvez para você agora.
Planejamos que teríamos pelo menos uma ordem de dados, se não 2, além de metadados. Ou seja, cada objeto será significativamente maior e a quantidade de metadados será menor. Como os dados são mais baratos de armazenar, menos operações com eles e os metadados são muito mais caros, tanto no sentido de hardware quanto no sentido de atender e executar várias operações neles.
Além disso, esses dados mudam a uma velocidade bastante alta. Dei aqui o valor máximo, o valor não máximo não é muito menor, mas, no entanto, uma carga bastante grande pode ser obtida em pontos específicos no tempo.
Esses números já foram obtidos de um sistema operacional, mas vamos voltar um pouco ao tempo de projetar o armazenamento em nuvem.
Escolhendo um repositório para metadados
Quando enfrentamos o desafio de que queremos ter regiões geográficas, ativo-ativo e precisamos armazenar metadados em algum lugar, pensamos que poderia ser?
Obviamente, o repositório (banco de dados) deve ter as seguintes propriedades:
- Suporte ativo-ativo ;
- Escalabilidade.
Gostaríamos realmente que nosso produto fosse extremamente popular e não sabemos como ele crescerá ao mesmo tempo, para que o sistema seja dimensionado.
- O equilíbrio entre tolerância a falhas e confiabilidade de armazenamento.
Os metadados devem ser armazenados com segurança, porque se os perdermos e houver um link para os dados neles, perderemos o objeto inteiro.
- Consistência personalizável de operações.
Devido ao fato de trabalharmos em vários CDs e permitir a possibilidade de que os CDs não estejam disponíveis, além disso, os CDs estão longe um do outro, não podemos, durante a maioria das operações da API, exigir que essa operação seja executada simultaneamente em dois CDs. Será muito lento e impossível se o segundo CD não estiver disponível. Portanto, parte das operações deve funcionar localmente em um controlador de domínio.
Mas, obviamente, algum tipo de convergência deve ocorrer em algum momento e, depois de resolver todos os conflitos, os dados devem estar visíveis nos dois data centers. Portanto, a consistência das operações deve ser ajustada.
Do meu ponto de vista, Cassandra é adequado para esses requisitos.
Cassandra
Eu ficaria muito feliz se não tivéssemos que usar Cassandra, porque para nós era uma espécie de nova experiência. Mas nada mais é adequado. Parece-me que essa é a situação mais triste do mercado para esses sistemas de armazenamento - não há
alternativa .

O que é Cassandra?
Este é um banco de dados de valor-chave distribuído. Do ponto de vista da arquitetura e das idéias nele incorporadas, parece-me que tudo é legal. Se eu fizesse, faria o mesmo. Quando começamos, pensamos em escrever nosso próprio sistema de armazenamento de metadados. Mas quanto mais longe, mais e mais percebemos que teríamos que fazer algo muito semelhante a Cassandra, e os esforços que vamos gastar nela não valem a pena. Durante todo o desenvolvimento
, tivemos apenas um mês e meio . Seria estranho gastá-los escrevendo seu banco de dados.
Se Cassandra estivesse em camadas como um bolo, eu selecionaria 3 camadas:
1.
Armazenamento KV local em cada nó.Este é um cluster de nós, cada um dos quais pode armazenar dados de valor-chave localmente.
2.
Dados de fragmentação em nós (hash consistente).O Cassandra pode distribuir dados entre os nós do cluster, incluindo replicação, e o faz de maneira que o cluster possa aumentar ou diminuir de tamanho e os dados serão redistribuídos.
3. Um
coordenador para redirecionar solicitações para outros nós.Quando acessamos dados para algumas consultas de nosso aplicativo, o Cassandra pode distribuir nossa consulta em nós para obter os dados desejados e com o nível de consistência de que precisamos - queremos lê-los apenas no quorum, ou deseja quorum com dois CDs, etc.
Para nós, dois anos com Cassandra - é uma montanha-russa ou uma montanha-russa - o que você quiser. Tudo começou no fundo, não tínhamos experiência com Cassandra. Nós estávamos com medo. Começamos e estava tudo bem. Mas então caem e decolam constantemente: o problema, tudo está ruim, não sabemos o que fazer, obtemos erros, resolvemos o problema etc.
Essas montanhas-russas, em princípio, não terminam até hoje.
Bom
O primeiro e o último capítulo, onde eu digo que Cassandra é legal. É muito legal, um ótimo sistema, mas se eu continuar dizendo o quão bom é, acho que você não estará interessado. Portanto, prestaremos mais atenção ao mal, mas mais tarde.
Cassandra é muito boa.
- Este é um dos sistemas que nos permite ter um tempo de resposta em milissegundos , ou seja, obviamente, menos de 10 ms. Isso é bom para nós, porque o tempo de resposta em geral é importante para nós. A operação com metadados para nós é apenas parte de qualquer operação relacionada ao armazenamento de um objeto, esteja ele recebendo ou gravando.
- Do ponto de vista da gravação, é alcançada alta escalabilidade . Você pode escrever no Cassandra a uma velocidade louca e, em algumas situações, isso é necessário, por exemplo, quando movemos grandes quantidades de dados entre registros.
- Cassandra é verdadeiramente tolerante a falhas . A queda de um nó não leva a problemas imediatamente, embora mais cedo ou mais tarde eles comecem. Cassandra declara que não possui um único ponto de falha, mas, de fato, há pontos de falha em todos os lugares. De fato, quem trabalhou com o banco de dados sabe que mesmo uma falha no nó não é algo que geralmente sofre até de manhã. Geralmente, essa situação precisa ser corrigida mais rapidamente.
- Simplicidade. Ainda assim, comparado a outros bancos de dados relacionais padrão do Cassandra, é mais fácil entender o que está acontecendo. Muitas vezes, algo dá errado, e precisamos entender o que está acontecendo. Cassandra tem mais chances de descobrir, chegar ao menor parafuso, provavelmente, do que em outro banco de dados.
Cinco histórias ruins
Repito, Cassandra é boa, funciona para nós, mas vou contar cinco histórias sobre as ruins. Eu acho que é para isso que você lê. Darei as histórias em ordem cronológica, embora elas não estejam muito ligadas umas às outras.

Essa história foi a mais triste para nós. Como armazenamos dados do usuário, a pior coisa possível é perdê-los e
perdê-los para sempre , como aconteceu nessa situação. Fornecemos maneiras de recuperar dados se os perdermos no Cassandra, mas os perdemos para que realmente não pudéssemos recuperar.
Para explicar como isso acontece, terei que falar um pouco sobre como tudo está organizado dentro de nós.
Da perspectiva do S3, existem algumas coisas básicas:
- Balde - pode ser imaginado como um enorme catálogo no qual o usuário carrega um objeto (a seguir denominado balde).
- Cada objeto possui um nome (chave) e metadados associados: tamanho, tipo de conteúdo e um ponteiro para os dados do objeto. Ao mesmo tempo, o tamanho do balde não é limitado por nada. Ou seja, pode ter 10 teclas, talvez 100 bilhões de teclas - não há diferença.
- Qualquer operação competitiva é possível, ou seja, pode haver vários preenchimentos competitivos na mesma chave, pode haver exclusão competitiva etc.
Em nossa situação, ativo-ativo, podem ocorrer operações, inclusive competitivamente em diferentes CDs, não apenas em um. Portanto, precisamos de algum tipo de esquema de conservação que nos permita implementar essa lógica. No final, escolhemos uma política simples: a última versão gravada vence. Às vezes, várias operações competitivas ocorrem, mas não é necessário que nossos clientes façam isso de propósito. Pode ser apenas uma solicitação iniciada, mas o cliente não esperou por uma resposta, algo mais aconteceu, tentou novamente etc.
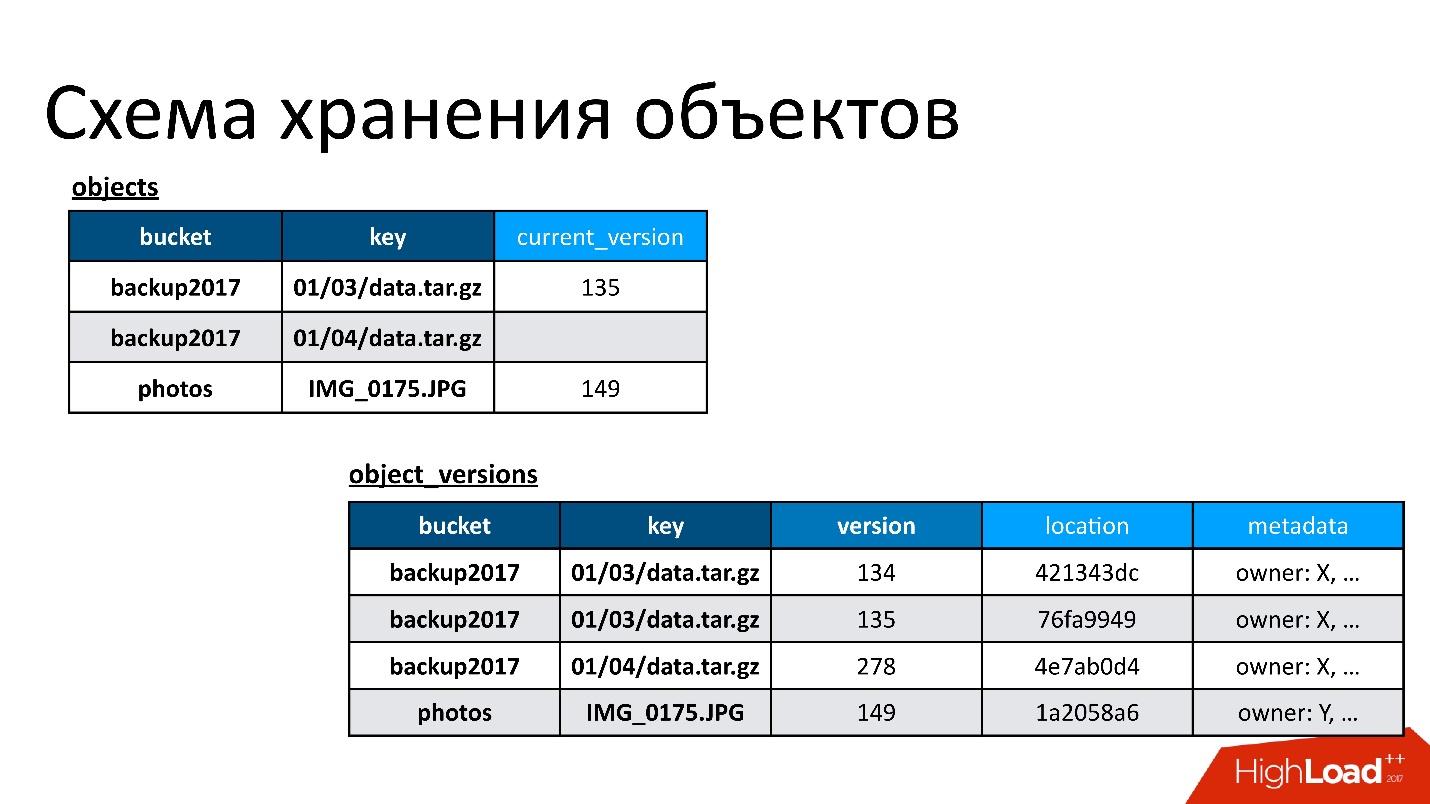
Portanto, temos duas tabelas base:
- Tabela de objetos . Nele, um par - o nome do bucket e o nome da chave - é associado à sua versão atual. Se o objeto for excluído, não há nada nesta versão. Se o objeto existir, há sua versão atual. De fato, nesta tabela, apenas alteramos o campo da versão atual.
- Tabela de versão dos objetos . Apenas inserimos novas versões nessa tabela. Cada vez que um novo objeto é baixado, inserimos uma nova versão na tabela de versões, fornecemos um número único, salvamos todas as informações sobre ele e, no final, atualizamos o link para ele na tabela de objetos.
A figura mostra um exemplo de como tabelas de objetos e versões de objetos estão relacionadas.

Aqui está um objeto que possui duas versões - uma atual e outra antiga, existe um objeto que já foi excluído e sua versão ainda está lá. Precisamos limpar versões desnecessárias de tempos em tempos, ou seja, excluir algo a que ninguém mais se refere. Além disso, não precisamos excluí-lo imediatamente, podemos fazê-lo no modo adiado. Esta é a nossa limpeza interna, apenas excluímos o que não é mais necessário.
Houve um problema.
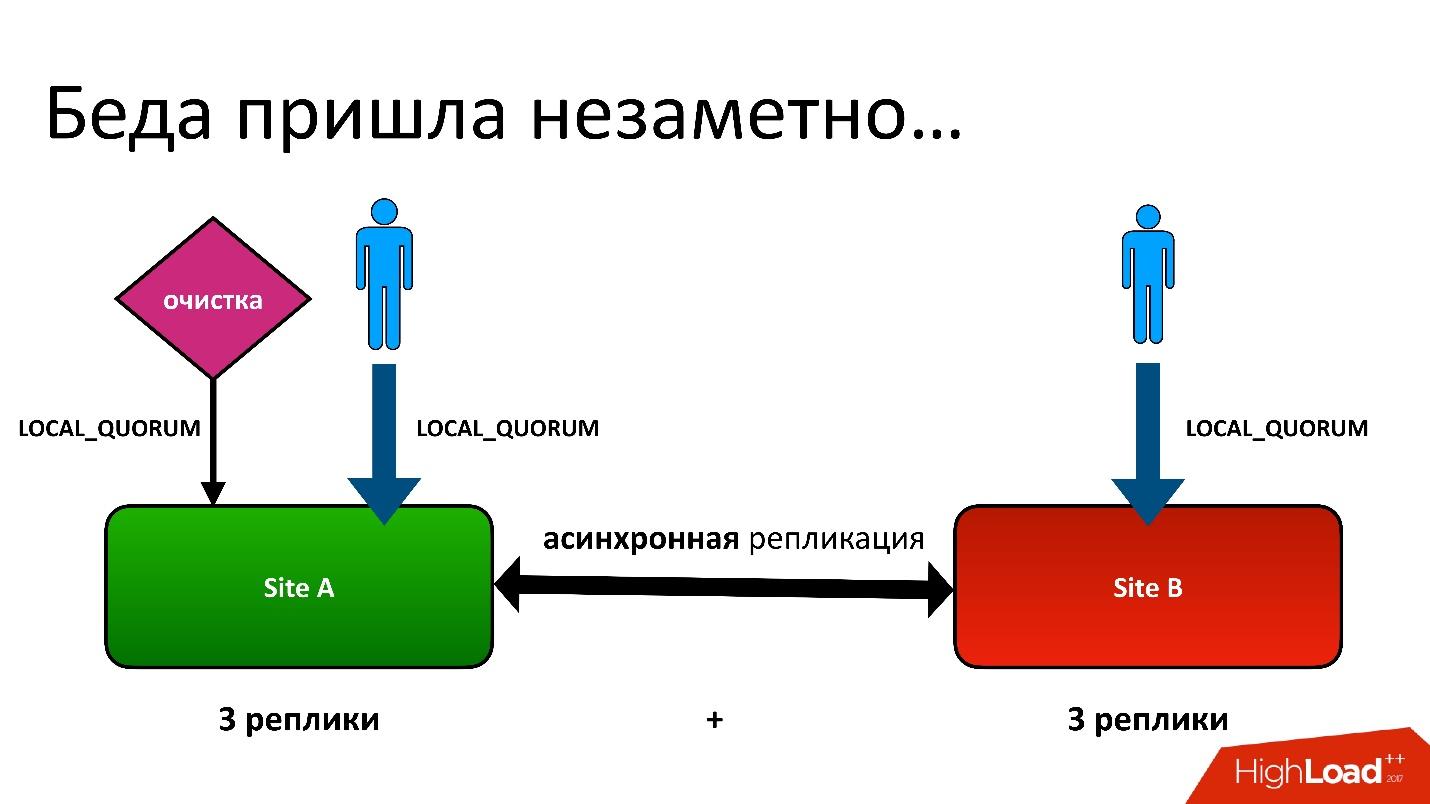
O problema era este: nós temos ativo-ativo, dois CDs. Em cada controlador de domínio, os metadados são armazenados em três cópias, ou seja, temos 3 + 3 - apenas 6 réplicas. Quando os clientes nos contactam, realizamos operações com consistência (do ponto de vista do Cassandra, isso é chamado LOCAL_QUORUM). Ou seja, é garantido que o registro (ou leitura) ocorreu em duas réplicas no controlador de domínio local. Isso é uma garantia - caso contrário, a operação falhará.
Cassandra sempre tentará escrever em todas as 6 linhas - 99% das vezes tudo ficará bem. De fato, todas as 6 réplicas serão as mesmas, mas garantidas para nós 2.
Tivemos uma situação difícil, embora nem fosse uma região geográfica. Mesmo para regiões comuns que estão em um controlador de domínio, ainda armazenamos a segunda cópia dos metadados em outro controlador de domínio. Esta é uma longa história, não vou dar todos os detalhes. Mas, no final, tivemos um processo de limpeza que removeu versões desnecessárias.
E então o mesmo problema surgiu. O processo de limpeza também funcionou com a consistência do quorum local em um data center, porque não há sentido em executá-lo em dois - eles irão lutar entre si.
Tudo estava bem até que nossos usuários ainda gravassem em outro data center, o que não suspeitávamos. Tudo foi preparado para o amante dos feylover, mas eles já estavam usando.
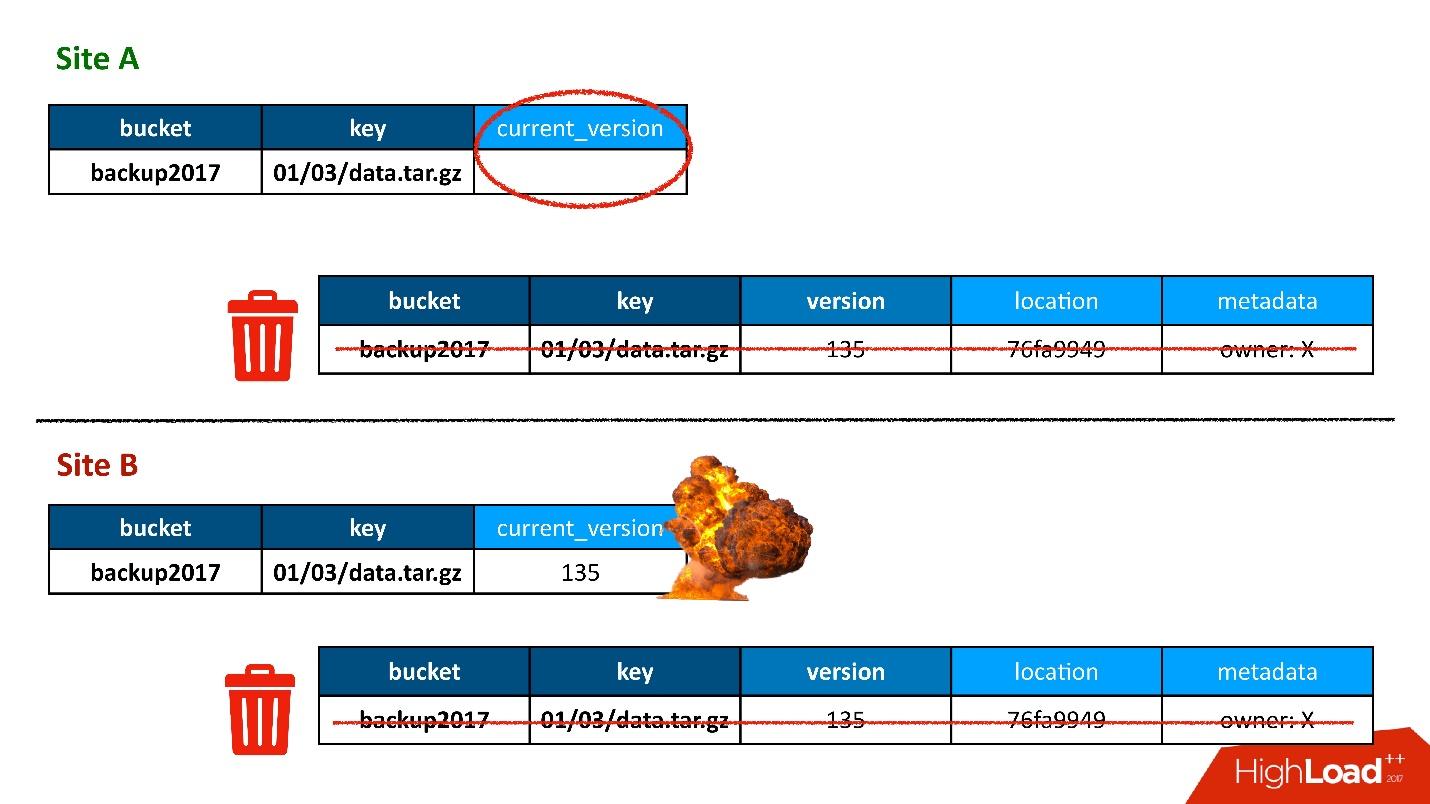
Na maioria das vezes, tudo estava bem até que um dia surgiu uma situação em que uma entrada na tabela de versões foi replicada nos dois CDs, mas o registro na tabela de objetos acabou em apenas um CD e não terminou no segundo. Consequentemente, o procedimento de limpeza, iniciado no primeiro CD (superior), viu que havia uma versão à qual ninguém estava se referindo e a excluiu. E apaguei não apenas a versão, mas também, é claro, os dados - tudo é completamente, porque é apenas um objeto desnecessário. E essa remoção é irrevogável.
Obviamente, há um "boom" adicional, porque ainda temos um registro na tabela de objetos que se refere a uma versão que não existe mais.
Então, a primeira vez que perdemos dados, e realmente irrevogavelmente - bom, um pouco.
Solução
O que fazer Na nossa situação, tudo é simples.
Como temos dados armazenados em dois data centers, o processo de limpeza é um processo de convergência e sincronização. Nós devemos ler os dados dos dois CDs. Esse processo funcionará apenas quando os dois controladores de domínio estiverem disponíveis. Como eu disse que esse é um processo atrasado que não ocorre durante o processamento da API, isso não é assustador.
Consistência ALL é um recurso do Cassandra 2. No Cassandra 3, tudo fica um pouco melhor - há um nível de consistência, chamado quorum em cada CD. Mas, em qualquer caso, há o problema de que é
lento , porque, primeiro, precisamos recorrer ao controlador de domínio remoto. Em segundo lugar, no caso de consistência de todos os 6 nós, isso significa que ele funciona na velocidade do pior desses 6 nós.
Mas, ao mesmo tempo, ocorre o chamado processo de
reparo e leitura , quando nem todas as réplicas são síncronas. Ou seja, quando a gravação falhou em algum lugar, esse processo as repara simultaneamente. É assim que Cassandra funciona.
Quando isso aconteceu, recebemos uma reclamação do cliente de que o objeto não estava disponível. Nós descobrimos, entendemos o porquê e a primeira coisa que queríamos fazer era descobrir quantos outros objetos possuímos. Executamos um script que tentou encontrar uma construção semelhante a essa quando havia uma entrada em uma tabela, mas nenhuma entrada em outra.
De repente, descobrimos que possuímos
10% desses registros . Provavelmente nada pior poderia ter acontecido se não tivéssemos adivinhado que não era esse o caso. O problema era diferente.

Os zumbis invadiram nosso banco de dados. Este é o nome semioficial para esse problema. Para entender o que é, você precisa falar sobre como a remoção funciona no Cassandra.
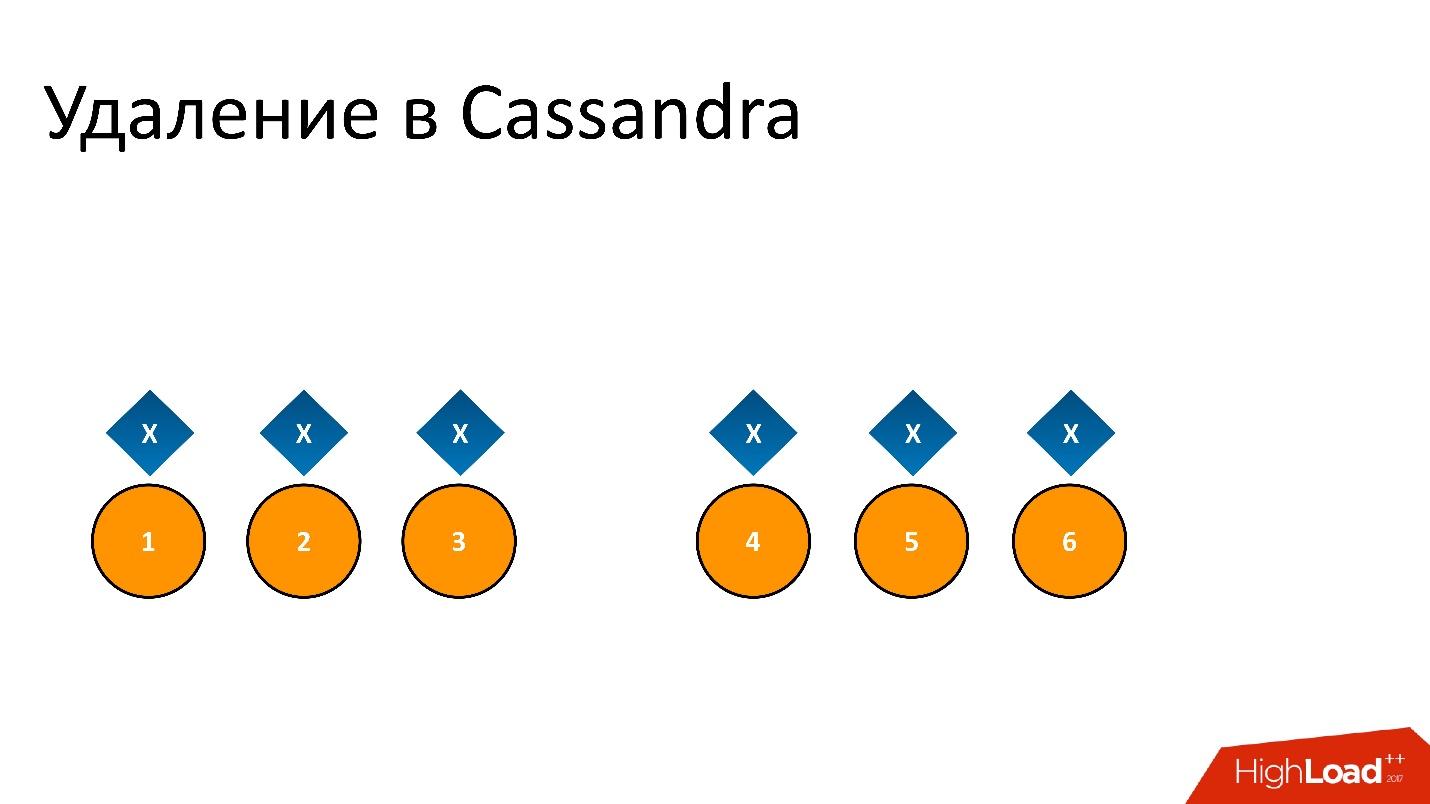
Por exemplo, temos alguns dados
x que são registrados e perfeitamente replicados para todas as 6 réplicas. Se quisermos excluí-lo, a remoção, como qualquer operação no Cassandra, pode não ser executada em todos os nós.
Por exemplo, queríamos garantir a consistência de 2 em 3 em um CD. Deixe a operação de exclusão ser executada em cinco nós, mas permaneça em um registro, por exemplo, porque o nó não estava disponível naquele momento.
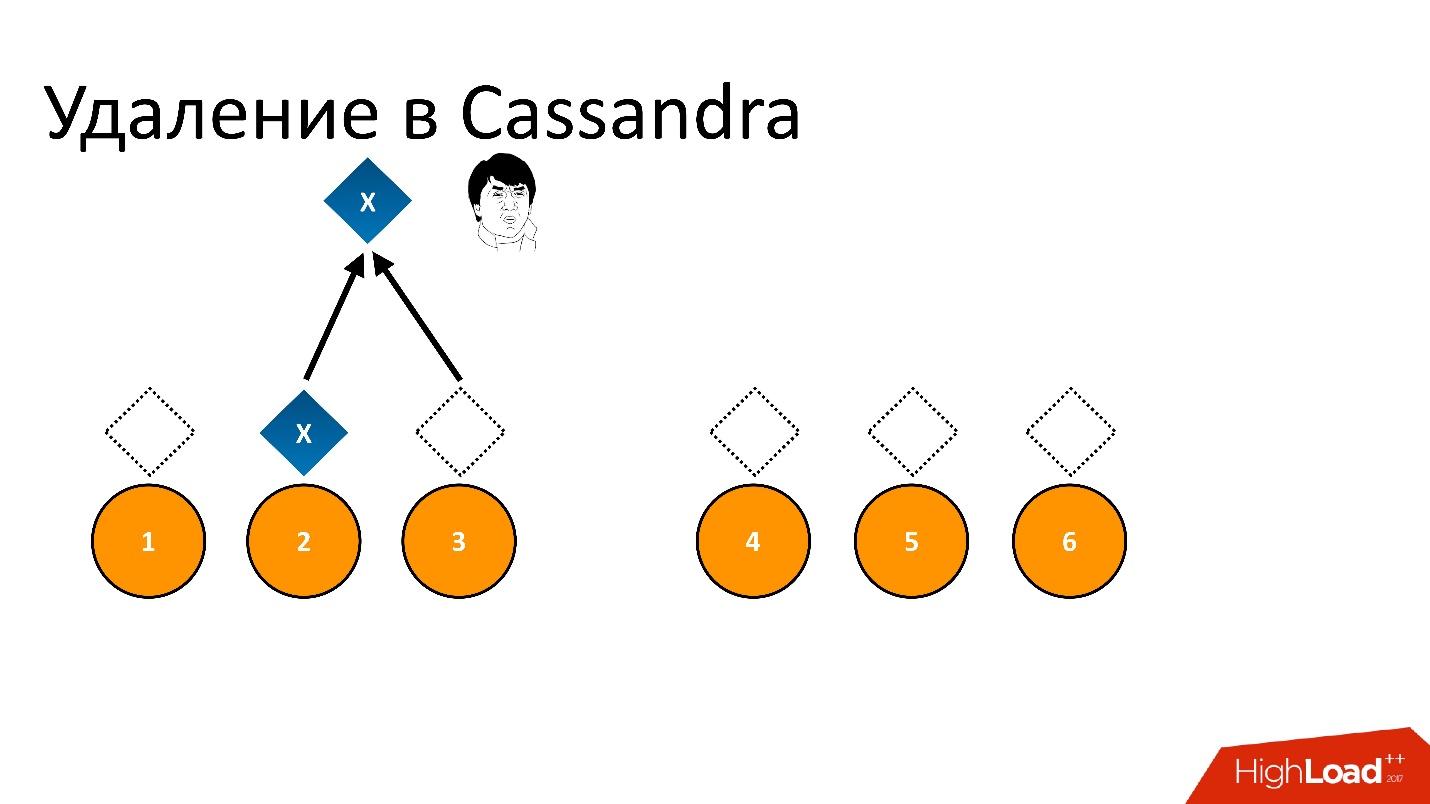
Se excluirmos isso e tentarmos ler “Quero 2 de 3” com a mesma consistência, Cassandra, vendo o valor e sua ausência, interpreta isso como a presença de dados. Ou seja, ao ler de volta, ela dirá: “Ah, existem dados!”, Embora os excluamos. Portanto, você não pode excluir dessa maneira.

Cassandra remove de forma diferente.
A exclusão é realmente um registro . Quando excluímos dados, Cassandra escreve um pequeno marcador chamado
Lápide (lápide). Marca que os dados foram excluídos. Portanto, se lermos o token de exclusão e os dados ao mesmo tempo, o Cassandra sempre prefere o token de exclusão nessa situação e diz que, na verdade, não há dados. É disso que você precisa.
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
Solução
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
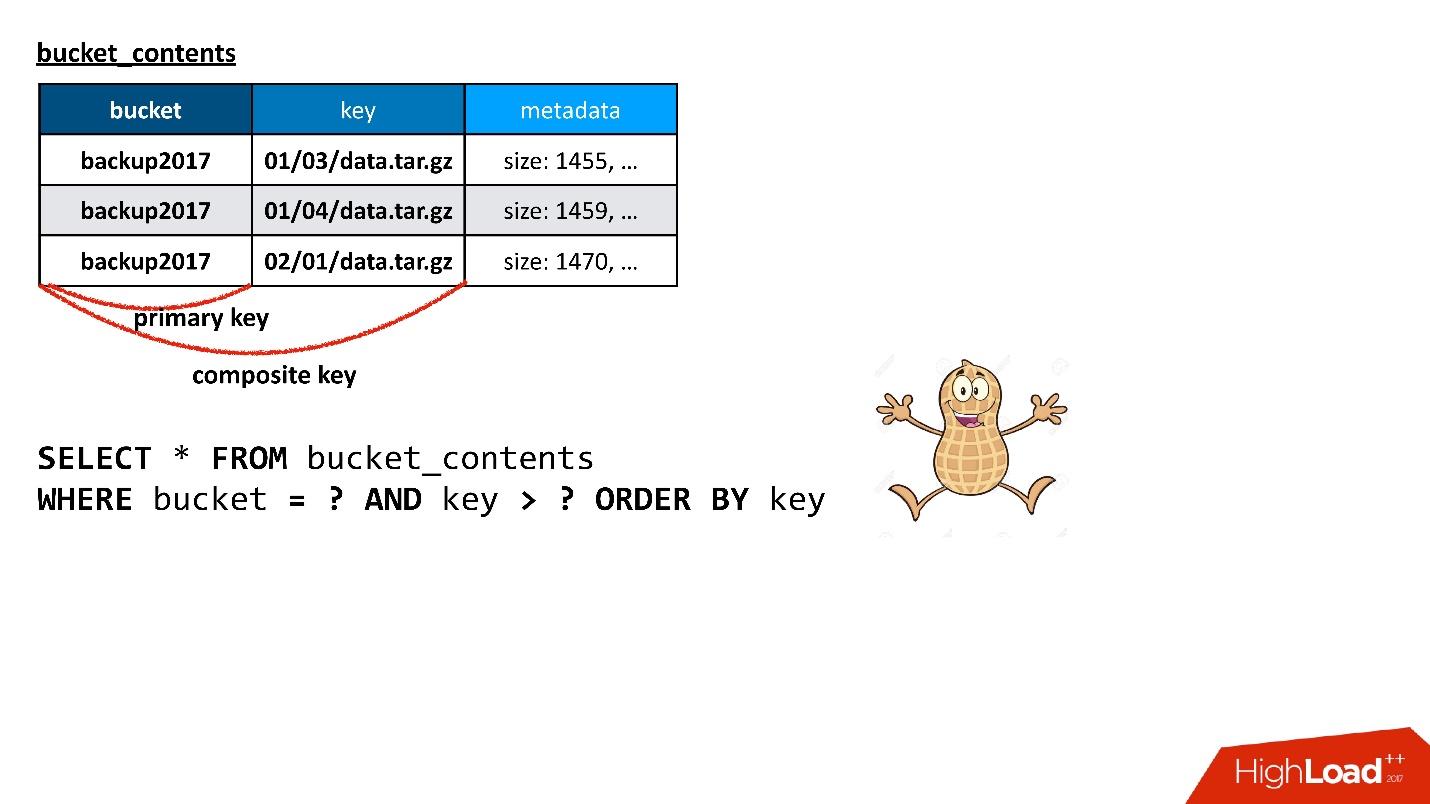
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
Agora temos algum estado do balde, de alguma forma é dividido em partições. Então entendemos que algumas partições são muito grandes ou muito pequenas. Precisamos encontrar uma nova partição, que, por um lado, seja ótima, ou seja, o tamanho de cada partição será menor que alguns de nossos limites e eles serão mais ou menos uniformes. Nesse caso, a transição do estado atual para um novo deve exigir um número mínimo de ações. É claro que qualquer transição requer mover chaves entre partições, mas quanto menos as movermos, melhor.
Nós conseguimos. Provavelmente, a parte que lida com a seleção da distribuição é a parte mais difícil de todo o serviço, se falarmos sobre trabalhar com metadados em geral. Reescrevemos, reformulamos e ainda fazemos, porque sempre são encontrados alguns clientes ou certos padrões de criação de chaves que atingem um ponto fraco desse esquema.
Por exemplo, presumimos que o balde crescesse mais ou menos uniformemente. Ou seja, escolhemos algum tipo de distribuição e esperávamos que todas as partições crescessem de acordo com essa distribuição. Mas encontramos um cliente que sempre escreve no final, no sentido de que suas chaves estão sempre na ordem de classificação. O tempo todo ele bate na última partição, que cresce a uma velocidade que em um minuto pode chegar a 100 mil chaves. E 100 mil é aproximadamente o valor que cabe em uma partição.
Simplesmente não teríamos tempo para processar essa adição de chaves com nosso algoritmo e tivemos que introduzir uma distribuição preliminar especial para esse cliente. Como sabemos como são as chaves dele, se vemos que é ele, começamos a criar partições vazias com antecedência no final, para que ele possa escrever com calma lá, e por enquanto teríamos um pouco de descanso até a próxima iteração, quando precisarmos novamente redistribua tudo.
Tudo isso acontece online, no sentido de que não paramos a operação. Pode haver operações de leitura e gravação, a qualquer momento você pode solicitar uma lista de chaves. Sempre será consistente, mesmo se estivermos no processo de reparticionamento.
É bem interessante, e acontece com Cassandra. Aqui você pode jogar com truques relacionados ao fato de Cassandra ser capaz de resolver conflitos. Se escrevermos dois valores diferentes na mesma linha, o valor que possui um carimbo de data / hora maior vence.
Normalmente, o carimbo de data / hora é o carimbo de data / hora atual, mas pode ser passado manualmente. Por exemplo, queremos escrever um valor em uma string, que em qualquer caso deve ser esfregada se o cliente escrever algo. Ou seja, estamos copiando alguns dados, mas queremos que o cliente, se de repente ele escreve conosco ao mesmo tempo, possa substituí-lo. Em seguida, podemos copiar nossos dados com um carimbo de data e hora um pouco do passado. Qualquer gravação atual será deliberadamente desgastada, independentemente da ordem em que a gravação foi feita.
Esses truques permitem fazer isso online.
Solução
- Nunca, nunca permita a aparência de uma partição grande .
- Divida os dados por chave primária, dependendo da tarefa.
Se algo semelhante a uma partição grande estiver planejado no esquema de dados, tente imediatamente fazer algo a respeito - descubra como quebrá-lo e como fugir dele. Mais cedo ou mais tarde, isso surge, porque qualquer índice invertido surge mais cedo ou mais tarde em quase qualquer tarefa. Eu já contei sobre essa história - temos uma chave de balde no objeto e precisamos obter uma lista de chaves do balde - na verdade, este é um índice.
Além disso, a partição pode ser grande não apenas a partir dos dados, mas também a partir de Tombstones (marcadores de exclusão). Do ponto de vista dos componentes internos do Cassandra (nunca os vemos de fora), os marcadores de exclusão também são dados e uma partição pode ser grande se muitas coisas forem excluídas, porque a exclusão é um registro. Você não deve esquecer isso também.

Outra história que é realmente constante é que algo dá errado do começo ao fim. Por exemplo, você vê que o tempo de resposta do Cassandra aumentou, ele responde lentamente. Como entender e entender qual é o problema? Nunca há um sinal externo de que o problema está lá.

Por exemplo, darei um gráfico - este é o tempo médio de resposta do cluster como um todo. Isso mostra que temos um problema - o tempo máximo de resposta é de 12 segundos - esse é o tempo limite interno do Cassandra. Isso significa que ela se esgotará. Se o tempo limite for superior a 12 s, isso provavelmente significa que o coletor de lixo está funcionando e Cassandra nem tem tempo para responder no momento certo. Ela responde a si mesma com tempo limite, mas o tempo de resposta para a maioria das solicitações, como eu disse, deve ser em média de 10 ms.
No gráfico, a média já excedeu centenas de milissegundos - algo deu errado. Mas, olhando para esta foto, é impossível entender qual é o motivo.

Mas se você expandir as mesmas estatísticas nos nós do Cassandra, poderá ver que, em princípio, todos os nós são mais ou menos nada, mas o tempo de resposta para um nó difere por ordens de magnitude. Provavelmente, há algum tipo de problema com ele.
As estatísticas nos nós alteram completamente a imagem. Essas estatísticas são do lado do aplicativo. Mas aqui é realmente muito difícil entender qual é o problema. Quando um aplicativo acessa o Cassandra, ele acessa algum nó, usando-o como coordenador. Ou seja, o aplicativo faz uma solicitação e o coordenador o redireciona para as réplicas com os dados. Eles já respondem, e o coordenador devolve a resposta final.
Mas por que o coordenador responde devagar? Talvez o problema esteja com ele, como tal, ou seja, ele diminui a velocidade e responde lentamente? Ou talvez ele diminua a velocidade, porque as réplicas respondem lentamente a ele? Se as réplicas responderem lentamente, do ponto de vista do aplicativo, parecerá uma resposta lenta do coordenador, embora não tenha nada a ver com isso.
Aqui está uma situação feliz - é claro que apenas um nó responde lentamente, e provavelmente o problema está nele.
Complexidade de interpretação
- Tempo de resposta do coordenador (nó x réplica).
- Uma tabela específica ou o nó inteiro?
- GC Pausar? Pool de threads inadequado?
- Muitas SSTables descompactadas?
É sempre difícil entender o que está errado. Ele só
precisa de muitas estatísticas e monitoramento , tanto do lado do aplicativo quanto do próprio Cassandra, porque, se estiver muito ruim, nada é visível no Cassandra. Você pode observar o nível de consultas individuais, no nível de cada tabela específica, em cada nó específico.
Pode haver, por exemplo, uma situação em que uma tabela do que é chamado no Cassandra SSTables (arquivos separados) tem muito. Para ler, Cassandra tem, grosso modo, que classificar todas as SSTables. Se houver muitos deles, simplesmente o processo dessa classificação leva muito tempo e a leitura começa a ceder.
A solução é compactação, o que reduz o número dessas SSTables, mas deve-se observar que ele pode estar apenas em um nó para uma tabela específica. Como o Cassandra, infelizmente, é escrito em Java e executado na JVM, talvez o coletor de lixo tenha entrado em uma pausa tão grande que simplesmente não tem tempo para responder. Quando o coletor de lixo entra em pausa, não apenas suas solicitações diminuem, mas a
interação no cluster Cassandra entre os nós começa a diminuir . Os nós um do outro começam a ser considerados como tendo caído, isto é, caído, morto.
Uma situação ainda mais divertida começa, porque quando um nó acredita que outro nó está inativo, primeiro não envia solicitações e, em segundo lugar, começa a tentar salvar os dados que precisaria replicar para outro nó em localmente, então ele começa a se matar lentamente, etc.
Há situações em que esse problema pode ser resolvido simplesmente usando as configurações corretas. Por exemplo, pode haver recursos suficientes, tudo está bem e maravilhoso, mas apenas um Pool de Threads, cujo número é de tamanho fixo, precisa ser aumentado.
Por fim, talvez seja necessário limitar a competitividade do lado do motorista. Às vezes, acontece que muitas solicitações competitivas foram enviadas e, como qualquer banco de dados, Cassandra não consegue lidar com elas e vai ao clinch quando o tempo de resposta aumenta exponencialmente, e estamos tentando dar cada vez mais trabalho.
Compreensão do contexto
Sempre há algum contexto para o problema - o que está acontecendo no cluster, se o Reparo está funcionando agora, em qual nó, em quais espaços-chave, em que tabela.
Por exemplo, tivemos problemas bastante ridículos com o ferro. Vimos que parte dos nós é lenta. Mais tarde, foi descoberto que o motivo era que, no BIOS, seus processadores estavam no modo de economia de energia. Por alguma razão, durante a instalação inicial do ferro, isso aconteceu e aproximadamente 50% dos recursos do processador foram usados em comparação com outros nós.
Compreender esse problema pode ser difícil, de fato. O sintoma é este - parece que o nó faz compactação, mas faz isso lentamente. Às vezes, é conectado ao ferro, às vezes não, mas esse é apenas mais um bug do Cassandra.
Portanto, o monitoramento é obrigatório e precisa de muito. Quanto mais complexo o recurso no Cassandra, mais distante fica da simples escrita e leitura, mais problemas existem com ele e mais rápido ele pode matar um banco de dados com um número suficiente de consultas. Portanto, se possível, não olhe para alguns chips "saborosos" e tente usá-los, é melhor evitá-los o máximo possível. Nem sempre é possível - é claro, mais cedo ou mais tarde é necessário.

A história mais recente é sobre como Cassandra estragou os dados. Nesta situação, aconteceu dentro de Cassandra. Isso foi interessante.
Vimos que, uma vez por semana, em nosso banco de dados, várias dezenas de linhas danificadas aparecem - elas estão literalmente entupidas de lixo. Além disso, Cassandra valida os dados que vão para sua entrada. Por exemplo, se for uma string, deve estar em utf8. Mas nessas linhas havia lixo, e não lixo, e Cassandra nem deu nada a ver com isso. Quando tento excluir (ou fazer outra coisa), não consigo excluir um valor que não seja utf8, porque, em particular, não posso inseri-lo em WHERE, porque a chave deve ser utf8.
Linhas estragadas aparecem, como um flash, em algum momento e depois desaparecem por vários dias ou semanas.
Começamos a procurar um problema. Pensamos que talvez houvesse um problema em um nó específico com o qual estávamos mexendo, fazendo algo com dados, copiando SSTables. Talvez, mesmo assim, você possa ver réplicas desses dados? Talvez essas réplicas tenham um nó comum, o menor fator comum? Talvez alguns nós falhem? Não, nada disso.
Talvez algo com um disco? Os dados estão corrompidos no disco? Não de novo.
Talvez uma lembrança? Não! Espalhados por um cluster.
Talvez este seja algum tipo de problema de replicação? Um nó estragou tudo e replicou ainda um valor ruim? - não.
Finalmente, talvez este seja um problema de aplicativo?
Além disso, em algum momento, as linhas danificadas começaram a aparecer em dois grupos de Cassandra. Um trabalhou na versão 2.1, o segundo no terceiro. Parece que Cassandra é diferente, mas o problema é o mesmo. Talvez o nosso serviço envie dados incorretos? Mas era difícil de acreditar. Cassandra valida os dados de entrada; não foi possível gravar lixo. Mas de repente?
Nada se encaixa.
Uma agulha foi encontrada!
Lutamos muito até descobrir um pequeno problema: por que temos algum tipo de despejo de memória da JVM nos nós aos quais não prestamos muita atenção? E, de alguma forma, parece suspeito no coletor de lixo de rastreamento de pilha ... E, por alguma razão, algum rastreamento de pilha também está entupido com lixo.
No final, percebemos - oh,
por algum motivo, estamos usando a JVM da versão antiga de 2015 . Essa era a única coisa comum que unia clusters do Cassandra em diferentes versões do Cassandra.
Ainda não sei qual era o problema, porque nada foi escrito sobre isso nas notas de versão oficiais da JVM. Mas após a atualização, tudo desapareceu, o problema não surgiu mais. Além disso, isso não ocorreu no cluster desde o primeiro dia, mas a partir de algum ponto, embora tenha funcionado na mesma JVM por um longo tempo.
Recuperação de dados
Que lição aprendemos disso:
● O backup é inútil.
Os dados, como descobrimos, foram corrompidos no segundo em que foram gravados. No momento em que os dados entraram no coordenador, eles já estavam corrompidos.
● A restauração parcial de colunas não danificadas é possível.
Algumas colunas não foram danificadas, pudemos ler esses dados, restaurá-los parcialmente.
● No final, tivemos que fazer a recuperação de várias fontes.
Tínhamos metadados de backup no objeto, mas nos próprios dados. Para se reconectar com o objeto, usamos logs etc.
● Os logs não têm preço!
Conseguimos recuperar todos os dados que foram corrompidos, mas, no final, é muito difícil confiar no banco de dados se ele os perder, mesmo sem nenhuma ação da sua parte.
Solução
- Atualize a JVM após testes extensivos.
- Monitoramento de falhas da JVM.
- Tenha uma cópia independente dos dados do Cassandra.
Dica: Tente ter algum tipo de cópia independente de Cassandra dos dados dos quais você pode recuperar, se necessário. Esta pode ser a solução de último nível. Deixe levar muito tempo, recursos, mas deve haver alguma opção que permita retornar dados.
Bugs
●
Baixa qualidade de teste de liberaçãoQuando você começa a trabalhar com o Cassandra, há uma sensação constante (especialmente se você estiver movendo, relativamente falando, de bancos de dados "bons", por exemplo, PostgreSQL) de que se você corrigisse um bug na versão anterior, você definitivamente adicionaria um novo. E o bug não é um absurdo, geralmente é dados corrompidos ou outro comportamento incorreto.
●
Problemas persistentes com recursos complexosQuanto mais complexo o recurso, mais problemas, erros etc. com ele.
●
Não use reparo incremental no 2.1O famoso reparo, sobre o qual falei, que corrige a consistência dos dados, no modo padrão, quando ele pesquisa todos os nós, funciona bem. Mas não no chamado modo incremental (quando o reparo ignora dados que não foram alterados desde o reparo anterior, o que é bastante lógico). Foi anunciado há muito tempo, formalmente, como um recurso, mas todos dizem: “Não, na versão 2.1, nunca use-o! Ele definitivamente sentirá falta de algo. Em 3 nós consertamos. ”
●
Mas não use reparo incremental no 3.xQuando a terceira versão saiu, alguns dias depois eles disseram: “Não, você não pode usá-la na 3ª. Há uma lista de 15 erros, portanto, em nenhum caso, não use reparo incremental. Em quarto lugar faremos melhor! ”
Eu não acredito neles. E esse é um grande problema, especialmente com o aumento do tamanho do cluster. Portanto, você precisa monitorar constantemente o rastreador de erros e ver o que acontece. Infelizmente, é impossível viver com eles sem ele.
●
Precisa acompanhar o JIRA
Se você espalhar todos os bancos de dados no espectro de previsibilidade, Cassandra estará à esquerda na área vermelha. Isso não significa que seja ruim, você apenas precisa estar preparado para o fato de que Cassandra é imprevisível em qualquer sentido da palavra: tanto no modo como funciona como no fato de que algo pode acontecer.

Desejo que você encontre outros ancinhos e pise neles, porque, do meu ponto de vista, não importa o quê, Cassandra é boa e, certamente, não é chata. Basta lembrar os solavancos na estrada!
Reunião aberta de ativistas do HighLoad ++
No dia 31 de julho em Moscou, às 19:00, será realizada uma reunião de palestrantes, o Comitê de Programa e ativistas da conferência de desenvolvedores de sistemas de alta carga HighLoad ++ 2018. Organizaremos um pequeno brainstorming sobre o programa deste ano para não perder nada novo e importante. A reunião está aberta, mas você precisa se registrar .
Chamada de trabalhos
Aceitando ativamente solicitações de relatórios no Highload ++ 2018. O Comitê de Programa aguarda seu resumo até o final do verão.