
Esta é uma continuação da primeira parte do artigo.
Na primeira parte do artigo, o autor falou sobre as condições do concurso para o jogo Agario em mail.ru, a estrutura do mundo do jogo e parcialmente sobre a estrutura do bot. Em parte, porque eles afetaram apenas o dispositivo de sensores de entrada e comandos na saída da rede neural (a seguir, em imagens e texto, haverá uma abreviação NN). Então, vamos tentar abrir a caixa preta e entender como tudo está organizado lá.
E aqui está a primeira foto:
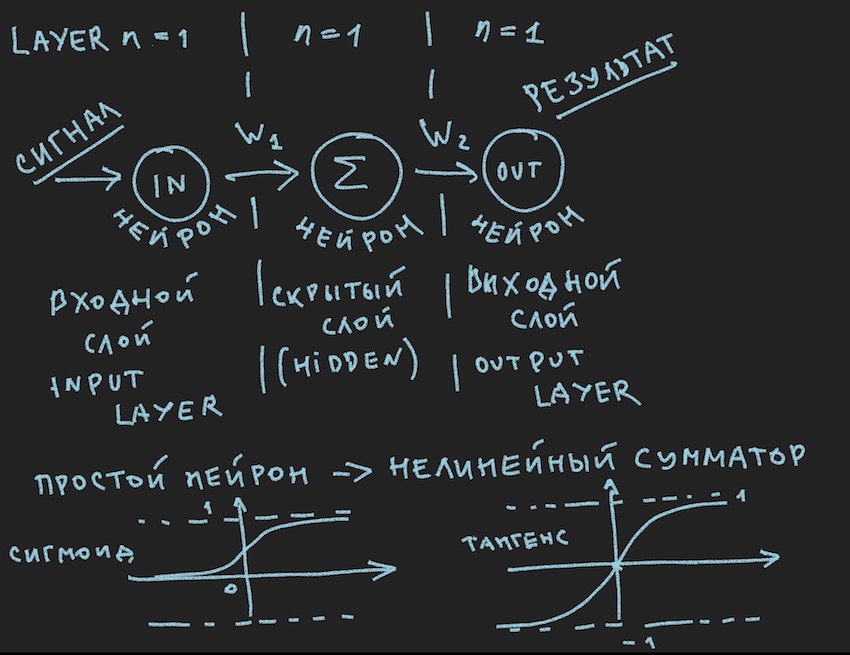
Descreve esquematicamente o que deve causar um sorriso entediado ao meu leitor, dizem novamente na primeira série, que foram vistos muitas vezes em várias fontes . Mas realmente queremos aplicar praticamente essa imagem ao gerenciamento do bot, portanto, após a Nota importante, vamos dar uma olhada mais de perto.
Nota importante: há um grande número de soluções prontas (estruturas) para trabalhar com redes neurais:

Todos esses pacotes resolvem as principais tarefas do desenvolvedor de redes neurais: a construção e o treinamento de NN ou a busca de pesos "ideais". E o principal método desta pesquisa é Backpropagation . Foi inventado nos anos 70 do século passado, como indicado no artigo no link acima, durante esse período, como parte inferior do navio, adquiriu várias melhorias, mas a essência é a mesma: encontrar coeficientes de peso com base em exemplos de treinamento e é altamente desejável que todos desses exemplos continha uma resposta pronta na forma de um sinal de saída de uma rede neural. O leitor pode se opor a mim. que redes de autoaprendizagem de várias classes e princípios já foram inventadas, mas tudo não está indo bem lá, até onde eu entendo. Obviamente, existem planos para estudar esse zoológico com mais detalhes, mas acho que vou encontrar pessoas que pensam que uma bicicleta feita de bricolage, mesmo a mais curva, está mais próxima do coração do criador do que um clone transportador de uma bicicleta ideal.
Entendendo que o servidor do jogo provavelmente não terá essas bibliotecas e o poder de computação alocado pelos organizadores como um núcleo de processador claramente não é suficiente para uma estrutura pesada, o autor continuou a criar sua própria bicicleta. Um comentário importante sobre isso terminou.
Vamos voltar à imagem que descreve provavelmente a mais simples das redes neurais possíveis com uma camada oculta (também conhecida como camada oculta ou camada oculta). Agora, o próprio autor tem contemplado constantemente a imagem com idéias neste exemplo simples para revelar ao leitor as profundezas das redes neurais artificiais. Quando tudo é simplificado para um primitivo, é mais fácil entender a essência. A conclusão é que o neurônio da camada oculta não tem nada para resumir. E provavelmente essa nem é uma rede neural. Nos livros didáticos, a NN mais simples é uma rede com duas entradas. Então aqui estamos nós, por assim dizer, os descobridores das redes mais simples.
Vamos tentar descrever essa rede neural (pseudocódigo):
Introduzimos a topologia de rede na forma de uma matriz, em que cada elemento corresponde à camada e ao número de neurônios nela:
int array Topology= { 1, 1, 1}
Também precisamos de uma matriz flutuante de pesos da rede neural W, considerando nossa rede como "redes neurais de avanço de alimentação (FF ou FFNN)", onde cada neurônio da camada atual está conectado a cada neurônio da próxima camada, obtemos a dimensão da matriz W [número de camadas , o número de neurônios na camada, o número de neurônios na camada]. Não é a codificação ideal, mas, considerando o hálito quente da GPU em algum lugar muito próximo do texto, é compreensível.
Um breve procedimento CalculateSize para contar o número de neurônios de neuroncount e o número de suas conexões na rede neural de dendritecount , acho que explicará melhor ao autor a natureza dessas conexões:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
Meu leitor, aquele que já sabe tudo isso, o autor chegou a essa opinião no primeiro artigo, certamente não perguntará: por que no terceiro loop aninhado Topologia [camada1 + 1] em vez de Topologia [camada1], que dá mais ao neurônio do que na topologia de rede . Eu não vou responder Também é útil para o leitor pedir lição de casa.
Estamos quase a um passo de construir uma rede neural funcional. Resta acrescentar a função de somar os sinais na entrada do neurônio e sua ativação. Existem muitas funções de ativação, mas as mais próximas da natureza do neurônio são Sigmoide e Tangensóide (provavelmente é melhor chamá-lo assim, embora esse nome não seja usado na literatura, o máximo é tangente, mas esse é o nome do gráfico, embora o gráfico seja um reflexo da função?)
Então aqui temos as funções de ativação dos neurônios (elas estão presentes na figura, na parte inferior)
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
Sigmoid retorna valores de 0 a 1.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
O tangentoide retorna valores de -1 a 1.
A ideia principal de um sinal que passa através de uma rede neural é uma onda: um sinal é alimentado para neurônios de entrada -> através de conexões neurais o sinal vai para a segunda camada -> neurônios da segunda camada resumem os sinais que os atingiram alterados por pesos interneuronais -> é adicionado através de um peso de polarização adicional -> usamos a função de ativação - e todos vamos para a próxima camada (leia o primeiro ciclo do exemplo por camadas), isto é, repetindo a cadeia desde o início, apenas os neurônios da próxima camada se tornarão neurônios de entrada. Na simplificação, você nem precisa armazenar os valores dos neurônios de toda a rede, apenas os pesos da NN e os valores dos neurônios da camada ativa.
Mais uma vez, enviamos um sinal para a entrada NN, a onda percorreu as camadas e na camada de saída removemos o valor obtido.
Aqui, pelo gosto do leitor, é possível resolver programaticamente usando recursão ou apenas um ciclo triplo como o do autor, para acelerar os cálculos, você não precisa cercar objetos na forma de neurônios e suas conexões e outras OOP. Novamente, isso ocorre devido à sensação de cálculos próximos da GPU, e nas GPUs, devido à natureza do paralelismo em massa, a OOP fica um pouco paralisada, isso é relativo a c # e C ++.
Além disso, o leitor é convidado a seguir o caminho da construção de uma rede neural em código, com o seu voluntariamente querendo, cuja ausência é bastante clara e familiar para o autor, como nos exemplos de criação de NN a partir do zero, há muitos exemplos na rede, por isso será difícil se perder, é assim tão simples quanto uma rede neural de distribuição direta na figura acima.
Mas onde o leitor exclamará, que ainda não se afastou da passagem anterior, e terá razão, na infância, o autor determinou o valor do livro através de ilustrações. Aqui está você:
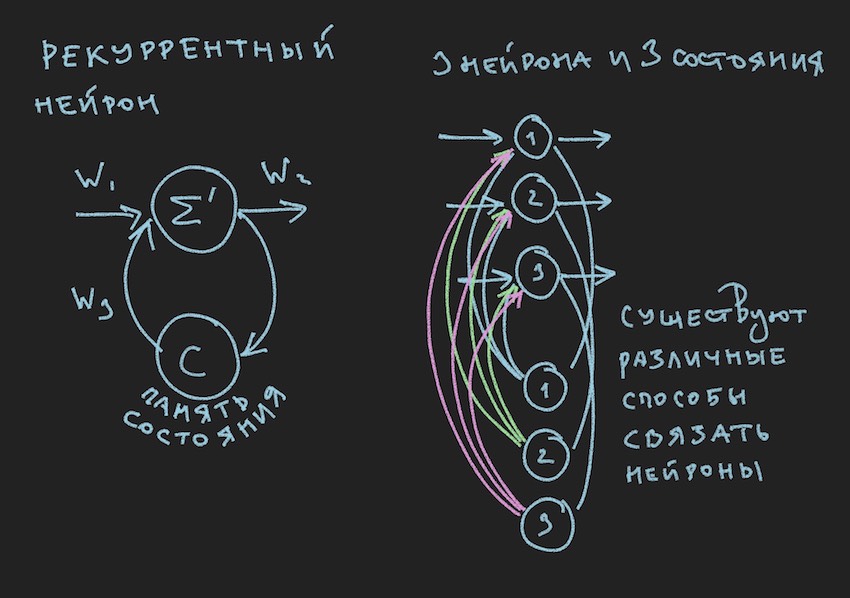
Na figura, vemos um neurônio recorrente e um NN construído a partir desses neurônios é chamado de recorrente ou RNN. A rede neural especificada possui uma memória de curto prazo e foi selecionada pelo autor para o bot como a mais promissora em termos de adaptação ao processo do jogo. Obviamente, o autor construiu uma rede neural de distribuição direta, mas, no processo de busca de uma solução "eficaz", mudou para a RNN.
Um neurônio recorrente possui um estado adicional C, que é formado após a primeira passagem de um sinal através de um neurônio, Tick + 0 na linha do tempo. Em palavras simples, esta é uma cópia do sinal de saída de um neurônio. Na segunda etapa, leia Tick + 1 (uma vez que a rede opera na frequência do bot e do servidor do jogo), o valor C retorna à entrada da camada neural através de pesos adicionais e, assim, participa da formação do sinal, mas já no momento do Tick + 1.
Nota: no trabalho de grupos de pesquisa sobre o gerenciamento de bots de jogos NN , há uma tendência de usar dois ritmos para uma rede neural, um ritmo é a frequência do jogo Tick, o segundo ritmo, por exemplo, é duas vezes mais lento que o primeiro. Diferentes partes do NN operam em diferentes frequências, o que fornece uma visão diferente da situação do jogo dentro do NN, aumentando assim sua flexibilidade.
Para criar RNN no código bot, introduzimos uma matriz adicional na topologia, onde cada elemento corresponde à camada e ao número de estados neurais nela:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
Pode-se observar pela topologia acima que a segunda camada é recorrente, uma vez que contém estados neurais. Também introduzimos pesos adicionais na forma de um flutuador da matriz WRR, a mesma dimensão que a matriz W.
A contagem de conexões em nossa rede neural mudará um pouco:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
O autor anexará o código geral para uma rede neural recorrente no final deste artigo, mas o principal a entender é o princípio: a passagem de uma onda através de camadas no caso de um NN recorrente não altera nada fundamentalmente, apenas mais um termo é adicionado à função de ativação do neurônio. Este é o termo do estado dos neurônios no Tick anterior multiplicado pelo peso da conexão neural.
Assumimos que a teoria e a prática das redes neurais foram atualizadas, mas o autor está claramente ciente de que não trouxe o leitor mais perto de entender como ensinar essa estrutura simples de redes neurais a tomar decisões na jogabilidade. Não temos bibliotecas com exemplos para ensinar NN. Nos grupos de desenvolvedores de bot na Internet, havia uma opinião: forneça um arquivo de log na forma de coordenadas de bots e outras informações do jogo para formar uma biblioteca de exemplos. Mas o autor, infelizmente, não conseguiu descobrir como usar esse arquivo de log para treinar NN. Ficarei feliz em discutir isso nos comentários do artigo. Portanto, o único método disponível ao autor para entender o método de treinamento, ou melhor, encontrar neurobalanças "efetivas" (neuroconnections), foi o algoritmo genético.
Preparou uma imagem sobre os princípios do algoritmo genético:
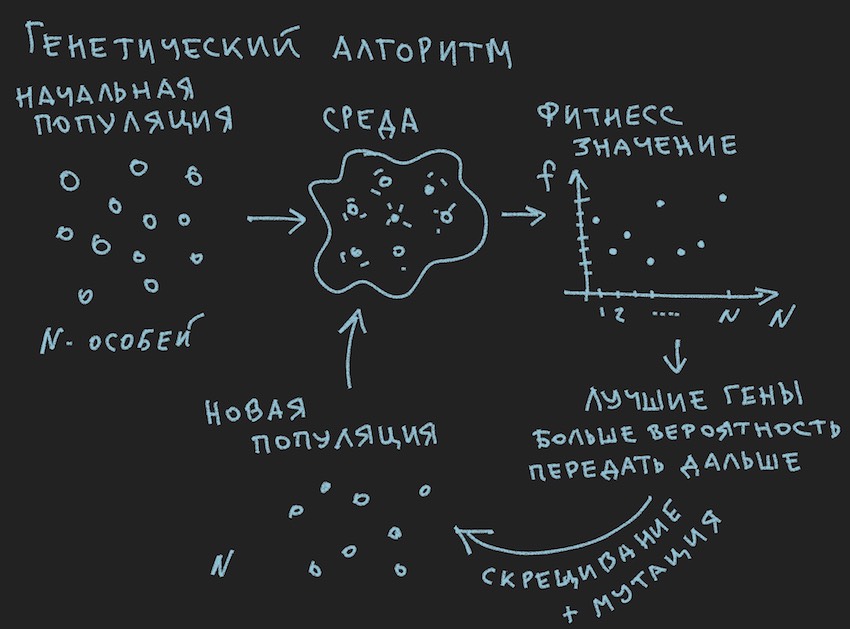
Então, o algoritmo genético .
O autor tentará não se aprofundar na teoria desse processo , mas lembrará apenas o mínimo necessário para continuar uma leitura completa do artigo.
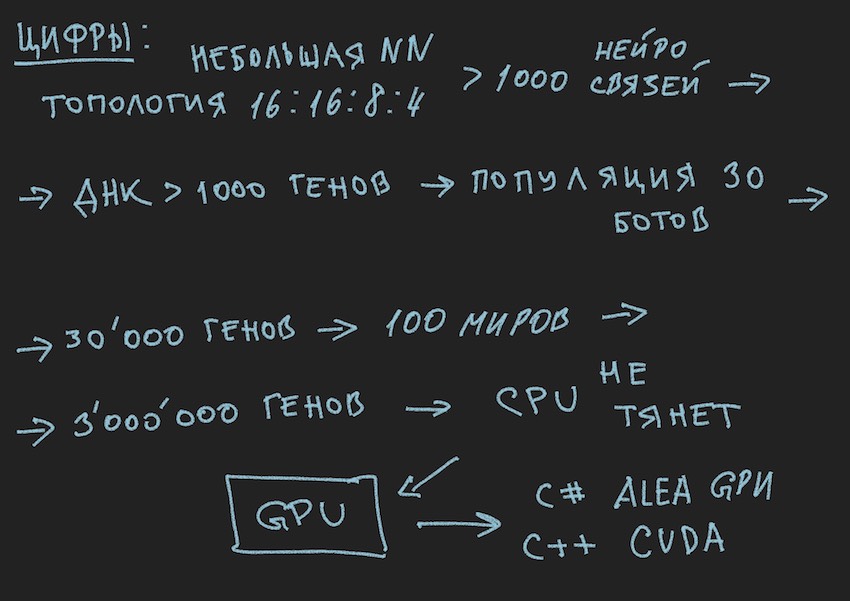
No algoritmo genético, o principal fluido de trabalho é o gene (DNA é o nome da molécula). O genoma, no nosso caso, é um conjunto seqüencial de genes ou uma matriz unidimensional de float long ...
No estágio inicial do trabalho com uma rede neural recém-construída, é necessário inicializá-la. Inicialização refere-se à atribuição de valores aleatórios de -1 a 1. Os balanços neurais.O autor mencionou que o intervalo de valores de -1 a 1 é muito extremo e as redes treinadas têm pesos em um intervalo menor, por exemplo, de -0,5 a 0,5 e que um intervalo de valores inicial deve ser aceito como excelente de -1 a 1. Mas seguiremos o caminho clássico de coletar todas as dificuldades em um portão e tomaremos o segmento mais amplo possível de variáveis aleatórias iniciais como base para inicializar a rede neural.
Agora uma bijeção ocorrerá. Assumiremos que o comprimento (tamanho) do genoma do bot será igual ao comprimento total das matrizes da rede neural TopologyNN.Length + TopologyRNN.Length não é à toa que o autor gastou o tempo do leitor no procedimento de contagem de conexões neurais.
Nota: Como o leitor já observou por si próprio, transferimos apenas os pesos da rede neural para o genótipo, a estrutura da conexão, as funções de ativação e os estados dos neurônios não são transmitidos. Para um algoritmo genético, apenas as conexões neurais são suficientes, o que sugere que elas são portadoras de informações. Há desenvolvimentos em que o algoritmo genético também altera a estrutura das conexões na rede neural e é bastante simples implementá-lo. Aqui, o autor deixa espaço para a criatividade do leitor, embora ele próprio pense nisso com interesse: você precisa entender usando dois genomas independentes e duas funções de condicionamento físico (dois algoritmos genéticos independentes simplificados) ou todos podem usar o mesmo gene e algoritmo.
E como inicializamos o NN com variáveis aleatórias, inicializamos o genoma. O processo inverso também é possível: inicialização do genótipo por variáveis aleatórias e sua posterior cópia em pesos neurais. A segunda opção é comum. Como o algoritmo genético no programa geralmente existe à parte da própria essência e é associado a ele apenas pelos dados do genoma e pelo valor da função de condicionamento físico ... Pare, pare, o leitor dirá que a imagem mostra claramente a população e não uma palavra sobre o genoma individual.
Ok, adicione algumas fotos ao forno da mente do leitor:
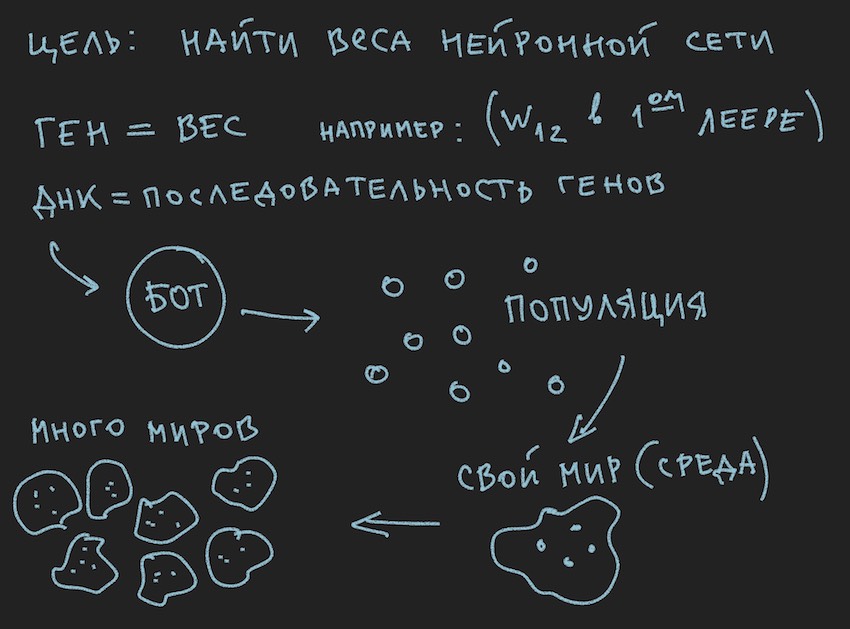
Como o autor pintou as figuras antes de escrever o texto do artigo, elas apóiam o texto, mas não seguem a letra da letra da história atual.
A partir das informações extraídas, conclui-se que o principal corpo de trabalho do algoritmo genético é uma população de genomas . Isso é um pouco contrário ao que o autor disse anteriormente, mas como no mundo real fazer sem pequenas contradições. Ontem, o sol girou em torno da Terra e hoje o autor fala sobre a rede neural dentro do bot de software. Não é à toa que ele se lembrou do forno da razão.
Confio no próprio leitor para resolver a questão das contradições do mundo. O mundo bot é completamente auto-suficiente para o artigo.
Mas o que o autor já conseguiu fazer, nesta parte do artigo, é formar uma população de bots.
Vamos dar uma olhada no lado do software:
Existe um bot (pode ser um objeto no OOP, uma estrutura, embora provavelmente seja também um objeto ou apenas uma matriz de dados). Por dentro, o Bot contém informações sobre suas coordenadas, velocidade, massa e outras informações úteis no processo do jogo, mas o principal para nós agora é que ele contém um link para seu genótipo ou o próprio genótipo, dependendo da implementação. Depois, você pode seguir de diferentes maneiras, limitar-se a matrizes de pesos de redes neurais ou introduzir uma variedade adicional de genótipos, pois será conveniente para o leitor imaginar isso em sua imaginação. Nas primeiras etapas, o autor do programa alocou matrizes de neurobalanças e genótipos. Então ele se recusou a duplicar informações e se limitou aos pesos da rede neural.
Seguindo a lógica da história, você precisa dizer que a população de bots é uma matriz dos bots acima. Que ciclo de jogo ... Pare novamente, que ciclo de jogo? os desenvolvedores educadamente forneceram um lugar para apenas um bot a bordo de um programa de simulação de mundo de jogo em um servidor ou no máximo quatro bots em um simulador local. E se você se lembra da topologia da rede neural escolhida pelo autor:
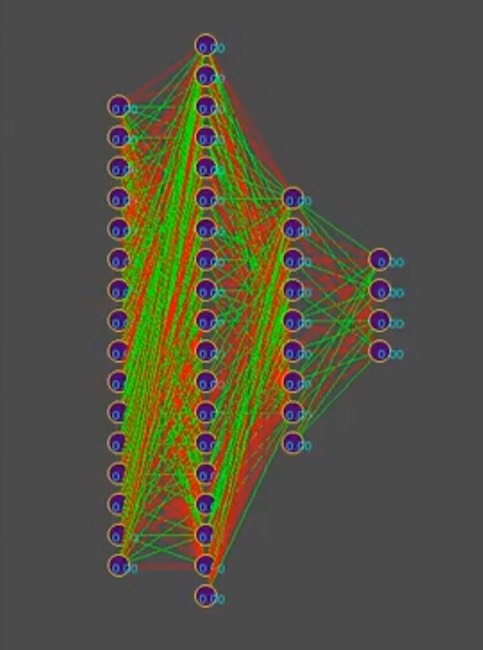
E para simplificar a história, suponha que o genótipo contenha aproximadamente 1000 conexões neurais, a propósito, no simulador, os genótipos se parecem com isso (vermelho é um valor genético negativo, verde é um valor positivo, cada linha é um genoma separado):

Nota para a foto: com o tempo, o padrão muda na direção da predominância de uma das soluções, as listras verticais são genes genotípicos comuns.
Portanto, temos 1000 genes no genótipo e um máximo de quatro bots no programa de simulador de mundo de jogo dos organizadores da competição. Quantas vezes você precisa executar uma simulação de uma batalha de bots para que pela força bruta, mesmo a mais inteligente, se aproxime em busca de "eficaz"
genótipo, leia a combinação "eficaz" de conexões neurais, desde que cada conexão neural varie de -1 a 1 em etapas, e qual etapa? inicialização foi aleatória float, é de 15 casas decimais. O passo ainda não está claro para nós. No número de variantes de combinações de pesos neurais, o autor assume que esse é um número infinito, ao escolher um determinado tamanho de etapa, provavelmente um número finito, mas, em qualquer caso, esses números são muito mais do que 4 lugares no simulador, mesmo considerando o lançamento sequencial da fila de bots e o lançamento paralelo simultâneo de simuladores oficiais, até 10 em um computador (para fãs de programação vintage: computadores).
Espero que as fotos ajudem o leitor.
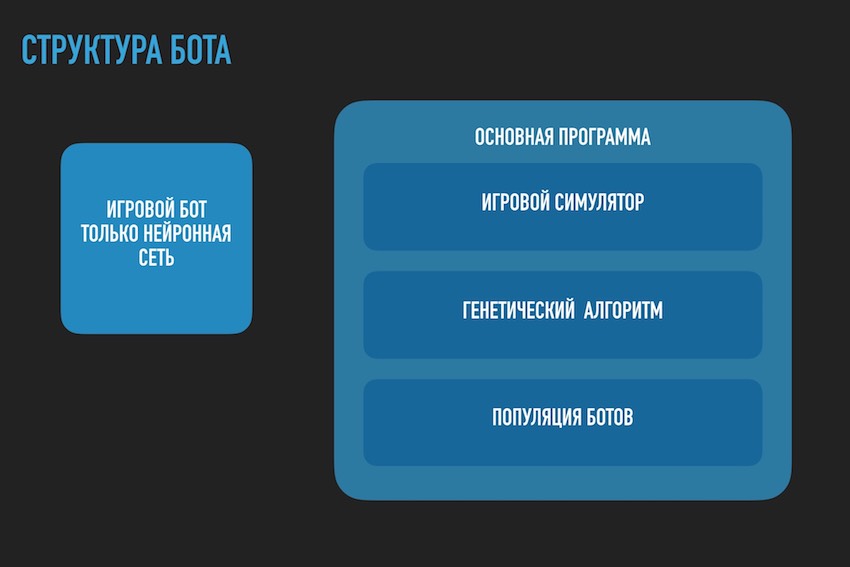
Aqui você precisa pausar e falar sobre a arquitetura da solução de software. Como a solução na forma de um bot de software separado, carregada no site da competição, não era mais adequada. Era necessário separar o bot playing de acordo com as regras da competição no âmbito do ecossistema de organizadores e o programa tentando encontrar a configuração da rede neural para ele. O diagrama a seguir é retirado da apresentação da conferência, mas geralmente reflete a imagem real.
Ele lembrou uma piada de barba:
Grande organização.
Horário 18:00, todos os funcionários trabalham como um. De repente, um dos funcionários desliga o computador, se veste e sai.
Todo mundo o segue com um olhar surpreso.
Dia que vem Às 18h00, o mesmo funcionário desliga o computador e sai. Todo mundo continua trabalhando e começa a sussurrar em desagrado.
No dia seguinte Às 18h00, o mesmo funcionário desliga o computador ...
Um colega se aproxima dele:
-Como você não tem vergonha, estamos trabalhando, no final do trimestre, tantos relatórios, também queremos chegar em casa na hora e você é um indivíduo ...
- Pessoal, eu geralmente estou de férias!
... para ser continuado.
Sim, quase esqueci de anexar o código do procedimento de cálculo da RNN, ele é válido e escrito de forma independente, portanto, talvez haja erros nele. Para amplificação, mostrarei como está, em c ++, conforme aplicado ao CUDA (uma biblioteca para cálculo na GPU).
Nota: matrizes multidimensionais não se dão bem em GPUs, é claro que existem texturas e cálculos de matriz, mas eles recomendam o uso de matrizes unidimensionais.
Um exemplo: uma matriz [i, j] da dimensão M por j se transforma em uma matriz da forma [i * M + j].
Código fonte do procedimento de cálculo RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }