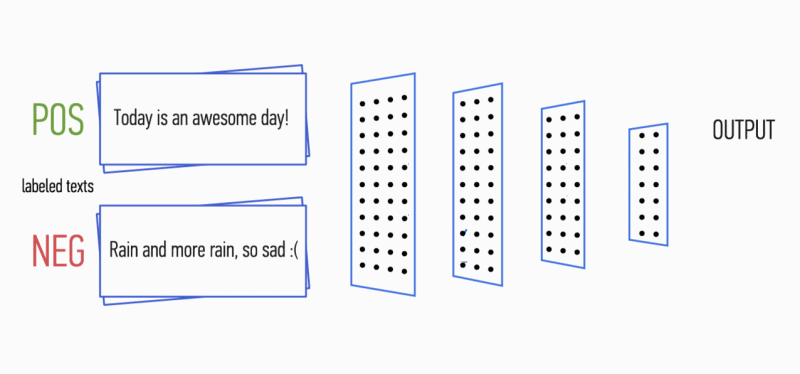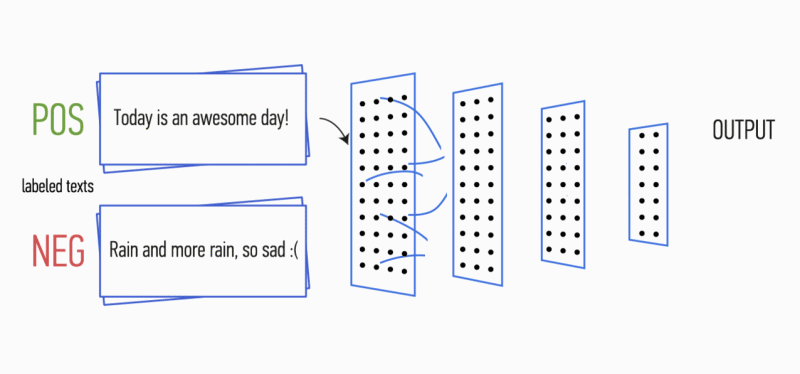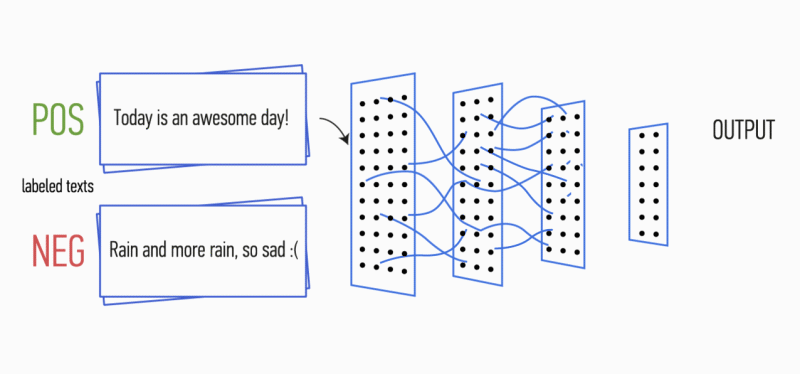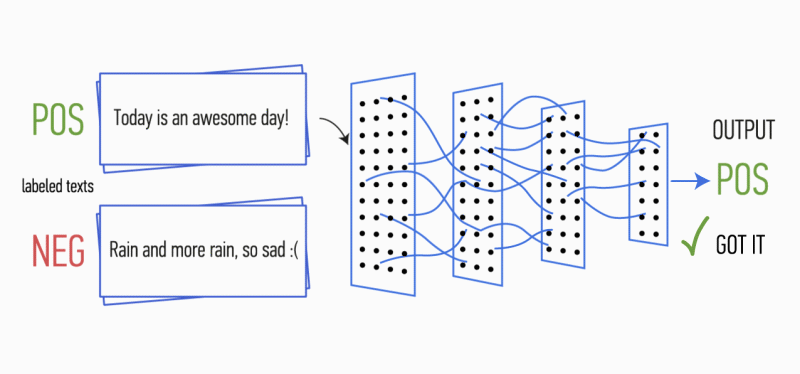
Imagine que você tem um parágrafo de texto. É possível entender que emoção esse texto carrega: alegria, tristeza, raiva? Você pode. Simplificamos nossa tarefa e classificamos a emoção como positiva ou negativa, sem especificação. Existem muitas maneiras de resolver esse problema, e uma delas são
as redes neurais convolucionais (Redes Neurais Convolucionais). A CNN foi desenvolvida originalmente para processamento de imagens, mas eles conseguem lidar com tarefas no campo do processamento automático de texto. Apresentarei uma análise binária da tonalidade de textos em russo usando uma rede neural convolucional, para a qual representações vetoriais de palavras foram formadas com base em um modelo treinado do
Word2Vec .
O artigo é de natureza geral, enfatizei o componente prático. Quero avisar imediatamente que as decisões tomadas em cada estágio podem não ser ideais. Antes de ler, recomendo que você se familiarize com o
artigo introdutório sobre o uso da CNN em tarefas de processamento de linguagem natural, bem como leia o
material sobre os métodos de representação vetorial de palavras.
Arquitetura
A arquitetura da CNN em consideração é baseada em abordagens [1] e [2]. Abordagem [1], que utiliza o conjunto de redes convolucionais e recorrentes, na maior competição anual em linguística de computadores O SemEval-2017 ficou em primeiro lugar [3] em cinco indicações na tarefa de análise da tonalidade
Tarefa 4 .
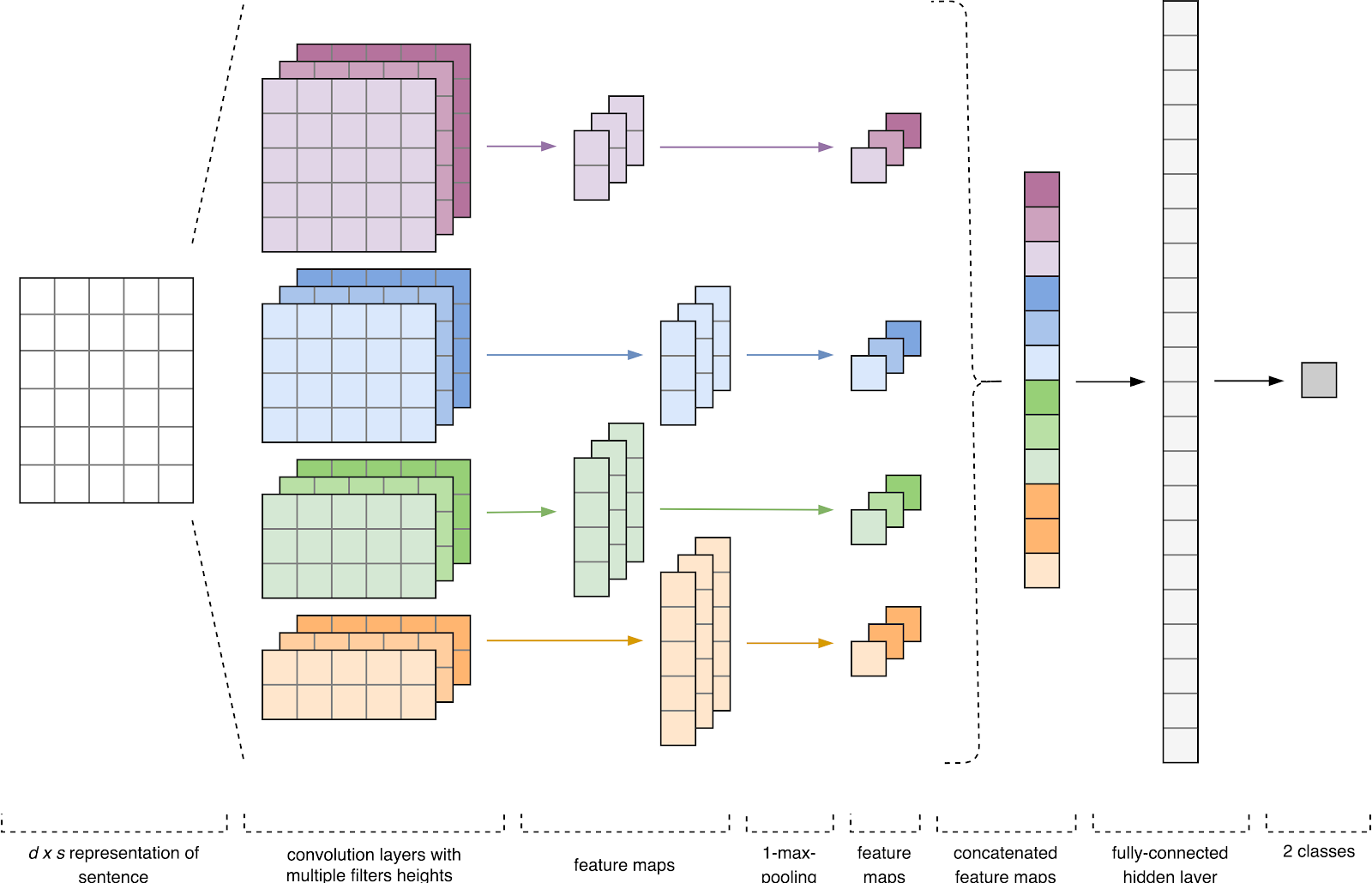 Figura 1. Arquitetura da CNN [2].
Figura 1. Arquitetura da CNN [2].A entrada CNN (Fig. 1) é uma matriz com uma altura fixa
n , em que cada linha é um mapeamento vetorial de um token para um espaço de recurso da dimensão
k . Ferramentas de semântica distributiva, como Word2Vec, Glove, FastText, etc. são frequentemente usadas para formar um espaço de recurso.
No primeiro estágio, a matriz de entrada é processada por camadas de convolução. Como regra, os filtros têm uma largura fixa igual à dimensão do espaço de atributo e apenas um parâmetro é configurado para tamanhos de filtro - altura
h . Acontece que
h é a altura das linhas adjacentes consideradas juntas pelo filtro. Consequentemente, a dimensão da matriz do recurso de saída para cada filtro varia dependendo da altura desse filtro
he da altura da matriz original
n .
Em seguida, o mapa de recursos obtido na saída de cada filtro é processado por uma camada de subamostragem com uma função de compactação específica (pool máximo de 1 na imagem), ou seja, reduz a dimensão do mapa de recursos gerado. Assim, as informações mais importantes são extraídas para cada convolução, independentemente de sua posição no texto. Em outras palavras, para a exibição vetorial usada, a combinação de camadas de convolução e subamostras permite extrair os
n gramas mais significativos do texto.
Depois disso, os mapas de características calculados na saída de cada camada de subamostragem são combinados em um vetor de característica comum. Ele é alimentado na entrada de uma camada oculta e totalmente conectada e, em seguida, alimentado na camada de saída da rede neural, onde são calculados os rótulos da classe final.
Dados de treinamento
Para o treinamento, escolhi o
corpus de textos curtos de Yulia Rubtsova , formados com base em mensagens em russo do Twitter [4]. Ele contém 114 991 tweets positivos e 111 923 negativos, além de uma base de tweets não alocados com um volume de 17 639 674 mensagens.
import pandas as pd import numpy as np
Antes do treinamento, os textos passaram pelo processamento preliminar:
- moldar para minúsculas;
- substituição de "e" por "e";
- Substituição de links para o token “URL”;
- substituição da menção do usuário pelo token USER;
- removendo sinais de pontuação.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
Em seguida, dividi o conjunto de dados em uma amostra de treinamento e teste em uma proporção de 4: 1.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Exibição de vetor de palavras
Os dados de entrada da rede neural convolucional são uma matriz com uma altura fixa
n , em que cada linha é um mapeamento vetorial de uma palavra para um espaço de característica da dimensão
k . Para formar a camada de incorporação de uma rede neural, usei o utilitário de semântica distributiva do Word2Vec [5], projetado para mapear o significado semântico das palavras no espaço vetorial. O Word2Vec localiza relacionamentos entre palavras, assumindo que palavras semanticamente relacionadas são encontradas em contextos semelhantes. Você pode ler mais sobre o Word2Vec no
artigo original , bem como
aqui e
aqui . Como os tweets são caracterizados por pontuação e emoticons de autores, definir os limites das frases se torna uma tarefa bastante demorada. Neste trabalho, assumi que cada tweet contém apenas uma frase.
A base de tweets não alocados é armazenada no formato SQL e contém mais de 17,5 milhões de registros. Por conveniência, converti-o para SQLite usando
este script.
import sqlite3
Em seguida, usando a biblioteca Gensim, treinei o modelo Word2Vec com os seguintes parâmetros:
- tamanho = 200 - dimensão do espaço de atributo;
- window = 5 - o número de palavras do contexto que o algoritmo analisa;
- min_count = 3 - a palavra deve ocorrer pelo menos três vezes para que o modelo a leve em consideração.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 Figura 2. Visualização de clusters de palavras semelhantes usando t-SNE.
Figura 2. Visualização de clusters de palavras semelhantes usando t-SNE.Para uma compreensão mais detalhada da operação do Word2Vec na Fig.
A Figura 2 mostra a visualização de vários clusters de palavras semelhantes do modelo treinado, mapeados no espaço bidimensional usando
o algoritmo de visualização t-SNE .
Exibição de vetor de textos
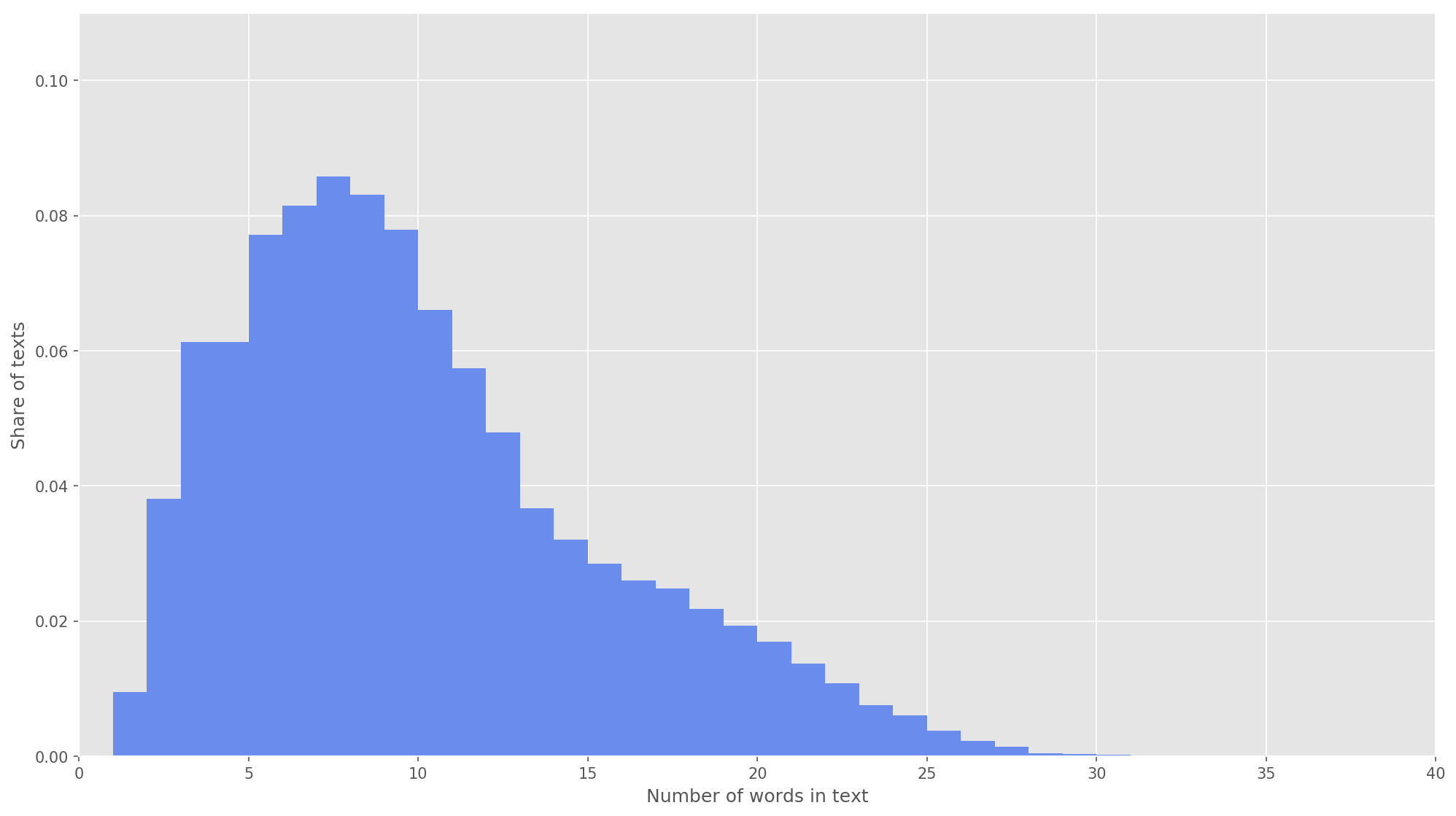 Fig 3. A distribuição do comprimento dos textos.
Fig 3. A distribuição do comprimento dos textos.Na próxima etapa, cada texto foi mapeado para uma matriz de identificadores de token. Escolhi a dimensão do vetor de texto
s = 26 , pois nesse valor 99,71% de todos os textos no corpo formado estão completamente cobertos (Fig. 3). Se durante a análise o número de palavras no tweet exceder a altura da matriz, as palavras restantes serão descartadas e não serão consideradas na classificação. A dimensão final da matriz da proposta foi
s × d = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
Rede Neural Convolucional
Para construir uma rede neural, usei a biblioteca Keras, que atua como um complemento de alto nível para TensorFlow, CNTK e Theano. Keras possui excelente documentação, além de um blog que cobre muitas tarefas de aprendizado de máquina, como a
inicialização da camada de incorporação . No nosso caso, a camada de incorporação foi iniciada pelos pesos obtidos com o aprendizado do Word2Vec. Para minimizar as alterações na camada de incorporação, congelei na primeira fase do treinamento.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
Na arquitetura desenvolvida, foram utilizados filtros com alturas
h = (2, 3, 4, 5) , projetados para o processamento paralelo de bigramas, trigramas, 4 e 5 gramas, respectivamente. Adicionadas 10 camadas convolucionais a cada rede neural para cada altura de filtro, a função de ativação é ReLU. As recomendações para encontrar a altura e o número ideais de filtros podem ser encontradas em [2].
Após o processamento por camadas de convolução, os mapas de atributos foram alimentados para as camadas de subamostragem, onde a operação 1-max-pooling foi aplicada a elas, extraindo assim os n-gramas mais significativos do texto. No estágio seguinte, eles se fundiram em um vetor de característica comum (camada de combinação), que era alimentado em uma camada totalmente conectada e oculta com 30 neurônios. No último estágio, o mapa final de características foi alimentado para a camada de saída da rede neural com uma função de ativação sigmoidal.
Como as redes neurais são propensas a reciclagem, após a camada de incorporação e antes da camada totalmente conectada oculta, adicionei uma regularização de abandono com a probabilidade de uma ejeção de vértices p = 0,2.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
Configurei o modelo final com a função de otimização de Adam (Adaptive Moment Estimation) e a entropia cruzada binária como uma função de erros. A qualidade do classificador foi avaliada em termos de precisão macro-média, completude e medidas f.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
Na primeira fase do treinamento, a camada de incorporação foi congelada, todas as outras camadas foram treinadas por 10 épocas:
- O tamanho do grupo de exemplos usados para o treinamento é 32.
- Tamanho da amostra de validação: 25%.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
LogsTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Em seguida, ele selecionou o modelo com as medidas F mais altas no conjunto de dados de validação, ou seja, modelo obtido na oitava época da educação (F
1 = 0,7791). O modelo descongelou a camada de incorporação, após o qual lançou mais cinco eras de treinamento.
from keras import optimizers
LogsTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
O maior indicador
F 1 = 76,80% na amostra de validação foi alcançado na terceira era do treinamento. A qualidade do modelo treinado nos dados do teste foi
F 1 = 78,1% .
Tabela 1. Qualidade da análise de sentimentos nos dados de teste.
Resultado
Como solução básica, eu
treinei um classificador Bayes ingênuo com um modelo de distribuição multinomial; os resultados da comparação são apresentados na tabela. 2)
Tabela 2. Comparação da qualidade da análise de tonalidade.
Como você pode ver, a qualidade da classificação da CNN excedeu o MNB em vários por cento. Os valores das métricas podem ser aumentados ainda mais se você trabalhar na otimização de hiperparâmetros e arquitetura de rede. Por exemplo, você pode alterar o número de eras de treinamento, verificar a eficácia do uso de várias representações vetoriais de palavras e suas combinações, selecionar o número de filtros e sua altura, implementar pré-processamento de texto mais eficaz (correção de erros de digitação, normalização, estampagem), ajustar o número de camadas e neurônios ocultos e totalmente conectados neles .
O código fonte
está disponível no Github , e os modelos CNN e Word2Vec treinados podem ser baixados
aqui .
Fontes
- Cliche M. BB_twtr no SemEval-2017 Tarefa 4: Análise de opinião do Twitter com CNNs e LSTMs // Anais do 11º Workshop Internacional de Avaliação Semântica (SemEval-2017). - 2017 .-- S. 573-580.
- Zhang Y., Wallace B. Uma análise de sensibilidade de (e guia dos profissionais) redes neurais convolucionais para classificação de sentenças // arXiv preprint arXiv: 1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. Tarefa 4 de SemEval-2017: Análise de sentimentos no Twitter // Anais do 11º Workshop Internacional de Avaliação Semântica (SemEval-2017). - 2017 .-- S. 502-518.
- Yu. V. Rubtsova. Construindo um corpo de textos para definir o classificador de tons // Software Products and Systems, 2015, No. 1 (109), —C.72-78.
- Mikolov T. et al. Representações distribuídas de palavras e frases e sua composicionalidade // Avanços nos sistemas de processamento de informações neurais. - 2013 .-- S. 3111-3119.