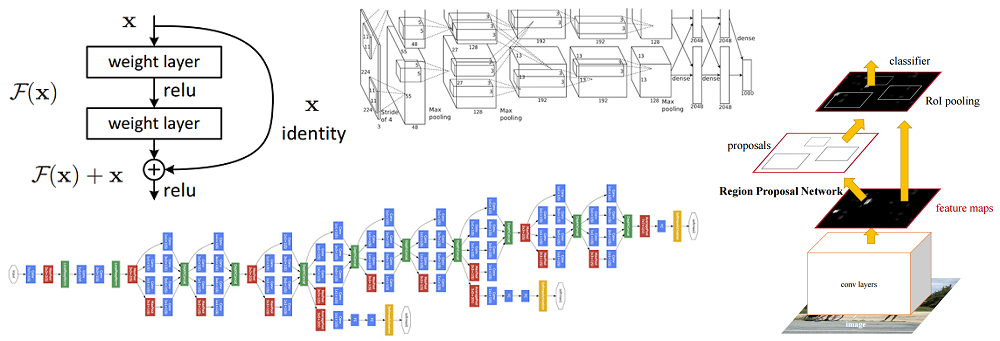
Em um artigo anterior,
Visão geral de redes neurais para classificação de imagens , nos familiarizamos com os conceitos básicos de redes neurais convolucionais, bem como com as idéias subjacentes. Neste artigo, examinaremos algumas arquiteturas de redes neurais profundas com grande poder de processamento - como AlexNet, ZFNet, VGG, GoogLeNet e ResNet - e resumiremos as principais vantagens de cada uma dessas arquiteturas. A estrutura do artigo é baseada em uma entrada de blog
Conceitos básicos de redes neurais convolucionais, parte 3 .
Atualmente, o
ImageNet Challenge é o principal incentivo subjacente ao desenvolvimento de sistemas de reconhecimento de máquinas e classificação de imagens. A campanha é uma competição para trabalhar com dados, na qual os participantes recebem um grande conjunto de dados (mais de um milhão de imagens). A tarefa da competição é desenvolver um algoritmo que permita classificar as imagens necessárias em objetos em 1000 categorias - como cães, gatos, carros e outros - com um número mínimo de erros.
De acordo com as regras oficiais do concurso, os algoritmos devem fornecer uma lista de não mais que cinco categorias de objetos em ordem decrescente de confiança para cada categoria de imagens. A qualidade da marcação da imagem é avaliada com base no rótulo que melhor corresponde à propriedade de verdade da imagem. A idéia é permitir que o algoritmo identifique vários objetos na imagem e não acumule pontos de penalidade no caso de algum dos objetos detectados estar realmente presente na imagem, mas não ter sido incluído na propriedade de verdade básica.
No primeiro ano da competição, os participantes receberam atributos de imagem pré-selecionados para treinar o modelo. Estes podem ser, por exemplo, sinais do algoritmo
SIFT processado usando quantização vetorial e adequado para uso no método de bolsa de palavras ou para apresentação como uma pirâmide espacial. No entanto, em 2012, houve um avanço real nessa área: um grupo de cientistas da Universidade de Toronto demonstrou que uma rede neural profunda pode obter resultados significativamente melhores em comparação com os modelos tradicionais de aprendizado de máquina construídos com base em vetores de propriedades de imagem selecionadas anteriormente. Nas seções a seguir, serão consideradas a primeira arquitetura inovadora proposta em 2012, bem como as arquiteturas que são seus seguidores até 2015.
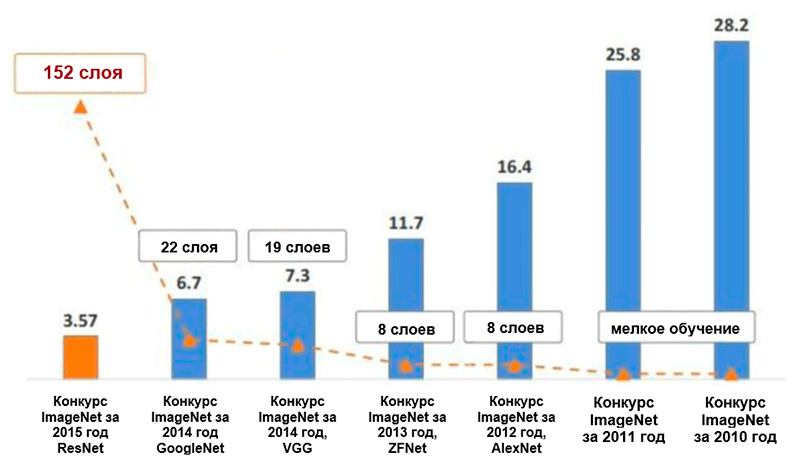 Diagrama de alterações no número de erros (em porcentagem) na classificação das imagens do ImageNet * para as cinco principais categorias. Imagem retirada da apresentação de Kaiming He, Deep Residual Learning for Image Recognition
Diagrama de alterações no número de erros (em porcentagem) na classificação das imagens do ImageNet * para as cinco principais categorias. Imagem retirada da apresentação de Kaiming He, Deep Residual Learning for Image RecognitionAlexnet
A arquitetura
AlexNet foi proposta em 2012 por um grupo de cientistas (A. Krizhevsky, I. Sutskever e J. Hinton) da Universidade de Toronto. Este foi um trabalho inovador no qual os autores usaram (na época) redes neurais convolucionais profundas com uma profundidade total de oito camadas (cinco convolucionais e três totalmente conectadas).
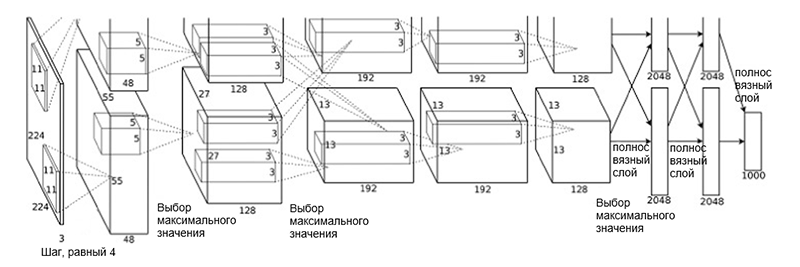 Arquitetura AlexNet
Arquitetura AlexNetA arquitetura de rede consiste nas seguintes camadas:
- [Camada de convolução + seleção de valor máximo + normalização] x 2
- [Camada de convolução] x 3
- [Escolhendo o valor máximo]
- [Camada completa] x 3
Esse esquema pode parecer um pouco estranho, porque o processo de aprendizado foi dividido entre as duas GPUs devido à sua alta complexidade computacional. Essa separação de trabalho entre GPUs requer separação manual do modelo em blocos verticais que interagem entre si.
A arquitetura do AlexNet reduziu o número de erros nas cinco principais categorias para 16,4% - quase metade em comparação com os desenvolvimentos avançados anteriores! Também dentro da estrutura dessa arquitetura foi introduzida uma função de ativação como uma unidade de retificação linear (
ReLU ), que atualmente é o padrão do setor. A seguir, é apresentado um breve resumo de outros recursos-chave da arquitetura AlexNet e seu processo de aprendizado:
- Aumento intensivo de dados
- Método de exclusão
- Otimização usando o momento SGD (consulte o guia de otimização “Visão geral dos algoritmos de otimização da descida do gradiente”)
- Ajuste manual da velocidade de aprendizado (redução desse coeficiente em 10 com estabilização da precisão)
- O modelo final é uma coleção de sete redes neurais convolucionais
- O treinamento foi realizado em dois processadores gráficos NVIDIA * GeForce GTX * 580 com um total de 3 GB de memória de vídeo em cada um deles.
Zfnet
A arquitetura de rede
ZFNet proposta pelos pesquisadores M. Zeiler e R. Fergus, da Universidade de Nova York, é quase idêntica à arquitetura AlexNet. As únicas diferenças significativas entre eles são as seguintes:
- Tamanho e etapa do filtro na primeira camada convolucional (no AlexNet, o tamanho do filtro é 11 × 11 e o passo é 4; no ZFNet - 7 × 7 e 2, respectivamente)
- O número de filtros em camadas convolucionais limpas (3, 4, 5).
 Arquitetura ZFNet
Arquitetura ZFNetGraças à arquitetura da ZFNet, o número de erros nas cinco principais categorias caiu para 11,4%. Talvez o principal papel disso seja o ajuste preciso dos hiperparâmetros (tamanho e número de filtros, tamanho do pacote, velocidade de aprendizado etc.). No entanto, também é provável que as idéias da arquitetura da ZFNet tenham se tornado uma contribuição muito significativa para o desenvolvimento de redes neurais convolucionais. Ziller e Fergus propuseram um sistema para visualizar núcleos, pesos e uma exibição oculta de imagens chamada DeconvNet. Graças a ela, tornou-se possível uma melhor compreensão e um maior desenvolvimento de redes neurais convolucionais.
VGG Net
Em 2014, K. Simonyan e E. Zisserman, da Universidade de Oxford, propuseram uma arquitetura chamada
VGG . A idéia principal e distinta dessa estrutura é
manter os filtros o mais simples possível . Portanto, todas as operações de convolução são executadas usando um filtro de tamanho 3 e uma etapa do tamanho 1, e todas as operações de subamostragem são executadas usando um filtro do tamanho 2 e uma etapa do tamanho 2. No entanto, isso não é tudo. Juntamente com a simplicidade dos módulos convolucionais, a rede cresceu significativamente em profundidade - agora possui 19 camadas! A idéia mais importante, proposta pela primeira vez neste trabalho, é
impor camadas convolucionais sem camadas de subamostragem . A ideia subjacente é que essa sobreposição ainda forneça um campo receptivo suficientemente grande (por exemplo, três camadas convolucionais sobrepostas de tamanho 3 × 3 nas etapas de 1 têm um campo receptivo semelhante a uma camada convolucional de 7 × 7), no entanto, o número de parâmetros é significativamente menor do que nas redes com filtros grandes (serve como regularizador). Além disso, torna-se possível introduzir transformações não lineares adicionais.
Essencialmente, os autores demonstraram que, mesmo com blocos de construção muito simples, você pode obter resultados de qualidade superior no concurso ImageNet. O número de erros para as cinco principais categorias foi reduzido para 7,3%.
 Arquitetura VGG. Observe que o número de filtros é inversamente proporcional ao tamanho espacial da imagem.
Arquitetura VGG. Observe que o número de filtros é inversamente proporcional ao tamanho espacial da imagem.GoogleNet
Anteriormente, todo o desenvolvimento da arquitetura era simplificar filtros e aumentar a profundidade da rede. Em 2014, C. Szegedy, juntamente com outros participantes, propôs uma abordagem completamente diferente e criou a arquitetura mais complexa da época, chamada GoogLeNet.
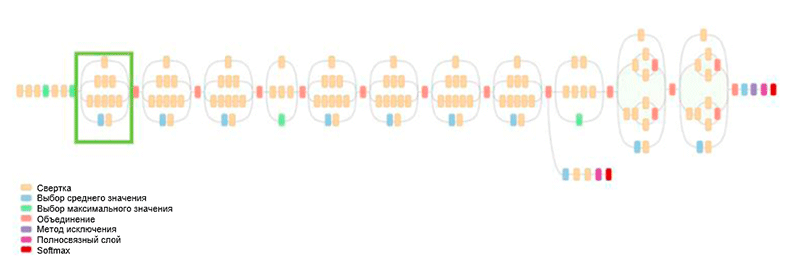 Arquitetura GoogLeNet. Ele usa o módulo Inception, destacado em verde na figura; construção de rede é baseada nesses módulos
Arquitetura GoogLeNet. Ele usa o módulo Inception, destacado em verde na figura; construção de rede é baseada nesses módulosUma das principais realizações deste trabalho é o chamado módulo de Iniciação, que é mostrado na figura abaixo. Redes de outras arquiteturas processam dados de entrada sequencialmente, camada por camada, enquanto usam o módulo Inception, os
dados de entrada são processados em paralelo . Isso permite acelerar a saída, bem como minimizar o
número total de parâmetros .
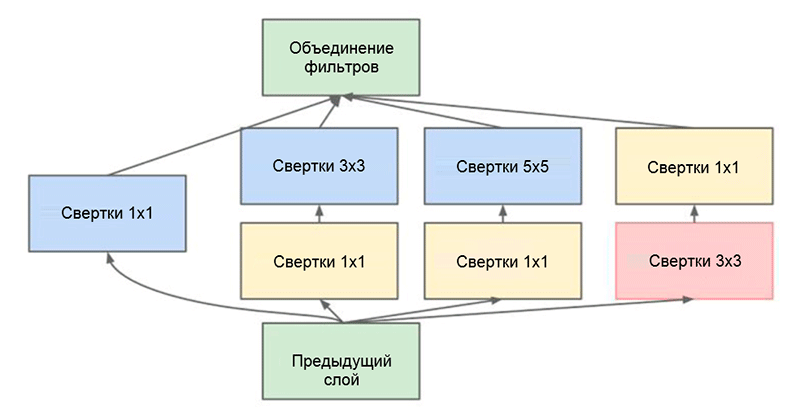 Módulo de iniciação. Observe que o módulo usa várias ramificações paralelas, que calculam propriedades diferentes com base nos mesmos dados de entrada e depois combinam os resultados
Módulo de iniciação. Observe que o módulo usa várias ramificações paralelas, que calculam propriedades diferentes com base nos mesmos dados de entrada e depois combinam os resultadosOutro truque interessante usado no módulo Inception é usar camadas convolucionais de tamanho 1 × 1. Isso pode parecer inútil até lembrarmos o fato de que o filtro cobre toda a dimensão da profundidade. Assim, uma convolução 1 × 1 é uma maneira simples de reduzir a dimensão de um mapa de propriedades. Este tipo de camadas convolucionais foi apresentado pela primeira vez em
Network por M. Lin et al., Uma explicação abrangente e compreensível também pode ser encontrada no blog
Convolution [1 × 1] - utilidade contrária à intuição de A. Prakash.
Por fim, essa arquitetura reduziu o número de erros para as cinco principais categorias em mais meio por cento - para um valor de 6,7 por cento.
Resnet
Em 2015, um grupo de pesquisadores (Cuming Hee e outros) da Microsoft Research Asia surgiu com uma idéia que atualmente é considerada pela maioria da comunidade como um dos estágios mais importantes no desenvolvimento da aprendizagem profunda.
Um dos principais problemas das redes neurais profundas é o problema de um gradiente de fuga. Em poucas palavras, esse é um problema técnico que surge ao usar o método de propagação de erro de retorno para o algoritmo de cálculo de gradiente. Ao trabalhar com propagação reversa de erros, uma regra de cadeia é usada. Além disso, se o gradiente tiver um valor pequeno no final da rede, ele poderá levar um valor infinitamente pequeno quando atingir o início da rede. Isso pode levar a problemas de natureza completamente diferente, incluindo a impossibilidade de aprender a rede em princípio (para obter mais informações, consulte a entrada do blog por R. Kapur
O problema de um gradiente desvanecido ).
Para resolver esse problema, Caiming Hee e seu grupo propuseram a seguinte idéia - permitir que a rede estudasse o mapeamento residual (um elemento que deveria ser adicionado à entrada) em vez da exibição em si. Tecnicamente, isso é feito usando a conexão de desvio mostrada na figura.
 Diagrama esquemático do bloco residual: os dados de entrada são transmitidos através de uma conexão reduzida, ignorando as camadas de conversão e adicionados ao resultado. Observe que uma conexão “idêntica” não adiciona parâmetros adicionais à rede, portanto sua estrutura não é complicada
Diagrama esquemático do bloco residual: os dados de entrada são transmitidos através de uma conexão reduzida, ignorando as camadas de conversão e adicionados ao resultado. Observe que uma conexão “idêntica” não adiciona parâmetros adicionais à rede, portanto sua estrutura não é complicadaEssa idéia é extremamente simples, mas ao mesmo tempo extremamente eficaz. Ele resolve o problema do gradiente que desaparece, permitindo que ele se mova sem nenhuma alteração das camadas superiores para as inferiores através de conexões "idênticas". Graças a essa idéia, você pode treinar redes muito profundas e extremamente profundas.
A rede que venceu o ImageNet Challenge em 2015 continha 152 camadas (os autores puderam treinar a rede que continha 1001 camadas, mas produziu aproximadamente o mesmo resultado, então pararam de trabalhar com ela). Além disso, essa idéia tornou possível reduzir o número de erros para as cinco principais categorias literalmente pela metade - para um valor de 3,6%. De acordo com um estudo do
que aprendi competindo com uma rede neural convolucional no concurso ImageNet de A. Karpathy, o desempenho humano para esta tarefa é de aproximadamente 5%. Isso significa que a arquitetura ResNet é capaz de superar os resultados humanos, pelo menos nesta tarefa de classificação de imagens.