Posso informar aos desenvolvedores front-end sobre a arquitetura sem servidor sem nuvem na AWS (Amazon Web Services) de uma maneira simples? Porque não Vamos renderizar o aplicativo AWS React / Redux e falar sobre os prós e contras das lambdas da AWS.
O material é baseado na transcrição do relatório de Marina Mironovich da nossa conferência HolyJS 2018 da primavera de 2018 em São Petersburgo.Oficialmente, Marina é uma desenvolvedora líder de EPAM. Agora ela trabalha em um grupo de arquitetos de soluções para um cliente e, por isso, participa de um grande número de projetos. Portanto, será mais fácil delinear o círculo de seus interesses atuais do que listar todas as tecnologias com as quais ela trabalha.
 Antes de tudo, estou interessado em todas as tecnologias em nuvem, em particular na AWS, porque trabalho muito com isso na produção. Mas tento acompanhar tudo o mais.
Antes de tudo, estou interessado em todas as tecnologias em nuvem, em particular na AWS, porque trabalho muito com isso na produção. Mas tento acompanhar tudo o mais.
O frontend é meu primeiro amor e parece para sempre. Em particular, atualmente estou trabalhando com o React e o React Native, por isso sei um pouco mais sobre isso. Eu também tento acompanhar tudo o mais. Estou interessado em tudo relacionado à documentação do projeto, por exemplo, diagramas UML. Como sou membro do grupo de arquitetos de soluções, tenho que fazer muito disso.
Parte 1. Antecedentes
A idéia de falar sobre o Serverless veio a mim há cerca de um ano. Eu queria falar sobre o Serverless para desenvolvedores de front-end de maneira fácil e natural. Para que você não precise de nenhum conhecimento adicional para usá-lo, mais tecnologias agora permitem isso.
Até certo ponto, a idéia foi concretizada -
falei sobre o Serverless no FrontTalks 2017. Porém, 45 minutos não são suficientes para uma história simples e compreensível. Portanto, o relatório foi dividido em duas partes, e agora antes de você é a segunda "série". Quem não viu o primeiro - não se preocupe, isso não fará mal para entender o que está escrito abaixo. Como em programas de TV decentes, começarei com um resumo da parte anterior. Depois, passarei ao próprio suco - renderizaremos o aplicativo React / Redux. E, finalmente, falarei sobre os prós e contras das funções da nuvem em princípio (em particular, a AWS lambdas) e o que mais pode ser feito com elas. Espero que esta parte seja útil para todos aqueles que já estão familiarizados com o AWS lambda. Mais importante ainda, o mundo não termina com a Amazon, então vamos falar sobre o que mais há no campo das funções da nuvem.
O que eu vou usar
Para renderizar o aplicativo, usarei muitos serviços da Amazon:
- S3 é um sistema de arquivos nas nuvens. Lá, armazenaremos ativos estáticos.
- IAM (direitos de acesso para usuários e serviços) - implicitamente, mas será usado em segundo plano para que os serviços se comuniquem.
- Gateway de API (URL para acessar o site) - você verá o URL onde podemos chamar nossa lambda.
- CloudFormation (para implantação) - será usado implicitamente em segundo plano.
- AWS Lambda - viemos aqui para isso.
O que é sem servidor e o que é o AWS Lambda?
Na verdade, sem servidor é uma grande fraude, porque é claro que existem servidores: em algum lugar, tudo começa. Mas o que está acontecendo lá?
Estamos escrevendo uma função, e essa função é executada nos servidores. Claro, começa não apenas assim, mas em algum tipo de recipiente. E, de fato, essa função no contêiner no servidor é chamada de lambda.
No caso do lambda, podemos esquecer os servidores. Eu diria até o seguinte: quando você escreve a função lambda, é prejudicial pensar nelas. Não trabalhamos com o lambda da mesma maneira que fazemos com um servidor.
Como implantar lambda
Surge uma questão lógica: se não temos um servidor, como o implantamos? Há SSH no servidor, nós carregamos o código, o lançamos - está tudo bem. O que fazer com lambda?
Opção 1. Não podemos implantá-lo.A AWS no console criou um IDE agradável e gentil para nós, onde podemos criar uma função ali mesmo.

É legal, mas não muito extensível.
Opção 2. Podemos fazer um zip e fazer o download na linha de comandoComo fazemos um arquivo zip?
zip -r build/lambda.zip index.js [node_modules/] [package.json]
Se você usar node_modules, tudo isso será compactado em um archive.
Além disso, dependendo de você estar criando uma nova função ou se já a possui, você pode
aws lambda create-function...
ou
aws lambda update-function-code...
Qual é o problema? Primeiro, a CLI da AWS deseja saber se uma função está sendo criada ou se você já tem uma. Estas são duas equipes diferentes. Se você deseja atualizar não apenas o código, mas também alguns atributos dessa função, os problemas começam. O número desses comandos está aumentando, e você precisa se sentar com um diretório e pensar em qual comando usar.
Podemos fazer isso melhor e mais fácil. Para isso, temos estruturas.
Estruturas do AWS Lambda
Existem muitas estruturas desse tipo. Isso é principalmente o AWS CloudFormation, que funciona em conjunto com a AWS CLI. CloudFormation é um arquivo Json que descreve seus serviços. Você os descreve em um arquivo Json e, em seguida, na CLI da AWS, diga "execute", e ele criará automaticamente tudo para você no serviço da AWS.
Mas ainda é difícil para uma tarefa tão simples como renderizar algo. Aqui o limite de entrada é muito grande - você precisa ler qual estrutura o CloudFormation possui, etc.
Vamos tentar simplificá-lo. E aqui aparecem várias estruturas: APEX, Zappa (apenas para Python), Claudia.js. Listei apenas alguns, aleatoriamente.
O problema e a força dessas estruturas é que elas são altamente especializadas. Então, eles são muito bons em fazer uma tarefa simples. Por exemplo, Claudia.js é muito bom para criar uma API REST. Ela fará o AWS ligar para o API Gateway, criará uma lambda para você, tudo ficará maravilhosamente bloqueado. Mas se você precisar implantar um pouco mais, os problemas começam - você precisa adicionar algo, ajuda, aparência etc.
Zappa foi escrito apenas para Python. E eu quero algo mais ambicioso. E aqui vem o Terraform e meu amor sem servidor.
Sem servidor está em algum lugar entre a CloudFormation muito grande, que pode fazer quase tudo, e essas estruturas altamente especializadas. Quase tudo pode ser implantado nele, mas fazer tudo ainda é bastante fácil. Ele também tem uma sintaxe muito leve.
Terraform é, em certa medida, um análogo do CloudFormation. O Terraform é de código aberto, nele você pode implantar tudo - bem, ou quase tudo. E quando a AWS cria os serviços, você pode adicionar algo novo lá. Mas é grande e complicado.
Para ser sincero, na produção usamos o Terraform, porque com o Terraform tudo o que temos é mais fácil - o Serverless não descreverá tudo isso. Mas o Terraform é muito complexo. E quando escrevo algo para o trabalho, primeiro o escrevo no Serverless, testo o desempenho e, somente depois que minha configuração é testada e elaborada, eu a reescrevo no Terraform (isso é "divertido" por mais alguns dias).
Sem servidor
Por que eu amo o Serverless?
- O Serverless possui um sistema que permite criar plugins. Na minha opinião, isso é uma salvação de tudo. Sem servidor - código aberto. Mas adicionar algo ao código aberto nem sempre é fácil. Você precisa entender o que está acontecendo no código existente, observar as diretrizes, pelo menos o estilo de código, enviar um PR, eles esquecerão esse PR e acumularão poeira por três anos. De acordo com os resultados, você bifurca-se, e isso será um lugar para você separadamente. Tudo isso não é muito saudável. Mas quando existem plugins, tudo é simplificado. Você precisa adicionar algo - você está ajoelhado criando seu próprio pequeno plugin. Para fazer isso, você não precisa mais entender o que está acontecendo no Serverless (se essa não for uma pergunta super personalizada). Você simplesmente usa a API disponível, em algum lugar salva o plug-in ou implementa-o para todos. E tudo funciona para você. Além disso, já existe um grande zoológico de plugins e pessoas que os escrevem. Ou seja, talvez algo já tenha sido decidido para você.
- Sem servidor ajuda a executar lambda localmente. O menos importante do lambda é que a AWS não pensou em como iremos depurá-lo e testá-lo. Mas o Serverless permite que você execute tudo localmente, veja o que acontece (ele até faz isso em conjunto com a API do Gateway).
Demonstração
Agora vou mostrar como tudo isso realmente funciona. Nos próximos um minuto e meio a dois minutos, poderemos criar um serviço que renderizará nossa página HTML.
Primeiro, em uma nova pasta, eu executo o modelo SLS Create:
mkdir sls-holyjs
cd sls-holyjs
sls create --template aws-nodejs-ecma-script

npm install

Os desenvolvedores sem servidor cuidaram de nós - tornou possível criar serviços a partir de modelos. Nesse caso, eu uso o modelo
nodejs-ecma-script , que criará alguns arquivos para mim, como a configuração do webpack, package.json, algumas funções e serverless.yml:
ls

Eu não preciso de todos os recursos. Vou remover o primeiro e o segundo renomear em holyjs:

Vou ajustar um pouco o serveless.yml, onde tenho uma descrição de todos os serviços necessários:
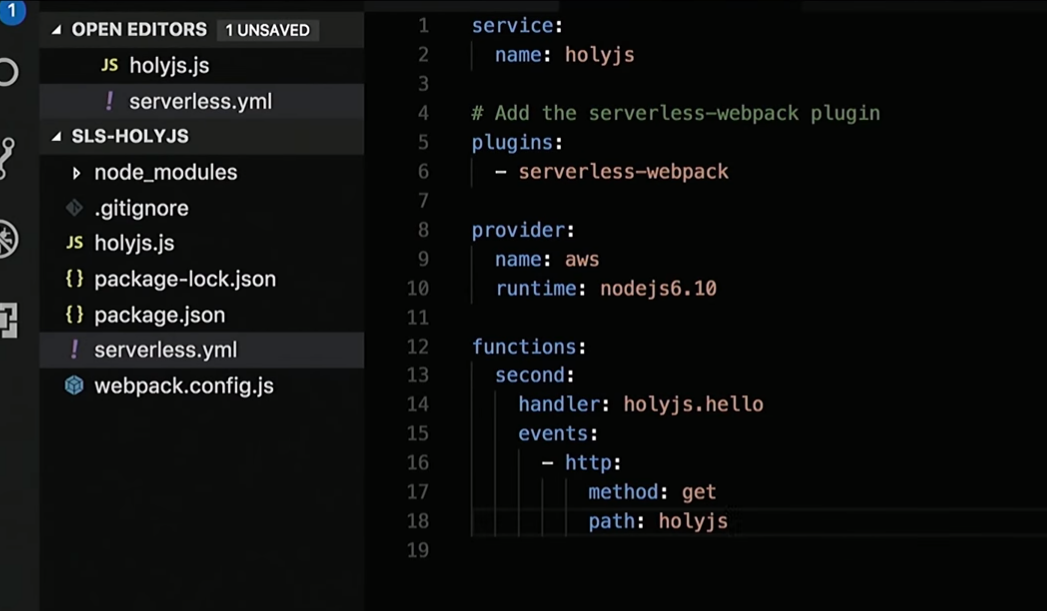
Bem, então vou corrigir a resposta que a função retorna:

Vou criar o HTML "Hello HolyJS" e adicionar identificador para renderização.
Seguinte:
sls deploy
E pronto! Existe uma URL onde eu posso ver em acesso público o que está sendo renderizado:

Confie, mas verifique. Vou ao Console da AWS e verifico se criei uma função holyjs:
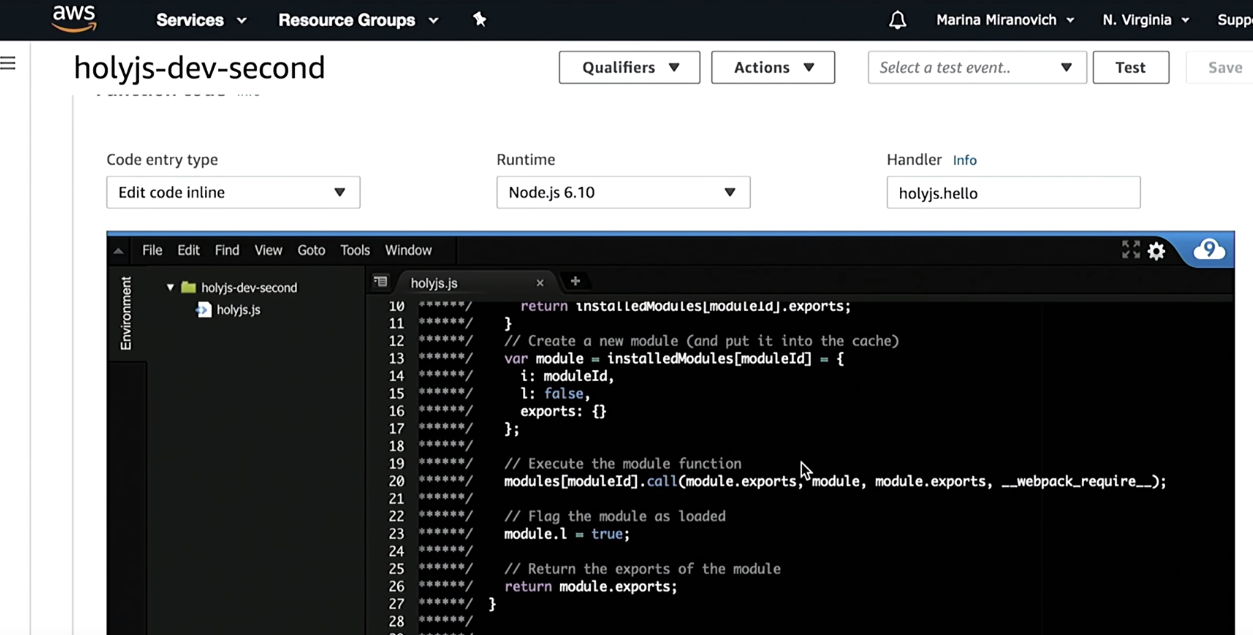
Como você pode ver, antes de implantá-lo, o Serverless o construirá usando o webpack. Além disso, o restante da infraestrutura descrita será criada - API Gateway, etc.
Quando eu quero remover isso:
sls remove
Toda a infraestrutura descrita em serverless.yml será excluída.

Se alguém está por trás do processo descrito aqui, convido você a revisar meu
relatório anterior .
Execute lambda localmente
Eu mencionei que o lambda pode ser executado localmente. Existem duas opções de inicialização aqui.
Opção 1. Acabamos de executar tudo no terminalNós obtemos o que nossa função retorna.
sls invoke local -f [fn_name]
Não se esqueça, estamos fazendo uma aplicação isomórfica, será HTML e CSS; portanto, no terminal, não é muito interessante observar longas linhas HTML. Lá você pode verificar se a função funciona. Mas eu gostaria de executar e renderizar isso no navegador. Portanto, preciso de um monte de gateway de API com lambda.
Para fazer isso, existe um plug-in offline sem servidor separado que iniciará o lambda em alguma porta (isto está escrito) e, em seguida, exibirá uma URL no terminal onde você pode acessá-lo.
sls offline --port 8000 start
A melhor parte é que há recarga a quente. Ou seja, você escreve o código da função, atualiza o navegador e atualiza o que a função retorna. Você não precisa reiniciar tudo.
Este foi um resumo da primeira parte do relatório. Agora vamos para a parte principal.
Parte 2. Renderizando com a AWS
O projeto descrito abaixo
já está no GitHub. Se você estiver interessado, pode fazer o download do código lá.
Vamos começar como tudo funciona.

Suponha que exista um usuário - eu.
- Eu abro o site.
- Em um determinado URL, acessamos a API do gateway. Quero observar que a API do Gateway já é um serviço da AWS, já estamos nas nuvens.
- A API do gateway chamará lambda.
- O lambda renderizará o site e tudo isso retornará ao navegador.
- O navegador começará a renderizar e perceberá que estão faltando alguns arquivos estáticos. Em seguida, ele passará para o bucket S3 (nosso sistema de arquivos, onde armazenaremos todas as estatísticas; no bucket S3, você poderá colocar tudo - fontes, imagens, CSS, JS).
- Os dados do bucket S3 retornarão ao navegador.
- O navegador renderizará a página.
- Todo mundo está feliz.
Vamos fazer uma pequena revisão de código do que escrevi.
Se você for ao GitHub, verá a seguinte estrutura de arquivos:
lambda-react
README.md
config
package.json
public
scripts
serverless.yml
src
yarn.lock
Tudo isso é gerado automaticamente no kit de ferramentas React / Redux. De fato, aqui estaremos interessados em apenas alguns arquivos e eles deverão ser levemente corrigidos:
- config
- package.json
- serverless.yml - porque iremos implantar,
- src - em nenhum lugar sem ele.
Vamos começar com a configuração
Para reunir tudo no servidor, precisamos adicionar outro webpack.config:

Este webpack.config já será gerado para você se você usar o modelo. E a variável
slsw.lib.entries é automaticamente substituída, o que apontará para seus manipuladores lambda. Se desejar, você mesmo pode alterá-lo especificando outra coisa.

Nós precisaremos renderizar tudo para o nó (
target: 'node' ). Em princípio, todos os outros carregadores permanecem os mesmos de uma aplicação React regular.
Além do package.json
Vamos apenas adicionar alguns scripts - o start e o build já foram gerados com o React / Redux - nada muda. Inclua um script para ativar o lambda e um script para implementar o lambda.

serverless.yml
Um arquivo muito pequeno - apenas 17 linhas, todas abaixo:

O que é interessante para nós nele? Primeiro de tudo, manipulador. O caminho completo para o arquivo é
src/lambda/handler (
src/lambda/handler ) e a função do manipulador é especificada através do ponto.
Se você realmente quiser, pode registrar vários manipuladores em um arquivo. Também aqui está o caminho para o webpack, que deve coletar tudo isso. Basicamente, tudo: o resto já é gerado automaticamente.
O mais interessante é src
Aqui está um enorme aplicativo React / Redux (no meu caso, não é enorme - para a página). Na pasta lambda adicional está tudo o que precisamos para renderizar a lambda:
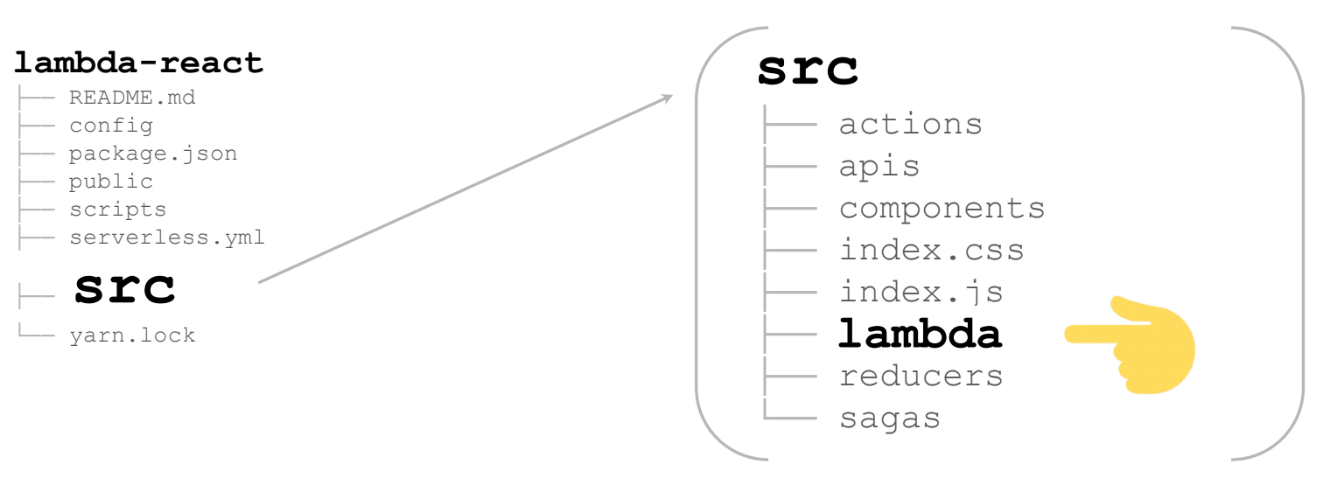
Estes são 2 arquivos:
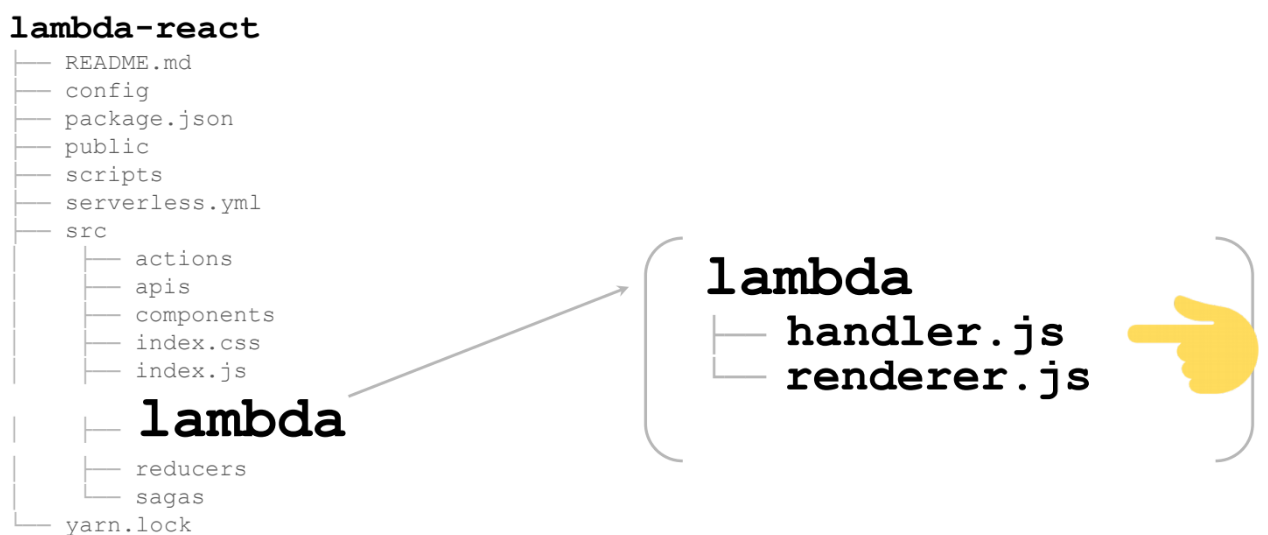
Vamos começar com o manipulador. O mais importante é a linha 13. Este é o renderizador, que é o próprio lambda que será chamado nas nuvens:

Como você pode ver, a função
render () retorna uma promessa, da qual todas as exceções devem ser capturadas. Essa é a peculiaridade do lambda, caso contrário, o lambda não terminará imediatamente, mas funcionará até o tempo limite. Você terá que pagar dinheiro extra por um código que já caiu. Para impedir que isso aconteça, você precisa finalizar o lambda o mais cedo possível - primeiro, capture e lide com todas as exceções. Mais tarde, voltaremos a isso.
Se não tivermos erros ou exceções, chamamos a função
createResponse , que leva literalmente cinco linhas. Apenas adicionamos todos os cabeçalhos para que sejam renderizados corretamente no navegador:

O mais interessante aqui é a função de
render , que renderizará nossa página:

Essa função chega até nós a partir do renderer.js. Vamos ver o que há lá.
Um aplicativo isomórfico é renderizado lá. Além disso, é renderizado em qualquer servidor - não importa se é lambda ou não.
Não vou falar em detalhes sobre o que é uma aplicação isomórfica, como renderizá-la, porque esse é um tópico completamente diferente, e há pessoas que disseram isso melhor do que eu. Aqui estão alguns tutoriais que encontrei pesquisando no Google em apenas alguns minutos:

Se você conhece outros relatórios, pode aconselhar, darei links para eles no meu Twitter.
Para não perder ninguém, eu só subo, digo o que está acontecendo lá.
Primeiro de tudo, precisamos renderizar isso com HTML / React / Redux.
Isso é feito através do método React padrão -
renderToString :

Em seguida, precisamos renderizar estilos para que nosso conteúdo não pisque. Esta não é uma tarefa muito trivial. Existem vários pacotes npm que o resolvem. Por exemplo, usei o
node-style-loader , que reunirá tudo em
styleTag e, em seguida, você poderá colá-lo no HTML.

Se houver pacotes melhores - é a seu critério.
Em seguida, precisamos passar o estado Redux. Como você está renderizando no servidor, provavelmente deseja obter alguns dados e não deseja que o Redux solicite novamente e os renderize novamente. Esta é uma tarefa bastante padrão. Existem exemplos no site principal do Redux sobre como fazer isso: criamos um objeto e depois passamos por uma variável global:

Agora um pouco mais perto da lambda.
É necessário fazer o tratamento de erros. Queremos pegar tudo e fazer algo com eles, pelo menos interromper o desenvolvimento do lambda. Por exemplo, eu fiz isso por
promise :

Em seguida, precisamos substituir nossos URLs por arquivos estáticos. E, para isso, precisamos descobrir onde o lambda é executado - localmente ou em algum lugar nas nuvens. Como descobrir?
Faremos isso através de variáveis de ambiente:
…
const bundleUrl = process.env.NODE_ENV === 'AWS' ?
AWS_URL : LOCAL_URL;
Uma pergunta interessante: como as variáveis de ambiente se reúnem em uma lambda. Na verdade, fácil o suficiente. No yml, você pode passar quaisquer variáveis para o
environment . Quando estiver bloqueado, eles estarão disponíveis:

Bem, um bônus - depois de implantarmos um lambda, queremos implantar todos os ativos estáticos. Para fazer isso, já escrevemos um plug-in no qual você pode designar a cesta S3 na qual deseja implantar algo:

No total, fizemos uma aplicação isomórfica em cerca de cinco minutos para mostrar que tudo é fácil.
Agora vamos falar um pouco sobre teoria - os prós e contras do lambda.
Vamos começar com o mal.
Contras funções lambda
As desvantagens podem incluir (ou talvez não) o tempo de partida a frio. Por exemplo, para o lambda no Node.js que estamos escrevendo agora, o horário de início frio não significa muito.
O gráfico abaixo mostra o horário de início a frio. E isso pode ser um grande problema, especialmente para Java e C # (preste atenção aos pontos laranja) - você não precisa de apenas cinco a seis segundos para começar a executar o código.
Para o Node.js, o horário de início é quase zero - 30 - 50 ms. Obviamente, para alguns, isso também pode ser um problema. Mas as funções podem ser aquecidas (embora este não seja o tópico deste relatório). Se alguém estiver interessado em como esses testes foram realizados, seja bem-vindo ao acloud.guru, eles lhe dirão tudo (
no artigo ).

Então, quais são as desvantagens?
Limitações de tamanho do código de função
O código deve ter menos de 50 MB. É possível escrever uma função tão grande? Por favor, não esqueça de node_modules. Se você conectar algo, especialmente se houver arquivos binários, poderá facilmente ultrapassar 50 MB, mesmo para arquivos zip. Eu tive esses casos. Mas esse é um motivo adicional para ver o que você está conectando ao node_modules.
Limitações de tempo de execução
Por padrão, a função é executada por um segundo. Se não terminar após um segundo, você terá um tempo limite. Mas esse tempo pode ser aumentado nas configurações. Ao criar uma função, você pode definir o valor para cinco minutos. Cinco minutos é um prazo difícil. Isso não é um problema para o site. Mas se você quiser fazer algo mais interessante em lambdas, por exemplo, processamento de imagens, conversão de texto em som ou som em texto, etc., esses cálculos podem facilmente levar mais de cinco minutos. E isso será um problema. O que fazer sobre isso? Otimize ou não use lambda.
Outra coisa interessante que surge em conexão com o limite de tempo para a execução de lambda. Lembre-se do layout do nosso site. Tudo funcionou perfeitamente até o produto chegar e desejar no feed em tempo real do site - mostrar notícias em tempo real. Sabemos que isso é implementado com WebSockets. Mas os WebSockets não funcionam por cinco minutos, eles precisam ser mantidos por mais tempo. E aqui o limite de cinco minutos se torna um problema.

Uma pequena observação. Para a AWS, isso não é mais um problema. Eles descobriram como contornar isso. Mas falando de maneira geral, assim que os soquetes da Web aparecerem, o lambda não é uma solução para você. Você precisa mudar para os bons servidores antigos novamente.
O número de funções paralelas por minuto
Acima, há um limite de 500 a 3.000, dependendo da região onde você está. Na minha opinião, na Europa, quase 500. 3000 são suportados nos EUA.
Se você tem um site ocupado e espera mais de três mil solicitações por minuto (o que é fácil de imaginar), isso se torna um problema. Mas antes de falarmos sobre isso, vamos falar um pouco sobre como o lambda é escalado.
Um pedido chega até nós e recebemos uma lambda. Enquanto esse lambda está sendo executado, mais duas solicitações chegam até nós - iniciamos mais duas lambdas. As pessoas começam a vir ao nosso site, os pedidos aparecem e as lambdas são lançadas, cada vez mais.

Ao fazer isso, você paga pelo tempo em que o lambda está em execução. Suponha que você pague um centavo por um segundo de execução lambda. Se você tiver 10 lambdas por segundo, pagará 10 centavos por esse segundo. Se você tem um milhão de lambdas em execução por segundo, são cerca de 10 mil dólares. Figura desagradável.
Portanto, a AWS decidiu que eles não desejam esvaziar sua carteira em um segundo se você fez seus testes incorretamente e você mesmo iniciou o DDOS, causando lambdas ou outra pessoa veio fazer o DDOS. Portanto, um limite de três mil foi estabelecido - para que você tenha a oportunidade de responder à situação.
Se o carregamento de 3000 solicitações for regular para você, você poderá escrever na AWS e elas aumentarão o limite.
Sem Estado
Este é o último, novamente, um menos polêmico.
O que é apátrida? Aqui surge uma piada sobre peixinho - eles simplesmente não sustentam o contexto:

O lambda, chamado pela segunda vez, não sabe nada sobre a primeira chamada.
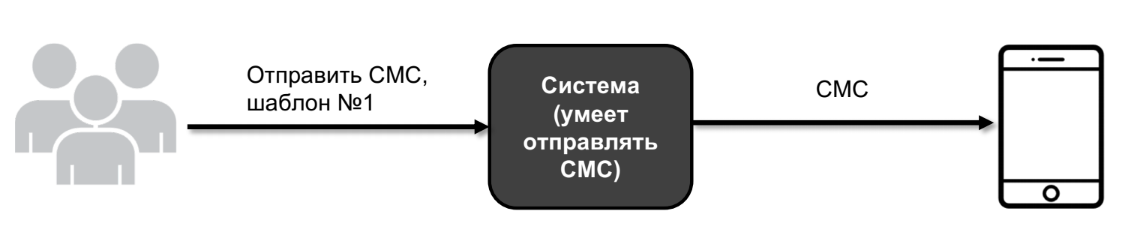
Deixe-me mostrar um exemplo. Digamos que eu tenho um sistema - uma grande caixa preta. E esse sistema, entre outras coisas, pode enviar SMS.
O usuário chega e diz: envie o número do modelo SMS 1. E o sistema envia para um dispositivo real.
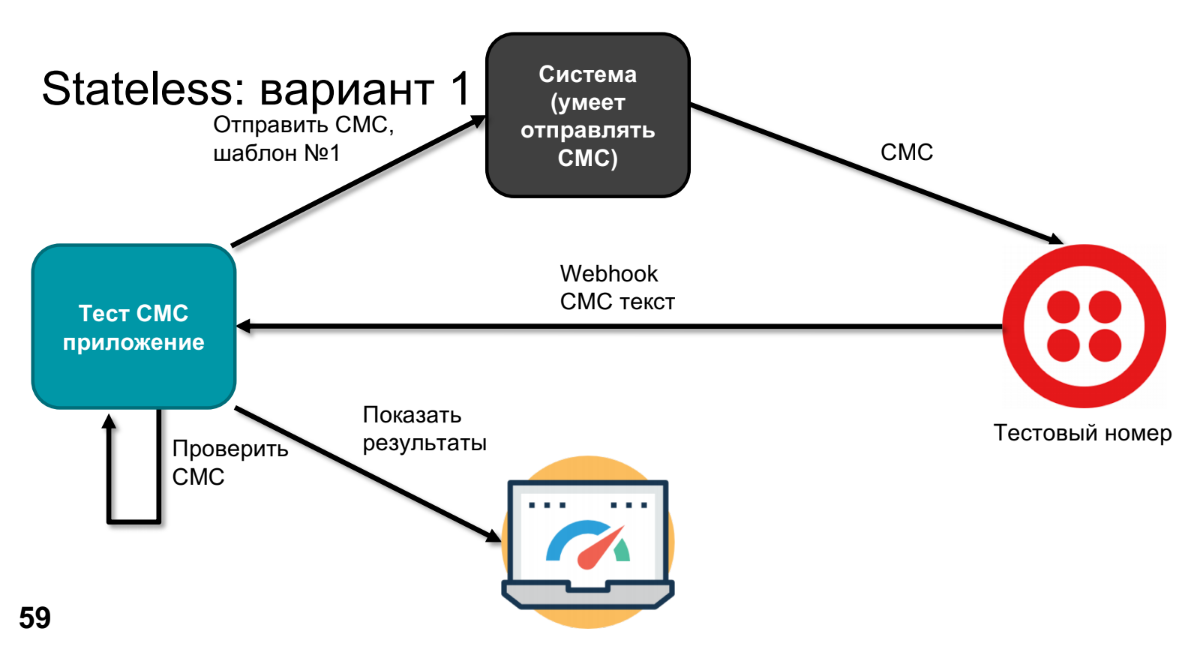
Em algum momento, o produto expressa o desejo de descobrir o que vai acontecer lá e de verificar se nada quebrou neste sistema em nenhum lugar. Para fazer isso, substituiremos o dispositivo real por algum tipo de número de teste - por exemplo, o Twilio pode fazer isso. Ele ligará para o Webhook, enviará o texto SMS, processaremos esse texto SMS no aplicativo (precisamos verificar se nosso modelo se tornou o SMS correto).
Para verificar, precisamos saber o que foi enviado - faremos isso através de um aplicativo de teste. Resta comparar e exibir os resultados.
Vamos tentar fazer o mesmo no lambda.
O Lambda enviará SMS, o SMS chegará ao Twilio.
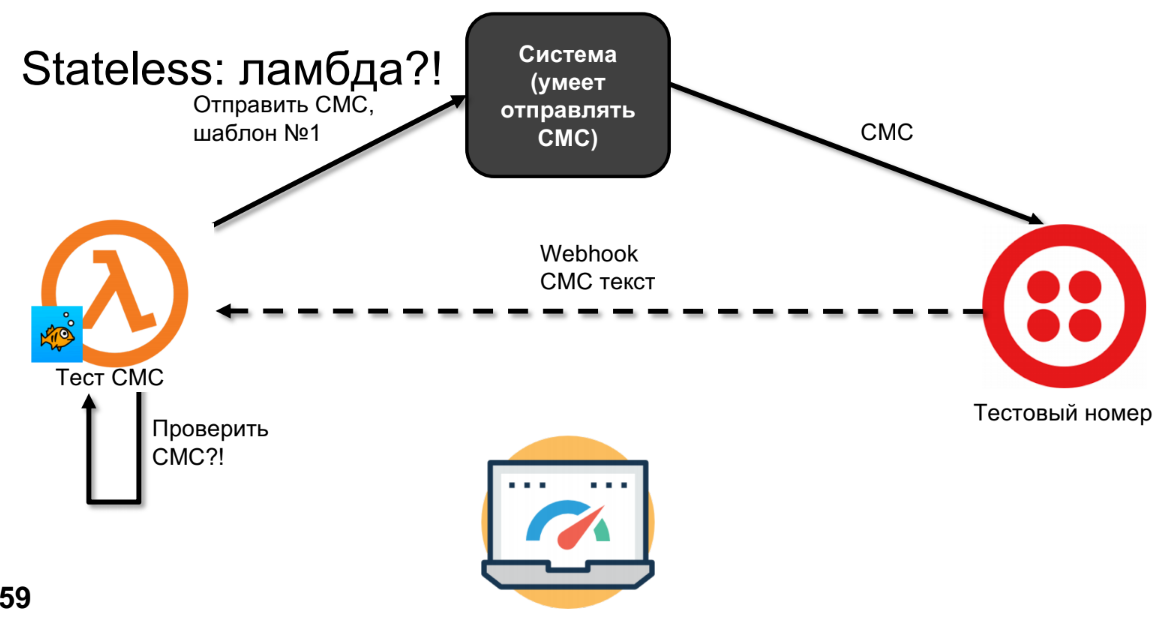
Eu desenhei a linha tracejada não por acidente, porque o SMS pode voltar em minutos, horas ou dias - depende da sua operadora, ou seja, não é uma chamada síncrona. A essa altura, o lambda esquecerá tudo e não poderemos verificar o SMS.
Eu diria que isso não é um sinal de menos, mas um recurso. O esquema pode ser refeito. Existem várias opções para fazer isso, vou oferecer o meu. Se tivermos apátrida e quisermos salvar alguma coisa, definitivamente precisamos usar o armazenamento, por exemplo, um banco de dados, S3, mas qualquer coisa que armazene nosso contexto.
No esquema com o armazenamento do SMS, ele será enviado para o número do teste. E quando o Webhook chama - sugiro chamar, por exemplo, o segundo lambda, porque essa é uma função ligeiramente diferente. E o segundo lambda já poderá acessar o SMS-ku que foi do banco de dados, verificá-lo e exibir os resultados.

Bingo!
No começo, eu disse que você precisa esquecer os servidores se escrever lambda. Eu conheci pessoas que escrevem no node.js e são usadas para expressar servidores. Eles gostam de confiar no cache, e o cache permanece em lambdas. E às vezes, quando testam, funciona, e às vezes não. Como isso é possível?Suponha que tenhamos um servidor e um contêiner comece nele. Lançar um contêiner é uma operação bastante cara. Primeiro, você precisa fazer esse contêiner. Somente depois de criado, o código da função é implantado lá e pode ser executado. Depois que sua função é executada, o contêiner não é morto, porque a AWS acredita que você pode chamar essa função novamente. A AWS nunca escreveu por quanto tempo o contêiner permanece após a função ser interrompida. Nós fizemos experimentos. Na minha opinião, para o nó são três minutos, para Java eles podem reter um contêiner por 12 a 15 minutos. Mas isso significa que, quando a próxima função for chamada, ela será chamada no mesmo contêiner e no mesmo ambiente. Se você usar o cache do nó em algum lugar, criará variáveis etc. - se você não os limpou, eles permanecerão lá. Então, se você escreve em lambda,então você precisa esquecer o cache em geral, caso contrário, poderá entrar em situações desagradáveis. Isso é difícil de desviar.Vantagens das funções lambda
Há menos deles, mas para mim eles parecem mais agradáveis.- Primeiro de tudo, realmente esquecemos que existe um servidor. Como desenvolvedor, escrevo uma função em javascript, e é isso. Estou certo de que muitos de vocês escreveram funções em javascript, não precisam saber mais nada sobre isso.
- Não há necessidade de pensar no cache, nem na escala, vertical ou horizontal. O que você escreveu vai funcionar. Não importa se uma pessoa acessa seu site por mês ou se há um milhão de visitas.
- No caso da AWS lambdas, eles já têm sua própria integração com quase todos os servidores (DynamoDB, Alexa, API Gateway, etc.).
O que mais pode ser feito em lambdas?
Dei um exemplo bastante padrão - falei sobre renderizar um aplicativo isomórfico, porque basicamente eles pensam em lambdas como uma API REST. Mas quero dar mais alguns exemplos do que pode ser feito com eles, apenas para fornecer alimento para o pensamento e a imaginação.Em princípio, nas lambdas você pode fazer qualquer coisa ... com um asterisco.- Serviços HTTP é o que eu estava falando. API REST, cada API de terminal é uma lambda. Combina perfeitamente. Especialmente considerando como a empresa costuma usar o node.js para criar middleware. Temos o java que custa todo o custo, depois escrevemos uma camada no js que lida com solicitações com muita facilidade. Pode ser reescrito em lambdas e será ainda mais legal.
- IoT — , Alexa - -, , .
- Chat Bots — , IoT.
- Image/Video conversions.
- Machine learning.
- Batch Jobs — - , Batch Job .
Agora, além da Amazon, Google, Azure, IBM, Twillio, quase todos os grandes serviços desejam implementar funções de nuvem em casa. Se Roskomnadzor bloqueia tudo, iniciamos um pequeno servidor favorito em nossa garagem e implantamos nossa computação em nuvem lá. Para fazer isso, precisamos de código aberto (tanto mais porque você precisa pagar por serviços, e o código aberto é gratuito). E o código aberto não fica parado. Eles já fizeram uma quantidade irreal de implementações de tudo isso. Agora vou dizer palavras assustadoras para os frontends - Docker Swarm, Kubernetes - tudo funciona dessa maneira.A melhor parte é que, em primeiro lugar, as funções da nuvem permanecem tão simples quanto. Se você tinha funções na AWS ou lambdas, traduzi-las para código aberto também é fácil.Nem todos os desenvolvimentos estão listados abaixo. Acabei de escolher uma maior e mais interessante. A lista completa é enorme: muitas startups estão começando a trabalhar neste tópico agora:- Funções de ferro
- Fnproject
- Openfaas
- Apache OpenWhisk
- Kubeless
- Fissão
- Funktion
Tentei o Fnproject e passei apenas algumas horas para transferir esse aplicativo isomórfico para o Fnproject e executá-lo localmente com um contêiner do Kubernetes.Ainda é rapidamente escalável. Você terá várias APIs de gateway (é claro, sem o restante dos serviços), mas ainda terá um URL que chama lambda. De fato, quase todo mundo pode esquecer os servidores, como prometido, exceto uma pessoa que implementará essa estrutura e configurará essa orquestração do Kubernetes para que desenvolvedores felizes possam usá-lo mais tarde.. HolyJS 2018 Moscow, 24-25 . , Early Bird-.