
Nova linguagem em ciência de dados. Julia é uma língua bastante rara na Rússia, embora tenha sido usada no exterior por 5 anos (eles me surpreenderam também). Como não há fontes em russo, decidi defender Julia, tirada de um livro maravilhoso. A melhor maneira de aprender um idioma é começar a escrever algo nele.
E para isso também atrair atenção, use o aprendizado de máquina.Olá habrozhitelam.
Há algum tempo, comecei a aprender o novo idioma de Julia. Bem, como novo. Isso é algo entre o Matlab e o Python, a sintaxe é muito semelhante e a própria linguagem é escrita em C / C ++. Em geral, a história da criação, o que, por que e por que está na Wikipedia e em alguns artigos sobre Habré.
A primeira coisa que começou meu estudo do idioma - certo, o
curso on-line do Google no Coursera google em inglês. Lá, sobre a sintaxe básica +, um mini-projeto sobre a previsão de doenças na África é escrito em paralelo. Noções básicas e prática imediatamente. Se você precisar de um certificado, compre a versão completa. Eu fui de graça. A diferença entre esta versão é que ninguém irá verificar seus testes e DZ. Era mais importante para mim conhecer do que um certificado. (Leia atolado 50 dólares)
Depois disso, decidi que deveria ler um livro sobre Julia. O Google publicou uma lista de livros e estudou mais críticas e críticas, escolheu uma delas e encomendou na Amazon. Versões de livros são sempre melhores para ler e desenhar a lápis.
O livro é chamado
Julia for Data Science por Zacharias Voulgaris, PhD. O trecho que quero apresentar contém muitos erros de digitação no código que corrigi e, portanto, apresentará a versão de trabalho + meus resultados.
kNN
Este é um exemplo da aplicação do algoritmo de classificação para o método dos vizinhos mais próximos. Provavelmente um dos algoritmos de aprendizado de máquina mais antigos. O algoritmo não possui uma fase de aprendizado e é bastante rápido. Seu significado é bastante simples: para classificar um novo objeto, você precisa encontrar "vizinhos" semelhantes no conjunto de dados (banco de dados) e depois determinar a classe votando.
Farei uma reserva imediata de que Julia possui pacotes prontos, e é melhor usá-los para reduzir o tempo e reduzir os erros. Mas esse código é, de certa forma, indicativo da sintaxe de Julia. É mais conveniente aprender um novo idioma por exemplos do que lendo extratos secos da forma geral de uma função.
Então, o que temos na entrada:
Dados de treinamento X (amostra de treinamento),
rótulos de dados de treinamento x (rótulos correspondentes),
dados de teste Y (seleção de teste),
número de vizinhos k (número de vizinhos).
Você precisará de 3 funções:
função de cálculo de distância, função de classificação e
principal .
A linha inferior é: pegue um elemento da matriz de teste, calcule a distância dela até os elementos da matriz de treinamento. Em seguida, selecionamos os índices desses
k elementos que se mostraram o mais próximo possível. Atribuímos o elemento em teste à classe que é a mais comum entre os
k vizinhos mais próximos.
function CalculateDistance{T<:Number}(x::Array{T,1}, y::Array{T,1}) dist = 0 for i in 1:length(x) dist += (x[i] - y[i])^2 end dist = sqrt(dist) return dist end
A principal função do algoritmo. A matriz de distâncias entre os objetos das amostras de treinamento e teste, os rótulos do conjunto de treinamento e o número de "vizinhos" mais próximos chegam à entrada. A saída são os rótulos previstos para novos objetos e as probabilidades de cada rótulo.
function Classify{T<:Any}(distances::Array{Float64,1}, labels::Array{T,1}, k::Int) class = unique(labels) nc = length(class) #number of classes indexes = Array(Int,k) #initialize vector of indexes of the nearest neighbors M = typemax(typeof(distances[1])) #the largest possible number that this vector can have class_count = zeros(Int, nc) for i in 1:k indexes[i] = indmin(distances) #returns index of the minimum element in a collection distances[indexes[i]] = M #make sure this element is not selected again end klabels = labels[indexes] for i in 1:nc for j in 1:k if klabels[j] == class[i] class_count[i] +=1 end end end m, index = findmax(class_count) conf = m/k #confidence of prediction return class[index], conf end
E, claro, todas as funções.
Teremos um conjunto de treinamento
X na entrada, marcas de conjunto de treinamento
x , conjunto de teste
Y e o número de "vizinhos"
k .
Na saída, receberemos os rótulos previstos e as probabilidades correspondentes de cada prêmio de classe.
function main{T1<:Number, T2<:Any}(X::Array{T1,2}, x::Array{T2,1}, Y::Array{T1,2}, k::Int) N = size(X,1) n = size(Y,1) D = Array(Float64,N) #initialize distance matrix z = Array(eltype(x),n) #initialize labels vector c = Array(Float64, n) #confidence of prediction for i in 1:n for j in 1:N D[j] = CalculateDistance(X[j,:], vec(Y[i,:])) end z[i], c[i] = Classify(D,x,k) end return z, c end
Teste
Vamos testar o que conseguimos. Por conveniência, salvamos o algoritmo no arquivo kNN.jl.
A base é emprestada do
Open Machine Learning Course . O conjunto de dados é chamado Samsung Human Activity Recognition. Os dados são provenientes dos acelerômetros e giroscópios dos celulares Samsung Galaxy S3, e também é conhecido o tipo de atividade de uma pessoa com um telefone no bolso - se ele andava, se levantava, deitava, sentava ou subia / descia as escadas. Resolveremos o problema de determinar o tipo de atividade física precisamente como um problema de classificação.
As tags corresponderão ao seguinte:
1 - andando
2 - suba as escadas
3 - descendo as escadas
4 - assento
5 - uma pessoa estava de pé neste momento
6 - a pessoa estava mentindo
include("kNN.jl") training = readdlm("samsung_train.txt"); training_label = readdlm("samsung_train_labels.txt"); testing = readdlm("samsung_test.txt"); testing_label = readdlm("samsung_test_labels.txt"); training_label = map(Int, training_label) testing_label = map(Int, testing_label) z = main(training, vec(training_label), testing, 7) n = length(testing_label) println(sum(testing_label .== z[1]) / n)
Resultado: 0.9053274516457415A qualidade é avaliada pela proporção de objetos previstos corretamente para toda a amostra de teste. Parece não ser tão ruim. Mas meu objetivo é mostrar a Julia, e que ele tem um lugar para estar na Data Science.
Visualização
Em seguida, eu queria tentar visualizar os resultados da classificação. Para fazer isso, você precisa criar uma imagem bidimensional, com 561 sinais e sem saber qual deles é o mais significativo. Portanto, para reduzir a dimensionalidade e o design de dados subsequente no subespaço ortogonal de recursos, foi decidido usar a
Análise de Componentes Principais (PCA). Em Julia, como em Python, existem pacotes prontos, então simplificamos um pouco nossa vida.
using MultivariateStats #for PCA A = testing[1:10,:] #PCA for A M_A = fit(PCA, A'; maxoutdim = 2) Jtr_A = transform(M_A, A'); #PCA for training M = fit(PCA, training'; maxoutdim = 2) Jtr = transform(M, training'); using Gadfly #shows training points and uncertain point pl1 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:], Geom.point)) #predicted values for uncertain points from testing data z1 = main(training, vec(training_label), A, 7) pl2 = plot(training, layer(x = Jtr[1,:], y = Jtr[2,:],color = training_label, Geom.point), layer(x = Jtr_A[1,:], y = Jtr_A[2,:],color = z[1], Geom.point)) vstack(pl1, pl2)
Na primeira figura, o conjunto de treinamento e vários objetos do conjunto de teste são marcados, os quais precisam ser atribuídos à sua classe. Assim, a segunda figura mostra que esses objetos foram marcados.

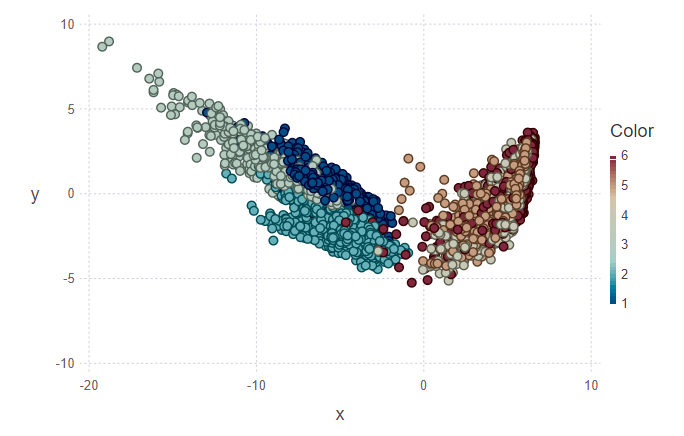
println(z[1][1:10], z[2][1:10]) > [5, 5, 5, 5, 5, 5, 5, 5, 5, 4][1.0, 0.888889, 0.888889, 0.888889, 1.0, 1.0, 1.0, 1.0, 0.777778, 0.555556]
Olhando para as imagens, quero fazer a pergunta “por que esses grupos são feios?”. Eu vou explicar Clusters individuais não são delineados com muita clareza devido à natureza dos dados e ao uso do PCA. Para o PCA, apenas caminhar e subir escadas é como uma classe - a classe de movimento. Assim, a segunda classe é a classe restante (sentado, em pé, deitado, que não são muito distinguíveis entre si). E, portanto, uma separação clara pode ser rastreada em duas classes, em vez de seis.
Conclusão
Para mim, isso é apenas uma imersão inicial em Julia e o uso dessa linguagem no aprendizado de máquina. Aliás, também sou provavelmente mais amador do que profissional. Mas enquanto estiver interessado, continuarei estudando esse assunto mais profundamente. Muitas fontes estrangeiras apostam em Julia. Bem, espere e veja.
PS: Se for interessante, posso dizer nos posts a seguir sobre os recursos da sintaxe, sobre o IDE, com a instalação da qual tive problemas.