Muitas vezes nos perguntam por que não organizamos competições para cientistas de dados. O fato é que, por experiência, sabemos que as soluções nelas não são aplicáveis ao prod. Sim, e contratar aqueles que estarão nos principais lugares nem sempre faz sentido.
Tais competições são muitas vezes vencidas com a ajuda do chamado empilhamento chinês, quando todos os algoritmos e valores de hiperparâmetros possíveis são tomados de maneira combinatória, e os modelos resultantes usam um sinal um do outro em vários níveis. Os satélites comuns dessas soluções são complexidade, instabilidade, dificuldade em depuração e suporte, consumo muito alto de recursos em treinamento e previsão, necessidade de supervisão humana cuidadosa em cada ciclo de treinamento repetido de modelos. Faz sentido fazer isso apenas em competições - pelo bem de dez milésimos nas métricas e posições locais na classificação.
Mas tentamos
Há cerca de um ano, decidimos tentar usar o empilhamento na produção. Sabe-se que modelos lineares permitem extrair um sinal útil de textos representados como um conjunto de palavras e vetorizados com tf-idf, apesar da grande dimensão de tais vetores. Nosso sistema já executou essa vetorização, portanto, não foi muito difícil para nós combinar vetores para currículos, vagas e, com base neles, ensinar regressão logística para prever a probabilidade de um candidato clicar com um currículo para uma determinada vaga.
Em seguida, essa previsão é usada pelos principais modelos como um recurso adicional, pois o modelo considera um meta-atributo. A vantagem é que, mesmo com o ROC AUC 0.7, o sinal desses modelos de meta-atributos é útil. A implementação deu cerca de 2 mil respostas por dia. E o mais importante - percebemos que podemos seguir em frente.
O modelo linear não leva em consideração as interações não lineares entre os recursos. Por exemplo, não é possível levar em consideração que, se houver um "C" no currículo e um "programador de sistema" na vaga, a probabilidade de uma resposta se tornará muito alta. Além da vaga e do currículo, além do texto, existem muitos campos numéricos e categóricos, e no currículo o texto é dividido em vários blocos separados. Portanto, decidimos adicionar uma extensão quadrática de recursos para modelos lineares e classificar todas as combinações possíveis de vetores tf-idf de campos e blocos.
Tentamos meta-sinais que prevêem a probabilidade de uma resposta sob várias condições:
- na descrição do trabalho, há um determinado conjunto de termos, categorias;
- No campo de texto da vaga e no campo de texto do currículo, um determinado conjunto de termos é encontrado;
- no campo de texto da vaga, havia um determinado conjunto de termos que não se encontravam no campo de texto do currículo;
- certos termos apareceram na vaga, o valor da categoria definida encontrado no currículo;
- em vagas e currículos, um determinado par de valores de categoria é atendido.
Depois, com a ajuda da seleção de recursos, eles selecionaram várias dezenas de meta-atributos que deram o máximo efeito, realizaram testes A / B e os liberaram para produção.
Como resultado, recebemos mais de 23 mil novas respostas por dia. Alguns dos atributos inseriram os principais atributos em força.
Por exemplo, em um sistema de recomendação, os principais atributos são
em um modelo de regressão logística que filtra currículos adequados:- região geográfica do currículo;
- área profissional do currículo;
- a diferença entre descrições de cargo e experiência de trabalho recente;
- diferença de regiões geográficas em vagas e currículos;
- a diferença entre o título da vaga e o título do currículo;
- a diferença entre especializações em vagas e currículos;
- a probabilidade de o candidato com um determinado salário em um currículo clicar em uma vaga com um determinado salário (meta-sinal em uma regressão logística);
- a probabilidade de uma pessoa com um determinado nome de currículo clicar em vagas com uma certa experiência de trabalho (meta-sinalização na regressão logística);
em um modelo XGBoost, filtrando currículos relevantes:- Quão semelhantes são as vagas e os currículos no texto;
- a diferença entre o nome da vaga e o nome do currículo e todas as posições na experiência no currículo, levando em consideração as interações de texto;
- a diferença entre o título da vaga e o título no currículo, levando em consideração as interações do texto;
- a diferença entre o nome da vaga e o nome do currículo e todas as posições na experiência do currículo, sem levar em consideração as interações de texto;
- a probabilidade de um candidato com a experiência de trabalho especificada ir para uma vaga com esse nome (meta-sinalização na regressão logística);
- a diferença entre a descrição do trabalho e a experiência anterior de trabalho no currículo;
- quanto a vaga e o currículo diferem no texto;
- a diferença entre a descrição do trabalho e a experiência anterior de trabalho no currículo;
- a probabilidade de que uma pessoa de um determinado sexo responda a uma vaga com um determinado nome (um meta-sinal na regressão logística).
no modelo de classificação no XGBoost:- a probabilidade de uma resposta por termos que estão presentes no nome da vaga e não estão no título e na posição do currículo (meta-sinalização na regressão logística);
- corresponder região da vaga e currículo
- a probabilidade de uma resposta por termos que estão presentes na vaga e não estão no currículo (meta-sinalização na regressão logística);
- atratividade prevista da vaga para o usuário (meta-tag no ALS);
- a probabilidade de uma resposta pelos termos presentes na vaga e no currículo (meta-sinal na regressão logística);
- a distância entre o nome da vaga e o título + posição do currículo, onde os termos são ponderados pelas ações do usuário (interação);
- distância entre especializações da vaga e currículo;
- a distância entre o título da vaga e o nome do currículo, onde os termos são ponderados pelas ações dos usuários (interação);
- a probabilidade de uma resposta sobre a interação de tf-idf de uma vaga e especialização de um currículo (meta-sinalização na regressão logística);
- distância entre vagas e retomar textos;
- DSSM pelo nome da vaga e pelo nome do currículo (meta-atributo na rede neural).
Um bom resultado mostra que, nessa direção, você ainda pode extrair um certo número de respostas e convites por dia com os mesmos custos de marketing.
Por exemplo, sabe-se que, com um grande número de sinais, a regressão logística aumenta a probabilidade de reciclagem.
Vamos usar para os textos de currículos e vagas o vetorizador tf-idf com um dicionário de 10 mil palavras e frases. Então, no caso de expansão quadrática em nossa regressão logística, haverá pesos de 2 * 10.000 + 10.000². É claro que, com tal escassez, até casos individuais podem afetar significativamente cada peso individual "no currículo havia uma palavra rara tal-e-tal - em uma vaga tal-e-tal, o usuário clicou".
Portanto, agora estamos tentando fazer meta-sinais na regressão logística, na qual os coeficientes de expansão quadrática são compactados usando máquinas de fatoração. Nossos pesos de 10.000 m² são representados como uma matriz de vetores latentes com uma dimensão de, por exemplo, 10.000x150 (onde escolhemos a dimensão de um vetor latente de 150). Ao mesmo tempo, casos individuais durante a compactação deixam de desempenhar um grande papel, e o modelo começa a considerar melhor padrões mais gerais, em vez de se lembrar de casos específicos.
Também usamos meta-atributos nas redes neurais do DSSM sobre as quais já
escrevemos e no ALS, sobre as quais também
escrevemos , mas de maneira simplificada. No total, a introdução de meta-atributos até o momento deu a nós (e nossos clientes) mais de 44 mil respostas adicionais (oportunidades) para vagas por dia.
Como resultado, o esquema simplificado de empilhamento de modelo nas recomendações de tarefas para currículos agora se parece com isso:
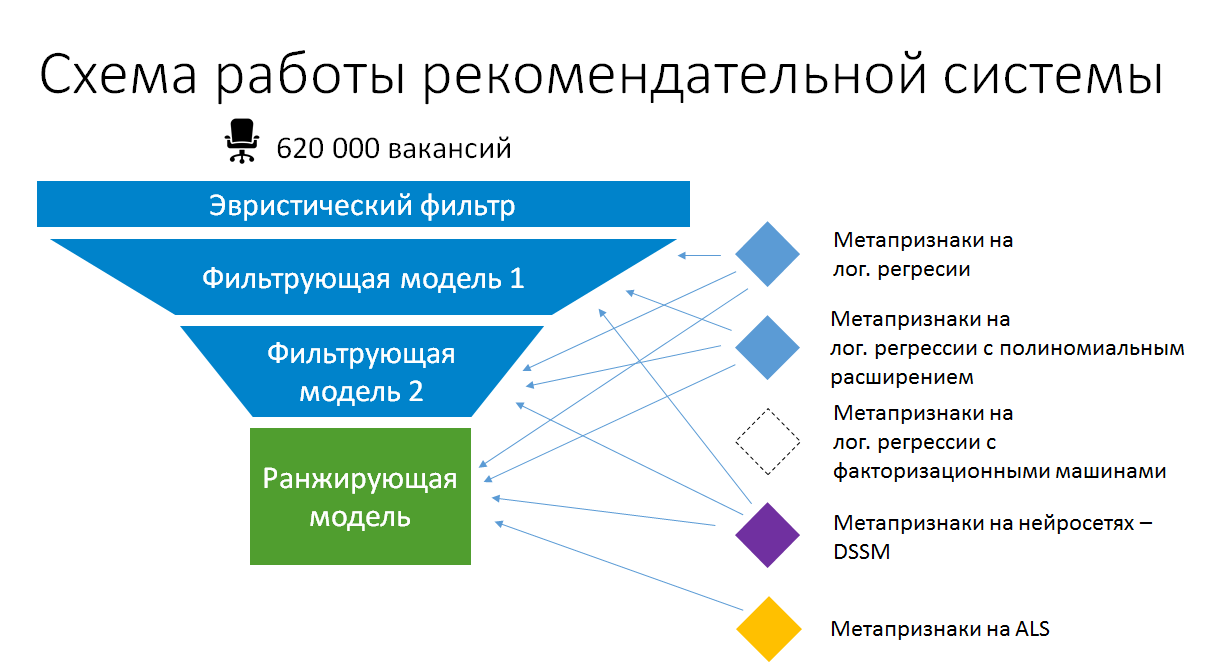
Portanto, o empilhamento na produção faz sentido. Mas esse não é o empilhamento combinatório automático. Garantimos que os modelos com base nos quais os meta-atributos sejam criados permaneçam simples e façam uso máximo dos dados existentes e dos atributos estáticos calculados. Somente dessa maneira eles poderão permanecer em produção sem se transformar gradualmente em uma caixa preta não suportada e permanecer em um estado em que possam ser treinados e aprimorados.