
Com base nos resultados de inúmeras avaliações operacionais de data centers em todo o mundo, o Uptime Institute observou que o nível de pessoal nos data centers varia muito de um lugar para outro. Essa observação é um tanto intrigante, mas não é surpreendente. Embora a equipe seja uma atividade comercial importante para os data centers que estão tentando manter a excelência operacional, muitos outros fatores influenciam as decisões das organizações sobre o nível necessário de equipe.
Entre os fatores que podem afetar o nível geral de pessoal, pode-se destacar a complexidade do data center, a rotatividade de pessoal, o número de horas de trabalho de suporte técnico necessárias, o número de contratos com contratados e as metas de negócios de acessibilidade. Os custos também são preocupantes, pois cada funcionário é um custo direto para o data center. Devido a esses muitos fatores, é necessário revisar constantemente os níveis de pessoal dos datacenters para fornecer suporte eficaz a um preço razoável.
O Uptime Institute costuma receber a pergunta: "Qual é o nível de pessoal apropriado para o meu data center?" Infelizmente, não há uma resposta concisa que seja universal para cada data center. O pessoal adequado depende de várias variáveis.
O tempo necessário para concluir as tarefas de manutenção e garantir que as mudanças no suporte técnico sejam concluídas são duas variáveis principais. A equipe para atender aos requisitos de manutenção é um fator relativamente fixo, mas depende de quais ações são executadas pelo pessoal do data center e de quais funções são atribuídas aos contratados. A gestão de turnos de suporte técnico é definida como equipe para monitorar um datacenter e responder a quaisquer incidentes e eventos. O pessoal da mudança para o suporte técnico pode ser determinado de várias maneiras. Cada método de equipe tem um impacto potencial nas operações, dependendo de quais processos são cobertos pelo suporte técnico.
Tendências de mudança
O principal objetivo da presença permanente de pessoal qualificado no local é minimizar o risco de falhas causadas por eventos anormais, impedindo um incidente, impedindo ou isolando-o, além de impedir sua propagação ou impacto em outros sistemas. Muitos data centers continuam a fornecer uma presença constante de uma equipe de eletricistas, engenheiros mecânicos e outros técnicos qualificados que fornecem um modo de operação 24x7. No entanto, as tecnologias de monitoramento remoto, o arranjo especial de edifícios na forma de um complexo, o desejo de equilibrar custos e outras razões podem levar as organizações a recrutar funcionários de diferentes maneiras.
O gerenciamento de um regime de suporte técnico sem a presença de pessoal qualificado a qualquer momento pode aumentar os riscos devido a uma resposta tardia a incidentes anormais. Por fim, a empresa deve tomar uma decisão com um nível de risco aceitável.
Outros modelos de suporte técnico de cobertura total incluem:
- Treinar o pessoal de segurança para responder a alarmes e executar procedimentos para resolver problemas;
- Monitorar o datacenter por meio de um sistema de monitoramento predial (BMS) local ou regional e envolver técnicos de chamadas;
- Disponibilidade de pessoal no local durante o horário comercial normal e de plantão à noite e nos fins de semana;
- O trabalho de vários data centers na forma de um complexo especial de edifícios, cuja equipe fornece suporte para vários data centers sem a necessidade de estar em cada data center separado a qualquer momento.
Esses e outros métodos devem ser avaliados em termos de eficácia individualmente. Para avaliar o modelo de suporte técnico, o datacenter deve determinar os riscos potenciais de incidentes no datacenter e seu impacto potencial nos negócios.
Nos últimos 20 anos, o Uptime Institute compilou um banco de dados de incidentes anormais (Relatórios de Incidentes Anormais, AIRs), usando informações recebidas de membros da Rede do Uptime Institute. O Uptime Institute analisa anualmente os dados e apresenta seus resultados aos membros da Rede. O banco de dados do AIRs contém informações interessantes sobre problemas de pessoal e modelos de pessoal eficazes para data centers.
Incidentes ocorrem fora do horário de trabalho
Em 2013, uma pequena maioria dos incidentes (dos 277 casos) ocorreu durante o horário comercial. No entanto, 44% dos incidentes ocorreram entre meia-noite e 8:00 da manhã, o que sublinha a necessidade potencial de um modo de suporte técnico 24x7 (veja a Figura 1).
Figura 1. Cerca da metade dos incidentes anormais ocorridos em 2013 ocorreu entre as 8h e o meio-dia, e a outra metade da meia-noite às 8h.
Incidentes podem ocorrer em qualquer época do ano. Concentrar a atividade da equipe em uma determinada época do ano em prioridade sobre outras não seria produtivo (por exemplo, uma proibição de férias). Os incidentes são distribuídos de maneira bastante uniforme ao longo do ano.
A Figura 2 mostra a distribuição dos incidentes por dia da semana. O diagrama mostra que cada dia da semana tem uma participação quase igual, o que sugere que a equipe deve ser a mesma para os turnos de cada dia da semana. Esta é uma conclusão importante, porque alguns datacenters concentraram os recursos de mão-de-obra de seu suporte técnico no período de segunda a sexta-feira e deixaram os dias de folga para monitoramento remoto (veja a Figura 2).
Figura 2. O pessoal do data center deve estar pronto todos os dias da semana.Incidentes por setor
A Figura 3 ilustra ainda mais os incidentes do setor e não mostra uma diferença significativa nas tendências entre os setores. O gráfico mostra que o setor de serviços financeiros relatou muito mais incidentes do que outros, mas isso provavelmente reflete a composição da amostra.
 Figura 3. Incidentes nos datacenters ocorrem o ano todo.
Figura 3. Incidentes nos datacenters ocorrem o ano todo.Causas de falhas e métodos de detecção
Sabendo quando ocorrem incidentes, pouco se pode dizer sobre o pessoal que deve estar no local. A compreensão de quais incidentes ocorrem com mais freqüência ajudará a moldar a estrutura de turnos, além de descobrir como os incidentes são detectados com mais frequência. A Figura 4 mostra que a maioria dos incidentes afeta os sistemas elétricos, seguidos pelos sistemas mecânicos. Por outro lado, cargas de trabalho críticas de TI causam um número relativamente pequeno de incidentes.
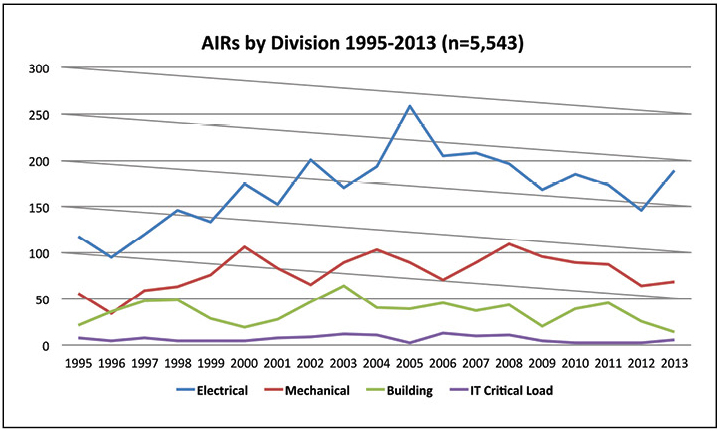 Figura 4. Mais da metade dos incidentes anormais relatados em 2013 estão relacionados ao sistema elétrico.
Figura 4. Mais da metade dos incidentes anormais relatados em 2013 estão relacionados ao sistema elétrico.Como resultado, faz sentido que as equipes de todos os turnos tenham experiência suficiente para responder aos incidentes mais comuns em sistemas elétricos. A equipe de suporte também deve responder a outros tipos de incidentes. O treinamento cruzado de engenheiros elétricos em sistemas mecânicos e prediais pode fornecer cobertura suficiente e os atendentes de chamadas podem cobrir incidentes de TI relativamente raros.
O banco de dados do AIRs também lança luz sobre como os incidentes são detectados. A Figura 5 mostra que mais da metade das informações primárias sobre todos os incidentes detectados em 2013 foram obtidas de sistemas de alarme, mais de 40% dos incidentes são detectados por especialistas técnicos no local, o que totaliza cerca de 95% dos casos. A maior mudança ao longo dos anos mostrada no diagrama é o lento crescimento de incidentes detectados por alarmes.
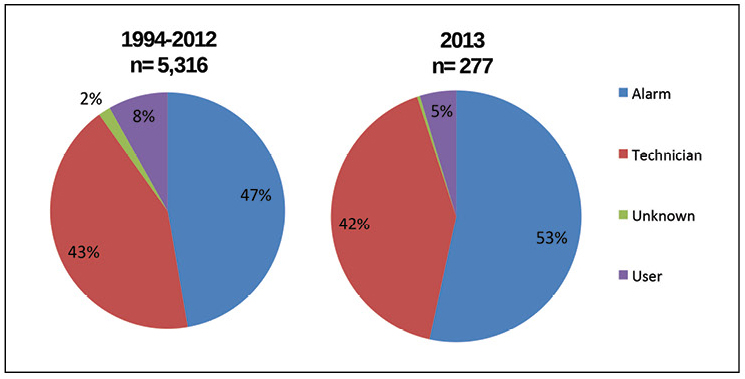 Figura 5. Agora, os alarmes são uma maneira de detectar a maioria dos incidentes; no entanto, os problemas de acessibilidade são mais frequentemente encontrados por especialistas técnicos.
Figura 5. Agora, os alarmes são uma maneira de detectar a maioria dos incidentes; no entanto, os problemas de acessibilidade são mais frequentemente encontrados por especialistas técnicos.No entanto, os alarmes não podem responder a incidentes ou mitigar consequências. O Uptime Institute testemunhou vários métodos que permitem que os data centers evitem falhas e reduzam seu impacto. Esses métodos exigem que a equipe responda ao incidente, crie redundância em sistemas críticos e programas eficazes de manutenção preditiva para prever possíveis falhas antes que elas ocorram. A Figura 6 mostra com que frequência cada um desses métodos "resgata" os data centers.
 Figura 6. A redundância de equipamentos em 2013 contribuiu para mais “resgate” do que nos anos anteriores.
Figura 6. A redundância de equipamentos em 2013 contribuiu para mais “resgate” do que nos anos anteriores.O diagrama também mostra que nos últimos anos a redundância de equipamentos e a manutenção preventiva tornaram-se mais eficientes e economizam cada vez mais dinheiro dos datacenters. Existem várias explicações possíveis para isso, incluindo o aumento da confiabilidade dos sistemas, o uso mais amplo de serviços proativos e cortes no orçamento, que levam a uma redução no número de pessoas ou sua realocação fora do data center.
Falhas no contexto da causa raiz
Os dados mostram que todos os problemas de acessibilidade em 2013 foram causados por incidentes com o sistema elétrico. A maioria das falhas ocorreu porque os procedimentos de manutenção não foram executados corretamente. Essa descoberta destaca a importância de ter procedimentos adequados e equipe bem treinada.
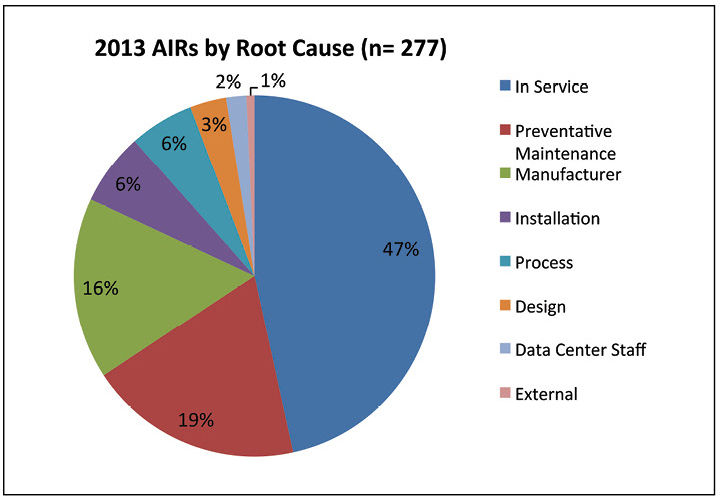 Figura 7. Quase metade das falhas relatadas em 2013 foram devido a problemas de manutenção.
Figura 7. Quase metade das falhas relatadas em 2013 foram devido a problemas de manutenção.Na fig. 7 discute ainda as causas dos incidentes em 2013. Cerca de metade dos incidentes foram descritos como "Em serviço", que é definido como manutenção inadequada, configuração inadequada do equipamento, falha no trabalho ou falta de uma causa raiz específica. Os casos de “manutenção preventiva” realmente se referem à manutenção preventiva que foi executada incorretamente. O pessoal do data center causou apenas 2% dos incidentes, mostrando que as interações entre pessoal e equipamento não eram a principal causa de incidentes e falhas.
Conclusão
A crescente complexidade do gerenciamento da infraestrutura do centro de dados (DCIM), dos sistemas de gerenciamento predial (BMS) e dos sistemas de automação predial (BAS) dificulta a resposta para a questão de saber se é possível reduzir o número de funcionários nos datacenters. Os avanços na melhoria desses sistemas são significativos. Eles podem melhorar o desempenho do seu data center; no entanto, os dados mostram que a prevenção de incidentes geralmente requer pessoal no local. É por isso que continuar com equipe equivalente em tempo integral (ETI) é uma diretiva para data centers certificados de Nível III e IV.
O objetivo principal é fornecer um tempo de resposta rápido para mitigar as consequências de quaisquer incidentes e eventos. Os dados mostram que, quando ocorrem incidentes, nenhum padrão temporário é observado. Sua aparência é bem distribuída nas 24 horas e nos 7 dias da semana.
O principal objetivo é a prevenção de riscos. Os data centers continuam a evoluir, permitindo o gerenciamento por meio de acesso remoto e aumentando a redundância de hardware. Cada data center é único e possui seu próprio conjunto de riscos inerentes. O modo de suporte técnico é apenas um fator, mas bastante importante. A decisão sobre a quantidade de funcionários envolvidos em cada turno e com quais qualificações podem ter um grande impacto na prevenção de riscos e na disponibilidade dos data centers. Faça escolhas inteligentes.
Outros artigos do blog Cloud4Y:→
Qual é o verdadeiro custo do tempo de inatividade da infraestrutura de TI para pequenas e médias empresas? (link externo)→
O auge da computação em nuvem na automação de empresas industriais (link externo)→
O que está acontecendo com os preços da computação em nuvem nos últimos anos (Habr)→
Como criar amostras para o sistema biométrico unificado e por que ele pode ser perigoso (Habr)