Este artigo discute vários tipos de testes em produção e as condições sob as quais cada um deles é mais útil e também descreve como organizar testes seguros de vários serviços em produção.
Vale ressaltar que o conteúdo deste artigo se aplica somente a esses
serviços , cuja implantação é controlada pelos desenvolvedores. Além disso, você deve avisar imediatamente que o uso de qualquer um dos tipos de testes descritos aqui não é uma tarefa fácil, que geralmente requer alterações sérias no design, desenvolvimento e teste de sistemas. E, apesar do título do artigo, não acho que nenhum dos tipos de teste em produção seja absolutamente confiável. Existe apenas uma opinião de que esses testes podem reduzir significativamente o nível de riscos no futuro, e os custos de investimento serão justificados.
(Nota: como o artigo original é Longrid, para conveniência dos leitores, é dividido em duas partes).Por que o teste de produção é necessário se pode ser feito na preparação?
A importância do cluster de preparação (ou ambiente de preparação) por diferentes pessoas é percebida de maneira diferente. Para muitas empresas, a implantação e o teste de um produto no preparo são um estágio integral que antecede seu lançamento final.
Muitas organizações conhecidas percebem a preparação como uma cópia em miniatura do ambiente de trabalho. Nesses casos, é necessário garantir a sincronização máxima. Nesse caso, geralmente é necessário garantir a operação de diferentes instâncias de sistemas com estado, como bancos de dados, e sincronizar regularmente os dados do ambiente de produção com a preparação. A exceção são apenas informações confidenciais que permitem estabelecer a identidade do usuário (isso é necessário para atender aos requisitos do
GDPR ,
PCI ,
HIPAA e outros regulamentos).
O problema com essa abordagem (na minha experiência) é que a diferença não está apenas no uso de uma instância separada do banco de dados que contém os dados reais do ambiente de produção. Muitas vezes, a diferença se estende aos seguintes aspectos:
- O tamanho do cluster de armazenamento temporário (se você pode chamá-lo de "cluster" - às vezes, é apenas um servidor disfarçado de cluster);
- O fato de a preparação geralmente usar um cluster muito menor também significa que as definições de configuração para quase todos os serviços variam. Isso se aplica a configurações de balanceadores de carga, bancos de dados e filas, por exemplo, o número de descritores de arquivos abertos, o número de conexões de bancos de dados abertos, o tamanho do conjunto de encadeamentos, etc. Se a configuração estiver armazenada em um banco de dados ou em um armazenamento de dados com valor-chave (por exemplo, Zookeeper ou Consul), esses sistemas auxiliares também devem estar presentes no ambiente de preparação;
- O número de conexões online processadas pelo serviço sem estado ou o método de reutilização de conexões TCP por um servidor proxy (se este procedimento for realizado);
- Falta de monitoramento na preparação. Mas, mesmo que o monitoramento seja realizado, alguns sinais podem se mostrar completamente imprecisos, pois um ambiente diferente daquele em funcionamento é monitorado. Por exemplo, mesmo se você monitorar a latência da consulta MySQL ou o tempo de resposta, é difícil determinar se o novo código contém uma consulta que pode iniciar uma verificação completa da tabela no MySQL, já que é muito mais rápido (e às vezes até preferível) executar uma verificação completa da pequena tabela usada no teste um banco de dados em vez de um banco de dados de produção, em que uma consulta pode ter um perfil de desempenho completamente diferente.
Embora seja justo supor que todas as diferenças acima não sejam argumentos sérios contra o uso da preparação como tal, diferentemente dos antipadrões que devem ser evitados. Ao mesmo tempo, o desejo de fazer tudo certo muitas vezes exige os enormes custos de mão-de-obra dos engenheiros na tentativa de garantir um ambiente consistente. A produção está constantemente mudando e é influenciada por vários fatores, portanto, tentar alcançar essa combinação é como ir a lugar nenhum.
Além disso, mesmo que as condições no preparo sejam o mais semelhante possível ao ambiente de trabalho, existem outros tipos de teste que são melhores para usar com base em informações reais de produção. Um bom exemplo seria o teste de imersão, no qual a confiabilidade e a estabilidade de um serviço são testadas por um longo período de tempo em níveis reais de multitarefa e carga. É usado para detectar vazamentos de memória, determinar a duração das pausas no GC, o nível de carga do processador e outros indicadores por um determinado período de tempo.
Nenhuma das opções acima sugere que a preparação é
completamente inútil (isso se tornará aparente após a leitura da seção sobre duplicação de sombra de dados ao testar serviços). Isso indica apenas que muitas vezes eles dependem da preparação em maior extensão do que o necessário e, em muitas organizações, continua sendo o
único tipo de teste executado antes da liberação completa do produto.
A arte de testar em produção
Aconteceu historicamente que o conceito de "teste em produção" está associado a certos estereótipos e conotações negativas ("programação de guerrilha", falta ou ausência de testes de unidade e integração, negligência ou desatenção à percepção do produto pelo usuário final).
Os testes de produção certamente merecerão tal reputação se forem realizados de maneira descuidada e ruim. Ele
não substitui de forma alguma os testes na fase de pré-produção e, sob nenhuma circunstância, é uma
tarefa simples . Além disso, defendo que os testes
bem -
sucedidos e
seguros na produção requerem um nível significativo de automação, uma boa compreensão das práticas estabelecidas e o design de sistemas com uma orientação inicial para esse tipo de teste.
Para organizar um processo abrangente e seguro de teste eficaz dos serviços em produção, é importante não considerá-lo um termo generalizado que denota um conjunto de diferentes ferramentas e técnicas. Infelizmente, esse erro também foi cometido por mim -
no meu artigo anterior, não foi apresentada uma classificação científica dos métodos de teste e, na seção "Testes em produção", várias metodologias e ferramentas foram agrupadas.
Na nota Testando microsserviços, o caminho são ("Uma abordagem inteligente para testar microsserviços")Desde a publicação da nota no final de dezembro de 2017, discuti seu conteúdo e, geralmente, o tópico de testes em produção com várias pessoas.
No decorrer dessas discussões, e também após uma série de conversas separadas, ficou claro para mim que o tópico de teste em produção não pode ser reduzido a vários pontos listados acima.
O conceito de "teste em produção" inclui toda uma gama de técnicas aplicadas
em três estágios diferentes . Quais - vamos entender.
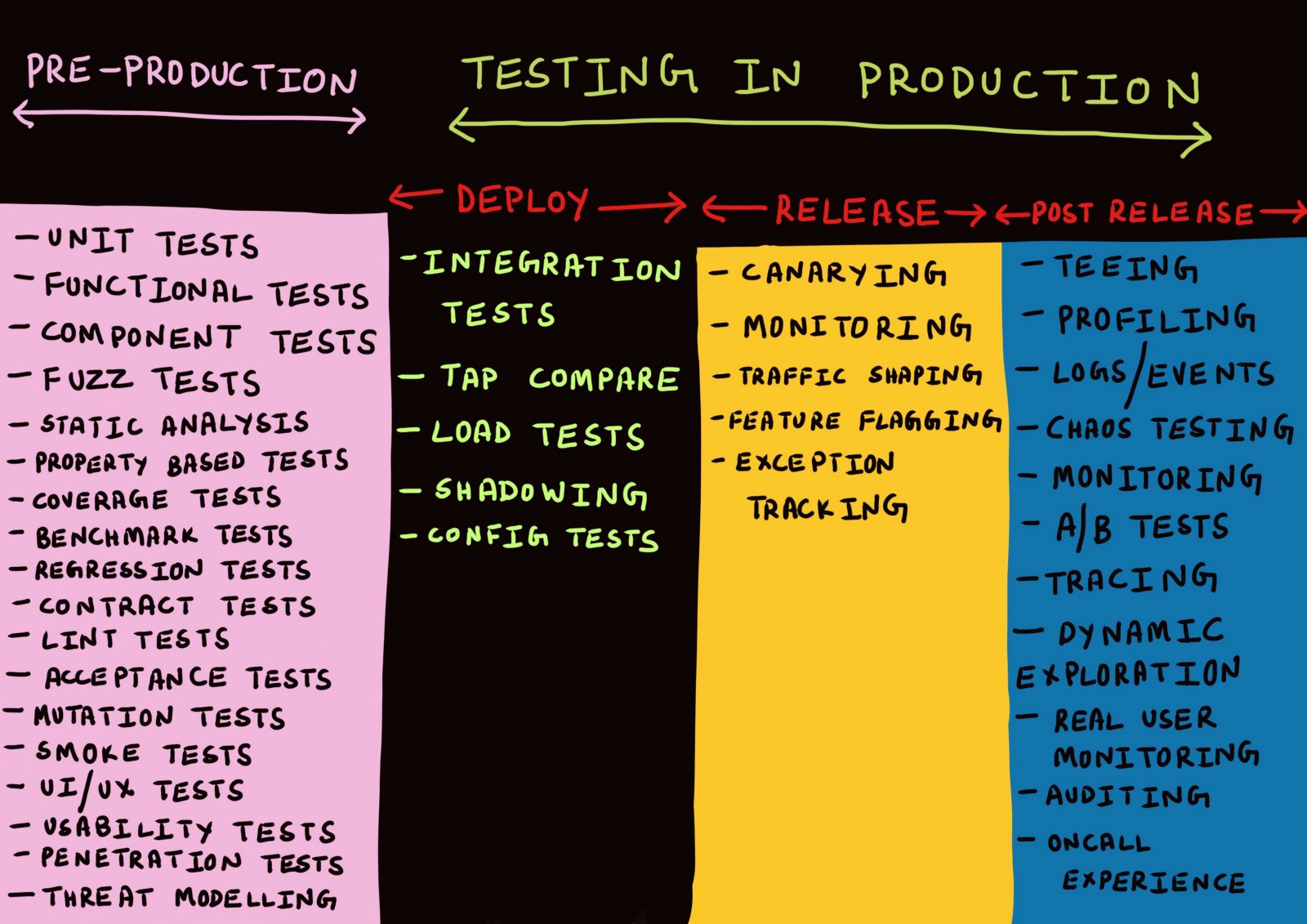
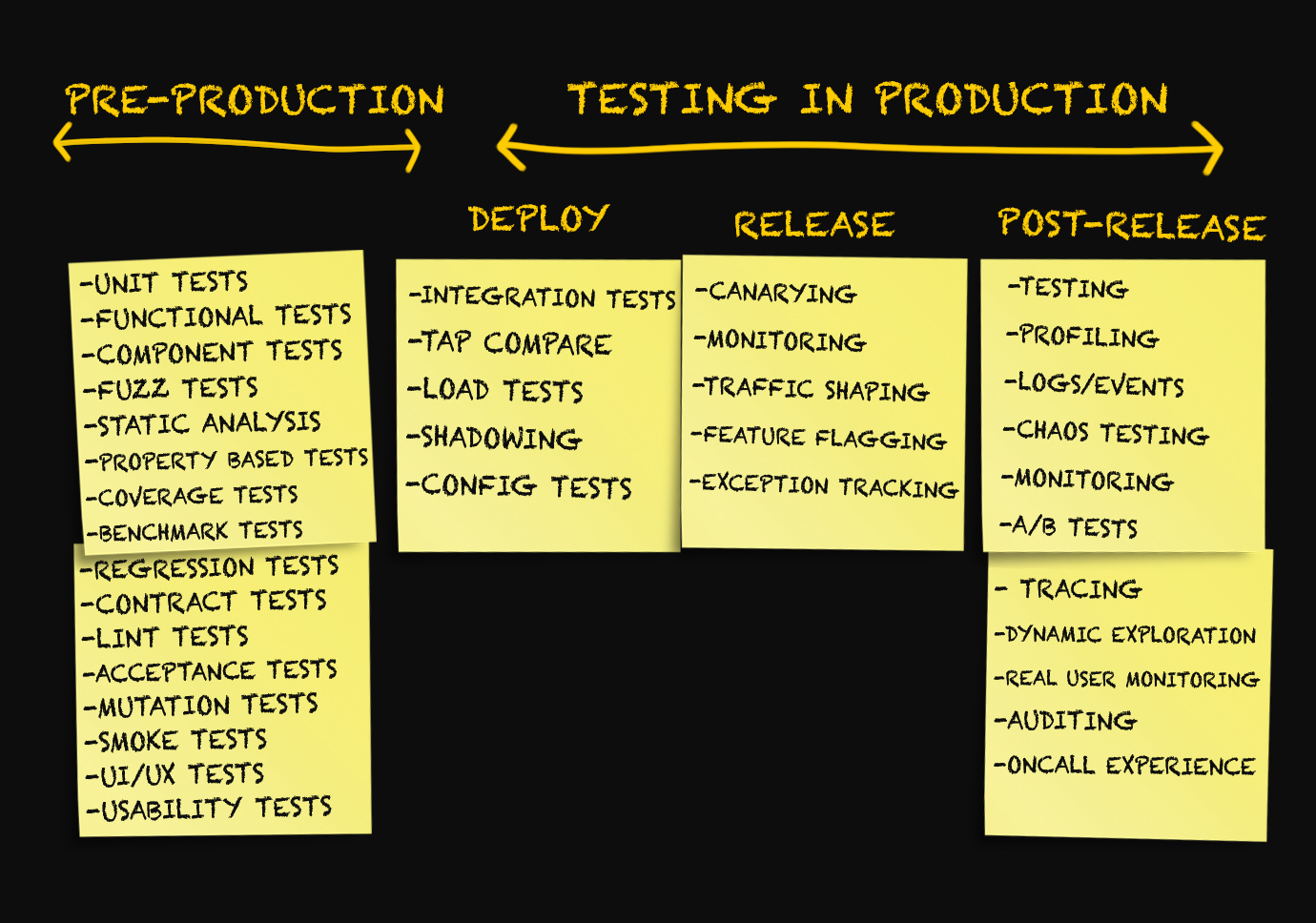
Três estágios de produção
Geralmente, as discussões sobre produção são conduzidas apenas no contexto da implantação de código na produção, no monitoramento ou em situações de emergência quando algo dá errado.
Até agora, eu mesmo utilizei termos como "implantação", "liberação", "entrega" etc., como sinônimos, com pouco pensamento sobre seu significado. Alguns meses atrás, todas as tentativas de distinguir esses termos seriam rejeitadas por mim como algo insignificante.
Depois de pensar nisso, cheguei à ideia de que
há uma necessidade real de distinguir entre as várias etapas da produção.
Etapa 1. Implantação
Quando o teste (mesmo em produção) é uma verificação da obtenção dos
melhores indicadores possíveis , a precisão do teste (e, de fato, de qualquer verificação) é garantida apenas com a condição de que o método de execução dos testes seja o mais próximo possível da maneira como o serviço é realmente usado na produção.
Em outras palavras, os testes precisam ser executados em um ambiente que
melhor simule um ambiente de trabalho .
E a
melhor imitação do ambiente de trabalho é ... o próprio ambiente de trabalho. Para executar o número máximo possível de testes em um ambiente de produção, é necessário que o resultado malsucedido de qualquer um deles não afete o usuário final.
Isso, por sua vez, é possível apenas se,
ao implantar o serviço em um ambiente de produção, os usuários não obtiverem acesso direto a esse serviço .
Neste artigo, decidi usar a terminologia do artigo
Deploy! = Release escrito por
Turbine Labs . Ele define o termo "implantação" da seguinte maneira:
“A implantação é a instalação por um grupo de trabalho de uma nova versão do código do programa de serviço na infraestrutura de produção. Quando dizemos que uma nova versão do software foi
implantada , queremos dizer que ele roda em algum lugar dentro da estrutura da infraestrutura de trabalho. Pode ser uma nova instância do EC2 na AWS ou um contêiner do Docker em execução no coração de um cluster Kubernetes. O serviço foi iniciado com êxito, passou em uma verificação de integridade e está pronto (você espera!) Para processar dados do ambiente de produção, mas na verdade pode não receber dados. Este é um ponto importante, enfatizo novamente:
para implantação, não é necessário que os usuários obtenham acesso à nova versão do seu serviço . Dada essa definição, a implantação pode ser chamada de processo com risco quase zero. ”
As palavras "processo de risco zero" são simplesmente um bálsamo para a alma de muitas pessoas que sofreram implantações malsucedidas. A capacidade de instalar o software
em um ambiente real sem permitir que os usuários tenham uma série de vantagens quando se trata de teste.
Em primeiro lugar, a necessidade de manter ambientes separados para desenvolvimento, teste e preparação, que inevitavelmente precisam ser sincronizados com a produção, é minimizada (e pode até desaparecer completamente).
Além disso, no estágio de design de serviços, torna-se necessário isolá-los um do outro, para que a falha em testar uma instância específica do serviço na produção
não leve a uma cascata ou afete os usuários pela falha de outros serviços. Uma solução para isso pode ser o design de um modelo de dados e esquema de banco de dados no qual consultas não idempotentes (principalmente
operações de gravação ) podem:
- A ser executado em relação ao banco de dados do ambiente de produção durante qualquer lançamento de teste do serviço em produção (eu prefiro essa abordagem);
- Ser rejeitado com segurança no nível do aplicativo até que eles atinjam o nível de gravação ou gravação;
- Seja alocado ou isolado no registro ou salve o nível de alguma maneira (por exemplo, armazenando metadados adicionais).
Etapa 2. Lançamento
Nota
Implantar! = Release define o termo release da seguinte maneira:
“Quando dizemos que o
lançamento da versão do serviço ocorreu, queremos dizer que ele fornece processamento de dados no ambiente de produção. Em outras palavras, uma
liberação é um processo que direciona os dados do ambiente de produção para uma nova versão do software. Com essa definição em mente, todos os riscos que associamos ao envio de novos fluxos de dados (interrupções no trabalho, insatisfação do cliente, notas tóxicas no
The Register ) estão relacionados ao
lançamento de um novo software e não à sua implantação (em algumas empresas, esse estágio também é chamado de
release) . Neste artigo, usaremos o termo
release ) ".
No livro do Google sobre SRE, o termo "release" é usado no
capítulo sobre organização de um release de software para descrevê-lo .
“Uma
questão é um elemento lógico do trabalho que consiste em uma ou mais tarefas separadas. Nosso objetivo é coordenar o processo de implantação com o perfil de risco desse serviço .
Em ambientes de desenvolvimento ou pré-produção, podemos construir a cada hora e distribuir automaticamente os lançamentos após a aprovação de todos os testes. Para grandes serviços orientados ao usuário, podemos iniciar a liberação com um cluster e aumentar sua escala até atualizar todos os clusters.
Para elementos importantes de infraestrutura, podemos estender o período de implementação para vários dias e executá-lo em diferentes regiões geográficas. ”Nesta terminologia, as palavras "release" e "release" significam o que o vocabulário geral se refere a "deploy", e os termos frequentemente usados para descrever várias estratégias de
implantação (por exemplo, implantação azul esverdeada ou implantação canária) referem-se à
liberação de um novo software.
Além disso, uma
liberação malsucedida
de aplicativos pode causar interrupções parciais ou significativas no trabalho. Nesse estágio, uma
reversão ou
hotfix também é executada se a nova versão do serviço
lançada for instável.
O processo de
liberação funciona melhor quando é automatizado e é executado de forma
incremental . Da mesma forma, uma
reversão ou
hotfix de um serviço é mais útil quando a taxa de erro e a frequência de solicitação são automaticamente correlacionadas à linha de base.
Etapa 3. Após o lançamento
Se o lançamento
ocorreu sem problemas e a nova versão do serviço processa os dados do ambiente de produção sem problemas óbvios, podemos considerá-
los bem
- sucedidos. Um lançamento bem-sucedido é seguido por um estágio que pode ser chamado de "pós-lançamento".
Qualquer sistema suficientemente complexo estará
sempre em um estado de perda gradual de desempenho. Isso não significa que
é necessária uma
reversão ou
hotfix . Em vez disso, é necessário monitorar essa deterioração (para vários fins operacionais e operacionais) e depurar, se necessário. Por esse motivo, testar após o lançamento não é mais como rotinas, mas
depurar ou coletar dados analíticos.
Em geral, acredito que todos os componentes do sistema devem ser criados, levando em consideração o fato de que nem um único sistema grande funciona perfeitamente a 100% e que as avarias devem ser reconhecidas e levadas em consideração nas etapas de design, desenvolvimento, teste, implantação e monitoramento do software. fornecendo.
Agora que identificamos os três estágios de produção, vejamos os vários mecanismos de teste disponíveis em cada um deles. Nem todo mundo tem a oportunidade de trabalhar em novos projetos ou reescrever código do zero. Neste artigo, tentei identificar claramente os métodos que funcionarão melhor no desenvolvimento de novos projetos, além de falar sobre o que mais podemos fazer para tirar proveito dos métodos propostos sem fazer alterações significativas nos projetos em funcionamento.
Teste de implantação
Separamos os estágios de implantação e lançamento e agora consideraremos alguns tipos de teste que podem ser aplicados após a implantação do código no ambiente de produção.
Teste de integração
Normalmente, o teste de integração é executado por um servidor de integração contínua em um ambiente de teste isolado para cada filial do Git. Uma cópia de
toda a topologia de serviço (incluindo bancos de dados, filas, proxies etc.) é implementada para conjuntos de testes de
todos os serviços que funcionarão juntos.
Eu acredito que isso não é particularmente eficaz por várias razões. Primeiro, o ambiente de teste, como o ambiente de preparação, não pode ser implantado de forma que seja
idêntico ao ambiente de produção real,
mesmo se os testes forem executados no mesmo contêiner Docker que será usado na produção. Isso é especialmente verdade quando a
única coisa executada em um ambiente de teste são os próprios testes.
Independentemente de o teste ser executado como um contêiner do Docker ou um processo POSIX, é mais provável que você faça
uma ou mais conexões com um serviço, banco de dados ou cache superior, o que é raro se o serviço estiver em um ambiente de produção em que possa simultaneamente processar várias conexões simultâneas, geralmente reutilizando conexões TCP inativas (isso é chamado reutilizando conexões HTTP).
Além disso, o problema é causado pelo fato de que a maioria dos testes em cada inicialização cria uma nova tabela de banco de dados ou espaço de chave em cache no
mesmo nó em que esse teste é executado (dessa maneira, os testes são isolados de falhas na rede). Esse tipo de teste, na melhor das hipóteses, pode mostrar que o sistema funciona corretamente com uma solicitação muito específica. Raramente é eficaz na simulação de tipos graves e bem distribuídos de falhas, sem mencionar os diferentes tipos de falhas parciais. Existem
estudos abrangentes que confirmam que os sistemas distribuídos geralmente exibem
comportamentos imprevisíveis que não podem ser previstos por análises realizadas de maneira diferente da de todo o sistema.
Mas isso não significa que o teste de integração seja,
em princípio, inútil. Só podemos dizer que a implementação de testes de integração em um ambiente
artificial e completamente isolado , por via de regra, não faz sentido. O teste de integração ainda deve ser executado para verificar se a nova versão do serviço:
- Não interfere na interação com serviços upstream ou downstream;
- Não afeta adversamente as metas e objetivos dos serviços superiores ou inferiores.
O primeiro pode ser fornecido até certo ponto através de testes de contrato.
Devido ao fato de as
interfaces entre os serviços funcionarem corretamente, o
teste de contrato é um método eficaz para desenvolver e testar serviços individuais no
estágio de pré-produção , o que não exige a implantação de toda a topologia de serviço.
Atualmente, as plataformas de teste de contrato orientadas para o cliente, como o
Pact , oferecem suporte apenas à interoperabilidade entre serviços por meio do RESTful JSON RPC, embora seja provável que haja
trabalho em andamento para oferecer suporte à interação assíncrona através de soquetes da Web, aplicativos que não sejam servidores e filas de mensagens . É provável que o suporte aos protocolos gRPC e GraphQL seja adicionado no futuro, mas agora ainda não está disponível.
No entanto, antes do
lançamento de uma nova versão, pode ser necessário verificar não apenas a operação correta das
interfaces .
E, por exemplo, verifique se a duração da chamada RPC entre os dois serviços cai dentro do limite permitido ao alterar a interface entre eles. Também é necessário verificar se a taxa de acertos no cache permanece constante, por exemplo, ao adicionar um parâmetro adicional à solicitação de entrada.Como se viu, o teste de integração não é opcional , seu objetivo é garantir que as alterações testadas não levem a tipos graves e generalizados de falha do sistema (geralmente aqueles para os quais os alertas são atribuídos).A esse respeito, surge a pergunta: como realizar com segurança os testes de integração na produção?. – , : - - ( C) MySQL ( D) memcache ( B).
, ( ), stateful- stateless- .
,
.
service discovery
( ),
.
.
,
C .
,
, , . , , . ,
, .
Google
Just Say No to More End-to-End Tests (« »), :
«
( ) . , ? , .
, , , »., :
. , A .
,
C MySQL, .
( , , «» ,
).
MySQL , , .
— -. , . -, .
, -
, /:
, (, ).
, ,
. IP- , , , , , , , , .
, , , , . . Facebook,
Kraken , :
«
— , . - , . , . - , , , »., , , , , .
- . service mesh . -. -, , , :
Se testarmos o serviço B, seu servidor proxy de saída poderá ser configurado para adicionar um cabeçalho especial
X-ServiceB-Test a cada solicitação de teste. Nesse caso, o servidor proxy de entrada do serviço superior C poderá:
- Detecte esse cabeçalho e envie uma resposta padrão ao serviço B;
- Informe ao Serviço C que a solicitação é um teste .
Teste de integração da interação da versão implantada do serviço B com a versão lançada do serviço C, em que as operações de gravação nunca chegam ao banco de dadosA execução de testes de integração dessa maneira também permite testar a interação do serviço B com serviços mais altos
quando eles processam dados normais do ambiente de produção - provavelmente é uma imitação mais próxima de como o serviço B se comportará quando
lançado na produção.
Também seria bom se cada serviço nessa arquitetura suportasse chamadas reais da API no modo de teste ou simulação, permitindo testar a execução de contratos de serviço com serviços downstream sem alterar os dados reais. Isso equivale a contratar testes, mas no nível da rede.
Duplicação de dados de sombra (teste de fluxo de dados escuro ou espelhamento)
A duplicação de sombra (no artigo no blog do Google é chamada de
lançamento escuro , e o termo
espelhamento é usado no
Istio ) em muitos casos, tem mais vantagens do que o teste de integração.
Os
Princípios da Engenharia do Caos afirmam o seguinte:
“Os
sistemas se comportam de maneira diferente, dependendo do ambiente e do esquema de transferência de dados. Como o modo de uso pode mudar a qualquer momento , a
amostragem de dados reais é a única maneira confiável de corrigir o caminho da solicitação. ”A duplicação de dados de sombra é um método pelo qual o fluxo de dados do ambiente de produção que entra em um determinado serviço é capturado e reproduzido em uma nova versão
implementada do serviço. Esse processo pode ser executado em tempo real, quando o fluxo de dados recebidos é dividido e enviado para as versões
lançada e
implantada do serviço ou de forma assíncrona, quando uma cópia dos dados capturados anteriormente é reproduzida no serviço
implantado .
Quando trabalhei na
imgix (uma startup com uma equipe de 7 engenheiros, dos quais apenas quatro eram engenheiros de sistema), fluxos de dados escuros eram usados ativamente para testar alterações em nossa infraestrutura de visualização de imagens. Registramos uma certa porcentagem de todas as solicitações recebidas e as enviamos ao cluster Kafka - passamos os logs de acesso HAProxy para o pipeline
heka , que, por sua vez, passou o fluxo de solicitação analisado para o cluster Kafka. Antes do estágio de
lançamento, uma nova versão do nosso aplicativo de processamento de imagens era testada em um fluxo de dados escuro capturado - isso tornava possível verificar se as solicitações foram processadas corretamente. No entanto, nosso sistema de visualização de imagens era em geral um serviço sem estado que era particularmente adequado para esse tipo de teste.
Algumas empresas preferem capturar não parte do fluxo de dados, mas transmitem uma
cópia completa desse fluxo para a nova versão do aplicativo.
O McRouter do Facebook (proxy memcached) suporta esse tipo de duplicação de sombra do fluxo de dados do memcache.
“
Ao testar uma nova instalação para o cache, achamos muito conveniente redirecionar uma cópia completa do fluxo de dados dos clientes. McRouter suporta configurações flexíveis de duplicação de sombra. É possível executar a duplicação de sombra de um pool de vários tamanhos (armazenando em cache novamente o espaço de chaves), copiar apenas parte do espaço de chaves ou alterar parâmetros dinamicamente durante a operação . ”
O aspecto negativo da duplicação de sombra de todo o fluxo de dados para um serviço
implantado em um ambiente de produção é que, se for executado no momento de máxima intensidade de transferência de dados, poderá exigir o dobro de energia.
Proxies como o Envoy oferecem suporte à duplicação de sombra do fluxo de dados para outro cluster no modo disparar e esquecer. Sua
documentação diz:
“
Um roteador pode executar duplicação de sombra do fluxo de dados de um cluster para outro. Atualmente, o modo disparar e esquecer é implementado, no qual o servidor proxy Envoy não espera por uma resposta do cluster de sombra antes de retornar uma resposta do cluster principal. Para o cluster de sombra, todas as estatísticas usuais são coletadas, o que é útil para fins de teste. Com duplicação de sombra, a opção -shadow é adicionada ao -shadow do host / autoridade. Isso é útil para o log. Por exemplo, cluster1 transforma em cluster1-shadow . "
No entanto, muitas vezes é impraticável ou impossível criar uma réplica de um cluster sincronizado com a produção para teste (pelo mesmo motivo que é problemático organizar um cluster de armazenamento temporário sincronizado). Se a duplicação de sombra for usada para testar um novo serviço
implantado que possui muitas dependências, ele poderá iniciar alterações imprevistas no estado dos serviços de nível superior em relação ao testado. A duplicação de sombra do volume diário de registros do usuário na versão
implantada do serviço com gravação no banco de dados de produção pode levar a um aumento na taxa de erro de até 100%, devido ao fato de que o fluxo de dados de sombra será percebido como repetidas tentativas de registro e rejeição.
Minha experiência pessoal sugere que a duplicação de sombra é mais adequada para testar solicitações não idempotentes ou serviços sem estado com stubs do lado do servidor. Nesse caso, a duplicação de dados de sombra é mais frequentemente usada para testar a carga, a estabilidade e as configurações. Ao mesmo tempo, com a ajuda do teste ou teste de integração, você pode testar como o serviço interage com um servidor com estado ao trabalhar com solicitações não-idempotentes.
Comparação TAP
A única menção a esse termo está em um
artigo do blog do Twitter dedicado ao lançamento de serviços com alto nível de qualidade de serviço.
“Para verificar a correção da nova implementação do sistema existente, usamos um método chamado de comparação de derivação . Nossa ferramenta de comparação de toques reproduz os dados de produção da amostra no novo sistema e compara as respostas recebidas com os resultados do antigo. Os resultados obtidos nos ajudaram a encontrar e corrigir erros no sistema antes mesmo que os usuários finais os encontrassem. ”Outra postagem no blog do Twitter define comparações de toque da seguinte forma:
"Enviando solicitações para instâncias de serviço, tanto em ambientes de produção quanto em teste, verificando os resultados e avaliando as características de desempenho".A diferença entre comparação de toque e duplicação de sombra é que, no primeiro caso, a resposta retornada pela versão
lançada é comparada com a resposta retornada pela versão
implantada e, no segundo, a solicitação é duplicada para a versão
implantada no modo offline, como acionar e esquecer.
Outra ferramenta para trabalhar nessa área é a biblioteca de
cientistas , disponível no GitHub. Essa ferramenta foi desenvolvida para testar o código Ruby, mas foi portada para
vários outros idiomas . É útil para alguns tipos de teste, mas tem vários problemas não resolvidos. Aqui está o que um desenvolvedor do GitHub escreveu em uma comunidade profissional do Slack:
“Essa ferramenta simplesmente executa duas ramificações de código e compara os resultados. Você deve ter cuidado com o código dessas ramificações. É necessário garantir que as consultas ao banco de dados não sejam duplicadas se isso resultar em problemas. Eu acho que isso se aplica não apenas a um cientista, mas também a qualquer situação em que você faça algo duas vezes e depois compare os resultados. A ferramenta cientista foi criada para verificar se o novo sistema de permissão funciona da mesma forma que o antigo e, em determinados momentos, era usado para comparar os dados típicos de praticamente todas as solicitações do Rails. Eu acho que o processo levará mais tempo, já que o processamento é realizado sequencialmente, mas esse é um problema do Ruby no qual os threads não são usados.
Na maioria dos casos conhecidos por mim, a ferramenta cientista foi usada para trabalhar com operações de leitura em vez de gravação, por exemplo, para descobrir se novas consultas e esquemas de permissão aprimorados recebem a mesma resposta que os antigos. Ambas as opções são executadas em um ambiente de produção (em réplicas). Se os recursos testados tiverem efeitos colaterais, acho que os testes terão que ser feitos no nível do aplicativo. ”Diffy é uma ferramenta de código aberto escrita Scala, introduzida pelo Twitter em 2015.
Um artigo do blog do Twitter intitulado
Testando sem escrever testes é provavelmente o melhor recurso para entender como as comparações de toques funcionam na prática.
“O Diffy detecta possíveis erros no serviço ao lançar simultaneamente uma versão nova e antiga do código. Essa ferramenta funciona como um servidor proxy e envia todas as solicitações recebidas para cada uma das instâncias em execução. Ele então compara as respostas das instâncias e relata todos os desvios encontrados durante a comparação. Diffy baseia-se na seguinte idéia: se duas implementações de um serviço retornam as mesmas respostas com um conjunto de solicitações suficientemente grande e variado, essas duas implementações podem ser consideradas equivalentes e as mais novas sem degradação no desempenho. A técnica inovadora de redução de ruído de Diffy o diferencia de outras ferramentas de análise de regressão comparativa. "A comparação de toque é ótima quando você precisa verificar se duas versões apresentam os mesmos resultados. De acordo com Mark McBride,
“A ferramenta Diffy era frequentemente usada no redesenho de sistemas. No nosso caso, dividimos a base de código-fonte do Rails em vários serviços criados usando o Scala, e um grande número de clientes de API utilizou funções de maneira diferente da esperada. Funções como formatação de data eram especialmente perigosas. ”A comparação por toque não é a melhor opção para testar a atividade do usuário ou a identidade do comportamento de duas versões do serviço com carga máxima. Como na duplicação de sombra, os efeitos colaterais continuam sendo um problema não resolvido, especialmente quando a versão implantada e a versão de produção gravam dados no mesmo banco de dados. Como nos testes de integração, uma maneira de contornar esse problema é usar testes de comparação de toque com apenas um conjunto limitado de contas.
Teste de carga
Para aqueles que não estão familiarizados com o teste de estresse,
este artigo pode servir como um bom ponto de partida. Não faltam ferramentas e plataformas para teste de carga de código aberto. Os mais populares deles são
Apache Bench ,
Gatling ,
wrk2 ,
Tsung , escritos em Erlang,
Siege ,
Iago , do Twitter, escritos em Scala (que reproduz os logs de um servidor HTTP, servidor proxy ou analisador de pacotes de rede em uma instância de teste). Alguns especialistas acreditam que a melhor ferramenta para gerar carga é o
mzbench , que suporta uma variedade de protocolos, incluindo MySQL, Postgres, Cassandra, MongoDB, TCP, etc. O
NDBench da Netflix é outra ferramenta de código aberto para carregar data warehouses de teste. , que suporta a maioria dos protocolos conhecidos.
O blog oficial do
Iago no Twitter descreve com mais detalhes quais recursos um bom gerador de carga deve ter:
“Solicitações sem bloqueio são geradas em uma determinada frequência com base em uma distribuição estatística personalizada interna ( o processo de Poisson é modelado por padrão). A frequência das solicitações pode ser alterada conforme necessário, por exemplo, para preparar o cache antes do trabalho em carga máxima.
Em geral, a principal atenção é dada à frequência das solicitações, de acordo com a lei de Little , e não ao número de usuários simultâneos, que podem variar dependendo da quantidade de atraso inerente a este serviço. Por esse motivo, surgem novas oportunidades para comparar os resultados de vários testes e evitar a deterioração do serviço, retardando a operação do gerador de carga.
Em outras palavras, a ferramenta Iago procura simular um sistema no qual as solicitações são recebidas, independentemente da capacidade do seu serviço em processá-las. Nisto, difere dos geradores de carga que simulam sistemas fechados nos quais os usuários trabalham pacientemente com o atraso existente. Essa diferença nos permite modelar com precisão os modos de falha que podem ser encontrados na produção ".Outro tipo de teste de carga é o teste de estresse, redistribuindo o fluxo de dados. Sua essência é a seguinte: todo o fluxo de dados do ambiente de produção é direcionado para um cluster menor que o preparado para o serviço; se houver problemas, o fluxo de dados é transferido de volta para o cluster maior. Essa técnica é usada pelo Facebook, conforme descrito em um dos
artigos em seu blog oficial :
“Redirecionamos especificamente um fluxo maior de dados para clusters ou nós individuais, medimos o consumo de recursos nesses nós e determinamos os limites da estabilidade do serviço. Esse tipo de teste, em particular, é útil para determinar os recursos da CPU necessários para suportar o número máximo de transmissões simultâneas do Facebook Live. ”Aqui está o que um ex-engenheiro do LinkedIn na comunidade profissional do Slack escreve:
“O LinkedIn também usou testes de redline na produção - os servidores foram removidos do balanceador de carga até que a carga atingisse os valores limite ou os erros começaram a ocorrer.”De fato, uma pesquisa no Google fornece um link para um
white paper completo e um
artigo de blog do LinkedIn sobre este tópico:
“A solução Redliner para medições utiliza um fluxo de dados real do ambiente de produção, o que evita erros que impedem medições precisas de desempenho em laboratório.
O Redliner redireciona parte do fluxo de dados para o serviço em teste e analisa em tempo real seu desempenho. Essa solução foi implementada em centenas de serviços internos do LinkedIn e é usada diariamente para vários tipos de análise de desempenho.
O Redliner suporta a execução de testes paralelos para instâncias de canário e produção. Isso permite que os engenheiros transfiram a mesma quantidade de dados para duas instâncias de serviço diferentes: 1) uma instância de serviço que contém inovações, como novas configurações, propriedades ou novo código; 2) uma instância de serviço da versão atual de trabalho."Os resultados do teste de carga são levados em consideração ao tomar decisões e ajudam a impedir a implantação do código, o que pode levar a um desempenho ruim".O Facebook levou o teste de carga usando fluxos de dados reais a um nível totalmente novo, graças ao sistema Kraken, e sua
descrição também merece ser lida.
O teste é implementado redistribuindo o fluxo de dados ao alterar os valores de peso (lidos no armazenamento de configuração distribuído) para dispositivos de borda e clusters na configuração do
Proxygen (balanceador de carga do Facebook). Esses valores determinam o volume de dados reais enviados, respectivamente, para cada cluster e região em um determinado ponto de presença.
Dados do white paper da KrakenO sistema de monitoramento (
Gorilla ) exibe indicadores de vários serviços (como mostrado na tabela acima). Com base nos dados e limites de monitoramento, é tomada uma decisão sobre o envio de dados adicionais de acordo com os valores de peso ou se é necessário reduzir ou até parar completamente a transferência de dados para um cluster específico.
Testes de configuração
Uma nova onda de ferramentas de infraestrutura de código aberto tornou a captura de todas as alterações na infraestrutura na forma de código não apenas possível, mas também relativamente
fácil . Também se tornou possível, em graus variados,
testar essas alterações, embora a maioria dos testes de infraestrutura como código no estágio de pré-produção só possa confirmar as especificações e a sintaxe corretas.
Além disso, a recusa em testar a nova configuração antes do
lançamento do código tornou-se a causa de um
número significativo de interrupções .
Para testes holísticos de alterações de configuração, é importante distinguir entre diferentes tipos de configurações. Fred Hebert sugeriu uma vez usar o seguinte quadrante:
Essa opção, é claro, não é universal, mas essa distinção permite que você decida qual a melhor forma de testar cada uma das configurações e em que estágio fazê-lo. A configuração do tempo de compilação faz sentido se você puder garantir a repetibilidade real das montagens. Nem todas as configurações são estáticas, mas nas plataformas modernas uma mudança dinâmica na configuração é inevitável (mesmo se estivermos lidando com uma "infraestrutura permanente").
, , blue-green , . (
Jamie Wilkinson ), Google ,
:
« , , , - . . - , — , , . ., . , , — ».Facebook :
« . — , . . , .
. Facebook , . , .
(, JSON). , . .
(, Facebook Thrift) . , .
, , - . . — A/B-, 1 % . A/B-, . A/B- . , , , , . , A/B- . , A/B-. Facebook .
, A/B- 1% , 1% , ( « »). , . , .
Facebook . , . , , . , , .- Cancelamento simples e conveniente de alterações
Em alguns casos, apesar de todas as medidas preventivas, a implantação de uma configuração inoperante é realizada. Encontrar e reverter rapidamente as alterações é fundamental para resolver esse problema. "As ferramentas de controle de versão estão disponíveis em nosso sistema de configuração, o que facilita muito a desfazer alterações."
Para ser continuado!UPD: continuou aqui .