Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3 Você pode usar a técnica de adivinhar o "canário" para seus próprios fins, a fim de descobrir a presença de bits "fracos", em termos de seleção. Ou seja, se você adivinhou corretamente, o servidor irá reiniciar, e isso servirá como um sinal para você de que o valor definido é bastante fácil de adivinhar. Assim, é possível derrotar os “canários” aleatórios, assumindo que após a reinicialização do servidor, seu valor não será alterado. Você também pode usar gadgets para implementar uma sequência relacionada de vários ataques.
A seguir, veremos uma maneira mais produtiva na qual você pode usar todos esses métodos para impedir a prevenção de execução de dados, espaços de endereços aleatórios e "canários".
Vamos voltar nossa atenção para arquiteturas de 64 bits em vez de arquiteturas de 32 bits. Os primeiros são mais adequados para a randomização, por isso oferecem muito mais "chance" de se defender contra um hacker. E esses sistemas parecem muito mais interessantes em termos de formação de ataques.
Esse tipo de arquitetura de 64 bits também foi considerado do ponto de vista do
BROP , programação “cega” de orientação reversa. Para simplificar, assumimos que a única diferença entre máquinas de 64 bits e 32 bits é que, em uma máquina de 64 bits, os argumentos são passados para os registradores e, para uma máquina de 32 bits, para a pilha.

Quando uma função começa a execução, é necessário "procurar" em certos registradores para descobrir onde estão os argumentos.
Agora vamos à essência da palestra de hoje - o que é programação cega voltada para o retorno, ou
BROP . A primeira coisa que faremos é encontrar um gadget de parada. Lembre-se de que quando dizemos "gadget", queremos dizer essencialmente endereços de retorno. O gadget é identificado com o endereço de retorno, o endereço inicial da sequência de instruções para a qual queremos ir. Então, o que é um gadget de parada?
Essencialmente, é o endereço de retorno para algum lugar do código; no entanto, se você pular para lá, basta pausar o programa, mas não cause a falha do programa. É por isso que isso é chamado de gadget de parada.
Você pode pular para algum lugar do código, que inicia uma chamada do sistema inativa, ou faz uma pausa ou algo assim. É possível que o programa de alguma forma "fique preso" em um loop infinito se você pular para este local. Realmente não importa por que a parada ocorre, mas você pode imaginar alguns cenários que levariam a ela.
Para que serve um gadget de parada?
Assim que o atacante conseguiu derrotar o "canário" usando a técnica interativa de adivinhar bits, ele pode começar a reescrever esse endereço de retorno, o
endereço de retiro e começa a "apalpar" o dispositivo de parada. Observe que a maioria dos endereços aleatórios que você pode colocar na pilha provavelmente causará uma falha no servidor. Novamente, esta mensagem é para você, atacante, é uma indicação de que o que você encontrou não é um gadget de parada. Porque quando o servidor trava, o soquete é fechado e você, como invasor, entende que não usou o dispositivo de parada. Mas se você adivinhou algo e o soquete depois disso permanece aberto por um tempo, você pensa: "Sim, eu encontrei esse dispositivo de parada!" Portanto, a idéia básica do primeiro passo é encontrar esse gadget de parada.

A segunda etapa é que você deseja encontrar dispositivos que excluam entradas da pilha usando o comando
pop . Portanto, você deve usar esta sequência de instruções cuidadosamente projetadas para descobrir quando você pega um desses gadgets de pilha. Essa sequência consistirá no
endereço da sonda , no
endereço de parada do endereço de parada e no
endereço de falha do sistema do
endereço de falha .
Portanto, o
endereço do probe é o que vamos colocar na pilha. Este será o endereço do gadget em potencial para limpar a pilha, o
endereço de parada - é o que consideramos na primeira etapa, este é o endereço do gadget de parada. Em seguida
, o endereço de falha será simplesmente o endereço do código não executável. Aqui você pode simplesmente colocar o endereço zero (0 x 0) e se você aplicar a função
ret a esse endereço e tentar executar o código lá, isso causará uma falha no programa.

Portanto, podemos usar esses tipos de endereços para descobrir onde esses gadgets limpam a
pilha .
Vou dar um exemplo simples. Suponha que tenhamos dois exemplos diferentes de
sondas , a armadilha de
captura e a
armadilha de parada . Suponha que, com a ajuda do
probe, vamos "testar" algum endereço, suponha que ele comece com 4 e termine com oito: 0x4 ... 8, e atrás dele esteja o próximo endereço do formulário 0x4 ... C. Hipoteticamente, podemos supor que um desses dois endereços seja o endereço do gadget de
popping de pilha .
A
armadilha de trap terá zero endereços 0x0 e 0x0 e permitirá que o dispositivo de
parada pare de ter endereços arbitrários como 0xS ... 0xS ..., isso não importa. Esse gadget de parada aponta para o código de suspensão (10), fazendo com que o programa seja pausado.
Vamos começar com a operação do
probe , que limpa alguns registros e retorna na seguinte sequência:
pop rax; ret . O que vai acontecer? Quando o sistema pula para esse endereço, o ponteiro da pilha se move para o meio do nosso gadget. O que o gadget vai fazer aqui? Certo, execute
a operação
pop rax .

E depois segue
ret , que moverá a função para a linha superior do gadget, ou seja, para
parar , e a função será interrompida sem travar o programa inteiro. Portanto, usando esse gadget, um invasor pode dizer que o endereço do
probe pertence a uma dessas funções, o que limpa a pilha, porque a conexão do cliente do servidor está aberta.
Agora, vamos supor que o segundo endereço do
probe aponte para algo como
xor rax, rax, ret para algum registro.

Então, o que acontece se tentarmos pular para esse gadget? Observe que ele não limpa nada na pilha, apenas altera o conteúdo dos registros. Então, vamos retornar ao endereço 0x0 localizado acima. E isso fará com que o sistema falhe. A conexão do cliente com o servidor será interrompida e o hacker entenderá que esse não é um gadget para limpar o
popping da pilha .
Dessa forma, você pode usar uma série mais bizarra de armadilhas e parar dispositivos, por exemplo, pode limpar dois itens na pilha. Para fazer isso, basta colocar outra instrução de
trap aqui, e se esse gadget não apagar dois elementos, você se encontrará em um desses trap e o código interromperá a execução. Os materiais da palestra descrevem uma coisa chamada
gadget BROP, que é útil se você não gosta de voltar à programação. Mas hoje também mostrarei como você pode usar esses gadgets
pop simples para iniciar um ataque semelhante. Depois que você entender isso, será muito mais fácil lidar com um
gadget BROP .
Mas todos vocês entendem como podemos usar a função de
sonda para esses gadgets? Suponha que você encontre o local dos trechos de código que permitem limpar a pilha com a função
pop , remova um elemento dela, mas você realmente não sabe em qual registro essa função
pop funcionará. Você apenas sabe que ela já está pronta para execução. Mas você precisa saber em qual registro esses gadgets
pop funcionarão, porque em uma arquitetura de 64 bits, os registros controlam onde estão localizados os argumentos da função que você deseja chamar.
Assim, nosso objetivo é poder criar dispositivos que nos permitam excluir os valores que colocamos em determinados registros de pilha e, finalmente, iniciar uma chamada de
sistema de chamada de sistema , o que nos permite fazer algo ruim.
Portanto, agora precisamos determinar quais registros são usados pelos gadgets
pop .

Para fazer isso, podemos tirar proveito da chamada do sistema de pausa. Se a chamada do sistema for pausada, a execução do programa será suspensa e ele não aceitará nenhum argumento. E isso significa que o sistema ignora tudo nos registros.
De fato, para encontrar a instrução de pausa que estamos executando, você pode vincular todos esses gadgets
pop para que possamos colocá-los todos na pilha e, entre cada um deles,
inserimos um número syscall para pausar. Então veremos se podemos "suspender" o programa dessa maneira. Deixe-me dar um exemplo concreto.
Aqui, colocamos um gadget na barra de endereço de retorno que limpa os registros da
RDI e aplica a função
ret a eles. Acima dele, colocaremos um
número syscall para pausar.
Suponha que tenhamos mais um gadget localizado acima que implemente a função
pop em outro registro, digamos
RSI e depois
ret . E então colocamos o
número syscall novamente para pausar. E fazemos isso para todos os gadgets que encontramos e acabamos no topo da pilha com o endereço putativo para
syscall .
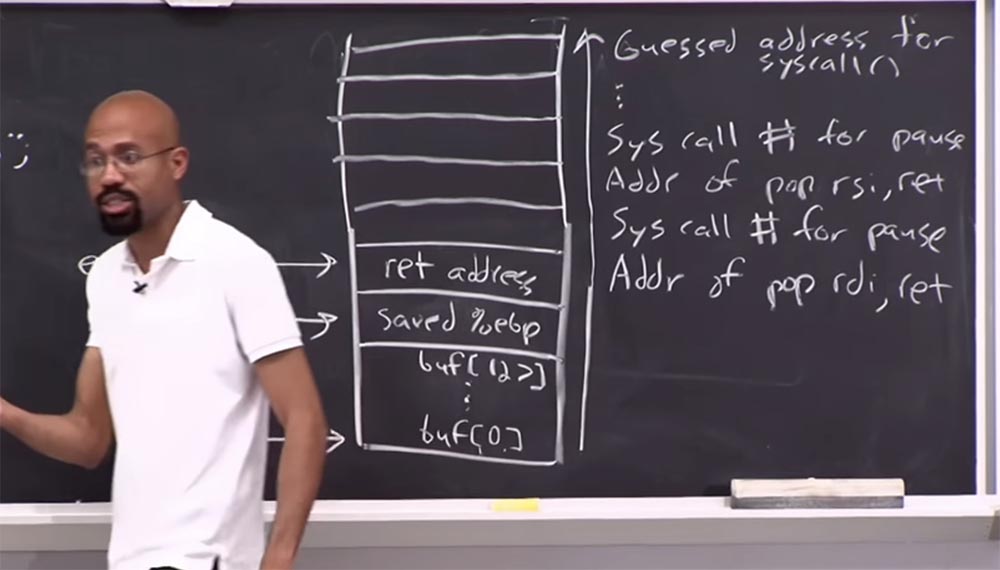
Lembre-se novamente de como você usa essas chamadas do sistema. Você deve colocar o
número syscall no registro
RAX e chamar a função
libc syscall , que está prestes a fazer a chamada do sistema solicitada.
Então, o que acontece quando executamos esse código? Vamos chegar aqui, na linha de
endereço ret , saltaremos para o endereço desse gadget; observe que o invasor sabe que esse gadget, localizado à direita, remove algo da pilha, mas ainda não sabe em qual registro está localizado.
Então, se pularmos para o
endereço ret , o que acontece? Ele usará a função
pop para pausar o
syscall , em alguns registros que o invasor não conhece e, em seguida, continuaremos subindo essa cadeia de operações na pilha.
Ao fazer isso, esperamos que um desses dispositivos execute a função
pop para o
número syscall no registro
RAX correspondente. Assim, quando chegamos aqui, no topo da pilha, no caminho "bagunçando" todos os registros que têm um
número de syscall para pausar, esperamos que ainda tenhamos um registro, que deve estar correto. Porque se um de nossos gadgets fizer isso e, em seguida, ao fazer o
ret , depois de um tempo retornaremos aqui, no topo da pilha, teremos uma pausa. Mais uma vez, a pausa atua como um sinal para o atacante. Como se esse endereço assumido para
syscall estiver incorreto, o programa falhará.
Então, o que nos permite fazer essa fase de ataque? Ainda não sabemos em quais registros
os gadgets
pop estão localizados, mas sabemos que um deles
liberará o
RAX que queremos controlar. E provavelmente sabemos o endereço
syscall , porque conseguimos pausar o sistema.
Depois de fazer isso, podemos verificar esses gadgets um por um e descobrir qual deles coloca o sistema em pausa. Em outras palavras, cortamos tudo entre a linha de
endereço ret e a parte superior da pilha para ir direto para
syscall . Verificaremos se ocorreu uma pausa ou falha no sistema. Se ocorrer uma falha, identificamos o gadget que o causou, por exemplo, está na linha inferior à direita, é o
pop rdi . Livre-se dele e tente o próximo. Coloque aqui na linha acima
ret address o endereço real para
syscall . Podemos pausar o programa? Sim, isso significa que aprendemos que esse gadget
pop deve liberar
RAX . Isso está claro?
Público-alvo: então, uma maneira de adivinhar o endereço de uma chamada do sistema é apenas uma transferência cega de gadgets?
Professor: sim, é, e há maneiras de otimizar esse processo nos materiais de aula quando você usa a extensão de arquivo
PLT e coisas semelhantes. Com o simples ataque que eu descrevi, você simplesmente colou o endereço aqui e verifique se causou uma pausa ou não. Como resultado do teste, descobrimos a localização do
syscall . Vamos descobrir onde
está localizada a instrução que executa o
pop RAX . Também precisamos de gadgets que executam
pop em alguns outros registros. Você pode fazer testes semelhantes para eles. Portanto, em vez de pausar o
número syscall , use
push para algum outro comando que, por exemplo, use os argumentos
RAX e
RDI .
Assim, você pode usar o fato de que, para qualquer conjunto específico de registros que você deseja controlar, existe algum tipo de
syscall que dará a um invasor um sinal para descobrir se você o interrompeu com êxito ou não. Portanto, no final desta fase, você terá o endereço
syscall e o endereço de heap do gadget, que permitem exibir registros arbitrários.
E agora vamos para o quarto passo, que será chamado de
gravação / gravação. O quarto passo é gravar uma chamada do sistema. Para ligar para
escrever , precisamos dos seguintes gadgets:
pop rdi, ret;
pop rsi, ret;
pop rdx, ret;
pop rax, ret;
syscall
Como esses registros são usados por uma chamada do sistema? O primeiro é o soquete, ou, mais geralmente, o descritor de arquivo que você irá transferir para gravação. O segundo é o buffer, o terceiro é o tamanho desse buffer, o quarto é o número de chamada do sistema e o quinto é o próprio
syscall .
Portanto, se encontrarmos todos esses dispositivos, podemos controlar os valores incorporados nos argumentos, que, por sua vez, são colocados nesses registros, porque apenas os "empurramos" para a pilha.
O que deve ser um soquete? Aqui temos que adivinhar um pouco. Você pode aproveitar o fato de o Linux limitar o número de conexões abertas simultâneas para um arquivo que atinge um valor de 2024. E também deve ser o mínimo de todos os disponíveis.
Gostaria de saber o que vamos inserir no ponteiro do buffer? É isso mesmo, pretendemos usar o fragmento de texto do programa aqui, vamos colocá-lo em um ponteiro em algum lugar no código do programa. Isso nos permite ler o arquivo binário fora da memória usando a chamada de cliente correta do soquete. Em seguida, o invasor pode pegar esse arquivo binário, analisá-lo offline e offline, usando o
GDB ou outra ferramenta para descobrir onde tudo isso está localizado. O invasor sabe que agora, toda vez que o servidor "travar", o mesmo conjunto aleatório de coisas será armazenado nele. Portanto, agora que um invasor pode descobrir os endereços e as compensações do conteúdo da pilha, ele pode atacar esses dispositivos diretamente. Ele pode atacar diretamente outras vulnerabilidades, descobrir como abrir o shell e similares. Em outras palavras, no local em que você forneceu o binário com o hacker, você foi derrotado.
É assim que o ataque do
BROP funciona . Como eu disse, nos materiais da palestra, existem muitas maneiras de otimizar esses processos, mas primeiro você precisa entender o material principal; caso contrário, a otimização perde seu significado. Portanto, você pode falar comigo sobre otimização individualmente ou depois da aula.
Por enquanto, basta dizer que estes são os princípios básicos de como você pode iniciar um ataque
BROP . Você deve encontrar o gadget de
parada , encontrar os gadgets que executam a função de entradas da pilha
pop , descobrir em quais registros eles estão localizados, onde o
syscall está localizado e, em seguida, iniciar a
gravação , com base nas informações obtidas.

Então, rapidamente
repasse o tópico, como você se defende do
BROP ? Portanto, a coisa mais óbvia que você tem é a re-randomização. Como os servidores "caídos" não reaparecem, não criam versões aleatórias de si mesmos, atuam como um sinal que dá ao invasor a oportunidade de testar várias hipóteses sobre como os programas funcionam.
Uma maneira fácil de se proteger é garantir que você execute
exec, em vez de
bifurcar, ao reviver seu processo. Porque quando você executa o processo, você cria um espaço completamente novo, localizado aleatoriamente, pelo menos é o que acontece no Linux. No Linux, quando você compila usando
PIE ,
Position Independent Execution , um executável independente de local, quando você usa
exec, você obtém apenas um novo espaço de endereço aleatório.
A segunda maneira é simplesmente usar o Windows, porque esse sistema operacional basicamente não tem o equivalente a uma função
fork . Isso significa que, quando você reviver um servidor no Windows, ele sempre terá um novo espaço de endereço aleatório.
Alguém aqui perguntou o que aconteceria se, após um mau funcionamento do servidor, ele não desconectasse? Portanto, se durante uma falha no servidor, de alguma forma, “capturar” esse erro e manter a conexão aberta por um tempo, podemos confundir o invasor para que ele não receba um sinal sobre a falha e pense que encontrou o endereço correto.
Nesse caso, seu ataque do
BROP se transformará em um ataque do
DOS . Porque você acabou de obter todos os possíveis processos zumbis que existem por aí. Eles são inúteis, mas você não pode deixá-los ir mais longe, caso contrário você terá que excluir essas informações.
Outra coisa em que você pode pensar é fazer a verificação de fronteira sobre a qual conversamos anteriormente. Os materiais da palestra dizem que esse método é improdutivo, pois é 2 vezes mais caro, mas você ainda pode usá-lo.
É assim que o
BROP funciona. Quanto aos trabalhos de casa, é feita uma pergunta mais delicada: e se você usar um hash do tempo atual? Ou seja, o período de tempo durante o qual você reinicia o programa. Isso é suficiente para impedir esse tipo de ataque? Observe que o hash não fornece magicamente bits de entropia, se os dados inseridos no hash forem facilmente previsíveis. Se o seu hash contiver bilhões de bits, isso não importa. Mas se você tiver apenas alguns significados, o atacante apenas os adivinhará. Obviamente, usar um hash de tempo aleatório é melhor do que não usar nada para proteger contra um hacker, mas isso não fornecerá a segurança com a qual você deve contar.
A versão completa do curso está disponível
aqui .
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?