Talvez hoje não exista outra tecnologia em torno da qual haja tantos mitos, mentiras e incompetências. Jornalistas que falam sobre tecnologia mentem, políticos que falam sobre implementação bem-sucedida mentem, a maioria dos vendedores de tecnologia mente. Todo mês, vejo as consequências de como as pessoas tentam implementar o reconhecimento facial em sistemas que não conseguem trabalhar com ele.

O tópico deste artigo, há muito tempo, tornou-se doloroso, mas de alguma forma era preguiçoso demais para escrevê-lo. Muito texto que eu já repeti vinte vezes para pessoas diferentes. Mas, depois de ler o próximo pacote de lixo, decidi que estava na hora. Vou dar um link para este artigo.
Então No artigo, responderei a algumas perguntas simples:
- É possível reconhecê- lo na rua? E quão automático / confiável?
- Anteontem, escreveram que os criminosos estavam detidos no metrô de Moscou e ontem escreveram que não podiam em Londres. E também na China eles reconhecem todos, todos na rua. E aqui eles dizem que 28 congressistas americanos são criminosos. Ou, eles pegaram um ladrão.
- Quem agora está lançando soluções de reconhecimento facial, qual a diferença entre soluções, recursos de tecnologia?
A maioria das respostas será baseada em evidências, com um link para pesquisa onde são mostrados os principais parâmetros dos algoritmos + com a matemática do cálculo. Uma pequena parte será baseada na experiência de implementação e operação de vários sistemas biométricos.
Não entrarei em detalhes de como o reconhecimento de face é implementado agora. Em Habré, existem muitos bons artigos sobre esse assunto:
a ,
b ,
c (há muito mais deles, é claro, esses aparecem na memória). Mas, ainda assim, alguns pontos que afetam decisões diferentes - eu descreverei. Portanto, a leitura de pelo menos um dos artigos acima simplificará a compreensão deste artigo. Vamos começar!
Introdução, Base
A biometria é uma ciência exata. Não há espaço para as frases “sempre funciona” e “ideal”. Tudo é muito bem considerado. E para calcular, você precisa conhecer apenas duas quantidades:
- Erros do primeiro tipo - uma situação em que uma pessoa não está em nosso banco de dados, mas nós o identificamos como uma pessoa presente no banco de dados (em biometria FAR (taxa de acesso falsa))
- Erros do segundo tipo - situações em que uma pessoa está no banco de dados, mas sentimos sua falta. (Em biometria FRR (taxa de rejeição falsa))
Esses erros podem ter vários recursos e critérios de aplicação. Falaremos sobre eles abaixo. Enquanto isso, vou lhe dizer onde obtê-los.
Características
A primeira opção Era uma vez, os próprios fabricantes publicaram erros. Mas aqui está a coisa: você não pode confiar no fabricante. Sob quais condições e como ele mediu esses erros - ninguém sabe. E se medido, ou o departamento de marketing chamou.
A segunda opção Bases abertas apareceram. Os fabricantes começaram a indicar erros nas bases. O algoritmo pode ser aprimorado para bancos de dados conhecidos, para que eles mostrem uma qualidade incrível para eles. Mas, na realidade, esse algoritmo pode não funcionar.
A terceira opção são concursos abertos com uma solução fechada. O organizador verifica a decisão. Essencialmente kaggle. O mais famoso deles é o
MegaFace . Os primeiros lugares nesta competição deram uma grande popularidade e fama. Por exemplo, N-Tech e Vocord fizeram um grande nome no MegaFace.
Tudo ficaria bem, mas honestamente. Você pode personalizar a solução aqui. Isso é muito mais difícil, por mais tempo. Mas você pode calcular pessoas, marcar manualmente a base etc. E o mais importante - não terá nada a ver com o modo como o sistema funcionará com dados reais. Agora você pode ver quem é o líder no MegaFace e procurar as soluções desses caras no próximo parágrafo.
A quarta opção . Até o momento, o mais honesto. Eu não sei trapacear lá. Embora eu não os exclua.
Um instituto grande e mundialmente famoso concorda em implantar um sistema de teste de solução independente. Um SDK é recebido dos fabricantes, que está sujeito a testes fechados, nos quais o fabricante não participa. O teste tem muitos parâmetros, que são publicados oficialmente.
Agora, esse
teste é realizado pelo NIST - Instituto Nacional Americano de Padrões e Tecnologias. Esse teste é o mais honesto e interessante.
Devo dizer que o NIST faz um ótimo trabalho. Eles desenvolveram cinco casos, lançaram novas atualizações a cada dois meses, melhoraram constantemente e incluíram novos fabricantes. Aqui você encontra a última edição do estudo.
Parece que esta opção é ideal para análise. Mas não! A principal desvantagem dessa abordagem é que não sabemos o que há no banco de dados. Veja este gráfico aqui:

Esses são os dados de duas empresas para as quais os testes foram realizados. O eixo x é o mês, y é a porcentagem de erros. Fiz o teste "Caras selvagens" (logo abaixo da descrição).
Um aumento repentino de precisão em 10 vezes em duas empresas independentes (em geral, todos saíram de lá). De onde
O log do NIST diz que "o banco de dados era muito complicado, nós o simplificamos". E não há exemplos nem da base antiga nem da nova. Na minha opinião, este é um erro grave. Foi na base antiga que a diferença entre os algoritmos do fornecedor era visível. No novo todos os 4-8% dos passes. E no antigo era 29-90%. Minha comunicação com o reconhecimento facial em sistemas de CFTV diz que 30% antes - esse foi o resultado real dos algoritmos grandmaster. É difícil reconhecer a partir dessas fotos:

E, claro, 4% de precisão não brilha neles. Mas sem ver a base do NIST, é 100% impossível fazer tais declarações. Mas é o NIST que é a principal fonte de dados independente.
No artigo, descrevo a situação relevante para julho de 2018. Ao mesmo tempo, confio na precisão, de acordo com o antigo banco de dados de pessoas para testes relacionados à tarefa "Faces na natureza".
É possível que em meio ano tudo mude completamente. Ou talvez seja estável nos próximos dez anos.
Então, precisamos desta tabela:
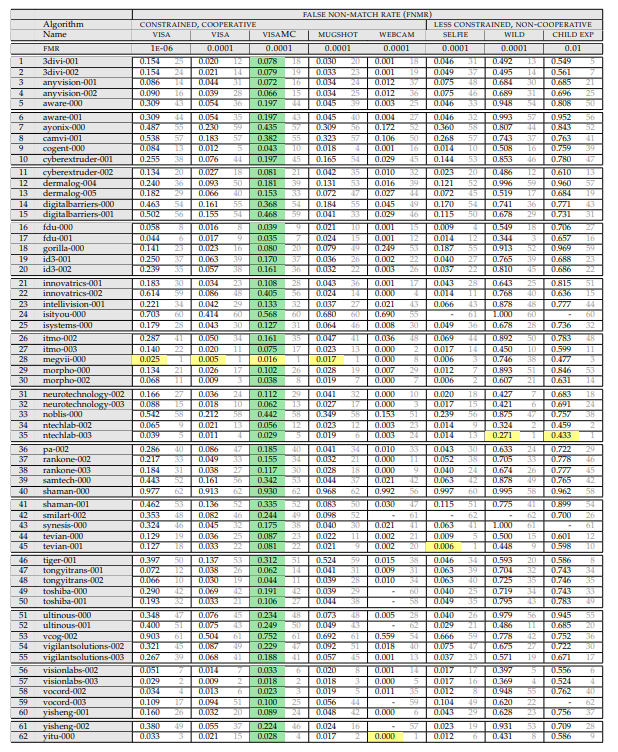
(Abril de 2018, porque o selvagem é mais adequado aqui)
Vejamos o que está escrito nele e como é medido.
Acima está uma lista de experimentos. O experimento consiste em:
Aquele em que o aparelho está sendo medido. Os conjuntos são:
- Foto do passaporte (ideal, frontal). O fundo é branco, sistemas de filmagem ideais. Às vezes, isso pode ser encontrado no ponto de verificação, mas muito raramente. Normalmente, essas tarefas são uma comparação de uma pessoa no aeroporto com a base.

- A fotografia é um bom sistema, mas sem qualidade superior. Existem fundos de fundo, uma pessoa pode não ficar uniformemente / olhar além da câmera etc.

- Selfies de uma câmera de smartphone / computador. Quando o usuário coopera, mas as condições de disparo são ruins. Existem dois subconjuntos, mas eles só têm muitas fotos em selfies.

- "Faces em estado selvagem" - filmagem de quase qualquer lado / filmagem oculta.Os ângulos máximos de rotação da face para a câmera são 90 graus. É aqui que o NIST simplificou bastante a base.

- Crianças. Todos os algoritmos funcionam mal para crianças.
Além disso, em que nível de erros do primeiro tipo são medidos (este parâmetro é considerado apenas para fotos de passaporte):
- 10 ^ -4 - FAR (um falso positivo do primeiro tipo) por 10 mil comparações com a base
- 10 ^ -6 - FAR (um falso positivo do primeiro tipo) por milhão de comparações com a base
O resultado do experimento é o valor da FRR. A probabilidade de termos perdido a pessoa que está no banco de dados.
E já aqui o leitor atento pôde perceber o primeiro ponto interessante. "O que significa FAR 10 ^ -4?" E este é o momento mais interessante!
Configuração principal
O que esse erro significa na prática? Isso significa que, na base de 10.000 pessoas, haverá uma coincidência errônea ao verificar qualquer pessoa comum nela. Ou seja, se tivermos uma base de 1000 criminosos e comparamos 10.000 pessoas por dia, teremos uma média de 1.000 falsos positivos. Alguém realmente precisa disso?
Na realidade, nem tudo é tão ruim.
Se você olhar para a construção de um gráfico da dependência de um erro do primeiro tipo sobre um erro do segundo tipo, você obtém uma imagem tão interessante (aqui imediatamente para uma dúzia de empresas diferentes, para a opção Wild, é isso que acontecerá na estação de metrô, se você colocar a câmera em algum lugar para que as pessoas não a vejam) :
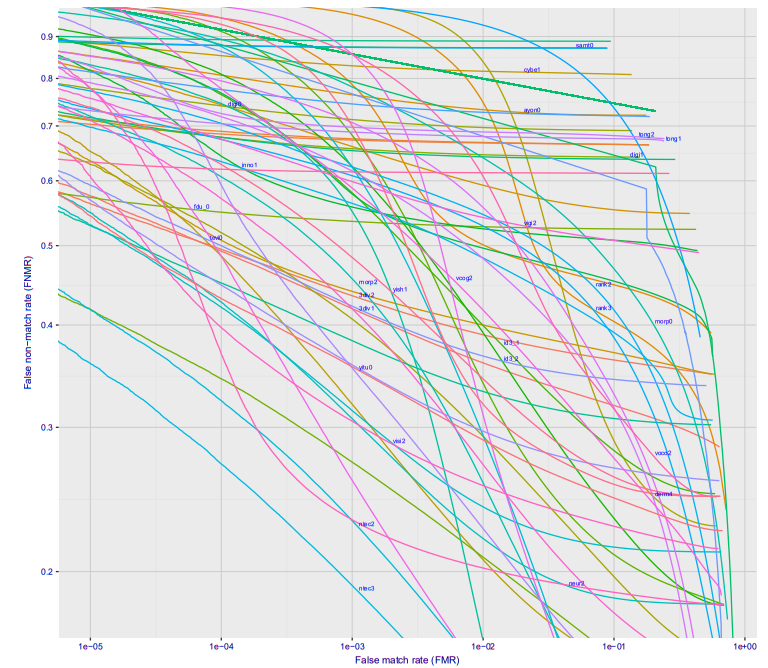
Com um erro de 10 ^ -4, 27% das pessoas não reconhecidas. 10 ^ -5 aproximadamente 40%. Muito provavelmente uma perda de 10 ^ -6 será de aproximadamente 50%
Então, o que isso significa em números reais?
É melhor seguir o paradigma de "quantos erros por dia podem ser cometidos". Temos um fluxo de pessoas na estação; se a cada 20 a 30 minutos o sistema der um falso positivo, ninguém levará isso a sério. Fixamos o número permitido de falsos positivos na estação de metrô 10 pessoas por dia (se é bom que o sistema não seja desligado como irritante, você precisará ainda menos). O fluxo de uma estação do metrô de Moscou
20-120 mil passageiros por dia. A média é de 60 mil.
Deixe o valor fixo de FAR em 10 ^ -6 (você não pode colocá-lo abaixo, perderemos 50% dos criminosos se estivermos otimistas). Isso significa que podemos permitir 10 alarmes falsos com um tamanho base de 160 pessoas.
É muito ou pouco? O tamanho da base na lista federal de procurados é de ~
300.000 pessoas . Interpol 35 mil. É lógico supor que sejam necessários cerca de 30 mil moscovitas.
Isso fornecerá um número irreal de alarmes falsos.
Vale ressaltar que 160 pessoas podem ser uma base suficiente se o sistema funcionar on-line. Se você procurar aqueles que cometeram um crime no último dia - este já é um volume de trabalho. Ao mesmo tempo, usando óculos / bonés pretos etc., você pode se disfarçar. Mas quantos os carregam no metrô?
O segundo ponto importante. É fácil criar um sistema no metrô que ofereça fotos de qualidade superior. Por exemplo, coloque a armação das câmeras da catraca. Já não haverá 50% de perdas por 10 ^ -6, mas apenas 2-3%. E por 10 ^ -7 5-10%. Aqui a precisão do gráfico no Visa, tudo certamente será muito pior em câmeras reais, mas acho que em 10 ^ -6 você pode deixar essa perda de 10%:

Novamente, o sistema não puxará a base de 30 mil, mas tudo o que acontece em tempo real permitirá a detecção.
Primeiras perguntas
Parece que é hora de responder a primeira parte das perguntas:
Liksutov
disse que 22 pessoas procuradas foram identificadas. Isso é verdade?
Aqui a questão principal é o que essas pessoas cometeram, quantas pessoas não procuradas foram verificadas, quanto reconhecimento facial ajudou na detenção dessas 22 pessoas.
Muito provavelmente, se essas são as pessoas que o plano de "interceptação" estava procurando, esses são realmente detidos. E este é um bom resultado. Mas minhas modestas suposições permitem-me dizer que, para alcançar esse resultado, foram verificadas pelo menos 2 a 3 mil pessoas, mas cerca de 10 mil.
Ele bate muito bem com os números que foram chamados em
Londres . Somente esses números são publicados honestamente, enquanto as pessoas
protestam . E nós estamos em silêncio ...
Ontem, em Habré, havia um artigo sobre a conta de
rostos falsos no reconhecimento facial. Mas este é um exemplo de manipulação na direção oposta. A Amazon nunca teve um bom sistema de reconhecimento facial. Além da questão de como definir limites. Eu posso pelo menos fazer 100% dos amendoins girando as configurações;)
Sobre os chineses, que reconhecem todos na rua - uma farsa óbvia. Embora, se eles fizeram um rastreamento competente, você pode fazer uma análise mais adequada. Mas, para ser sincero, não acredito que até agora seja possível. Em vez disso, um conjunto de plugues.
E a minha segurança? Na rua, no comício?
Vamos mais longe. Vamos avaliar outro momento. Procure uma pessoa com uma biografia conhecida e com um bom perfil nas redes sociais.
O NIST verifica o reconhecimento frente a frente. Duas faces da mesma / pessoas diferentes são tomadas e comparadas com a proximidade entre elas. Se a proximidade for maior que o limite, essa é uma pessoa. Se ainda mais - diferente. Mas existe uma abordagem diferente.
Se você ler os artigos que eu aconselhei no começo, saberá que, ao reconhecer uma face, é gerado um código de hash da face, que exibe sua posição no espaço N-dimensional. Geralmente, esse é um espaço dimensional, embora todos os sistemas tenham maneiras diferentes.
Um sistema de reconhecimento de rosto ideal converte a mesma face no mesmo código. Mas não há sistemas ideais. Uma e a mesma pessoa geralmente ocupa alguma área do espaço. Bem, por exemplo, se o código fosse bidimensional, poderia ser algo como isto:
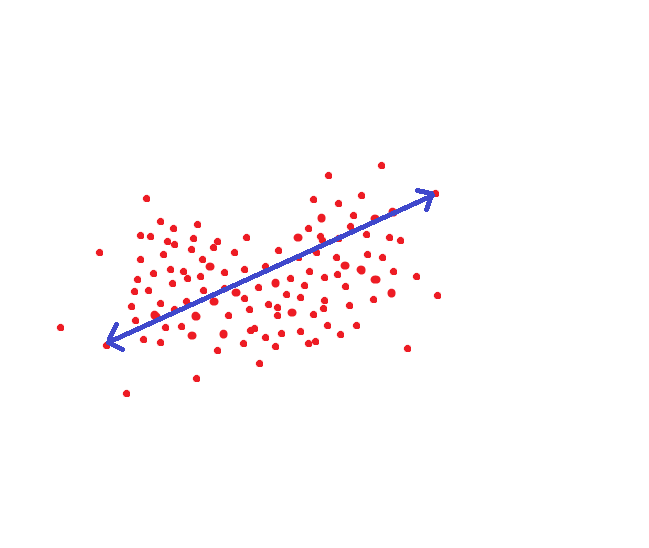
Se formos guiados pelo método adotado pelo NIST, essa distância seria um limite-alvo para que possamos reconhecer uma pessoa como o mesmo indivíduo com uma probabilidade de 95%:
Mas você pode fazer o contrário. Para cada pessoa, configure a área do hiperespaço em que os valores válidos para ela são armazenados:

Então a distância do limiar, mantendo a precisão, diminuirá várias vezes.
Só precisamos de muitas fotos para cada pessoa.
Se uma pessoa tem um perfil nas redes sociais / a base de suas fotos de diferentes idades, a precisão do reconhecimento pode aumentar muito. Não sei a avaliação exata de como o FAR | FRR cresce. E já está incorreto avaliar essas quantidades. Alguém neste banco de dados tem 2 fotos, alguém tem 100. Muita lógica de quebra de linha. Parece-me que a classificação máxima é de um / um e meio pedidos. Isso permite adicionar 10 ^ -7 a erros com probabilidade de não reconhecer 20-30%. Mas é especulativo e otimista.
Em geral, é claro, não há alguns problemas com o gerenciamento desse espaço (chips de idade, chips de editor de imagem, chips de ruído, chips de nitidez), mas pelo que entendi, a maioria deles já foi resolvida com sucesso por grandes empresas que precisavam de uma solução.
Por que estou fazendo isso? Além disso, o uso de perfis permite várias vezes aumentar a precisão dos algoritmos de reconhecimento. Mas está longe de ser absoluto. Os perfis exigem muito trabalho manual. Existem muitas pessoas semelhantes. Mas se você começar a definir restrições sobre idade, local etc., esse método permitirá obter uma boa solução. Para um exemplo de como eles encontraram uma pessoa com o princípio de "encontrar perfil por foto" -> "usar perfil para procurar por uma pessoa", dei um
link no início.
Mas, na minha opinião, este é um processo altamente escalável. E, novamente, pessoas com um grande número de fotos no perfil, Deus proíba 40-50% em nosso país. Sim, e muitos deles são crianças para quem tudo funciona mal.
Mas, novamente - esta é uma avaliação.
Então aqui. Sobre sua segurança. Quanto menos fotos de perfil você tiver, melhor. Quanto maior o rali para onde você for, melhor. Ninguém analisará 20 mil fotos manualmente. Para aqueles que se preocupam com a segurança e a privacidade deles - aconselho você a não criar perfis com suas fotos.
Em um comício em uma cidade com uma centésima milésima população, eles o encontrarão facilmente, observando 1-2 partidas. Em Moscou, eles ficam um pouco presos. Há
cerca de meio ano,
Vasyutka , com quem trabalhamos juntos, falou sobre esse assunto:
By the way, sobre redes sociais
Então me permito fazer uma pequena excursão para o lado. A qualidade do treinamento para o algoritmo de reconhecimento facial depende de três fatores:
- A qualidade do rosto.
- Métrica usada de proximidade de pessoas durante o treinamento Perda de trigêmeos, Perda central, perda esférica, etc.
- Tamanho base
De acordo com a reivindicação 2, parece que o limite foi atingido. Em princípio, a matemática desenvolve essas coisas muito rapidamente. E mesmo após a perda de trigêmeos, o restante das funções de perda não produziu um aumento dramático, apenas uma melhoria suave e uma diminuição no tamanho da base.
A extração de rosto é difícil se você precisar encontrar rostos de todos os ângulos, tendo perdido uma fração de um por cento. Mas criar esse algoritmo é um processo bastante previsível e bem gerenciado. Quanto mais azul estiver tudo, melhores, grandes ângulos serão processados corretamente:

E seis meses atrás, era assim:

Pode-se ver que mais e mais empresas estão se movendo lentamente dessa maneira, algoritmos estão começando a reconhecer cada vez mais faces viradas.
Mas com o tamanho da base - tudo é mais interessante. Bases abertas são pequenas. Boas bases para no máximo algumas dezenas de milhares de pessoas. Os grandes são estranhamente estruturados / ruins (
megaface ,
MS-Celeb-1M ).
Onde você acha que os criadores dos algoritmos conseguiram esses bancos de dados?
Pequena dica. O primeiro produto NTech que eles estão
lançando atualmente é o Find Face, uma pesquisa de pessoas para contato. Eu acho que nenhuma explicação é necessária. Obviamente, contate brigas com bots que esvaziam todos os perfis abertos. Mas, tanto quanto eu ouvi, as pessoas ainda tremem. E colegas de classe. E instagram.
Parece que com o Facebook - tudo é mais complicado lá. Mas tenho quase certeza de que algo também foi inventado.
Então, sim, se o seu perfil estiver aberto - você pode se orgulhar, ele foi usado para aprender algoritmos;)
Sobre soluções e sobre empresas
Aqui você pode se orgulhar. Das 5 principais empresas do mundo, duas são agora russas. Estes são N-Tech e VisionLabs. Há meio ano, NTech e Vocord eram os líderes; o primeiro trabalhava muito melhor em rostos rotacionados, o segundo nos rostos da frente.
Agora, o resto dos líderes - 1-2 empresas chinesas e 1 americana, Vocord foram bem-sucedidas nas classificações.
Ainda russo no ranking de itmo, 3divi, intellivision. A Synesis é uma empresa bielorrussa, embora alguns já estivessem em Moscou, há cerca de três anos eles tinham um blog sobre Habré. Também conheço várias soluções que pertencem a empresas estrangeiras, mas os escritórios de desenvolvimento também estão na Rússia. Ainda existem várias empresas russas que não estão na competição, mas que parecem ter boas soluções. Por exemplo, os ODM têm. Obviamente, Odnoklassniki e Vkontakte também têm seus próprios bons, mas são para uso interno.
Em suma, sim, nós e os chineses somos trocados de rosto.
A NTech em geral foi a primeira no mundo a mostrar bons parâmetros de novos níveis. Em algum lugar no
final de 2015 . O VisionLabs alcançou apenas a NTech. Em 2015, eles eram líderes de mercado. Mas a solução deles era da última geração e eles começaram a tentar alcançar a NTech apenas no final de 2016.
Para ser sincero, não gosto dessas duas empresas. Marketing muito agressivo. Vi pessoas que tinham uma solução claramente inadequada que não solucionava seus problemas.
Neste lado, gostei muito do Vocord. De alguma forma, ele aconselhou os caras a quem Vokord disse honestamente: "seu projeto não funcionará com essas câmeras e pontos de instalação". A NTech e a VisionLabs tentaram vender com satisfação. Mas algo que Vokord desapareceu recentemente.
Conclusões
Nas conclusões, quero dizer o seguinte. . . .
OpenSource . ( ), VisionLabs|Ntech, , . OpenSource .
, , . , . , . , . , — . - .