Já escrevemos no
primeiro artigo do blog corporativo sobre como funciona o algoritmo de detecção de empréstimos transferíveis. Apenas alguns parágrafos desse artigo são dedicados ao tópico de comparar textos, embora a idéia mereça uma descrição muito mais detalhada. No entanto, como você sabe, não se pode contar imediatamente sobre tudo, embora realmente se queira. Em uma tentativa de prestar homenagem a esse tópico e à arquitetura da rede chamada "
codificador automático ", para a qual temos sentimentos muito calorosos,
Oleg_Bakhteev e eu escrevemos essa resenha.

Fonte:
Deep Learning for PNL (sem Magia)Como mencionamos naquele artigo, a comparação dos textos era “semântica” - não comparamos os fragmentos de texto em si, mas os vetores correspondentes a eles. Tais vetores foram obtidos como resultado do treinamento de uma rede neural, que exibia um fragmento de texto de comprimento arbitrário em um vetor de dimensão grande, mas fixa. Como obter esse mapeamento e como ensinar a rede a produzir os resultados desejados é uma questão separada, que será discutida abaixo.
O que é um codificador automático?
Formalmente, uma rede neural é chamada de codificador automático (ou codificador automático), que treina para restaurar objetos recebidos na entrada da rede.
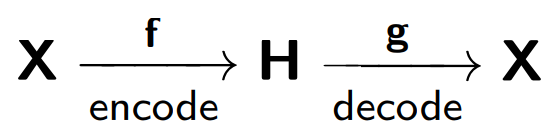
O codificador automático consiste em duas partes: um codificador
f , que codifica a amostra
X em sua representação interna
H , e um decodificador
g , que restaura a amostra original. Portanto, o codificador automático tenta combinar a versão restaurada de cada objeto de amostra com o objeto original.
Ao treinar um codificador automático, a seguinte função é minimizada:
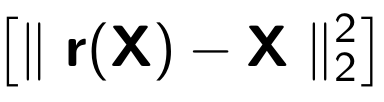
Onde
r representa a versão restaurada do objeto original:

Considere o exemplo fornecido em
blog.keras.io :

A rede recebe um objeto
x como uma entrada (no nosso caso, o número 2).
Nossa rede codifica esse objeto em um estado oculto. Então, de acordo com o estado latente, a reconstrução do objeto
r é restaurada, que deve ser semelhante a x. Como vemos, a imagem restaurada (à direita) ficou mais embaçada. Isso é explicado pelo fato de tentarmos manter em uma visão oculta apenas os sinais mais importantes do objeto, para que o objeto seja restaurado com perdas.
O modelo do codificador automático é treinado no princípio de um telefone danificado, em que uma pessoa (codificador) transmite informações
(x ) para a segunda pessoa (decodificador
) e, por sua vez, o informa à terceira
(r (x)) .
Um dos principais objetivos desses codificadores automáticos é reduzir a dimensão do espaço de origem. Quando estamos lidando com codificadores automáticos, o próprio procedimento de treinamento de rede neural faz com que o codificador automático se lembre das principais características dos objetos a partir dos quais será mais fácil restaurar os objetos de amostra originais.
Aqui, podemos fazer uma analogia com o
método dos componentes principais : este é um método para reduzir a dimensão, cujo resultado é a projeção da amostra em um subespaço no qual a variação dessa amostra é máxima.
De fato, o codificador automático é uma generalização do método do componente principal: no caso em que nos restringimos à consideração de modelos lineares, o método do codificador automático e do componente principal fornece as mesmas representações vetoriais. A diferença surge quando consideramos modelos mais complexos, por exemplo, redes neurais multicamadas totalmente conectadas, como codificador e decodificador.
Um exemplo de comparação do método do componente principal e do codificador automático é apresentado no artigo
Reduzindo a dimensionalidade dos dados com redes neurais :
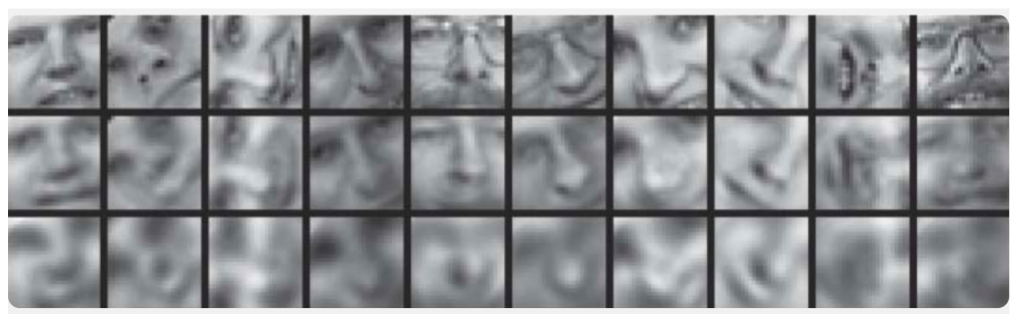
Aqui, são demonstrados os resultados do treinamento do codificador automático e o método do componente principal para amostragem de imagens de rostos humanos. A primeira linha mostra os rostos das pessoas da amostra de controle, ou seja, de uma parte especialmente diferida da amostra que não foi usada pelos algoritmos no processo de aprendizado. Na segunda e terceira linhas estão as imagens restauradas dos estados ocultos do codificador automático e do método do componente principal, respectivamente, da mesma dimensão. Aqui você pode ver claramente quanto melhor o codificador automático funcionou.
No mesmo artigo, outro exemplo ilustrativo: comparando os resultados do codificador automático e o método
LSA para a tarefa de recuperação de informações. O método LSA, como o método do componente principal, é um método clássico de aprendizado de máquina e é frequentemente usado em tarefas relacionadas ao processamento de linguagem natural.

A figura mostra uma projeção 2D de vários documentos obtidos usando o codificador automático e o método LSA. As cores indicam o tema do documento. Pode-se ver que a projeção do codificador automático divide bem os documentos por tópico, enquanto o LSA produz um resultado muito mais barulhento.
Outra aplicação importante dos auto-
codificadores é o pré-treinamento da rede . O pré-treinamento da rede é usado quando a rede otimizada é profunda o suficiente. Nesse caso, o treinamento da rede "do zero" pode ser bastante difícil, portanto, primeiro toda a rede é representada como uma cadeia de codificadores.
O algoritmo de pré-treinamento é bastante simples: para cada camada, treinamos nosso próprio codificador automático e depois definimos que a saída do próximo codificador é simultaneamente a entrada para a próxima camada de rede. O modelo resultante consiste em uma cadeia de codificadores treinados para preservar ansiosamente os recursos mais importantes dos objetos, cada um em sua própria camada. O esquema de pré-treinamento é apresentado abaixo:
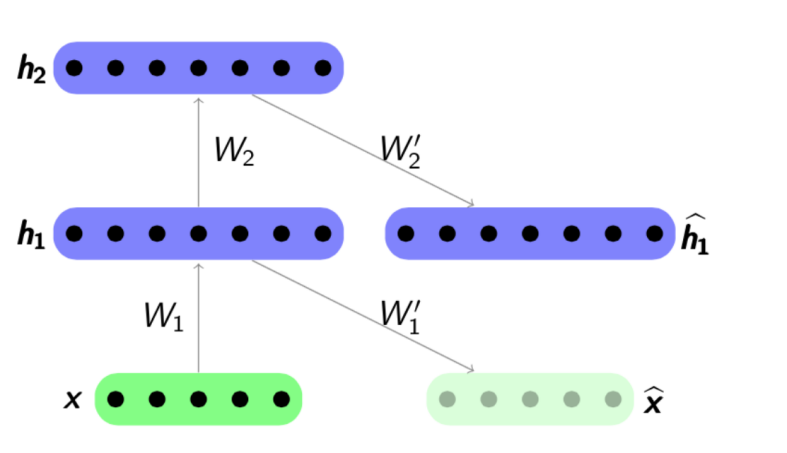
Fonte:
psyyz10.imtqy.comEssa estrutura é denominada Autoencoder empilhado e é frequentemente usada como "overclocking" para treinar ainda mais o modelo de rede completo e profundo. A motivação para esse treinamento de uma rede neural é que uma rede neural profunda é uma função não convexa: no processo de treinamento de uma rede, a otimização dos parâmetros pode "ficar presa" no mínimo local. O pré-treinamento ganancioso dos parâmetros de rede permite encontrar um bom ponto de partida para o treinamento final e, assim, tentar evitar esses mínimos locais.
Obviamente, não consideramos todas as estruturas possíveis, porque existem
Autoencodificadores Esparsos ,
Autoencodificadores Denoising ,
Autoencoder Contrativo ,
Autoencoder Contrativo de Reconstrução . Eles diferem entre si usando várias funções de erro e termos de penalidade para eles. Todas essas arquiteturas, em nossa opinião, merecem uma revisão separada. Em nosso artigo, mostramos, antes de tudo, o conceito geral de codificadores automáticos e as tarefas específicas de análise de texto que são resolvidas usando-o.
Como isso funciona nos textos?
Passamos agora a exemplos específicos do uso de autocoders para tarefas de análise de texto. Estamos interessados em ambos os lados da aplicação - nos dois modelos para obter representações internas e no uso dessas representações internas como atributos, por exemplo, no problema de classificação adicional. Os artigos sobre esse tópico costumam abordar tarefas como análise de sentimentos ou detecção de reformulação, mas também existem trabalhos que descrevem o uso de codificadores automáticos para comparar textos em diferentes idiomas ou para tradução automática.
Nas tarefas de análise de texto, na maioria das vezes o objeto é a frase, ou seja, sequência ordenada de palavras. Assim, o codificador automático recebe exatamente essa sequência de palavras, ou melhor, representações vetoriais dessas palavras extraídas de algum modelo previamente treinado. O que são representações vetoriais de palavras, foi considerado em Habré em detalhes suficientes, por exemplo
aqui . Assim, o codificador automático, tomando uma sequência de palavras como entrada, deve treinar alguma representação interna de toda a sentença que atenda às características que são importantes para nós, com base na tarefa. Em problemas de análise de texto, precisamos mapear sentenças para vetores para que elas fiquem próximas no sentido de alguma função de distância, geralmente uma medida de cosseno:
Fonte:
Deep Learning for PNL (sem Magia)Um dos primeiros autores a mostrar o uso bem-sucedido de codificadores automáticos na análise de texto foi
Richard Socher .
Em seu artigo
Pool dinâmico e desdobramento de auto-codificadores recursivos para detecção de parafrase, ele descreve uma nova estrutura de autocodificação - Desdobramento de autoencoder recursivo (desdobramento do RAE) (veja a figura abaixo).

Revelação do RAE
Supõe-se que a estrutura da sentença seja definida por um
analisador sintático . A estrutura mais simples é considerada - a estrutura de uma árvore binária. Essa árvore consiste em folhas - palavras de um fragmento, nós internos (nós de ramificação) - frases e um vértice terminal. Tomando a sequência de palavras (x
1 , x
2 , x
3 ) como entrada (três representações vetoriais de palavras neste exemplo), o codificador automático sequencialmente codifica, nesse caso, da direita para a esquerda, representações vetoriais de palavras de sentença em representações vetoriais de colocações e depois em vetor Apresentação de toda a oferta. Especificamente neste exemplo, primeiro concatenamos os vetores x
2 e x
3 e depois os multiplicamos pela matriz
. Temos a dimensão
oculta × 2 visível , onde
oculto é onde o tamanho da representação interna oculta,
visível , é a dimensão do vetor de palavras. Assim, reduzimos a dimensão e adicionamos não linearidade usando a função tanh. No primeiro passo, obtemos uma representação vetorial oculta para a frase duas palavras
x 2 ex 3 :
h 1 =
tanh (W e [x 2 , x 3 ] + b e ) . No segundo, combinamos a palavra restante
h 2 =
tanh (W e [h 1 , x 1 ] + b e ) e obtemos uma representação vetorial para toda a sentença -
h 2 . Como mencionado acima, na definição de um codificador automático, precisamos minimizar o erro entre os objetos e suas versões restauradas. No nosso caso, são palavras. Portanto, tendo recebido a representação vetorial final de toda a sentença
h 2 , decodificaremos suas versões restauradas (x
1 ', x
2 ', x
3 '). O decodificador aqui funciona com o mesmo princípio que o codificador, apenas a matriz de parâmetros e o vetor shift são diferentes aqui:
W d e
b d .
Usando a estrutura de uma árvore binária, você pode codificar sentenças de qualquer comprimento em um vetor de dimensão fixa - sempre combinamos um par de vetores da mesma dimensão, usando a mesma matriz de parâmetros
W e . No caso de uma árvore não binária, você só precisa inicializar as matrizes antecipadamente se quisermos combinar mais de duas palavras - 3, 4, ... n, nesse caso, a matriz terá apenas a dimensão
oculta × invisível .
Vale ressaltar que, neste artigo, representações vetoriais treinadas de frases são usadas não apenas para resolver o problema de classificação - algumas frases são reformuladas ou não. Os dados de um experimento na pesquisa dos vizinhos mais próximos também são apresentados - com base apenas no vetor de oferta recebido, são pesquisados os vetores mais próximos da amostra que estão próximos a ele no significado:

No entanto, ninguém nos incomoda em usar outras arquiteturas de rede para codificar e decodificar para combinar sequencialmente palavras em frases.
Aqui está um exemplo de um artigo do NIPS 2017 -
Aprendizado de representação de parágrafos deconvolucionais :

Vemos que a codificação da amostra
X na representação oculta
h ocorre usando uma
rede neural convolucional , e o decodificador trabalha com o mesmo princípio.
Ou aqui está um exemplo usando
GRU-GRU no artigo
Vetores de reflexão.
Uma característica interessante aqui é que o modelo trabalha com triplas frases: (
s i-1 , s i , s i + 1 ). A sentença si é codificada usando fórmulas GRU padrão, e o decodificador, usando as informações de representação interna si, tenta decodificar si
-1 e si
+ 1 , também usando GRU.

O princípio de operação neste caso se assemelha ao modelo padrão de
tradução automática de rede neural , que funciona de acordo com o esquema de codificador-decodificador. No entanto, aqui não temos dois idiomas, enviamos uma frase em um idioma para a entrada da nossa unidade de codificação e tentamos restaurá-la. No processo de aprendizagem, há uma minimização de alguma qualidade funcional interna (isso nem sempre é um erro de reconstrução); então, se necessário, vetores pré-treinados são usados como características em outro problema.
Outro artigo,
Autoencodificadores recursivos por correspondência bilíngüe para tradução automática estatística , apresenta uma arquitetura que dá uma nova olhada na tradução automática. Primeiro, para dois idiomas, os autocoders recursivos são treinados separadamente (de acordo com o princípio descrito acima - onde o Unfolding RAE foi introduzido). Então, entre eles, um terceiro codificador automático é treinado - um mapeamento entre dois idiomas. Essa arquitetura tem uma clara vantagem - ao exibir textos em diferentes idiomas em um espaço oculto comum, podemos compará-los sem usar a tradução automática como uma etapa intermediária.
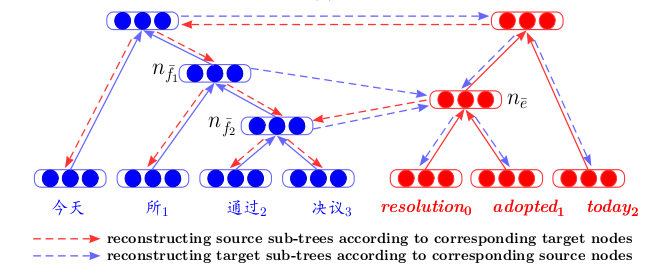
O treinamento de codificadores automáticos em fragmentos de texto é frequentemente encontrado em artigos sobre
classificação de treinamento . Aqui, novamente, o fato de estarmos treinando a funcionalidade final da qualidade da classificação é importante, primeiro treinamos o codificador automático para inicializar melhor os vetores de solicitações e respostas enviadas à entrada da rede.

E, é claro, não podemos deixar de mencionar
Autoencoders Variacionais , ou
VAEs , como modelos generativos. É melhor, é claro, apenas assistir a
esta palestra da Yandex . Basta dizer o seguinte: se queremos
gerar objetos a partir do espaço oculto de um codificador automático convencional, a qualidade dessa geração será baixa, pois não sabemos nada sobre a distribuição da variável oculta. Mas você pode treinar imediatamente o codificador automático para gerar, introduzindo uma suposição de distribuição.
E, usando o VAE, você pode gerar textos a partir desse espaço oculto, por exemplo, como
fazem os autores do artigo
Gerando Sentenças a partir de um Espaço Contínuo ou
Um Autoencoder Variacional Convolucional Híbrido para Geração de Texto .
As propriedades generativas do VAE também funcionam bem em tarefas que comparam textos em diferentes idiomas -
Uma abordagem de auto-codificação variacional para induzir intercambios de palavras em vários idiomas
é um excelente exemplo disso.
Como conclusão, queremos fazer uma pequena previsão.
Aprendizado de representação - o treinamento em representações internas usando exatamente o VAE, especialmente em conjunto com as
Redes Adversárias Generativas , é uma das abordagens mais desenvolvidas nos últimos anos - isso pode ser julgado pelo menos pelos tópicos mais comuns dos artigos nas últimas principais
conferências de aprendizado de máquina da
ICLR 2018 e
ICML 2018 . Isso é bastante lógico - porque seu uso ajudou a melhorar a qualidade em várias tarefas, e não apenas em textos. Mas este é o tópico de uma revisão completamente diferente ...