Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3Palestra 4: “Separação de Privilégios”
Parte 1 /
Parte 2 /
Parte 3 Então, o que mais tínhamos nessa lista? Processos. A memória é algo que acontece simultaneamente com o processo. Portanto, se você não estiver nesse processo, não poderá acessar sua memória. A memória virtual aprimora perfeitamente esse isolamento para nós. Além disso, o mecanismo de depuração permite "pop" na memória de outro processo, se você tiver o mesmo ID do usuário
Em seguida, temos a rede. As redes no
Unix não correspondem exatamente ao modelo descrito acima, em parte devido ao fato de o
sistema operacional
Unix ter sido desenvolvido pela primeira vez e, em seguida, aparecer uma rede, que logo se tornou popular. Tem um conjunto de regras ligeiramente diferente. Portanto, as operações que realmente precisamos cuidar estão conectando alguém à rede se você gerencia a rede ou escutando alguma porta se você atua como servidor. Pode ser necessário ler ou gravar dados nessa conexão ou enviar e receber pacotes
brutos .

Assim, as redes no
Unix não são relacionadas à
identificação do
usuário . As regras são que qualquer pessoa sempre pode conectar-se a qualquer máquina ou endereço IP ou abrir uma conexão. Se você deseja escutar em uma porta, nesse caso, há uma diferença: a maioria dos usuários está proibida de escutar portas com um número abaixo do "valor mágico" de 1024. Em princípio, você pode escutar essas portas, mas nesse caso você deve Seja um usuário especial chamado
"superusuário" com
uid = 0 .
Em geral, no Unix, existe o conceito de administrador ou superusuário, representado pelo identificador uid = 0, que pode ignorar quase todas essas verificações; portanto, se você trabalha com direitos de root, pode ler e gravar arquivos, alterar os direitos de acesso a eles. O sistema operacional permitirá que você faça isso porque acha que você deve ter todos os privilégios. E você realmente precisa de tais privilégios para ouvir em portas com número <1024. O que você acha dessa restrição tão estranha?
Público: identifica números de porta específicos para conexões específicas, por exemplo, para
http na porta 80.
Professor: sim, por padrão, o
protocolo HTTP usa a porta 80. Por outro lado, outros serviços podem usar portas com um número maior que 1024, por que essa restrição é necessária? Qual é a utilidade aqui?
Público: porque você não deseja que ninguém escute acidentalmente seu
HTTP .
Professor: sim. Eu acho que a razão para isso é que você costumava ter muitos usuários na mesma máquina. Eles efetuaram login com seus logins, lançaram seus aplicativos, para que você desejasse ter certeza de que algum usuário aleatório, tendo efetuado login no computador, não seria capaz de se apossar do servidor Web em execução. Como os usuários que se conectam de fora não sabem quem trabalha nessa porta e apenas se conectam à porta 80. Se eu quiser entrar nesta máquina e iniciar meu próprio servidor da Web, transfiro todo o tráfego do servidor da Web para esse carro. Esse provavelmente não é um plano muito bom, mas é o modo como o subsistema de rede Unix impede que usuários aleatórios controlem serviços conhecidos executados nesses números de porta baixos. Essa é a lógica de tal limitação.

Além disso, do ponto de vista da leitura e gravação de dados de conexão, se você tiver um arquivo descritor para um soquete específico, o
Unix permitirá que você leia e
grave quaisquer dados nessa
conexão TCP ou
uTP . Ao enviar pacotes
brutos , o
Unix se comporta como um paranóico, portanto não permite o envio de pacotes arbitrários pela rede. Isso deve estar dentro do contexto da conexão especial, a menos que você tenha o
root - o certo e você possa fazer o que quiser.
Então, uma pergunta interessante que você poderia fazer é de onde vêm todos esses
IDs de usuário ?
Estamos falando de processos com
userid ou
groupid . Ao iniciar o
PS no seu computador, você definitivamente verá uma série de processos com diferentes valores de
uid . De onde eles vieram?
Precisamos de algum mecanismo para carregar todos esses valores de
ID do
usuário .
O Unix possui várias chamadas de sistema projetadas para isso. Portanto, para inicializar esses valores de identificador, existe uma função chamada
setuid (uid) , para que você possa atribuir o número de
uid de algum processo atual a esse valor. Esta é realmente uma operação perigosa, como tudo na tradição do
Unix , porque você só pode fazer isso se o seu
uid = 0 . De qualquer forma, deve ser assim.
Portanto, se você é um usuário com direitos de root e possui
uid = 0 , pode chamar
setuid (uid) e alternar o usuário para qualquer processo. Existem algumas outras chamadas de sistema semelhantes para inicializar o
gid relacionado ao processo: são
setgid e
setgroups . Portanto, essas chamadas do sistema permitem configurar privilégios de processo.

O fato de seus processos obterem os direitos de acesso corretos quando você efetua login na máquina
Unix não ocorre porque você tem o mesmo
ID dos processos, porque o sistema ainda não sabe quem você é. Em vez disso, no
Unix, existe algum tipo de procedimento de login quando o
protocolo shell seguro
SSH inicia o processo para qualquer pessoa que se conecta ao computador e tenta autenticar o usuário.
Portanto, inicialmente esse processo de login começa com
uid = 0, como para um usuário com direitos de root, e quando recebe um nome de usuário e senha específicos, ele os verifica em seu próprio banco de dados de contas. Como regra, no
Unix, esses dados são armazenados em dois arquivos:
/ etc / password (por razões históricas, as senhas não são mais armazenadas nesse arquivo) e no arquivo
/ etc / shadow , no qual as senhas são armazenadas. No entanto, há uma tabela no arquivo
/ etc / password que exibe cada nome de usuário no sistema como um valor inteiro.
Portanto, seu nome de usuário é mapeado para um número inteiro específico neste arquivo
/ etc / password e, em seguida, o processo de login verifica se sua senha está correta de acordo com este arquivo. Se encontrar seu
uid inteiro, ele definirá as funções
setuid para esse valor de
uid e iniciará o shell com o comando
exec (/ bin / sh) . Agora você pode interagir com o shell, mas ele funciona sob o seu
uid ; portanto, você não poderá causar danos acidentais a esta máquina.
 Público: é
Público: é possível iniciar um novo processo com
uid = 0 se o seu
uid não for realmente 0?
Professor: se você tiver privilégios de root, poderá se limitar a outro
uid , diminuir sua autoridade, mas, em qualquer caso, poderá criar um processo com apenas o mesmo
uid que o seu. Mas acontece que, por várias razões, você deseja aumentar seus privilégios. Suponha que você precise instalar um pacote, para o qual você precisa de privilégios de
root .
Existem duas maneiras de definir privilégios no
Unix . Um que já mencionamos é um descritor de arquivo. Portanto, se você realmente deseja aumentar seus privilégios, pode conversar com alguém que trabalha com direitos de root e pedir que ele abra esse arquivo para você. Ou você precisa instalar uma nova interface, esse assistente abre um arquivo para você e retorna um descritor de arquivo para você usando a transferência
fd . Essa é uma maneira de aumentar seus privilégios, mas é inconveniente porque, em alguns casos, existem processos em execução com um grande número de privilégios. Para isso, o
Unix possui um mecanismo inteligente, mas ao mesmo tempo problemático, chamado
"binários setuid" . Esse mecanismo é executável regularmente em um
sistema de arquivos
Unix , exceto quando você executa
exec no binário
setuid , por exemplo,
/ bin / su na maioria das máquinas, ou
sudo , na inicialização.
Um sistema
Unix típico possui um monte de binários
setuid . A diferença é que, quando você executa um desses binários, na verdade, ele alterna a
identificação do usuário do processo para o proprietário desse binário. Esse mecanismo parece estranho quando você o vê pela primeira vez. Como regra, as maneiras de usá-lo são que esse “binário” provavelmente possui um proprietário
de 0, porque você realmente deseja restaurar muitos privilégios.

Você deseja restaurar os direitos do superusuário para poder executar este comando
su , e o kernel, ao executar esse binário, alternará o processo
uid para 0, para que este programa agora execute algumas coisas privilegiadas.
Público: se você tiver
uid = 0 e alterar o
uid de todos esses binários
setuid para algo diferente de 0, poderá restaurar seus privilégios?
Professor: não, muitos processos não poderão restaurar privilégios ao diminuir o nível de acesso; portanto, você pode ficar preso nesse local. Este mecanismo não está vinculado a
uid = 0 . Como qualquer usuário de um sistema
Unix , você pode criar qualquer arquivo binário, criar um programa, compilá-lo e definir esse bit
setuid para o próprio programa. Pertence a você, usuário, seu ID de usuário. E isso significa que qualquer pessoa que execute seu programa executará esse código com seu ID de usuário. Existe algum problema com isso? O que precisa ser feito?
Público: ou seja, se houve um erro no seu aplicativo, alguém poderia fazer algo com ele, agindo com seus privilégios?
Professor: certo, isso acontece se meu aplicativo for "buggy" ou se permitir que você execute tudo o que deseja. Suponha que eu possa copiar o shell do sistema e
defini- lo para mim, mas qualquer um pode executar esse shell na minha conta. Este provavelmente não é o melhor plano de ação. Mas esse mecanismo não cria um problema, porque a única pessoa que pode definir o bit
setuid em um arquivo binário é o proprietário desse arquivo. Você, como proprietário do arquivo, tem o privilégio
uid , para poder transferir sua conta para outra pessoa, mas essa outra pessoa não poderá criar o binário
setuid com seu
ID do usuário .
Esse bit setuid é armazenado próximo a esses bits de permissão, ou seja, em cada
inode também há um bit
setuid que diz se esse arquivo executável deve ou se o programa mudou para o proprietário
uid durante a execução.
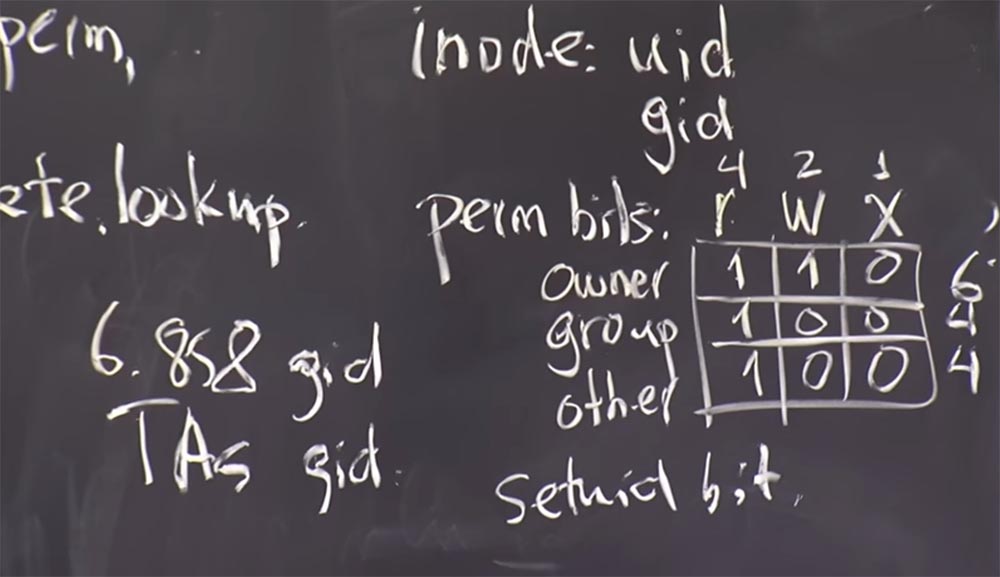
Acontece que este é um mecanismo muito complicado quando usado corretamente e, graças a ele, o kernel implementa o programa corretamente. Na verdade, isso é bastante fácil de fazer, porque apenas uma verificação é realizada: se esse bit
setuid existe, o processo muda para
uid . É bem simples.
Mas usá-lo com segurança é bastante difícil, porque, como acabamos de indicar, se este programa contém erros ou faz algo inesperado, você pode fazer coisas arbitrárias sob
uid = 0 ou sob qualquer outro
uid . No
Unix, quando você executa um programa, herda muitas coisas do processo pai.
Por exemplo, você pode passar variáveis de ambiente para binários
setuid . O fato é que, no
Unix, você pode especificar qual biblioteca compartilhada usar para o processo, definindo a variável de ambiente, e os binários
setuid não se importam em filtrar essas variáveis de ambiente.
Por exemplo, você pode executar o
bin / su , mas use bibliotecas compartilhadas para a função
printf , para que o
printf inicie quando o
bin / su imprimir alguma coisa e você possa executar o shell em vez de o printingf.
Existem muitas sutilezas que você deve entender corretamente em relação à desconfiança do programa com os dados inseridos pelo usuário. Como você geralmente confia na entrada do usuário, o
setuid nunca foi a parte mais segura de um sistema
Unix inteiro. Tem perguntas sobre isso?
Público: o
setuid também se aplica a grupos ou apenas ao usuário?
Professor: existe um bit
setgid simétrico ao bit
setuid , que você também pode definir. Se o arquivo tiver um
gid específico e esse bit
setgid estiver definido quando o programa for iniciado, você o receberá.
O Setgid não
é particularmente usado, mas pode ser útil nos casos em que você deseja fornecer privilégios muito específicos. Por exemplo, o
bin / su provavelmente precisa de muitos privilégios, mas talvez haja algum programa que precise de alguns privilégios extras, por exemplo, para gravar algo em um arquivo de log especial. Portanto, você provavelmente deseja fornecer a ela um determinado grupo e criar um arquivo de log que seja gravável por esse grupo. Portanto, mesmo que o programa seja "buggy", você não perderá nada além deste grupo. Isso é útil como um mecanismo que, por algum motivo, não é usado com muita frequência, porque, afinal, as pessoas devem usar mais os direitos de root.
Público: existem restrições sobre quem pode alterar o acesso?
Professor: sim. Implementações diferentes do
Unix têm verificações diferentes para isso. A regra geral é que apenas o root pode alterar o proprietário do arquivo, porque você não deseja criar arquivos que pertencerão a outra pessoa e, é claro, não deseja se apropriar dos arquivos de outras pessoas. Portanto, se o seu
uid não
for 0, você estará preso. Você não pode alterar a propriedade de nenhum arquivo. Se seu
uid = 0 , você possui privilégios de root e pode alterar o proprietário para qualquer um. Existem algumas complicações se você tiver um
setuid binário e mudar de um
uid para outro, isso é bastante complicado, mas basicamente você não pode alterar o proprietário do arquivo se não tiver privilégios de root.
Por todas as contas, este é um sistema um pouco desatualizado. Você provavelmente poderia imaginar várias maneiras de simplificar os processos descritos acima, mas, na verdade, os sistemas mais avançados se parecem com isso porque evoluem com o tempo. Mas você pode usar perfeitamente esses mecanismos como uma "caixa de areia".
Estes são apenas alguns tipos de princípios básicos do
Unix , que aparecem em quase todos os sistemas operacionais do tipo Unix:
Mac OS X ,
Linux ,
FreeBSD ,
Solaris , se alguém o usa, e assim por diante. Mas cada um desses sistemas possui mecanismos mais sofisticados que você pode usar. Por exemplo, no
Linux, existe um conjunto de "sandbox"
COMP , o
Mac OS X usa o cinto de
segurança "sandbox". Na próxima semana, darei exemplos de caixas de proteção disponíveis em todos os sistemas baseados em
Unix .
Portanto, um dos últimos mecanismos, que consideraremos antes de mergulhar no
OKWS , explica como você precisa lidar com binários
setuid e mostra como você pode se proteger contra falhas de segurança existentes. O problema é que você inevitavelmente terá alguns binários
setuid no seu sistema, como
/ bin / su ou
sudo ou qualquer outra coisa, e é provável que seus programas apresentem erros. Por isso, alguém poderá executar o binário
setuid e o processo poderá obter acesso
root , o que você não deseja permitir.

O mecanismo
Unix , que geralmente é usado para impedir a execução de um processo potencialmente malicioso usando binários
setuid , é usar o namespace do sistema de arquivos para alterá-lo usando a chamada do sistema
chroot , a operação de alterar o diretório raiz.
O OKWS , como servidor da web especializado na criação de serviços da web rápidos e seguros, usa isso amplamente.

Então, no
Unix, você pode executar
chroot em um diretório específico, então talvez você também possa executar
chroot ("/ foo") .
Existem 2 explicações para o que o
chroot faz. O primeiro é apenas intuitivo, significa que, após executar o
chroot , o diretório raiz ou o diretório localizado atrás da barra é basicamente equivalente ao que
/ foo usou antes de você chamar
chroot . Parece limitar o namespace abaixo do seu
/ foo . Portanto, se você tem um arquivo que costumava ser chamado
/ foo / x , depois de chamar o
chroot, pode obtê-lo simplesmente abrindo
/ x . Portanto, basta limitar seu espaço para nome a um subdiretório. Aqui está o que é a versão intuitiva.

Obviamente, em segurança, não é a versão intuitiva que importa, mas o que exatamente o kernel faz com essa chamada de sistema? E faz basicamente duas coisas. Primeiro, ele altera o valor dessa barra, portanto, sempre que você acessa ou inicia o nome do diretório com uma barra, o kernel inclui qualquer arquivo que você forneceu nas operações
chroot . No nosso exemplo, este é o arquivo
/ foo antes de você chamar
chroot , ou seja, obtemos esse
/ = / foo .

A próxima coisa que o kernel tentará fazer é protegê-lo de ser capaz de "escapar" do seu
/ se você fizer
/../ . Porque no
Unix, eu poderia pedir que você me desse, por exemplo,
/../etc/password . Portanto, se eu apenas suplementasse essa linha assim:
/foo/../etc/password , isso não seria bom, porque eu poderia simplesmente sair do
/ foo e continuar com o
/ etc / password .
A segunda coisa que o kernel faz com uma chamada de sistema
Unix é que, quando você chama
chroot para esse processo específico, ele muda a maneira como
/../ é avaliado neste diretório. Portanto, modifica
/../ para que
/ foo aponte para si mesmo. Portanto, isso não permite que você "escape", e essa alteração se aplica apenas a esse processo e não afeta o resto. Que idéias você tem sobre como "escapar" do ambiente
chroot usando como ele é implementado?
Curiosamente, o kernel monitora apenas um diretório
chroot , então você provavelmente pode executar a operação
chroot = (/ foo) , mas você estaria preso a esse local. Então você quer obter o
/ etc / password , mas como fazê-lo? Você pode abrir o diretório raiz agora mesmo, digitando
abrir (* / *) . Isso fornecerá um descritor de arquivo descrevendo o que é
/ foo . Então você pode chamar
chroot novamente e executar
chroot (`/ bar) .

, :
root /foo ,
/foo/bar /../ /foo / bar/..
,
/foo .
fchdir (fd) (*/*) ,
chdir (..) .

 /foo
/foo ,
/../ .
/foo ,
root , .
, , . .
Unix root-
chroot ,
chroot . ,
Unix uid = 0 ,
chroot . . , ,
chroot ,
userid . ,
Unix , ,
root , .
, , , .
chroot — . .
: ,
inod , ?
: ! , , , : «
inode 23», -
hroot . ,
Unix inode inode , , , root-.
, , ,
OKWS . ,
OKWS .
, -, , - , . , ,
httpd , ,
Apache .
userid www /etc/password . , ,
SSL ,
PHP , . , , ,
MySQL , .
MySQL .
MySQL , , , .
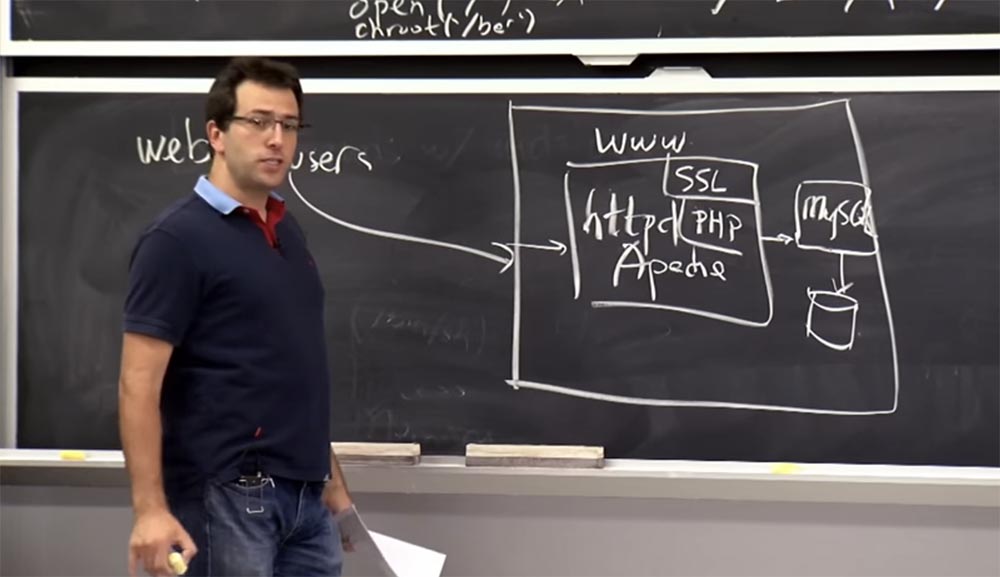
, , ,
MySQL , , .
, , , , . , , ,
Apache , SSL ou talvez no código do aplicativo ou no interpretador PHP . E, como existem erros, você pode usá-los para obter todo o conteúdo do aplicativo.52:30 minContinuação:Curso MIT "Segurança de sistemas de computadores". Palestra 4: “Compartilhando Privilégios”, Parte 2A versão completa do curso está disponível aqui .Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?