Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3Palestra 4: “Separação de Privilégios”
Parte 1 /
Parte 2 /
Parte 3Palestra 5: “De onde vêm os sistemas de segurança?”
Parte 1 /
Parte 2Palestra 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Palestra 7: “Sandbox do Cliente Nativo”
Parte 1 /
Parte 2 /
Parte 3 Público: por que o intervalo de capacidade da memória do intervalo de endereços deve começar do zero?
Professor: porque em termos de desempenho, é mais eficiente usar o salto de destino se você souber que um endereço válido é um conjunto contínuo de endereços começando do zero. Porque então você pode fazer isso com uma única máscara
AND , onde todos os bits altos são um e apenas um par de bits baixos é zero.
Público: Eu pensei que a máscara
AND deveria fornecer alinhamento.
Professor: certo, a máscara fornece alinhamento, mas por que começa do zero? Eu acho que eles confiam no
hardware segmentado por hardware de segmentação. Então, basicamente, eles poderiam usá-lo para mover a área para cima, em termos de espaço linear. Ou talvez esteja relacionado apenas ao modo como o aplicativo "vê" esse intervalo. De fato, você pode colocá-lo com diferentes compensações no seu espaço de endereço virtual. Isso permitirá que você execute certos truques com hardware segmentado para executar vários módulos no mesmo espaço de endereço.
 Público:
Público: Talvez seja porque eles querem "capturar" o ponto de recebimento do ponteiro nulo?
Professor: sim, porque eles querem pegar todos os pontos de recepção. Mas você tem uma maneira de fazer isso. Porque o ponteiro nulo se refere ao segmento que está sendo acessado. E se você mover o segmento, poderá exibir uma página zero não utilizada no início de cada segmento. Portanto, isso ajudará a criar alguns módulos.
Eu acho que uma das razões para essa decisão - iniciar o intervalo de 0 - se deve ao desejo de portar seu programa para a plataforma
x64 , que tem um design um pouco diferente. Mas o artigo deles não diz isso. No design de 64 bits, o próprio equipamento se livrou de algum hardware de segmentação, no qual eles contavam por razões de eficiência, então eles tiveram que fornecer uma abordagem orientada a software. No entanto, para
x32, esse ainda não é um bom motivo para o espaço começar do zero.
Portanto, continuamos a questão principal - o que queremos garantir do ponto de vista da segurança. Vamos abordar esse assunto de forma um tanto "ingênua" e ver como podemos arruinar tudo e depois tentar consertá-lo.
Acredito que um plano ingênuo é procurar instruções proibidas simplesmente digitalizando o executável do começo ao fim. Então, como você pode identificar essas instruções? Você pode simplesmente pegar o código do programa e colocá-lo em uma linha gigante que varia de zero a 256 megabytes, dependendo do tamanho do seu código, e então iniciar a busca.

Essa linha pode primeiro conter o módulo de instruções
NOP , depois o módulo de instruções
ADD ,
NOT ,
JUMP e assim por diante. Você apenas procura e, se encontrar uma instrução incorreta, diga que é um módulo inválido e descarte-o. E se você não vir nenhuma chamada do sistema para esta instrução, poderá ativar o lançamento deste módulo e fazer tudo dentro do intervalo de 0 a 256. Você acha que isso vai funcionar ou não? Com o que eles estão preocupados? Por que isso é tão difícil?
Público: Eles estão preocupados com o tamanho das instruções?
Professor: sim, o fato é que a plataforma
x86 possui instruções de tamanho variável. Isso significa que o tamanho exato da instrução depende dos primeiros bytes desta instrução. De fato, você pode observar o primeiro byte para dizer que a instrução será muito maior e, em seguida, talvez seja necessário observar mais alguns bytes e decidir qual tamanho será necessário. Algumas arquiteturas como
Spark ,
ARM ,
MIPS têm instruções de comprimento mais fixo.
O ARM possui dois comprimentos de instrução - 2 ou 4 bytes. Mas na plataforma
x86, o comprimento das instruções pode ser de 1, 5 e 10 bytes e, se você tentar, poderá obter uma instrução bastante longa de 15 bytes. No entanto, estas são instruções complexas.
Como resultado, um problema pode aparecer. Se você digitalizar esta linha de código linearmente, tudo ficará bem. Mas talvez em tempo de execução você vá para o meio de algum tipo de instrução, por exemplo,
NÃO .

É possível que seja uma instrução multibyte e, se você a interpretar a partir do segundo byte, ela parecerá completamente diferente.
Outro exemplo no qual vamos "brincar" com o assembler. Suponha que tenhamos a instrução
25 CD 80 00 00 . Tendo examinado o segundo byte, você o interpretará como uma instrução de cinco bytes, ou seja, terá que olhar 5 bytes para frente e ver que é seguido pela instrução
AND% EAX, CD 0x00 00 80 , começando com o operador
AND para o registro
EAX com alguns constantes definidas, por exemplo,
00 00 80 CD . Esta é uma das instruções seguras que o
Native Client deve simplesmente permitir pela primeira regra de verificação de instruções binárias. Mas se, durante a execução do programa, a
CPU decidir que deve começar a executar o código do
CD , marcarei este local da instrução com uma seta, então a instrução
% EAX, 0x00 00 80 CD , que na verdade é uma instrução de 4 bytes, significará a execução do
INT $ 0x80 , que é uma maneira de fazer uma chamada de sistema no
Linux .
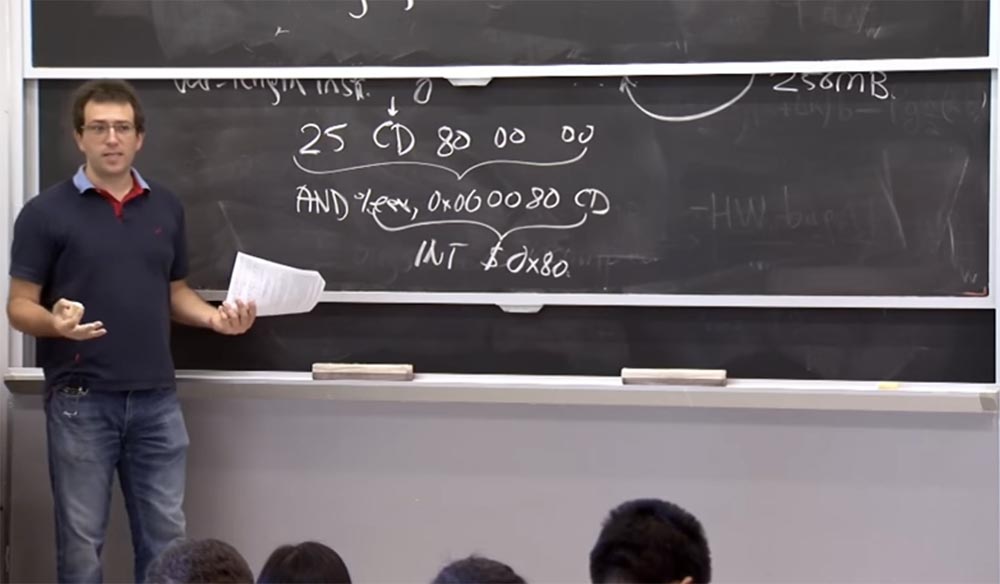
Portanto, se você perder esse fato, deixe o módulo não confiável "pular" no kernel e fazer chamadas ao sistema, ou seja, faça o que você deseja impedir. Como podemos evitar isso?
Talvez devêssemos tentar observar o deslocamento de cada byte. Como o x86 pode começar a interpretar apenas uma instrução nos limites de bytes, não de bits. Portanto, você deve observar o deslocamento de cada byte para ver onde a instrução começa. Você acha que esse é um plano viável?
Público: Eu acho que se alguém realmente usa
AND , o processador não salta para este local, mas simplesmente permite que o programa seja executado.
Professor: sim, porque basicamente ele não é propenso a falsos positivos. Agora, se você realmente quiser, pode alterar um pouco o código para evitá-lo. Se você souber exatamente o que o dispositivo de teste está procurando, poderá alterar essas instruções. Talvez configurando
AND primeiro para uma instrução e depois use a máscara em outra. Mas é muito mais fácil evitar esses arranjos de bytes suspeitos, embora isso pareça bastante inconveniente.
É possível que a arquitetura inclua uma alteração no compilador. Basicamente, eles têm algum tipo de componente que realmente precisa compilar o código corretamente. Você não pode simplesmente "decolar" o
GCC e compilar o código para o
Native Client . Então, basicamente, isso é factível. Mas, provavelmente, eles acham que isso causa muitos problemas, não será uma solução confiável ou de alto desempenho e assim por diante. Além disso, existem várias instruções
x86 que são proibidas ou devem ser consideradas inseguras e, portanto, devem ser proibidas. Mas, na maioria das vezes, eles têm um byte de tamanho, por isso é muito difícil encontrá-los ou filtrá-los.
Portanto, se eles não podem simplesmente coletar e classificar instruções inseguras e esperar o melhor, precisam usar um plano diferente para desmontá-lo de maneira confiável. Então, o que o
Native Client faz para garantir que não "tropeça" nessa codificação de tamanho variável?
De certa forma, se realmente varrermos o arquivo executável da esquerda para a direita e procurarmos todos os códigos incorretos possíveis, e se for assim que o código for executado, estaremos em boa forma. Mesmo que haja algumas instruções estranhas e algum viés, o processador ainda não vai “pular” para lá, ele executará o programa na mesma ordem em que as instruções são digitalizadas, ou seja, da esquerda para a direita.

Assim, o problema com a desmontagem confiável surge devido ao fato de que em algum lugar da aplicação pode haver "saltos". O processador pode falhar se der um “salto” para alguma instrução de código que não percebeu ao digitalizar da esquerda para a direita. Portanto, este é um problema de desmontagem confiável até agora em desenvolvimento. E o plano principal é verificar para onde todos os "saltos" levam. De fato, é bastante simples em algum nível. Existem várias regras que consideraremos em um segundo, mas o plano aproximado é que, se você vir uma instrução de "salto", precisará garantir que o objetivo do "salto" tenha sido observado anteriormente. Para fazer isso, de fato, basta escanear da esquerda para a direita, ou seja, o procedimento que descrevemos em nossa abordagem ingênua do problema.
Nesse caso, se você vir alguma instrução de “salto” e o endereço para o qual esta instrução aponta, verifique se esse é o mesmo endereço que você já viu durante a desmontagem da esquerda para a direita.
Se uma instrução de salto para este byte de CD for encontrada, devemos marcá-lo como inválido, porque nunca vimos a instrução iniciando no byte de CD, mas vimos outra instrução começando com o número 25. Mas se todas as instruções de salto ordenado a ir para o início da instrução, neste caso para 25, então estamos bem. Isso está claro?
O único problema é que você não pode verificar os objetivos de cada salto no programa, pois pode haver saltos indiretos. Por exemplo, em
x86, você pode ter algo como um salto no valor desse registro
EAX . Isso é ótimo para implementar ponteiros de função.

Ou seja, o ponteiro de função está em algum lugar da memória, você o mantém em algum registro e depois vai para qualquer endereço no registro de movimento.
Então, como esses caras lidam com saltos indiretos? Porque, de fato, não tenho idéia se isso será um “salto” para o byte
CD ou o byte 25. O que eles fazem nesse caso?
Público: usando ferramentas?
Professor: sim, a instrumentação é o principal truque. Portanto, sempre que virem que o compilador está pronto para executar a geração, isso prova que esse salto não causará problemas. Para fazer isso, eles precisam garantir que todos os saltos sejam executados com uma multiplicidade de 32 bytes. Como eles fazem isso? Eles mudam todas as instruções de salto para o que chamam de "pseudo instruções". Estas são as mesmas instruções, mas prefixadas, que limpam os 5 bits baixos no registro
EAX . O fato de a instrução limpar 5 bits baixos significa que faz com que o valor fornecido seja um múltiplo de 32, de dois a cinco, e então um salto para esse valor já é realizado.

Se você observar isso durante a verificação, certifique-se de que esse "par" instrucional "salte" apenas com uma multiplicidade de 32 bytes. E então, para garantir que não haja possibilidade de "pular" em algumas instruções estranhas, você aplica uma regra adicional. Consiste no fato de que, durante a desmontagem, quando você olha suas instruções da esquerda para a direita, assegura que o início de cada instrução válida também seja um múltiplo de 32 bytes.
Assim, além deste kit de ferramentas, você verifica se cada código múltiplo de 32 é a instrução correta. Por uma instrução válida e válida, quero dizer uma instrução desmontada da esquerda para a direita.
Público: Por que o número 32 foi escolhido?
Professor: sim, por que eles escolheram 32 em vez de 1000 ou 5? Por que 5 é ruim?
Público: porque o número deve ser uma potência de 2.
Professor: sim, bem, é por isso. Porque, caso contrário, garantir o uso de algo múltiplo de 5 exigirá instruções adicionais que levem à sobrecarga. E oito? O número é oito o suficiente?
Público-alvo: você pode ter instruções com mais de oito bits.
Professor: sim, isso pode ser para a instrução mais longa permitida na plataforma x86. Se temos uma instrução de 10 bytes e tudo deve ter um múltiplo de 8, não podemos inseri-la em nenhum lugar. Portanto, o comprimento deve ser suficiente para todos os casos, porque a maior instrução que vi foi de 15 bytes. Então 32 bytes é suficiente.
Se você deseja adaptar as instruções para entrar ou sair do ambiente de serviço de processo, pode precisar de uma quantidade não trivial de código em um slot de 32 bytes. Por exemplo, 31 bytes, porque 1 byte contém uma instrução. Deveria ser muito maior? Devemos fazer isso igual a, digamos, 1024 bytes? Se você tiver muitos ponteiros de função ou muitos saltos indiretos, toda vez que quiser criar um local para pular, deverá continuar na próxima borda, independentemente do seu valor. Portanto, com 32 bits, é um tamanho bastante normal. Na pior das hipóteses, você perderá apenas 31 bytes se precisar chegar rapidamente à próxima borda. Mas se você tem um tamanho múltiplo de 1024 bytes, existe a possibilidade de desperdiçar um kilobyte inteiro de memória em vão para um salto indireto. Se você tiver funções curtas ou muitos ponteiros de função, um tamanho tão grande da multiplicidade do comprimento do "salto" causará um desperdício significativo de memória.
Eu não acho que o número 32 seja uma pedra de tropeço para o
Native Client . Alguns blocos podem funcionar com uma multiplicidade de 16 bits, alguns de 64 ou 128 bits, isso não importa. Apenas 32 bits pareciam o valor ideal mais aceitável.
Então, vamos fazer um plano para uma desmontagem confiável. Como resultado, o compilador deve ter um pouco de cuidado ao compilar o
código C ou
C ++ em um binário do
Native Client e observar as seguintes regras.

Portanto, sempre que ele pular, como mostrado na linha superior, ele deve adicionar essas instruções adicionais fornecidas nas 2 linhas inferiores. E, independentemente do fato de ele criar uma função para a qual ele "saltará", nossa instrução saltará como a adição
AND $ 0xffffffe0,% eax indica. E não pode apenas complementá-lo com zeros, porque tudo isso deve ter os códigos corretos. Portanto, a adição é necessária para garantir que todas as instruções possíveis sejam válidas. E, felizmente, na plataforma
x86 , nem uma única função
noop é descrita por um único byte, ou pelo menos não há um único
noop com 1 byte de tamanho. Assim, você sempre pode adicionar coisas ao valor de uma constante.
Então, o que isso nos garante? Vamos garantir que sempre vejamos o que acontece na terminologia das instruções que serão seguidas. Aqui está o que essa regra nos fornece - a garantia de que uma chamada do sistema não será feita por acidente. Isso se aplica aos saltos, mas e os retornos? Como eles lidam com retornos? Podemos
retornar a uma função no
Native Client ? O que acontece se você executar o código em brasa?
Público: Pode estourar a pilha.
Professor: é verdade que aparece inesperadamente na pilha. Mas o fato é que a pilha usada pelos módulos do
Native Client realmente contém alguns dados. Portanto, ao lidar com o
Native Client, você não deve se preocupar com o estouro de pilha.
Público: espere, mas você pode colocar qualquer coisa na pilha. E quando você dá um salto indireto.
Professor: é verdade. O retorno parece quase um salto indireto de algum lugar da memória, localizado no topo da pilha. Portanto, acho que uma coisa que eles poderiam fazer para a função de
retorno é definir o prefixo da mesma maneira que na verificação anterior. E esse prefixo verifica o que aparece no topo da pilha. Você verifica se isso é válido e, ao escrever ou usar o operador
AND , verifica o que está no topo da pilha. Isso parece um pouco confiável devido à constante mudança de dados. Como, por exemplo, se você olhar para o topo da pilha e verificar se está tudo bem, e depois escrever alguma coisa, o fluxo de dados no mesmo módulo poderá modificar algo no topo da pilha, após o qual você se referirá ao errado endereço
Público: Isso não se aplica ao salto na mesma extensão?
Professor: sim, então o que acontece lá com um salto? Nossas condições de corrida podem de alguma forma invalidar este teste?
Público: Mas o código não é gravável?
Professor: sim, o código não pode ser escrito, isso é verdade. Portanto, você não pode modificar AND. Mas não poderia outro fluxo alterar o objetivo do salto entre essas duas instruções?
Público: isso está no registro, então ...
Professor: Sim, isso é uma coisa legal. Como se um fluxo modificar algo na memória ou no
conteúdo carregado do
EAX (por si só, você o faz antes do download), nesse caso, o
EAX estará em um estado ruim, mas eliminará os bits ruins. Ou ele pode alterar a memória depois, quando o ponteiro já estiver no
EAX , portanto, não importa que ele altere o local da memória da qual o registro
EAX foi carregado.
De fato, os threads não compartilham conjuntos de registros. Portanto, se outro segmento alterar o registro
EAX , isso não afetará o registro
EAX desse segmento. Portanto, outros segmentos não podem invalidar esta sequência de instruções.
Há outra questão interessante. Podemos contornar isso
E ? Eu posso pular para onde quiser em qualquer lugar deste espaço de endereço. ,
AND .

, , , , ,
AND . .
jmp , .

, , - , 1237. , 32.
Native Client , , , . , , 1237 ?
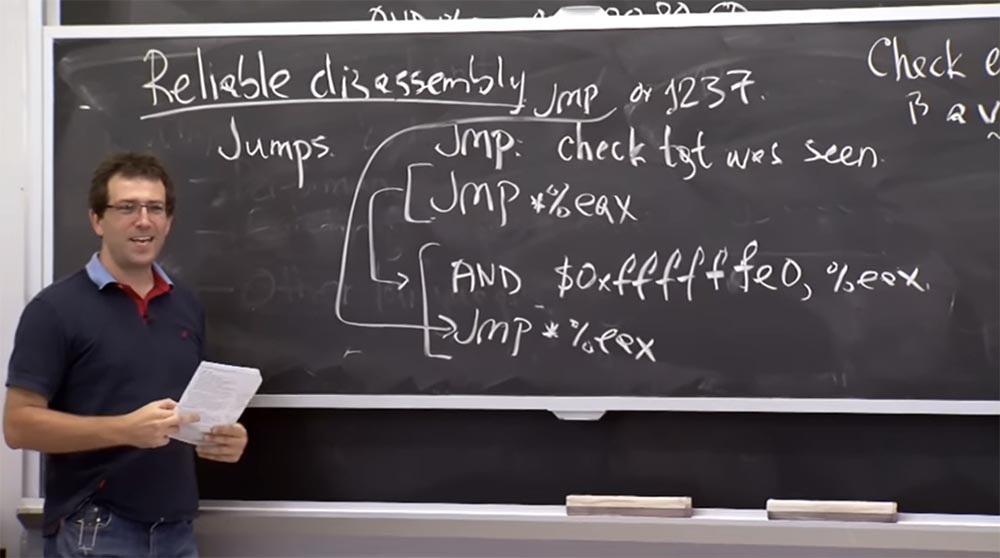
-
EAX , , , , . , ? ?
: NaCl , .
: , .
x86 , ,
NaCl , 2 . , , : «, , !»,
25 CD 80 00 00 . . ,
x86 .
,
Native Client . , , , ,
NaCl . , .
: , , . , . , , , , .
 :
: , . , . , , ,
EAX . , - .
EAX ,
EBX . , .
EAX EBX AND . , ,
EAX , . , -
64 .
Jmp *% eax AND .

, , , , .
Intel , , , , . , , .
AND ,
EAX , «» .
, , . , . , , , . , , , .
, ,
C1 C7 .
C1 , , . , «» . , , . , , - . , .
2 , 0
64 . , , . , , .
3 , , , . , , .
4 ,
hlt .
halt ? ,
C4 . , , - , .
, , ? , , - .
, , , , . , , , , . .

55:20
:
Curso MIT "Segurança de sistemas de computadores". 7: « Native Client», 3.
, . Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
3 Dell R630 —
2 Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 41TB HDD 2240GB SSD / 1Gbps 10 TB — $99,33 , ,
.
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?