Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3Palestra 4: “Separação de Privilégios”
Parte 1 /
Parte 2 /
Parte 3Palestra 5: “De onde vêm os sistemas de segurança?”
Parte 1 /
Parte 2Palestra 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Palestra 7: “Sandbox do Cliente Nativo”
Parte 1 /
Parte 2 /
Parte 3 Há uma ressalva na regra
C4 . Você não pode "pular" no final de um programa. A última coisa para a qual você pode pular é a última instrução. Portanto, essa regra garante que, quando o programa for executado no processo "mecanismo", não haverá discrepância.
A regra
C5 diz que não pode haver instruções maiores que 32 bytes. Consideramos uma certa versão dessa regra quando falamos sobre a multiplicidade de tamanhos de instruções para 32 bytes; caso contrário, você pode pular para o meio da instrução e criar um problema com a chamada do sistema, que pode "ocultar" lá.
A regra
C6 declara que todas as instruções disponíveis podem ser desmontadas desde o início. Portanto, isso garante que vejamos cada instrução e possamos verificar todas as instruções que são executadas quando o programa é executado.
A regra
C7 afirma que todos os saltos diretos estão corretos. Por exemplo, você pula diretamente para a parte da instrução em que o destino está indicado e, embora não seja um múltiplo de 32, ainda é a instrução correta à qual a desmontagem é aplicada da esquerda para a direita.
 Público:
Público: qual é a diferença entre
C5 e
C3 ?
Professor: Eu acho que o
C5 diz que se eu tiver uma instrução de vários bytes, ela não poderá atravessar as fronteiras dos endereços adjacentes. Suponha que eu tenha um fluxo de instruções e que haja um endereço 32 e um endereço 64. Portanto, uma instrução não pode cruzar a borda múltipla de 32 bytes, ou seja, não deve começar com um endereço menor que 64 e terminar com um endereço maior que 64.

É isso que a regra
C5 diz. Porque, caso contrário, tendo saltado a multiplicidade 32, você pode entrar no meio de outra instrução em que não se sabe o que está acontecendo.
E a regra
C3 é um análogo dessa proibição ao lado do salto. Ele afirma que sempre que você pula, o comprimento do seu pulo deve ser um múltiplo de 32.
C5 também afirma que qualquer coisa no intervalo de endereços que seja múltiplo de 32 é uma instrução segura.
Depois de ler a lista dessas regras, tive um sentimento misto, pois não conseguia avaliar se essas regras são suficientes, ou seja, a lista é mínima ou completa.
Então, vamos pensar na lição de casa que você precisa concluir. Eu acho que, de fato, há um erro na operação do
Native Client ao executar algumas instruções complicadas na sandbox. Acredito que eles não tinham o código de tamanho correto, o que poderia levar a algo ruim, mas não me lembro exatamente qual foi o erro.
Suponha que um validador de sandbox receba incorretamente o comprimento de algum tipo de instrução. Que mal pode acontecer neste caso? Como você usaria esse deslize?
Público-alvo: por exemplo, você pode ocultar a chamada do sistema ou a declaração de retorno
ret .
Professor: sim. Suponha que exista alguma versão sofisticada da instrução
AND que você anotou. É possível que o validador tenha se enganado e considerado que seu comprimento é de 6 bytes com o comprimento real de 5 bytes.
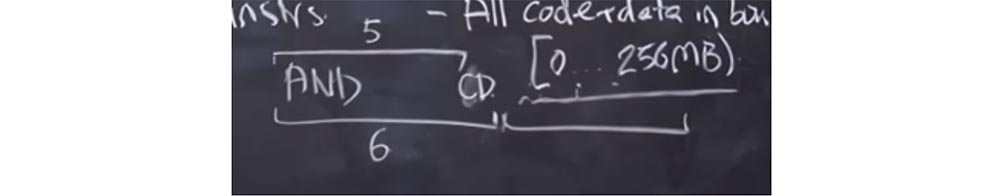
O que vai acontecer? O validador considera o comprimento desta instrução em 6 bytes e possui outra instrução válida por trás. Mas o processador, ao iniciar o código, usa o comprimento real da instrução, ou seja, 5 bytes. Como resultado, temos um byte livre no final da instrução
AND , onde podemos inserir uma chamada do sistema e usá-la em nosso benefício. E se inserirmos um
CD byte aqui, será como o início de outra instrução. Em seguida, colocaremos algo no próximo intervalo de 6 bytes, e será como uma instrução que começa com o byte do
CD , embora na verdade faça parte da instrução
AND . Depois disso, podemos fazer uma chamada do sistema e "escapar" da caixa de areia.
Assim, o validador
Native Client deve sincronizar suas ações com as ações da
CPU , ou seja, "adivinhar" exatamente como o processador interpretará cada instrução. E isso deve estar em todos os níveis do sandbox, o que é bastante difícil de implementar.
De fato, existem outros erros interessantes no
Native Client . Uma delas é a limpeza incorreta do ambiente do processador ao saltar para o
Trusted Service Runtime . Acho que falaremos sobre isso em um segundo. Mas o
Trusted Service Runtime funcionará basicamente com o mesmo conjunto de registradores de
CPU projetados para executar módulos não confiáveis. Portanto, se o processador esquecer de limpar alguma coisa ou reiniciar, o tempo de execução pode ser enganado, considerando o módulo não confiável como um aplicativo confiável e fazendo algo que não deveria ter sido feito ou que não era a intenção dos desenvolvedores.
Então, onde estamos agora? No momento, entendemos como desmontar todas as instruções e como impedir a execução de instruções proibidas. Agora vamos ver como armazenamos memória e links para código e dados no módulo
Native Client .
Por motivos de desempenho, os
funcionários do
Native Client estão começando a usar o suporte de hardware para garantir que o armazenamento de memória e links não cause muita sobrecarga. Mas antes de considerar o suporte de hardware que eles usam, quero ouvir sugestões, como eu poderia fazer o mesmo sem o suporte de hardware? Podemos apenas fornecer acesso a todos os processos de memória dentro dos limites estabelecidos pela máquina anteriormente?
Público: Você pode instruir instruções para limpar todos os bits altos.
 Professor:
Professor: sim, está certo. De fato, vemos que temos essa instrução
AND aqui, e toda vez, por exemplo, pulamos em algum lugar, isso limpa os bits mais baixos. Mas, se quisermos manter todo o código possível executado nos 256 MB baixos, podemos simplesmente substituir o primeiro atributo
f por
0 e obter
$ 0x0fffffe0 em vez de
$ 0xffffffe0 . Isso limpa os bits baixos e define um limite superior de 256 MB.
Assim, isso faz exatamente o que você oferece, certificando-se de que sempre que você pula, você está dentro de 256 MB. E o fato de estarmos fazendo a desmontagem também permite verificar se todos os saltos diretos estão ao seu alcance.
A razão pela qual eles não fazem isso por seu código é que, na plataforma
x86 , você pode codificar
AND de maneira muito eficaz, onde todos os bits superiores são 1. Isso se transforma na existência de uma instrução de 3 bytes para
AND e uma instrução de 2 bytes. para o salto. Assim, temos uma despesa adicional de 3 bytes. Mas se você precisar de um bit alto que não seja da unidade, como este
0 em vez de
f , de repente você terá uma instrução de 5 bytes. Portanto, acho que, neste caso, eles estão preocupados com as despesas gerais.
Público: Há algum problema com a existência de algumas instruções que incrementam a versão que você está tentando obter? Ou seja, você pode dizer que sua instrução pode ter um viés constante ou algo assim?
Professor: Eu acho que sim. Provavelmente, você proibirá instruções que saltem para alguma fórmula complexa de endereço e suportará apenas instruções que saltam diretamente para esse valor, e esse valor sempre obtém
AND .
Público: é mais necessário acessar a memória do que ...
Professor: sim, porque é apenas código. E para acessar a memória na plataforma
x86 , existem muitas maneiras estranhas de acessar um local de memória específico. Normalmente, você deve primeiro calcular a localização da memória, adicionar um
AND adicional e somente então acessar. Penso que esta é a verdadeira razão da sua preocupação com o declínio no desempenho devido ao uso deste kit de ferramentas.
Na plataforma
x86 , ou pelo menos na plataforma de 32 bits descrita no artigo, eles usam suporte de hardware em vez de restringir os dados de código e endereço referentes aos módulos não confiáveis.
Vamos ver como fica antes de descobrir como usar o módulo
NaCl em uma sandbox. Esse hardware é chamado de segmentação. Ele surgiu antes mesmo da plataforma
x86 receber um arquivo de troca. Na plataforma
x86 , existe uma tabela de hardware suportada durante o processo. Chamamos isso de tabela de descritores de segmentos. É um monte de segmentos numerados de 0 até o final de uma tabela de qualquer tamanho. Isso é algo como um descritor de arquivo no
Unix , exceto que cada entrada consiste em 2 valores: a base
base e o
comprimento do comprimento.
Esta tabela nos diz que temos um par de segmentos e, sempre que nos referimos a um segmento específico, isso significa que estamos falando de um pedaço de memória que começa no endereço
base da
base e continua ao longo do
comprimento .

Isso nos ajuda a manter os limites da memória na plataforma
x86 , porque cada instrução, acessando a memória, refere-se a um segmento específico nesta tabela.
Por exemplo, quando executamos
mov (% eax), (% ebx) , ou seja, movemos o valor da memória de um ponteiro armazenado no registro
EAX para outro ponteiro armazenado no registro
EBX , o programa sabe quais são os endereços inicial e final em vista de e salvará o valor no segundo endereço.
Mas na verdade, na plataforma
x86 , quando falamos de memória, existe uma coisa implícita chamada descritor de segmento, semelhante a um descritor de arquivo no
Unix . Este é apenas um índice na tabela do descritor e, a menos que seja indicado de outra forma, cada código de operação contém um segmento padrão.
Portanto, quando você executa
mov (% eax) , refere-se a
% ds ou ao registro do segmento de dados, que é um registro especial no seu processador. Se bem me lembro, é um número inteiro de 16 bits que aponta para esta tabela de descritor.
E o mesmo vale para
(% ebx) - refere-se ao mesmo seletor de segmento
% ds . De fato, no
x86 , temos um grupo de 6 seletores de código:
CS, DS, ES, FS, GS e
SS . O
seletor de chamadas CS é usado implicitamente para receber instruções. Portanto, se o ponteiro de sua instrução apontar para algo, ele se refere àquele que selecionou o seletor de segmentos
CS .
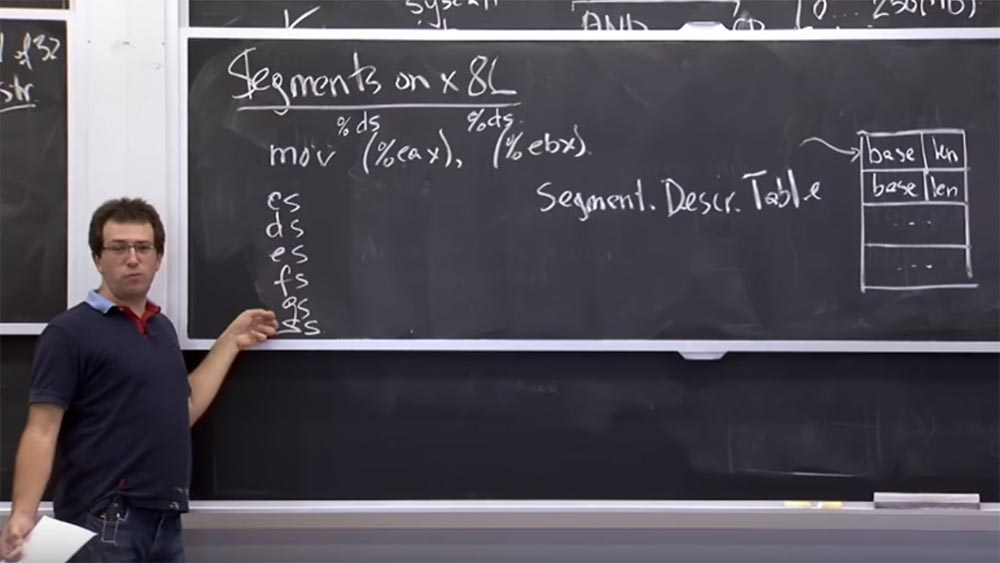
A maioria das referências de dados usa implicitamente
DS ou
ES ,
FS e
GS indicam algumas coisas especiais, e o
SS é sempre usado para operações de pilha. E se você
pressiona e pop , eles implicitamente vêm deste seletor de segmentos. Essa é uma mecânica bastante arcaica, mas acaba sendo extremamente útil nesse caso específico.
Se você obtiver acesso a algum endereço, por exemplo, no seletor
% ds: addr , o hardware o redirecionará para a operação com a tabela
adrr + T [% ds] .base . Isso significa que o endereço do comprimento do módulo será retirado da mesma tabela. Portanto, toda vez que você acessa a memória, ele possui um banco de dados de seletores de segmentos na forma de entradas da tabela de descritores e pega o endereço especificado e o combina com o comprimento do segmento correspondente.
Público: então, por que não é usado, por exemplo, para proteger o buffer?
Professor: sim, essa é uma boa pergunta! Poderíamos usar isso para proteger contra estouros de buffer? Por exemplo, para cada buffer que temos, você pode colocar a base do buffer aqui e o tamanho do buffer.
Público-alvo: e se você não precisar colocá-lo em uma tabela antes de escrever? Você não precisa estar lá constantemente.
Professor: sim. Portanto, acho que o motivo pelo qual essa abordagem geralmente não é usada para proteger contra estouros de buffer é porque o número de entradas nesta tabela não pode exceder 2 no 16º grau, porque os descritores têm 16 bits, mas na verdade de fato, mais alguns bits são usados para outras coisas. Portanto, na verdade, você só pode colocar 2 na 13ª potência dos registros nesta tabela. Portanto, se você tiver no seu código uma matriz de dados maior que 2
13 , poderá ocorrer um estouro dessa tabela.
Além disso, seria estranho para o compilador gerenciar diretamente essa tabela, porque geralmente é manipulada usando chamadas do sistema. Você não pode gravar diretamente nesta tabela; primeiro você precisa fazer uma chamada do sistema para o sistema operacional, após o qual o sistema operacional colocará o registro nessa tabela. Portanto, acho que a maioria dos compiladores simplesmente não deseja lidar com um sistema de gerenciamento de buffer de memória tão complexo.

A propósito, o
Multex usa essa abordagem: possui 2
18 registros para vários segmentos e 2
18 registros para possíveis compensações. E cada fragmento de biblioteca comum ou fragmento de memória são segmentos separados. Todos são verificados quanto à faixa e, portanto, não podem ser usados em um nível variável.
Audiência: Presumivelmente, a necessidade constante de usar o kernel atrasará o processo.
Professor: sim, está certo. Portanto, teremos sobrecarga devido ao fato de que, quando um novo buffer é criado de repente na pilha, precisamos fazer uma chamada de sistema para adicioná-lo.
Então, quantos desses elementos realmente usam o mecanismo de segmentação? Você pode adivinhar como isso funciona. Eu acho que, por padrão, todos esses segmentos em
x86 têm uma base igual a 0 e o comprimento é de 2 a 32. Assim, você pode acessar todo o intervalo de memória que deseja. Portanto, para
NaCl, eles codificam a base 0 e definem o comprimento para 256 megabytes. Em seguida, apontam para todos os registros de 6 seletores de segmento nesse registro para a área de 256 MB. Assim, sempre que o equipamento acessa a memória, ele a modifica com um deslocamento de 256 MB. Portanto, a capacidade de alterar o módulo será limitada a 256 MB.
Acho que agora você entende como esse hardware é suportado e como funciona, para que você possa acabar usando esses seletores de segmento.
Então, o que pode dar errado se apenas implementarmos esse plano? Podemos pular do seletor de segmentos em um módulo não confiável? Penso que uma coisa a ter cuidado é que esses registros são como registros regulares e você pode mover valores para dentro e para fora deles. Portanto, você deve garantir que o módulo não confiável não distorça esses registros do seletor de segmentos. Porque em algum lugar da tabela do descritor pode muito bem haver um registro, que também é o descritor do segmento de origem para um processo que tem uma base de 0 e um comprimento de até
32 .

Portanto, se um módulo não confiável conseguir alterar
CS ,
DS ,
ES ou qualquer um desses seletores para que eles comecem a apontar para esse sistema operacional original, que cobre todo o seu espaço de endereço, você poderá criar um link de memória para esse segmento e " pule para fora da caixa de areia.
Assim, o
Native Client teve que adicionar mais algumas instruções a esta lista proibida. Eu acho que eles proíbem todas as instruções como
mov% ds, es e assim por diante. Portanto, uma vez na caixa de proteção, você não pode alterar o segmento ao qual se referem algumas coisas referentes a ela. Na plataforma
x86, as instruções para alterar a tabela do descritor de segmentos são privilegiadas, mas as próprias
ds, es etc. A tabela é completamente sem privilégios.
Público: você pode inicializar a tabela para que o comprimento zero seja colocado em todos os slots não utilizados?
Professor: sim. Você pode definir o comprimento da tabela para algo em que não haja slots não utilizados. Acontece que você realmente precisa desse slot adicional contendo 0 e 2
32 , porque o ambiente de
tempo de execução confiável deve iniciar nesse segmento e obter acesso a todo o intervalo de memória. Portanto, essa entrada é necessária para o ambiente de
tempo de
execução confiável funcionar.
Público: o que é necessário para alterar o comprimento da saída da tabela?
Professor: você deve ter privilégios de root. Na verdade, o
Linux possui um sistema chamado
modify_ldt () para a tabela de descritores locais, que permite que qualquer processo modifique sua própria tabela, ou seja, na verdade há uma tabela para cada processo. Mas na plataforma
x86 isso é mais complicado, há uma tabela global e uma tabela local. Uma tabela local para um processo específico pode ser alterada.
Agora vamos tentar descobrir como saltamos e saltamos do processo de execução do
Native Client ou saímos da sandbox. O que queremos dizer com isso?

Portanto, precisamos executar esse código confiável, e esse código confiável "vive" em algum lugar acima do limite de 256 MB. Para pular lá, teremos que desfazer todas as proteções que o
Native Client instalou. Basicamente, eles se resumem a mudar esses seis seletores. Eu acho que nosso validador não aplicará as mesmas regras para coisas localizadas acima do limite de 256 MB, então isso é bastante simples.
Mas, então, precisamos de alguma forma entrar no
tempo de execução confiável e reinstalar os seletores de segmento para os valores corretos para esse segmento gigante, cobrindo o espaço de endereço de todo o processo - esse intervalo é de 0 a 2
32 . Eles chamaram esses mecanismos existentes nos trampolins de
trampolim e no
trampolim do
Native Client . Eles vivem em um módulo baixo de 64k. O mais legal é que esses "trampolins" e "saltos" são trechos de código localizados nos 64k mais baixos do espaço do processo. Isso significa que esse módulo não confiável pode saltar para lá, porque é um endereço de código válido que está dentro dos limites de 32 bits e 256 MB. Então você pode pular neste trampolim.
Native Client «» - . ,
Native Client «», trampoline
trusted runtime . ,
DS, CS , .
, , -
malo , «», «» 32- .
, 4096 + 32 , . , ,
mov %ds, 7 ,
ds , 7 0 2
32 .
CS trusted service runtime , 256 .

, , ,
trusted service runtime , . , . DS , , , , - .
, ? , «»? , ?
: 64.
: , , . malo, 64, 32 . , , , .
, 32- , . , , 32 , 32- , . «»
trusted runtime 32 .

. , ,
DS, CS . , 256- ,
trusted runtime , . .
«»,
trusted runtime 256
Native Client . «»
DS , ,
mov %ds, 7 , ,
trusted runtime . . , «», - .
halt 32- «». «», .
trusted service runtime , 1 .
 trusted service runtime
trusted service runtime , , .
: «» ?
: «» 0 256 . 64- , , «», - -.
Native Client .
: ?
: , ? , «»? ?
: , ?
: , -
%eax ,
trusted runtime : «, »!
EAX ,
mov , «»
EAX ,
trusted runtime . , «»?
: , , . …
: , , — , , 0 2
32 . . «», 256 .
, «», . , «» , . , «» .
: «» 256 ?
: , . ,
CS - . «»,
halt , mov,
CS , , 256 .
, , «». ,
DS , ,
CSe pular em algum lugar.Provavelmente, se você tentar, poderá criar alguma sequência de instruções x86 que possam fazer isso fora dos limites do espaço de endereço do módulo Native Client .Então, até a próxima semana e fale sobre segurança na web.A versão completa do curso está disponível aqui .Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10 GB DDR4 240 GB SSD de 1 Gbps até dezembro de graça quando pagar por um período de seis meses, você pode fazer o pedido aqui .Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?