Conteúdo
Mnemônica é uma palavra ou frase que nos ajuda a lembrar de algo. A mnemônica mais famosa é "todo caçador quer saber onde fica o faisão". Quem você pergunta, todo mundo a conhece.
Mas na esfera profissional, tudo é um pouco mais triste. Pergunte aos seus companheiros se eles sabem o que é SPDFOT ou RCRCRC. Longe de um fato ... Mas a mnemônica nos ajuda a executar os testes, sem esquecer de verificar o mais importante. A lista de verificação entrou em colapso em uma frase!
Colegas de testes que falam inglês usam ativamente mnemônicos. Um amigo que lê blogs estrangeiros diz que os americanos os criam quase todos os espirros.
E eu acho isso ótimo. Mnemônicos estrangeiros podem não ser adequados especificamente para o seu sistema ou seus processos. E o dele, querido, lembrará você "para não esperar para verificar isso e aquilo" e limitará o número de bugs na produção.
Hoje quero compartilhar com vocês meus mnemônicos BMW para o estudo dos valores-limite. Pode ser:
- dar junior para desenvolvimento geral em design de teste;
- usar na entrevista - o candidato geralmente resolve a tarefa “encontrar a borda em número”, mas ele encontrará a borda na linha ou fará o download do arquivo?
BMW Mnemonics
B - grande
M - pequeno
B - apenas para a direita

É fácil de lembrar. Apenas lembre-se deste carro legal e imediatamente a descriptografia está pronta! Mas o que isso significa e como isso ajudará nas entrevistas?
Just right

Em princípio, "exatamente" você está testando sem mnemônicos. Sempre começamos com testes positivos para verificar se o sistema funciona em princípio.
Se o campo for numérico, insira o valor comum. Digamos que temos uma loja online de varejo. Na quantidade de mercadorias, podemos verificar 1 ou 2.
Um teste positivo - isso é "correto". Eu mostrei mnemônicos na forma de um mouse. Aqui está um tamanho padrão.
Grande
Então dizemos que o mouse deve ser inflado para um tamanho incrível, para que não caiba diretamente na imagem. E veja como o sistema funcionará com ele.

Neste caso, estamos apenas indo "muito à frente". MUITO DISTANTE O rato grande representa uma busca por um limite tecnológico em algum lugar, fora de um valor arbitrário.
Para inserir a quantidade de mercadorias, será "99999999999999999999999999999999999999999999999999999999 ...". Não apenas um ótimo valor (9999), mas MUITO grande. Lembre-se do mouse - ele foi tão ampliado que nem se encaixou na imagem.
A diferença é importante, uma grande importância ajudará a encontrar uma fronteira arbitrária e uma enorme ajudará a encontrar uma fronteira tecnológica. O teste para "grande" é frequentemente realizado, para "enorme" - não. Mnemônicos lembra precisamente sobre ele.
Pequeno
Nós perfuramos o mouse e ele é ampliado para um tamanho microscópico.

O ratinho é uma busca por valores próximos de zero. O menor valor positivo.
E o teste para "0.00000001"? Verificado como zero, mas não se esqueça de cavar lado a lado.
E o que tem aí?
Parece estar dizendo coisas óbvias. Parece que todo mundo já sabe disso. Basta dar uma entrevista sobre uma tarefa numérica, o mesmo triângulo (uma
tarefa de Myers ), e você entende que isso não é assim ... Pouquíssimas pessoas procuram um limite tecnológico ou tentam inserir um valor fracionário próximo de zero. Zero máximo e oferecerá para verificar.
E se você propõe NÃO testar um número, esse é um estupor ainda maior. Com o número, tudo bem, verificamos zero e a fronteira de acordo com a declaração de trabalho, já não é ruim. E na linha o que testar? E no arquivo?
Eu quero falar sobre isso no artigo. Como você pode usar mnemônicos na vida real e ao mesmo tempo capturar bugs? Vamos começar com exemplos comuns - encontrados em todos os projetos. E o que pode ser dado na entrevista na forma de uma pequena tarefa.
E então vou contar exemplos do meu trabalho. Sim, eles são específicos. Sim, eles são sobre tecnologias específicas. E daí? Mas eles mostram como você pode aplicar mnemônicos em lugares mais complexos.
O significado é o mesmo: as fronteiras estão em quase toda parte. Basta encontrar o número e experimentar. E não se esqueça dos mnemônicos da BMW, porque é no B e no M que frequentemente encontramos bugs.
Exemplos comuns
Exemplos que estão em qualquer projeto: um campo numérico, uma string, uma data ... Vamos considerar nesta ordem:
Número
- 10
- 0,00000001
- 999999999999999999999999 ....
Diga uma caixa com o número de livros, vestidos ou pacotes de suco. Como teste positivo, escolhemos uma quantidade adequada: 3, 5, 10.
Como um valor pequeno, selecione o mais próximo possível de zero. Lembre-se de que o mouse deve ser muito pequeno. Esta não é apenas uma unidade, mas a n-ésima casa decimal. De repente ele vai arredondar para zero e em algum lugar nas fórmulas irá falhar? Além disso, no número "1" tudo funcionará bem.
Bem, o máximo é alcançado inserindo 10 milhões de noves. Gere essa string usando ferramentas como Perlclip e vá em frente, teste MUITO!
Veja também:Classes de equivalência para uma sequência que denota um número - ainda mais ideias para testes de sequência numérica
Como gerar uma string grande, ferramentas - assistentes na geração de grande valor
Data
- 26/05/2017
- 01/01/1900
- 21/12/003
Uma data positiva é "hoje" se enviarmos o relatório em alguma data. Ou sua própria data de nascimento, se estivermos falando sobre DR, ou outra que se adapte ao seu processo de negócios.
Como uma data pequena, escolhemos a data mágica "01/01/1900", na qual os aplicativos geralmente desmoronam. A partir desta data, a hora começa no Excel. Ele também se infiltra em aplicativos. Você expõe esse número mágico - e o relatório se desfaz, mesmo que haja proteção contra o tolo em zeros. Então, eu recomendo para verificação.
Se falamos de um mouse muito pequeno, você ainda pode verificar "00.00.0000". Esta será uma verificação zero, o que também é importante. Mas os desenvolvedores são mais frequentemente protegidos contra esse tolo do que em 01/01/1900.
Far Ahead também pode ser diferente. Você pode entrar em negativo e verificar uma data ou mês que realmente não existe: 40/05/2018. Ou pesquise a fronteira tecnológica usando a data 99.99.9999. E você pode ter um valor um pouco mais real, que simplesmente não chegará em breve: 2400 ou 3000.
Veja também:Classes de equivalência para uma sequência que indica uma data - ainda mais idéias para testar uma data

String
- Vasya
- (um espaço)
- (Havia muito texto)
Digamos que ao se registrar, exista um campo com um nome. Um teste positivo é um nome comum: Olga, Vasya, Peter ...
Ao procurar um pequeno mouse, pegamos uma linha vazia ou um truque: um ou dois espaços. Nesse caso, a linha permanece vazia (não há caracteres), mas parece estar preenchida.
Qual é o foco ao procurar um mouse grande? Quando testamos uma string grande, precisamos testar a string BIG! Lembre-se de que o mouse deve ser GRANDE. Porque geralmente explico aos alunos como tudo isso funciona, como procurar uma fronteira tecnológica etc. E então eles me dão DZ e escrevem "Eu verifiquei 1000 caracteres - não há fronteira tecnológica".
Século 21 no quintal, bem, o que são 1000 caracteres? Adotamos qualquer ferramenta que nos permita gerar 10 milhões e inserir 10 milhões, agora essa será a busca de uma fronteira tecnológica. E já existem bugs, o sistema pode ser interrompido. Mas 1000 caracteres? Não.
Veja também:Como gerar uma string grande, ferramentas - assistentes na geração de grande valor
Mas tudo bem, aqui também está claro. E o que acontecerá se testarmos o arquivo?
Ficheiro
Onde posso encontrar um número em um arquivo?
Primeiramente, o arquivo tem seu tamanho:
Ao testar um arquivo grande, eles geralmente tentam algo como 30 Mb e se acalmam. E então você carrega 1 GB - e é isso, o servidor congela.
Obviamente, se você é iniciante e está testando algum site real em busca de experiência, não deve carregá-lo sem o conhecimento do proprietário. Mas quando você testar no trabalho, verifique o mouse grande.
Em segundo lugar, o arquivo tem um nome → e esse é o comprimento da linha que acabamos de discutir.
Mas o arquivo também tem seu conteúdo! Há um número de colunas (colunas) e linhas. Testes de linha:
- 5 linhas
- 1 linha
- 1.000.000.000 de linhas
E aqui começa a diversão. Porque mesmo no mesmo Excel em versões diferentes, existem restrições diferentes no número de linhas que ele suporta:
- Excel abaixo de 97-16384
- Excel 97-2003 - 65 536
- Excel 2007 - 1.048.576
Mas ainda assim os números são bastante grandes, não é interessante. Mas o antigo exel não abriu mais de 256 nas colunas, e esta é uma limitação séria:
- Excel 2003 - 256
- Excel 2007 - 16.385
Seu irmão livre, LibreOffice, não pode abrir mais de 1024 colunas.

História de vida
Escrevemos alguns autotestes no formato CSV. Na entrada da mesa, na saída da mesa. Abra e edite no LibreOffice para ver onde está a coluna. Tudo está ótimo, tudo funciona. Enquanto o número de colunas não sai para 1024.
É aqui que a dor na vida começa. O teste do LibreOffice não será mais aberto, no formato CSV é inconveniente, porque é difícil entender onde está a coluna 555. Você abre o teste no Excel, edita, salva, executa o teste ... Ele cai em 10 novos locais: o TIN está com defeito. É longo, por exemplo, 7710152113. O Excel o converte alegremente no formato 1.2E + 5.
Outros números longos também são perdidos.
Se o valor estiver entre aspas, ele estará entre aspas adicionais que o teste não espera.
E você corrige essas pequenas coisas já no formato CSV, repreendendo mentalmente o Excel para si mesmo ... Portanto, há uma limitação que deve ser lembrada! Embora não apareça no próprio sistema, pode simplesmente complicar a vida do testador.
Tabela no Oracle (banco de dados)
E como estamos falando de 1024 colunas, vamos nos lembrar do Oracle (um banco de dados popular). Existe a mesma restrição: em uma tabela, pode haver no máximo 1024 colunas.
É melhor lembrar isso com antecedência! Tínhamos uma mesa na qual havia cerca de 1000 colunas, mas metade estava reservada para o futuro: "algum dia será útil, isso será suficiente para nós por um longo tempo". Chega, mas não por muito tempo ...
Nenhum lugar para expandir a tabela - se deparou com uma limitação. Portanto, divida a tabela em duas ou empacote o conteúdo em um BLOB: isso é algo que um arquivo zip com dados acaba ocupando uma coluna, mas dentro dela contém quantas você quiser.
Mas, de qualquer forma, isso é migração de dados. E a migração de dados é sempre uma dor. Em uma base grande, leva muito tempo, traz novos problemas que só podem ser solucionados em seis meses ... Brrr! Se você pode fazer sem a migração, é melhor fazer.
Se você possui uma tabela com MUITO dados, pense no futuro. Você sempre caberá em 1024 colunas? Você precisará migrar mais tarde? Afinal, quanto mais tempo o sistema permanecer, mais difícil será a transferência. E “o suficiente por 5 anos” significa que um volume de cinco anos terá que ser migrado.
Como testá-lo? Sim, por código, avalie suas tabelas de dados, veja onde estão. Preste atenção ao mouse grande: aquelas tabelas que já possuem muitas colunas. Haverá problemas com eles no futuro?
Relatório no sistema
Mas por que fazemos upload de arquivos para o sistema ou bombeamos dados do Oracle? Provavelmente para criar algum tipo de relatório. E aqui você também pode aplicar esta mnemônica.
Os dados podem estar na entrada (muito, um pouco, apenas à direita) e na saída! E isso também é importante, pois são classes de equivalência diferentes.
Como resultado, testamos a quantidade:
- colunas de relatório
- linhas
- dados de entrada;
- dados de saída (no próprio relatório).
Estrutura (colunas e linhas)Podemos influenciar o número de linhas ou colunas? Às vezes sim, nós podemos. No segundo trabalho, testei o designer de relatórios: à esquerda, você tem cubos com os nomes dos parâmetros que podem ser lançados horizontal ou verticalmente no próprio relatório. Ou seja, você decide quantas linhas serão e quantas colunas.
Aplique mnemônicos. Após um relatório padrão (teste positivo, mouse "correto"), tentamos fazer um pouco:
- 1 coluna, 0 linhas;
- 0 colunas, 1 linha;
- 1 coluna, 1 linha.
Então muito:
- máximo de colunas, 1 linha (todos os cubos são lançados em colunas);
- linhas máximas, 1 coluna;
- se os cubos puderem ser duplicados, então, ali e ali, ao máximo, mas isso é duvidoso;
- máximo de níveis aninhados (é quando outros dois estão dentro de uma coluna agregadora).
Em seguida, testamos os dados de entrada e saída. Podemos influenciá-los em qualquer relatório, mesmo que não haja construtor e o número de linhas e colunas seja sempre o mesmo.
Dados de entradaDescobrimos como o relatório é formado. Suponha que todos os dias alguns dados sejam preenchidos, digamos, o número de vestidos vendidos, vestidos de verão, camisetas. E no relatório, vemos um agrupamento de dados por categorias, cores, tamanhos. Quanto é vendido por dia / mês / hora.
Criamos um relatório e influenciamos os dados de entrada:
- O número usual (5 vestidos por dia, embora em locais enormes esse número possa ser 2000 ou mais, é necessário esclarecer o que será mais positivo para o seu sistema).
- Vazio, não vendeu / vendeu 1 item por mês.
- O volume é irrealisticamente grande, com um máximo de cada produto, cada cor, cada tamanho. Definimos o máximo de "mentiras no armazém" e vendemos tudo: dentro de um mês ou até um dia. O que dirão os relatórios?
Dados de saídaEm teoria, os dados de saída se correlacionam com os dados de entrada. Na entrada um pouco → na saída haverá um pouco. Na entrada há muitos - na saída há muitos.
Mas isso nem sempre funciona. Às vezes, os dados de entrada podem ser eliminados ou, inversamente, multiplicados. E então podemos de alguma forma brincar com isso.
Por exemplo, o sistema
Dadat . Você carrega um arquivo com uma coluna de nome completo, na saída você obtém vários de uma vez:
- Nome original, o que estava no arquivo;
- Nome desmontado (se você pudesse entender);
- Rod caso;
- Dat caso;
- Crie. caso;
- Sobrenome
- Primeiro nome;
- Nome do meio;
- Analisar status - reconhecimento confiável por um mecanismo ou verificado por uma pessoa;

Temos 9. Em uma célula, e isso é apenas pelo nome, e o sistema também pode analisar endereços. Lá, quase 50 são obtidas de uma célula: além dos componentes granulares, existem todos os tipos de códigos KLADR, FIAS, OKATO ...
E aqui é interessante. Acontece que podemos ter poucos dados na entrada, mas muitos na saída. E se examinarmos o máximo em colunas, teremos duas opções:
- 500 colunas na saída (que são cerca de 10 endereços na entrada);
- 500 colunas na entrada (e um monte na saída).
O princípio também funciona na direção oposta. E se a entrada for um monte de dados e a saída for zero? Se, em vez de um nome completo, houver algum tipo de absurdo como "op34e8n8pe"? Acontece que todas as colunas adicionais estão vazias, apenas o status da análise "você me enviou lixo". Portanto, obtemos um mínimo na saída (um pequeno mouse), que também vale a pena conferir.
E se os alto-falantes podem ser excluídos! É possível verificar a classe de equivalência “zero” quando o zero estiver na saída, o arquivo de origem não estiver vazio. Você pode verificar pelo menos quando eles deixaram uma coluna em cem.
O principal aqui é lembrar que, além dos dados de entrada, temos dados de saída. E às vezes neles você pode verificar os limites, o que não dependerá dos dados de entrada. E então isso deve ser feito.
Aplicativos móveis
Comunicação
Existem diferentes opções de comunicação:
- Normal
- Muito figo (rato pequeno);
- Super rápido (grande).
Além disso, a comunicação ruim pode ser parcialmente: se você estiver em uma área com Wi-Fi normal e uma rede celular ruim. A Internet funciona bem, mas o SMS é ruim.
Quantidade de memória
Também é importante quanta memória o aplicativo possui:
- Quantidade normal;
- Muito poucos;
- Muito.
E se, neste caso, o primeiro e o terceiro testes nesse caso puderem ser combinados, o ratinho será muito interessante. E existem opções diferentes:
- execute o aplicativo no telefone, que já tem pouca memória;
- execute quando a memória estiver normal, entre em colapso, implante algo grande, tente retornar ao primeiro aplicativo.
Agora, se o aplicativo não souber como reservar memória normalmente, no segundo caso ele simplesmente trava, a memória já foi pressionada.
Diagonal do dispositivo
- Padrão (estudamos o mercado, olha o que é mais popular entre nossos usuários).
- Mínimo (telefone).
- Máximo (tablet grande).
Resolução da tela
Não confunda resolução e diagonal, estas são duas coisas diferentes. Você pode ter um dispositivo antigo com uma tela grande, mas eu tenho um novo smartphone moderno, onde a resolução é 5 vezes melhor. E o que acontecerá em 20 anos é assustador de se imaginar.
Caminhos GPX
Os caminhos GPX são arquivos XML com coordenadas sequenciais. Eles podem ser baixados para emuladores móveis, para que o telefone pense que se move no espaço a alguma velocidade.
Útil se o aplicativo lê coordenadas GPS para alguns de seus propósitos. Portanto, ele próprio determina se você está indo, correndo ou andando. E você não pode executar, basta alimentar as coordenadas do aplicativo, definir o coeficiente de sua passagem e testar enquanto está sentado no escritório.
Quais probabilidades valem a pena conferir? Tudo de acordo com a mnemônica:
- 1 - coeficiente normal, substitui a caminhada simples;
- 0,01 - como se você estivesse arrastando meeeeeeeeeeeeeeeeeeeeee por via oral;
- 200 - nem corra, mas voe!
Por que tudo isso deve ser verificado? Quais erros podem ser encontrados?
Por exemplo, o aplicativo pode falhar no avião - ele foi lançado, mas caiu imediatamente. Uma vez que lê as coordenadas e tenta determinar sua velocidade. Mas quem sabia que a velocidade estaria acima de 130?
Em velocidade lenta, o aplicativo pode falhar. Ele estabelecerá um milhão de pontos intermediários e não será capaz de mantê-los em sua memória. E é isso aí!
Veja também:Quais são os caminhos GPX e por que eles precisam de um testador? - mais sobre caminhos gpx e um exemplo de arquivo
Resumo de exemplos comuns
Quero mostrar aqui que parece que "grande, pequeno" é um campo numérico e é isso!
Mas, de fato, mnemônicos podem ser usados em qualquer lugar, sejam arquivos, brinquedos, relatórios ... E isso realmente nos ajuda a encontrar bugs. Aqui estão alguns exemplos da minha prática:Ratinho (limite inferior)- Data 01/01/1900Quando trabalhei como freelancer, essa data arruinou todos os relatórios para mim. Porque mesmo que o desenvolvedor defina a proteção contra o tolo, ele definirá a proteção de 0000. Mas ele não definirá a proteção de 1900.- Um personagem solitário no final de uma linha.Esteteste me foi sugerido por um colega mais experiente quando discutimos exemplos do uso de mnemônicos. Se o sistema verificar se o arquivo está vazio, é necessário verificar se não está completamente vazio.Eu recomendo este teste: adicione um terminador de linha ao arquivo. Nem mesmo um espaço, mas um personagem especial. E veja como o sistema responde. E ela nem sempre responde bem =)Mouse grande (limite superior)Se falamos de mouse grande, geralmente há um número infinito de bugs:- Guerra e paz;- muitos dados;- 2 GB.Você pode fazer upload de guerra e paz em um campo de texto, fazer upload de um arquivo enorme para o sistema, obter muitos dados de entrada ou saída. Todos esses são erros comuns que encontrei na minha prática. E não apenas eu, o limite superior é frequentemente verificado apenas porque eles sabem que pode haver erros. Em vez disso, eles esquecem o mouse pequeno.Outro exemplo de um mouse grande é o teste de estresse. Oh!
Eu tenho esses exemplos, então vamos ao hardcore.Se você conhece o contexto, se sabe como seu aplicativo funciona por dentro, em qual linguagem de programação está escrito, em qual banco de dados ele usa, você também pode usar esse mnemônico. E quero mostrar isso com exemplos concretos.Meus exemplos de prática
Rato grande
Linux, Lucene, Mmap
No sistema operacional Linux, há uma configuração para o número máximo de descritores de arquivos abertos:- redhat-6 - /etc/security/limits.conf
- redhat-7 - / etc / systemd / system / [nome do serviço] .service.d / limits.conf (para cada serviço próprio)
Um descritor de arquivo é aberto para qualquer ação com arquivos:- criar uma conexão com o banco de dados;
- leia o arquivo;
- escreva para um arquivo.
- ...
Se o seu sistema trabalha ativamente com arquivos e realiza muitas operações, a configuração precisa ser aumentada. Caso contrário, a menor carga irá colocá-lo.Nosso sistema usa o índice de pesquisa Lucene. É quando pegamos alguns dados do banco de dados e os carregamos no disco, para que mais tarde possamos procurá-los mais rapidamente. E se construirmos o índice usando a tecnologia mmap, ele criará muitos arquivos para gravação durante a construção do índice.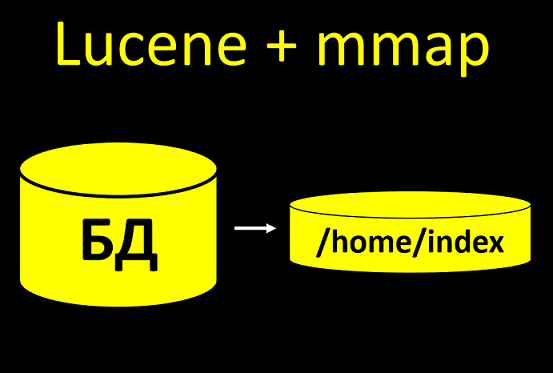 A base de teste geralmente tem 100 clientes, bem, 1000. Não tantos. A reconstrução é executada sem problemas, mesmo se você não configurar os descritores.E no sistema real, haverá mais de 10 milhões de clientes. E se você não configurar o número de descritores de arquivo, então, quando você começar a criar índices, tudo irá falhar.Você precisa saber sobre isso e escrever imediatamente uma instrução: configure o sistema operacional no servidor, caso contrário, haverá tais e tais conseqüências. E, por outro lado, é importante realizar não apenas testes funcionais, mas também testes de estresse, com uma quantidade real de dados.
A base de teste geralmente tem 100 clientes, bem, 1000. Não tantos. A reconstrução é executada sem problemas, mesmo se você não configurar os descritores.E no sistema real, haverá mais de 10 milhões de clientes. E se você não configurar o número de descritores de arquivo, então, quando você começar a criar índices, tudo irá falhar.Você precisa saber sobre isso e escrever imediatamente uma instrução: configure o sistema operacional no servidor, caso contrário, haverá tais e tais conseqüências. E, por outro lado, é importante realizar não apenas testes funcionais, mas também testes de estresse, com uma quantidade real de dados.Redhat 6 ≠ Redhat 7
Ao testar um mouse grande (carga), não esqueça que em diferentes configurações o aplicativo funcionará de maneira diferente. Se você seguir as instruções do último parágrafo, ele deverá não apenas ser escrito, mas também verificado. E verifique o ambiente do cliente.Porque diferentes sistemas operacionais funcionam de maneira diferente. E tivemos uma situação que parece que tudo está configurado, mas o sistema falha e diz "Não tenho descritores suficientes de arquivos abertos". Dizemos:- Verifique o parâmetro.- Ele está configurado, tudo está de acordo com as suas instruções!Como assim? Acontece que temos instruções para o Redhat 6, e eles têm o Redhat 7, onde a configuração está em um lugar completamente diferente! Como resultado, eles fizeram isso de acordo com as instruções que não funcionam e como se não o fizessem.Portanto, se você estiver trabalhando com diferentes versões das distribuições Linux, precisará verificar todas elas. E não apenas implantar os serviços em uma máquina, mas também realizar testes de carga pelo menos uma vez: verifique se tudo funciona. Afinal, é melhor detectar um bug em um ambiente de teste do que entender a produção posteriormente.Coleta de Java e Lixo
Usamos a linguagem java, que possui um coletor de lixo interno ... Às vezes, parece que se o aplicativo usa muita memória e está à beira do OOM (Memória insuficiente) para uma operação complexa, você pode resolver esse problema facilmente, simplesmente aumentando a quantidade de memória disponível ! Por que testar?Na verdade não. Dê muito Xmx - o aplicativo ficará no coletor de lixo ... E se manifestará repentinamente para o usuário. Aqui, à noite, eles arquivavam uma grande carga, baixavam muitos dados - especialmente depois de horas, para não incomodar ninguém. De manhã, o usuário chega, enquanto ele é o único que trabalha com o sistema, quase não há carga e tudo está congelando. E ele nem entende o porquê.Mas, de fato, a carga passou, a carga se foi e o coletor de lixo saiu para limpar tudo, por causa desse friso. E embora agora não haja carga e um usuário solitário esteja trabalhando, ele está triste.Portanto, apenas alocar muita memória para o aplicativo "e você não pode testá-lo" - isso não funciona. Melhor checar.
E se manifestará repentinamente para o usuário. Aqui, à noite, eles arquivavam uma grande carga, baixavam muitos dados - especialmente depois de horas, para não incomodar ninguém. De manhã, o usuário chega, enquanto ele é o único que trabalha com o sistema, quase não há carga e tudo está congelando. E ele nem entende o porquê.Mas, de fato, a carga passou, a carga se foi e o coletor de lixo saiu para limpar tudo, por causa desse friso. E embora agora não haja carga e um usuário solitário esteja trabalhando, ele está triste.Portanto, apenas alocar muita memória para o aplicativo "e você não pode testá-lo" - isso não funciona. Melhor checar.Wildfly
O servidor de aplicativos Java WildFly não permitirá o download de arquivos grandes, se não estiver configurado adequadamente. Usamos o servidor de aplicativos Jboss, também conhecido como Wildfly. E acontece que, por padrão, você não pode fazer upload de arquivos grandes para ele. E lembramos que o mouse deve ser GRANDE. Se testarmos 5mb ou 50, tudo funcionará, tudo estará bem.Mas se você tentar fazer o download de 2 GB, o sistema apresentará um erro 404 e você não entenderá nada dos logs: os logs do aplicativo estão vazios. Como esse aplicativo não pode baixar um arquivo, o próprio Wildfly o corta.Se você não realizar testes do seu lado, o cliente poderá encontrar isso. E será muito desagradável, ele virá com a pergunta "Por que não está carregado?". E sem o desenvolvedor, você não pode dizer nada. Portanto, é melhor não esquecer de testar os limites, incluindo arquivos grandes a serem enviados ao sistema. Pelo menos você saberá o resultado de tais ações.E aqui podemos corrigi-lo aumentando o parâmetro max-post-size, ou fornecemos informações sobre a restrição e a prescrevemos na declaração de trabalho.
Usamos o servidor de aplicativos Jboss, também conhecido como Wildfly. E acontece que, por padrão, você não pode fazer upload de arquivos grandes para ele. E lembramos que o mouse deve ser GRANDE. Se testarmos 5mb ou 50, tudo funcionará, tudo estará bem.Mas se você tentar fazer o download de 2 GB, o sistema apresentará um erro 404 e você não entenderá nada dos logs: os logs do aplicativo estão vazios. Como esse aplicativo não pode baixar um arquivo, o próprio Wildfly o corta.Se você não realizar testes do seu lado, o cliente poderá encontrar isso. E será muito desagradável, ele virá com a pergunta "Por que não está carregado?". E sem o desenvolvedor, você não pode dizer nada. Portanto, é melhor não esquecer de testar os limites, incluindo arquivos grandes a serem enviados ao sistema. Pelo menos você saberá o resultado de tais ações.E aqui podemos corrigi-lo aumentando o parâmetro max-post-size, ou fornecemos informações sobre a restrição e a prescrevemos na declaração de trabalho.Registo
Outro exemplo para testar o mouse "grande". Sim, ela lembra de alguma forma mais exemplos ... Na maioria das vezes, ela pega bugs!Digamos que verifiquemos o log de erros. Que o erro foi gravado no rastreamento de pilha no log. Então nós verificamos, somos ótimos: sim, tudo é legal, tudo é gravado! E eu entendi tudo da pilha no texto do erro. Se o cliente cair, entenderei imediatamente o porquê. E o que acontecerá se não tivermos um erro, mas vários? Está tudo bem também, tudo está logado, está tudo bem! Mas lembramos que o mouse deve ser GRANDE:
E o que acontecerá se não tivermos um erro, mas vários? Está tudo bem também, tudo está logado, está tudo bem! Mas lembramos que o mouse deve ser GRANDE: O que acontecerá se tivermos muitos erros? Nós apenas tivemos essa situação. O sistema de origem carrega dados para a tabela de buffer no banco de dados. Nosso sistema pega esses dados a partir daí e, de alguma forma, trabalha com eles.O sistema de origem travou e fez o upload de um incremento incorreto, onde todos os dados estavam errados. Nosso sistema recebeu o incremento e há 13.600 erros. E quando Java tentou gerar um rastreamento de pilha para erros de 13k, ela consumiu toda a memória alocada a ele e disse: "Ah, espaço de heap de java".Como consertar isso? Adicionamos o parâmetro maxStoredErrors (padrão 100) à tarefa de carregamento - o número máximo de erros armazenados na memória para um fluxo. Ao atingir esse valor, os erros são registrados e a lista é limpa.Também removemos a duplicação de mensagens de erro sobre a execução de uma tarefa por nossa Tarefa e pelo Quarz RunShell, aumentando o nível de log da última para avisar (a mensagem é exibida em informações). Devido à duplicação, a pilha dobrou ...E qual é a conclusão dessa história? Não basta verificar "apenas para a direita". Este é um teste importante e útil, sim, ninguém discute. Examinamos se o erro está registrado em princípio, em qual teste etc. Mas é muito importante verificar o mouse GRANDE. O que acontece se houver muitos erros?E você precisa entender que "muito" - isso significa muito. Se você carregar um incremento de 10 erros e disser "10 erros também são normais, o sistema exibirá todos os rastreamentos de pilha", parece que eles fizeram o teste, mas não revelaram o problema. Se percebermos que o sistema exibe todas as mensagens, precisamos pensar com antecedência: o que acontecerá se houver MUITAS delas? E confira.
O que acontecerá se tivermos muitos erros? Nós apenas tivemos essa situação. O sistema de origem carrega dados para a tabela de buffer no banco de dados. Nosso sistema pega esses dados a partir daí e, de alguma forma, trabalha com eles.O sistema de origem travou e fez o upload de um incremento incorreto, onde todos os dados estavam errados. Nosso sistema recebeu o incremento e há 13.600 erros. E quando Java tentou gerar um rastreamento de pilha para erros de 13k, ela consumiu toda a memória alocada a ele e disse: "Ah, espaço de heap de java".Como consertar isso? Adicionamos o parâmetro maxStoredErrors (padrão 100) à tarefa de carregamento - o número máximo de erros armazenados na memória para um fluxo. Ao atingir esse valor, os erros são registrados e a lista é limpa.Também removemos a duplicação de mensagens de erro sobre a execução de uma tarefa por nossa Tarefa e pelo Quarz RunShell, aumentando o nível de log da última para avisar (a mensagem é exibida em informações). Devido à duplicação, a pilha dobrou ...E qual é a conclusão dessa história? Não basta verificar "apenas para a direita". Este é um teste importante e útil, sim, ninguém discute. Examinamos se o erro está registrado em princípio, em qual teste etc. Mas é muito importante verificar o mouse GRANDE. O que acontece se houver muitos erros?E você precisa entender que "muito" - isso significa muito. Se você carregar um incremento de 10 erros e disser "10 erros também são normais, o sistema exibirá todos os rastreamentos de pilha", parece que eles fizeram o teste, mas não revelaram o problema. Se percebermos que o sistema exibe todas as mensagens, precisamos pensar com antecedência: o que acontecerá se houver MUITAS delas? E confira.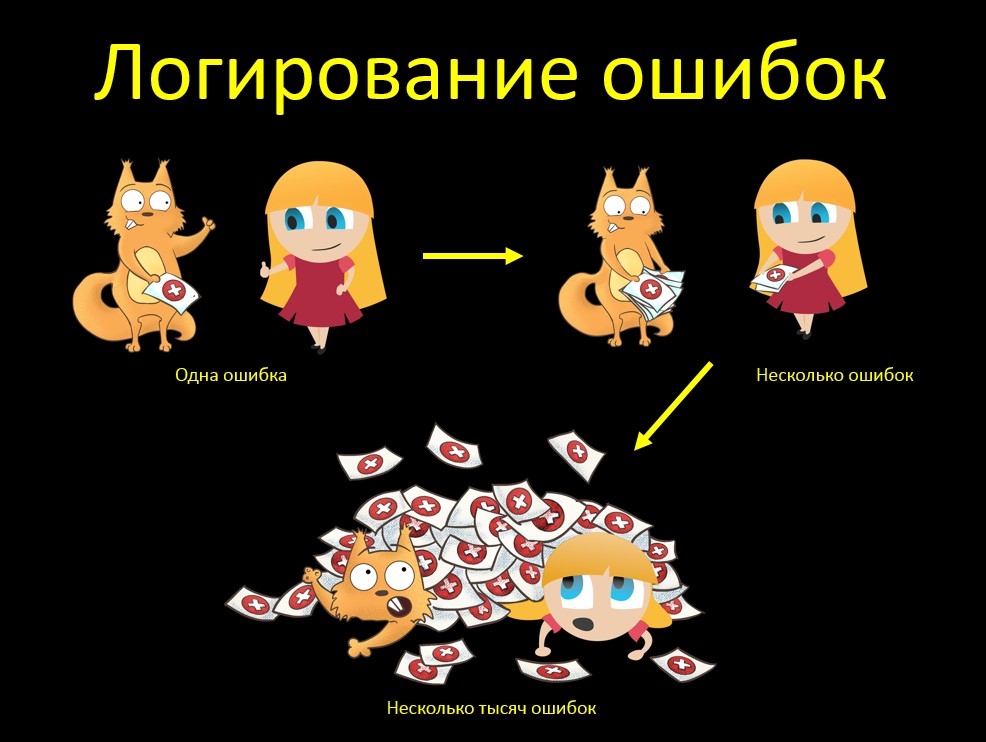
Transliteração
Se você tem algum tipo de princípio de transliteração, pode tentar descobrir, mas como isso funciona? Se ele transliterar duas letras como uma, o que acontecerá se introduzirmos três ou quatro letras idênticas?OO = ULLC =? E o que acontecerá se introduzirmos muitos deles? É possível que o sistema comece a classificar as opções e entre em recursão infinita e, em seguida, congele. Portanto, verificamos a longa fila:Oooohhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa -- ld - pelas -de-as-as-as- coisas- "
E o que acontecerá se introduzirmos muitos deles? É possível que o sistema comece a classificar as opções e entre em recursão infinita e, em seguida, congele. Portanto, verificamos a longa fila:Oooohhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa -- ld - pelas -de-as-as-as- coisas- "
Oracle RAC
Oracle é um banco de dados popular. O Oracle RAC é quando você tem várias instâncias de banco de dados. É necessário garantir o bom funcionamento dos sistemas críticos para os negócios: mesmo que uma instância seja quebrada, o restante continuará funcionando, o usuário nem saberá.
Se você usa o Oracle RAC - é OBRIGATÓRIO realizar testes de carga nele. Se você não o tiver, precisará perguntar ao cliente com quem ele está para realizar a carga de lado.
Aqui a questão pode surgir - por que então você não a possui? É simples, o hardware para teste geralmente é sempre pior. E se o sistema estiver focado apenas no Oracle e o RAC usar um cliente em cada vinte, comprá-lo para teste não será rentável, pois o RAC é muito caro. É mais fácil negociar com um cliente e ajudá-lo a realizar testes.
O que acontece se o teste de carga não for realizado? Aqui está um exemplo da vida.
No banco de dados, há uma oportunidade de criar uma coluna e dizer que é um campo de incremento automático. Isso significa que você não preenche totalmente o campo; o banco de dados o gera. Existe uma nova linha? Eu gravei o valor "1". Outra nova linha? Ela terá um valor de "2". E cada novo valor será cada vez mais.
Assim, por exemplo, é muito conveniente gerar identificadores. Você sempre sabe que seu ID é único. E para cada nova linha é mais do que para a anterior. Em teoria ...
Temos dois identificadores de entidade em nosso sistema:
- id - identificador de uma versão específica, campo de incremento automático;
- hid é um identificador histórico, para uma entidade é sempre constante e não muda.
Como resultado, você pode selecionar de acordo com uma versão específica ou selecionar pelo oculto de uma entidade e ver todo o seu histórico.
Quando uma entidade é criada, id = hid. E, em seguida, o id cresce, é sempre maior para novas versões do que o oculto. Portanto, a fórmula para determinar a versão:
versão = (id - oculto) + 1Não pode ser negativo, pois o id é criado pelo próprio banco de dados.
Mas aqui eles nos chegam com uma pergunta em essência e mostram registros do banco de dados. Não me lembro sobre o que era essa pergunta e isso não importa. Olho os registros e não consigo acreditar nos meus olhos: aí a versão tem valores negativos. Como assim ?? Isso é impossível. Acabou sendo possível.
No RAC, cada nó tem seu próprio cache. E pode acontecer que os nós não tenham tempo para notificar um ao outro e você tenha o mesmo número duas vezes no tablet:
- Cria uma entidade. Noda olha no cache, qual é o último valor do campo de incremento automático? Sim, 10. Então eu darei o identificador 11.
- Imediatamente, uma nova entidade chega ao segundo nó (as solicitações vieram simultaneamente e o balanceador lançou uma no nó 1 e a segunda no nó 2).
- O segundo nó procura em seu cache, qual é o último valor do campo? Sim, 10 (o primeiro nó ainda não conseguiu informar o segundo que levou esse número). Então eu darei o identificador 11.
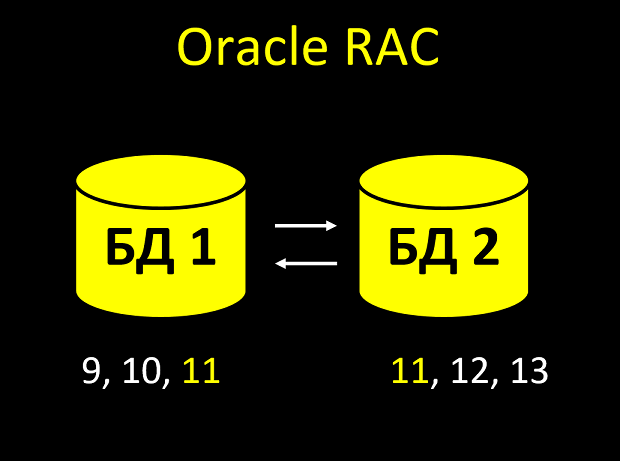
Total que não recebemos valor exclusivo de um campo exclusivo. E, afinal, com uma carga pesada dessas interseções de identificadores, não haverá um ou até dois ... Se você tiver toda a lógica de negócios ligada ao fato de que o id é sempre único e sempre aumenta, será OH.
No nosso caso, nada de catastrófico aconteceu e o teste de carga na bancada de testes do cliente ajudou. Descobrimos o problema desde o início, como se viu, versões negativas do sistema não interferem na vida. Mas adicionamos o sequenciamento aos scripts de criação de banco de dados, apenas para esses casos.
A moral dessa fábula é essa - é MUITO importante realizar testes de carga no mesmo hardware que estará no PROD. Tudo pode afetar o resultado: as configurações do próprio sistema operacional, as configurações do banco de dados, sim qualquer coisa. O que você nem suspeitou.
Teste com antecedência. E lembre-se de que nem todos os problemas podem ser encontrados por testes funcionais. Neste exemplo, um teste simples não encontraria erros. De fato, se você criar entidades manualmente, ou seja, lentamente, todos os nós do banco de dados terão tempo para notificar os nós vizinhos, para que não tenhamos inconsistência.
Ratinho
Json vazio
Se você usar a biblioteca aberta do Axis, tente enviar JSON vazio para o aplicativo. Ele pode muito bem pendurá-lo completamente.
E o mais importante - você não pode fazer nada do seu lado! Este é um erro em uma biblioteca de terceiros. Então, aqui, aguardando uma correção oficial ou alterando a biblioteca, o que pode ser muito difícil.
De fato, esse bug já foi corrigido na nova versão do Axis. Parece que basta atualizar, e é isso! Mas ... O sistema raramente usa uma biblioteca de terceiros. Normalmente existem vários deles, eles estão amarrados um em cima do outro. Para atualizá-los, você precisa atualizar tudo de uma vez. É necessário realizar a refatoração, porque agora eles funcionam de maneira diferente. Os recursos do desenvolvedor devem ser alocados.
Em geral, apenas atualizar a versão da biblioteca às vezes requer um release completo de um desenvolvedor legal. Por exemplo, quando mudamos para a nova versão do Lucene, passamos 56 horas na tarefa, ou seja, 7 dias por homem, uma semana do desenvolvedor em tempo integral e mais testes. A tarefa em si se parece com isso, o arquiteto coloca:
Lucene Alterne para usar PointValues em vez de Long / IntegerField
A doca Lucene Migration 5 -> 6 possui uma cláusula sobre a eliminação do campo Long (Integer / Double) em favor de PointValues.
Ao mudar para o Lucene 6.3.1, deixei os campos antigos (todas as classes foram renomeadas com a adição do prefixo Legado), porque a tradução é direcionada para uma tarefa separada.
Você precisa abandonar os campos antigos e usar as classes de ponto longo (inteiro / duplo), que são mais rápidas e menos ponderadas no índice pelos testes. Tem que reescrever muito código.
Claro! A transição deve ser compatível com versões anteriores para que a pesquisa (pelo menos as funções principais) não seja interrompida com a atualização da versão. Ele deve funcionar no índice antigo (antes da reconstrução) e após a reconstrução (no momento conveniente para o cliente), novos campos devem ser selecionados.
E isso é apenas uma atualização da biblioteca! E abandonar uma biblioteca por causa de um bug é geralmente assustador imaginar quanto tempo levará ...
Portanto, é bem possível que, por algum tempo, você simplesmente viva com um bug. Saiba sobre ele, mas não mude nada. No final, "não há nada para enviar solicitações tolas".
Mas, em qualquer caso, você deve pelo menos saber sobre a presença de um bug. Porque se um usuário vem até você e diz: "Tudo desligou em você", você deve entender o porquê. Dado que os logs estão vazios. Como esse aplicativo não é congelado, tudo trava no estágio de conversão JSON.
Parece - um pedido vazio! E aqui isso pode levar a ... Ou seja, mesmo que você não saiba que o Axis tem esse bug, basta verificar o JSON vazio, uma solicitação SOAP vazia. No final, este é um ótimo exemplo de um teste zero no contexto de uma solicitação JSON.
Lembre-se de testar zero. E o menor valor é o ratinho, porque também traz bugs, às vezes muito assustadores.
Veja também:A classe de equivalência "Zero-não zero" - mais sobre como testar zero
"Moscow" no campo de endereço
O serviço
da Dadat é capaz de padronizar endereços - coloque o endereço em uma linha em componentes granulares + determine a área do apartamento, se estiver no diretório.
Durante o teste, um bug engraçado foi encontrado - se você digitar a palavra "Moscou" no endereço, o sistema determinará a área do apartamento. Embora, ao que parece, onde está o apartamento nesse "endereço"?

Eu acho que este é um ótimo exemplo de um "ratinho". Porque o que geralmente é verificado? O endereço habitual, o endereço da rua, da casa ... Um campo vazio. Qualquer caractere único - é considerado um teste de unidade.
Mas se você digitar uma letra, o sistema determinará a entrada como uma lixeira completa e limpará o endereço. Ele se comporta corretamente, mas esse é um caso negativo por unidade. Esta é uma verificação exclusivamente do tamanho do campo.
E aqui vale a pena pensar mais - existe uma unidade positiva? Existe. Uma palavra, esse sistema determinará. E aqui também existem diferentes classes de equivalência: pode ser uma palavra desde o início do endereço (cidade) ou pode ser do meio (rua). Vale a pena tentar os dois. Mas se você se restringir apenas a "unidade no campo de texto = um caractere", nunca encontrará esse bug.
Total
Mnemônico, existem muitos. E usá-los pode ajudá-lo. Como você já está analisando seu aplicativo pela décima, centésima vez ... Você já perdeu os olhos, pode pular o erro óbvio. E se você usar qualquer mnemônica existente, observe o aplicativo de uma nova maneira. O que ajudará a detectar novos bugs.
E mesmo uma mnemônica simples como a BMW ajuda muito. Mas, parece ... Grande, pequeno, pense! Valores limite simples. Mas eles devem sempre ser lembrados e sempre verificados! Traz frutas e uma variedade de insetos.
Usando meus exemplos, eu queria mostrar que você pode procurar bordas não apenas em um campo numérico ou de texto. O Mnemonics funciona em qualquer lugar: no Oracle RAC, Java, Wildfly, em qualquer lugar! Aprenda a examinar os limites além do entendimento usual de "inserir Guerra e Paz na caixa de texto".
Obviamente, a ênfase principal está no "rato grande", que traz mais bugs. São precisamente esses casos que são lembrados quando você pensa que se encontrou no seu projeto.
Mas você não deve esquecer o "ratinho". Sim, consegui lembrar apenas alguns exemplos específicos do meu trabalho. Mas isso não significa que não encontro bugs em um mouse pequeno. Eu acho! Aqueles que estão na seção de exemplos gerais: 01.01.1900 data, arquivo de 1 kb, relatório vazio quando os dados são preenchidos ...
Fronteiras são muito importantes. Lembre-se de testá-los. Espero que meus exemplos o inspirem, e os mnemônicos da BMW sempre aparecerão na minha cabeça ao destacar as classes de equivalência.
Ou talvez você venha com seus próprios mnemônicos. Qual será para você, sua equipe, seus recursos e seus processos. E também é ótimo, também é sucesso. O principal é que isso ajuda!
PS é um trecho do
meu livro para testadores iniciantes. Eu também falei sobre mnemônicos em um relatório do SQA Days,
vídeo aqui .