Oi Meu nome é Konstantin Evteev, trabalho em Avito como líder da unidade de DBA. Nossa equipe desenvolve sistemas de armazenamento Avito, ajuda na seleção ou emissão de bancos de dados e infraestrutura relacionada, oferece suporte ao Objetivo de nível de serviço para servidores de banco de dados e também somos responsáveis pela eficiência e monitoramento de recursos, aconselhamos sobre o design e, possivelmente, desenvolvemos microsserviços, vinculado a sistemas de armazenamento ou serviços para o desenvolvimento da plataforma no contexto de armazenamento.
Quero contar como resolvemos um dos desafios da arquitetura de microsserviços: realizar transações comerciais na infraestrutura de serviços criados usando o banco de dados por padrão de serviço. Fiz uma apresentação sobre esse tópico na conferência Highload ++ Siberia 2018 .

Teoria O mais curto possível
Não descreverei em detalhes a teoria das sagas. Vou fazer uma breve introdução para que você entenda o contexto.
Como era antes (do início de Avito até 2015 - 2016): vivíamos em um monólito, com bases monolíticas e aplicações monolíticas. Em algum momento, essas condições começaram a nos impedir de crescer. Por um lado, encontramos o desempenho de um servidor com um banco de dados principal, mas esse não é o principal motivo, pois o problema de desempenho pode ser resolvido, por exemplo, usando sharding. Por outro lado, o monólito tem uma lógica muito complexa e, em um certo estágio de crescimento, a entrega de alterações (lançamentos) se torna muito longa e imprevisível: existem muitas dependências não óbvias e complexas (tudo está intimamente conectado), também é difícil de testar, em geral há muitos problemas. A solução é mudar para a arquitetura de microsserviço. Nesse estágio, tivemos uma dúvida sobre transações comerciais fortemente vinculadas a ACIDs fornecidos por uma base monolítica: não está claro como migrar essa lógica de negócios. Ao trabalhar com o Avito, existem muitos cenários diferentes implementados por vários serviços quando a integridade e a consistência dos dados são muito importantes, por exemplo, comprar uma assinatura premium, debitar dinheiro, aplicar serviços a um usuário, comprar pacotes VAS - em caso de acidentes ou imprevistos, tudo pode não acontecer inesperadamente de acordo com o plano. Encontramos a solução nas sagas.
Gosto da descrição técnica das sagas em 1987 por Kenneth Salem e Hector Garcia-Molina, um dos atuais membros do conselho de administração da Oracle. Como o problema foi formulado: há um número relativamente pequeno de transações de longa duração que, durante muito tempo, impedem a execução de operações pequenas, com menos recursos e mais frequentes. Como resultado desejado, você pode dar um exemplo da vida: com certeza, muitos de vocês ficaram na fila para copiar documentos, e o operador da copiadora, se ele tivesse a tarefa de copiar um livro inteiro ou apenas muitas cópias, fazia cópias de outros membros da fila de tempos em tempos. Mas o descarte de recursos é apenas parte do problema. A situação é agravada por bloqueios de longo prazo ao executar tarefas que consomem muitos recursos, cuja cascata será construída no seu DBMS. Além disso, podem ocorrer erros durante uma transação longa: a transação não será concluída e a reversão começará. Se a transação foi longa, a reversão também levará muito tempo e provavelmente haverá uma nova tentativa do aplicativo. Em geral, "tudo é bastante interessante". A solução proposta na descrição técnica do SAGAS é dividir uma transação longa em partes.
Parece-me que muitos abordaram isso sem sequer ler este documento. Nós falamos repetidamente sobre nosso defproc (procedimentos adiados implementados usando o pgq). Por exemplo, ao bloquear um usuário por fraude, executamos rapidamente uma transação curta e respondemos ao cliente. Nesta transação curta, inclusive, colocamos a tarefa em uma fila transacional e, em seguida, de forma assíncrona, em pequenos lotes, por exemplo, dez anúncios bloqueiam seus anúncios. Fizemos isso implementando filas transacionais do Skype .
Mas nossa história hoje é um pouco diferente. Precisamos analisar esses problemas do outro lado: ser um monólito em microsserviços criados usando o banco de dados por padrão de serviço.
Um dos parâmetros mais importantes para nós é alcançar a velocidade máxima de corte. Portanto, decidimos transferir a funcionalidade antiga e toda a lógica para microsserviços, sem alterar nada. Requisitos adicionais que precisávamos cumprir:
- Fornecer alterações de dados dependentes para dados críticos de negócios
- ser capaz de definir uma ordem estrita;
- observe cem por cento de consistência - coordene os dados mesmo em caso de acidentes;
- garantir a operação de transações em todos os níveis.
Sob os requisitos acima, a solução na forma de uma saga orquestrada é a mais adequada.
Implementação de uma saga orquestrada como um serviço PG Saga
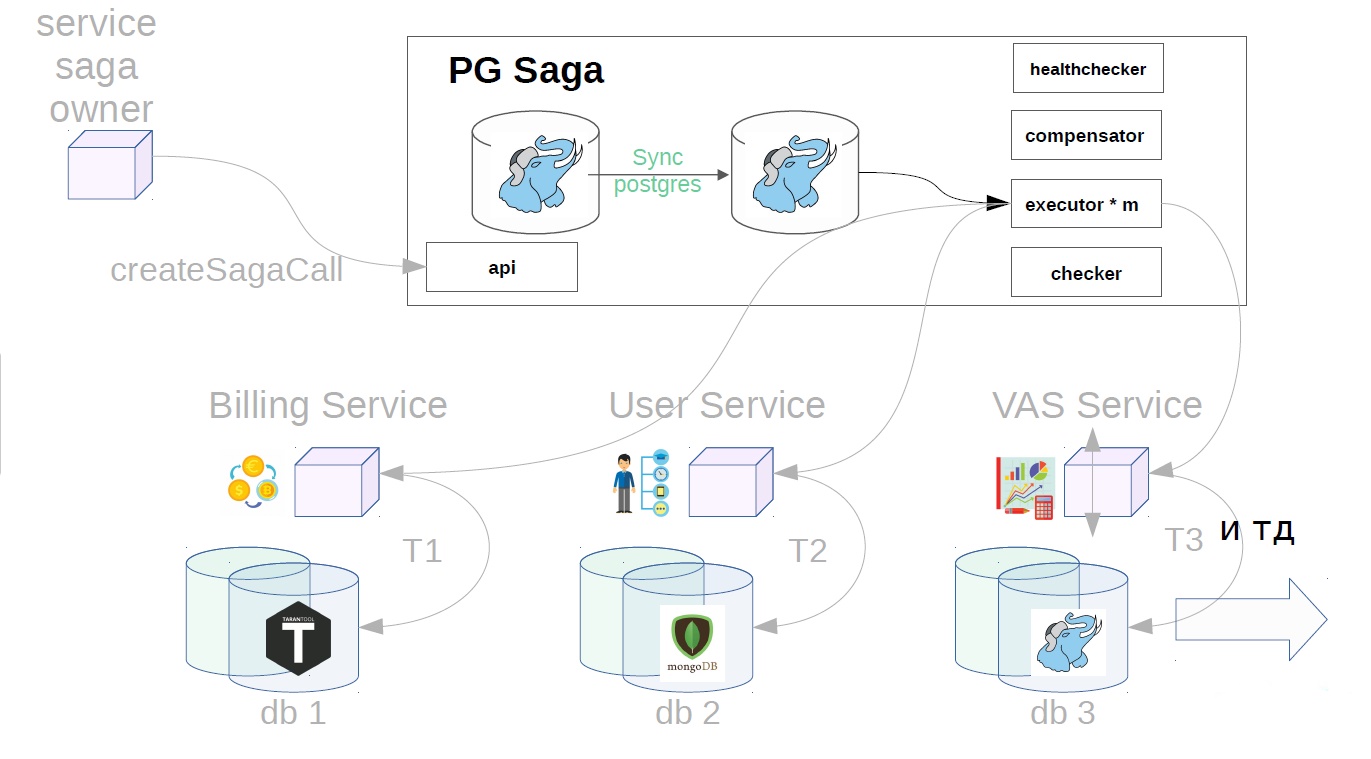
É assim que o serviço da PG Saga se parece.
PG no nome, porque o PostgreSQL síncrono é usado como um repositório de serviços. O que mais há dentro:
- API
- executor;
- verificador;
- verificador de saúde;
- compensador.
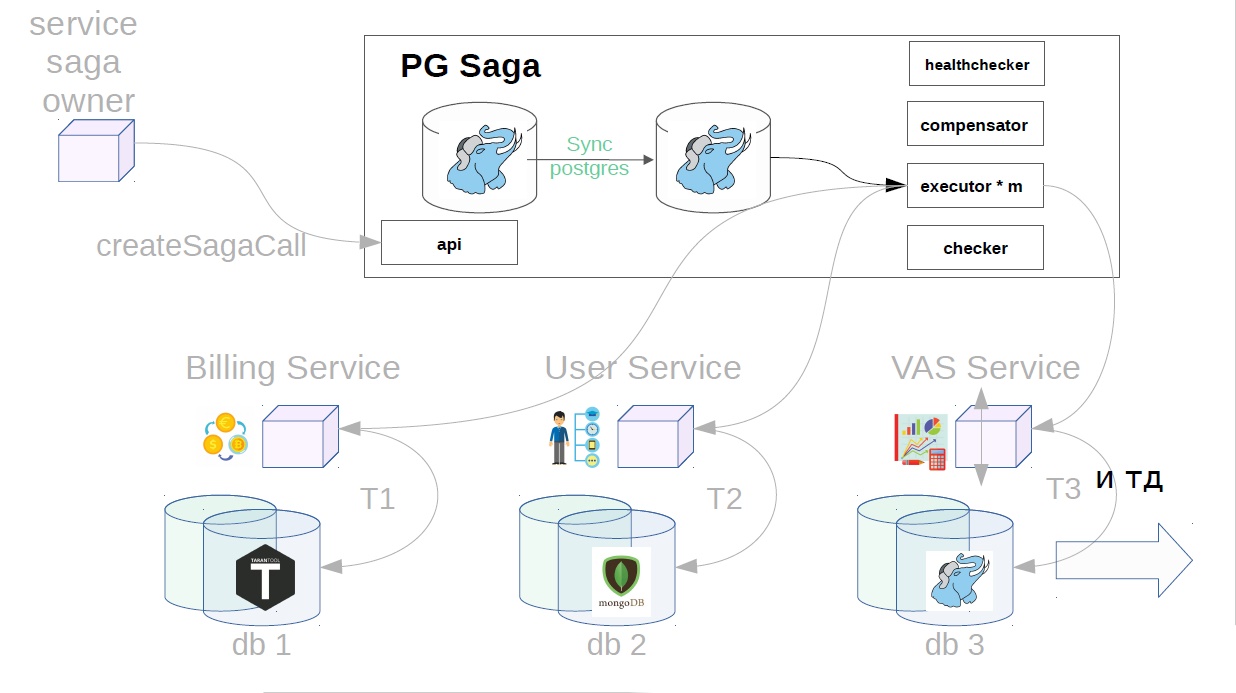
O diagrama também mostra o proprietário do serviço das sagas e abaixo estão os serviços que executarão as etapas da saga. Eles podem ter repositórios diferentes.
Como isso funciona
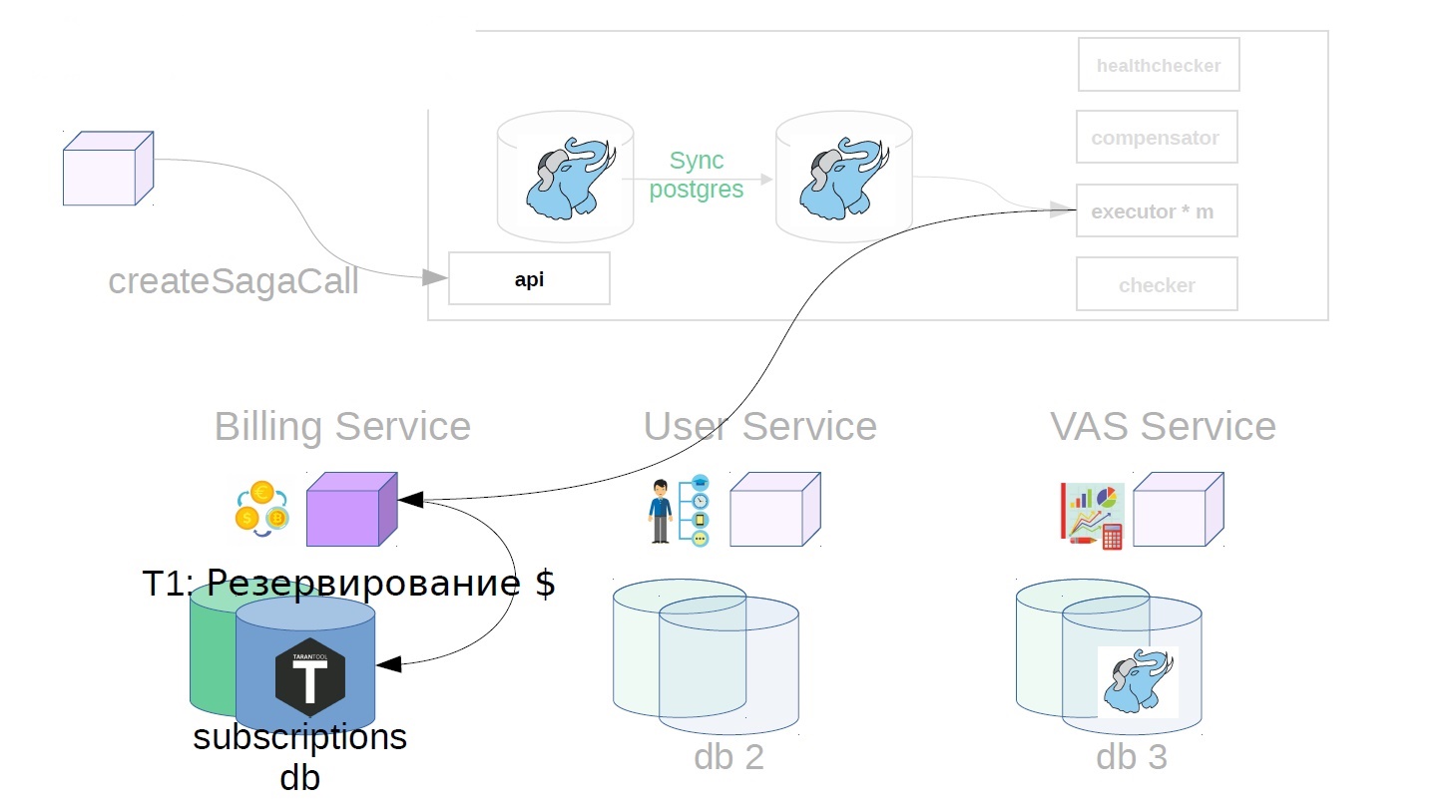
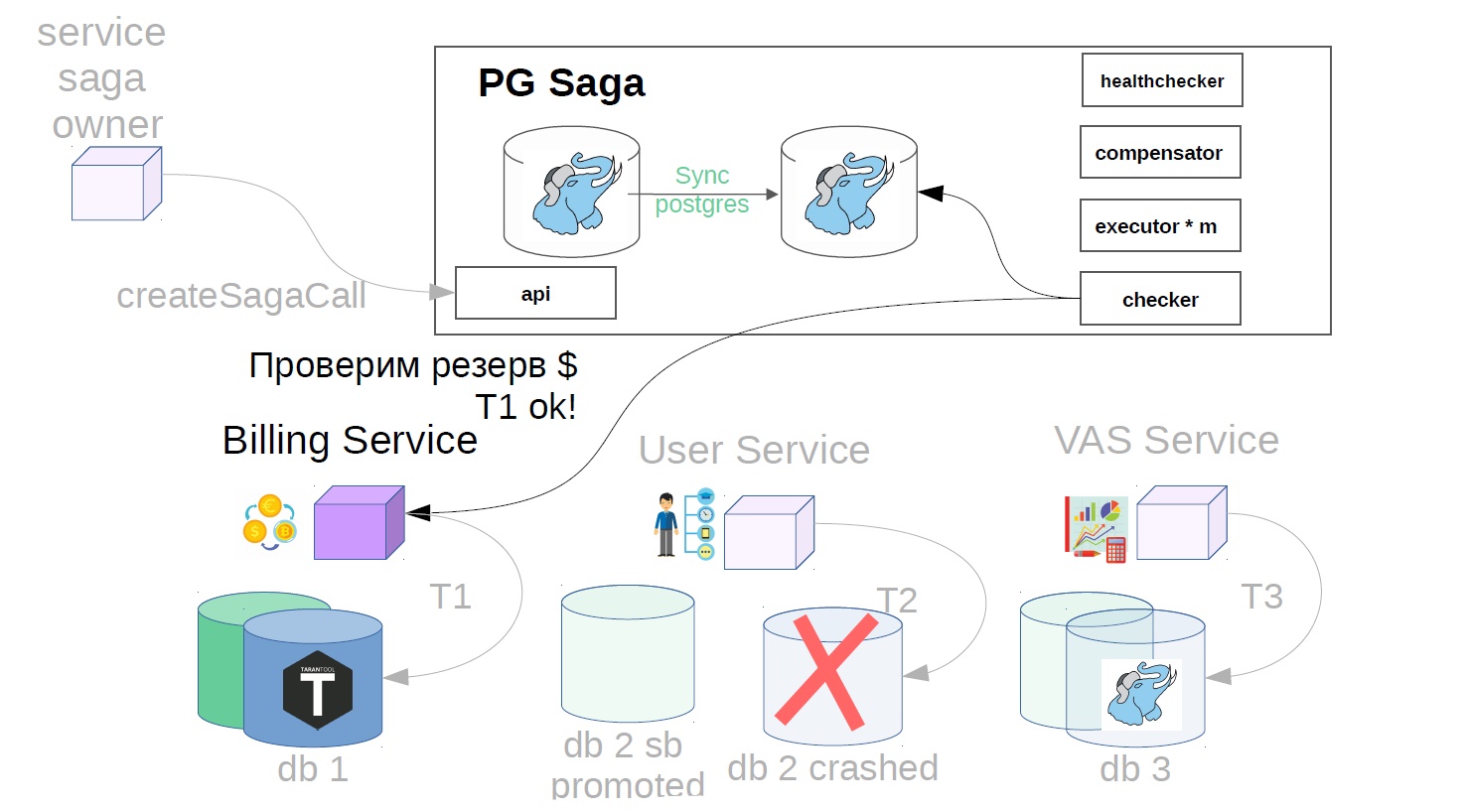
Considere o exemplo de compra de pacotes VAS. VAS (serviços com valores agregados) - serviços pagos para promoção de anúncios.
Primeiro, o proprietário do serviço da saga deve registrar a criação da saga no serviço da saga
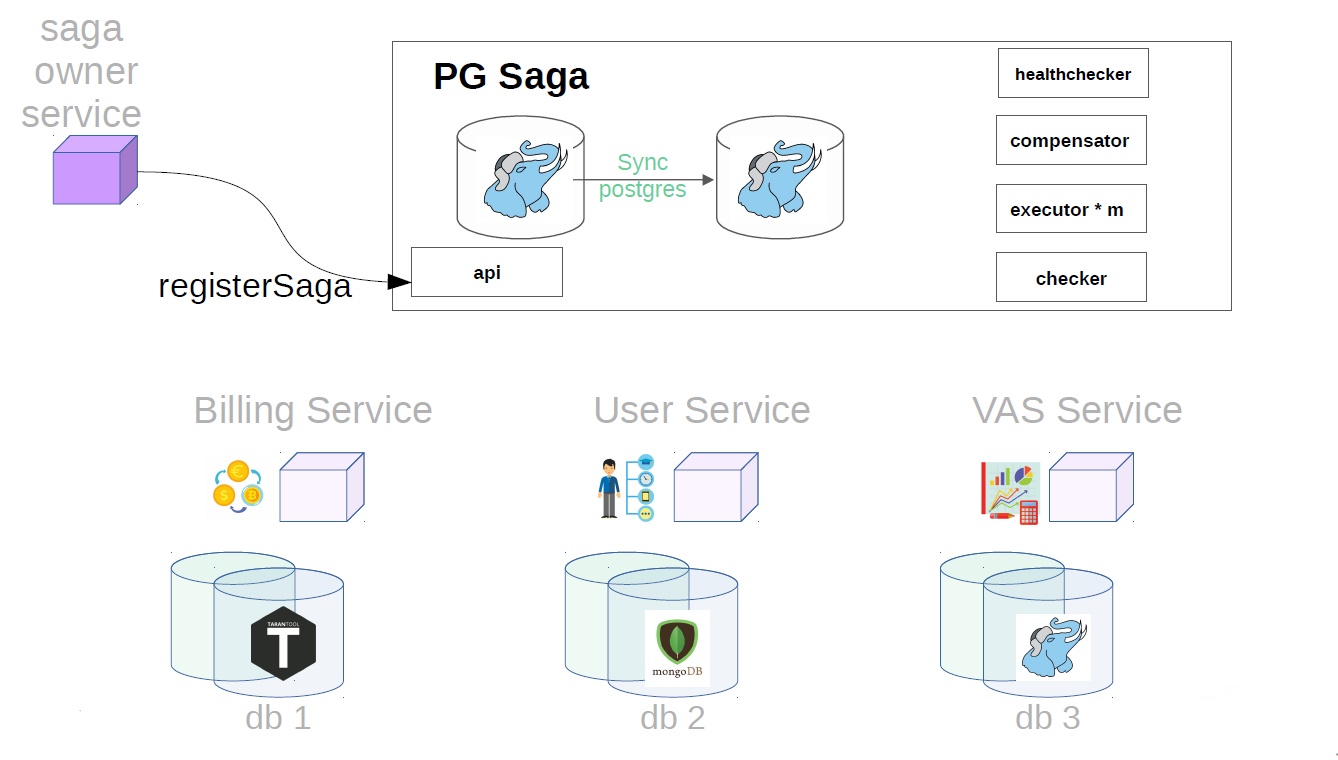
Depois disso, ele gera uma classe de saga já com Payload.
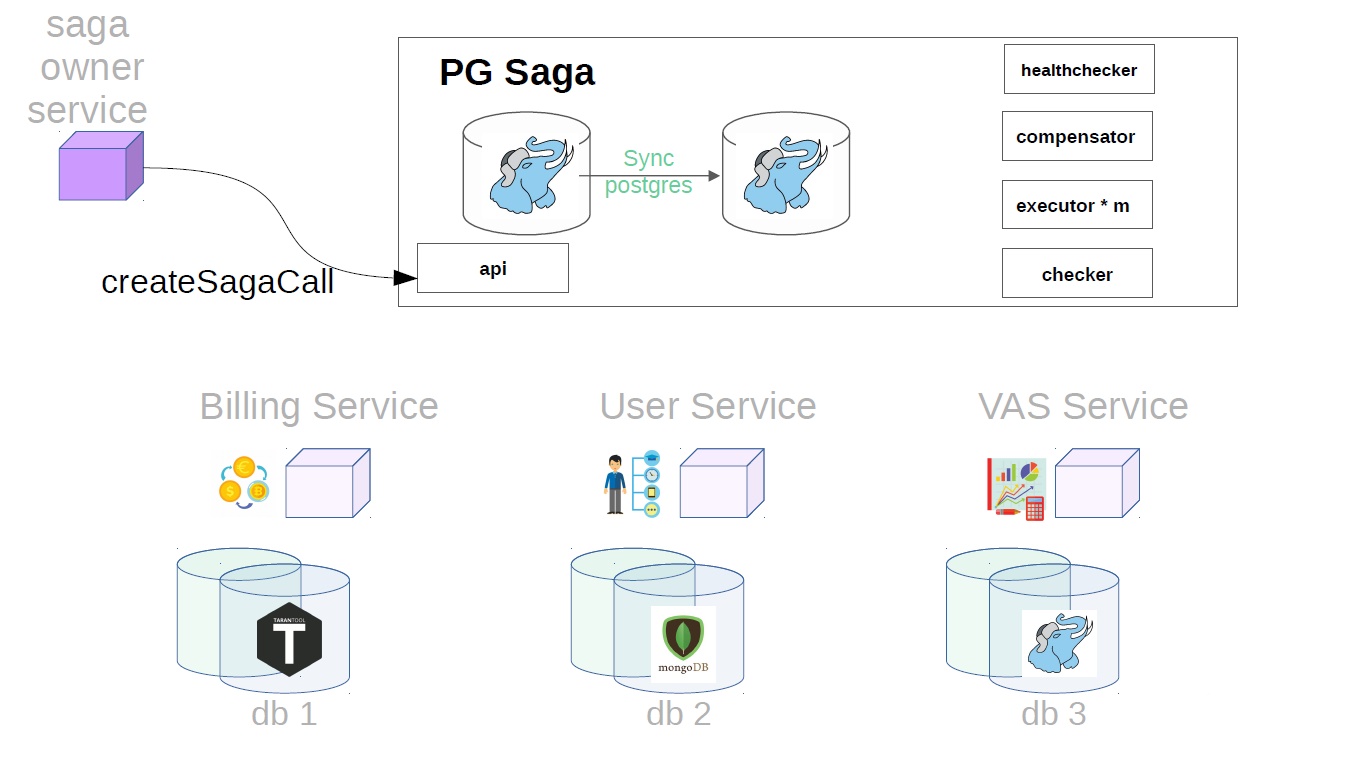
Além disso, já no serviço sag, o executor atende a chamada de saga criada anteriormente na loja e começa a executá-la em etapas. O primeiro passo no nosso caso é comprar uma assinatura premium. Neste momento, o dinheiro é reservado no serviço de cobrança.

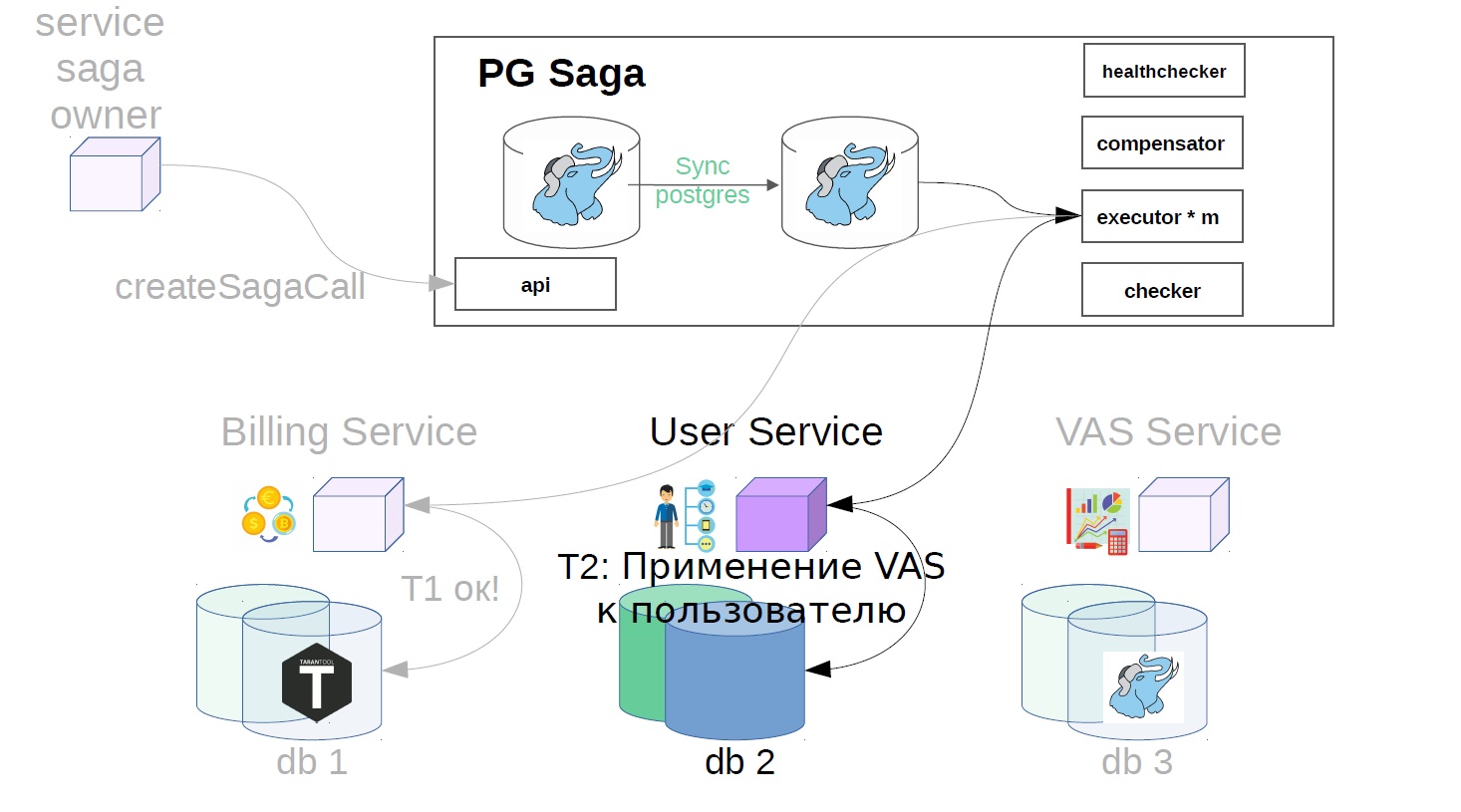
Em seguida, no serviço do usuário, as operações do VAS são aplicadas.
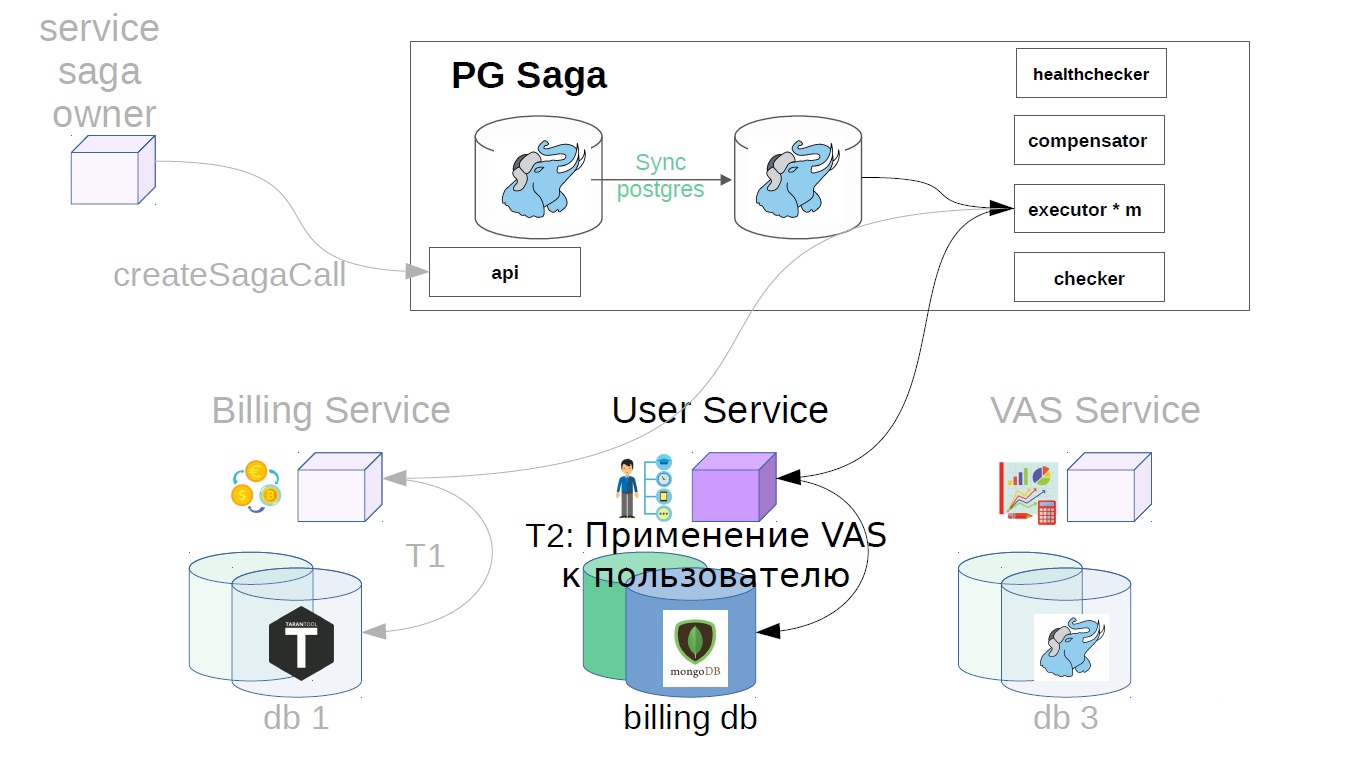
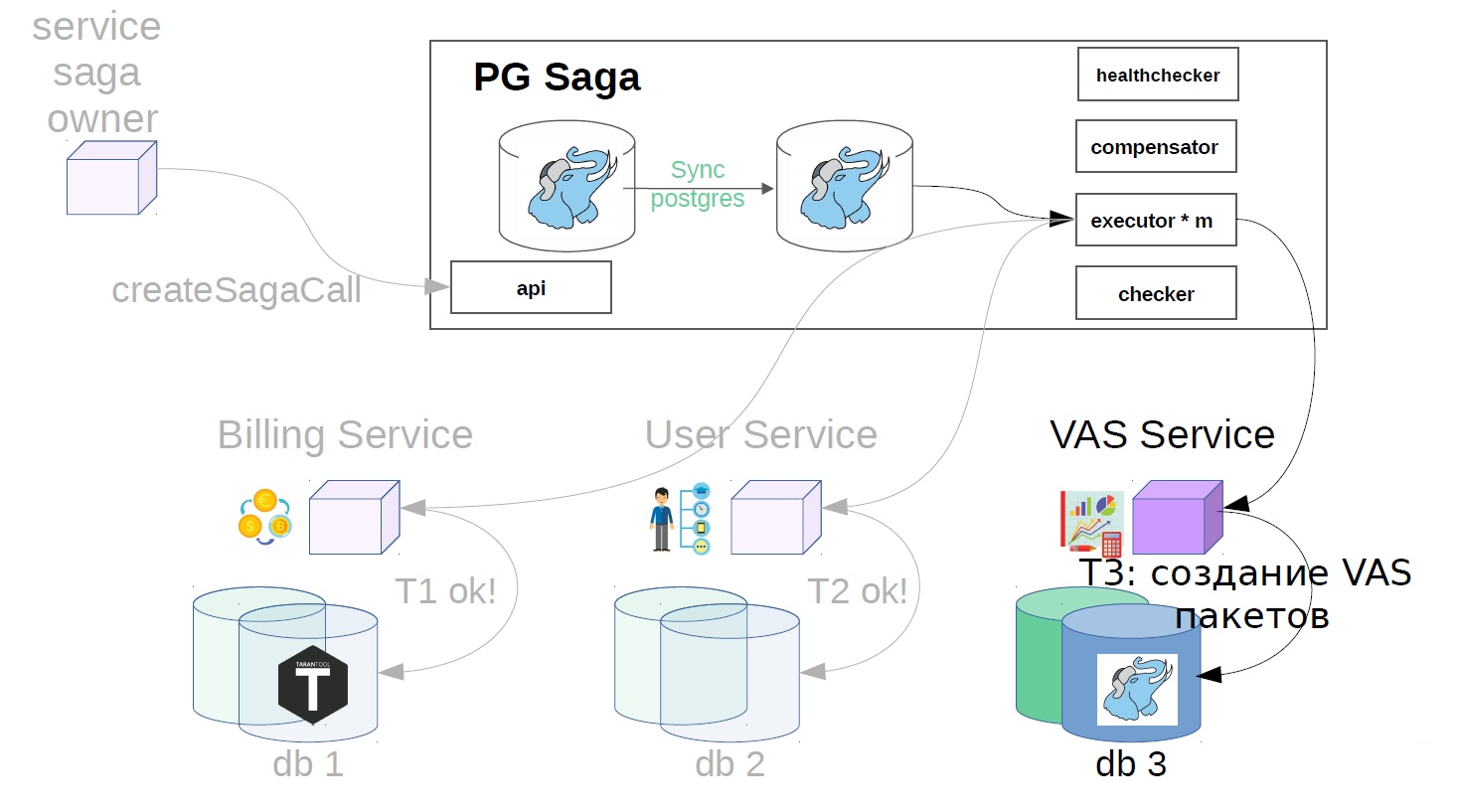
Os serviços VAS já estão em vigor e os pacotes são criados. Outros passos são possíveis ainda mais, mas não são tão importantes para nós.
Crashes
Os acidentes podem ocorrer em qualquer serviço, mas existem truques conhecidos sobre como se preparar para eles. Em um sistema distribuído, é importante conhecer essas técnicas. Por exemplo, uma das limitações mais importantes é que a rede nem sempre é confiável. Abordagens que resolverão os problemas de interação em sistemas distribuídos:
- Nós tentamos novamente.
- Marcamos cada operação com uma chave idempotente. Isso é necessário para evitar duplicação de operações. Mais sobre chaves idempotentes podem ser encontradas neste artigo.
- Nós compensamos as transações - uma característica da ação das sagas.
Compensação da transação: como funciona
Para cada transação positiva, devemos descrever as ações reversas: um cenário de negócios da etapa, caso algo dê errado.
Em nossa implementação, oferecemos o seguinte cenário de remuneração:
Se alguma etapa da saga não teve êxito e fizemos várias tentativas, há uma chance de que a última repetição da operação tenha sido um sucesso, mas simplesmente não obtivemos uma resposta. Tentaremos compensar a transação, embora essa etapa não seja necessária se o executor do serviço da etapa com problema realmente quebrar e estiver completamente inacessível.
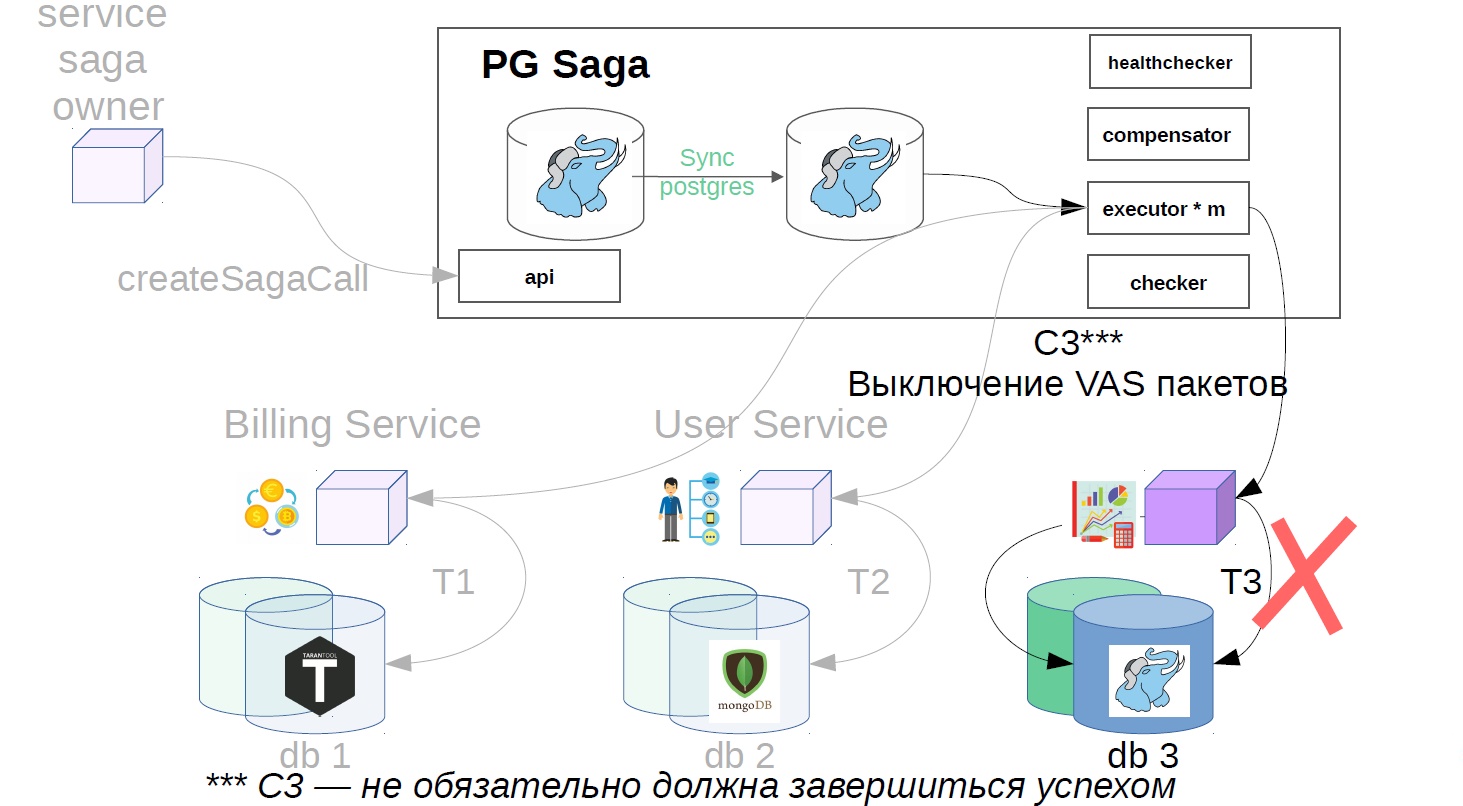
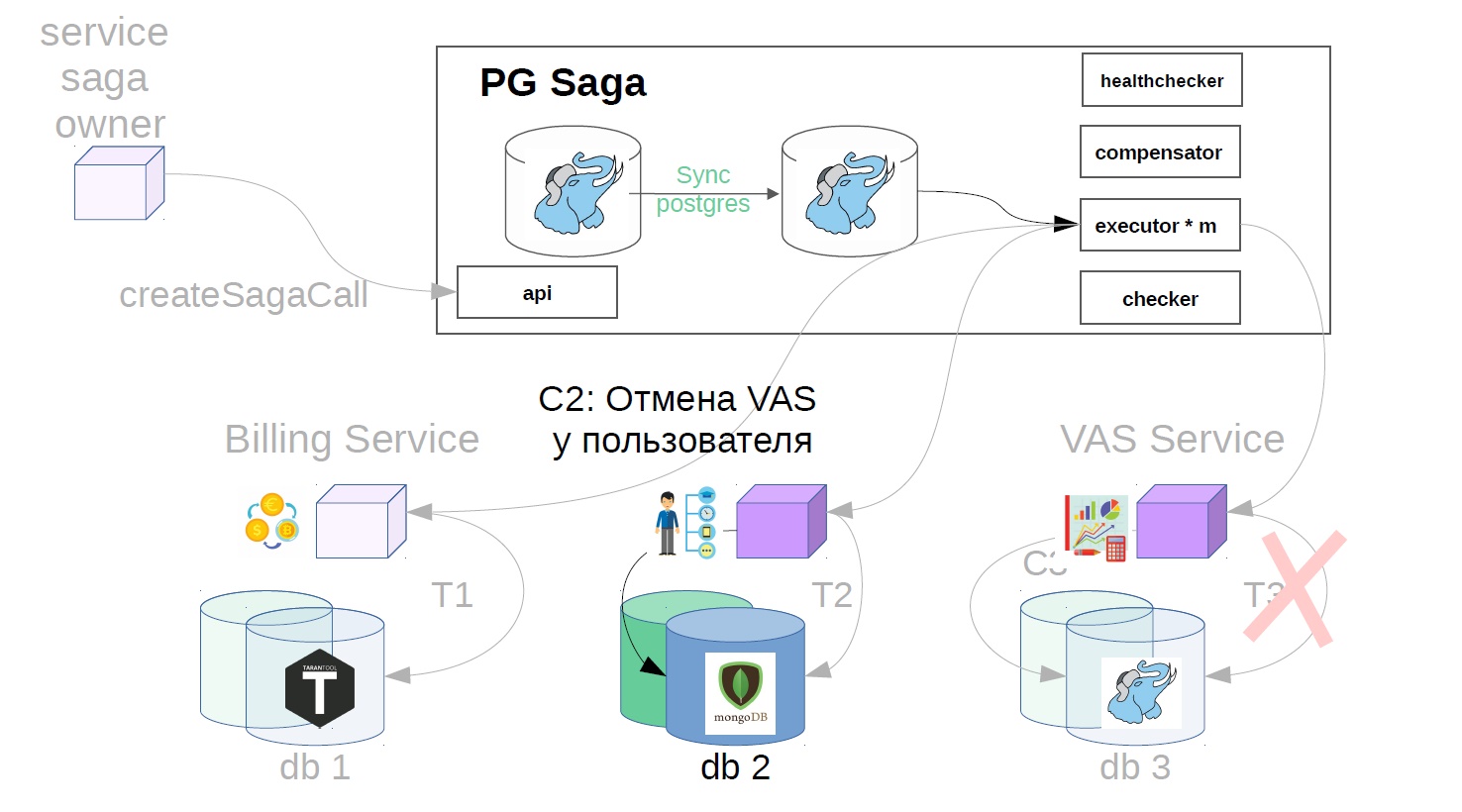
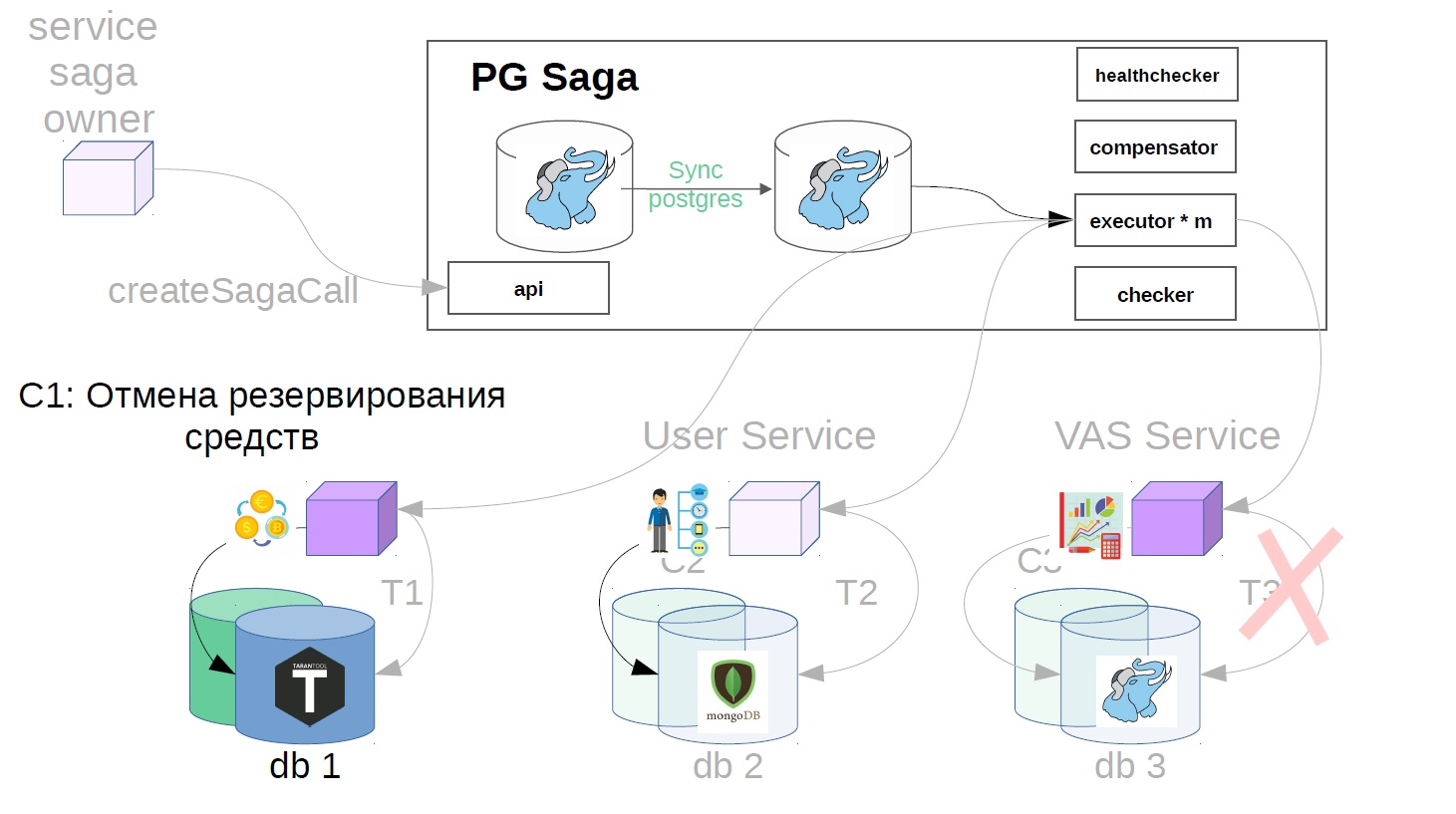
No nosso exemplo, será assim:
- Desative os pacotes VAS.
- Cancele a operação do usuário.
- Cancelamos a reserva de fundos.
O que fazer se a compensação não funcionar
Obviamente, devemos agir aproximadamente no mesmo cenário. Novamente, aplique novas chaves idempotentes para compensar transações, mas se nada sair desta vez, por exemplo, o serviço não está disponível, você deverá entrar em contato com o proprietário do serviço da saga, informando que a saga falhou. Além disso, ações mais sérias: escalonar o problema, por exemplo, para uma avaliação manual ou automação de lançamento para resolver esses problemas.
O que é mais importante: imagine que alguma etapa do serviço saga esteja indisponível. Certamente, o iniciador dessas ações fará algumas tentativas. E, no final, o serviço saga dá o primeiro passo, o segundo passo e seu executor não está disponível, você cancela o segundo passo, cancela o primeiro passo e também podem ocorrer anomalias relacionadas à falta de isolamento. Em geral, o serviço saga nessa situação está envolvido em um trabalho inútil, que ainda gera uma carga e erros.
Como fazer isso? O Healthchecker deve entrevistar os serviços que concluem as etapas de queda e ver se eles funcionam. Se o serviço se tornar indisponível, existem duas maneiras: compensar as sagas que estão em operação e impedir que novas sagas criem novas instâncias (chamadas) ou crie sem levá-las ao trabalho como executor para que o serviço não funcione. ações desnecessárias.
Outro cenário de acidente
Imagine que estamos fazendo a mesma assinatura premium novamente.
- Compramos pacotes VAS e reservamos dinheiro.
- Aplicamos serviços ao usuário.
- Criamos pacotes VAS.
Parece ser bom. Mas de repente, quando a transação foi concluída, verifica-se que a replicação assíncrona é usada no serviço ao usuário e ocorreu um acidente na base principal. Pode haver vários motivos para um atraso na réplica: uma carga específica na réplica que diminui a velocidade da reprodução da replicação ou bloqueia a reprodução da replicação. Além disso, a fonte (principal) pode ser sobrecarregada e um atraso no envio de alterações aparece no lado da fonte. Em geral, por algum motivo, a réplica estava atrasada e as alterações da etapa concluída com êxito após o acidente desapareceram repentinamente (resultado / estado).
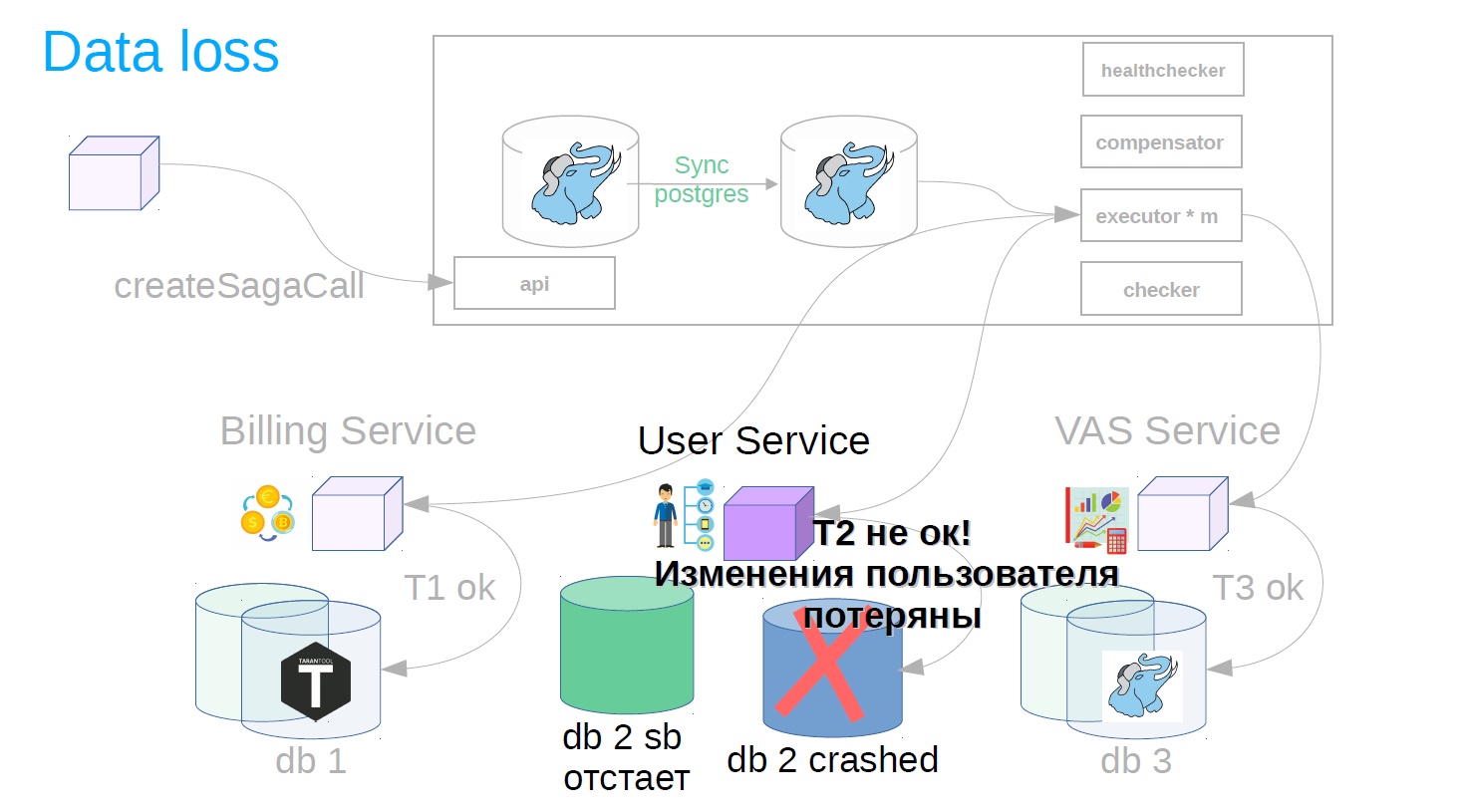
Para fazer isso, implementamos outro componente no sistema - usamos o verificador. O Checker verifica todas as etapas das sagas bem-sucedidas por um tempo conhecido por ser maior que todos os possíveis atrasos (por exemplo, após 12 horas) e verifica se elas ainda foram concluídas com êxito. Se o passo falhar repentinamente, a saga retrocede.
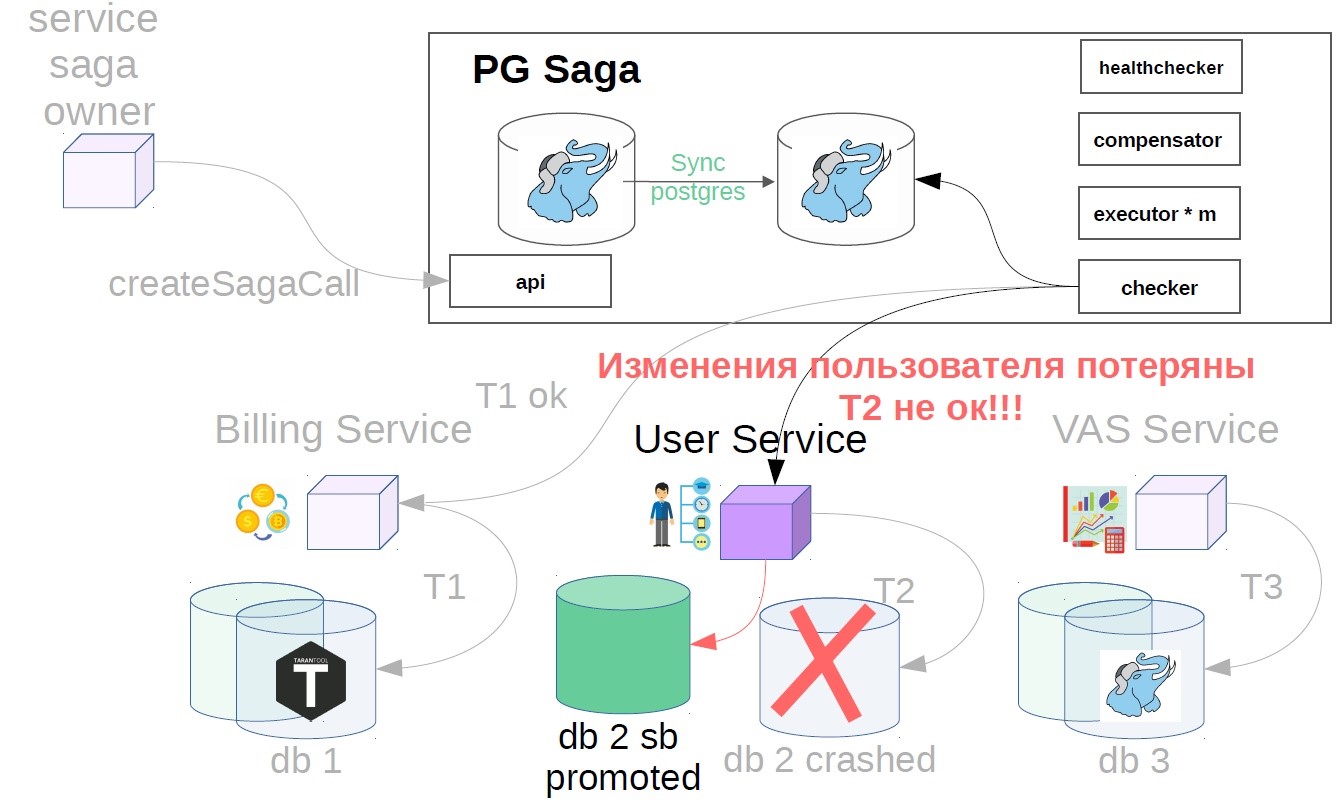
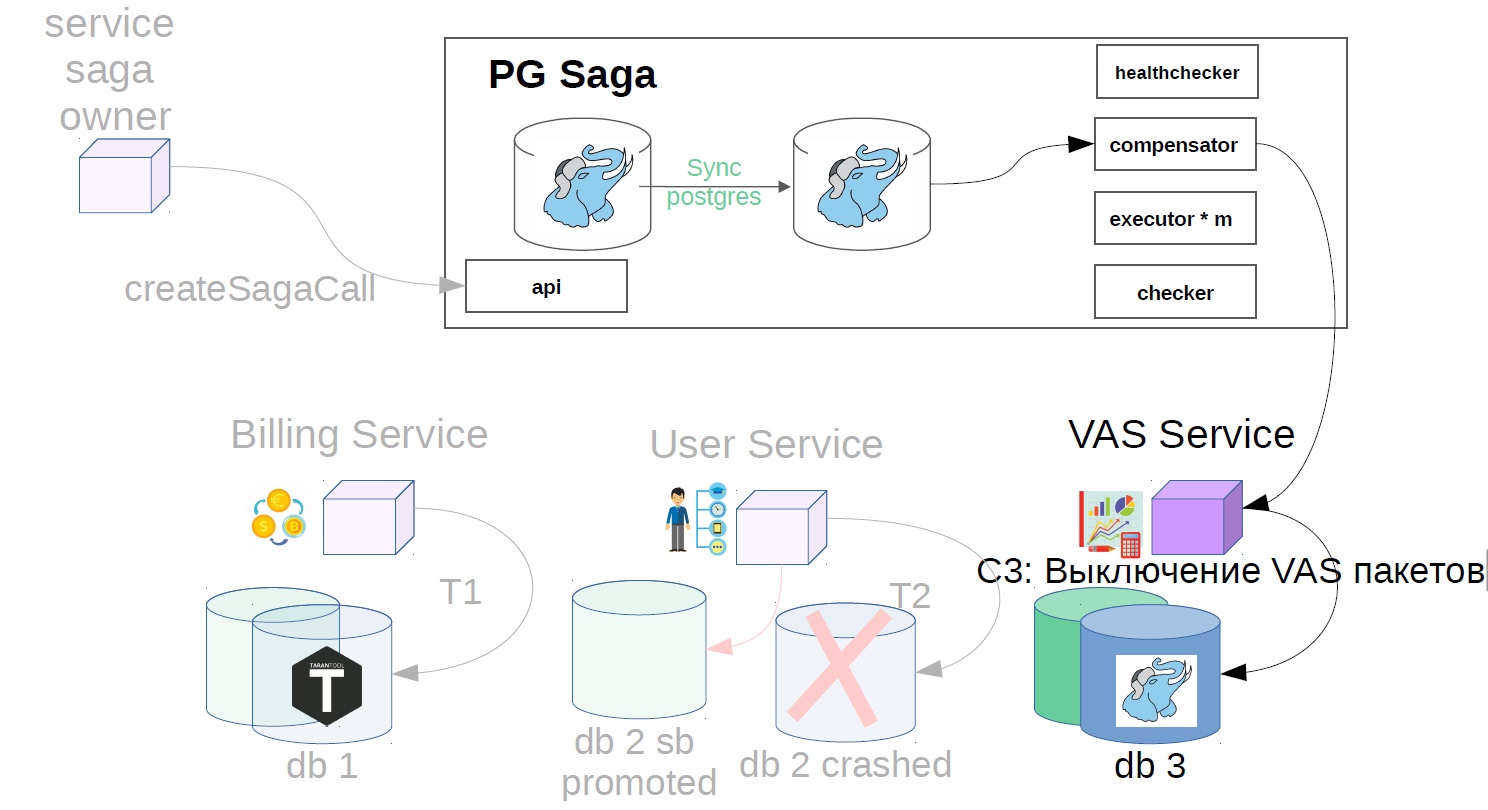
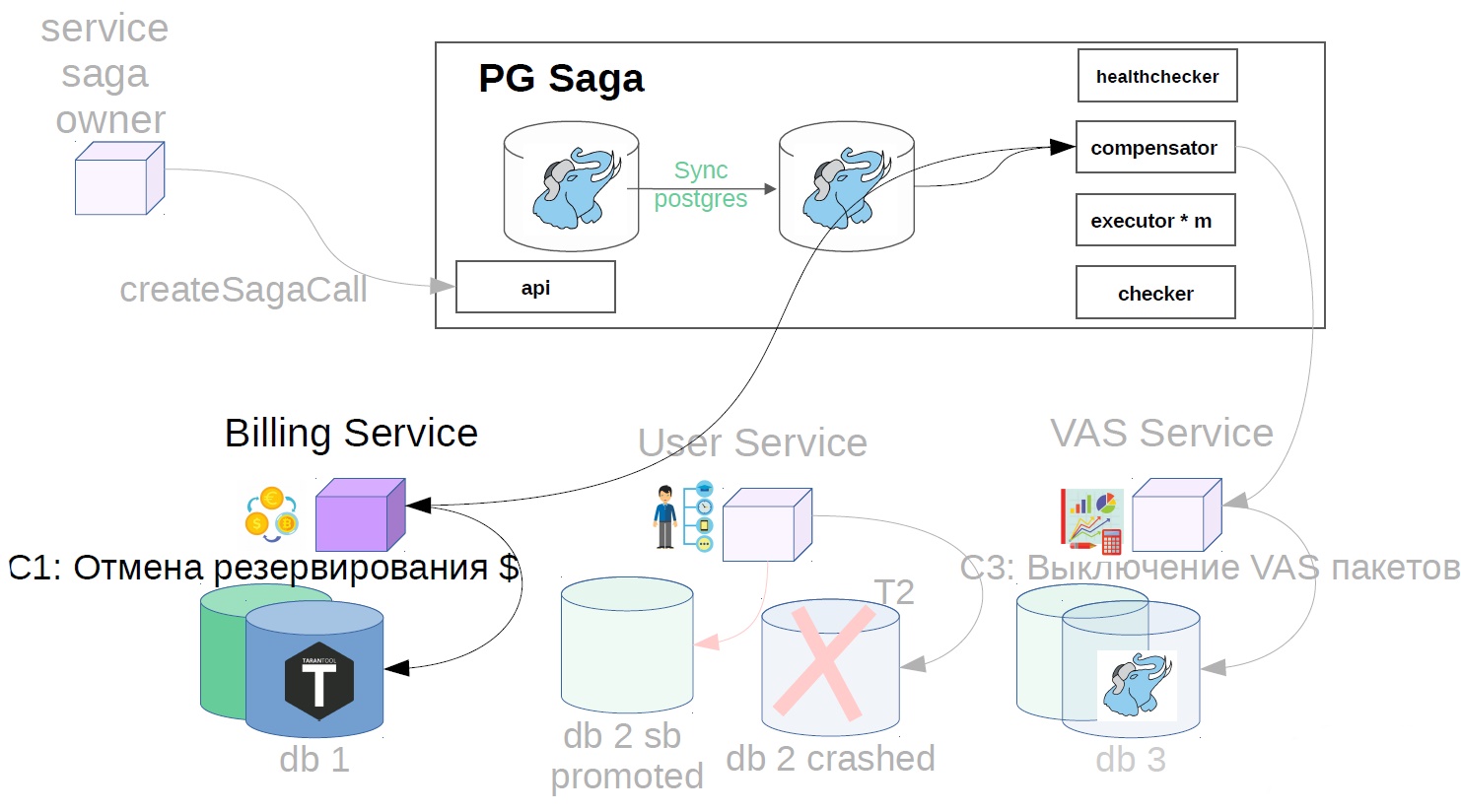
Também pode haver situações em que, após 12 horas, não haja mais nada para cancelar - tudo muda e se move. Nesse caso, em vez do cenário de cancelamento, a solução pode ser sinalizar ao serviço do proprietário da saga que esta operação não foi concluída. Se a operação de cancelamento não for possível, por exemplo, você precisará fazer um cancelamento após cobrar do usuário, e o saldo dele já será zero e o dinheiro não poderá ser baixado. Temos tais cenários são sempre resolvidos na direção do usuário. Você pode ter um princípio diferente, isso é consistente com os representantes do produto.
Como resultado, como você deve ter notado, em diferentes locais para integração com o serviço sag, você precisa implementar muitas lógicas diferentes. Portanto, quando as equipes de clientes desejam criar uma saga, elas terão um conjunto muito grande de tarefas muito óbvias. Primeiro, criamos uma saga para que a duplicação não funcione, por isso estamos trabalhando com alguma operação idempotente de criar uma saga e seu rastreamento. Além disso, nos serviços, é necessário perceber a capacidade de rastrear todas as etapas de cada saga, para não executá-la duas vezes, por um lado, e, por outro lado, para poder responder se foi realmente concluída. E todos esses mecanismos precisam ser atendidos de alguma forma, para que os repositórios de serviços não transbordem. Além disso, existem muitos idiomas nos quais os serviços podem ser escritos e uma enorme seleção de repositórios. Em cada estágio, você precisa entender a teoria e implementar toda essa lógica em diferentes partes. Caso contrário, você pode cometer vários erros.
Existem muitas maneiras corretas, mas não há menos situações em que você pode "se matar". Para que as sagas funcionem corretamente, é necessário encapsular todos os mecanismos acima nas bibliotecas de clientes que os implementarão de forma transparente para seus clientes.
Um exemplo de lógica de geração de saga que pode ser oculta na biblioteca do cliente
Isso pode ser feito de maneira diferente, mas proponho a seguinte abordagem.
- Nós obtemos o ID da solicitação pelo qual devemos criar a saga.
- Vamos ao serviço sag, obtemos seu identificador exclusivo e o salvamos no armazenamento local em conjunto com o ID da solicitação do ponto 1.
- Execute a saga com carga útil no serviço sag. Uma nuance importante: proponho operações locais do serviço que cria a saga, para projetar, como o primeiro passo da saga.
- Existe uma certa corrida em que o serviço da saga pode executar esta etapa (ponto 3), e nosso back-end, que inicia a criação da saga, também a executará. Para fazer isso, fazemos operações idempotentes em todos os lugares: uma pessoa a executa e a segunda chamada simplesmente recebe "OK".
- Chamamos o primeiro passo (ponto 4) e somente depois disso respondemos ao cliente que iniciou esta ação.
Neste exemplo, trabalhamos com a saga como um banco de dados. Você pode enviar uma solicitação e a conexão pode ser interrompida, mas a ação será executada. Essa é a mesma abordagem.
Como verificar tudo
É necessário cobrir todo o serviço de testes de queda. Provavelmente, você fará alterações e os testes escritos no início ajudarão a evitar surpresas inesperadas. Além disso, é necessário verificar as próprias sagas. Por exemplo, como organizamos o teste do serviço sag e testamos a sequência do sag em uma transação. Existem diferentes blocos de teste. Se falamos sobre o serviço sag, ele sabe como realizar transações positivas e de compensação; se a compensação não funcionar, ele informa o proprietário do sag do serviço. Escrevemos testes de maneira geral para trabalhar com uma saga abstrata.
Por outro lado, transações positivas e transações de remuneração em serviços que executam etapas de queda são uma API simples, e os testes dessa parte são de responsabilidade da equipe proprietária desse serviço.
E a equipe do proprietário da saga escreve testes de ponta a ponta, onde verifica se toda a lógica de negócios funciona corretamente quando a saga é executada. O teste de ponta a ponta é executado em um ambiente de desenvolvimento completo, todas as instâncias de serviço são geradas, incluindo o serviço sag, e um cenário de negócios já está sendo testado lá.
Total:
- escreva mais testes de unidade;
- escrever testes de integração;
- escreva testes de ponta a ponta.
O próximo passo é o CDC. A arquitetura de microsserviço afeta as especificidades dos testes. No Avito, adotamos a seguinte abordagem para testar a arquitetura de microsserviços: Contratos orientados ao consumidor. Essa abordagem ajuda, em primeiro lugar, a destacar problemas que podem ser identificados nos testes de ponta a ponta, mas o teste de ponta a ponta é "muito caro".
Qual é a essência do CDC? Existe um serviço que fornece um contrato. Ele tem uma API - este é um provedor. E há outro serviço que chama a API, ou seja, usa o contrato - consumidor.
O serviço ao consumidor grava testes para o contrato do provedor e testes que somente o contrato verificará não são testes funcionais. É importante garantir que, ao alterar a API, as etapas neste contexto não sejam interrompidas. Depois que escrevemos os testes, outro elemento do intermediário de serviço aparece - as informações sobre os testes do CDC são registradas nele. Cada vez que o serviço do provedor é alterado, ele cria um ambiente isolado e executa os testes que o consumidor escreveu. Qual é o resultado: a equipe que gera as sagas escreve testes para todas as etapas da saga e os registra.
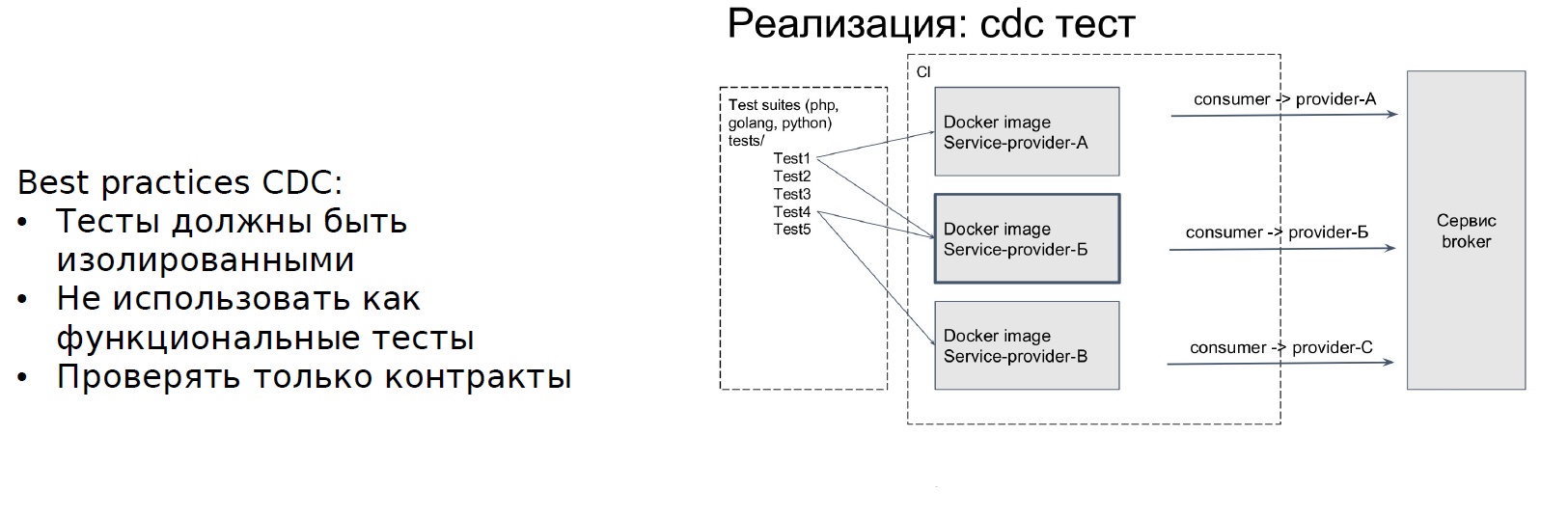
Sobre como a Avito implementou a abordagem do CDC para testar microsserviços Frol Kryuchkov falou no RIT ++. Os resumos podem ser encontrados no site Backend.conf - eu recomendo que você se familiarize.
Tipos de Sagas
Na ordem das chamadas de função
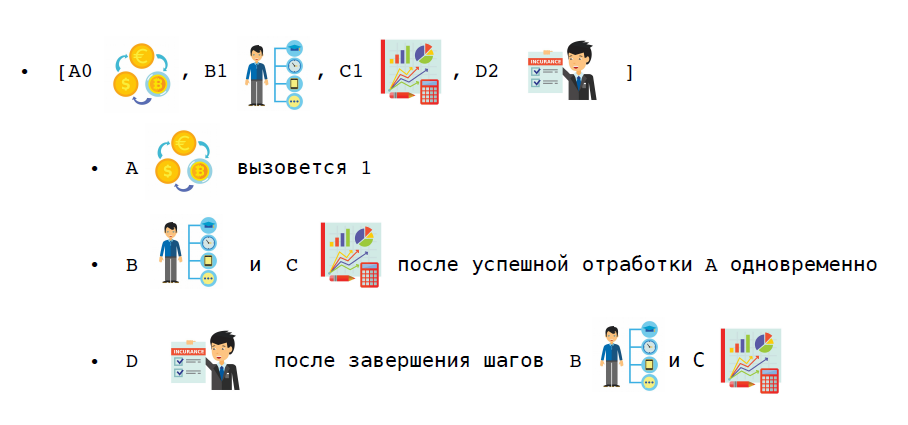
a) desordenado - as funções da saga são chamadas em qualquer ordem e não esperam que o outro termine;
b) ordenado - as funções da saga são chamadas na ordem dada, uma após a outra, a seguinte não é chamada até que a anterior seja concluída;
c) misto - para parte das funções a ordem é definida, mas para a parte não, mas é definida antes ou depois de quais estágios para executá-las.
Considere um cenário específico. No mesmo cenário de compra de uma assinatura premium, o primeiro passo é reservar dinheiro. Agora, podemos fazer alterações no usuário e criar pacotes premium em paralelo, e notificaremos o usuário apenas quando essas duas etapas terminarem.
Obtendo o resultado da chamada de função
a) síncrona - o resultado da função é conhecido imediatamente;
b) assíncrono - a função retorna "OK" imediatamente e o resultado é retornado mais tarde, através de um retorno de chamada para a API do serviço sag do serviço ao cliente.
Quero alertá-lo contra um erro: é melhor não executar etapas síncronas das sagas, especialmente ao implementar uma saga orquestrada. Se você executar etapas de queda síncrona, o serviço de queda esperará que esta etapa seja concluída. É uma carga extra, problemas extras no serviço das sagas, uma vez que é uma delas, e há muitos participantes nas sagas.
Escamação de Sag
A escala depende do tamanho do sistema que você planeja. Considere a opção com uma única instância de armazenamento:
- um manipulador de etapas de saga, processe as etapas com lotes;
- n manipuladores, implementamos um “pente” - tomamos medidas para o restante da divisão: quando cada executor obtém suas próprias etapas.
- n manipuladores e pular bloqueados - serão ainda mais eficientes e flexíveis.
E somente então, se você souber com antecedência que terá o desempenho de um servidor em um DBMS, precisará fazer sharding - n instâncias de banco de dados que funcionem com o conjunto de dados. O sharding pode estar oculto atrás da API de serviço sag.
Mais flexibilidade
Além disso, nesse padrão, pelo menos em teoria, o serviço ao cliente (executando a etapa da saga) pode acessar e se encaixar no serviço sag, e a participação na saga também pode ser opcional. Também pode haver outro cenário: se você já enviou um email, é impossível compensar a ação - é impossível retornar a carta. Mas você pode enviar uma nova carta informando que a anterior estava errada e parece mais ou menos. É melhor usar um cenário em que a saga será reproduzida apenas para a frente, sem qualquer compensação. Se não avançar, é necessário informar o serviço do proprietário da saga sobre o problema.
Quando você precisa de uma fechadura
Uma pequena digressão sobre as sagas em geral: se você pode fazer sua lógica sem a saga, faça-o. Sagas são difíceis. Com uma trava, é a mesma coisa: é melhor sempre evitar bloqueios.
Quando cheguei à equipe de cobrança para falar sobre sagas, eles disseram que precisavam de uma trava. Consegui explicar a eles por que é melhor ficar sem e como fazê-lo. Mas se você ainda precisar de uma trava, isso deve ser previsto com antecedência. Antes do serviço sag, já implementamos bloqueios na estrutura de um DBMS. Um exemplo com defproc e um script para bloquear anúncios de forma assíncrona e bloquear uma conta de forma síncrona, quando primeiro fazemos parte da operação de forma síncrona e configuramos o bloqueio e, em seguida, de forma assíncrona em segundo plano, finalizamos o restante do trabalho com lotes.
Como fazer isso? , , , , , - , . . . : , , .
-, , . , , . , , . . — , , .
ACID —
, , . . — durability. . . , . - , - - ,
— - , - , , - , . , - , - .
— .
:
- , , , , .
- , . , , , , , .
- .
- payload . eventual consistency — , , , . , , , -.
Monitoramento
. , . . checker. . , .
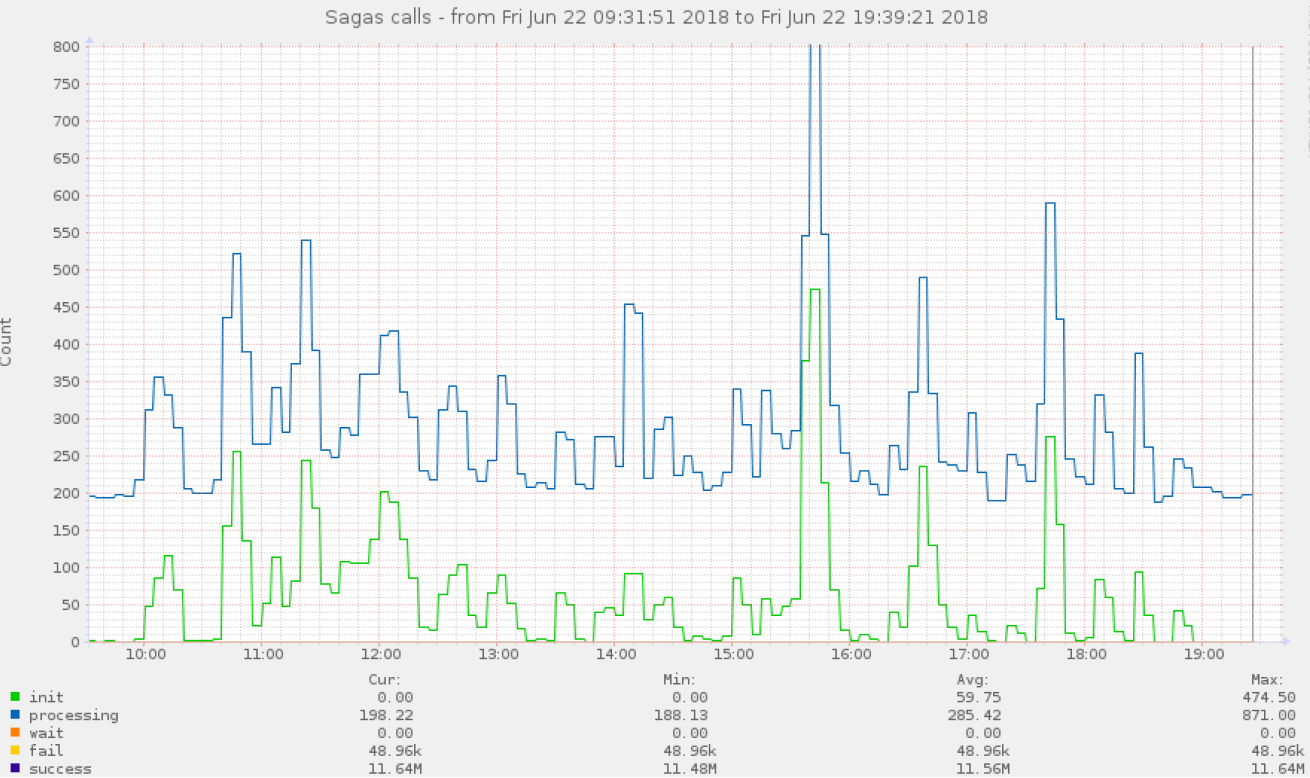
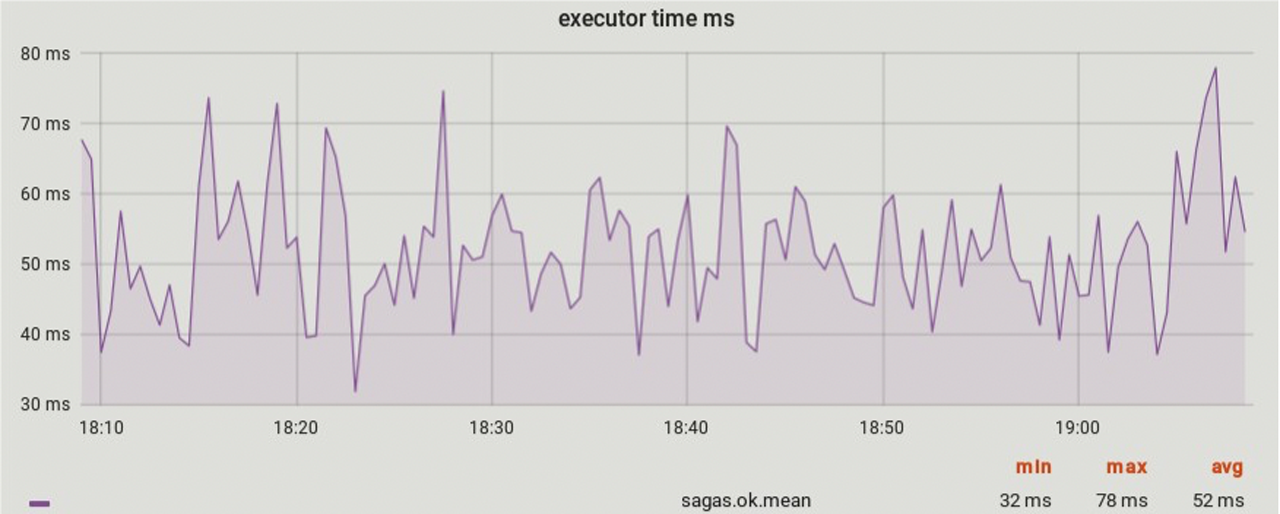
(50%, 75%, 95%, 99%), , - .
, — , . . , - . , — .
. , - ( ) . healthchecker endpoint' info (keep-alive) .
. -. -, - , - . , , , end-to-end. - . , , — .
. .
:
, healthchecker, - , . , . .
, . , , . . choreography — - . , choreography- , . choreography , . , . , , , .
. , , . , + .
API
, - - ( API ), , API. API . — . API , , 100% .
, , , , . — , , . .
, , , . ( ) .
, , , , .
. , , .
saga call ID
. API , .
—
- legacy . , ( «» ). « »? - , , , , - , . , , , . , « », , -. . — . , .
Sou a favor de uma abordagem pragmática do desenvolvimento; portanto, para escrever um serviço de saga, deve-se justificar um investimento em escrever esse serviço. Além disso, provavelmente, muitas pessoas precisam apenas de parte do que descrevi, e essa parte resolverá as necessidades atuais. O principal é entender com antecedência o que exatamente é necessário. E quantos recursos você tem.
Se você tiver dúvidas ou estiver interessado em aprender mais sobre as sagas, escreva nos comentários. Ficarei feliz em responder.