Co-autor do artigo: Mike Cheng
O Google Cloud Platform agora possui imagens de máquinas virtuais em seu portfólio, projetadas especificamente para os envolvidos no Deep Learning. Hoje falaremos sobre o que essas imagens representam, quais vantagens eles oferecem aos desenvolvedores e pesquisadores e, é claro, como criar uma máquina virtual baseada nelas.
Digressão lírica: no momento da redação, o produto ainda estava na versão Beta, respectivamente, sem SLAs aplicáveis.
Que tipo de besteira é essa: imagens de máquinas virtuais para o Deep Learning do Google?
Imagens de máquinas virtuais para o Deep Learning do Google são imagens do Debian 9 que, prontas para uso, têm tudo o que o Deep Learning precisa. Atualmente, existem versões de imagens com TensorFlow, PyTorch e imagens de uso geral. Cada versão existe na edição para instâncias apenas de CPU e GPU. Para entender melhor qual imagem você precisa, desenhei uma pequena folha de dicas:
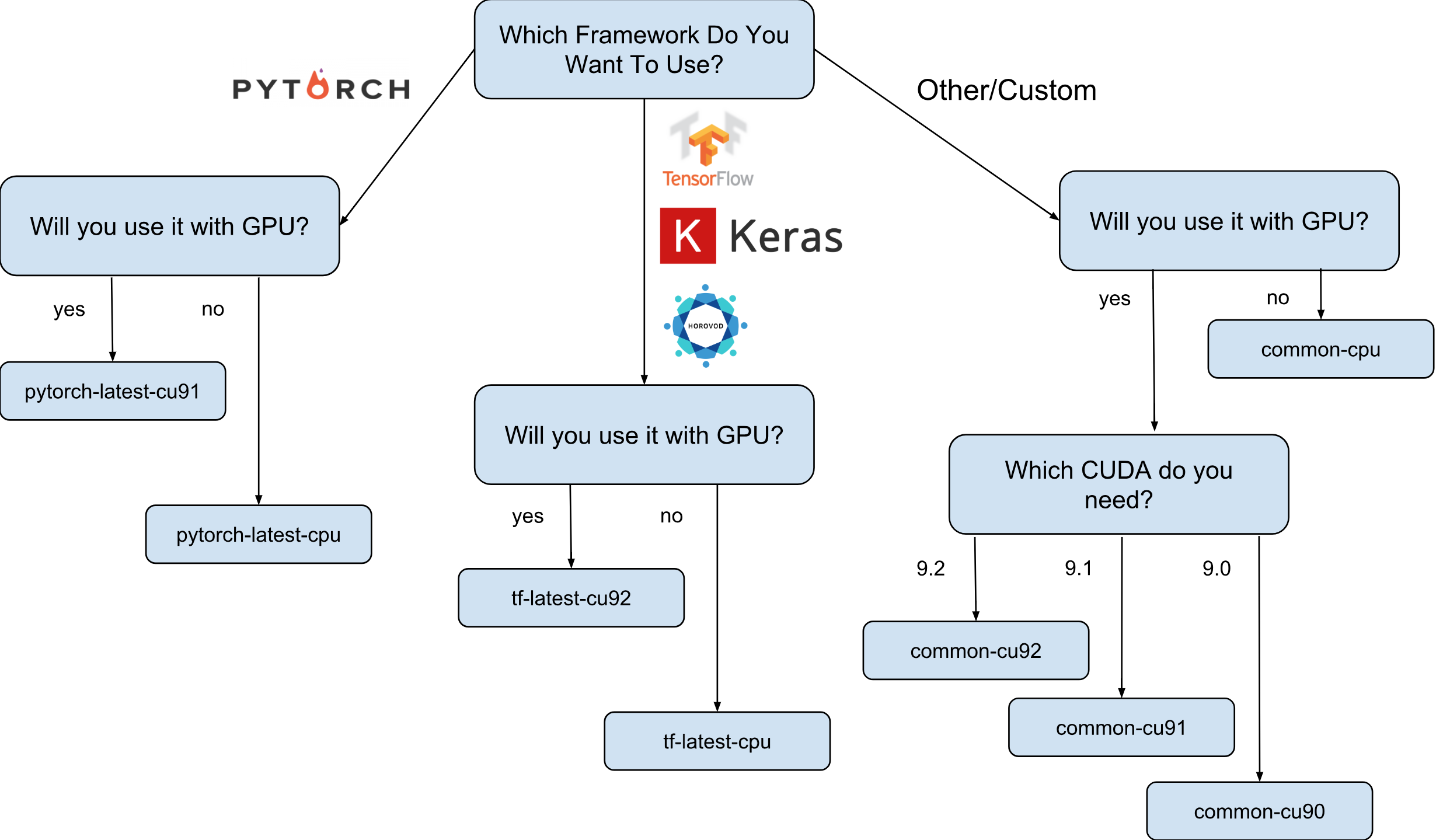
Como mostrado na folha de dicas, existem 8 famílias de imagens diferentes. Como já mencionado, eles são todos baseados no Debian 9.
O que exatamente é pré-instalado nas imagens?
Todas as imagens têm Python 2.7 / 3.5 com os seguintes pacotes pré-instalados:
- entorpecido
- sklearn
- escamoso
- pandas
- nltk
- travesseiro
- Ambientes Jupyter (Lab e Notebook)
- e muito mais
Pilha configurada da Nvidia (apenas em imagens de GPU):
- CUDA 9. *
- CuDNN 7.1
- NCCL 2. *
- mais recente driver da nvidia
A lista é atualizada constantemente, portanto, fique atento na página oficial .
E por que essas imagens são realmente necessárias?
Digamos que você precise treinar um modelo de rede neural usando Keras (com TensorFlow). A velocidade de aprendizado é importante para você e você decide usar a GPU. Para usar a GPU, você precisará instalar e configurar a pilha Nvidia (driver Nvidia + CUDA + CuDNN + NCCL). Esse processo não é apenas bastante complicado por si só (especialmente se você não é um engenheiro de sistemas, mas um pesquisador), é ainda mais complicado pelo fato de precisar levar em conta as dependências binárias da sua versão da biblioteca TensorFlow. Por exemplo, a distribuição oficial do TensorFlow 1.9 é compilada com o CUDA 9.0 e não funcionará se você tiver uma pilha com o CUDA 9.1 ou 9.2 instalado. Configurar esta pilha pode ser um processo "divertido", acho que ninguém pode discutir com isso (especialmente aqueles que fizeram isso).
Agora, suponha que, depois de várias noites sem dormir, tudo esteja configurado e funcionando. Pergunta: essa configuração, que você conseguiu configurar, é a mais ideal para o seu hardware? Por exemplo, é verdade que o CUDA 9.0 instalado e o pacote binário oficial TensorFlow 1.9 mostram a velocidade mais rápida em uma instância com um processador SkyLake e uma GPU Volta V100?
É quase impossível responder sem testar com outras versões do CUDA. Para responder com certeza, você precisa recriar manualmente o TensorFlow em diferentes configurações e executar seus testes. Tudo isso deve ser realizado naquele hardware caro, no qual está planejado treinar o modelo posteriormente. Bem, e a última, todas essas medições podem ser descartadas assim que a nova versão do TensorFlow ou da pilha da Nvidia for lançada. Pode-se afirmar com segurança que a maioria dos pesquisadores simplesmente não fará isso e simplesmente usará o conjunto TensorFlow padrão, não tendo a velocidade ideal.
É aqui que as imagens do Deep Learning do Google aparecem em cena. Por exemplo, as imagens com TensorFlow têm seu próprio conjunto TensorFlow, otimizado para o hardware disponível no Google Cloud Engine. Eles são testados com uma configuração diferente da pilha Nvidia e são baseados na que apresentou o melhor desempenho (spoiler: esse nem sempre é o mais novo). Bem e o mais importante - quase tudo o que você precisa para pesquisa já está pré-instalado!
Como posso criar uma instância com base em uma das imagens?
Existem duas opções para criar uma nova instância com base nessas imagens:
- Usando a interface da web do Google Cloud Marketplace
- Usando gcloud
Como sou um grande fã dos utilitários de terminal e CLI, neste artigo vou falar sobre essa opção. Além disso, se você gosta da interface do usuário, há uma boa documentação descrevendo como criar uma instância usando a interface da web .
Antes de continuar, instale (se você ainda não tiver instalado) a ferramenta gcloud. Opcionalmente, você pode usar o Google Cloud Shell , mas lembre-se de que a função WebPreview no Google Cloud Shell não é suportada no momento e, portanto, não é possível usar o Jupyter Lab ou Notebook lá.
O próximo passo é selecionar uma família de imagens. Permitirei-me mais uma vez trazer a folha de dicas com a escolha de uma família de imagens.
Por exemplo, supomos que sua escolha tenha caído em tf-latest-cu92 e a usaremos posteriormente no texto.
Espere, mas e se eu precisar de uma versão específica do TensorFlow, em vez da "mais recente"?
Suponha que tenhamos um projeto que exija o TensorFlow 1.8, mas ao mesmo tempo 1.9 já tenha sido lançado e as imagens da família tf-latest já tenham 1.9. Para este caso, temos uma família de imagens, que sempre possui uma versão específica da estrutura (no nosso caso, tf-1-8-cpu e tf-1-8-cu92). Essas famílias de imagens serão atualizadas, mas a versão do TensorFlow não será alterada.
Como esta é apenas uma versão beta, agora suportamos apenas o TensorFlow 1.8 / 1.9 e o PyTorch 0.4. Planejamos oferecer suporte a versões futuras, mas no estágio atual não podemos responder claramente à questão de quanto tempo as versões antigas serão suportadas.
E se eu quiser criar um cluster ou usar a mesma imagem?
De fato, pode haver muitos casos em que é necessário reutilizar a mesma imagem repetidamente (em vez de uma família de imagens). A rigor, usar imagens diretamente é quase sempre a opção preferida. Bem, por exemplo, se você executar um cluster com várias instâncias, nesse caso, não é recomendado especificar famílias de imagens diretamente em seus scripts, pois se a família for atualizada no momento em que o script estiver em execução, é provável que diferentes instâncias de cluster sejam criadas a partir de imagens diferentes (e pode ter versões diferentes de bibliotecas!). Nesses casos, é preferível obter primeiro um nome específico para a imagem de sua família e usar somente um nome específico.
Se você estiver interessado neste tópico, consulte o meu artigo "Como usar as famílias de imagens corretamente".
Você pode ver o nome da última imagem na família com um comando simples:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
Suponha que o nome de uma imagem específica seja tf-latest-cu92-1529452792, você já pode usá-la em qualquer lugar:
Hora de criar nossa primeira instância!
Para criar uma instância de uma família de imagens, basta executar um comando simples:
export IMAGE_FAMILY="tf-latest-cu92"
Se você usar o nome da imagem e não a família de imagens, precisará substituir “- image-family = $ IMAGE_FAMILY” por “- image = $ IMAGE-NAME”.
Se você estiver usando uma instância com uma GPU, precisará prestar atenção às seguintes circunstâncias:
Você precisa selecionar a zona correta . Se você criar uma instância com uma GPU específica, precisará garantir que esse tipo de GPU esteja disponível na zona em que você criou a instância. Aqui você pode encontrar a correspondência de zonas para os tipos de GPU. Como você pode ver, us-west1-b é a única zona na qual existem todos os três tipos possíveis de GPUs (K80 / P100 / V100).
Verifique se você possui cotas suficientes para criar uma instância com a GPU . Mesmo se você escolheu a região certa, isso não significa que você tenha uma cota para criar uma instância com uma GPU nessa região. Por padrão, a cota da GPU é definida como zero em todas as regiões; portanto, todas as tentativas de criar uma instância com a GPU falharão. Uma boa explicação de como aumentar a cota pode ser encontrada aqui .
Verifique se há GPUs suficientes na zona para atender sua solicitação . Mesmo se você tiver escolhido a região certa e tiver uma cota para GPUs nessa região, isso não significa que exista uma GPU de seu interesse nessa zona. Infelizmente, não sei de que outra forma você pode verificar a disponibilidade da GPU, exceto como uma tentativa de criar uma instância e ver o que acontece =)
Escolha o número correto de GPUs (dependendo do tipo de GPU) . O fato é que o sinalizador "acelerador" em nossa equipe é responsável pelo tipo e número de GPUs que estarão disponíveis para a instância: ou seja, “- accelerator = 'type = nvidia-tesla-v100, count = 8'” criará uma instância com oito GPUs Nvidia Tesla V100 (Volta) disponíveis. Cada tipo de GPU possui uma lista válida de valores de contagem. Aqui está a lista para cada tipo de GPU:
- nvidia-tesla-k80, pode ter contagens: 1, 2, 4, 8
- nvidia-tesla-p100, pode ter contagens: 1, 2, 4
- nvidia-tesla-v100, pode ter contagens: 1, 8
Dê permissão ao Google Cloud para instalar o driver da Nvidia em seu nome no momento em que você inicia a instância . O driver da Nvidia é obrigatório. Por motivos fora do escopo deste artigo, as imagens não possuem um driver Nvidia pré-instalado. No entanto, você pode conceder ao Google Cloud o direito de instalá-lo em seu nome na primeira vez em que iniciar a instância. Isso é feito adicionando o sinalizador “- metadados = 'install-nvidia-driver = True'”. Se você não especificar esse sinalizador, na primeira vez em que se conectar via SSH, você será solicitado a instalar o driver.
Infelizmente, o processo de instalação do driver demora na primeira inicialização, pois ele precisa baixar e instalar esse driver (e isso também implica a reinicialização da instância). No total, isso não deve levar mais de 5 minutos. Falaremos um pouco mais tarde sobre como você pode reduzir o primeiro tempo de inicialização.
Conecte-se a uma instância via SSH
Isso é mais simples que um nabo e pode ser feito com um comando:
gcloud compute ssh $INSTANCE_NAME
O gcloud criará um par de chaves e fará o upload automaticamente para a instância recém-criada, além de criar seu usuário. Se você deseja tornar esse processo ainda mais simples, pode usar uma função que também simplifica isso:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
A propósito, você pode encontrar todas as minhas funções do gcloud bash aqui . Bem, antes de chegarmos à questão de quão rápido essas imagens são, ou o que pode ser feito com elas, deixe-me esclarecer o problema com a velocidade de lançamento de instâncias.
Como posso reduzir o tempo da primeira partida?
Tecnicamente, o tempo do primeiro lançamento não é nada. Mas você pode:
- crie a instância n1-standard-1 mais barata com um K80;
- aguarde até que o primeiro download seja concluído;
- verifique se o driver da Nvidia está instalado (isso pode ser feito executando “nvidia-smi”);
- Pare a instância
- Crie sua própria imagem a partir de uma instância parada
- Lucro - todas as instâncias criadas a partir de sua imagem derivada terão um lendário tempo de inicialização de 15 segundos.
Portanto, nesta lista, já sabemos como criar uma nova instância e conectar-se a ela, também sabemos como verificar a operacionalidade dos drivers. Resta apenas falar sobre como parar a instância e criar uma imagem a partir dela.
Para parar a instância, execute o seguinte comando:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
E aqui está o comando para criar a imagem:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
Parabéns, agora você tem sua própria imagem com os drivers da Nvidia instalados.
E o Jupyter Lab?
Depois que sua instância estiver em execução, o próximo passo lógico seria iniciar o Jupyter Lab para começar a trabalhar diretamente :) Com novas imagens, é muito simples. O Jupyter Lab já está em execução desde o lançamento da instância. Tudo o que você precisa fazer é conectar-se à instância e encaminhar a porta na qual o Jupyter Lab está escutando. E esta é a porta 8080. Isso é feito com o seguinte comando:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
Está tudo pronto, agora você pode simplesmente abrir seu navegador favorito e acessar http: // localhost: 8080
Quanto mais rápido o TensorFlow das imagens?
Uma questão muito importante, já que a velocidade de treinamento do modelo é de dinheiro real. No entanto, a resposta completa a esta pergunta será a mais longa já escrita neste artigo. Então você tem que esperar pelo próximo artigo :)
Enquanto isso, vou cuidar de alguns números obtidos no meu pequeno experimento pessoal. Portanto, a velocidade de treinamento no ImageNet era de 6100 imagens por segundo (rede ResNet-50). Meu orçamento pessoal não me permitiu concluir o treinamento do modelo completamente, no entanto, a essa velocidade, presumo que seja possível obter uma precisão de 75% em 5 horas com um pouco.
Onde obter ajuda?
Se precisar de informações sobre novas imagens, você pode:
- faça uma pergunta no stackoverflow, com a tag google-dl-platform;
- escreva para o público Google Group ;
- pode escrever para mim no correio ou no twitter .
Seu feedback é muito importante. Se você tem algo a dizer sobre as imagens, não hesite em entrar em contato comigo de qualquer maneira conveniente para você ou deixar um comentário neste artigo.