Nota perev. : Este artigo foi publicado no blog oficial do Kubernetes e foi escrito por dois funcionários da Intel que estão diretamente envolvidos no desenvolvimento do CPU Manager, um novo recurso do Kubernetes sobre o qual escrevemos na revisão da versão 1.8 . No momento (ou seja, para o K8s 1.11), esse recurso tem status beta e leia mais sobre seu objetivo posteriormente na nota.A publicação fala sobre o
CPU Manager , um recurso beta no Kubernetes. O Gerenciador de CPU permite distribuir melhor as cargas de trabalho no Kubelet, ou seja, no agente host Kubernetes, atribuindo CPUs dedicadas a contêineres de uma lareira específica.
Parece ótimo! Mas o Gerenciador de CPU vai me ajudar?
Depende da carga de trabalho. O único nó de computação no cluster Kubernetes pode executar muitas lareiras, e algumas delas podem executar cargas ativas no consumo da CPU. Nesse cenário, as lareiras podem competir pelos recursos do processo disponíveis neste nó. Quando essa competição aumenta, a carga de trabalho pode mudar para outras CPUs, dependendo de ter sido
otimizada e de quais CPUs estavam disponíveis no momento do planejamento. Além disso, pode haver casos em que a carga de trabalho é sensível às alternâncias de contexto. Em todos esses cenários, o desempenho da carga de trabalho pode ser afetado.
Se sua carga de trabalho for sensível a esses cenários, você poderá ativar o Gerenciador de CPU para fornecer um melhor isolamento de desempenho, alocando CPUs específicas à carga.
O CPU Manager pode ajudar com cargas com os seguintes recursos:
- Sensível aos efeitos de otimização da CPU
- sensível a alternância de contexto;
- falta de cache do processador;
- Beneficiando da divisão dos recursos do processador (por exemplo, cache de dados e instruções);
- memória sensível à memória entre soquetes do processador (uma explicação detalhada do que os autores têm em mente é fornecida no Unix Stack Exchange - aprox. transl. ) ;
- hyperthreads sensíveis ou exigindo o mesmo núcleo físico da CPU.
Ok! Como usá-lo?
Usar o Gerenciador de CPU é fácil. Primeiro,
habilite-o usando a Política Estática no Kubelet em execução nos nós de computação do cluster. Em seguida, configure a classe
QoS ( Garantia de qualidade de serviço) para a lareira. Solicite um número inteiro de núcleos de CPU (por exemplo,
1000m ou
4000m ) para contêineres que precisam de núcleos dedicados. Crie no método anterior (por exemplo,
kubectl create -f pod.yaml ) ... e pronto - o CPU Manager atribuirá núcleos de processador dedicados a cada contêiner de lareira, de acordo com as necessidades da CPU.
apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M"
Especificação de uma lareira solicitando 2 CPUs dedicadas.Como o CPU Manager funciona?
Consideramos três tipos de controle de recursos da CPU disponíveis na maioria das distribuições Linux, que serão relevantes para o Kubernetes e os objetivos desta publicação. Os dois primeiros são compartilhamentos CFS (qual é a minha parcela "honesta" ponderada do tempo de CPU no sistema) e cota CFS (qual é o tempo máximo de CPU alocado para mim no período). O CPU Manager também usa um terceiro, chamado afinidade da CPU (em que CPUs lógicas posso executar cálculos).
Por padrão, todos os pods e contêineres em execução no nó do cluster Kubernetes podem ser executados em qualquer kernel do sistema disponível. O número total de compartilhamentos e cotas atribuídos é limitado pelos recursos da CPU reservados para
Kubernetes e daemons do sistema . No entanto, os limites do tempo de CPU usado podem ser determinados usando
limites na CPU na especificação da lareira . O Kubernetes usa a
cota do CFS para impor os limites da CPU nos contêineres da lareira.
Quando você ativa o CPU Manager com uma política
Estática , ele gerencia um pool dedicado de CPUs. Inicialmente, esse pool contém toda a CPU do nó de computação. Quando o Kubelet cria um contêiner na lareira com um número garantido de núcleos de processador dedicados, as CPUs atribuídas a esse contêiner são alocadas a ele por toda a vida útil e são removidas do pool compartilhado. As cargas dos contêineres restantes são transferidas desses núcleos dedicados para outros.
Todos os contêineres sem CPUs dedicadas (
Burstable ,
BestEffort e
Garantido com CPUs não inteiras ) são executados nos kernels deixados no pool compartilhado. Quando um contêiner com CPUs dedicadas para de funcionar, seus kernels retornam ao pool compartilhado.
Mais detalhes, por favor ...

O diagrama acima mostra a anatomia do CPU Manager. Ele usa o método
UpdateContainerResources do Container Runtime Interface (CRI) para alterar as CPUs nas quais os contêineres são executados.
O Manager periodicamente combina o
cgroupfs com o estado atual dos recursos da CPU para cada contêiner em execução.
O Gerenciador de CPU usa
Políticas para decidir sobre a alocação de núcleos de CPU. Duas políticas são implementadas:
Nenhuma e
Estática . Por padrão, começando com o Kubernetes versão 1.10, ele é ativado com a política
Nenhum .
A política
estática atribui os contêineres de pod alocados à CPU à classe de QoS garantida, que solicita um número inteiro de núcleos. A política
estática tenta designar a CPU da melhor maneira topológica e na seguinte ordem:
- Atribua todas as CPUs a um soquete do processador, se disponível, e o contêiner exige uma CPU na quantidade de pelo menos um soquete de CPU inteiro.
- Atribua todas as CPUs lógicas (hyperthreads) de um núcleo físico da CPU, se disponível, e o contêiner exige uma CPU de pelo menos todo o núcleo.
- Atribua quaisquer CPUs lógicas disponíveis, com preferência por CPUs a partir de um único soquete.
Como o CPU Manager melhora o isolamento da computação?
Com a política
estática ativada no Gerenciador de CPU, as cargas de trabalho podem ter um desempenho melhor por um dos seguintes motivos:
- CPUs dedicadas podem ser atribuídas a um contêiner com uma carga de trabalho, mas não a outros contêineres. Esses (outros) contêineres não usam os mesmos recursos da CPU. Como resultado, esperamos um melhor desempenho devido ao isolamento em casos de aparecimento de um "agressor" (processos exigentes de CPU - aprox. Transl. ) Ou carga de trabalho adjacente.
- Há menos concorrência pelos recursos utilizados pela carga de trabalho, pois podemos dividir a CPU pela própria carga de trabalho. Esses recursos podem incluir não apenas a CPU, mas também hierarquias de cache e largura de banda da memória. Isso melhora o desempenho geral da carga de trabalho.
- O Gerenciador de CPU atribui a CPU em uma ordem topológica com base nas melhores opções disponíveis. Se o soquete inteiro estiver livre, ele atribuirá todas as suas CPUs à carga de trabalho. Isso melhora o desempenho da carga de trabalho devido à falta de tráfego entre soquetes.
- Os contêineres em pods com QoS garantido estão sujeitos ao limite de cota do CFS. As cargas de trabalho propensas a explosões repentinas podem ser planejadas e excederem sua cota antes do final do período alocado, como resultado das quais elas são reguladas . As CPUs envolvidas no momento podem ter um trabalho significativo e não muito útil. No entanto, esses contêineres não estarão sujeitos à otimização do CFS quando a CPU da cota for suplementada por uma política de alocação de CPU dedicada.
Ok! Você tem algum resultado?
Para ver as melhorias de desempenho e o isolamento fornecidos pela inclusão do CPU Manager no Kubelet, realizamos experimentos em um nó de computação com dois soquetes (CPU Intel Xeon E5-2680 v3) e com o hyperthreading ativado. O nó consiste em 48 CPUs lógicas (24 núcleos físicos, cada um com hyperthreading). Os benefícios de desempenho e isolamento do CPU Manager capturados pelas cargas de trabalho de referência e da vida real em três cenários diferentes são mostrados abaixo.
Como interpretar gráficos?
Para cada cenário, são mostrados gráficos (
diagramas de amplitude , gráficos de caixas) ilustrando o tempo de execução normalizado e sua variabilidade ao iniciar um benchmark ou uma carga real com o CPU Manager ativado e desativado. O tempo de execução é normalizado para os lançamentos de melhor desempenho (1,00 no eixo Y representa o melhor tempo de inicialização: quanto menor o valor do gráfico, melhor). A altura do gráfico no gráfico mostra a variabilidade no desempenho. Por exemplo, se o site for uma linha, não haverá variação no desempenho para esses lançamentos. Nessas áreas, a linha do meio é a mediana, a parte superior é o percentil 75 e a parte inferior é o percentil 25. A altura do gráfico (ou seja, a diferença entre os percentis 75 e 25) é definida como o intervalo interquartil (IQR). "Bigode" mostra dados fora desse intervalo e os pontos mostram valores discrepantes. As emissões são definidas como quaisquer dados que diferem do IQR em 1,5 vezes - menos ou mais que o quartil correspondente. Cada experimento foi realizado 10 vezes.
Proteção Agressiva
Lançamos seis benchmark'ov de um
conjunto de PARSEC (cargas de trabalho - "vítimas")
[mais sobre as cargas de trabalho das vítimas podem ser lidas, por exemplo, aqui - aprox. perev. ] próximo ao contêiner que carrega a CPU (carga de trabalho "agressor") com o CPU Manager ativado e desativado.
O contêiner do agressor é lançado
como abaixo da classe
Burstable QoS, solicitando 23 sinalizadores de CPU -
--cpus 48 . Os benchmarks são executados
como pods com a classe QoS
garantida , que requer um conjunto de CPUs de um soquete completo (ou seja, 24 CPUs neste sistema). Os gráficos abaixo mostram o horário de início do pod normalizado com uma referência ao lado do agressor do pod, com a política
Estática do CPU Manager e sem ela. Em todos os casos de teste, você pode ver um desempenho aprimorado e uma variabilidade reduzida de desempenho com a política ativada.

Isolamento para cargas adjacentes
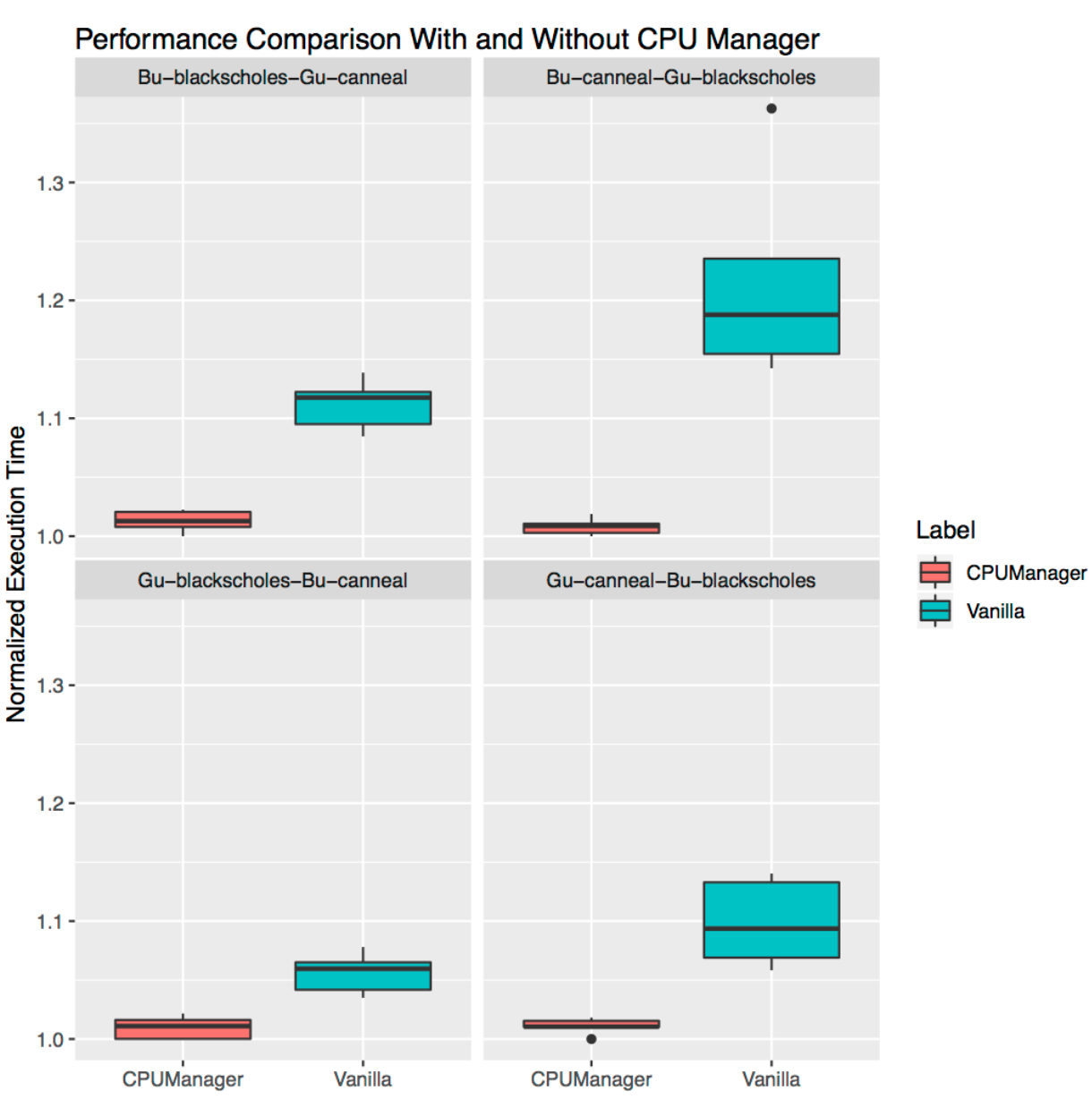
Isso demonstra o quão útil o CPU Manager pode ser para muitas cargas de trabalho localizadas. Os diagramas de abrangência abaixo mostram o desempenho de dois parâmetros de referência do conjunto PARSEC (
Blackscholes e
Canneal ) lançado para as classes QoS
Guaranteed (Gu) e
Burstable (Bu) que são adjacentes, com a política
estática ativada e desativada.
Seguindo no sentido horário do gráfico superior esquerdo, vemos o desempenho dos
Blackscholes para Bu QoS (superior esquerdo),
Canneal para Bu QoS (superior direito),
Canneal para Gu QoS (inferior direito) e
Blackscholes para Gu QoS (inferior esquerdo). Em cada gráfico, eles estão localizados (no sentido horário novamente) junto com
Canneal para Gu QoS (canto superior esquerdo),
Blackscholes para Gu QoS (canto superior direito),
Blackscholes para Bu QoS (canto inferior direito) e
Canneal para Bu QoS (canto inferior esquerdo) em conformidade. Por exemplo, o
gráfico Bu-blackscholes-Gu-canneal (canto superior esquerdo) mostra o desempenho de
Blackscholes executando com Bu QoS e localizado ao lado de
Canneal com a classe Gu QoS. Em cada caso, abaixo da classe Gu QoS requer um núcleo de soquete completo (ou seja, 24 CPUs) e abaixo da classe Bu QoS - 23 CPUs.
Há melhor desempenho e menos variação no desempenho para ambas as cargas de trabalho adjacentes em todos os testes. Por exemplo, observe
Bu-blackscholes-Gu-canneal (canto superior esquerdo) e
Gu-canneal-Bu-blackscholes (
canto inferior direito). Eles mostram o desempenho dos
Blackscholes e
Canneal em
execução com o CPU Manager
ativado e desativado. Nesse caso, o
Canneal recebe mais núcleos dedicados do CPU Manager, pois pertence à classe Gu QoS e solicita um número inteiro de núcleos da CPU. No entanto, o
Blackscholes também recebe um conjunto dedicado de CPUs, pois essa é a única carga de trabalho no pool compartilhado. Como resultado, os
Blackscholes e o
Canneal aproveitam o isolamento de carga ao usar o CPU Manager.
Isolamento para cargas independentes
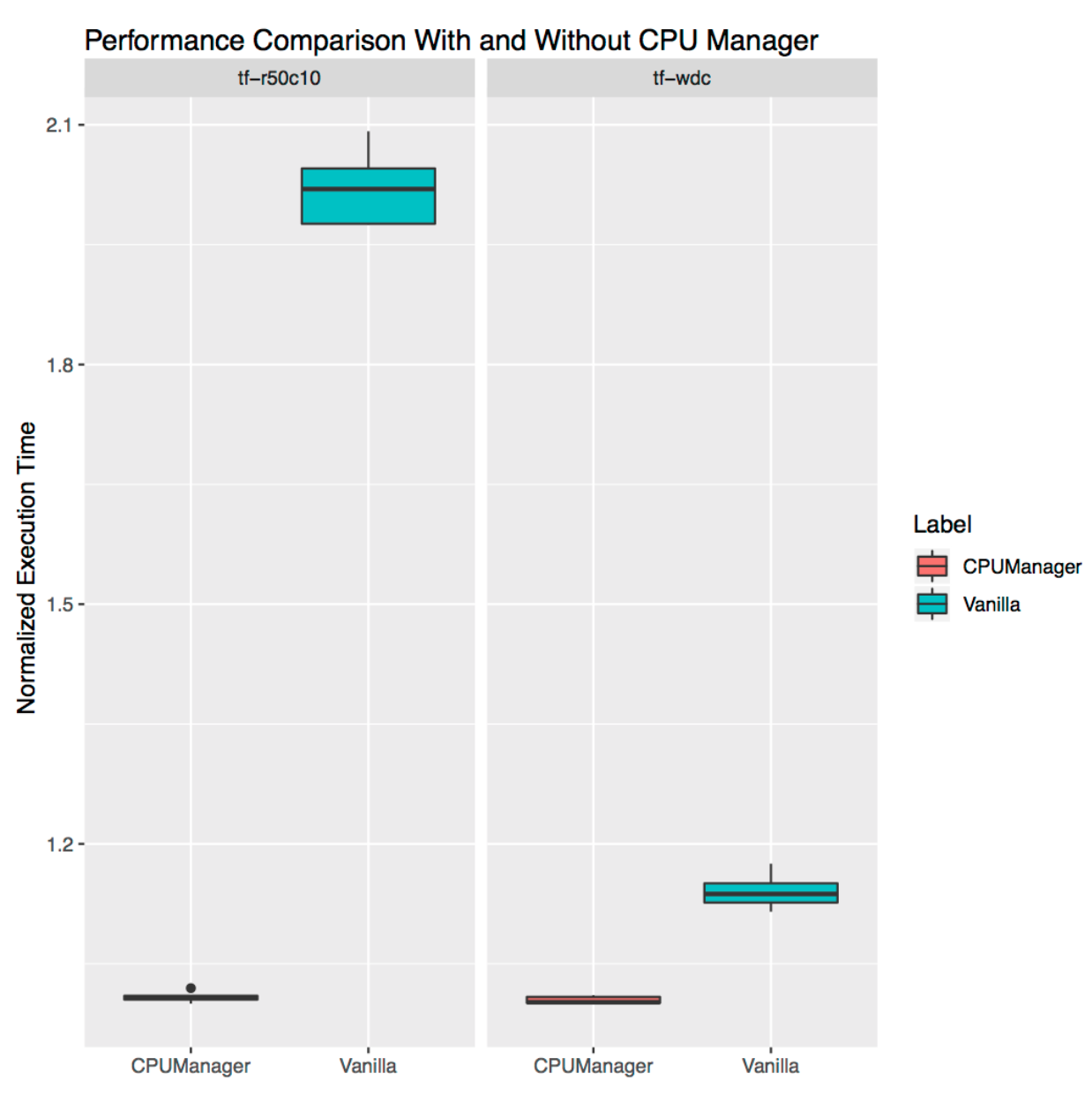
Ele demonstra o quão útil o CPU Manager pode ser para cargas de trabalho independentes da vida real. Pegamos duas cargas dos
modelos oficiais do TensorFlow :
amplo e profundo e
ResNet . Os conjuntos de dados típicos são usados para eles (censo e CIFAR10, respectivamente). Em ambos os casos, as
lareiras (
ampla e profunda ,
ResNet ) requerem 24 CPUs, o que corresponde a um soquete completo. Conforme mostrado nos gráficos, em ambos os casos, o Gerenciador de CPU fornece melhor isolamento.
Limitações
Os usuários podem querer que as CPUs alocadas em um soquete próximo ao barramento se conectem a um dispositivo externo, como um acelerador ou uma placa de rede de alto desempenho, para evitar tráfego entre soquetes. Esse tipo de configuração ainda não é suportado no Gerenciador de CPU. Como o CPU Manager fornece a melhor alocação possível de CPUs pertencentes a um soquete ou núcleo físico, é sensível a casos extremos e pode levar à fragmentação. O CPU Manager não leva em consideração o parâmetro de inicialização do kernel do
isolcpus Linux, embora seja usado como uma prática popular em alguns casos
(para obter mais detalhes sobre esse parâmetro, consulte, por exemplo, aqui - aprox. Transl. ) .
PS do tradutor
Leia também em nosso blog: