
Nos últimos anos, o tópico inteligência artificial e aprendizado de máquina deixou de ser algo para pessoas do reino da ficção e entrou firmemente na vida cotidiana. As redes sociais se oferecem para participar de eventos que são do nosso interesse, carros nas estradas aprendem a se locomover sem motorista e um assistente de voz no telefone informa quando é melhor sair de casa para evitar congestionamentos e se deve levar um guarda-chuva.
Neste artigo, consideraremos as ferramentas de aprendizado de máquina oferecidas pelos desenvolvedores da Apple, analisaremos o que a empresa mostrou de novo nesta área no WWDC18 e tentaremos entender como colocar tudo isso em prática.
Aprendizado de máquina
Portanto, o aprendizado de máquina é um processo durante o qual um sistema, usando certos algoritmos de análise de dados e processando um grande número de exemplos, identifica padrões e os utiliza para prever as características de novos dados.
O aprendizado de máquina nasceu da teoria de que os computadores podem aprender por conta própria, ainda não programados para executar determinadas ações. Em outras palavras, diferentemente dos programas convencionais com instruções predefinidas para solucionar problemas específicos, o aprendizado de máquina permite que o sistema aprenda como reconhecer padrões de forma independente e fazer previsões.
BNNS e CNN
A Apple usa a tecnologia de aprendizado de máquina em seus dispositivos há algum tempo: o Mail identifica emails de spam, o Siri ajuda a encontrar respostas rapidamente para suas perguntas, o Photos reconhece rostos em imagens.
Na WWDC16, a empresa introduziu duas APIs baseadas em redes neurais - sub-rotinas de redes neurais básicas (BNNS) e redes neurais convolucionais (CNN). O BNNS faz parte do sistema Accelerate, que é a base para realizar cálculos rápidos na CPU, e o CNN é a biblioteca Metal Performance Shaders que usa a GPU. Você pode aprender mais sobre essas tecnologias, por exemplo, aqui .
Core ML e Turi Create
No ano passado, a Apple anunciou uma estrutura que facilita muito o trabalho com tecnologias de aprendizado de máquina - o Core ML. Ele se baseia na idéia de pegar um modelo de dados pré-treinado e integrá-lo ao seu aplicativo em apenas algumas linhas de código.
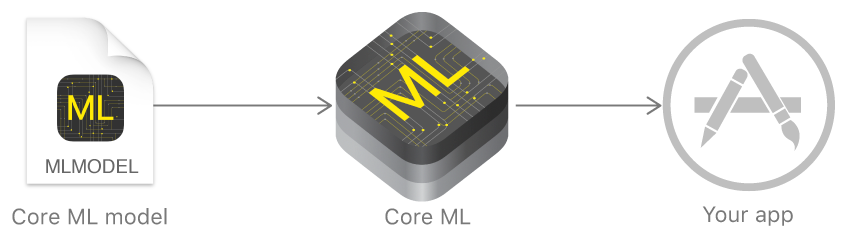
Usando o Core ML, você pode implementar várias funções:
- definição de objetos em uma foto e vídeo;
- introdução assistida de texto;
- rastreamento e reconhecimento de rosto;
- análise de movimento;
- definição de código de barras;
- compreensão e reconhecimento de texto;
- reconhecimento de imagem em tempo real;
- estilização de imagens;
- e muito mais
O Core ML, por sua vez, usa Metal, Accelerate e BNNS de baixo nível e, portanto, os resultados dos cálculos são muito rápidos.
O kernel suporta redes neurais, modelos lineares generalizados, engenharia de recursos, algoritmos de tomada de decisão baseados em árvores (conjuntos de árvores), método de máquinas de vetores de suporte e modelos de pipeline.
Mas a Apple não mostrou inicialmente suas próprias tecnologias para criar e treinar modelos, mas apenas converteu outras estruturas populares: Caffe, Keras, scikit-learn, XGBoost, LIBSVM.
O uso de ferramentas de terceiros geralmente não era a tarefa mais fácil, os modelos treinados eram bastante grandes e o treinamento em si demorava muito tempo.
No final do ano, a empresa introduziu o Turi Create - uma estrutura de aprendizado de modelos cuja principal idéia era a facilidade de uso e suporte para um grande número de cenários - classificação de imagens, definição de objetos, sistemas de recomendação e muitos outros. Mas o Turi Create, apesar de sua relativa facilidade de uso, apenas suportava Python.
Criar ML
E este ano, a Apple, além do Core ML 2, finalmente mostrou sua própria ferramenta para modelos de treinamento - a estrutura Create ML usando as tecnologias nativas da Apple - Xcode e Swift.
Ele funciona rápido e criar modelos de modelo com o Create ML é realmente fácil.
Na WWDC, o desempenho impressionante do Create ML e Core ML 2 foi anunciado usando o aplicativo Memrise como exemplo. Se anteriormente levava 24 horas para treinar um modelo usando 20 mil imagens, o Create ML reduz esse tempo para 48 minutos no MacBook Pro e até 18 minutos no iMac Pro. O tamanho do modelo treinado diminuiu de 90 MB para 3 MB.
Criar ML permite usar imagens, textos e objetos estruturados como tabelas, por exemplo, como dados de origem.
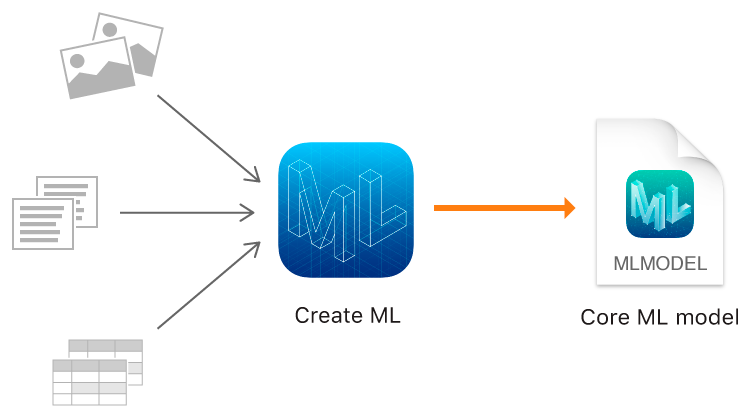
Classificação da imagem
Primeiro, vamos ver como a classificação de imagens funciona. Para treinar o modelo, precisamos de um conjunto de dados inicial: tiramos três grupos de fotos de animais: cães, gatos e pássaros e os distribuímos em pastas com os nomes correspondentes, que se tornarão os nomes das categorias do modelo. Cada grupo contém 100 imagens com uma resolução de até 1920 × 1080 pixels e um tamanho de até 1Mb. As fotografias devem ser o mais diferentes possível, para que o modelo treinado não se baseie em sinais como a cor da imagem ou o espaço circundante.
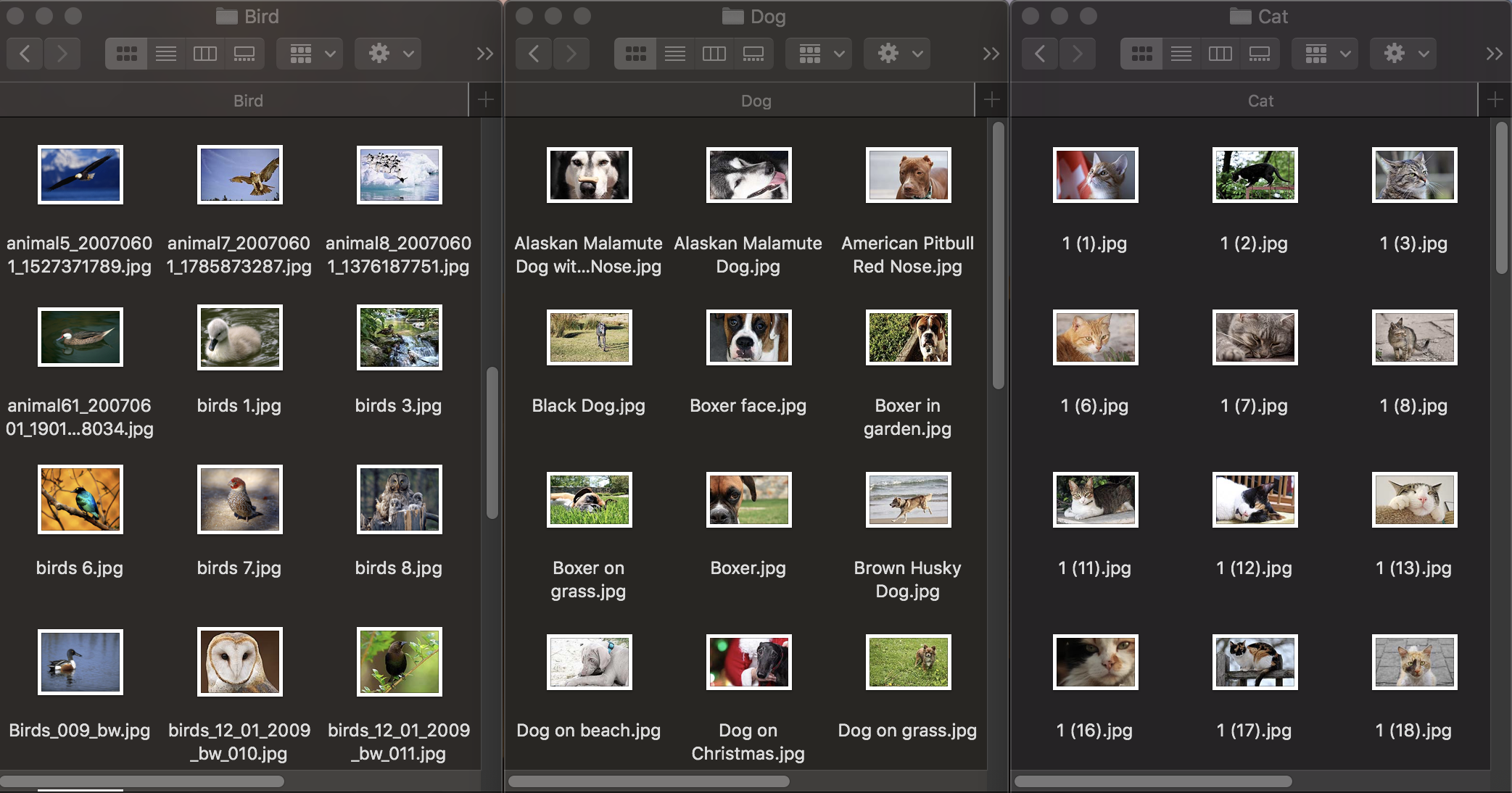
Além disso, para verificar como um modelo treinado lida com o reconhecimento de objetos, você precisa de um conjunto de dados de teste - imagens que não estão no conjunto de dados original.
A Apple fornece duas maneiras de interagir com o Create ML: usando a interface do usuário no MacOS Playground Xcode e programaticamente usando CreateMLUI.framework e CreateML.framework. Usando o primeiro método, basta escrever algumas linhas de código, transferir as imagens selecionadas para a área especificada e aguardar enquanto o modelo aprende.

No Macbook Pro 2017 na configuração máxima, o treinamento levou 29 segundos para 10 iterações e o tamanho do modelo treinado foi de 33 KB. Parece impressionante.
Vamos tentar descobrir como conseguimos alcançar esses indicadores e o que está "sob o capô".
A tarefa de classificar imagens é um dos usos mais populares das redes neurais convolucionais. Primeiro, vale a pena explicar o que são.
Uma pessoa, vendo a imagem de um animal, pode atribuí-la rapidamente a uma determinada classe com base em qualquer característica distintiva. Uma rede neural age de maneira semelhante, procurando características básicas. Tomando a matriz inicial de pixels como entrada, ela passa seqüencialmente as informações através de grupos de camadas convolucionais e cria abstrações cada vez mais complexas. Em cada camada subsequente, ela aprende a destacar certos recursos - primeiro são linhas, depois conjuntos de linhas, formas geométricas, partes do corpo e assim por diante. Na última camada, obtemos a conclusão de uma classe ou grupo de classes prováveis.
No caso do Create ML, o treinamento em rede neural não é realizado do zero. A estrutura usa uma rede neural previamente treinada em um grande conjunto de dados, que já inclui um grande número de camadas e tem alta precisão.
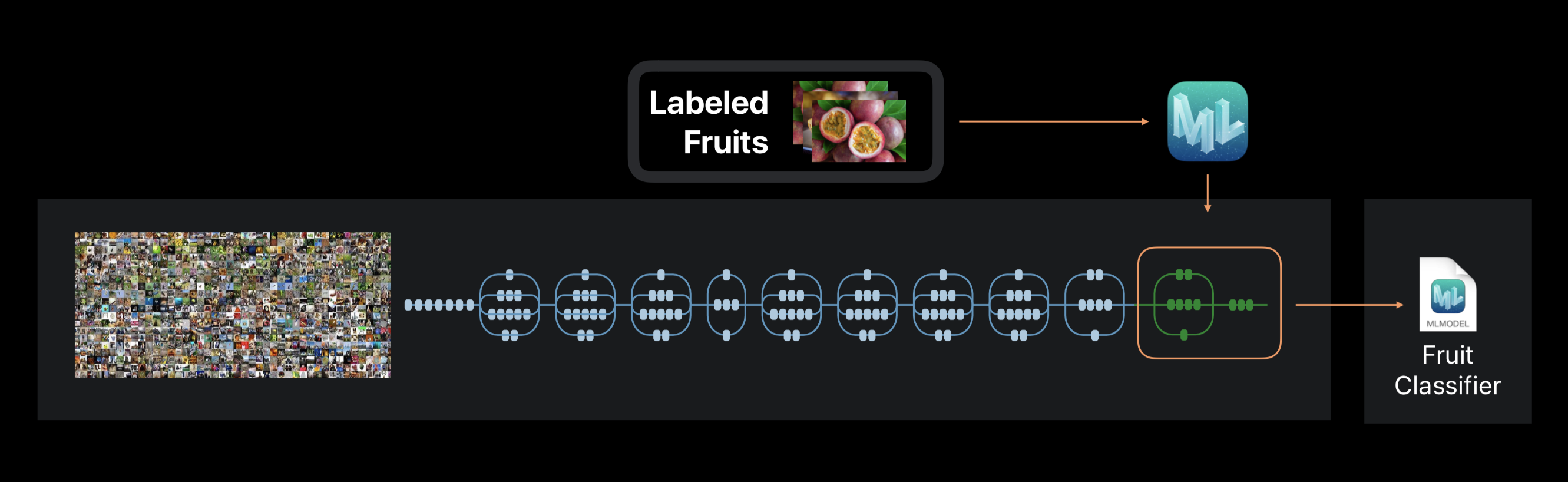
Essa tecnologia é chamada de transferência de aprendizado. Com ele, você pode alterar a arquitetura de uma rede pré-treinada para que seja adequada para resolver um novo problema. A rede alterada é treinada em um novo conjunto de dados.
Crie ML durante os extratos de treinamento da foto, com cerca de 1000 recursos distintos. Pode ser a forma dos objetos, a cor das texturas, a localização dos olhos, tamanhos e muitos outros.
Deve-se notar que o conjunto de dados inicial no qual a rede neural usada é treinada, como a nossa, pode conter fotografias de gatos, cães e pássaros, mas essas categorias não são alocadas especificamente. Todas as categorias formam uma hierarquia. Portanto, é simplesmente impossível aplicar essa rede em sua forma pura - é necessário treiná-la novamente em nossos dados.
No final do processo, vemos com que precisão nosso modelo foi treinado e testado após várias iterações. Para melhorar os resultados, podemos aumentar o número de imagens no conjunto de dados original ou alterar o número de iterações.
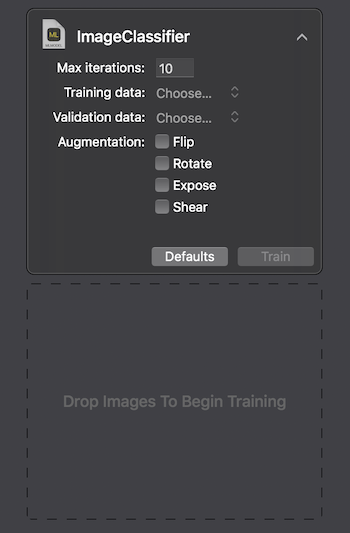
Em seguida, podemos testar o modelo em um conjunto de dados de teste. As imagens devem ser únicas, ou seja, Não entre no conjunto de fontes.
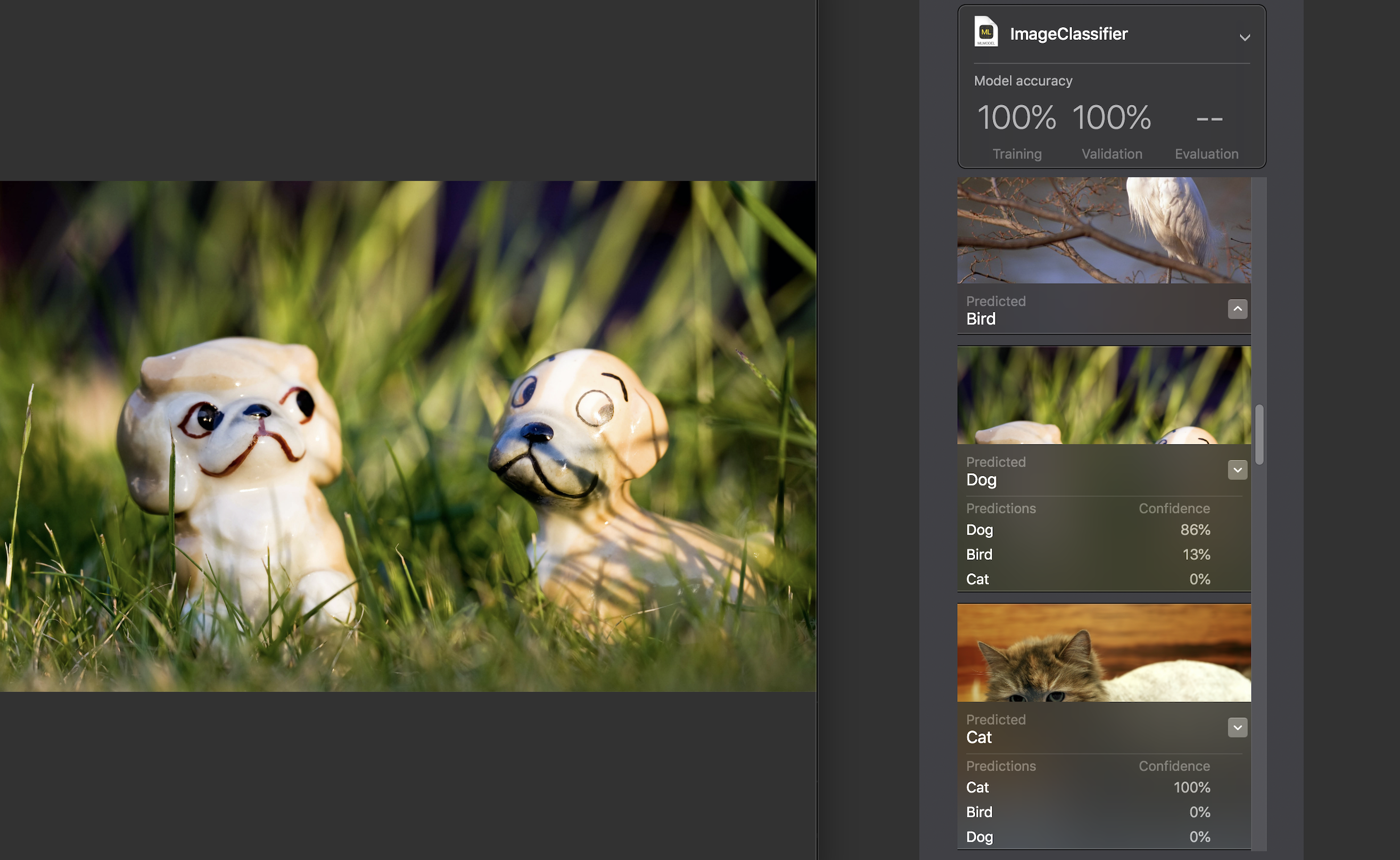
Para cada imagem, um indicador de confiança é exibido - com que precisão, com a ajuda do nosso modelo, a categoria foi reconhecida.
Para quase todas as fotos, com raras exceções, esse número foi de 100%. Adicionei especificamente a imagem que você vê acima ao conjunto de dados de teste e, como você pode ver, o Create ML reconheceu 86% do cão e 13% do pássaro.
O treinamento do modelo foi concluído e tudo o que resta para nós é salvar o arquivo * .mlmodel e adicioná-lo ao seu projeto.
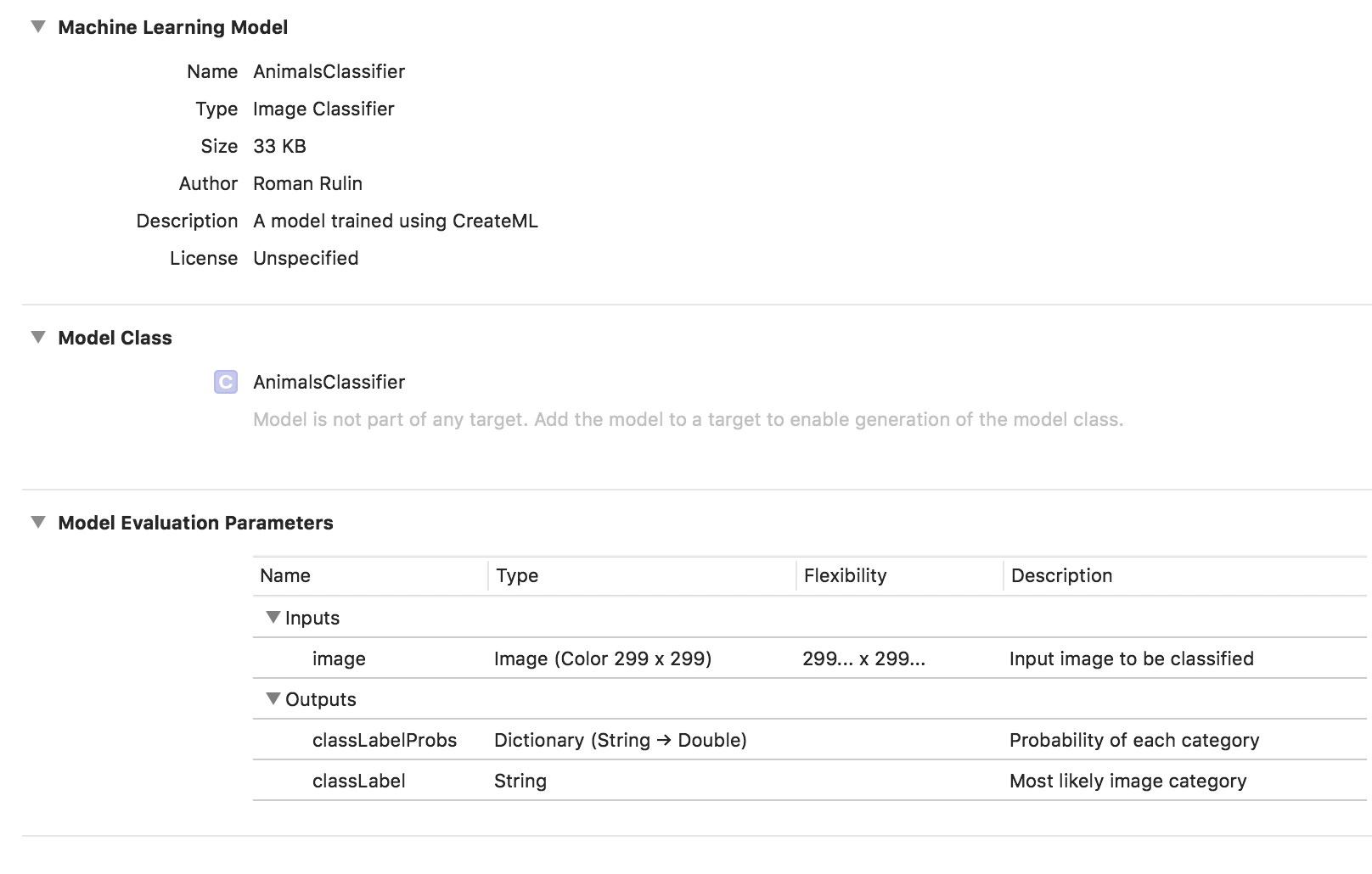
Para testar o modelo, escrevi um aplicativo simples usando a estrutura do Vision. Ele permite que você trabalhe com modelos Core ML e resolva problemas usando-os, como classificação de imagens ou detecção de objetos.
Nosso aplicativo reconhecerá a imagem da câmera do dispositivo e exibirá a categoria e a porcentagem de confiança na classificação.
Inicializamos o modelo Core ML para trabalhar com o Vision e configuramos a consulta:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
Adicione um método que processará os resultados de VNCoreMLRequest. Mostramos apenas aqueles com um indicador de confiança de mais de 70%:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
E a última - adicionaremos o método delegado AVCaptureVideoDataOutputSampleBufferDelegate, que será chamado a cada novo quadro da câmera e executará a solicitação:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
Vamos verificar como o modelo lida com sua tarefa:

A categoria é determinada com uma precisão bastante alta, e isso é especialmente surpreendente quando você considera a rapidez com que o treinamento foi realizado e o tamanho do conjunto de dados original. Periodicamente, contra um fundo escuro, o modelo revela pássaros, mas acho que isso pode ser facilmente resolvido aumentando o número de imagens no conjunto de dados original ou aumentando o nível mínimo de confiança aceitável.
Se quisermos treinar novamente o modelo para classificar outra categoria, basta adicionar um novo grupo de imagens e repetir o processo - isso levará alguns minutos.
Como experimento, fiz outro conjunto de dados, no qual alterei todas as fotos de gatos na foto de um gato de ângulos diferentes, mas no mesmo plano de fundo e no mesmo ambiente. Nesse caso, o modelo quase sempre cometia erros e reconhecia a categoria em uma sala vazia, aparentemente confiando na cor como uma característica fundamental.
Outro recurso interessante introduzido no Vision apenas neste ano é a capacidade de reconhecer objetos na imagem em tempo real. É representado pela classe VNRecognizedObjectObservation, que permite obter a categoria de um objeto e sua localização - boundingBox.

Agora, o Create ML não permite criar modelos para implementar essa funcionalidade. A Apple sugere o uso do Turi Create neste caso. O processo não é muito mais complicado que o acima: você precisa preparar pastas de categorias com fotos e um arquivo no qual para cada imagem serão indicadas as coordenadas do retângulo onde o objeto está localizado.
Processamento de linguagem natural
A próxima função Criar ML é treinar modelos para classificar textos em linguagem natural - por exemplo, para determinar a coloração emocional das frases ou detectar spam.
Para criar um modelo, precisamos coletar uma tabela com o conjunto de dados original - sentenças ou textos completos atribuídos a uma determinada categoria e treinar o modelo usando-o usando o objeto MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
Nesse caso, o modelo treinado é do tipo Classificador de texto:
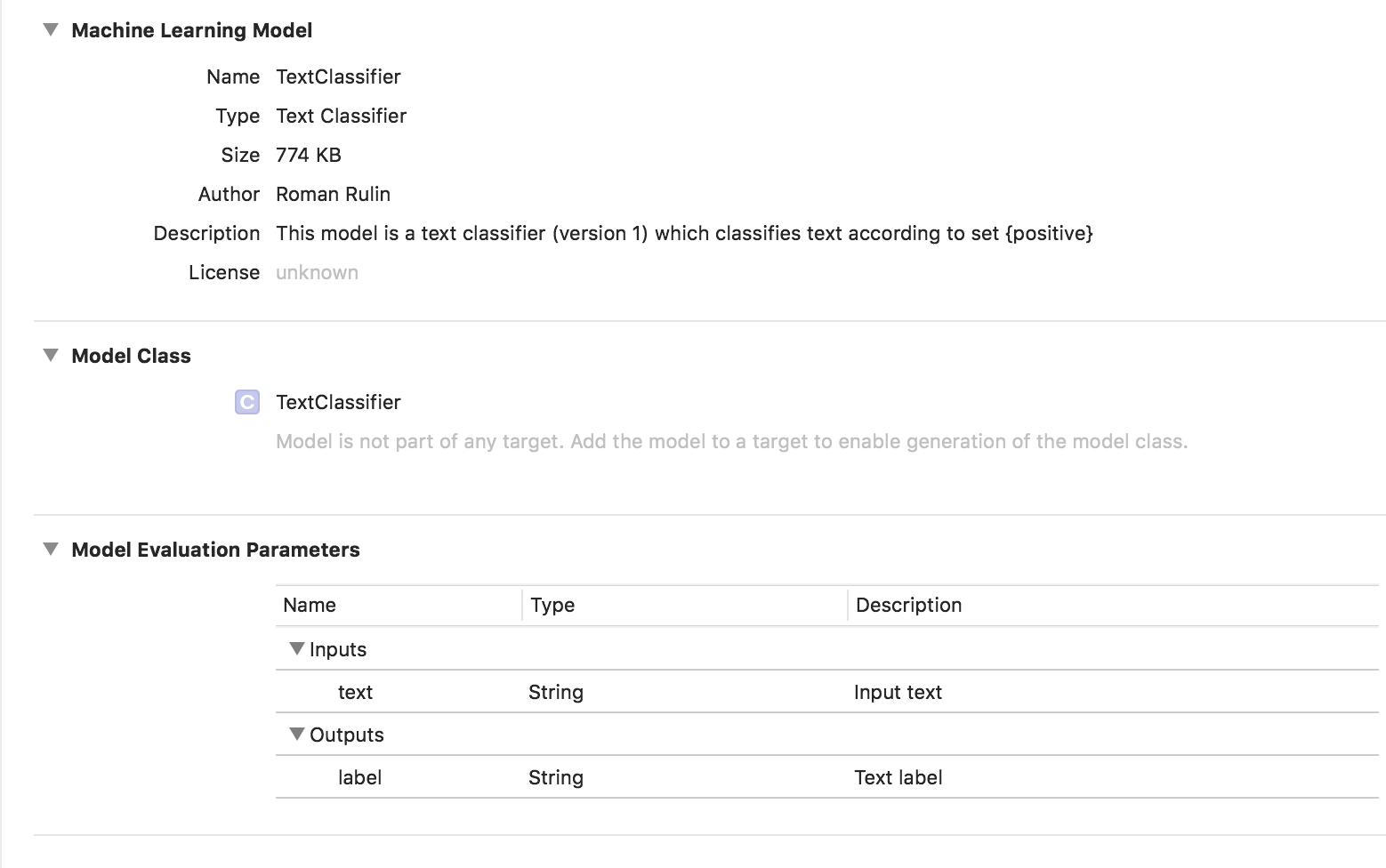
Dados tabulares
Vamos dar uma olhada em outro recurso do Create ML - treinando um modelo usando dados estruturados (tabelas).
Escreveremos um aplicativo de teste que prevê o preço de um apartamento com base em sua localização no mapa e em outros parâmetros especificados.
Portanto, temos uma tabela com dados abstratos de apartamentos em Moscou na forma de um arquivo csv: a área de cada apartamento, andar, número de quartos e coordenadas (latitude e longitude) são conhecidos. Além disso, o custo de cada apartamento é conhecido. Quanto mais próximo do centro ou maior a área, maior o preço.
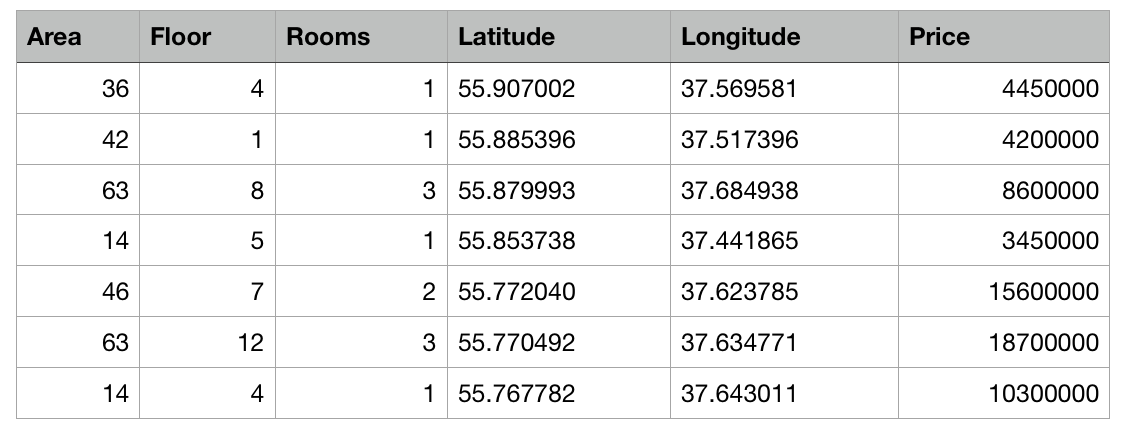
A tarefa do Create ML será construir um modelo capaz de prever o preço de um apartamento com base nessas características. Tal tarefa no aprendizado de máquina é chamada de tarefa de regressão e é um exemplo clássico de aprendizado com um professor.
O Create ML suporta muitos modelos - Regressão Linear, Regressão em Árvore de Decisão, Classificador em Árvore, Regressão Logística, Classificador de Floresta Aleatória, Regressão em Árvores Impulsionadas, etc.
Usaremos o objeto MLRegressor, que selecionará a melhor opção com base nos dados de entrada.
Primeiro, inicialize o objeto MLDataTable com o conteúdo do nosso arquivo csv:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
Dividimos o conjunto de dados inicial em dados para treinamento e teste de modelo em uma porcentagem de 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
Criamos o modelo MLRegressor, indicando os dados para o treinamento e o nome da coluna cujos valores queremos prever. O tipo de regressor específico da tarefa (linear, árvore de decisão, árvore potencializada ou floresta aleatória) será selecionado automaticamente com base no estudo dos dados de entrada. Também podemos especificar colunas de recurso - colunas de parâmetro específicas para análise, mas neste exemplo isso não é necessário, usaremos todos os parâmetros. No final, salve o modelo treinado e adicione ao projeto:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
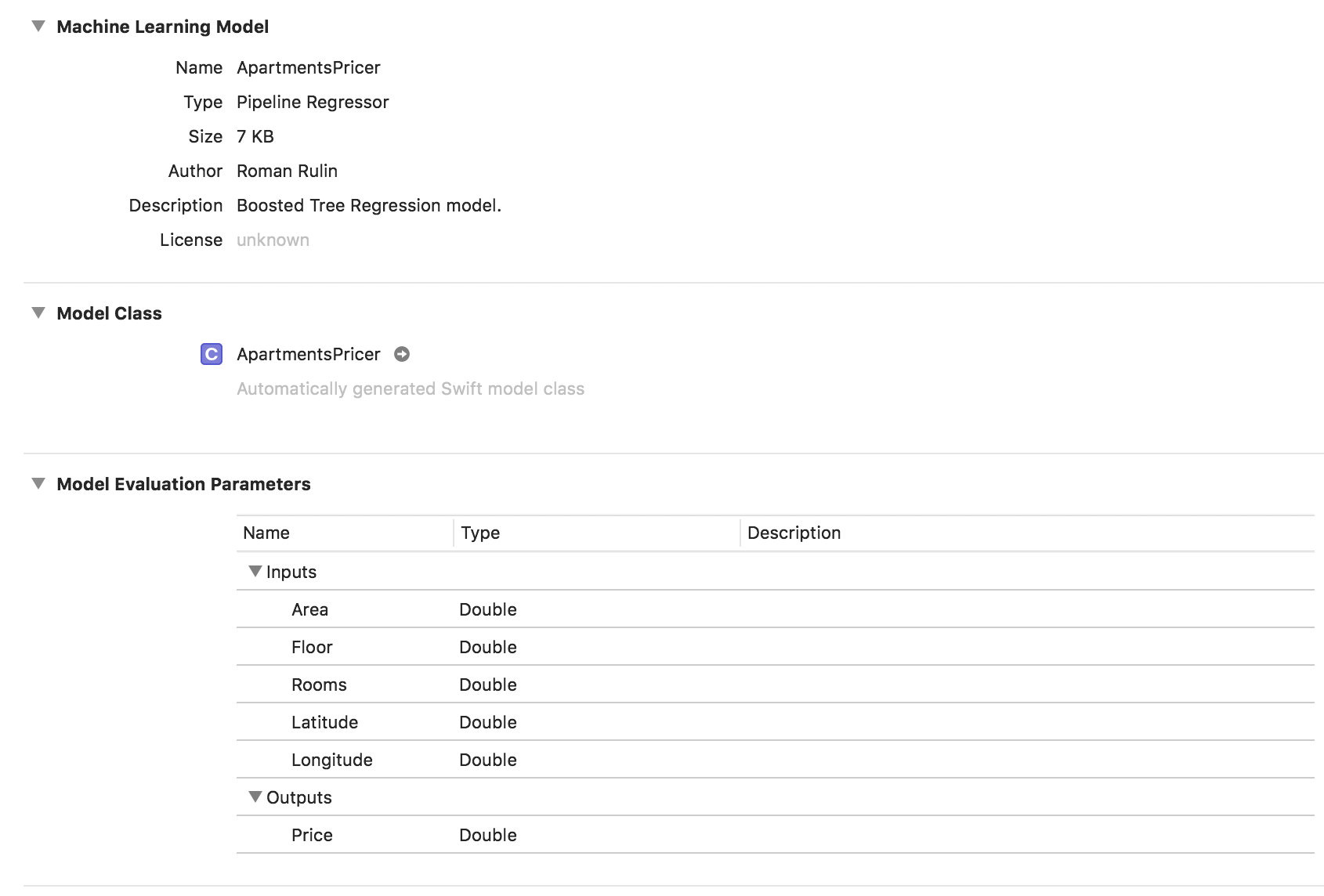
Neste exemplo, vemos que o tipo de modelo já é Regressor de Pipeline e o campo Descrição contém o tipo de regressor selecionado automaticamente - Modelo de Regressão de Árvore Reforçada. Os parâmetros Entradas e Saídas correspondem às colunas da tabela, mas seu tipo de dados se tornou Duplo.
Agora verifique o resultado.
Inicialize o objeto de modelo:
let model = ApartmentsPricer()
Chamamos o método de previsão, passando os parâmetros especificados para ele:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
Exibimos o valor previsto do custo:
let price = prediction?.price priceLabel.text = formattedPrice(price)
Alterando um ponto no mapa ou nos valores dos parâmetros, obtemos o preço do apartamento bem próximo dos dados de teste:
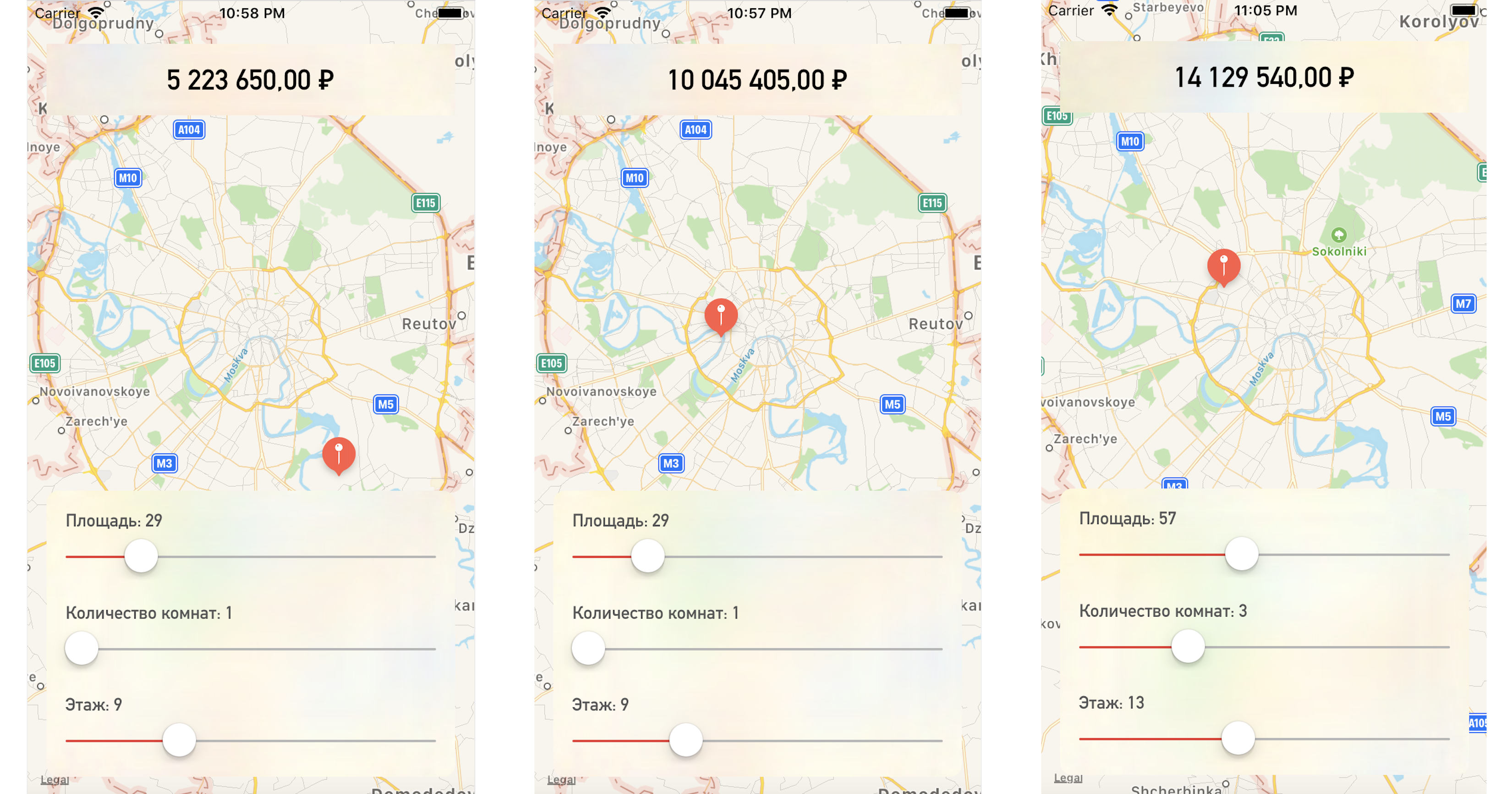
Conclusão
A estrutura Create ML é agora uma das maneiras mais fáceis de trabalhar com tecnologias de aprendizado de máquina. Ainda não permite criar modelos para solucionar alguns problemas: reconhecimento de objetos em uma imagem, estilização de uma foto, determinação de imagens semelhantes, reconhecimento de ações físicas com base em dados de um acelerômetro ou giroscópio, com o qual Turi Create, por exemplo, lida.
Mas vale a pena notar que a Apple fez um progresso bastante sério nessa área ao longo do ano passado e, com certeza, veremos em breve o desenvolvimento das tecnologias descritas.