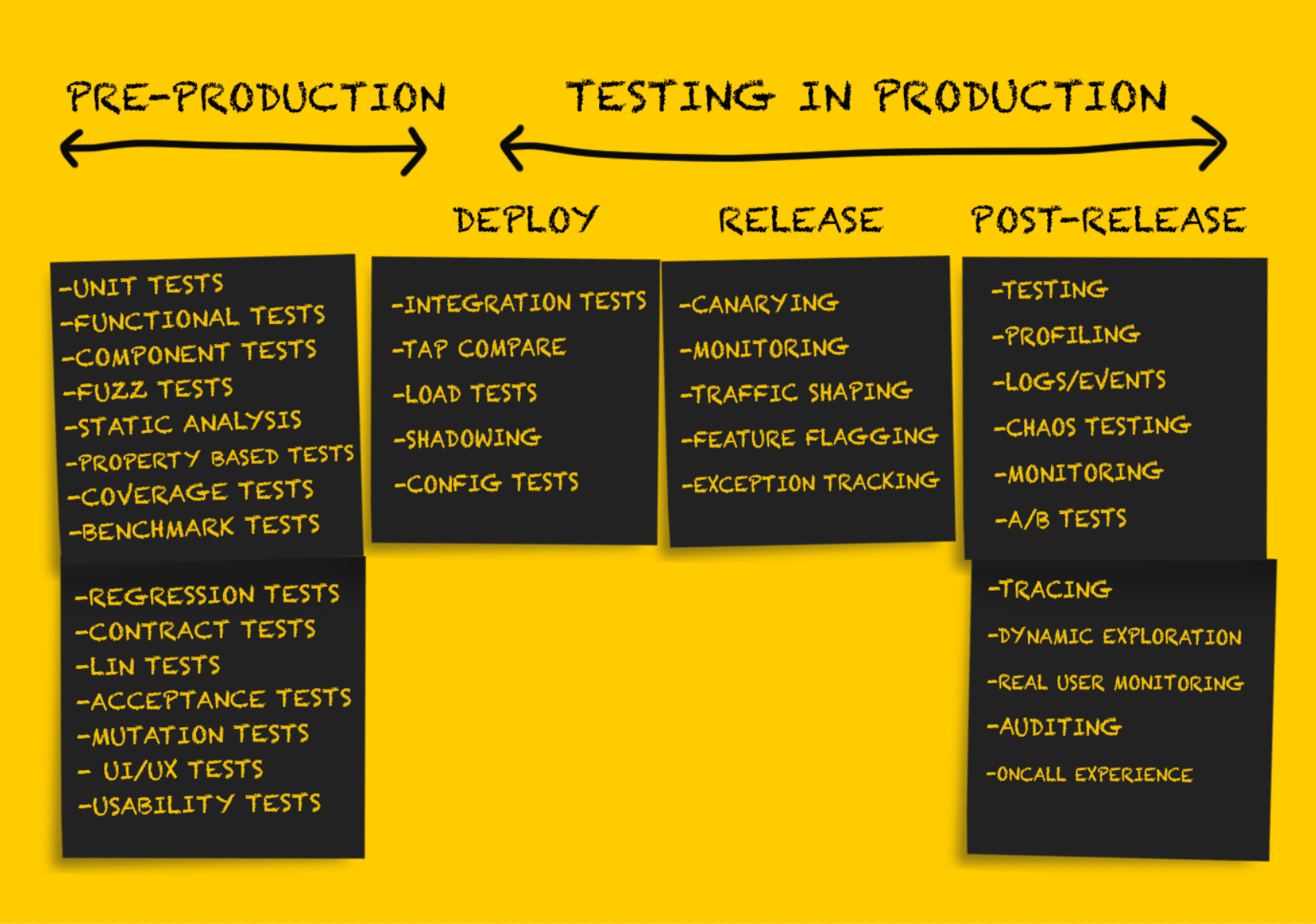
Nesta parte do artigo, continuaremos a considerar vários tipos de testes em produção. Quem pulou a primeira parte pode ler
aqui . Para o resto - bem-vindo ao gato.
Teste de produção: Liberação
Após testar o serviço após a
implantação , ele deve estar preparado para a
liberação .
É importante observar que, nesta fase, a reversão de alterações é possível apenas em situações de falha
sustentável , por exemplo:
- loop de falha de serviço;
- exceder o tempo de espera por um número significativo de conexões a montante, causando um forte aumento na frequência de erros;
- mudança inaceitável na configuração, por exemplo, a falta de uma chave secreta em uma variável de ambiente que causa falha no serviço (geralmente é melhor evitar variáveis de ambiente, mas esse é um tópico para outra discussão).
Testes completos no estágio de
implantação permitem minimizar idealmente ou evitar completamente surpresas desagradáveis no estágio de
lançamento . No entanto, existem várias recomendações para a liberação segura de novo código.
Implantação das Canárias
A implantação do Canary é uma
liberação parcial
de um serviço em produção. À medida que a verificação básica de integridade passa, as pequenas partes do tráfego atual do ambiente de produção são enviadas para as peças liberadas. Os resultados das partes do serviço são monitorados à medida que o tráfego é processado, os indicadores são comparados com os de referência (não relacionados aos canários) e, se estiverem fora dos valores limite aceitáveis, será executada uma reversão para o estado anterior. Embora essa abordagem seja normalmente usada ao liberar software de servidor, o
teste canário de software cliente também está se tornando mais comum.
Vários fatores influenciam o tráfego que será usado para a implantação de canários. Em várias empresas, as partes liberadas do serviço primeiro recebem apenas o tráfego interno do usuário (o chamado dogfooding). Se nenhum erro for observado, uma pequena parte do tráfego do ambiente de produção será adicionada, após o qual uma implementação completa será realizada.
Recomenda-se reverter
automaticamente para o estado anterior no caso de resultados inválidos de implantação de canários, e ferramentas como o
Spinnaker têm suporte interno para funções de análise e reversão automatizadas.
Existem alguns problemas com o teste de canário, e
este artigo fornece uma visão geral bastante completa deles.
Monitoramento
O monitoramento é um procedimento absolutamente necessário em
todas as etapas da implantação do produto na produção, mas essa função será especialmente importante na fase de
lançamento . O monitoramento é adequado para obter informações sobre o nível geral de desempenho do sistema. Mas monitorar tudo no mundo pode não ser a melhor solução.
O monitoramento
eficaz é realizado no sentido do ponto, o que permite identificar um pequeno conjunto de modos de falha sustentável do sistema ou um conjunto básico de indicadores. Exemplos de tais modos de falha podem ser:
- aumento da taxa de erro;
- uma diminuição na velocidade geral de processamento de solicitações em todo o serviço, em um endpoint específico ou, pior ainda, em uma interrupção completa do trabalho;
- atraso aumentado.
A observação de qualquer um desses modos de falha sustentável é a base para uma reversão imediata para um estado anterior ou uma reversão de novas versões
lançadas do software. É importante lembrar que é improvável que o monitoramento nesta fase seja completo e indicativo. Muitos acreditam que o número ideal de sinais monitorados durante o monitoramento é de 3 a 5, mas
definitivamente não mais que 7-10. O white paper do Kraken Facebook oferece a seguinte solução:
"O problema é resolvido com a ajuda de um componente de monitoramento facilmente configurável, que reporta dois indicadores básicos (o percentil 99 do tempo de resposta do servidor da Web e a frequência de ocorrência de erros HTTP fatais) que descrevem objetivamente a qualidade da interação do usuário".O conjunto de indicadores de sistema e aplicativo que são monitorados durante a fase de liberação é melhor determinado durante o design do sistema.
Rastreamento de exceção
Estamos falando sobre o rastreamento de exceções no estágio de lançamento, embora possa parecer que nos estágios de
implantação e após o lançamento isso não seria menos útil. As ferramentas de rastreamento de exceção geralmente não garantem a mesma abrangência, precisão e cobertura em massa que algumas outras ferramentas de monitoramento do sistema, mas ainda podem ser muito úteis.
As ferramentas de código aberto (como o
Sentry ) exibem informações avançadas sobre solicitações recebidas e criam pilhas de dados de rastreamento e variáveis locais, o que simplifica bastante o processo de depuração, que geralmente consiste em exibir logs de eventos. O rastreamento de exceções também é útil ao classificar e priorizar problemas que não exigem uma reversão completa para um estado anterior (por exemplo, um caso de fronteira que gera uma exceção).
Modelagem de tráfego
A modelagem do tráfego (redistribuição do tráfego) não é tanto uma forma independente de teste, mas uma ferramenta para apoiar a abordagem canária e o lançamento em fases do novo código. De fato, a modelagem de tráfego é garantida com a atualização da configuração do balanceador de carga, que permite redirecionar gradualmente mais tráfego para a nova versão
lançada .
Esse método também é útil para a implantação em fases de novo software (separada da implantação regular). Considere um exemplo. A Imgix precisava implantar uma arquitetura de infraestrutura fundamentalmente nova em junho de 2016. Após o primeiro teste da nova infraestrutura com uma certa quantidade de tráfego escuro, eles começaram a implantar na produção, redirecionando inicialmente cerca de 1% do tráfego do ambiente de produção para uma nova pilha. Então, ao longo de várias semanas, o volume de dados que chegava à nova pilha foi aumentado (resolvendo problemas ao longo do caminho), até que começou a processar 100% do tráfego.
A popularidade da arquitetura de malha de serviço provocou um novo aumento no interesse em servidores proxy. Como resultado, os proxies antigos (nginx, HAProxy) e os novos (Envoy, Conduit) adicionaram suporte para novas funções na tentativa de superar os concorrentes. Parece-me que o futuro, no qual a redistribuição de tráfego de 0 a 100% no estágio de lançamento do produto é realizada automaticamente, está chegando.
Teste de produção: Após a liberação
O teste pós-liberação é realizado como uma verificação realizada
após uma liberação bem
- sucedida
do código. Nesse estágio, você pode ter certeza de que o código como um todo está correto, foi
liberado com sucesso na produção e processa o tráfego corretamente. O código implantado é usado direta ou indiretamente em condições reais, atendendo clientes reais ou executando tarefas que têm um impacto significativo nos negócios.
O objetivo de qualquer teste neste estágio é principalmente verificar a operacionalidade do sistema, levando em consideração várias cargas possíveis e padrões de tráfego. A melhor maneira de fazer isso é coletar evidências documentais de tudo o que acontece na produção e usá-lo para depuração e para obter uma imagem completa do sistema.
Sinalização de recurso ou inicialização escura
A publicação mais antiga sobre o uso bem-sucedido de sinalizadores de recursos que eu encontrei foi publicada há quase dez anos.
O Featureflags.io fornece o guia mais abrangente para isso.
“A sinalização de recurso é um método usado pelos desenvolvedores para marcar uma nova função usando instruções if-then, o que permite mais controle sobre seu lançamento. Ao sinalizar uma função e isolá-la dessa maneira, o desenvolvedor pode ativar e desativar essa função, independentemente do status da implantação. Isso efetivamente separa a liberação da função da implantação do código ".Ao sinalizar o novo código, você pode testar seu desempenho e desempenho na produção, conforme necessário. A sinalização de recurso é um dos tipos geralmente aceitos de teste em produção, é bem conhecido e geralmente é
descrito em
várias fontes . O fato de esse método poder ser usado no processo de teste da
transferência de bancos de dados ou software para sistemas pessoais é muito menos conhecido.
Os autores dos artigos raramente escrevem sobre os melhores métodos para desenvolver e usar sinalizadores de função. O uso descontrolado de sinalizadores pode ser um problema sério. A falta de disciplina em termos de remoção de sinalizadores não utilizados após um período especificado às vezes leva ao fato de que você deve realizar uma auditoria completa e excluir sinalizadores obsoletos acumulados ao longo de meses (se não anos) de trabalho.
Teste A / B
O teste A / B é geralmente executado como parte de uma análise experimental e não é considerado como teste na produção. Por esse motivo, os testes A / B não são apenas amplamente utilizados (às vezes até de maneira
dúbia ), mas também
estudados e
descritos ativamente (incluindo artigos sobre o
que determina um scorecard eficaz para experimentos on-line). Muito menos comumente, os testes A / B são usados para testar várias configurações de hardware ou máquinas virtuais. Eles são freqüentemente chamados de "ajuste" (por exemplo, ajuste da JVM), mas não são classificados como testes A / B típicos (embora o ajuste possa ser considerado como um tipo de teste A / B executado com o mesmo nível de rigor no que diz respeito às medições) .
Logs, eventos, indicadores e rastreamento
Você
pode ler sobre as chamadas “três baleias da observabilidade” - registros, indicadores e rastreamento distribuído
aqui .
Criação de perfil
Em alguns casos, para diagnosticar problemas de desempenho, é necessário usar o perfil do aplicativo na produção. Dependendo dos idiomas e tempos de execução suportados, a criação de perfil pode ser um procedimento bastante simples, que envolve a adição de apenas uma linha de código ao aplicativo (
import _ "net/http/pprof" no caso do Go). Por outro lado, pode exigir o uso de muitas ferramentas ou testar o processo pelo método da caixa preta e verificar os resultados usando ferramentas como
gráficos de flama .
Teste de Tee
Muitas pessoas consideram que esse teste é algo como duplicação de dados de sombra, pois em ambos os casos o tráfego do ambiente de produção é enviado para clusters ou processos que não são de produção. Na minha opinião, a diferença é que o uso do tráfego para fins de
teste é um pouco diferente do seu uso para fins de
depuração .
A Etsy escreveu em seu blog sobre o uso de tee-tests como uma ferramenta de verificação (este exemplo realmente se parece com a duplicação de dados de sombra).
“Aqui tee pode ser entendido como o comando tee na linha de comando. Escrevemos uma regra da iRule com base em um balanceador de carga F5 existente para clonar o tráfego HTTP direcionado a um dos conjuntos e redirecioná-lo para outro conjunto. Assim, pudemos usar o tráfego do ambiente de produção direcionado ao nosso cluster de API e enviar uma cópia dele para o cluster HHVM experimental, bem como para um cluster PHP isolado para comparação.
Esta técnica provou ser muito eficaz. Ele nos permitiu comparar o desempenho das duas configurações usando perfis de tráfego idênticos. ”No entanto, às vezes é necessário um teste tee com base no tráfego do ambiente de produção em um sistema autônomo para
depuração . Nesses casos, o sistema autônomo pode ser alterado para configurar a saída de informações adicionais de diagnóstico ou outro procedimento de compilação (por exemplo, usando a ferramenta de limpeza de fluxo), o que simplifica bastante o processo de solução de problemas. Nesses casos, os testes tee devem ser considerados, em vez disso,
ferramentas de depuração , e não
verificação .
Anteriormente, esses tipos de depuração eram relativamente raros no
imgix , mas ainda eram usados, principalmente quando se tratava de problemas com aplicativos de depuração sensíveis ao atraso.
Por exemplo, a seguir, é apresentada uma descrição analítica de um desses incidentes ocorridos em 2015. O erro 400 ocorreu tão raramente que quase não foi visto ao tentar reproduzir o problema. Ela apareceu em apenas alguns casos em um bilhão. Havia muito poucos deles durante o dia. Como resultado, verificou-se que era simplesmente impossível reproduzir o problema de maneira confiável, por isso era necessário executar a depuração usando o tráfego de trabalho para ter a chance de rastrear a ocorrência desse erro. Aqui está o que meu ex-colega escreveu sobre isso:
“Eu escolhi uma biblioteca que deveria ser interna, mas no final tive que criar a minha própria com base na biblioteca fornecida pelo sistema. Na versão fornecida pelo sistema, ocorreu um erro periodicamente que não apareceu de forma alguma enquanto a quantidade de tráfego era pequena. No entanto, o nome truncado no título era o problema real.
Nos dois dias seguintes, estudei em detalhes o problema associado ao aumento da frequência de erros falsos 400. O erro foi manifestado em um número muito pequeno de solicitações, e problemas desse tipo são difíceis de diagnosticar. Tudo isso parecia a notória agulha no palheiro: o problema foi encontrado em um caso por bilhão.
A primeira etapa para localizar a origem dos erros foi obter todos os dados brutos da solicitação HTTP que resultaram em uma resposta incorreta. Para executar um teste tee do tráfego de entrada quando conectado a um soquete, adicionei o ponto de extremidade do soquete do domínio Unix ao servidor de renderização. A idéia era permitir a rápida e fácil ativação e desativação do fluxo de tráfego escuro e a realização de testes diretamente no computador do desenvolvedor. Para evitar problemas na produção, era necessário interromper a conexão se houvesse um problema de contrapressão. I.e. se a duplicata não conseguir lidar com a tarefa, ela será desconectada. Esse soquete foi muito útil em alguns casos durante o desenvolvimento. Desta vez, no entanto, nós o usamos para coletar o tráfego recebido nos servidores selecionados, na esperança de obter solicitações suficientes para revelar o padrão que levou ao aparecimento de erros falsos 400. Usando o dsh e o netcat, consegui produzir com relativa facilidade o tráfego recebido para um arquivo local .
A maior parte do ambiente foi gasta coletando esses dados. Assim que tivemos dados suficientes, pude usar o netcat para reproduzi-lo no sistema local, cuja configuração foi alterada para exibir uma grande quantidade de informações de depuração. E tudo correu perfeitamente. O próximo passo é reproduzir os dados na velocidade mais alta possível. Nesse caso, o loop com a verificação da condição enviou as solicitações brutas uma de cada vez. Após cerca de duas horas, consegui alcançar o resultado desejado. Os dados nos logs mostraram a falta de um cabeçalho!
Eu uso madeira vermelho-preta para transmitir os cabeçalhos. Tais estruturas consideram comparabilidade como identidade, o que por si só é muito útil quando há requisitos especiais para chaves: no nosso caso, os cabeçalhos HTTP não diferenciavam maiúsculas de minúsculas. Inicialmente, pensamos que o problema estava no nó da folha da biblioteca usada. A ordem de adição realmente afeta a ordem de construção da árvore base, e equilibrar a árvore vermelho-preta é um processo bastante complicado. E embora essa situação fosse improvável, não era impossível. Eu mudei para outra implementação de ébano vermelho. Foi consertado há vários anos, então decidi incorporá-lo diretamente na fonte para obter exatamente a versão necessária. No entanto, a montagem escolheu uma versão diferente e, como eu estava contando com uma versão mais nova, tive um comportamento incorreto no final.
Por isso, o sistema de visualização gerou 500 erros, o que levou à interrupção do ciclo. É por isso que o erro ocorreu apenas ao longo do tempo. Após o processamento cíclico de vários assemblies, o tráfego deles foi redirecionado para uma rota diferente, o que aumentou a escala do problema nesse servidor. Minha suposição de que o problema estava na biblioteca estava errada, e a chave reversa resolveu 500 erros.
Voltei a 400 erros: ainda havia um problema com o erro, que levou cerca de duas horas para ser detectado. Alterar a biblioteca, obviamente, não resolveu o problema, mas eu tinha certeza de que a biblioteca selecionada era confiável o suficiente. Não percebendo a falácia da escolha, não mudei nada. Tendo estudado a situação com mais detalhes, percebi que o valor correto estava armazenado em um cabeçalho de um caractere (por exemplo, "h: 12345"). Finalmente me ocorreu que h era o personagem final do cabeçalho Content-Length. Observando os dados novamente, percebi que o cabeçalho Content-Length estava vazio.
Como resultado, a coisa toda foi um erro de viés ao ler os cabeçalhos. O analisador HTTP nginx / joyent cria dados parciais e, cada vez que o campo do cabeçalho parcial era um caractere menor que o necessário, enviava o cabeçalho sem um valor e, subsequentemente, recebia um campo de cabeçalho de um caractere contendo o valor correto. Essa é uma combinação bastante rara, portanto, sua operação leva tanto tempo. Portanto, aumentei a quantidade de coleta de dados toda vez que um cabeçalho de um caractere apareceu, apliquei a correção proposta e executei o script com êxito por várias horas.
É claro que algumas outras armadilhas com o mau funcionamento da biblioteca mencionado podem ser detectadas, mas os dois erros foram corrigidos. ”
Os engenheiros envolvidos no desenvolvimento de aplicativos sensíveis ao atraso precisam da capacidade de depurar usando o tráfego dinâmico capturado, porque geralmente ocorrem erros que não podem ser reproduzidos durante o teste da unidade ou detectados usando uma ferramenta de monitoramento (especialmente se houver um atraso grave no registro).
Abordagem da Engenharia do Caos
A Engenharia do Caos é uma abordagem baseada em experimentos em um sistema distribuído para confirmar sua capacidade de suportar as condições caóticas do ambiente de produção.O método Chaos Engineering, tornado famoso pelo
Chaos Monkey da Netflix, agora se tornou uma disciplina independente. O termo Engenharia do Caos apareceu recentemente, mas o teste de falhas é uma prática de longa data.
O termo "teste caótico" refere-se às seguintes técnicas:
- desabilitar nós arbitrários para determinar quão resistente o sistema é à falha;
- introdução de erros (por exemplo, aumento do atraso) para confirmar que o sistema os processa corretamente;
- violação forçada da rede para determinar a resposta do serviço.
A maioria das empresas usa um ambiente operacional insuficientemente complexo e hierárquico para realizar efetivamente testes caóticos. É importante enfatizar que a introdução de falhas no sistema é melhor feita após definir as funções básicas da tolerância a falhas.
Este white paper de Gremlin fornece uma descrição bastante abrangente dos princípios de testes caóticos, além de instruções para a preparação deste procedimento.
“Especialmente importante é o fato de a Chaos Engineering ser considerada uma disciplina científica. Dentro desta disciplina, processos de engenharia de alta precisão são aplicados.
A tarefa da Chaos Engineering é informar aos usuários algo novo sobre as vulnerabilidades do sistema, realizando experimentos. É necessário identificar todos os problemas ocultos que podem surgir na produção, mesmo antes que causem uma falha maciça. Somente depois disso você poderá eliminar efetivamente todas as fraquezas do sistema e torná-lo verdadeiramente tolerante a falhas. ”Conclusão
O objetivo do teste na produção não é
eliminar completamente todas as falhas possíveis no sistema.
John Allspaw diz:
“ Vemos que os sistemas estão se tornando mais tolerantes a falhas - e isso é ótimo. Mas devemos admitir: "mais e mais" não é igual a "absolutamente". Em qualquer sistema complexo, uma falha pode acontecer (e acontecerá) da maneira mais imprevisível. ”
Testar a produção à primeira vista pode parecer uma tarefa bastante complicada, indo muito além da competência da maioria das empresas de engenharia. E embora esse teste
não seja uma tarefa
fácil , associada a alguns riscos, se você o seguir de acordo com todas as regras, ajudará a obter a confiabilidade de sistemas distribuídos complexos encontrados hoje em toda parte.