Em um artigo anterior, analisamos os padrões e topologias usados no RabbitMQ. Nesta parte, veremos o Kafka e o compararemos com o RabbitMQ para obter algumas idéias sobre suas diferenças. Deve-se ter em mente que as arquiteturas de aplicativos orientadas a eventos serão comparadas em vez de pipelines de processamento de dados, embora a linha entre esses dois conceitos seja um pouco confusa nesse caso. Em geral, isso é mais um espectro do que uma separação clara. Nossa comparação se concentrará simplesmente na parte desse espectro relacionada a aplicativos orientados a eventos.

A primeira diferença que vem à mente é que os mecanismos de repetição e adiamento de mensagens usados no RabbitMQ para trabalhar com mensagens não entregues no Kafka não fazem sentido. No RabbitMQ, as mensagens são temporárias, são transmitidas e desaparecem. Portanto, adicioná-los novamente é um caso de uso absolutamente real. E em Kafka, a revista ocupa o centro do palco. Resolver problemas de entrega reenviando uma mensagem para a fila não faz sentido e prejudica apenas o diário. Uma das vantagens é a distribuição clara e garantida de mensagens entre as partições do diário; as mensagens repetidas confundem um esquema bem organizado. No RabbitMQ, você já pode enviar mensagens para a fila com a qual um destinatário trabalha, e na plataforma Kafka há um diário para todos os destinatários. Atrasos na entrega e problemas com a entrega da mensagem não causam muitos danos à operação do diário, mas o Kafka não contém mecanismos de atraso internos.
Como entregar novamente as mensagens na plataforma Kafka será discutido na seção sobre esquemas de mensagens.
A segunda grande diferença que afeta os possíveis esquemas de mensagens é que o RabbitMQ armazena mensagens muito menos que o Kafka. Quando uma mensagem já foi entregue ao destinatário no RabbitMQ, ela é excluída sem deixar rastro de sua existência. No Kafka, todas as mensagens são mantidas em um log até serem limpas. A frequência da limpeza depende da quantidade de dados disponíveis, da quantidade de espaço em disco que você planeja alocar para eles e dos esquemas de mensagens que você deseja fornecer. Você pode usar a janela de tempo em que armazenamos mensagens por um determinado período: os últimos dias / semanas / meses.
Dessa forma, o Kafka permite que o destinatário revise ou recupere as mensagens anteriores. Parece uma tecnologia para enviar mensagens, embora não funcione da mesma forma que no RabbitMQ.
Se o RabbitMQ mover mensagens e fornecer elementos poderosos para a criação de esquemas de roteamento complexos, o Kafka salvará o estado atual e o anterior do sistema. Essa plataforma pode ser usada como uma fonte de dados históricos confiáveis, uma vez que o RabbitMQ não pode.
Exemplo de esquema de mensagens na plataforma Kafka
O exemplo mais simples de usar o RabbitMQ e o Kafka é a disseminação de informações de acordo com o esquema de "publicador-assinante". Um ou mais editores adicionam mensagens ao log particionado e essas mensagens são recebidas pelo assinante de um ou mais grupos de assinantes.

Figura 1. Vários publicadores enviam mensagens para o log particionado e vários grupos de destinatários as recebem.
Se você não entrar em detalhes sobre como o editor envia mensagens para as seções necessárias da revista e como os grupos de destinatários são coordenados entre si, esse esquema não difere da topologia de fanout (troca bifurcada) usada no RabbitMQ.
Em um artigo anterior, foram discutidos todos os esquemas de mensagens e topologias do RabbitMQ. Talvez em algum momento você tenha pensado "Não preciso de todas essas dificuldades, só quero enviar e receber mensagens na fila", e o fato de poder retroceder a revista para posições anteriores falou das vantagens óbvias da Kafka.
Para as pessoas que estão acostumadas com os recursos tradicionais dos sistemas de filas, é incrível a possibilidade de voltar o relógio e rebobinar o registro de eventos no passado. Essa propriedade (disponível usando o log em vez da fila) é muito útil para recuperar falhas. Eu (o autor do artigo em inglês) comecei a trabalhar para meu cliente atual há 4 anos como gerente técnico do grupo de suporte ao sistema de servidor. Tínhamos mais de 50 aplicativos que receberam informações em tempo real sobre eventos de negócios por meio do MSMQ, e o normal era que, quando ocorria um erro no aplicativo, o sistema o detectava apenas no dia seguinte. Infelizmente, muitas vezes as mensagens desapareceram como resultado, mas geralmente conseguimos obter os dados iniciais de um sistema de terceiros e encaminhar mensagens apenas para o "assinante" que estava com o problema. Isso exigiu a criação de uma infraestrutura de mensagens para os destinatários. E se tivéssemos a plataforma Kafka, não seria mais difícil executar esse trabalho do que alterar o link para o local da última mensagem recebida para o aplicativo em que ocorreu o erro.
Integração de dados em aplicativos e sistemas orientados a eventos
Esse esquema é, de várias maneiras, um meio de gerar eventos, embora não esteja relacionado a um único aplicativo. Existem dois níveis de geração de eventos: software e sistema. O presente esquema está associado ao último.
Geração de evento no nível do programa
O aplicativo gerencia seu próprio estado por meio de uma sequência imutável de eventos de alteração que são armazenados no armazenamento de eventos. Para obter o estado atual do aplicativo, você deve reproduzir ou combinar seus eventos na sequência correta. Normalmente, nesse modelo, o modelo CQRS Kafka pode ser usado como esse sistema.
Interação entre aplicativos no nível do sistema.
Aplicativos ou serviços podem gerenciar seu estado da maneira que seu desenvolvedor desejar, por exemplo, em um banco de dados relacional regular.
Mas os aplicativos geralmente precisam de dados um sobre o outro, isso leva a arquiteturas abaixo do ideal, por exemplo, bancos de dados comuns, indefinição dos limites da entidade ou APIs REST inconvenientes.
Eu (o autor do artigo em inglês) ouvi o podcast “ Software Engineering Daily ”, que descreve um cenário orientado a eventos para os perfis de serviço nas redes sociais. Existem vários serviços relacionados no sistema, como pesquisa, um sistema de gráficos sociais, um mecanismo de recomendação etc., todos eles precisam saber sobre uma alteração no status de um perfil de usuário. Quando eu (o autor do artigo em inglês) trabalhava como arquiteto da arquitetura de um sistema relacionado ao transporte aéreo, tínhamos dois grandes sistemas de software com uma infinidade de pequenos serviços relacionados. Os serviços de suporte exigiram dados de pedidos e voos. Cada vez que um pedido foi criado ou alterado, quando um voo atrasou ou foi cancelado, esses serviços tiveram que ser ativados.
Exigia uma técnica para gerar eventos. Mas primeiro, vamos examinar alguns problemas comuns que surgem em grandes sistemas de software e ver como a geração de eventos pode resolvê-los.
Um grande sistema corporativo integrado geralmente se desenvolve organicamente; migrações para novas tecnologias e novas arquiteturas são realizadas, o que pode não afetar 100% do sistema. Os dados são distribuídos para diferentes partes da instituição, os aplicativos divulgam bancos de dados para uso público, para que a integração ocorra o mais rápido possível, e ninguém pode prever com certeza como todos os elementos do sistema irão interagir.
Distribuição aleatória de dados
Os dados são distribuídos em lugares diferentes e gerenciados em lugares diferentes, por isso é difícil entender:
- como os dados se movem nos processos de negócios;
- como as mudanças em uma parte do sistema podem afetar outras partes;
- o que fazer com os conflitos de dados que surgem devido ao fato de haver muitas cópias de dados que se espalham lentamente.
Se não houver limites claros para as entidades de domínio, as alterações serão caras e arriscadas, pois afetam muitos sistemas ao mesmo tempo.
Banco de dados distribuído centralizado
Um banco de dados aberto publicamente pode causar vários problemas:
- Ele não é otimizado o suficiente para cada aplicativo separadamente.O mais provável é que esse banco de dados contenha um conjunto de dados excessivamente completo para o aplicativo, além disso, é normalizado de forma que os aplicativos tenham que executar consultas muito complexas para recebê-los.
- Usando um banco de dados comum, os aplicativos podem afetar o trabalho um do outro.
- Alterações na estrutura lógica do banco de dados requerem coordenação em grande escala e trabalho na migração de dados, e o desenvolvimento de serviços individuais será interrompido durante todo o processo.
- Ninguém quer mudar a estrutura de armazenamento. As mudanças pelas quais todos estão esperando são muito dolorosas.
Usando a API REST inconveniente
Obter dados de outros sistemas através da API REST, por um lado, adiciona conveniência e isolamento, mas ainda assim nem sempre é bem-sucedido. Cada uma dessas interfaces pode ter seu próprio estilo especial e suas próprias convenções. A obtenção dos dados necessários pode exigir muitas solicitações HTTP e ser bastante complicada.
Estamos nos movendo cada vez mais para a centralidade da API, e essas arquiteturas oferecem muitas vantagens, especialmente quando os próprios serviços estão fora de nosso controle. Existem tantas maneiras convenientes de criar uma API no momento que não precisamos escrever o código necessário antes. No entanto, essa não é a única ferramenta disponível e existem alternativas para a arquitetura interna do sistema.
Kafka como um repositório de eventos
Nós damos um exemplo. Existe um sistema que gerencia reservas em um banco de dados relacional. O sistema utiliza todas as garantias de atomicidade, consistência, isolamento e durabilidade oferecidas pelo banco de dados para gerenciar efetivamente suas características e todos estão felizes. A divisão de responsabilidade em equipes e solicitações, a geração de eventos, microsserviços estão ausentes, em geral, um monólito tradicionalmente construído. Mas há uma infinidade de serviços de suporte (possivelmente microsserviços) relacionados a reservas: notificações push, distribuição de e-mail, sistema antifraude, programa de fidelidade, cobrança, sistema de cancelamento etc. A lista continua e continua. Todos esses serviços exigem detalhes da reserva e existem várias maneiras de obtê-los. Esses serviços produzem dados que podem ser úteis para outros aplicativos.

Figura 2. Vários tipos de integração de dados.
Arquitetura alternativa baseada em Kafka. Cada vez que você faz uma nova reserva ou altera uma reserva anterior, o sistema envia dados completos sobre o estado atual dessa reserva para Kafka. Ao consolidar o diário, você pode encurtar as mensagens para que apenas as informações sobre o status mais recente da reserva sejam deixadas nele. Nesse caso, o tamanho do diário estará sob controle.
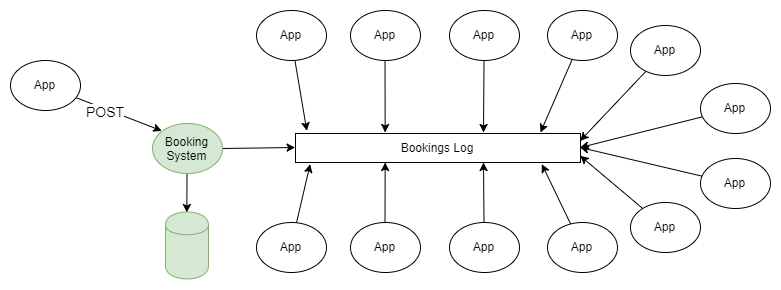
Figura 3. Integração de dados baseada em Kafka como base para geração de eventos
Para todos os aplicativos para os quais isso é necessário, essas informações são a fonte da verdade e a única fonte de dados. De repente, passamos de uma rede integrada de dependências e tecnologias para o envio e recebimento de dados para / de tópicos de Kafka.
Kafka como um repositório de eventos:
- Se não houver problema com o espaço em disco, o Kafka pode armazenar todo o histórico de eventos, ou seja, um novo aplicativo pode ser implantado e fazer o download de todas as informações necessárias do diário. Registros de eventos que refletem completamente as características dos objetos podem ser compactados compilando o log, o que tornará essa abordagem mais justificada para muitos cenários.
- E se os eventos precisarem ser executados na ordem correta? Desde que os registros dos eventos sejam distribuídos corretamente, você pode definir a ordem da reprodução e aplicar filtros, ferramentas de conversão, etc., para que a reprodução dos dados sempre termine nas informações necessárias. Dependendo da possibilidade de distribuição dos dados, é possível garantir o processamento altamente paralelo na ordem correta.
- Uma alteração no modelo de dados pode ser necessária. Ao criar uma nova função de filtro / transformação, pode ser necessário reproduzir registros de todos os eventos ou eventos da semana passada.
As mensagens podem chegar ao Kafka não apenas a partir de aplicativos da sua organização que enviam mensagens sobre todas as alterações em suas características (ou os resultados dessas alterações), mas também de serviços de terceiros integrados ao seu sistema. Isso acontece das seguintes maneiras:
- Exportação, transferência, importação periódica de dados recebidos de serviços de terceiros e seu download para Kafka.
- Download de dados de serviços de terceiros em Kafka.
- Dados do CSV e outros formatos carregados de serviços de terceiros são carregados no Kafka.
Voltemos às perguntas que consideramos anteriormente. A arquitetura baseada em Kafka simplifica a distribuição de dados. Sabemos onde está a fonte da verdade, onde estão as fontes de dados e todos os aplicativos de destino trabalham com cópias derivadas desses dados. Os dados vão do remetente para os destinatários. Os dados de origem pertencem apenas ao remetente, mas outros são livres para trabalhar com suas projeções. Eles podem filtrar, transformar, complementá-los com dados de outras fontes, salvá-los em seus próprios bancos de dados.
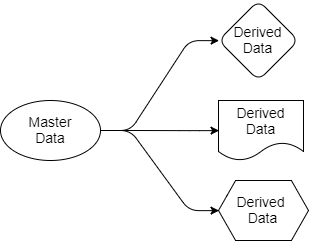
Fig 4. Dados de origem e saída
Todo aplicativo que precisar de dados de reserva e voo os receberá por si próprio, porque é "inscrito" nas seções do Kafka que contêm esses dados. Para esse aplicativo, eles podem usar SQL, Cypher, JSON ou qualquer outra linguagem de consulta. Um aplicativo pode salvar os dados em seu sistema como entender. O esquema de distribuição de dados pode ser alterado sem afetar a operação de outros aplicativos.
A questão pode surgir: por que tudo isso não pode ser feito usando o RabbitMQ? A resposta é que o RabbitMQ pode ser usado para processar eventos em tempo real, mas não como base para gerar eventos. O RabbitMQ é uma solução completa apenas para responder a eventos que estão acontecendo agora. Quando um novo aplicativo é adicionado e precisa de sua própria parte dos dados de reserva apresentados em um formato otimizado para as tarefas desse aplicativo, o RabbitMQ não poderá ajudar. Com o RabbitMQ, retornamos aos bancos de dados compartilhados ou à API REST.
Em segundo lugar, a ordem na qual os eventos são processados é importante. Se você trabalha com o RabbitMQ, ao adicionar um segundo destinatário à fila, a garantia de conformidade com o pedido é perdida. Assim, a ordem correta de envio de mensagens é observada apenas para um destinatário, mas isso, é claro, não é suficiente.
O Kafka, por outro lado, pode fornecer todos os dados que esse aplicativo precisa para criar sua própria cópia dos dados e mantê-los atualizados, enquanto o Kafka segue a ordem na qual as mensagens são enviadas.
Agora, de volta às arquiteturas centradas na API. Essas interfaces sempre serão a melhor escolha? Quando você deseja abrir o acesso a dados somente leitura, eu preferiria uma arquitetura emissora de eventos. Ele evitará falhas em cascata e reduzirá a vida útil associada a um aumento no número de dependências em outros serviços. Haverá mais oportunidades para a organização criativa e eficiente de dados nos sistemas. Mas, às vezes, você precisa alterar os dados de forma síncrona no sistema e em outro sistema e, em tal situação, os sistemas centrados em API serão úteis. Muitos os preferem a outros métodos assíncronos. Eu acho que isso é uma questão de gosto.
Alto tráfego e aplicativos sensíveis ao processamento de eventos.
Há pouco tempo, surgiu um problema com um dos receptores do RabbitMQ, que recebeu arquivos na fila de um serviço de terceiros. O tamanho total do arquivo era grande e o aplicativo foi configurado especificamente para receber esse volume de dados. O problema era que os dados chegavam inconsistentemente, isso criava muitos problemas.
Além disso, às vezes havia um problema no fato de, às vezes, dois arquivos serem destinados ao mesmo destino e a hora de chegada diferir por vários segundos. Ambos passaram pelo processamento e tiveram que ser carregados em um servidor. E depois que a segunda mensagem foi gravada no servidor, a primeira mensagem a seguir substitui a segunda. Assim, tudo terminou com o salvamento de dados inválidos. O RabbitMQ cumpriu seu papel e enviou mensagens na ordem correta, mas, mesmo assim, tudo acabou na ordem errada no próprio aplicativo.
Esse problema foi resolvido lendo o registro de data e hora dos registros existentes e a falta de resposta se a mensagem era antiga. Além disso, o hash consistente foi aplicado durante a troca de dados e a fila foi dividida, como na mesma partição na plataforma Kafka.
Como parte da partição, o Kafka armazena as mensagens na ordem em que foram enviadas a ela. A ordem das mensagens existe apenas dentro da partição. No exemplo acima, usando Kafka, tivemos que aplicar a função hash ao ID do destino para selecionar a partição desejada. Tivemos que criar um conjunto de partições, deveria haver mais do que o cliente exigia. A ordem do processamento de mensagens deveria ter sido alcançada devido ao fato de que cada partição é destinada a apenas um destinatário. Simples e eficaz.
O Kafka, comparado ao RabbitMQ, tem algumas vantagens associadas à divisão de mensagens usando o hash. Não há nada na plataforma RabbitMQ que evite conflitos de destinatário na mesma fila que é gerada como parte da troca de dados usando hash consistente. O RabbitMQ não ajuda a coordenar os destinatários para que apenas um destinatário de toda a fila use a mensagem. Kafka fornece tudo isso através do uso de grupos de destinatários e um nó coordenador. Isso permite que você garanta que apenas um destinatário da seção use a mensagem e que a ordem de processamento de dados seja garantida.
Localidade dos dados
Usando uma função hash para distribuir dados entre partições, o Kafka fornece localidade dos dados. Por exemplo, as mensagens do usuário com o ID 1001 devem sempre ir para o destinatário 3. Como os eventos do usuário 1001 sempre vão para o destinatário 3, o destinatário 3 pode efetivamente executar algumas operações que seriam muito mais difíceis se fosse necessário o acesso regular a um banco de dados externo ou outros sistemas para receber dados. Podemos ler dados, realizar agregações, etc. diretamente com informações na memória do destinatário. É nesse local que os aplicativos orientados a eventos e o fluxo de dados começam a se combinar.
Como o Kafka fornece a localidade dos dados? Para começar, é importante observar que o Kafka não permite aumentar e diminuir elasticamente o número de partições. Primeiro de tudo, você não pode reduzir o número de partições: se houver 10, não poderá reduzir o número para 9. Mas, por outro lado, isso não é necessário. Cada destinatário pode usar 1 ou várias partições, portanto, dificilmente é necessário reduzir seu número. A criação de partições adicionais no Kafka leva a um atraso no momento do reequilíbrio. Por isso, tentamos escalar o número de partições levando em consideração os picos de carga.
Mas se ainda precisarmos aumentar o número de partições e destinatários para poder escalar, precisaremos apenas de custos indiretos únicos se o reequilíbrio for necessário. Deve-se notar que, quando a escala de dados antigos permanece nas mesmas partições em que estavam. Porém, novas mensagens recebidas já serão roteadas de maneira diferente e novas partições começarão a receber novas mensagens. As mensagens do usuário 1001 agora podem ir para o destinatário 4 (porque os dados sobre o usuário 1001 estão agora em duas seções).
Além disso, iremos comparar e comparar a semântica de entrega das mensagens de entrega nos dois sistemas. O tópico rebalanceamento e particionamento merece um artigo separado, que discutiremos na próxima parte.