Python é incrível. Dizemos "instalação do pip" e provavelmente a biblioteca necessária será entregue. Mas às vezes a resposta será: "falha na compilação", porque existem módulos binários. Eles sofrem com algum tipo de dor em quase todas as linguagens modernas, porque há muitas arquiteturas, algo precisa ser montado para uma máquina específica, algo precisa estar vinculado a outras bibliotecas. Em geral, uma pergunta interessante, mas pouco estudada: como eles podem ser feitos e que problemas existem? Dmitry Zhiltsov (
zaabjuda ) tentou responder a essa pergunta no MoscowPython Conf no ano passado.
Abaixo do corte, está a versão em texto do relatório de Dmitry. Vamos pensar brevemente em quando os módulos binários são necessários e quando é melhor abandoná-los. Vamos discutir as regras que devem ser seguidas ao escrevê-las. Considere cinco opções de implementação possíveis:
- Extensão nativa C / C ++
- Swig
- Cython
- Ctypes
- Ferrugem
Sobre o palestrante : Dmitry Zhiltsov se desenvolve há mais de 10 anos. Ele trabalha na CIAN como arquiteto de sistemas, ou seja, é responsável por soluções técnicas e controle de tempo. Na minha vida, eu tentei o assembler, Haskell, C e, durante os últimos 5 anos, tenho programado ativamente em Python.
Sobre empresa
Muitos que vivem em Moscou e alugam moradias provavelmente conhecem o CIAN. CYAN é de 7 milhões de compradores e inquilinos por mês. Todos esses usuários todos os meses, usando nosso serviço, encontram um lugar para morar.
Cerca de 75% dos moscovitas conhecem nossa empresa, e isso é muito legal. Em São Petersburgo e Moscou, somos praticamente considerados monopolistas. No momento, estamos tentando entrar nas regiões e, portanto, o desenvolvimento cresceu 8 vezes nos últimos 3 anos. Isso significa que a equipe aumentou 8 vezes, a velocidade de entrega de valores ao usuário aumentou 8 vezes, ou seja, desde uma ideia de produto até como a mão de um engenheiro implementou uma construção para produção. Aprendemos em nossa grande equipe a desenvolver muito rapidamente e entender muito rapidamente o que está acontecendo no momento, mas hoje falaremos um pouco sobre outra coisa.
Vou falar sobre módulos binários. Agora, quase 50% das bibliotecas Python possuem algum tipo de módulo binário. E, como se viu, muitas pessoas não estão familiarizadas com elas e acreditam que isso é algo transcendental, algo sombrio e desnecessário. E outras pessoas sugerem escrever melhor um microsserviço separado e não usar módulos binários.
O artigo será composto de duas partes.
- Minha experiência: por que eles são necessários, quando são mais bem utilizados e quando não são.
- Ferramentas e tecnologias com as quais você pode implementar um módulo binário para Python.
Por que são necessários módulos binários?
Todos sabemos perfeitamente que Python é uma linguagem interpretada. É quase a mais rápida das linguagens interpretadas, mas, infelizmente, sua
velocidade nem sempre é suficiente para cálculos matemáticos pesados. Imediatamente surge o pensamento de que C será mais rápido.
Mas o Python tem mais uma dor - é o
GIL . Um grande número de artigos foi escrito sobre ele e foram feitos relatórios sobre como contorná-lo.
Também precisamos de extensões binárias para
reutilizar a lógica . Por exemplo, encontramos uma biblioteca que possui todas as funcionalidades de que precisamos e por que não usá-la. Ou seja, você não precisa reescrever o código, apenas pegamos o código finalizado e o reutilizamos.
Muitas pessoas acreditam que usando extensões binárias você pode
ocultar o código fonte . A questão é muito, muito controversa, é claro, com a ajuda de algumas perversões selvagens, isso pode ser alcançado, mas não há 100% de garantia. O máximo que você pode obter é não deixar o cliente descompilar e ver o que acontece no código que você passou.
Quando as extensões binárias são realmente necessárias?
Sobre velocidade e Python, é claro - quando alguma função funciona muito lentamente e ocupa 80% do tempo de execução de todo o código, começamos a pensar em escrever uma extensão binária. Mas, para tomar essas decisões, você precisa começar, como disse um famoso orador, pensar com seu cérebro.
Para escrever extensões de extensão, é preciso levar em consideração que isso, em primeiro lugar, será longo. Primeiro, você precisa "lamber" seus algoritmos, ou seja, veja se existem ombreiras.
Em 90% dos casos, após uma verificação completa do algoritmo, a necessidade de escrever algumas extensões desaparece.
O segundo caso em que as extensões binárias são realmente necessárias é o
uso de multiencadeamento para operações simples . Agora isso não é tão relevante, mas ainda permanece na empresa sangrenta, em alguns integradores de sistemas, onde o Python 2.6 ainda está escrito. Não há assincronia, e mesmo para coisas simples, por exemplo, ao enviar um monte de fotos, o multi-threading aumenta. Parece que inicialmente isso não incorre em nenhuma despesa de rede, mas quando carregamos a imagem no buffer, o mal-intencionado GIL chega e algum tipo de freio é iniciado. Como mostra a prática, essas coisas são melhor resolvidas usando bibliotecas das quais o Python não sabe nada.
Se você precisar implementar algum protocolo específico, pode ser conveniente criar um código C / C ++ simples e livrar-se de muita dor. Fiz isso no meu tempo em uma operadora de telecomunicações, já que não havia uma biblioteca pronta - tive que escrever sozinha. Mas repito, agora isso não é muito relevante, porque existe assíncio, e para a maioria das tarefas isso é suficiente.
Sobre
operações obviamente
difíceis, eu já disse com antecedência. Quando há falhas, matrizes grandes e similares, faz sentido que você precise fazer uma extensão para C / C ++. Quero observar que algumas pessoas pensam que não precisamos de extensões binárias aqui, é melhor fazer um microsserviço em alguma "
linguagem super rápida " e transferir matrizes enormes pela rede. Não, é melhor não fazer isso.
Outro bom exemplo de quando eles podem e devem ser tomados é quando você tem uma
lógica estabelecida do módulo . Se você já tem um módulo ou biblioteca Python em sua empresa há 3 anos, há alterações uma vez por ano e depois duas linhas, por que não transformá-lo em uma biblioteca C normal se houver tempo e recursos livres. No mínimo, obtenha um aumento de produtividade. E também haverá um entendimento de que, se algumas alterações cardinais forem necessárias na biblioteca, isso não é tão simples e, talvez, valha a pena pensar novamente com o cérebro e usar essa biblioteca de uma maneira diferente.
5 regras de ouro
Eu derivei essas regras na minha prática. Eles dizem respeito não apenas ao Python, mas também a outras linguagens para as quais você pode usar extensões binárias. Você pode discutir com eles, mas também pode pensar e trazer o seu.
- Somente funções de exportação . A construção de classes em Python em bibliotecas binárias consome bastante tempo: você precisa descrever muitas interfaces, revisar muita integridade de referência no próprio módulo. É mais fácil escrever uma pequena interface para a função.
- Use classes de wrapper . Alguns gostam muito de OOP e realmente querem aulas. De qualquer forma, mesmo que não sejam classes, é melhor escrever um wrapper Python: criar uma classe, definir um método de classe ou regular, chamar funções nativas de C / C ++. No mínimo, isso ajuda a manter a integridade da arquitetura de dados. Se você usar algum tipo de extensão de terceiros do C / C ++ que não possa ser corrigida, no invólucro poderá cortá-la para que tudo funcione.
- Você não pode passar argumentos do Python para uma extensão - isso nem é uma regra, mas um requisito. Em alguns casos, isso pode funcionar, mas geralmente é uma má idéia. Portanto, em seu código, você deve primeiro criar um manipulador que projete o tipo Python para o tipo C. E somente depois disso chamará qualquer função nativa que já funcione com os tipos s. O mesmo manipulador recebe uma resposta de uma função executável e a transforma em tipos de dados Python, e a lança no código Python.
- Leve em consideração a coleta de lixo . O Python possui um GC bem conhecido, e você não deve esquecê-lo. Por exemplo, passamos um grande pedaço de texto por referência e tentamos encontrar alguma palavra na biblioteca. Queremos paralelizar isso, passamos o link para essa área de memória e para o lançamento de vários threads. Nesse momento, o GC simplesmente pega e decide que nada mais se refere a esse objeto e o remove da área de memória. No mesmo código, obtemos apenas uma referência nula, e isso geralmente é uma falha de segmentação. Não devemos esquecer esse recurso do coletor de lixo e passar os tipos de dados mais simples para as bibliotecas de char: char, integer etc.
Por outro lado, o idioma em que a extensão está escrita pode ter seu próprio coletor de lixo. A combinação de Python e a biblioteca C # é uma dor nesse sentido.
- Defina explicitamente os argumentos da função exportada . Com isso, quero dizer que essas funções precisarão ser anotadas qualitativamente. Se aceitarmos a função PyObject, e em qualquer caso a aceitarmos em nossa biblioteca, precisaremos indicar explicitamente quais argumentos pertencem a quais tipos. Isso é útil porque se passarmos o tipo de dados errado, obteremos um erro na biblioteca. Ou seja, você precisa para sua conveniência.
Arquitetura de extensão binária

Na verdade, não há nada complicado na arquitetura de extensões binárias. Existe o Python, existe uma função de chamada que chega a um invólucro que chama nativamente o código. Essa chamada, por sua vez, se baseia em uma função que é exportada para Python e que pode ser chamada diretamente. É nessa função que você precisa converter tipos de dados para tipos de dados do seu idioma. E somente depois que essa função nos traduz tudo, chamamos a função nativa, que faz a lógica principal, retorna o resultado na direção oposta e o lança no Python, convertendo os tipos de dados de volta.
Tecnologia e Ferramentas
A maneira mais famosa de escrever extensões binárias é a extensão Native C / C ++. Só porque é a tecnologia Python padrão.
Extensão nativa C / C ++
O próprio Python é implementado em C, e os métodos e estruturas do python.h são usados para escrever extensões. A propósito, isso também é bom porque é muito fácil implementá-lo em um projeto existente. Basta especificar xt_modules em setup.py e dizer que, para construir o projeto, você precisa compilar essas fontes com esses sinalizadores de compilação. Abaixo está um exemplo.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
Prós da extensão nativa C / C ++
- Tecnologia nativa.
- É facilmente integrado à montagem do projeto.
- A maior quantidade de documentação.
- Permite criar seus próprios tipos de dados.
Contras da extensão C / C ++ nativa
- Limite de entrada alto.
- É necessário conhecimento de C.
- Boost.Python.
- Falha na segmentação.
- Dificuldades na depuração.
De acordo com essa tecnologia, uma enorme quantidade de documentação é gravada, tanto em publicações padrão quanto em blogs. Uma grande vantagem é que podemos criar nossos próprios tipos de dados Python e construir nossas classes.
Essa abordagem tem grandes desvantagens. Primeiro, é o limite de entrada - nem todo mundo sabe C o suficiente para codificar para produção. Você precisa entender que, para isso, não basta ler o livro e executar para escrever extensões nativas. Se você quiser fazer isso, então: primeiro, aprenda C; então comece a escrever utilitários de comando; somente depois disso, continue escrevendo extensões.
O Boost.Python é muito bom para C ++, permite abstrair quase completamente todos esses wrappers que usamos no Python. Mas o menos, eu acho, é que você precisa suar muito para tomar parte dele e importá-lo para o projeto sem baixar o Boost inteiro.
Listando as dificuldades na depuração nos pontos negativos, quero dizer que agora todos estão acostumados a usar um depurador gráfico e, com módulos binários, isso não funciona. Provavelmente você precisa instalar o GDB com um plug-in para Python.
Vejamos um exemplo de como criamos isso.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
Para começar, incluímos os arquivos de cabeçalho Python. Depois disso, descrevemos a função addList_add que o Python usará. O mais importante é nomear a função corretamente; nesse caso, addList é o nome do módulo, _add é o nome da função que será usada no Python. Passamos o próprio módulo PyObject e passamos os argumentos usando o PyObject também. Depois disso, realizamos verificações padrão. Nesse caso, estamos tentando analisar o argumento da tupla e dizer que é um objeto - o literal "O" deve ser especificado explicitamente. Depois disso, sabemos que passamos listObj como um objeto e tentamos descobrir seu comprimento usando métodos padrão do Python: PyList_Size. Observe que aqui ainda não podemos usar chamadas para descobrir a duração desse vetor, mas usar a funcionalidade Python. Nós omitimos a implementação, após a qual é necessário retornar todos os valores de volta ao Python. Para fazer isso, chame Py_BuildValue, especifique qual tipo de dados estamos retornando; neste caso, "i" é um número inteiro e a própria variável sum.
Nesse caso, todos entendem - encontramos a soma de todos os elementos da lista. Vamos um pouco mais longe.
for(i = 0; i< length; i++){
É a mesma coisa: no momento, listObj é um objeto Python. E, neste caso, estamos tentando pegar os itens da lista. Python.h tem tudo o que você precisa para isso.
Depois que temos temperatura, tentamos prolongá-la por muito tempo. E somente depois disso você pode fazer algo em C.
Depois de implementarmos toda a função, é necessário escrever a documentação.
A documentação é sempre boa , e este kit de ferramentas tem tudo para uma manutenção conveniente. Após a convenção de nomenclatura, nomeamos o módulo addList_docs e salvamos a descrição lá. Agora você precisa registrar o módulo, para isso existe uma estrutura especial PyMethodDef. Descrevendo as propriedades, dizemos que a função é exportada para Python com o nome "add", que essa função chama PyCFunction. METH_VARARGS significa que uma função pode potencialmente levar qualquer número de variáveis. Também escrevemos linhas adicionais e descrevemos uma verificação padrão, caso apenas importássemos o módulo, mas não usássemos nenhum método para que não caísse.
Depois que anunciamos tudo isso, tentamos fazer um módulo. Criamos um moduledef e colocamos tudo o que fizemos lá.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT é uma constante padrão do Python que você deve sempre usar. -1 indica que nenhuma memória adicional precisa ser alocada no estágio de importação.
Quando criamos o próprio módulo, precisamos inicializá-lo. O Python está sempre procurando init, portanto, crie um PyInit_addList para addList. Agora, a partir da estrutura montada, você pode chamar PyModule_Create e, finalmente, criar o próprio módulo. Em seguida, adicione as meta-informações e retorne o próprio módulo.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
Como você já notou, há muitas coisas a serem transformadas. Você deve sempre se lembrar do Python quando escrevermos em C / C ++.
Por isso, para facilitar a vida de um programador mortal comum, há cerca de 15 anos, a tecnologia SWIG apareceu.
Swig
Essa ferramenta permite abstrair das ligações do Python e escrever código nativo. Tem os mesmos prós e contras que o C / C ++ nativo, mas há exceções.
Profissionais do SWIG:
- Tecnologia estável.
- Uma grande quantidade de documentação.
- Resumos da ligação ao Python.
Contras de SWIG:
- Configuração longa.
- Conhecimento C.
- Falha na segmentação.
- Dificuldades na depuração.
- A complexidade da integração na montagem do projeto.
O primeiro ponto negativo é que,
enquanto você o configura, você perde a cabeça . Quando o configurei pela primeira vez, passei um dia e meio para lançá-lo. Então, é claro, é mais fácil. O SWIG 3.x se tornou mais fácil.
Para não entrar mais no código, considere o esquema geral do SWIG.
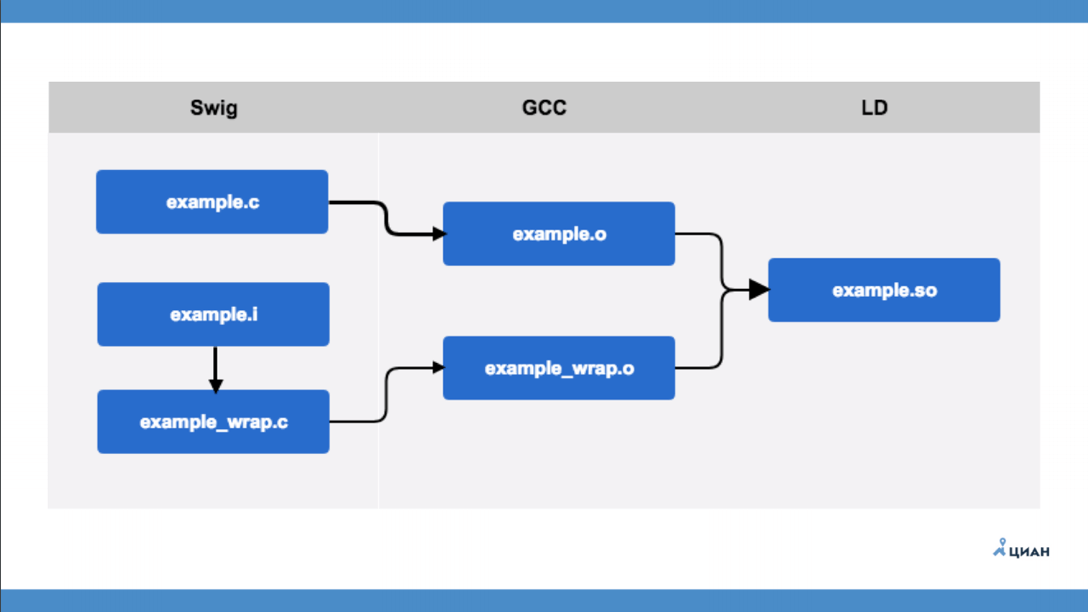
example.c é um módulo C que não sabe nada sobre Python. Há um arquivo de interface example.i, descrito no formato SWIG. Depois disso, execute o utilitário SWIG, que cria example_wrap.c a partir do arquivo de interface - este é o mesmo wrapper que costumávamos fazer com nossas mãos. Ou seja, o SWIG apenas cria um invólucro de arquivo para nós, a chamada ponte. Depois disso, usando o GCC, compilamos dois arquivos e obtemos dois arquivos de objeto (example.o e example_wrap.o) e somente então criamos nossa biblioteca. Tudo é simples e claro.
Cython
Andrey Svetlov fez um excelente
relatório no Moscow Python Conf, então vou apenas dizer que esta é uma tecnologia popular com boa documentação.
Prós Cython:
- Tecnologia popular.
- Bastante estável.
- É facilmente integrado à montagem do projeto.
- Boa documentação.
Contras do Cython:
- Sintaxe própria.
- Conhecimento C.
- Falha na segmentação.
- Dificuldades na depuração.
Contras, como sempre, é. A principal é a sua própria sintaxe, que é semelhante ao C / C ++, e muito ao Python.
Mas quero ressaltar que o código Python pode ser acelerado usando o Cython escrevendo código nativo.

Como você pode ver, há muitos decoradores, e isso não é muito bom. Se você deseja usar o Cython - consulte o relatório de Andrei Svetlov.
CTypes
CTypes é a biblioteca Python padrão que funciona com a Interface de Função Estrangeira. FFI é uma biblioteca de baixo nível. Esta é uma tecnologia nativa, é muito usada em código, com sua ajuda, é fácil de implementar entre plataformas.
Mas o FFI carrega muita sobrecarga porque todas as pontes, todos os manipuladores em tempo de execução são criados dinamicamente. Ou seja, carregamos a biblioteca dinâmica e, atualmente, o Python não sabe o que é a biblioteca. Somente quando uma biblioteca é chamada na memória essas pontes são construídas dinamicamente.
Prós de CTypes:
- Tecnologia nativa.
- Fácil de usar no código.
- Fácil de implementar em várias plataformas.
- Você pode usar quase qualquer idioma.
Contras CTypes:
- Carrega em cima.
- Dificuldades na depuração.
from ctypes import *
Eles pegaram adder.so e o chamaram em tempo de execução. Podemos até passar em tipos nativos de Python.
Depois de tudo isso, a pergunta é: "De alguma forma é complicado, em todo lugar C, o que fazer?".
Ferrugem
Ao mesmo tempo, não dei a devida atenção ao idioma, mas agora praticamente me volto a ele.
Profissionais da ferrugem:
- Linguagem segura.
- Poderosas garantias estáticas de comportamento correto.
- Integra-se facilmente às construções do projeto ( PyO3 ).
Contras de ferrugem:
- Limite de entrada alto.
- Configuração longa.
- Dificuldades na depuração.
- Há pouca documentação.
- Em alguns casos, sobrecarga.
Ferrugem é uma linguagem segura com prova automática de trabalho. A própria sintaxe e o pré-processador de linguagem não permitem que um erro explícito seja cometido. Ao mesmo tempo, concentra-se na variabilidade, ou seja, deve processar qualquer resultado da execução da ramificação de código.
Graças à equipe do PyO3, existem bons binders do Python para o Rust e ferramentas para integração no projeto.
Por outro lado, considero que, para um programador despreparado, leva muito tempo para configurá-lo. Pouca documentação, mas em vez de contras, não temos uma falha de segmentação. No Rust, em um bom sentido, em 99% dos casos, um programador pode obter uma falha de segmentação apenas se ele indicar explicitamente desembrulhar e apenas pontuar.
Um pequeno exemplo de código, o mesmo módulo que examinamos anteriormente.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
O código tem uma sintaxe específica, mas você se acostuma muito rapidamente. De fato, tudo é o mesmo aqui. Usando macros, fazemos modinit, que, para nós, faz todo o trabalho adicional de gerar todos os tipos de ligantes para Python. Lembre-se de que eu disse, você precisa fazer um wrapper de manipulador, aqui está o mesmo. run_py converte tipos, então chamamos o código nativo.
Como você pode ver, para exportar alguma função, há açúcar sintático. Apenas dizemos que precisamos da função add e não descrevemos nenhuma interface. Aceitamos list, que é exatamente py_list, não Object, porque o próprio Rust configurará os binders necessários no momento da compilação. Se passarmos o tipo de dados errado, como nas extensões, um TypeError ocorrerá. Depois que chegamos à lista, começamos a processá-la.
Vamos ver com mais detalhes o que ele está começando a fazer.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
O mesmo código que estava em C / C ++ / Ctypes, mas apenas em Rust. Lá, tentei converter o PyObject por algum tempo. O que aconteceria se listássemos, com exceção dos números, obteríamos uma string? Sim, obteríamos um SystemEerror. Nesse caso, através de
let mut sum
: i32 = 0; também estamos tentando obter um valor da lista e convertê-lo para i32. Ou seja, não conseguiremos escrever esse código sem item.extract (), inconscientemente e convertido para o tipo desejado. Quando escrevemos o i32, no caso de um erro de Ferrugem, no estágio de compilação, ele diz: “Manuseie o caso quando não o i32”. Nesse caso, se tivermos i32, retornamos um valor, se for um erro, lançamos uma exceção.
O que escolher
Após esse breve passeio, pensaremos sobre o que escolher no final?
A resposta é realmente o seu gosto e cor.
Não promoverei nenhuma tecnologia específica.

Apenas resuma o que foi dito:
- No caso de SWIG e C / C ++, você precisa conhecer muito bem o C / C ++, entender que o desenvolvimento deste módulo implicará em alguma sobrecarga adicional. Mas um mínimo de ferramentas será usado, e trabalharemos na tecnologia nativa do Python, que é suportada pelos desenvolvedores.
- No caso do Cython, temos um pequeno limiar de entrada, uma alta velocidade de desenvolvimento e esse também é um gerador de código comum.
- À custa dos CTypes, quero alertá-lo sobre a sobrecarga relativamente grande. O carregamento dinâmico da biblioteca, quando não sabemos que tipo de biblioteca é, pode causar muitos problemas.
- Eu aconselho o Rust a levar alguém que não conhece bem o C / C ++. A ferrugem na produção realmente traz menos problemas.
Chamada de trabalhos
Aceitamos aplicativos para Moscow Python Conf ++ até 7 de setembro - escreva desta forma simples que você conhece sobre Python e que realmente precisa compartilhar com a comunidade.
Para aqueles que estão mais interessados em ouvir, posso falar sobre relatórios interessantes.
- Donald Whyte adora falar sobre a aceleração da matemática em Python e está preparando uma nova história para nós: como tornar a matemática 10 vezes mais rápida usando bibliotecas populares, truques e insidiosidade, e o código é claro e suportado.
- Artyom Malyshev reuniu todos os seus muitos anos de experiência no desenvolvimento do Django e está apresentando um guia de relatórios sobre o framework! Tudo o que acontece entre receber uma solicitação HTTP e enviar uma página da Web finalizada: expor magia, um mapa dos mecanismos internos da estrutura e muitas dicas úteis para seus projetos.