Se você conhece C #, provavelmente sabe que sempre deve substituir
Equals e
GetHashCode para evitar a
GetHashCode desempenho. Mas o que acontecerá se isso não for feito? Hoje, comparamos o desempenho com duas opções de ajuste e consideramos ferramentas para ajudar a evitar erros.

Quão sério é esse problema?
Nem todo problema de desempenho potencial afeta o tempo de execução do aplicativo. O método
Enum.HasFlag não
Enum.HasFlag muito eficiente (*), mas se você não o usar em um trecho de código que
Enum.HasFlag muitos recursos, não haverá problemas sérios no projeto. Esse também é o caso de
cópias protegidas criadas por tipos de estrutura não somente leitura no contexto somente leitura. O problema existe, mas é improvável que seja perceptível em aplicativos comuns.
(*) Corrigido no .NET Core 2.1 e, como mencionei em uma publicação anterior , agora as consequências podem ser atenuadas usando o HasFlag auto-configurado para versões mais antigas.Mas o problema sobre o qual falaremos hoje é especial. Se os métodos
Equals e
GetHashCode não forem criados na estrutura, suas versões padrão de
System.ValueType . E eles podem reduzir significativamente o desempenho do aplicativo final.
Por que as versões padrão são lentas?
Os autores do CLR fizeram o possível para tornar as versões padrão do Equals e GetHashCode o mais eficientes possível para os tipos de valor. Mas há várias razões pelas quais esses métodos perdem a eficácia da versão do usuário, escrita para um determinado tipo manualmente (ou gerada pelo compilador).
1. Distribuição da conversão de embalagens. O CLR é projetado de maneira que todas as chamadas para um elemento definido nos tipos
System.ValueType ou
System.Enum disparam uma transformação de empacotamento (**).
(**) Se o método não suportar a compilação JIT. Por exemplo, no Core CLR 2.1, o compilador JIT reconhece o método Enum.HasFlag e gera código adequado que não inicia a quebra.2. Conflitos potenciais na versão padrão do método
GetHashCode . Ao implementar uma função hash, enfrentamos um dilema: tornar a distribuição da função hash boa ou rápida. Em alguns casos, você pode fazer as duas coisas, mas no tipo
ValueType.GetHashCode , isso geralmente é difícil.
Uma função tradicional de hash do tipo struct "combina" os códigos de hash de todos os campos. Mas a única maneira de obter o código hash do campo no método
ValueType é usar a reflexão. É por isso que os autores do CLR decidiram sacrificar a velocidade por causa da distribuição, e a versão padrão do
GetHashCode retorna apenas o código de hash do primeiro campo diferente de zero e o
"estraga" com o identificador de tipo (***) (para obter mais detalhes, consulte
RegularGetValueTypeHashCode no repositório coreclr no github).
(***) A julgar pelos comentários no repositório CoreCLR, a situação pode mudar no futuro. public readonly struct Location { public string Path { get; } public int Position { get; } public Location(string path, int position) => (Path, Position) = (path, position); } var hash1 = new Location(path: "", position: 42).GetHashCode(); var hash2 = new Location(path: "", position: 1).GetHashCode(); var hash3 = new Location(path: "1", position: 42).GetHashCode();
Este é um algoritmo razoável até que algo dê errado. Mas se você não tiver sorte e o valor do primeiro campo do seu tipo de estrutura for o mesmo na maioria dos casos, a função hash sempre produzirá o mesmo resultado. Como você deve ter adivinhado, se você salvar essas instâncias em um conjunto de hash ou tabela de hash, o desempenho cairá.
3. A velocidade de implementação baseada na reflexão é baixa. Muito baixo A reflexão é uma ferramenta poderosa se usada corretamente. Mas as consequências serão terríveis se você executá-lo em um pedaço de código que consome muitos recursos.
Vamos ver como uma função hash com falha, que pode resultar de (2) e implementação baseada em reflexão, afeta o desempenho:
public readonly struct Location1 { public string Path { get; } public int Position { get; } public Location1(string path, int position) => (Path, Position) = (path, position); } public readonly struct Location2 {
Method | NumOfElements | Mean | Gen 0 | Allocated | -------------------------------- |------ |--------------:|--------:|----------:| Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B | Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B | Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B | Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B | Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B | Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B |
Se o valor do primeiro campo for sempre o mesmo, por padrão, a função hash retornará um valor igual para todos os elementos e o conjunto de hash será efetivamente convertido em uma lista vinculada com operações de inserção e pesquisa de O (N). O número de operações para preencher a coleção se torna O (N ^ 2) (onde N é o número de inserções com complexidade O (N) para cada inserção). Isso significa que a inserção em um conjunto de 1000 elementos renderá quase 500.000 chamadas para
ValueType.Equals . Aqui estão as consequências de um método usando reflexão!
Como mostra o teste, o desempenho será aceitável se você tiver sorte e o primeiro elemento da estrutura for único (no caso de
Position_Path_DefaultEquality ). Mas se não for assim, a produtividade será extremamente baixa.
Problema real
Acho que agora você pode adivinhar o problema que encontrei recentemente. Há algumas semanas, recebi uma mensagem de erro: o tempo de execução do aplicativo em que estou trabalhando aumentou de 10 para 60 segundos. Felizmente, o relatório foi muito detalhado e continha um rastreamento de eventos do Windows; portanto, o local do problema foi descoberto rapidamente - o
ValueType.Equals carregou 50 segundos.
Após uma rápida olhada no código, ficou claro qual era o problema:
private readonly HashSet<(ErrorLocation, int)> _locationsWithHitCount; readonly struct ErrorLocation {
Eu usei uma tupla que continha um tipo de estrutura personalizado com a versão padrão do
Equals . E, infelizmente, tinha um primeiro campo opcional, que quase sempre era igual a
String.equals . A produtividade permaneceu alta até o número de elementos no conjunto aumentar significativamente. Em questão de minutos, uma coleção com dezenas de milhares de elementos foi inicializada.
A implementação padrão ValueType.Equals/GetHashCode sempre em execução lenta?
ValueType.Equals e
ValueType.GetHashCode têm métodos especiais de otimização. Se o tipo não tiver "ponteiros" e estiver compactado corretamente (mostrarei um exemplo em um minuto), serão usadas versões otimizadas: iterações
GetHashCode são executadas em blocos de instância, é usado XOR de 4 bytes, o método
Equals compara duas instâncias usando o
memcmp .
A verificação em si é realizada em
ValueTypeHelper::CanCompareBits , é chamada tanto da iteração de
ValueType.Equals quanto da iteração de
ValueType.GetHashCode .
Mas a otimização é uma coisa muito insidiosa.
Em primeiro lugar, é difícil entender quando está ligado; mesmo pequenas alterações no código podem ativá-lo e desativá-lo:
public struct Case1 {
Para obter mais informações sobre a estrutura da memória, consulte o meu blog,
"Elementos internos de um objeto gerenciado, parte 4. Estrutura do campo" .
Em segundo lugar, comparar a memória não fornece necessariamente o resultado correto. Aqui está um exemplo simples:
public struct MyDouble { public double Value { get; } public MyDouble(double value) => Value = value; } double d1 = -0.0; double d2 = +0.0;
-0,0 e
+0,0 são iguais, mas têm diferentes representações binárias. Isso significa que
Double.Equals é true e
MyDouble.Equals é false. Na maioria dos casos, a diferença não é significativa, mas imagine quantas horas você gastará corrigindo o problema causado por essa diferença.
Como evitar um problema semelhante?
Você pode me perguntar como isso pode acontecer em uma situação real? Uma maneira óbvia de executar os métodos
Equals e
GetHashCode nos tipos de estrutura é usar a
regra FxCop
CA1815 . Mas há um problema: essa é uma abordagem muito estrita.
Um aplicativo para o qual o desempenho é crítico pode ter centenas de tipos de estrutura que não são necessariamente usados em conjuntos de hash ou dicionários. Portanto, os desenvolvedores de aplicativos podem desativar a regra, o que causará conseqüências desagradáveis se o tipo de estrutura usar funções modificadas.
Uma abordagem mais correta é avisar o desenvolvedor se a estrutura do tipo "inadequado" com valores padrão iguais de elementos (definidos no aplicativo ou em uma biblioteca de terceiros) é armazenada em um conjunto de hash. Claro que estou falando do
ErrorProne.NET e da regra que adicionei lá assim que me deparei com este problema:

A versão ErrorProne.NET não é perfeita e "culpará" o código correto se um resolvedor de igualdade personalizado for usado no construtor:
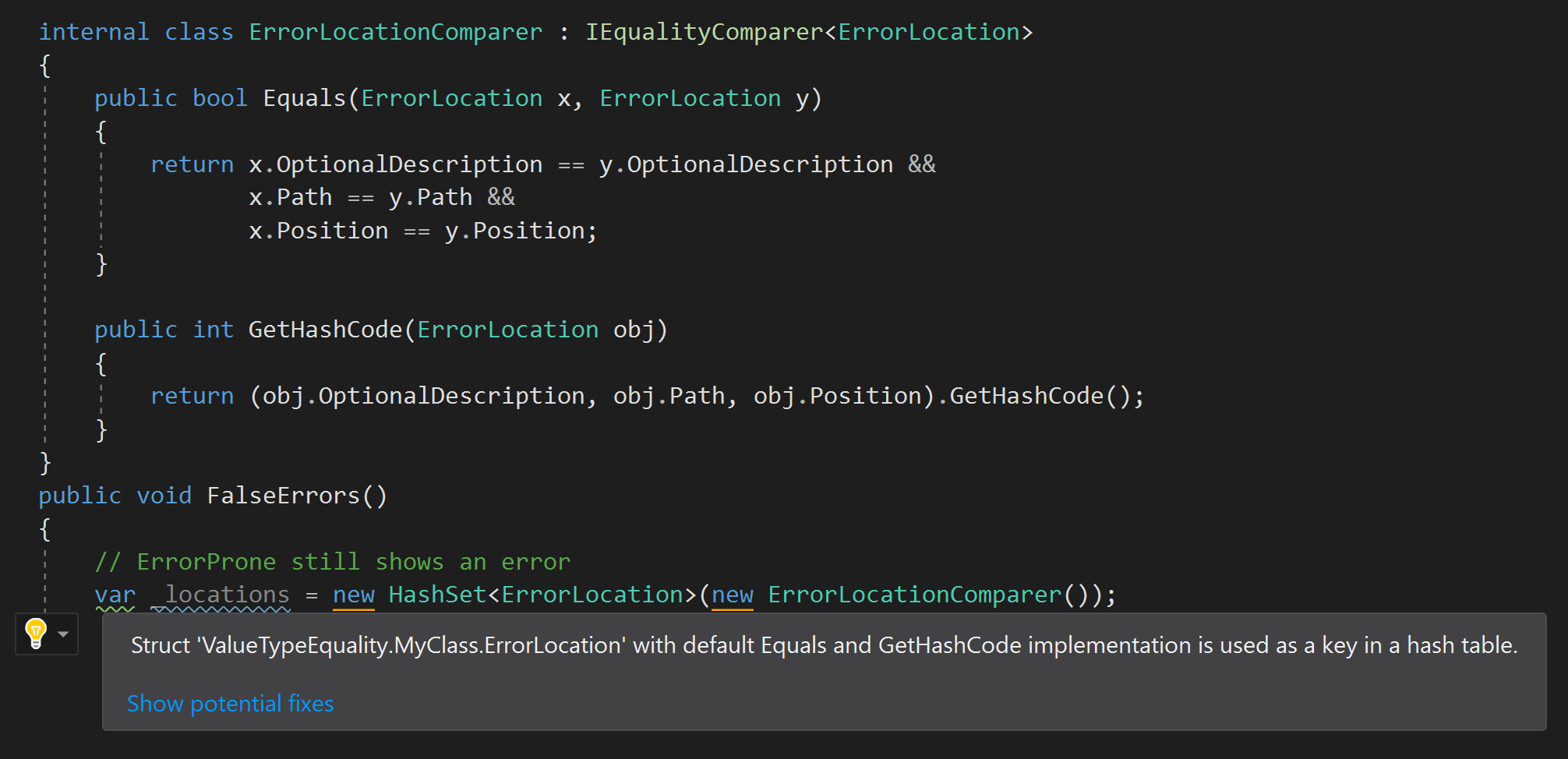
Mas ainda acho que vale a pena avisar se uma estrutura com elementos iguais por padrão não for usada quando estiver sendo produzida. Por exemplo, quando verifiquei minha regra, percebi que a estrutura
System.Collections.Generic.KeyValuePair <TKey, TValue> definida no mscorlib não substitui
Equals e
GetHashCode . É improvável que alguém defina uma variável como
HashSet <KeyValuePair<string, int>> hoje, mas acredito que mesmo o BCL pode violar a regra. Portanto, é útil descobrir isso antes que seja tarde demais.
Conclusão
- A implementação da igualdade padrão para os tipos de estrutura pode ter sérias conseqüências para seu aplicativo. Este é um problema real, não teórico.
- Os elementos de igualdade padrão para os tipos de valor são baseados na reflexão.
- A distribuição executada pela versão padrão do
GetHashCode ficará muito ruim se o primeiro campo de muitas instâncias tiver o mesmo valor. - Existem versões otimizadas para os métodos
Equals e GetHashCode padrão, mas você não deve confiar neles, pois mesmo uma pequena alteração no código pode desativá-los. - Use a regra FxCop para garantir que cada tipo de estrutura substitua os elementos de igualdade. No entanto, é melhor evitar o problema com o analisador se a estrutura “inadequada” estiver armazenada em um conjunto de hash ou em uma tabela de hash.
Recursos Adicionais