Olá Habr! Mais recentemente, falamos
brevemente sobre interfaces de linguagem natural. Bem, hoje não temos brevemente. Abaixo, você encontrará uma história completa sobre a criação do NL2API para a Web-API. Nossos colegas da Research tentaram uma abordagem única para coletar dados de treinamento para a estrutura. Inscreva-se agora!

Anotação
À medida que a Internet evolui para uma arquitetura orientada a serviços, as interfaces de software (APIs) estão se tornando cada vez mais importantes como forma de fornecer acesso a dados, serviços e dispositivos. Estamos trabalhando na questão da criação de uma interface de linguagem natural para a API (NL2API), com foco em serviços da web. As soluções NL2API têm muitos benefícios em potencial, por exemplo, ajudando a simplificar a integração de serviços da Web em assistentes virtuais.
Oferecemos a primeira plataforma abrangente (estrutura) que permite criar NL2API para uma API da web específica. A principal tarefa é coletar dados para treinamento, ou seja, os pares "comando NL - chamada de API", permitindo que o NL2API estude a semântica de ambos os comandos NL que não possuem um formato estritamente definido e chamadas formalizadas à API. Oferecemos nossa própria abordagem exclusiva para coletar dados de treinamento para NL2API usando crowdsourcing - atraindo muitos trabalhadores remotos para gerar várias equipes de NL. Otimizamos o próprio processo de crowdsourcing para reduzir custos.
Em particular, oferecemos um modelo probabilístico hierárquico fundamentalmente novo que nos ajudará a distribuir o orçamento para crowdsourcing, principalmente entre as chamadas de API de alto valor para o aprendizado da NL2API. Aplicamos nossa estrutura a APIs reais e mostramos que ela permite coletar dados de treinamento de alta qualidade a um custo mínimo, além de criar NL2API de alto desempenho a partir do zero. Também demonstramos que nosso modelo de crowdsourcing melhora a eficiência desse processo, ou seja, os dados de treinamento coletados em sua estrutura fornecem um desempenho mais alto de NL2API, o que excede significativamente a linha de base.
1. Introdução
As interfaces de programação de aplicativos (APIs) estão desempenhando um papel cada vez mais importante no mundo virtual e físico, graças ao desenvolvimento de tecnologias como arquitetura orientada a serviços (SOA), computação em nuvem e Internet das Coisas (IoT). Por exemplo, os serviços web hospedados na nuvem (clima, esportes, finanças, etc.) por meio da API da web fornecem dados e serviços aos usuários finais, e os dispositivos IoT permitem que outros dispositivos de rede usem suas funcionalidades.
 Figura 1. Os pares “comando NL (esquerda) e chamada de API (direita)” reunidos
Figura 1. Os pares “comando NL (esquerda) e chamada de API (direita)” reunidos
nossa estrutura e comparação com o IFTTT. GET-Messages e GET-Events são duas APIs da web para localizar emails e eventos de calendário, respectivamente. A API pode ser chamada com vários parâmetros. Nós nos concentramos em chamadas de API totalmente parametrizadas, enquanto o IFTTT é limitado a APIs com parâmetros simples.Normalmente, as APIs são usadas em uma variedade de software: aplicativos de desktop, sites e aplicativos móveis. Eles também atendem aos usuários por meio de uma interface gráfica do usuário (GUI). A GUI fez uma grande contribuição para a popularização dos computadores, mas, à medida que a tecnologia de computadores evoluiu, suas muitas limitações se manifestam cada vez mais. Por um lado, à medida que os dispositivos se tornam menores, mais móveis e inteligentes, os requisitos para exibição gráfica na tela aumentam constantemente, por exemplo, no que diz respeito a dispositivos portáteis ou dispositivos conectados à IoT.
Por outro lado, os usuários precisam se adaptar a várias GUIs especializadas para vários serviços e dispositivos. À medida que o número de serviços e dispositivos disponíveis aumenta, o custo do treinamento e da adaptação do usuário também aumenta. As interfaces de linguagem natural (NLIs), como os assistentes virtuais Apple Siri e Microsoft Cortana, também chamadas de interfaces de conversação ou de diálogo (CUIs), demonstram um potencial significativo como uma ferramenta inteligente única para uma ampla gama de serviços e dispositivos de servidor.
Neste artigo, consideramos o problema de criar uma interface de linguagem natural para a API (NL2API). Mas, diferentemente dos assistentes virtuais, esses não são NLIs de uso geral,
estamos desenvolvendo abordagens para criar NLIs para APIs da web específicas, ou seja, APIs de serviços da web, como o serviço multiesporte ESPN1. Esses NL2APIs podem resolver o problema de escalabilidade dos NLIs de uso geral, permitindo o desenvolvimento distribuído. A utilidade de um assistente virtual depende em grande parte da amplitude de seus recursos, ou seja, do número de serviços que ele suporta.
No entanto, integrar serviços da Web em um assistente virtual, um de cada vez, é um trabalho incrivelmente minucioso. Se os provedores de serviços da web individuais tivessem uma maneira barata de criar NLIs para suas APIs, os custos de integração seriam significativamente reduzidos. Um assistente virtual não precisaria processar interfaces diferentes para diferentes serviços da web. Seria o suficiente para ele simplesmente integrar NL2APIs individuais, que alcançam uniformidade graças à linguagem natural. Por outro lado, o NL2API também pode simplificar a descoberta de serviços da Web e sistemas de recomendação e assistência de programação para APIs, eliminando a necessidade de lembrar o grande número de APIs da Web disponíveis e sua sintaxe.
Exemplo 1. Dois exemplos são mostrados na Figura 1. A API pode ser chamada com vários parâmetros. No caso da API de pesquisa de email, os usuários podem filtrar email por propriedades específicas ou procurar emails por palavras-chave. A principal tarefa do NL2API é mapear comandos NL para as chamadas de API correspondentes.
Desafio. A coleta de dados de treinamento é uma das tarefas mais importantes associadas à pesquisa no desenvolvimento de interfaces NLI e sua aplicação prática. As NLIs usam dados de treinamento controlados, que no caso da NL2API consistem em pares de "comando NL - chamada de API" para estudar a semântica e mapear inequivocamente os comandos NL para as representações formalizadas correspondentes. A linguagem natural é muito flexível, para que os usuários possam descrever a chamada à API de maneiras sintaticamente diferentes, ou seja, a parafraseando ocorre.
Considere o segundo exemplo na Figura 1. Os usuários podem reformular esta pergunta da seguinte maneira: “Onde será a próxima reunião” ou “Encontre um local para a próxima reunião”. Portanto, é extremamente importante coletar dados de treinamento suficientes para que o sistema reconheça ainda mais essas opções. Os NLIs existentes geralmente aderem ao princípio "melhor possível" na coleta de dados. Por exemplo, o análogo mais próximo de nossa metodologia para comparar comandos NL com chamadas de API usa o conceito de IF-This-Then-That (IFTTT) - "se for, então" (Figura 1). Os dados de treinamento vêm diretamente do site da IFTTT.
No entanto, se a API não for suportada ou não for totalmente suportada, não há como corrigir a situação. Além disso, os dados de treinamento coletados dessa maneira não são aplicáveis ao suporte a comandos avançados com vários parâmetros. Por exemplo, analisamos os logs de chamadas anonimizados da API da Microsoft para procurar e-mails para o mês e descobrimos que cerca de 90% deles usam dois ou três parâmetros (aproximadamente a mesma quantidade), e esses parâmetros são bastante diversos. Portanto, nos esforçamos para fornecer suporte completo à parametrização de API e implementar comandos avançados de NL. O problema de implantar um processo ativo e personalizável de coleta de dados de treinamento para uma API específica atualmente permanece sem solução.
Os problemas do uso do NLI em combinação com outras representações formalizadas, como bancos de dados relacionais, bases de conhecimento e tabelas da web, foram bem trabalhados, embora quase nenhuma atenção tenha sido dada ao desenvolvimento do NLI para APIs da web. Oferecemos a primeira plataforma abrangente (estrutura) que permite criar NL2API para uma API da web específica do zero. Na implementação da API da web, nossa estrutura inclui três estágios: (1) Apresentação. O formato original da API da web HTTP contém muitos detalhes redundantes e, portanto, perturbadores do ponto de vista da NLI.
Sugerimos o uso de uma representação semântica intermediária para a API da Web, para não sobrecarregar o NLI com informações desnecessárias. (2) Um conjunto de dados de treinamento. Oferecemos uma nova abordagem para obter dados de treinamento controlados com base no crowdsourcing. (3) NL2API. Também oferecemos dois modelos NL2API: um modelo de extração baseado em linguagem e um modelo de rede neural recorrente (Seq2Seq).
Um dos principais resultados técnicos deste trabalho é uma abordagem fundamentalmente nova para a coleta ativa de dados de treinamento para NL2API com base em crowdsourcing - usamos executivos remotos para anotar chamadas de API ao compará-las com comandos de NL. Isso permite que você alcance três objetivos de design, fornecendo: (1) Personalização. Você deve poder especificar quais parâmetros para qual API usar e quantos dados de treinamento coletar. (2) baixo custo. Os serviços dos trabalhadores de crowdsourcing são uma ordem de magnitude mais barata que os serviços de especialistas especializados, e é por isso que eles devem ser contratados. (3) de alta qualidade. A qualidade dos dados de treinamento não deve ser reduzida.
Ao projetar essa abordagem, dois problemas principais surgem. Primeiro, as chamadas de API com parametrização avançada, como na Figura 1, são incompreensíveis para o usuário médio; portanto, você precisa decidir como formular o problema da anotação para que os funcionários do crowdsourcing possam lidar com ele facilmente. Começamos desenvolvendo uma representação semântica intermediária para a API da web (consulte a seção 2.2), o que nos permite gerar chamadas de API com os parâmetros necessários.
Depois, pensamos na gramática para converter automaticamente cada chamada de API em um comando NL canônico, o que pode ser bastante complicado, mas ficará claro para o funcionário comum de crowdsourcing (consulte a seção 3.1). Os artistas só terão que reformular a equipe canônica para torná-la mais natural. Essa abordagem permite evitar muitos erros na coleta de dados de treinamento, uma vez que a tarefa de reformular é muito mais simples e mais compreensível para o funcionário comum de crowdsourcing.
Em segundo lugar, você precisa entender como definir e anotar apenas as chamadas de API que são de valor real para aprender NL2API. A “explosão combinatória” que surge durante a parametrização leva ao fato de que o número de chamadas, mesmo para uma API, pode ser bastante grande. Não faz sentido anotar todas as chamadas. Oferecemos um modelo probabilístico hierárquico fundamentalmente novo para a implementação do processo de crowdsourcing (consulte a seção 3.2). Por analogia com a modelagem de linguagem com o objetivo de obter informações, assumimos que os comandos NL são gerados com base nas chamadas de API correspondentes, portanto o modelo de linguagem deve ser usado para cada chamada de API para registrar esse processo "generativo".
Nosso modelo é baseado na natureza composicional das chamadas de API ou representações formalizadas da estrutura semântica como um todo. Em um nível intuitivo, se uma chamada de API consistir em chamadas mais simples (por exemplo, "e-mails não lidos sobre um candidato ao curso de ciências" = "e-mails não lidos" + "e-mails para um candidato ao curso de ciências", podemos construí-lo modelo de linguagem a partir de chamadas simples à API, mesmo sem anotação, portanto, anotando um pequeno número de chamadas à API, podemos calcular o modelo de linguagem para todos os outros.
Obviamente, os modelos de linguagem calculados estão longe do ideal, caso contrário, já teríamos resolvido o problema de criar o NL2API. No entanto, essa extrapolação do modelo de linguagem para chamadas de API não anotadas nos fornece uma visão holística de todo o espaço das chamadas de API, bem como a interação da linguagem natural e das chamadas de API, o que nos permite otimizar o processo de crowdsourcing. Na Seção 3.3, descrevemos um algoritmo para anotar seletivamente chamadas de API para ajudar a tornar as chamadas de API mais distinguíveis, ou seja, para maximizar a discrepância entre seus modelos de idioma.
Aplicamos nossa estrutura a duas APIs implantadas do pacote Microsoft Graph API2. Demonstramos que dados de treinamento de alta qualidade podem ser coletados a um custo mínimo, se a abordagem proposta for usada3. Também mostramos que nossa abordagem melhora o crowdsourcing. A custos semelhantes, coletamos melhores dados de treinamento, excedendo significativamente a linha de base. Como resultado, nossas soluções NL2API oferecem maior precisão.
Em geral, nossa principal contribuição inclui três aspectos:
- Fomos um dos primeiros a estudar os problemas do NL2API e propusemos uma estrutura abrangente para a criação do NL2API do zero.
- Propusemos uma abordagem única para a coleta de dados de treinamento usando crowdsourcing e um modelo probabilístico hierárquico fundamentalmente novo para otimizar esse processo.
- Aplicamos nossa estrutura a APIs da Web reais e demonstramos que uma solução NL2API suficientemente eficaz pode ser criada do zero.
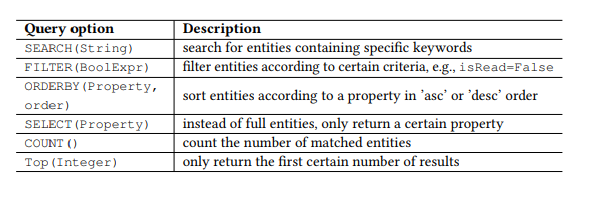 Tabela 1. Parâmetros de consulta OData.
Tabela 1. Parâmetros de consulta OData.Preâmbulo
API RESTful
Recentemente, as APIs da web que estão em conformidade com o estilo de arquitetura REST, ou seja, a API RESTful, estão se tornando cada vez mais populares devido à sua simplicidade. APIs RESTful também são usadas em smartphones e dispositivos IoT. As APIs Restful funcionam com recursos endereçados via URIs e fornecem acesso a esses recursos para uma ampla gama de clientes usando comandos HTTP simples: GET, PUT, POST, etc. Trabalharemos principalmente com a API RESTful, mas os métodos básicos podem ser usados e outras APIs.
Por exemplo, considere o popular Open Data Protocol (OData) para a API RESTful e duas APIs da web do pacote Microsoft Graph API (Figura 1), que, respectivamente, são usadas para procurar emails e eventos de calendário do usuário. Recursos no OData são entidades, cada uma delas associada a uma lista de propriedades. Por exemplo, a entidade Mensagem - um email - possui propriedades como assunto (assunto), de (de), isRead (leitura), receivedDateTime (data e hora do recebimento), etc.
Além disso, o OData define um conjunto de parâmetros de consulta, permitindo executar manipulações avançadas nos recursos. Por exemplo, o parâmetro FILTER permite procurar e-mails de um remetente específico ou cartas recebidas em uma data específica. Os parâmetros de solicitação que usaremos são apresentados na Tabela 1. Chamamos cada combinação do comando HTTP e da entidade (ou conjunto de entidades) como uma API, por exemplo, GET-Messages - para procurar emails. Qualquer solicitação parametrizada, por exemplo, FILTER (isRead = False), é chamada de parâmetro e uma chamada de API é uma API com uma lista de parâmetros.
NL2API
A principal tarefa do NLI é comparar uma instrução (um comando em uma linguagem natural) com uma certa representação formalizada, por exemplo, formulários lógicos ou consultas SPARQL para bases de conhecimento ou APIs da Web no nosso caso. Quando é necessário focar no mapeamento semântico sem se distrair com detalhes irrelevantes, uma representação semântica intermediária geralmente é usada para não trabalhar diretamente com o destino. Por exemplo, a gramática categórica combinatória é amplamente usada na criação de NLIs para bancos de dados e bases de conhecimento. Uma abordagem semelhante à abstração também é muito importante para o NL2API. Muitos detalhes, incluindo convenções de URL, cabeçalhos HTTP e códigos de resposta, podem "distrair" o NL2API da solução do principal problema - o mapeamento semântico.
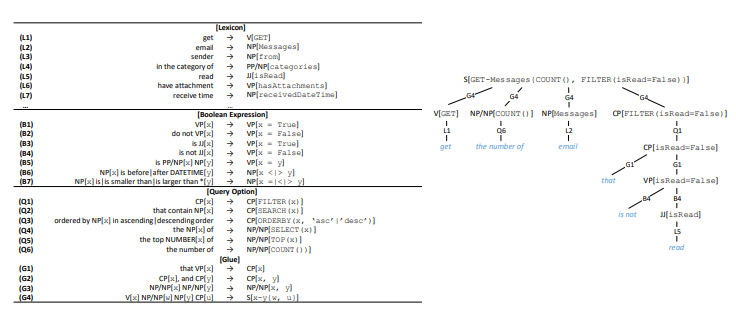
Portanto, criamos uma visualização intermediária para APIs RESTful (Figura 2) com o nome frame da API; essa visualização reflete a semântica do frame. O quadro da API consiste em cinco partes. HTTP Verb (Comando HTTP) e Recurso são os elementos básicos para uma API RESTful. O Tipo de retorno permite criar APIs compostas, ou seja, combinar várias chamadas de API para executar uma operação mais complexa. Os parâmetros necessários são usados com mais frequência em chamadas PUT ou POST na API, por exemplo, o endereço, o cabeçalho e o corpo da mensagem são parâmetros necessários para o envio de email. Parâmetros opcionais geralmente estão presentes nas chamadas GET na API, eles ajudam a restringir a solicitação de informações.
Se os parâmetros necessários estiverem ausentes, serializamos o quadro da API, por exemplo: Mensagens GET {FILTER (isRead = False), SEARCH ("aplicativo de doutorado"), COUNT ()}. Um quadro de API pode ser determinístico e convertido em uma chamada de API real. Durante o processo de conversão, os dados contextuais necessários serão adicionados, incluindo ID do usuário, local, data e hora. No segundo exemplo (Figura 1), o valor now no parâmetro FILTER será substituído pela data e hora da execução do comando correspondente durante a conversão do quadro da API em uma chamada de API real. Além disso, os conceitos de um quadro de API e uma chamada de API serão usados de forma intercambiável.
 Figura 2. O quadro da API. Acima: equipe de linguagem natural. No meio: API do quadro. : API.
Figura 2. O quadro da API. Acima: equipe de linguagem natural. No meio: API do quadro. : API.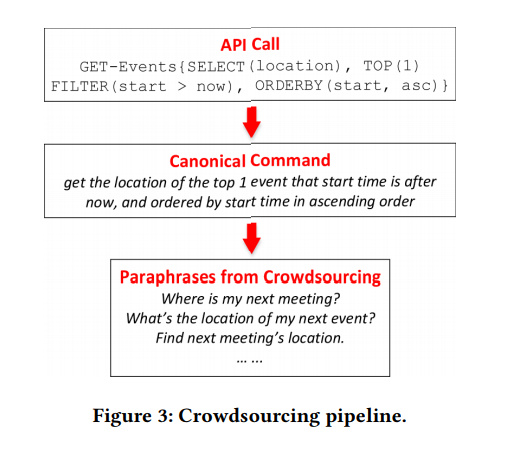 3. .
3. .NL2API . API , ( 3.1), ( 3). API, ( 3.2), ( 3.3).
 4. . : . : .
4. . : . : .API
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
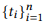
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
Podemos gerar um grande número de chamadas de API usando a abordagem acima, mas anotar todas elas usando o crowdsourcing não é economicamente viável. Portanto, propomos um modelo probabilístico hierárquico para crowdsourcing que ajuda a decidir quais chamadas de API devem ser anotadas. Até onde sabemos, este é o primeiro modelo probabilístico de uso de crowdsourcing para criar interfaces NLI, o que nos permite resolver a tarefa única e intrigante de modelar a interação entre representações da linguagem natural e representações formalizadas da estrutura semântica. Representações formalizadas da estrutura semântica em geral e chamadas de API em particular são de natureza composicional. Por exemplo, z12 = GET-Messages {COUNT (), FILTER (isRead = False)} consiste em z1 = GET-Messages {FILTER (isRead = False)} e z2 = GET-Messages {COUNT ()} (esses exemplos são mais detalhados discutir mais).
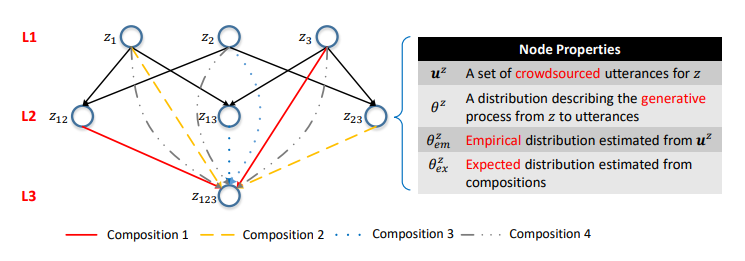 Figura 5. A rede semântica. A i-ésima camada consiste em chamadas de API com parâmetros i. Costelas são composições. As distribuições de probabilidade nos vértices caracterizam os modelos de linguagem correspondentes.
Figura 5. A rede semântica. A i-ésima camada consiste em chamadas de API com parâmetros i. Costelas são composições. As distribuições de probabilidade nos vértices caracterizam os modelos de linguagem correspondentes.Um dos principais resultados de nosso estudo foi a confirmação de que essa composicionalidade pode ser usada para modelar o processo de crowdsourcing.
Primeiro, definimos a composição com base em um conjunto de parâmetros de chamada da API.
Definição 3.1 (composição). Faça uma API e um conjunto de chamadas de API
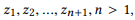
se definirmos r (z) como um conjunto de parâmetros para z, então
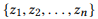
é uma composição
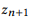
se e somente se
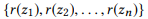
faz parte
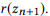
Com base nos relacionamentos de composição das chamadas de API, você pode organizar todas as chamadas de API em uma única estrutura hierárquica. As chamadas de API com o mesmo número de parâmetros são representadas como os vértices de uma camada e as composições são representadas como
costelas direcionadas entre as camadas. Chamamos essa estrutura de rede semântica (ou SeMesh).
Por analogia com a abordagem baseada na modelagem de linguagem na recuperação de informações, assumimos que as instruções correspondentes a uma chamada da API z são geradas usando um processo estocástico caracterizado por um modelo de linguagem
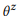
. Para simplificar, focamos nas probabilidades das palavras,

onde
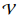
denota um dicionário.
Por razões que se tornarão aparentes um pouco mais tarde, em vez do modelo de unigrama de linguagem padrão, sugerimos o uso de um conjunto de distribuições de Bernoulli (Bag of Bernoulli, BoB). Cada distribuição de Bernoulli corresponde a uma variável aleatória W, determinando se a palavra w aparece na sentença gerada com base em z, e a distribuição BoB é um conjunto de distribuições de Bernoulli para todas as palavras

. Vamos usar
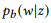
como uma notação curta para
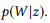
.
Suponha que tenhamos formado um (multi) conjunto de declarações

para z,
a estimativa de máxima verossimilhança (MLE) para a distribuição BoB permite selecionar instruções contendo w:
 Exemplo 2.
Exemplo 2. Com relação à chamada de API acima z1, suponha que tenhamos duas instruções u1 = "encontrar e-mails não lidos" e u2 = "e-mails que não são lidos" e u = {u1, u2}. pb ("emails" | z) = 1.0, pois "emails" está presente nas duas instruções. Da mesma forma, pb ("não lido" | z) = 0,5 e pb ("reunião" | z) = 0,0.
Na rede semântica, há três operações básicas no nível do vértice:
Anotação, layout e interpolação.
ANOTAR (anotar) significa coletar instruções
parafrasear o comando canônico do vértice z usando crowdsourcing e avaliar a distribuição empírica
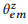
método de máxima verossimilhança.
COMPOSE (compor) tenta derivar um modelo de linguagem baseado em composições para calcular a distribuição esperada
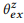
. Como mostramos experimentalmente,
É uma composição para z. Se prosseguirmos com a suposição de que as declarações correspondentes são caracterizadas pela mesma conexão composicional, então
deve ser apresentado em

:

onde f é uma função composicional. Para a distribuição BoB, a função de composição ficará assim:
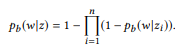
Em outras palavras, se ui é uma afirmação zi, u é uma afirmação
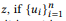
composicionalmente forma u, então a palavra w não pertence a u. Se e somente se não pertencer a nenhuma interface do usuário. Quando z tem muitas composições, θe x é calculado separadamente e depois calculado a média. O modelo de unigrama de linguagem padrão não leva a uma função composicional natural. No processo de normalização das probabilidades de palavras, está envolvido o comprimento das frases, as quais, por sua vez, levam em consideração a complexidade das chamadas de API, violando a decomposição na equação (2). É por isso que oferecemos distribuição BoB.
Exemplo 3. Suponha que preparamos uma anotação para as chamadas API mencionadas anteriormente z1 e z2, cada uma das quais com duas instruções:
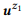
= {"Localizar emails não lidos", "emails que não são lidos"} e
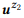
= {"Quantos emails eu tenho", "encontre o número de emails"}. Classificamos modelos de idiomas
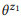
e
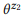
. A operação de composição está tentando avaliar
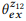
sem perguntar
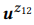
. Por exemplo, para a palavra "e-mails", pb ("e-mails" | z1) = 1.0 e pb ("e-mails" | z2) = 1.0, portanto, da equação (3) segue que pb ("e-mails" | z12) = 1.0, isto é, acreditamos que esta palavra será incluída em qualquer declaração da z12. Da mesma forma, pb ("encontrar" | z1) = 0,5 e pb ("encontrar" | z2) = 0,5, portanto, pb ("encontrar" | z12) = 0,75. Uma palavra tem uma boa chance de ser gerada a partir de qualquer z1 ou z2, portanto, sua probabilidade para z12 deve ser maior.
Obviamente, nem sempre as declarações são combinadas em termos de composição. Por exemplo, vários elementos em uma representação formalizada de uma estrutura semântica podem ser transmitidos em uma única palavra ou frase em uma linguagem natural, esse fenômeno é chamado de composicionalidade sublexica. Um exemplo é mostrado na Figura 3, onde os três parâmetros - TOP (1), FILTER (start> now) e ORDERBY (start, asc) - são representados pela palavra "next". No entanto, é impossível obter essas informações sem anotar a chamada da API; portanto, o problema se assemelha ao problema de frango e ovos. Na ausência de tais informações, é razoável aderir à suposição padrão de que as instruções são caracterizadas pelo mesmo relacionamento de composição que as chamadas de API.
Esta é uma suposição plausível. Vale ressaltar que essa suposição é usada apenas para modelar o processo de crowdsourcing com o objetivo de coletar dados. Na fase de teste, as declarações de usuários reais podem não corresponder a essa suposição. A interface de linguagem natural será capaz de lidar com essas situações não composicionais se elas forem cobertas pelos dados de treinamento coletados.
INTERPOLATE (interpolação) combina todas as informações disponíveis sobre z, ou seja, declarações anotadas z e informações obtidas das composições e obtém uma estimativa mais precisa
por interpolação
e
.
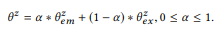
O parâmetro de balanço α controla trade-offs entre anotações
os picos atuais que são precisos, mas suficientes, e as informações obtidas de composições baseadas na suposição de composição podem não ser tão precisas, mas fornecem uma cobertura mais ampla. Em certo sentido,
serve ao mesmo objetivo que o anti-aliasing na modelagem de linguagem, o que permite uma melhor estimativa da distribuição de probabilidade com dados insuficientes (anotações). Mais que
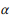
quanto mais peso
. Para um vértice raiz que não tem composição,
=
. Para um topo não anotado
=
.
Em seguida, descrevemos o algoritmo de atualização de rede semântica, ou seja, cálculos
para todo z (algoritmo 1), mesmo que apenas uma pequena parte dos vértices tenha sido anotada. Assumimos que o valor
Já atualizado para todos os sites anotados. Descendo de cima para baixo, calculamos sequencialmente
e
para cada vértice z. Primeiro, você precisa atualizar as camadas superiores para poder calcular a distribuição esperada dos vértices do nível inferior. Anotamos todos os vértices raiz, para que possamos calcular
para todos os vértices.
Algoritmo 1. Distribuições de nós de atualização da malha semântica
3.3 Otimização de Crowdsourcing
A rede semântica forma uma visão holística de todo o espaço das chamadas de API, bem como a interação de instruções e chamadas. Com base nessa visão, podemos anotar seletivamente apenas um subconjunto de chamadas à API de alto valor. Nesta seção, descrevemos nossa estratégia de distribuição diferencial para otimizar o crowdsourcing.
Considere uma rede semântica com muitos vértices Z. Nossa tarefa é determinar um subconjunto de vértices dentro do processo iterativo
para ser anotado por trabalhadores de crowdsourcing. Os vértices anotados anteriormente serão chamados de state state,
então precisamos encontrar políticas de política

para avaliar cada vértice não anotado com base no estado atual.
Antes de aprofundar na discussão de abordagens para calcular políticas eficazes, suponha que já tenhamos uma e forneça uma descrição de alto nível de nosso algoritmo de crowdsourcing (Algoritmo 2) para descrever os métodos que a acompanham. Mais especificamente, primeiro anotamos todos os vértices raiz para avaliar a distribuição de todos os vértices em Z (linha 3). A cada iteração, atualizamos a distribuição de vértices (linha 5), calculamos
uma política baseada no estado atual da rede semântica (linha 6), selecione o vértice não anotado com a classificação máxima (linha 7) e anote o vértice e o resultado no novo estado (linha 8). Em termos práticos, você pode anotar vários vértices como parte de uma iteração para aumentar a eficiência.
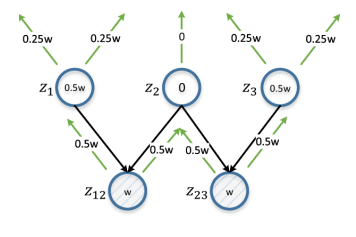 Figura 6. Distribuição diferencial. z12 e z23 representam o par de vértices em estudo. w é uma estimativa calculada com base em d (z12, z23) e se propaga iterativamente de baixo para cima, dobrada em cada iteração. A estimativa para o vértice será a diferença absoluta de suas estimativas de z12 e z23 (portanto diferencial). z2 obtém uma pontuação de 0 porque é a entidade pai comum de z12 e z23; a anotação neste caso será de pouca utilidade em termos de garantir a distinção entre z12 e z23.
Figura 6. Distribuição diferencial. z12 e z23 representam o par de vértices em estudo. w é uma estimativa calculada com base em d (z12, z23) e se propaga iterativamente de baixo para cima, dobrada em cada iteração. A estimativa para o vértice será a diferença absoluta de suas estimativas de z12 e z23 (portanto diferencial). z2 obtém uma pontuação de 0 porque é a entidade pai comum de z12 e z23; a anotação neste caso será de pouca utilidade em termos de garantir a distinção entre z12 e z23.Em um sentido amplo, as tarefas que resolvemos podem ser atribuídas ao problema da aprendizagem ativa; estabelecemos o objetivo de identificar um subconjunto de exemplos para anotação, a fim de obter um conjunto de treinamento que possa melhorar os resultados da aprendizagem. No entanto, várias diferenças importantes não permitem a aplicação direta de métodos clássicos de ensino ativo, como "incerteza de amostragem". Normalmente, no processo de aprendizado ativo, o aluno, que no nosso caso seria a interface NLI, tenta estudar o mapeamento f: X → Y, onde X é a amostra do espaço de entrada, consistindo em um pequeno conjunto de amostras marcadas e um grande número de amostras não marcadas, e Y geralmente é um conjunto de marcadores classe.
O aluno avalia o valor informativo dos exemplos não identificados e seleciona o mais informativo para obter uma nota Y dos trabalhadores de crowdsourcing. Mas, dentro da estrutura do problema que estamos resolvendo, o problema da anotação é colocado de maneira diferente. Precisamos selecionar uma instância de Y, um grande espaço de chamada da API, e pedir aos funcionários de crowdsourcing que o rotulem especificando padrões em X, o espaço da frase. Além disso, não estamos vinculados a um trainee específico. Assim, propomos uma nova solução para o problema em questão. Nós nos inspiramos em várias fontes de aprendizado ativo.
Primeiro, determinaremos a meta, com base na qual o conteúdo das informações dos nós será avaliado. Obviamente, queremos que diferentes chamadas de API sejam distinguíveis. Na rede semântica, isso significa que a distribuição
picos diferentes têm diferenças óbvias. Para começar, apresentamos cada distribuição
como um vetor n-dimensional

onde n = |
| - o tamanho do dicionário. Por uma certa métrica da distância do vetor d (em nossos experimentos, usamos a distância entre os vetores pL1), queremos dizer

, ou seja, a distância entre dois vértices é igual à distância entre suas distribuições.
O objetivo óbvio é maximizar a distância total entre todos os pares de vértices. No entanto, a otimização de todas as distâncias aos pares pode ser muito complicada para cálculos, e mesmo isso não é necessário. Um par de picos distantes já possui diferenças suficientes, portanto, um aumento adicional na distância não faz sentido. Em vez disso, podemos nos concentrar nos pares de vértices que causam mais confusão, ou seja, a distância entre eles é a menor.
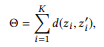
onde
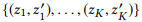
aponta para os primeiros K pares de vértices se classificarmos todos os pares de nós por distância em ordem crescente.
Algoritmo 2. Anote iterativamente uma malha semântica com uma política Algoritmo 3. Política de computação baseada na propagação diferencial
Algoritmo 3. Política de computação baseada na propagação diferencial Algoritmo 4. Propague recursivamente uma pontuação de um nó de origem para todos os seus nós pais
Algoritmo 4. Propague recursivamente uma pontuação de um nó de origem para todos os seus nós pais
Vértices com maior conteúdo de informações após a anotação potencialmente aumentam o valor de Θ. Para quantificação, neste caso, propomos o uso de uma estratégia de distribuição diferencial. Se a distância entre um par de vértices for pequena, examinaremos todos os seus vértices pai: se o vértice pai for comum para um par de vértices, ele deverá receber uma classificação baixa, pois a anotação levará a alterações semelhantes nos dois vértices.
Caso contrário, o vértice deve ser altamente classificado e, quanto mais próximo o par de vértices, maior será a classificação. Por exemplo, se a distância entre os vértices de "e-mails não lidos sobre o aplicativo PhD" e "quantos e-mails são sobre o aplicativo PhD" é pequena, a anotação do vértice pai "e-mails sobre o aplicativo PhD" não faz muito sentido do ponto de vista da distinção entre esses vértices. É mais aconselhável anotar nós pai que não serão comuns a eles: "emails não lidos" e "quantos emails".
Um exemplo dessa situação é mostrado na Figura 6 e seu algoritmo é o algoritmo 3. Como estimativa, tomamos o recíproco da distância do nó limitada por uma constante (linha 6), para que os pares de vértices mais próximos tenham o maior impacto. Ao trabalhar com um par de vértices, atribuímos simultaneamente uma avaliação de cada vértice a todos os seus vértices pai (linha 9, 10 e algoritmo 4). Uma estimativa de um vértice não anotado é a diferença absoluta nas estimativas do par de vértices correspondente com a soma de todos os pares de vértices (linha 12).
Interface de linguagem natural
Para avaliar a estrutura proposta, é necessário treinar os modelos NL2API usando os dados coletados. No momento, o modelo NL2API finalizado não está disponível, mas estamos adaptando dois modelos NLI testados de outras áreas para aplicá-los à API.
Modelo de extração de modelo de linguagem
Com base nos desenvolvimentos recentes no campo do NLI para bases de conhecimento, podemos considerar a criação do NL2API no contexto do problema de extração de informações, a fim de adaptar o modelo de extração baseado no modelo de linguagem (LM) às nossas condições.
Para dizer "u", você precisa encontrar uma chamada da API z na rede semântica com a melhor correspondência para "u". Primeiro, transformamos a distribuição do BoB

cada chamada da API z para o modelo de unigrama do idioma:
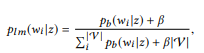
onde usamos suavização aditiva e 0 ≤ β ≤ 1 é o parâmetro de suavização. Maior valor
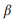
, maior o peso das palavras que ainda não foram analisadas. As chamadas de API podem ser classificadas por sua probabilidade logarítmica:
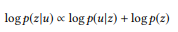
(sujeito a uma distribuição uniforme de probabilidade a priori)
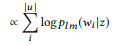
A chamada da API com a classificação mais alta é usada como resultado da simulação.
Módulo de reformulação Seq2Seq
As redes neurais estão se tornando mais difundidas como modelos para NLI, enquanto o modelo Seq2Seq é melhor que os outros para esse fim, pois permite processar naturalmente sequências de entrada e saída de comprimentos variáveis. Nós adaptamos este modelo para NL2API.
Para sequência de entrada e

, o modelo estima a distribuição de probabilidade condicional p (y | x) para todas as sequências de saída possíveis
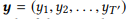
. Os comprimentos T e T 'podem variar e assumir qualquer valor. No NL2API, x é a instrução de saída. y pode ser uma chamada de API serializada ou seu comando canônico. Usaremos comandos canônicos como sequências de saída de destino, o que realmente transforma nosso problema em um problema de reformulação.
Um codificador implementado como uma rede neural recorrente (RNN) com unidades de recorrência controlada (GRU) primeiro representa x como um vetor de tamanho fixo,

onde RN N é uma breve representação para aplicar GRU a toda a sequência de entrada, marcador por marcador, seguido pela saída do último estado oculto.
O decodificador, que também é um RNN com GRU, toma h0 como o estado inicial e processa a sequência de saída y, marcador por marcador, para gerar uma sequência de estados,

A camada de saída toma cada estado do decodificador como um valor de entrada e gera uma distribuição de dicionário
como o valor de saída. Apenas usamos a transformação afim seguida pela função logística multi-variável softmax:
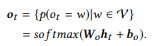
A probabilidade condicional final, que nos permite avaliar até que ponto o comando canônico reformula a instrução de entrada x, é

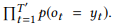
. As chamadas de API são então classificadas pela probabilidade condicional de seu comando canônico. Recomendamos que você se familiarize com a fonte, onde o processo de aprendizado do modelo é descrito em mais detalhes.
Experiências
Experimentalmente, estudamos os seguintes assuntos de pesquisa: [PI1]: Podemos usar a estrutura proposta para coletar dados de treinamento de alta qualidade a um preço razoável? [PI2]: A rede semântica fornece uma avaliação mais precisa dos modelos de linguagem do que a avaliação de probabilidade máxima? [PI3]: Uma estratégia de distribuição diferencial melhora a eficiência do crowdsourcing?
Crowdsourcing
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
 2. API.
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
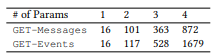
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
, , ROOT,
. , , . MLE. , , [2] .
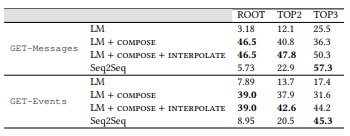
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
7. .
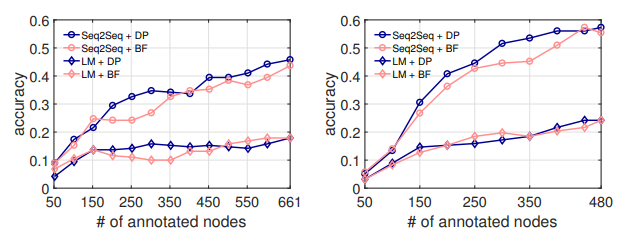
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?