O modelo de máquina de estado finito (FSM) é usado para escrever código para uma ampla variedade de plataformas, incluindo o Android. Ele permite que você torne o código menos complicado, se encaixa bem no paradigma Model-View-Presenter (MVP) e se presta a testes simples. O desenvolvedor Vladislav Kuznetsov disse ao Droid Party como esse modelo ajuda no desenvolvimento do aplicativo Yandex.Disk.
- Primeiro, vamos falar sobre teoria. Acho que cada um de vocês já ouviu falar sobre o MVP e a máquina de estado, mas vamos repetir.

Vamos falar sobre motivação, sobre por que tudo isso é necessário e como isso pode nos ajudar. Vamos seguir o que fizemos, com um exemplo real, mostrarei trechos de código. E, no final, falaremos sobre testes, sobre como essa abordagem ajudou a testar tudo de forma conveniente.
A máquina de estado e o MVP, ou algo semelhante - provavelmente o MVI - foram usados por todos.
Existem muitas máquinas de estado. Aqui está a definição mais simples que pode ser dada a eles: esse é um tipo de abstração matemática, apresentada na forma de um conjunto finito de estados, eventos e transições do estado atual para um novo, dependendo do evento.
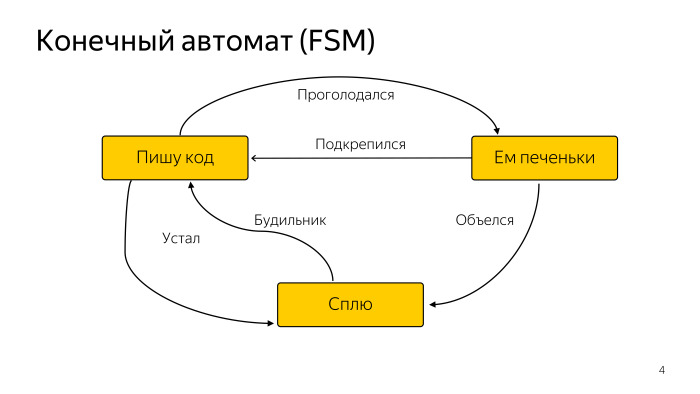
Aqui está um diagrama simples de algum programador abstrato que às vezes dorme, às vezes come, mas escreve principalmente código. Isso é suficiente para nós. Há um grande número de variedades de uma máquina de estados finitos, mas isso é suficiente para nós.

O escopo da máquina de estado é bastante grande. Para cada item, eles são usados e aplicados com sucesso.
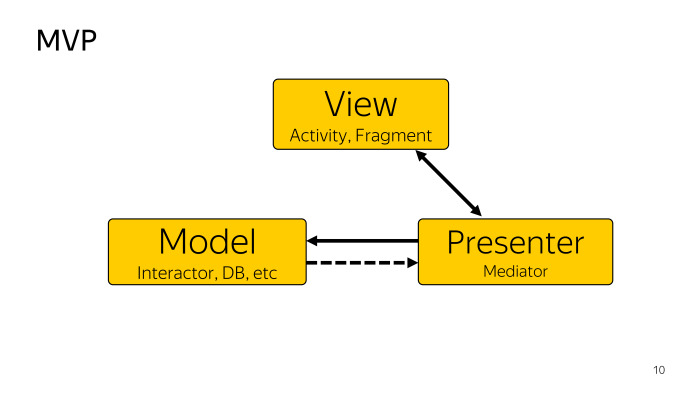
Como qualquer abordagem, o MVP divide nosso aplicativo em várias camadas. Visualização - geralmente uma Atividade ou Fragmento, cuja tarefa é encaminhar alguma ação ao usuário, para identificar o Apresentador que o usuário fez alguma coisa. Consideramos o Model como um provedor de dados. Pode ser como um banco de dados, se estamos falando de arquitetura limpa, ou Interactor, tudo pode ser. O Presenter é um intermediário que conecta a View e o modelo, enquanto, ao mesmo tempo, pode selecionar e atualizar a View do modelo. Isso é suficiente para nós.
Quem pode dizer em uma frase o que é um programa? Código executável? Muito geral, mais detalhado. Um algoritmo? Um algoritmo é uma sequência de ações.
Este é um conjunto de dados e algum tipo de fluxo de controle. Não importa quem manipula esses dados: o usuário ou não. Segue-se o pensamento de que a qualquer momento o estado de um aplicativo é determinado pela totalidade de todos os seus dados. E quanto mais dados no aplicativo, mais difícil é gerenciá-los, mais imprevisível pode surgir uma situação quando algo der errado.

Imagine uma classe simples com três sinalizadores booleanos. Para garantir que você cubra todos os cenários para combinar esses sinalizadores, você precisa de 2³ cenários. É necessário cobrir oito cenários com garantia de que estou processando todas as combinações de sinalizadores com certeza. Se você adicionar outro sinalizador, ele aumentará proporcionalmente.
Enfrentamos um problema semelhante. Parecia ser uma tarefa simples, mas, à medida que desenvolvíamos e trabalhamos, começamos a perceber que algo estava dando errado. Vou falar sobre os recursos que lançamos. É chamado de exclusão de fotos locais. O ponto é que o usuário carrega alguns dados na nuvem no modo automático. Provavelmente, são fotos e vídeos que ele tirou no telefone. Acontece que os arquivos parecem estar na nuvem. Por que ocupar um espaço precioso no seu telefone quando você pode excluir essas fotos?

Os designers desenharam esse conceito. Parece apenas um diálogo, tem um cabeçalho no qual é desenhada a quantidade de espaço que podemos liberar, o texto da mensagem e uma marca de verificação de que existem dois modos de limpeza: exclua todas as fotos que o usuário enviou ou apenas aquelas com mais de um mês.

Nós olhamos - parece não haver nada complicado. Caixa de diálogo, dois TextViews, caixa de seleção, botões. Mas quando começamos a trabalhar com esse problema em detalhes - percebemos que obter dados sobre quantos arquivos podemos excluir é uma tarefa de longo prazo. Portanto, devemos mostrar ao usuário algum tipo de esboço. Este é um pseudo-código, na vida real parece diferente, mas o significado é o mesmo.
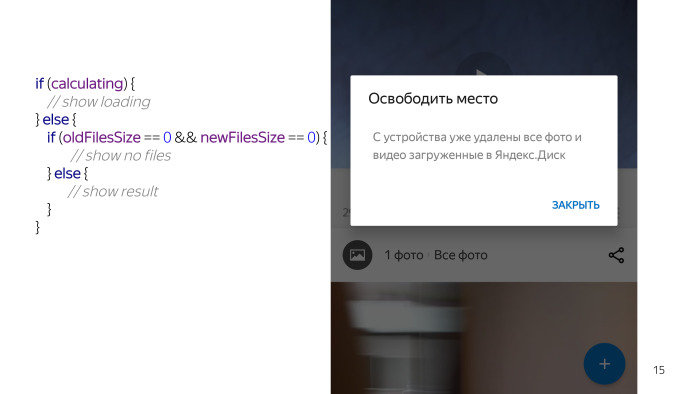
Verificamos algum estado, verificamos que estamos calculando e desenhamos um plug "Wait".

Quando os cálculos terminam, temos várias opções para o que exibir ao usuário. Por exemplo, o número de arquivos que podemos excluir é zero. Nesse caso, enviamos uma mensagem ao usuário de que não há nada a ser excluído; portanto, venha da próxima vez. Em seguida, os designers vêm até nós e dizem que devemos distinguir entre situações em que o usuário já limpou os arquivos ou não limpou nada, nada carregado. Portanto, outra condição parece que estamos aguardando a inicialização e atraímos outra mensagem para ele.
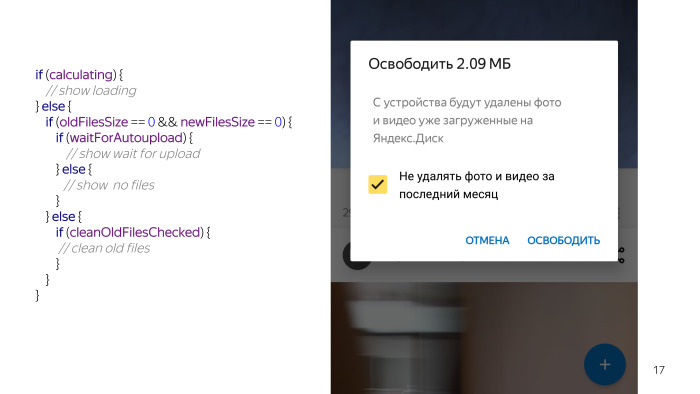
Existem situações em que algo funcionou e, por exemplo, o usuário tem uma marca de seleção para não excluir novos arquivos. Nesse caso, também existem duas opções. Os arquivos podem ser limpos ou os arquivos não podem ser limpos, ou seja, já limparam todos os arquivos; portanto, avisamos que você já excluiu todos os arquivos novos.
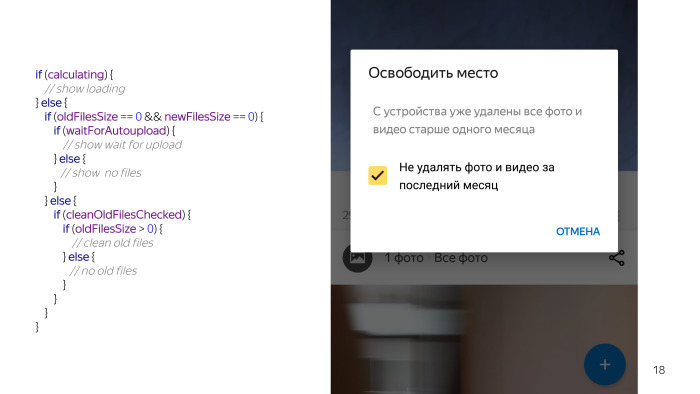
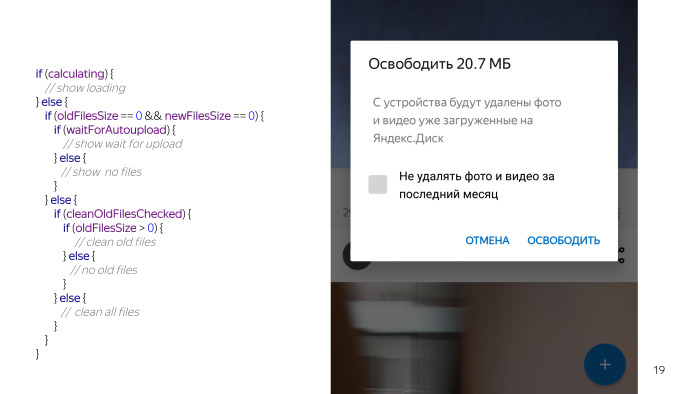
Há mais uma condição em que podemos realmente excluir algo. Desmarcado, e há uma opção que você pode excluir algo. Você olha para este código e parece que algo está errado. Ainda não listei tudo, temos uma verificação de permissão, porque nada funciona sem eles, não podemos tocar nos arquivos do cartão, além de precisarmos verificar se o usuário está com o carregamento automático ativado, porque os recursos são inúteis sem o carregamento automático, o que iremos limpar. E mais algumas condições. E, caramba, parece uma coisa tão simples, e muitos problemas surgiram por causa disso.
E, obviamente, vários problemas surgem imediatamente. Primeiro de tudo, esse código é ilegível. Aqui, um certo pseudocódigo é representado, mas em um projeto real, ele está espalhado por diferentes funções, partes do código, não é tão fácil de perceber a olho. O suporte para esse código também é bastante complicado. Especialmente quando você chega a um novo projeto, é informado que precisa criar esse recurso, adiciona alguma condição, verifica um cenário positivo, tudo funciona, mas os testadores chegam e dizem que, sob certas condições, tudo quebrou. Isso acontece porque você simplesmente não levou em consideração nenhum cenário.
Além disso, é redundante no sentido de que, como temos um grande ramo de condições, devemos verificar todas as condições que não nos convêm com antecedência. Eles são negativos antecipadamente, mas, como são escritos com tais ramificações, devemos verificá-las. O fato é que no exemplo eu tenho algum tipo de sinalizadores booleanos, mas na prática, você pode ter chamadas para funções que vão para algum lugar mais profundo no banco de dados. Tudo pode ser devido à redundância, haverá freios adicionais.
E o mais triste é um comportamento inesperado que foi esquecido durante a fase de teste, nada aconteceu lá, e em algum lugar da produção o usuário não aconteceu na melhor das hipóteses, algum tipo de curva da interface do usuário e, na pior das hipóteses, caiu ou os dados foram perdidos . Apenas o aplicativo não se comportou de forma consistente.
Como resolver este problema? Pelo poder da máquina de estado.

A principal tarefa que a máquina de estado lida é pegar uma tarefa grande e complexa e dividi-la em pequenos estados discretos, mais fáceis de interagir e gerenciar. Depois de sentar, pensar, já que estamos tentando fazer algo MVP, como vincular nosso estado a tudo isso? Chegamos a aproximadamente esse esquema. Quem lê o livro do GOF é um padrão de estado clássico, exatamente o que é chamado de contexto, eu o chamei de state-oner e, de fato, é um apresentador. O apresentador tem esse estado, sabe como alterná-los e ainda pode fornecer alguns dados para os nossos estados se eles quiserem saber algo, por exemplo, tamanho do arquivo ou desejar solicitar uma solicitação assíncrona, selecione.

Não há nada super-duper aqui, o próximo slide é mais importante.
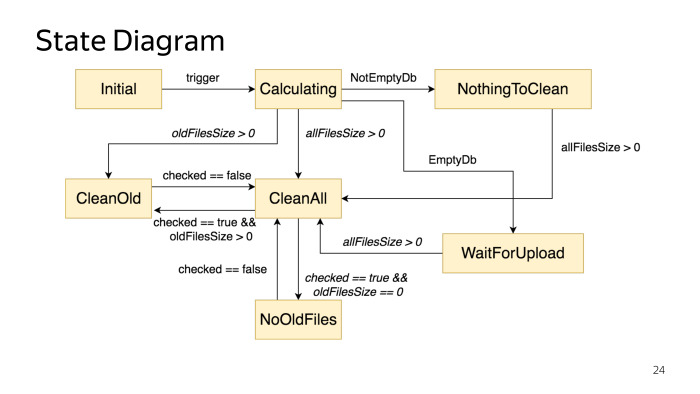
Com isso, você precisa iniciar o desenvolvimento ao começar a criar uma máquina de estado. Você está sentado no seu computador ou em algum lugar ao redor da mesa e, em um pedaço de papel ou em ferramentas especiais, desenha um diagrama de estados. Também não há nada complicado, mas esse estágio tem muitas vantagens. Primeiro, em um estágio inicial, você pode detectar imediatamente algumas inconsistências na lógica de negócios. Seus produtos podem vir, expressar seu desejo, está tudo bem, mas quando você começa a escrever código, entende que algo não se encaixa. Eu acho que todo mundo teve uma situação dessas. Mas quando você faz um diagrama, pode ver desde o início que algo não está ancorado. Ele é desenhado de maneira bem simples, existem ferramentas especiais, como o PlantUML, nas quais você nem precisa desenhar, precisa escrever pseudocódigo e ele próprio gera gráficos.
Nosso gráfico se parece com isso, que descreve o estado desse diálogo. Existem vários estados e a lógica da transição entre eles.

Vamos seguir para o código. Afirme que não há nada importante, o principal é que ele possui três métodos: onEnter, que, ao entrar, chama primeiro invalidateView. Por que isso é feito? Para que, assim que entrarmos no estado, a interface do usuário seja atualizada. Além disso, existe o método invalidateView, que sobrecarregamos se precisamos fazer algo com a interface do usuário e o método onExit, no qual podemos fazer algo se sairmos do estado.

StateOwner. Uma interface que fornece a capacidade de clicar em estado. Como descobrimos, será um futuro apresentador. E esses são métodos que fornecem acesso adicional aos dados. Se algum dado for vasculhado entre estados, podemos mantê-lo no apresentador e fornecê-lo por essa interface. Nesse caso, podemos fornecer o tamanho dos arquivos que podemos limpar e oferecer a oportunidade de fazer algum tipo de solicitação. Estamos em um estado, queremos solicitar algo e, através do StateOwner, podemos chamar um método.
Outra utilidade é que ele também pode retornar um link para a visualização. Isso é feito para que, se você tiver um estado e alguns dados chegarem, não desejar mudar para um novo estado, é apenas redundante, você pode atualizar diretamente a exibição, o texto. Usamos isso para atualizar o número de dígitos que o usuário vê quando olha para o diálogo. Estamos em tempo de download de arquivos, ele olha para o diálogo e os números são atualizados. Não estamos entrando em um novo estado, estamos apenas atualizando a Visualização atual.

Aqui está o MVP padrão, tudo deve ser extremamente simples, sem lógica, métodos simples que desenham algo. Eu aderi a esse conceito. Não deve haver lógica, pelo menos algum tipo de ação. Nós pegamos algumas Text View de maneira limpa, mudamos, não mais.

Apresentador Há coisas mais interessantes. Primeiro de tudo, podemos encontrar dados através deles para alguns estados, temos duas variáveis marcadas com a anotação State. Quem usou o Icepick está familiarizado com isso. Não escrevemos serialização com as mãos no Partible, usamos uma biblioteca pronta.
O seguinte é o estado inicial. É sempre útil definir o estado inicial, mesmo que não faça nada. A utilidade é que você não precisa fazer verificações nulas, mas se dissermos que isso pode fazer alguma coisa. Por exemplo, você precisa fazer algo uma vez para o ciclo de vida do seu aplicativo; quando começamos, você precisa executar o procedimento uma vez e nunca mais fazê-lo. Quando saímos do estado inicial, sempre podemos fazer algo assim e nunca voltamos a esse estado. Digite para que o diagrama de estado seja desenhado. Embora quem sabe quem vai desenhar, talvez você possa voltar.
Sou a favor de minimizar as verificações para Null e assim por diante, por isso aqui mantenho um link para uma implementação de exibição simples. Não precisamos sincronizar nada, apenas em algum momento em que ocorre a desanexação, substituímos a visualização por uma vazia e o apresentador pode alternar para algum lugar nos estados, pensar que há uma visualização, ela atualiza, mas na verdade funciona com implementação vazia.
Existem vários outros métodos para salvar o estado, mas queremos sobreviver ao levante da Activity, neste caso, tudo é feito através do construtor. Tudo é um pouco mais complicado, aqui está um exemplo exagerado.

É necessário encaminhar saveState, se alguém trabalhou com bibliotecas semelhantes, tudo é bastante trivial. Você pode escrever com as mãos. E dois métodos são muito importantes: anexar, chamado onStart e desanexar, chamado onStop.

Qual a importância deles? Inicialmente, planejamos anexar e desanexar no onCreateView, onDestroyView, mas isso não foi suficiente. Se você tiver uma Visualização, seu texto pode ser atualizado ou um fragmento de diálogo pode aparecer. E se você não for pego no onStop e tentar mostrar o fragmento, verá a exceção bem conhecida de que não pode confirmar uma transação quando ainda temos o estado. Use a perda de estado de confirmação ou não. Portanto, somos detalhados no onStop, enquanto o apresentador continuará trabalhando lá, alternar estados, capturar eventos. E, no momento em que o início ocorrer, acionaremos o evento de visualização anexada e o apresentador atualizará a interface do usuário para corresponder ao estado atual.


Existe um método de liberação, geralmente chamado onDestroy, você desanexa e libera recursos adicionalmente.

Outro método setState importante. Como planejamos alterar a interface do usuário em onEnter e onExit, há uma verificação para o thread principal. Isso cria uma restrição para nós de que não estamos fazendo nada pesado aqui, todas as solicitações devem ser para a interface do usuário ou devem ser assíncronas. A vantagem deste local é que aqui podemos reservar a entrada e a saída do estado, é muito útil ao depurar, por exemplo, quando algo dá errado, você pode ver como o sistema clicou e entender o que estava errado.
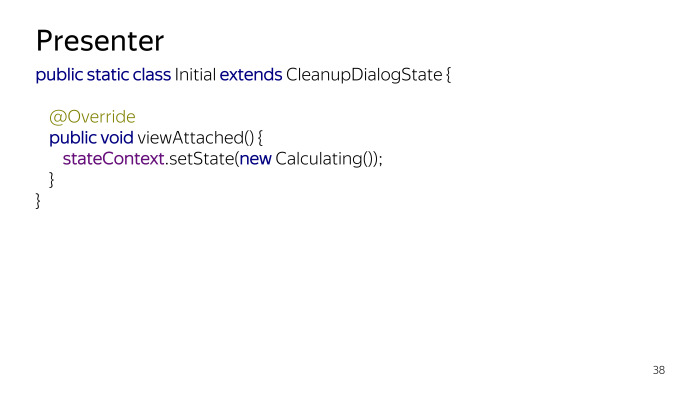
Alguns exemplos de condições. Existe um estado inicial, apenas aciona o cálculo de quanto espaço você precisa liberar no momento em que a visualização ficou disponível. Isso acontecerá após o onStart. Assim que onStart acontece, entramos em um novo estado e o sistema começa a solicitar dados.

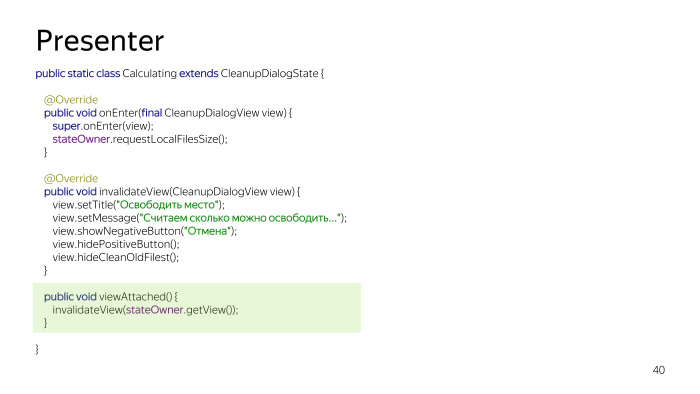
Um exemplo do estado é Cálculo, declararemos o tamanho dos arquivos com stateOwner, de alguma forma rastreará o banco de dados e, em seguida, ainda haverá um inValidateView, atualizaremos a interface do usuário do usuário atual. E viewAttached é chamado se a visualização for reconectada. Se estivéssemos em segundo plano, o cálculo era em segundo plano, retornamos novamente à nossa atividade, esse método é chamado e atualiza todos os dados.

Um exemplo de evento, perguntamos a stateOwner quantos arquivos podem ser liberados e chama o método filesSizeUpdated. Aqui eu estava com preguiça, era possível escrever três métodos separados, como atualizados, existem tantos arquivos antigos quanto separar eventos diferentes. Mas você precisa entender, uma vez que será difícil para você, uma vez que será muito mais simples. Não é necessário cair na superengenharia de que cada evento é um método separado. Você pode conviver com um simples se, não vejo nada de errado nisso.

Eu vejo várias melhorias em potencial. Não gosto que sejamos forçados a contornar esses métodos, como onStart, on Stop, onCreate, onSave e muito mais. Você pode se conectar ao Lifecycle, mas não está claro o que fazer com o saveState. Há uma ideia, por exemplo, de criar um fragmento de apresentador. Porque não Um fragmento sem uma interface do usuário que captura o ciclo de vida e, em geral, não precisaremos de nada, tudo voará para nós por si só.
Outro ponto interessante: esse apresentador é recriado todas as vezes e, se você tem grandes dados armazenados no apresentador, foi ao banco de dados, segura um cursor enorme e é inaceitável solicitar cada vez que você gira a tela. Portanto, você pode armazenar em cache o apresentador, como faz, por exemplo, o ViewModule da Architecture Components, criar algum fragmento que reterá o cache dos apresentadores e os retornará para cada visualização.
Você pode usar a maneira tabular para especificar máquinas de estado, porque o padrão de estado que usamos tem uma desvantagem significativa: assim que você precisar adicionar um método a um novo evento, deverá adicionar implementação a todos os descendentes. Pelo menos vazio. Ou faça-o em condições básicas. Isso não é muito conveniente. Portanto, a maneira tabular de especificar máquinas de estado é usada em todas as bibliotecas - se você procurar no GitHub a palavra FSM, encontrará um grande número de bibliotecas que fornecem um tipo de construtor no qual você define o estado inicial, o evento e o estado final. Expandir e manter uma máquina desse tipo é muito mais fácil.
Outro ponto interessante: se você usar o padrão de estado, se sua máquina de estados começar a crescer, provavelmente precisará lidar com alguns eventos da mesma maneira para que o código não seja copiado, você cria um estado básico. Quanto mais eventos, mais condições básicas começam a aparecer, a hierarquia cresce e algo dá errado.
Como sabemos, a herança deve ser substituída pela delegação, e as máquinas de estado hierárquico ajudam a resolver esse problema. Você tem estados que não dependem do nível de herança - basta criar uma árvore de estados que passam pelo manipulador acima. Você também pode ler separadamente, uma coisa muito útil. No Android, por exemplo, máquinas de estado hierárquicas são usadas no WatchDog Wi-Fi, que monitora o status da rede, eles estão lá, diretamente na fonte do Android.

Por último mas não menos importante. Como isso pode ser testado? Primeiro de tudo, estados determinísticos podem ser testados. Há um estado separado, criamos uma instância, puxamos o método onEnter e vemos que os valores correspondentes são chamados na exibição. Assim, validamos que nosso estado atualize corretamente a visualização. Se o seu View não faz nada sério, é provável que você cubra um grande número de cenários.

Você pode bloquear alguns métodos com uma função que retorna o tamanho, chamar outro evento após onEnter e ver como um determinado estado responde a eventos específicos. Nesse caso, quando o evento filesSizeUpdated ocorre e quando AllFilesSize é maior que zero, devemos fazer a transição para o novo estado CleanAllFiles. Com a ajuda do layout, verificamos tudo isso.

E o último - podemos testar todo o sistema. Construímos o estado, enviamos um evento para ele e verificamos como o sistema se comporta. Temos três estágios de teste. , UI, , , , .
, 70%. 80% . , .

, ? — . - .
. . - , , - , — , .
- , , , . , , . , , . - , , . , , . lock . - , .
— . , , , , . , - , , -, , . , . , .