Como posso imprimir um fluxo contínuo de mensagens do Twitter com algumas linhas de código adicionando dados meteorológicos aos locais onde seus autores moram? E como você pode limitar a velocidade das solicitações ao provedor meteorológico para que elas não nos incluam na lista negra?
Hoje, mostraremos como fazê-lo, mas primeiro conheceremos a tecnologia Akka Streams, que torna o trabalho com fluxos de dados em tempo real tão fácil quanto os programadores que trabalham com expressões LINQ sem exigir a implementação de atores individuais ou interfaces de fluxos reativos. .
O artigo é baseado em uma transcrição do
relatório de Vagif Abilov da nossa conferência de dezembro DotNext 2017 em Moscou.
Meu nome é Vagif, trabalho para a empresa norueguesa Miles. Hoje falaremos sobre a biblioteca do Akka Streams.
Akka e Reative Streams são a interseção de conjuntos bastante estreitos, e pode-se ter a impressão de que esse é um nicho que você precisa ter um grande conhecimento para entrar, mas exatamente o oposto. E este artigo pretende mostrar que, usando o Akka Streams, você pode evitar a programação de baixo nível necessária ao usar o Reactive Streams e o Akka.NET. Olhando para o futuro, posso dizer imediatamente: se no início do nosso projeto, no qual usamos o Akka, soubéssemos da existência do Akka Streams, escreveríamos de maneira muito diferente, economizaríamos tempo e código.
"Talvez o pior que você possa fazer é levar as pessoas que não sentem dor a tomar sua aspirina".
Max Kreminski
“Portas fechadas, dores de cabeça e necessidades intelectuais”
Antes de entrarmos nos detalhes técnicos, um pouco sobre qual pode ser o seu caminho para o Akka Streams e o que pode levá-lo até lá. Um dia, me deparei com o blog de Max Kreminski, onde ele fazia uma pergunta filosófica para programadores: como ou por que é impossível para um programador explicar o que são mônadas. Ele explicou da seguinte maneira: muitas vezes as pessoas vão imediatamente aos detalhes técnicos, explicando como a programação é lindamente funcional e qual o sentido da mônada, sem se preocupar em se perguntar por que o programador pode precisar dela. Fazendo uma analogia, é como tentar vender aspirina sem se preocupar em descobrir se seu paciente está com dor.
Usando essa analogia, eu gostaria de fazer a seguinte pergunta: se o Akka Streams é aspirina, qual deve ser a dor que o levará a isso?
Fluxos de dados
Primeiro, vamos falar sobre fluxos de dados. O fluxo pode ser bastante simples, linear.
Aqui temos um certo consumidor de dados (um coelho no vídeo). Consome dados a uma velocidade adequada. Essa é a interação ideal do consumidor com o fluxo: ele estabelece a largura de banda e os dados fluem silenciosamente para ele. Esse fluxo de dados simples pode ser infinito ou pode terminar.
Mas o fluxo pode ser mais complexo. Se você plantar vários coelhos lado a lado, já teremos paralelização de fluxos. O que os Reativos reativos estão tentando resolver é precisamente como podemos nos comunicar com os fluxos em um nível mais conceitual, isto é, independentemente de estarmos apenas falando sobre algum tipo de medição do sensor de temperatura, em que as medições lineares ocorrem , ou temos medições contínuas de milhares de sensores de temperatura que entram no sistema através das filas do RabbitMQ e armazenados nos logs do sistema. Todos os itens acima podem ser considerados como um fluxo composto. Se você for ainda mais longe, o gerenciamento automatizado da produção (por exemplo, em algumas lojas on-line) também poderá ser reduzido a um fluxo de dados, e seria ótimo se pudéssemos falar sobre o planejamento de um fluxo desse tipo, por mais complicado que seja.

Para projetos modernos, o suporte a threads não é muito bom. Se bem me lembro, Aaron Stannard, cujo tweet você vê na foto, queria obter um fluxo de um arquivo de vários gigabytes contendo CSV, ou seja, texto e acabou que não há nada que você possa executar e usar imediatamente, sem várias ações adicionais. Mas ele simplesmente não conseguiu obter um fluxo de valores CSV, o que o entristeceu. Existem poucas soluções (com exceção de algumas áreas especiais), muito é percebido pelos métodos antigos, quando abrimos tudo isso, começamos a ler, armazenamos em buffer, no pior dos casos, obtemos algo como o bloco de notas, que diz que o arquivo é muito grande.
Em um alto nível conceitual, estamos todos envolvidos no processamento de fluxos de dados, e o Akka Streams o ajudará se:
- Você conhece Akka, mas deseja poupar os detalhes associados à escrita do código do ator e sua coordenação;
- Você está familiarizado com o Reactive Streams e gostaria de usar uma implementação pronta de suas especificações;
- Os elementos de bloco do Akka Streams para estágios são adequados para modelar seu processo;
- Você deseja aproveitar a contrapressão (contrapressão) do Akka Streams para gerenciar e refinar dinamicamente os estágios de rendimento do seu fluxo de trabalho.
De atores a Akka Streams

A primeira maneira é dos atores ao Akka Streams, do meu jeito.
A imagem mostra por que começamos a usar o modelo de ator. Estávamos exaustos pelo controle manual de fluxos, estado compartilhado, só isso. Todo mundo que trabalhou com sistemas grandes, com multiencadeamento, entende o quanto leva tempo e como é fácil cometer um erro, o que pode ser fatal para todo o processo. Isso nos levou ao modelo de atores. Não lamentamos a escolha feita, mas, é claro, quando você começa a trabalhar e a programar mais, não é que o entusiasmo inicial dê lugar a outra coisa, mas você começa a perceber que algo pode ser feito de maneira ainda mais eficaz.
“Por padrão, os destinatários de suas mensagens são inseridos no código dos atores. Se eu criar um ator A que envie uma mensagem ao ator B e você desejar substituir o destinatário pelo ator C, no caso geral, isso não funcionará para você ”
Noel Welch (underscore.io)
Atores criticados por não comporem. Um dos primeiros a escrever sobre isso em seu blog foi Noel Welch, um dos desenvolvedores do Underscore. Ele percebeu que o sistema de atores se parece com isso:

Se você não usar nada adicional, como injeção de dependência, o endereço do destinatário será costurado no ator.

Quando eles começam a enviar mensagens um para o outro, tudo isso você define antecipadamente, atores de programação. E sem truques adicionais, um sistema tão rígido é obtido.
Um dos desenvolvedores da Akka, Roland Kuhn,
explicou o que geralmente se entende por layout ruim. O método ator é baseado no método tell, ou seja, mensagens unidirecionais: é do tipo nulo, ou seja, não retorna nada (ou unidade, dependendo do idioma). Portanto, é impossível construir uma descrição do processo a partir de uma cadeia de atores. Então você enviou dizer, então o que? Parar Ficamos nulos. Você pode compará-lo, por exemplo, com expressões LINQ, onde cada elemento da expressão retorna IQueryable, IEnumerable e tudo isso pode ser facilmente compilado. Os atores não dão essa oportunidade. Ao mesmo tempo, Roland Kuhn se opôs ao fato de que eles supostamente não compõem em princípio, dizendo que de fato são compilados de outras maneiras, no mesmo sentido em que a sociedade humana se presta ao layout. Parece um argumento filosófico, mas se você pensar sobre isso, a analogia faz sentido - sim, os atores enviam mensagens unidirecionais um ao outro, mas também nos comunicamos, emitindo mensagens unidirecionais, mas ao mesmo tempo interagimos com bastante eficácia, ou seja, criamos sistemas complexos. No entanto, existem críticas a esses atores.
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { } private void Idle() { Receive<Job>(job => ); } private void Working() { Receive<Cancel>(job => ); } }
Além disso, a implementação do ator exige pelo menos escrever uma classe se você trabalha em C # ou funciona se você trabalha em F #. No exemplo acima - código padrão, que você deve escrever em qualquer caso. Embora não seja muito grande, é um certo número de linhas que você sempre precisará escrever nesse nível baixo. Quase todo o código que está presente aqui é uma espécie de cerimônia. O que acontece quando um ator recebe diretamente uma mensagem não é mostrado aqui. E tudo isso precisa ser escrito. Isso, é claro, não é muito, mas é uma evidência de que trabalhamos com atores em um nível baixo, criando esses métodos vazios.
E se pudéssemos ir para um nível diferente, mais alto, nos fazer perguntas sobre como modelar nosso processo, que inclui o processamento de dados de várias fontes que são misturadas, convertidas e transferidas?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Um análogo dessa abordagem pode ser o que estamos acostumados a trabalhar com o LINQ há dez anos. Não nos perguntamos como funciona a junção. Sabemos que existe um provedor LINQ que fará tudo isso por nós e estamos interessados em um nível superior em atender à solicitação. E geralmente podemos misturar bancos de dados aqui, podemos enviar solicitações distributivas. E se você pudesse descrever o processo dessa maneira?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word)
(Fonte)Ou, por exemplo, transformações funcionais. O que muitas pessoas gostam na programação funcional é que você pode transmitir dados através de uma série de transformações e obter um código compacto bastante claro, independentemente do idioma em que o escreve. É fácil de ler. O código da imagem é especialmente escrito em F #, mas em geral, provavelmente, todo mundo entende o que está acontecendo aqui.
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~>
(Fonte)Que tal isso então? No exemplo acima, temos uma fonte de dados de origem, que consiste em números inteiros de 1 a 10. Essa é a chamada DSL gráfica (linguagem específica de domínio). Os elementos do idioma do domínio no exemplo acima são símbolos de seta unidirecionais - são operadores adicionais definidos por ferramentas de idioma que mostram graficamente a direção do fluxo. Passamos o Source por uma série de transformações - para facilitar a demonstração, todas adicionam dez ao número. Em seguida, vem a transmissão: multiplicamos os canais, ou seja, cada número entra em dois canais. Em seguida, adicionamos 10 novamente, misturamos nossos fluxos de dados, obtemos um novo fluxo, adicionamos 10 nele também, e tudo isso vai para o nosso fluxo de dados, no qual nada acontece. Este é o código real escrito em Scala, parte do Akka Streams, implementado neste idioma. Ou seja, você especifica as fases da transformação de seus dados, indica o que fazer com eles, especifica a origem, o estoque, alguns pontos de verificação e forma um gráfico usando o DSL gráfico. Isso é todo o código para um único programa. Algumas linhas de código mostram o que está acontecendo no processo.
Vamos esquecer como escrever o código de definição para atores individuais e aprender as primitivas de layout de alto nível que criarão e conectarão os atores necessários dentro de si. Quando executamos esse gráfico, o sistema que fornece o Akka Streams criará o ator necessário por si só, enviará todos esses dados para lá, processará como deve e, eventualmente, os entregará ao destinatário final.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
O exemplo acima mostra como isso pode parecer em C #. A maneira mais simples: temos uma fonte de dados - esses são números de 1 a 1000 (como você pode ver, no Akka Streams, qualquer IEnumerable pode se tornar uma fonte de fluxo de dados, o que é muito conveniente). Fazemos alguns cálculos simples, digamos, multiplicamos por dois e, depois, no fluxo de dados, tudo isso é exibido na tela.
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); });
O que é mostrado no exemplo acima é chamado de "DSL gráfico em C #". De fato, não há gráficos aqui, é uma porta com o Scala, mas no C # não há como definir operadores dessa maneira, por isso parece um pouco mais complicado, mas ainda compacto o suficiente para entender o que está acontecendo aqui. Então, estamos criando um determinado gráfico (existem diferentes tipos de gráfico, aqui é chamado FlowShape) a partir de diferentes componentes, onde há uma fonte de dados e algumas transformações. Enviamos dados para um canal no qual geramos contagem, ou seja, o número de elementos de dados a serem transmitidos, e no outro geramos a soma e depois misturamos tudo. A seguir, veremos exemplos mais interessantes do que apenas processar números inteiros.
Este é o primeiro caminho que pode levá-lo ao Akka Streams, se você tiver experiência em trabalhar com um modelo de ator e tiver pensado em escrever manualmente cada um, mesmo o ator mais simples. A segunda maneira pela qual os Akka Streams chegam é através dos Streams Reativos.
De córregos reativos a córregos Akka
O que são
fluxos reativos ? Esta é uma iniciativa conjunta para desenvolver um padrão para processamento assíncrono de fluxos de dados. Ele define o conjunto mínimo de interfaces, métodos e protocolos que descrevem as operações e entidades necessárias para atingir a meta - processamento assíncrono de dados em tempo real com contrapressão (contrapressão) sem bloqueio. Permite várias implementações usando diferentes linguagens de programação.
O Reactive Streams permite processar um número potencialmente ilimitado de elementos em uma sequência e transferir elementos de forma assíncrona entre componentes com contrapressão sem bloqueio.
A lista de iniciadores da criação de Reactive Streams é bastante impressionante: aqui estão Netflix, Oracle e Twitter.
A especificação é muito simples para tornar a implementação em diferentes idiomas e plataformas o mais acessível possível. Os principais componentes da API do Reactive Streams:
- Publisher
- Assinante
- Assinatura
- Processador
Essencialmente, essa especificação não implica que você começará manualmente a implementar essas interfaces. Entende-se que existem alguns desenvolvedores de bibliotecas que farão isso por você. E o Akka Streams é uma das implementações desta especificação.
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); }
As interfaces, como você pode ver no exemplo, são realmente muito simples: por exemplo, o Publisher contém apenas um método - "inscrever-se". O assinante, Assinante, contém apenas algumas reações ao evento.
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { }
Por fim, a assinatura contém dois métodos - "iniciar" e "recusar". O processador não define nenhum método novo: combina um editor e um assinante.
O que diferencia os Fluxos Reativos de outras implementações de fluxo? O Reativo Reativo combina os modelos push e pull. Para suporte, este é o cenário de desempenho mais eficiente. Suponha que você tenha um assinante de dados lento. Nesse caso, pressionar por ele pode ser fatal: se você enviar uma quantidade enorme de dados, ele não poderá processá-los. É melhor usar pull para que o próprio assinante extraia os dados do editor. Mas se o editor estiver lento, o assinante ficará bloqueado o tempo todo, aguardando o tempo todo. Uma solução intermediária pode ser a configuração: temos um arquivo de configuração no qual determinamos qual deles é mais rápido. E se a velocidade deles mudar?
Portanto, a implementação mais elegante é aquela em que podemos alterar dinamicamente os modelos push e pull.
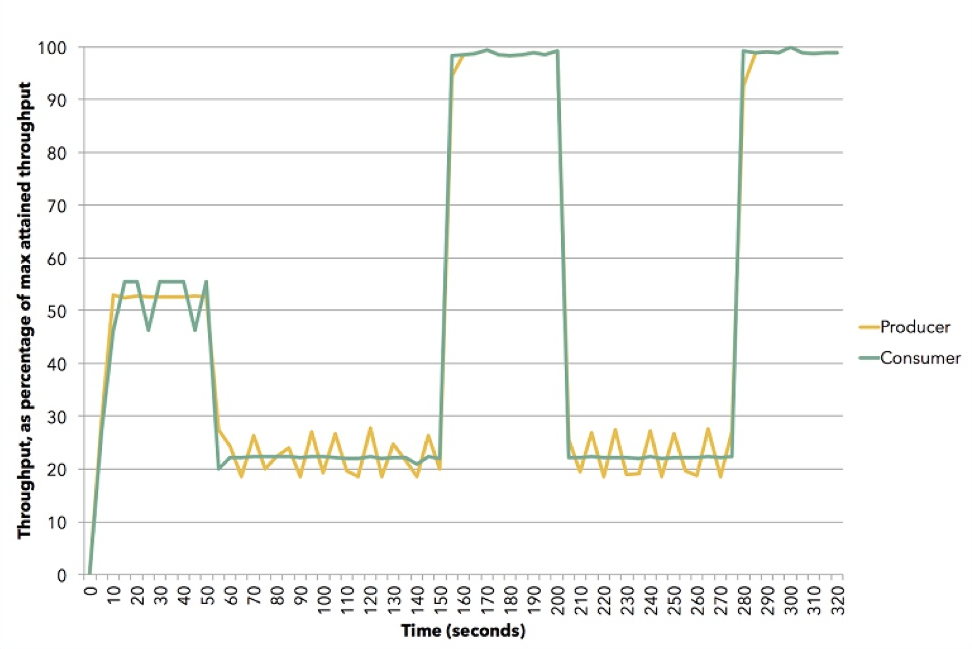 (Origem (Apache Flink))
(Origem (Apache Flink))O diagrama mostra como isso pode acontecer. Esta demonstração usa o Apache Flink. Yellow é um editor, produtor de dados, ele foi definido em cerca de 50% de sua capacidade. O assinante tenta escolher a melhor estratégia - acaba sendo um empurrão. Em seguida, redefinimos o assinante para uma velocidade de cerca de 20% e ele muda para puxar. Então vamos 100%, retornamos novamente 20% ao modelo pull, etc. Tudo isso acontece na dinâmica, você não precisa interromper o serviço, inserir algo na configuração. Esta é uma ilustração de como a contrapressão funciona no Akka Streams.
Princípios do Akka Streams
Obviamente, o Akka Streams não estaria ganhando popularidade se não houvesse blocos embutidos muito fáceis de usar. Existem muitos deles. Eles são divididos em três grupos principais:
- Fonte de dados (Fonte) - estágio de processamento com uma saída.
- Pia é uma etapa de processamento de entrada única.
- Ponto de verificação (fluxo) - estágio de processamento com uma entrada e uma saída. As transformações funcionais ocorrem aqui, e não necessariamente na memória: pode ser, por exemplo, uma chamada para um serviço da web, para alguns elementos do paralelismo, multithread.
Desses três tipos, gráficos podem ser formados. Essas já são etapas de processamento mais complexas, construídas a partir de fontes, drenos e pontos de verificação. Mas nem todo gráfico pode ser executado: se houver buracos, ou seja, entradas e saídas abertas, esse gráfico não será executado.
Um gráfico é um gráfico executável, se estiver fechado, ou seja, haverá uma saída para cada entrada: se os dados foram inseridos, eles devem ter ido para algum lugar.

O Akka Streams possui fontes internas: na imagem, você vê quantas delas. Seus nomes são um por um e refletem o que o Scala ou a JVM possui, com exceção de algumas fontes úteis específicas do .NET. Os dois primeiros (FromEnumerator e From) são alguns dos mais importantes: qualquer numeração, qualquer ienumerável pode ser transformado em uma fonte de fluxo.

Existem drenos internos: alguns deles se parecem com os métodos LINQ, por exemplo, First, Last, FirstOrDefault. Obviamente, tudo o que você obtém pode despejar em arquivos, em fluxos, não no Akka Streams, mas nos fluxos .NET. E, novamente, se você tiver algum ator em seu sistema, poderá usá-lo na entrada e na saída do sistema, ou seja, se desejar, incorpore isso no sistema finalizado.

E há um grande número de pontos de verificação internos, que talvez sejam ainda mais reminiscentes do LINQ, porque aqui existem Select, SelectMany e GroupBy, ou seja, tudo com o qual estamos acostumados a trabalhar no LINQ.
Por exemplo, Select in Scala é chamado SelectAsync: é poderoso o suficiente porque leva o nível de paralelismo como um dos argumentos. Ou seja, você pode indicar que, por exemplo, o Select envia dados para algum serviço da Web em paralelo em dez threads, depois todos são coletados e transmitidos. De fato, você determina o grau de escala do ponto de verificação com uma linha de código.
Uma declaração de fluxo é seu plano de execução, ou seja, um gráfico, mesmo que seja executado, não pode ser executado exatamente assim - ele precisa ser materializado. Deve haver um sistema instanciado, um sistema ator, você deve fornecer um fluxo, esse plano de execução e, em seguida, ele será executado. Além disso, no tempo de execução, ele é altamente otimizado, como quando você envia uma expressão LINQ para um banco de dados: um provedor pode otimizar seu SQL para obter uma saída de dados mais eficiente, substituindo essencialmente o comando query por outro. O mesmo acontece com o Akka Streams: a partir da versão 2.0, é possível definir um certo número de pontos de verificação, e o sistema entenderá que alguns deles podem ser combinados para que sejam executados por um ator (fusão do operador). Os pontos de verificação, como regra, mantêm a ordem dos elementos de processamento.
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
A materialização do fluxo pode ser comparada com o último elemento ToList na expressão LINQ no exemplo acima. Se não escrevermos ToList, obteremos uma expressão LINQ não materializada que não fará com que os dados sejam transferidos para o servidor SQL ou Oracle, pois a maioria dos provedores LINQ oferece suporte à chamada execução adiada da consulta (execução atrasada da consulta), t ou seja, a solicitação é executada apenas quando um comando é fornecido para fornecer algum resultado. Dependendo do que for solicitado - uma lista ou o primeiro resultado - a equipe mais eficaz será formada. Quando dizemos ToList, solicitamos ao provedor LINQ que nos forneça o resultado final.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
O Akka Streams funciona da mesma maneira. Na figura está o gráfico lançado, que consiste em uma fonte de pontos de verificação e escoamento, e agora queremos executá-lo.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); }
Para que isso aconteça, precisamos criar um sistema de atores, nele existe um materializador, passa nosso gráfico para ele e ele o executa. Se o recriarmos, ele será executado novamente e outros resultados poderão ser obtidos.
Além da materialização do fluxo, falando sobre a parte material do Akka Streams, vale mencionar os valores materializados.
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right);
Quando temos um fluxo que vai da fonte através dos pontos de verificação até o dreno, se não solicitarmos valores intermediários, eles não estarão disponíveis para nós, pois ele será executado da maneira mais eficiente. É como uma caixa preta. Mas pode ser interessante extrairmos alguns valores intermediários, porque em cada ponto à esquerda entram alguns valores, outros saem à direita e você pode especificar um gráfico para indicar em que está interessado. No exemplo acima, um gráfico de introdução no qual NotUsed é indicado, ou seja, nenhum valor materializado nos interessa. Abaixo, criamos com a indicação de que, no lado direito do escoamento, ou seja, após todas as transformações terem sido concluídas, precisamos fornecer valores materializados. Obtemos o gráfico Tarefa - uma tarefa, após a conclusão da qual obtemos um int, ou seja, o que acontece no final deste gráfico. Você pode indicar em cada parágrafo que precisa de algum tipo de valor materializado, tudo isso será coletado gradualmente.
Para transferir dados para os fluxos do Akka Streams ou para tirá-los de lá, é claro, é necessário algum tipo de interação com o mundo exterior. Os estágios de origem incorporada contêm uma ampla variedade de fluxos de dados reativos:
- Source.FromEnumerator e Source.From permitem transferir dados de qualquer fonte que implemente IEnumerable;
- Unfold e UnfoldAsync geram os resultados dos cálculos de funções, desde que retornem valores diferentes de zero;
- FromInputStream transforma um fluxo;
- FromFile analisa o conteúdo do arquivo no fluxo reativo;
- ActorPublisher converte mensagens de ator.
Como eu já disse, para desenvolvedores .NET é muito produtivo usar o Enumerator ou o IEnumerable, mas às vezes é muito primitivo, muito ineficiente para acessar dados. Origens mais complexas que contêm uma grande quantidade de dados requerem conectores especiais. Tais conectores são escritos. Existe um projeto de código aberto Alpakka, que apareceu originalmente no Scala e agora está no .NET. Além disso, o Akka possui os chamados atores persistentes e eles têm seus próprios fluxos que podem ser usados (por exemplo, o Akka Persistence Query forma o fluxo de conteúdo do Akka Event Journal).

Se você trabalha com a Scala, a maneira mais fácil é para você: há um grande número de conectores e você certamente encontrará algo ao seu gosto. Para informação, Kafka é o chamado Kafka Reativo, não Kafka Streams. O Kafka Streams, até onde eu sei, não suporta contrapressão. O Kafka reativo é uma implementação de fluxo do Kafka que suporta Fluxos reativos.
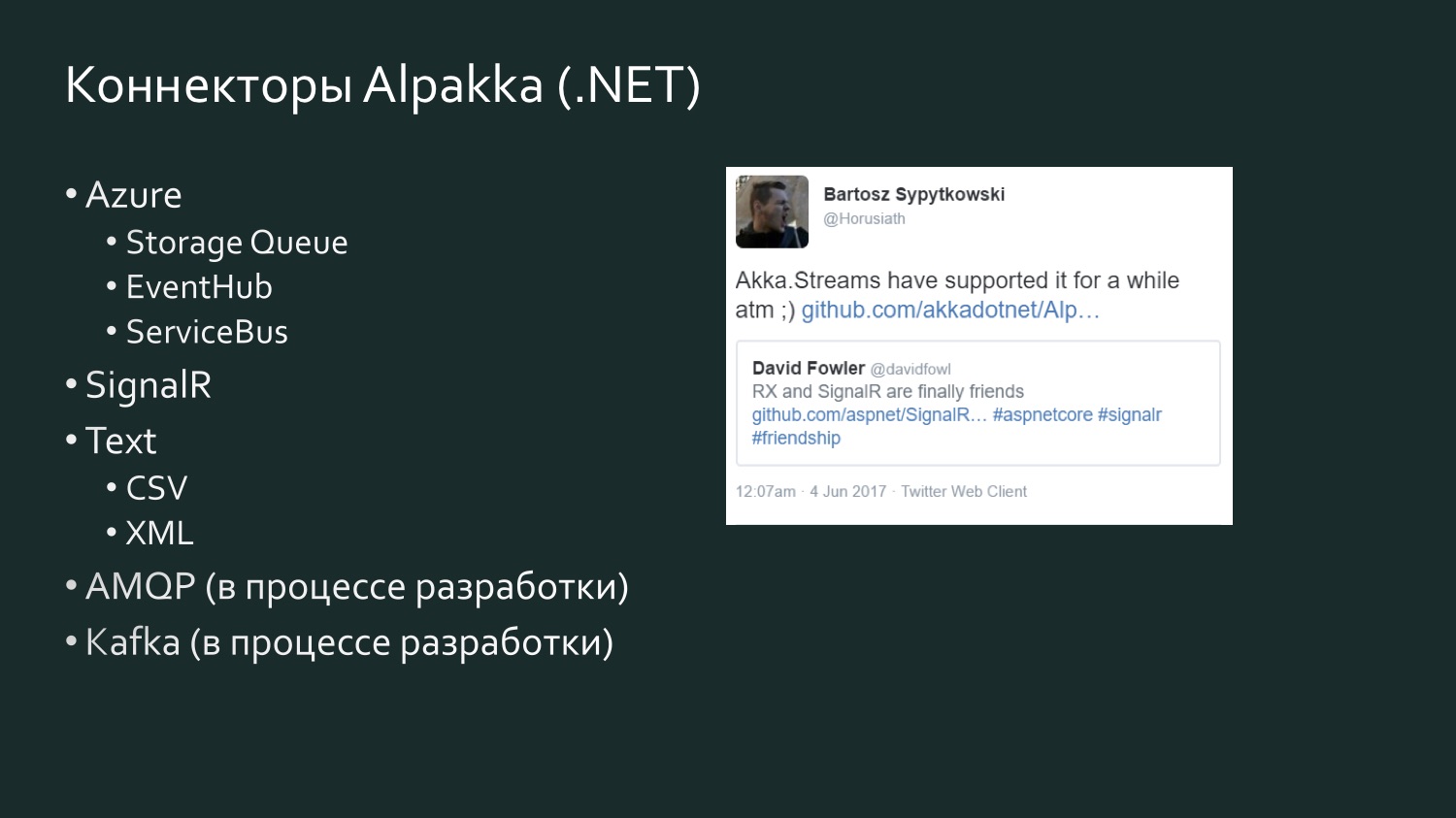
A lista de conectores Alpakka .NET é mais modesta, mas é reabastecida e há um elemento de competição. Há um tweet de seis meses de David Fowler, da Microsoft, que disse que o SignalR agora pode trocar dados com o Reactive Extensions, e um dos desenvolvedores da Akka respondeu que ele já estava no Akka Streams há algum tempo. Akka suporta vários serviços do Microsoft Azure. O CSV é o resultado da frustração de Aaron Stannard quando ele descobriu que não há um bom fluxo para o CSV: agora a Akka tem seu próprio fluxo para o XML do CSV. Existe o AMQP (na realidade, o RabbitMQ), ele está em desenvolvimento, mas está disponível para uso, funciona. Kafka também está em desenvolvimento. Esta lista continuará a se expandir.
Algumas palavras sobre as alternativas, pois se você trabalha com fluxos de dados, o Akka Streams não é, obviamente, a única maneira de lidar com esses fluxos. Provavelmente, no seu projeto, a escolha de como implementar threads dependerá de muitos outros fatores que podem se tornar fundamentais. Por exemplo, se você trabalha muito com o Microsoft Azure e o Orleans é incorporado de forma orgânica às necessidades do seu projeto, com o suporte a atores virtuais ou, como eles os chamam, grãos, eles têm sua própria implementação que não atende à especificação de Reativos - Orleans Streams, que será o mais próximo para você e faz sentido prestar atenção a ele. Se você trabalha muito com o TPL, existe o TPL DataFlow - essa pode ser a analogia mais próxima do Akka Streams: ele também possui primitivas para compor fluxos de dados, além de ferramentas de buffer e limitação de largura de banda (BoundedCapacity, MaxMessagePerTask). Se as idéias do modelo do ator estão próximas de você, o Akka Streams é uma maneira de resolver isso e economizar uma quantidade significativa de tempo sem precisar escrever cada ator manualmente.
Exemplo de implementação: Fluxo de Log de Eventos
Vejamos alguns exemplos de implementação.
O primeiro exemplo não está implementando diretamente um fluxo, é como usar um fluxo. Esta foi a nossa primeira experiência com o Akka Streams, quando descobrimos que, de fato, podemos assinar um fluxo que simplificará muito para nós.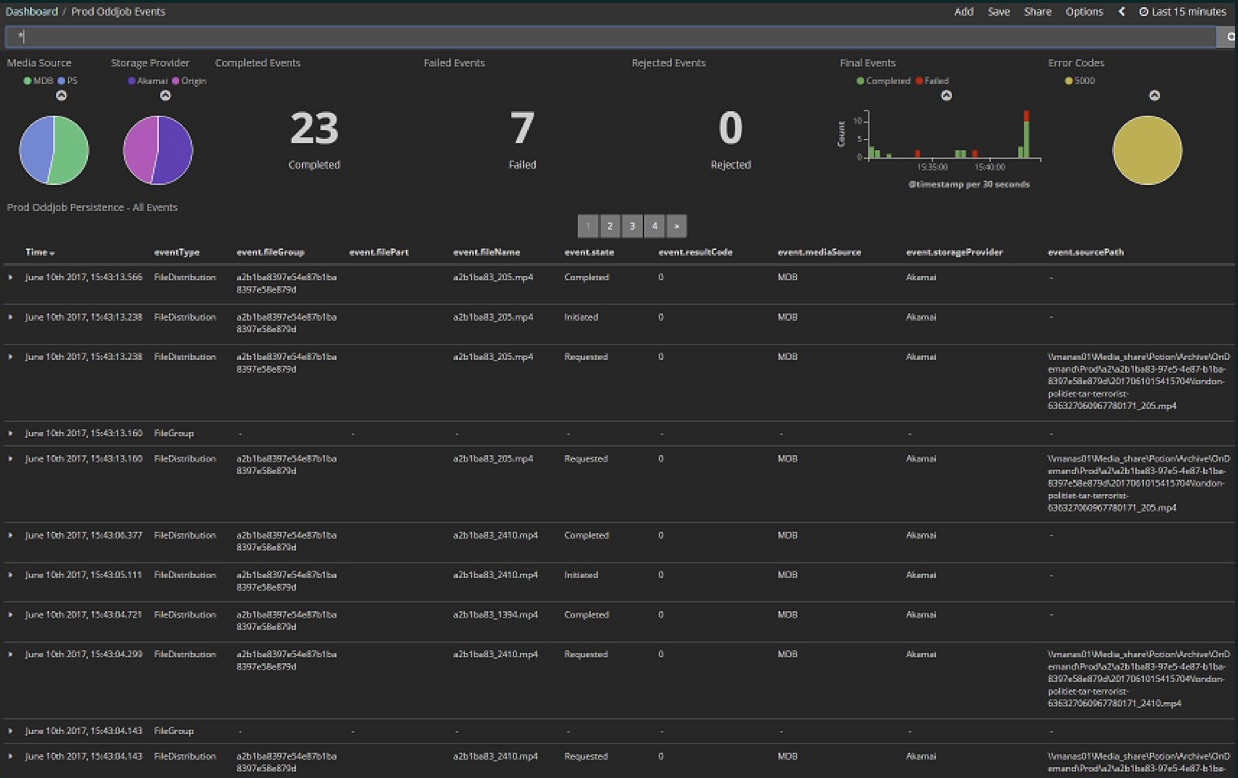 Carregamos vários arquivos de mídia na nuvem. Esta foi uma fase inicial do projeto: aqui nos últimos 15 minutos 23 arquivos, dos quais 7 erros. Agora praticamente não há erros e o número de arquivos é muito maior - centenas passam a cada poucos minutos. Tudo isso está contido no Painel Kibana.
Carregamos vários arquivos de mídia na nuvem. Esta foi uma fase inicial do projeto: aqui nos últimos 15 minutos 23 arquivos, dos quais 7 erros. Agora praticamente não há erros e o número de arquivos é muito maior - centenas passam a cada poucos minutos. Tudo isso está contido no Painel Kibana.Kibana Elasticsearch , Elasticsearch , , , , . , , , . . . (event journal) Akka, Microsoft SQL Server. , .
CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) )
, , , , SQL Server, eventstore Akka, eventJournal. eventstore.
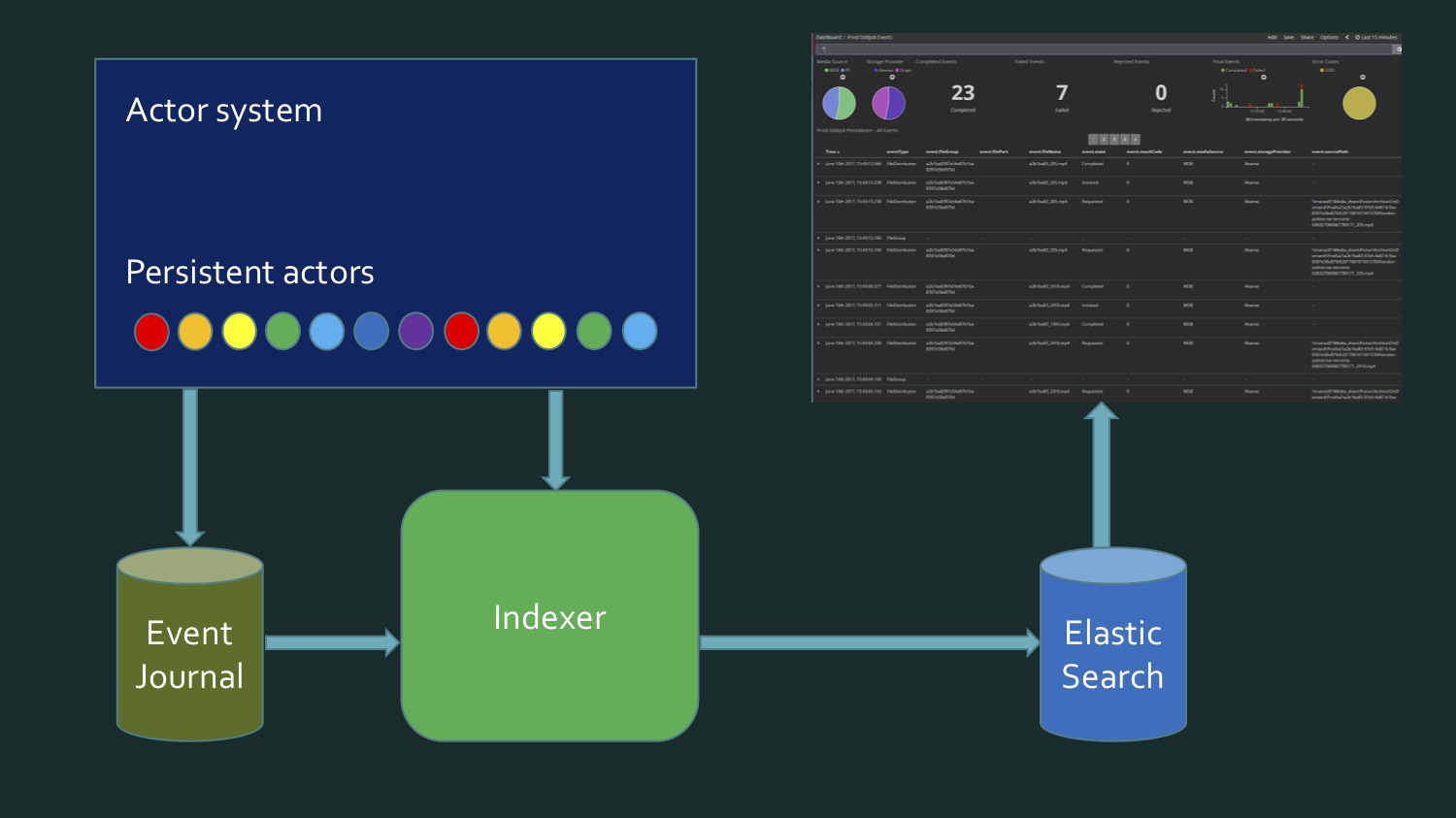
, . , , , , - : , . , . . . - . , . , . , Akka persistence query.
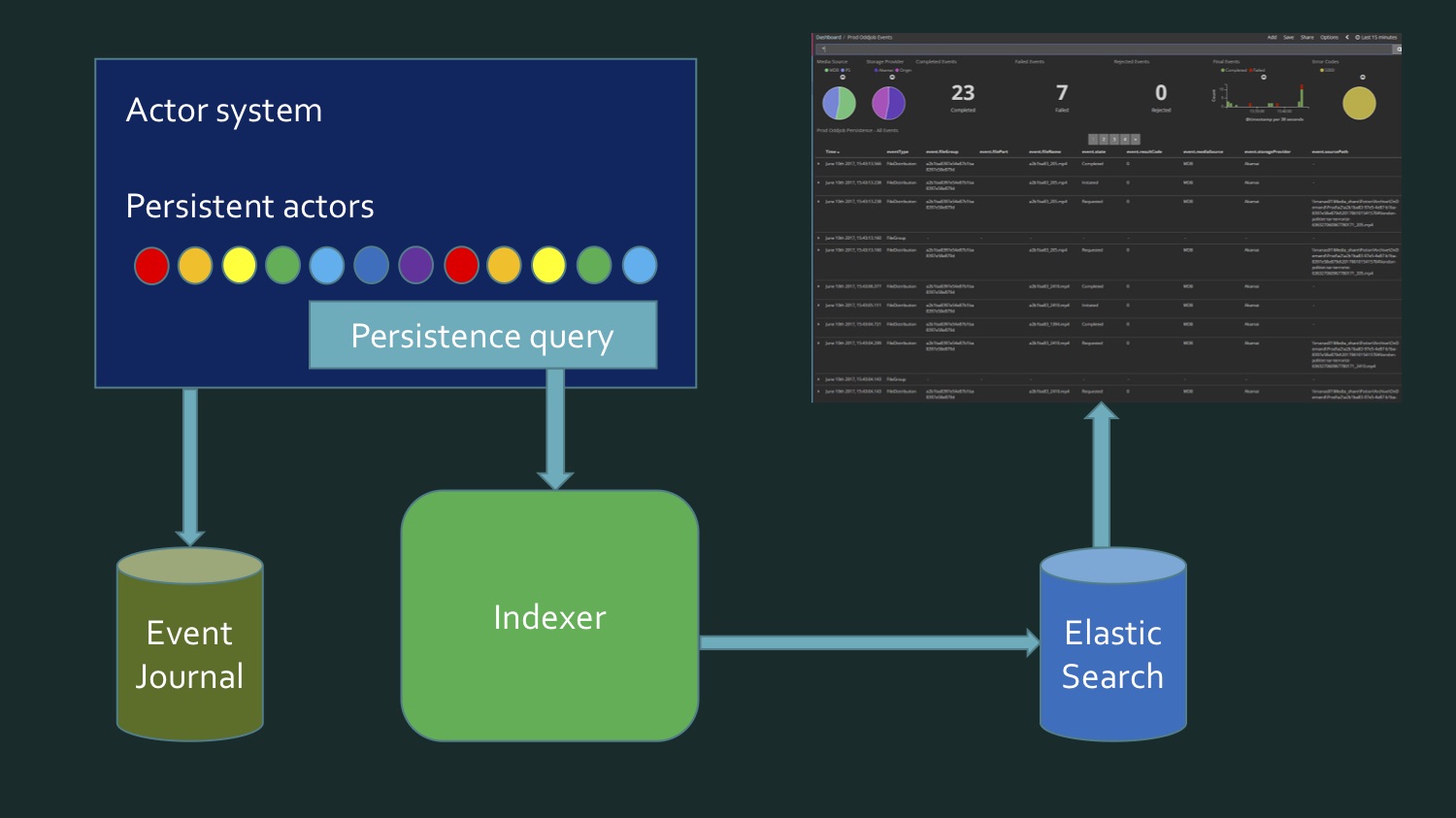
, , .
(persistence queries):
- AllPersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
, , , Current — , . — . EventsByTag.
let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid
, . F#, C# . EventsByTag, Akka Streams, , Elasticsearch. . . - , , , — . .
. , , , , Twitter , — , , , . , Akka Streams.
:
Akka Scala, Akka.NET, , , , , . . - .
Tweetinvi — , Twitter, . Reactive Streams, . . , , , , - Akka, , .

, , . . Broadcast-. , , . : , , , , .
GitHub-,
AkkaStreamsDemo . (
).
Vamos começar com um simples. Twitter: Program.cs
var useCachedTweets = false
Caso eu seja banido do Twitter, tenho tweets em cache, eles são mais rápidos. Para começar, criamos alguns RunnableGraph. public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); }
( Fonte )Temos uma fonte de tweets aqui, que vem de um ator. Vou mostrar a você como puxamos esses tweets para lá, formatamos (o formato de tweet dá um tweet ao autor) e depois escrevemos na tela.StartTweetStream - aqui usaremos a biblioteca Tweetinvi. public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); }
(
)
CreateSampleStream , . , , , : « ». IEnumerable, .
TweetEnumerator : , Current, MoveNext, Reset, Dispose, . , . , . .
useCachedTweets true, . CashedTweets — , 50000 , , , . , , . — . , .
TweetsWithBroadcast:
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
Scala, , DSL. Broadcast — out(0), out(1) — CreatedBy, , . .
— . .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });}
(
)
10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
, SelectAsync, . , , 5: , 5 , , . , , .
public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); }
(
)
. -, , - , HttpClient , XML, , .
,
, , . 10 10 , , .
, — , . , Akka Streams, , . , , .
, , , Akka Streams, . , , Akka Streams, C# , , , , .
 Que idéias sobre o Akka Streams eu gostaria que você criasse depois de ler este artigo? No DotNext 2017 Moscou, eu estava em uma apresentação de Alex Thyssen
Que idéias sobre o Akka Streams eu gostaria que você criasse depois de ler este artigo? No DotNext 2017 Moscou, eu estava em uma apresentação de Alex Thyssen Azure Functions. - , deployment, , ( - , , ), . , , , . , , Akka Streams, .. , . .
Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap».
, .
This is the Akka Stream.
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
This is the Sink that is filled from the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
. — 22-23
DotNext 2018 Moscow , .
( ).