De 19 a 21 de abril, a conferência C ++ Rússia 2018 foi realizada em São Petersburgo. De ano para ano, a organização e a conduta se tornam um nível superior, o que é uma boa notícia. Agradeço ao organizador permanente da C ++ Russia Sergey Platonov por sua contribuição para o desenvolvimento desta área.
No dia 19 de abril, foram planejadas aulas de mestrado, das quais, infelizmente, não pudemos comparecer, e nos dias 20 e 21, foi realizado o principal programa da conferência, do qual participamos com grande interesse. Sergey
Sermp fez um ótimo trabalho e atraiu vários oradores estrangeiros notáveis como oradores. O primeiro dia da conferência foi aberto por Jon Kalb, organizador do CppCon e autor do C ++ Today: The Beast is Back. O segundo dia começou com uma apresentação de Daveed Vandevoorde, membro do comitê de padronização, um dos autores do C ++ Templates: The Complete Guide. Andrei Alexandrescu estava no centro das atenções, que, depois de seu relatório sobre exceções, em certo momento reuniu uma multidão de pessoas que queriam obter um autógrafo e tirar uma foto conjunta. Pela primeira vez, uma palestra de Herb Sutter foi transmitida no Skype sobre o operador de nave espacial para C ++ 20.
Embora a conferência tenha ocorrido há mais de três meses, o vídeo (
lista de reprodução completa ) foi postado agora, então é hora de atualizar suas memórias e mergulhar nos incríveis recursos do C ++.
Essa palestra aborda por que os engenheiros que procuram desempenho escolhem C ++. Jon apresenta uma perspectiva histórica do C ++, concentrando-se no que está acontecendo na comunidade C ++ no momento e para onde está indo a linguagem e sua base de usuários. Com um interesse renovado no desempenho para data centers e dispositivos móveis, e com o sucesso das bibliotecas de software de código aberto, o C ++ está de volta e está quente. Essa palestra explica por que o C ++ é a linguagem preferencial dos engenheiros de software para desempenho. Você receberá um esboço histórico aproximado que coloca o C ++ em perspectiva e cobre sua popularidade altos e baixos.

Pares de iteradores são onipresentes em toda a biblioteca C ++. É geralmente aceito que a combinação desse par em uma única entidade, geralmente denominada Range, fornece código mais conciso e legível. A definição da semântica precisa desse conceito de alcance é surpreendentemente complicada. As considerações teóricas conflitam com as práticas. Alguns objetivos de design são completamente incompatíveis.
Todos sabemos que devemos conhecer os algoritmos STL. Incluí-los em nossos projetos nos permite tornar nosso código mais expressivo e mais robusto. E às vezes, de uma maneira espetacular.
Mas você conhece seus algoritmos STL?
Nesta palestra, o autor apresenta 105 algoritmos que o STL possui atualmente, incluindo os adicionados em C ++ 11 e C ++ 17. Porém, mais do que apenas uma lista, o objetivo desta palestra é apresentar os diferentes grupos de algoritmos, os padrões que eles formam no STL e como os algoritmos se relacionam.
Esse tipo de quadro geral é a melhor maneira de lembrar de todos eles e constitui uma caixa de ferramentas repleta de maneiras de tornar nosso código mais expressivo e robusto.
Sempre quis modificar algum valor ou executar alguma instrução enquanto seu programa C ++ está sendo executado apenas para testar algo - não é trivial ou possível com um depurador? As linguagens de script possuem um REPL (read-eval-print-loop). A coisa mais próxima que o C ++ tem é o apego (desenvolvido por pesquisadores do CERN), mas é construído sobre o LLVM e é muito complicado de configurar. O RCRL (Read-Compile-Run-Loop) é um projeto de demonstração que mostra uma abordagem inovadora para fazer a compilação de C ++ em tempo de execução de uma maneira independente de plataforma e compilador, que pode ser facilmente incorporada. Nesta apresentação, é mostrado como usá-lo, como funciona e como pode ser modificado e integrado a qualquer aplicativo e fluxo de trabalho.

Não seria bom se tivéssemos um tipo C ++ padrão para representar strings? Oh, espere ... nós fazemos: std :: string. Não seria bom se pudéssemos usar esse tipo padrão em todo o nosso aplicativo / projeto? Bem ... não podemos! A menos que esteja escrevendo um aplicativo ou serviço de console. Mas, se estivermos escrevendo um aplicativo com GUI ou interagindo com APIs de SO modernas, é provável que precisemos lidar com pelo menos um outro tipo de string C ++ não padrão. Dependendo da plataforma e do projeto, pode ser CString do MFC ou ATL, Platform :: String do WinRT, QString do Qt, wxString do wxWidgets, etc. Ah, não vamos esquecer nosso velho amigo const char *, melhor ainda const wchar_t * para a família C de APIs ...
Então, acabamos com dois tipos de string em nossa base de código. OK, isso é gerenciável: mantemos std :: string para todo o código independente de plataforma e convertemos para o outro XString ao interagir com APIs do sistema ou código da GUI. Faremos algumas cópias desnecessárias ao atravessar esta ponte e terminaremos com algumas funções engraçadas manipulando dois tipos de strings; mas isso é cola, enfim ... certo?
É um bom plano ... até que nosso projeto cresça e acumulemos muitos utilitários e algoritmos de string. Restringimos esses itens algorítmicos a std :: string? Nós recorremos ao denominador comum const char * e perdemos a segurança de tipo / memória do nosso tipo C ++? O C ++ 17 std :: string_view é a resposta para todos os nossos problemas de string?
O autor tenta explorar as opções, em conjunto, com um estudo de caso em um aplicativo Windows de 15 anos: Advanced Installer (www.advancedinstaller.com) - um projeto C ++ desenvolvido ativamente, modernizado para C ++ 17, graças ao clang-tidy e "Clang Power Tools" (
www.clangpowertools.com) ...
Escrever código resiliente a erros sempre foi um problema em todos os idiomas. As exceções são os meios politicamente corretos para sinalizar erros no C ++, mas muitos aplicativos ainda recorrem a códigos de erro por motivos relacionados à facilidade de entendimento, facilidade de manipulação de erros localmente e eficiência do código gerado.
Esta palestra mostra como uma variedade de artefatos teóricos e práticos podem ser combinados para abordar códigos de erro e exceções em um pacote simples e saudável. O tipo genérico Expected pode ser usado para modos local (estilo de código de erro) e centralizado (estilo de exceção), utilizando os pontos fortes de cada um.

Software com lógica de negócios muito complexa, como jogos, sistemas CAD e sistemas corporativos, geralmente precisa compor e modificar objetos em tempo de execução - por exemplo, para adicionar ou substituir um método em um objeto existente. O C ++ padrão possui tipos rígidos que são definidos em tempo de compilação e dificultam isso. Por outro lado, linguagens com tipos dinâmicos como lua, Python e JavaScript tornam isso muito fácil. Portanto, para manter o código legível e de manutenção e para cumprir requisitos complexos de lógica de negócios, muitos projetos usam essas linguagens ao lado do C ++. Algumas desvantagens dessa abordagem incluem a complexidade adicionada em uma camada de ligação de idioma, a perda de desempenho do uso de uma linguagem interpretada e a inevitável duplicação de código para muitas funcionalidades de utilidades pequenas.
O DynaMix é uma biblioteca que tenta remover, ou pelo menos reduzir bastante, a necessidade de uma linguagem de script separada, permitindo que os usuários componham e modifiquem objetos polimórficos em tempo de execução em C ++. Essa palestra elabora esse problema e apresenta a biblioteca e seus principais recursos a usuários ou pessoas em potencial que podem se beneficiar da abordagem com um exemplo anotado e uma pequena demonstração.

No C ++, você pode resolver uma única tarefa de várias maneiras. O autor escolhe uma tarefa real da produção e investiga como ela pode ser resolvida com várias ferramentas fornecidas pelo C ++: contêineres STL, boost.range, intervalos C ++ 20, corotinas. Ele também compara as restrições da API e o desempenho de diferentes soluções, e como elas podem ser facilmente convertidas de uma para outra, se o código estiver bem estruturado. Durante o processo, o autor também explora aplicativos de alguns recursos úteis do C ++ 17, como constexpr if, instruções de seleção com inicializador, std :: not_fn, etc. É dada atenção especial aos algoritmos de tópicos padrão.

A programação paralela é um tópico muito multifacetado e profundo. Ao longo das décadas de pesquisa, um grande número de abordagens, práticas e ferramentas foi desenvolvido, mas dificilmente podemos assumir que a linguagem C ++ acompanhou essas tendências. Começando com o padrão C ++ 11, conceitos como std :: thread, std :: atomic, std :: future, std :: mutex foram introduzidos e, no futuro, espera-se a adição de corotinas, um modelo de cálculos assíncronos. Bem, essas são coisas interessantes para estudar, mas o relatório se concentrará em uma idéia completamente diferente.
A Memória Transacional de Software (STM) - o conceito de um modelo de dados mutável transacionalmente - existe há muito tempo e possui várias implementações para todos os idiomas. Usando o STM, você expressa seu modelo de dados e inicia a mudança em vários segmentos, competitivamente, sem ter que se preocupar com a sincronização de segmentos, o estado válido dos dados ou bloqueios. STM fará tudo por você. Isso parece muito bom, mas nem todas as bibliotecas STM são igualmente úteis. Os STMs imperativos tradicionais são muito complexos, propensos a erros multithread não triviais e difíceis de usar. Por outro lado, no mundo da programação funcional, o conceito de STM combinatório já existe há muito tempo, transações nas quais são tijolos compostáveis, a partir das quais você constrói transações de um nível superior. A abordagem combinatória do STM permite expressar um modelo de dados competitivo de maneira mais flexível, clara e confiável. A programação paralela também pode ser agradável!
No relatório, o autor falará sobre os recursos do STM combinatório, como usá-lo e como ele pode ser implementado no C ++ 17.
Ao longo de toda a história da programação, o processamento seqüencial de vários tipos de coleções tem sido e ainda é uma das tarefas práticas mais comuns. A representação interna das coleções, bem como o algoritmo usado para buscar elementos subseqüentes, podem variar em uma variedade muito ampla: matriz, lista vinculada, árvore, tabela de hash, arquivo e outros. No entanto, por trás da variedade de idiomas, funções de biblioteca padrão, soluções ad-hoc, pode-se revelar a essência que permanece invariável para toda essa classe de tarefas. Esta palestra tem como objetivo mostrar uma transição passo a passo de algoritmos baseados na descrição explícita de ações sobre elementos individuais para ferramentas de processamento declarativas de alto nível que tratam uma coleção como uma entidade e revelam adequadamente a lógica do domínio.
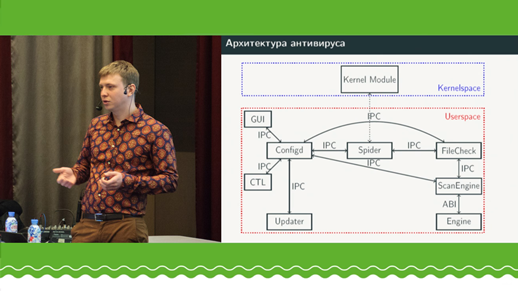
O autor contará sobre sua experiência no desenvolvimento de um mecanismo antivírus em C ++ na forma de uma biblioteca compartilhada. Um recurso exclusivo é a ausência de dependências externas (tempo de execução C ++ ou C). Todo esse grupo é criado com base no uso de uma cadeia de ferramentas personalizada no GCC para um destino especial, que o libc newlib vai usar para o mesmo destino, além do qual o libstdc ++ é criado. Assim, a biblioteca compartilhada é montada por meio de uma cadeia de ferramentas customizada com libgcc_s, libc, libcstdc ++ customizada (alterações apenas na montagem). Toda interação com o tempo de execução é por meio da biblioteca compartilhada ABI. Portanto, a biblioteca mantém a capacidade de usar C ++ moderno completo sem restrições (RTTI, exceções, iostream, etc.), que vai para libstdc ++ libc (newlib) | l ibgcc-ABI. Uma abordagem semelhante foi testada nas cadeias de ferramentas GCC / newlib / libstdc ++ para Linux e clang / newlib / libc ++ para MacOS. O relatório pode ser de interesse para quem deseja usar C ++ em bibliotecas compartilhadas, mas não pode pagá-lo devido a dependências externas.

No último ano e meio, o autor liderou a criação da especialização Coursera em C ++ moderno. A especialização consistirá em cinco cursos, dois dos quais já estão em execução e outro está quase pronto.
O relatório dirá:
- que problemas podem ser encontrados no trabalho em cursos (por exemplo, após 3 meses de trabalho, os desenvolvedores jogaram fora todo o material e começaram de novo)
- como o currículo é formado e por que exatamente (por exemplo, por que a palavra "ponteiro" não soou nos dois primeiros cursos nem uma vez)
Além disso, durante o trabalho de especialização, foi desenvolvido um conjunto de princípios aplicáveis ao trabalho cotidiano:
- no processo de integração de um novo funcionário ao projeto
- durante a revisão de código
- ao contratar
Portanto, o autor não apenas quer dizer como se especializa, mas também tenta transferir a experiência adquirida para as tarefas diárias.
Não é segredo que o desenvolvimento em C / C ++ tem requisitos muito mais altos para a qualidade do código do que o desenvolvimento em Java. A probabilidade de cometer um erro fatal é muito maior. Ao mesmo tempo, coletar informações sobre esses erros é uma tarefa não trivial, mesmo para programadores experientes.
Na primeira parte do relatório, analisaremos brevemente os desenvolvimentos existentes: como o depurador interno do Android funciona, que soluções já existem. A segunda parte é dedicada à história de como funciona "por baixo do capô": como obter o estado do processador no momento do erro, como relaxar a pilha de chamadas, como descobrir os números de linha no código-fonte. Uma visão geral das bibliotecas de promoção de pilha, como libcorkscrew, libunwind, libunwindstack, será fornecida.
O relatório será de interesse dos desenvolvedores do Android, cujos aplicativos usam NDK, e de todos os outros para ampliar seus horizontes.
int * ptr = novo int;
* ptr = 42;
delete ptr;
O que realmente acontece quando essas três linhas de código são executadas? Examinaremos o alocador de memória, o sistema operacional e o hardware moderno para dar uma resposta exaustiva a esta pergunta.
Em 2017, a questão de escolher um alocador em C ++ não perde relevância. Eles adicionaram uma nova maneira ao padrão de escolher um alocador local para contêineres (std :: pmr), tcmalloc global e jemalloc continuam a evoluir, bem como as interfaces do kernel nas quais eles dependem. Este relatório é dedicado ao "andar inferior" deste design: os recursos do mmap e do madvise no kernel Linux e o impacto desses recursos no desempenho dos alocadores.

A nova nave espacial foi adotada recentemente como um recurso de linguagem para C ++ 20. Nesta palestra, o designer e autor da proposta da nave espacial fornece uma visão geral do recurso, discute sua motivação e design e apresenta exemplos de como usá-lo. Ele enfatiza particularmente como o recurso torna o código C ++ mais limpo para escrever e ler, mais rápido, evitando trabalhos redundantes e mais robusto, evitando várias armadilhas importantes, porém sutis, no código mais frágil que anteriormente tínhamos que escrever manualmente sem esse recurso.

Quando você olha para modelos, reflexão, geração de código no estágio de compilação, metaclasses, você sente que o C ++ se propôs a tarefa de "ocultar" o código final do desenvolvedor o máximo possível. Um uso não trivial do pré-processador (e várias ramificações) pode tornar a sequência do programa muito óbvia. Obviamente, essas abordagens salvam os desenvolvedores de copiar e colar sem fim e repetir partes semelhantes da base de código, mas requerem suporte mais avançado nas ferramentas de desenvolvimento.
É possível depurar o código sem reiniciá-lo continuamente, sem um depurador e mesmo sem uma compilação simples de toda a base de código? É possível encontrar erros no código que não podem ser montados ou executados na máquina local? Existe! Os Ambientes de Desenvolvimento Integrado (IDEs) têm amplo conhecimento e entendimento do código personalizado e são eles que podem fornecer as ferramentas apropriadas.
Este relatório mostrará como se pode “depurar” as substituições de macro aninhadas pelo typedef, entender os tipos de variáveis (que no C ++ moderno são frequentemente “ocultas”), depurar diferentes ramos do pré-processador ou sobrecarga do operador e muito mais com a ajuda de um software verdadeiramente inteligente. IDE Alguns dos recursos já estão disponíveis no CLion e ReSharper C ++, e alguns são apenas idéias interessantes para o futuro, que seriam interessantes para discutir com o público.

A montagem de um projeto C ++ pode ser movida dentro do contêiner do docker, enquanto em vez de instalar as bibliotecas e dependências necessárias no sistema host, eles podem ser instalados diretamente na imagem do docker (por exemplo, Cuda) ou instalados usando o gerenciador C ++ da biblioteca Conan (por exemplo, Impulso). Isso resulta em um ambiente controlado (e sempre o mesmo) isolado para a montagem, no qual você pode conectar o cache do Conan, para que projetos diferentes usando as mesmas bibliotecas usem as mesmas montagens. Além disso, a construção não depende mais da distribuição Linux em que o projeto está sendo construído, o principal é que você pode executar o Docker nessa distribuição.

No decorrer do relatório, escreveremos uma pequena biblioteca de trabalho com std :: tuple. Usando esta biblioteca, compilamos o tempo de compilação em uma tabela de hash heterogênea. Além disso - em sua base, escreveremos uma pequena estrutura RPC, usando o fato de não termos apagamento de tipo.
Haverá muitos cálculos constexpr, modelos e novos recursos no C ++ 17 (especificamente, se constexpr).
Muitas vezes, é necessária reflexão para generalizar algoritmos de serialização. Implementação de vários protocolos, trabalho com bancos de dados. Para resolver esses problemas, escrevemos um compilador homebrew IDL para gerar estruturas C ++ e uma biblioteca para interagir com o resultado. Protobuf com pedais e se valeu a pena.
Há algum tempo, o comitê de padronização do C ++ criou um subgrupo "SG-7" para explorar como adicionar recursos de reflexão à linguagem. Mais recentemente, esse grupo adicionou "metaprogramação" ao seu prato e tomou algumas decisões significativas em relação ao formato da solução final. Nesta palestra, o autor examina o passado que nos trouxe aqui e examina um possível caminho para o suporte de primeira classe de C ++ à "metaprogramação reflexiva".
Com os conceitos sendo adicionados à próxima revisão do C ++, espera-se que novos conceitos sejam definidos. Cada conceito define um conjunto de operações usadas pelo código genérico. Um desses usos pode ser um teste genérico, verificando se todas as partes de um conceito estão definidas e verificando interações genéricas entre as operações de um conceito. O ideal é que esse teste funcione com classes apenas modelando parcialmente um conceito para orientar a implementação de classes.
Esta apresentação não usa as extensões de conceito reais, mas mostra como testes genéricos podem ser criados usando os recursos do C ++ 17. Para os testes genéricos, o idioma de detecção e o constexpr são usados para determinar a disponibilidade das operações necessárias e lidar com a abundância de operações. Os testes genéricos devem ser capazes de cobrir o básico de classes que modelam um conceito. Obviamente, o comportamento específico das classes ainda exigirá testes correspondentes.

A programação paralela pode ser usada para tirar proveito das arquiteturas multicêntricas e heterogêneas e pode aumentar significativamente o desempenho do software. O C ++ moderno foi um longo caminho para tornar a programação paralela mais fácil e mais acessível; fornecendo abstrações de alto e baixo nível. O C ++ 17 leva isso adiante, fornecendo algoritmos paralelos de alto nível, e muito mais é esperado no C ++ 20. Esta palestra fornece uma visão geral dos atuais utilitários de paralelismo disponíveis e analisa o futuro de como GPUs e sistemas heterogêneos podem ser suportados por meio de novos recursos de biblioteca padrão e outros padrões como SYCL.
A linguagem C ++ e a infraestrutura em torno dela continuam evoluindo, o que torna essa linguagem uma das ferramentas mais eficazes no momento. Gostaria de destacar três fatores que tornam a linguagem C ++ agora tão atraente.
- Primeiro: inovações no padrão da linguagem, permitindo escrever código eficiente.
- Segundo: a maturidade das ferramentas de desenvolvimento e um aumento na velocidade de montagem dos projetos.
- Terceiro: ferramentas de suporte avançadas que permitem controlar a qualidade do código e outros aspectos do ciclo de vida do projeto.
Este relatório é uma ode à linguagem de programação C ++!
No campo do desenvolvimento de aplicativos multithread ou distribuídos altamente carregados, é possível ouvir cada vez mais conversas sobre código assíncrono, incluindo especulações sobre a necessidade (falta de necessidade) de levar em consideração a assincronia no código, sobre a compreensibilidade (incompreensibilidade) do código assíncrono e sua eficiência (ineficiência). Neste relatório, tentaremos aprofundar a área de assunto: analisaremos o que é assincronia; quando surge; como isso afeta o código que escrevemos e a linguagem de programação que usamos. Vamos tentar descobrir o que os futuros e promessas têm a ver com isso, vamos falar um pouco sobre corotinas e atores. Iremos afetar o JavaScript e os sistemas operacionais. O objetivo do relatório é tornar mais explícitos os compromissos que surgem com uma ou outra abordagem para o desenvolvimento de software distribuído ou multithread.

O relatório discutirá o estado atual do WebAssembly em relação a produtos reais. Falaremos sobre nossa experiência de portar o aplicativo, sobre quais problemas surgiram e como os resolvemos.
Os tópicos abordados incluem:
- Suporte para o padrão em diferentes plataformas e navegadores.
- Desempenho e tamanho da construção versus asm.js.
- Interações com o navegador.
- Construir falhas do usuário.
- Recursos da VM.
O sistema de criação do CMake está gradualmente se tornando o padrão de fato para a programação C ++ entre plataformas. No entanto, muitas vezes é criticado de maneira justa, incluindo a linguagem de script inconveniente, a documentação desatualizada e o fato de que as mesmas tarefas podem ser executadas de maneiras diferentes, e pode ser bastante difícil entender qual é a mais correta em uma situação específica . O autor dirá:- anti-padrões populares freqüentes e por que eles são ruins,
- em que níveis de abstração o CMake funciona e quando "vazam",
- o que é o "Modern CMake" e quais são suas vantagens,
- como localizar e depurar problemas nos scripts do CMake (incluindo alguns bastante exóticos).
A arquitetura limpa do projeto, abstrações simples em cada camada é o sonho de qualquer equipe. Para realizar esse sonho, muitas técnicas orientadas a objetos foram inventadas. Levados pelo OOP, os desenvolvedores esquecem de monitorar a limpeza do código na junção de C e C ++. É aqui que o estilo processual ajudará a restaurar a ordem, criar abstrações convenientes e seguras que se encaixam facilmente no código orientado a objeto do projeto. Vamos descobrir:- por que você precisa isolar a API C (como winapi, POSIX, SQLite, OpenGL, OpenSSL)
- por que OOP funciona mal neste negócio
- como escrever uma camada de abstração em cima da API de estilo C
- como lidar com retornos de chamada, tratamento de erros e gerenciamento de recursos para tornar compreensível o código tradicionalmente complexo e confuso, mesmo para jovens
Seus interesses profissionais são a semântica de linguagens de programação, o design e a implementação de compiladores do YaP e outras ferramentas orientadas a linguagem. Entre as realizações mais significativas estão a participação em projetos como a criação de um compilador do padrão completo da linguagem C ++ (Interstron, Moscou, 2000), a implementação do compilador da linguagem Zonnon para .NET (ETH Zurich, 2005) e a implementação do protótipo Swift para a plataforma Tizen ( Samsung Research Institute, Moscou, 2015).O C ++ sempre teve uma poderosa sub-linguagem de metaprogramação que permitiu que os desenvolvedores de bibliotecas realizassem proezas mágicas como introspecção estática para obter execução polimórfica sem herança. O problema era que a sintaxe era estranha e desnecessariamente detalhada, o que tornava a aprendizagem de metaprogramação uma tarefa assustadora.Com as recentes melhorias no padrão e com os recursos planejados para o C ++ 20, a metaprogramação ficou muito mais fácil, e os metaprogramas ficaram mais fáceis de entender e raciocinar.Nesta palestra, o autor apresenta algumas técnicas modernas de metaprogramação, com foco principal na meta-função mágica void_t.O autor do relatório é responsável pelo desenvolvimento da estrutura SObjectizer de código-fonte aberto há 16 anos. Essa é uma das poucas estruturas de ator de plataforma cruzada em desenvolvimento e em desenvolvimento para C ++. O desenvolvimento do SObjectizer começou no ano de 2002, quando o C ++ estava entre as linguagens de programação mais populares e comuns. Nos últimos tempos, o C ++ mudou muito e a atitude em relação ao C ++ mudou ainda mais. O relatório discutirá como essas mudanças afetaram o desenvolvimento de uma ferramenta com um histórico de 16 anos e quão simples e conveniente foi criar essa ferramenta para a linguagem C ++. E se era necessário criar essa ferramenta para C ++ em geral.
- Pratique usando o padrão Model-View-Presenter
- Gerenciamento de ciclo de vida de documentos
- Armazenamento de arquivos de ponteiros inteligentes
Notícias sobre a próxima vulnerabilidade encontrada regularmente são exibidas aqui e ali. As perdas colaterais de $, como regra, são enormes. Portanto, em vez de corrigir vulnerabilidades, elas não devem aparecer.
Uma maneira de lidar com erros no código é usar a análise estática. Mas quão adequado é procurar vulnerabilidades? E existe realmente uma grande diferença entre bugs simples e vulnerabilidades de código?
Discutiremos essas questões durante o relatório e, ao mesmo tempo, falaremos sobre como usar a análise estática para tirar o máximo proveito dela.
PSPor conta própria, quero chamar sua atenção para a mini-intriga em torno de
std :: string relacionada aos relatórios da minha colega Andrei Karpov. Então, em ordem:
- Um fragmento do relatório de Andrei (C ++ Rússia 2016) "Contos particulares de desenvolvedores de analisadores de código" de 30:05 - link .
- Trolling fácil de pessoas como nós por Anton Polukhin (C ++ Rússia 2017) no relatório “Como não fazer: construção de bicicletas em C ++ para profissionais” a partir das 2:00 - link .
- A história de Andrey na conferência C ++ Russia 2018 de que não somos dinossauros e estamos aprendendo uma coisa nova: "C ++ eficaz" a partir das 12:21 - link .
Isso é tudo! Aproveite seus relatórios.