Atualmente, nossa empresa SberTech (Sberbank Technologies) usa o HDFS 2.8.4 porque possui várias vantagens, como o ecossistema Hadoop, trabalho rápido com grandes quantidades de dados, é bom em análises e muito mais. Mas em dezembro de 2017, a Apache Software Foundation lançou uma nova versão da estrutura de código-fonte aberto para desenvolvimento e execução de programas distribuídos - Hadoop 3.0.0, que inclui várias melhorias significativas em relação à linha de versão principal anterior (hadoop-2.x). Uma das atualizações mais importantes e interessantes para nós é o suporte a códigos de redundância (Erasure Coding). Portanto, a tarefa foi definida para comparar essas versões entre si.
A SberTech Company alocou 10 máquinas virtuais de 40 GB cada para este trabalho de pesquisa. Como a política de codificação RS (10.4) requer um mínimo de 14 máquinas, ela não funcionará para testá-la.
Em uma das máquinas, o NameNode estará localizado além do DataNode. Os testes serão realizados com as seguintes políticas de codificação:
- XOR (2.1)
- RS (3,2)
- RS (6,3)
E também, usando a replicação com um fator de replicação 3.
O tamanho do bloco de dados foi escolhido igual a 32 MB.
Pesquisa
Teste de taxa de dados
Testes para taxas de transferência de dados foram realizados. Os dados foram transferidos do sistema de arquivos local para o sistema de arquivos distribuído. O tamanho do arquivo usado neste teste é 292,2 MB.
Os seguintes resultados foram obtidos:
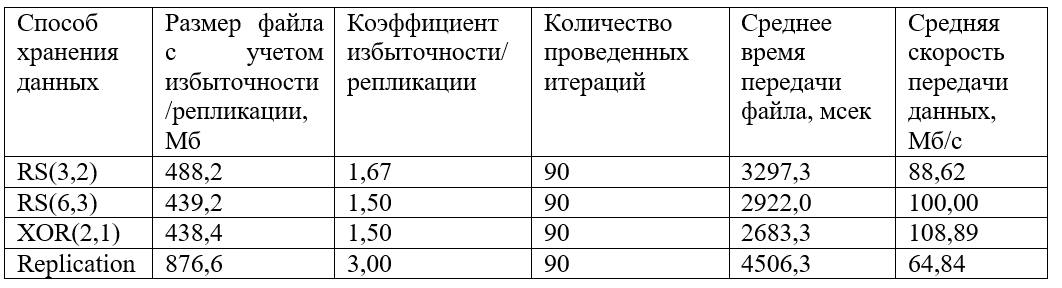
Também é construído um gráfico dos valores recebidos agrupados do tempo de transferência de arquivos:

E também, um gráfico de taxas de dados recebidos agrupados:
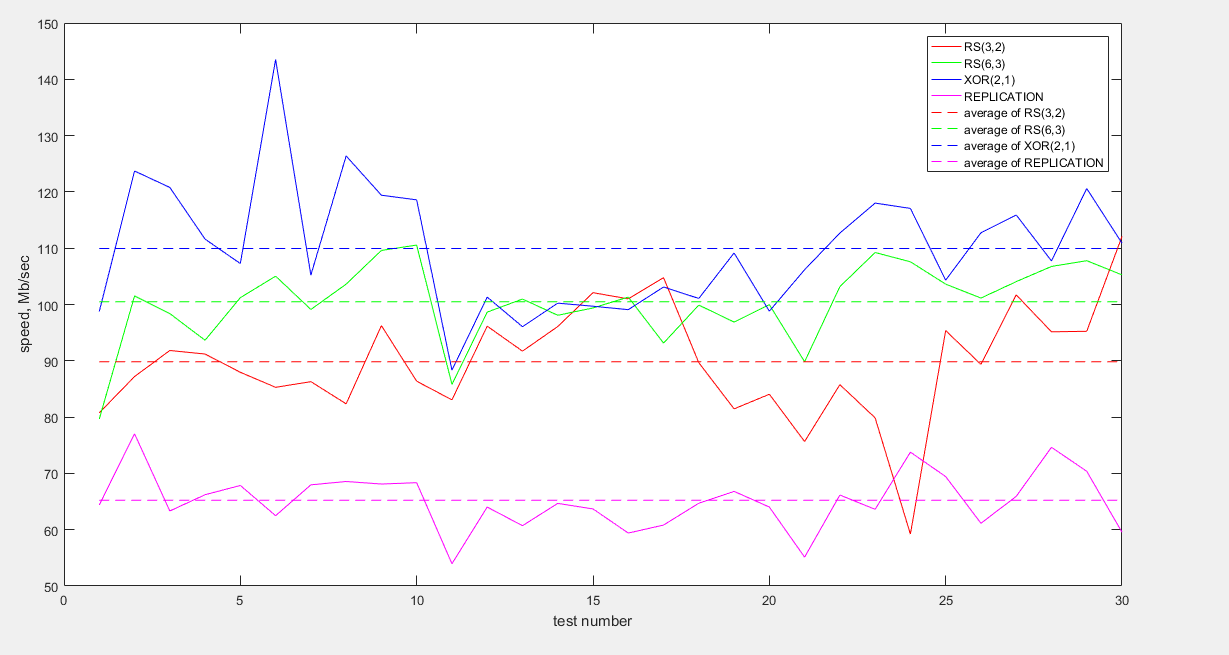
Como pode ser visto no gráfico, os dados mais rápidos são transmitidos codificados com XOR (2,1). As codificações RS (6.3) e RS (3.2) mostram comportamento semelhante, embora o valor médio da velocidade para RS (6.3) seja um pouco maior. A replicação perde muito em velocidade (cerca de 1,5 vezes menos que o XOR e 1,5 vezes menos que o RS).
Quanto à eficiência de armazenamento, XOR (2.1) e RS (6.3) são os métodos de armazenamento mais lucrativos; os dados redundantes são de apenas 50%. A replicação, com uma taxa de replicação de 3, perde novamente, armazenando 200% dos dados redundantes.
Teste de desempenho
No teste anterior, o status dos servidores foi monitorado usando a ferramenta de monitoramento Grafana.
Abaixo está um gráfico mostrando a carga da CPU durante os testes de transferência de dados:
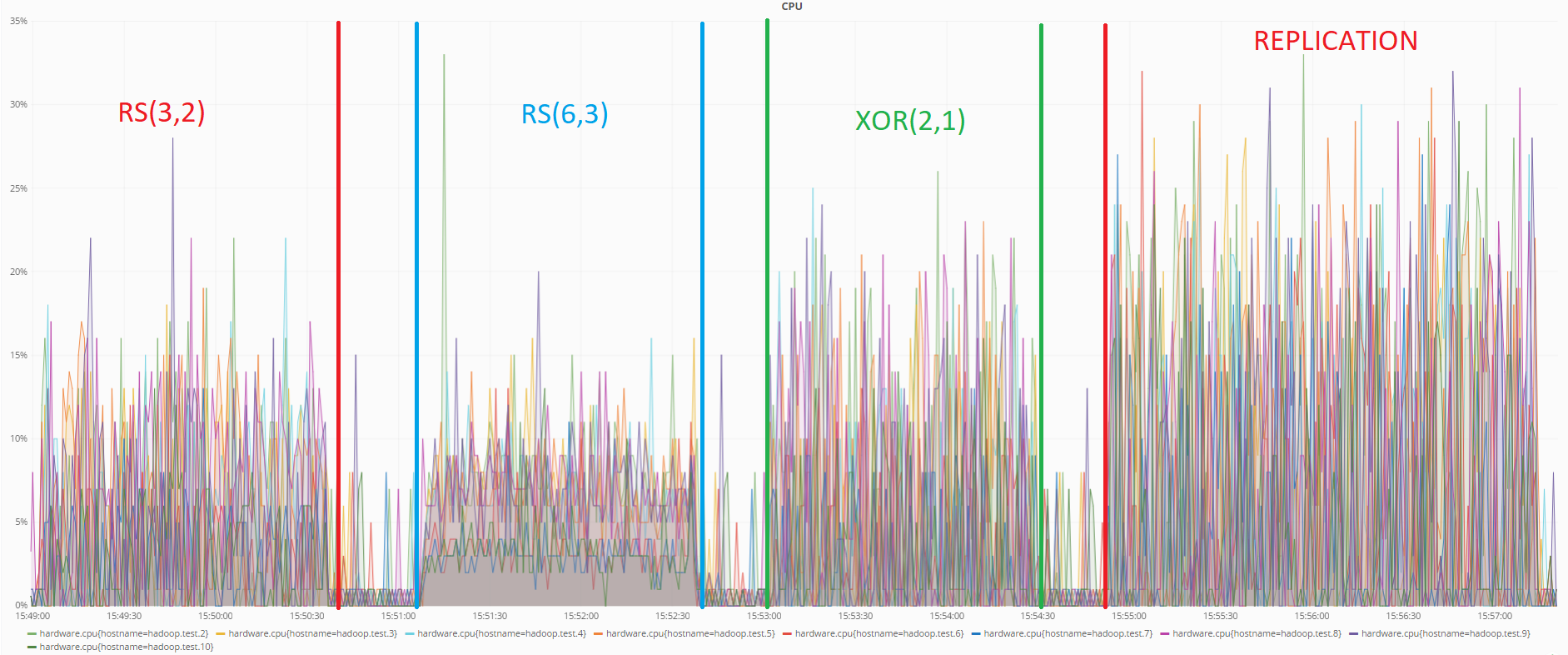
Como pode ser visto no gráfico, neste teste também a codificação RS (6.3) consome menos recursos. A replicação mostra novamente o pior resultado.
Consumo de recursos na recuperação de dados
Para realizar esse teste, uma certa quantidade de dados foi carregada no sistema de arquivos distribuídos Hadoop. Em seguida, duas máquinas com um DataNode foram omitidas.
Abaixo estão os gráficos do estado das máquinas no momento da recuperação de dados com a codificação RS (6.3) e ao usar a replicação:
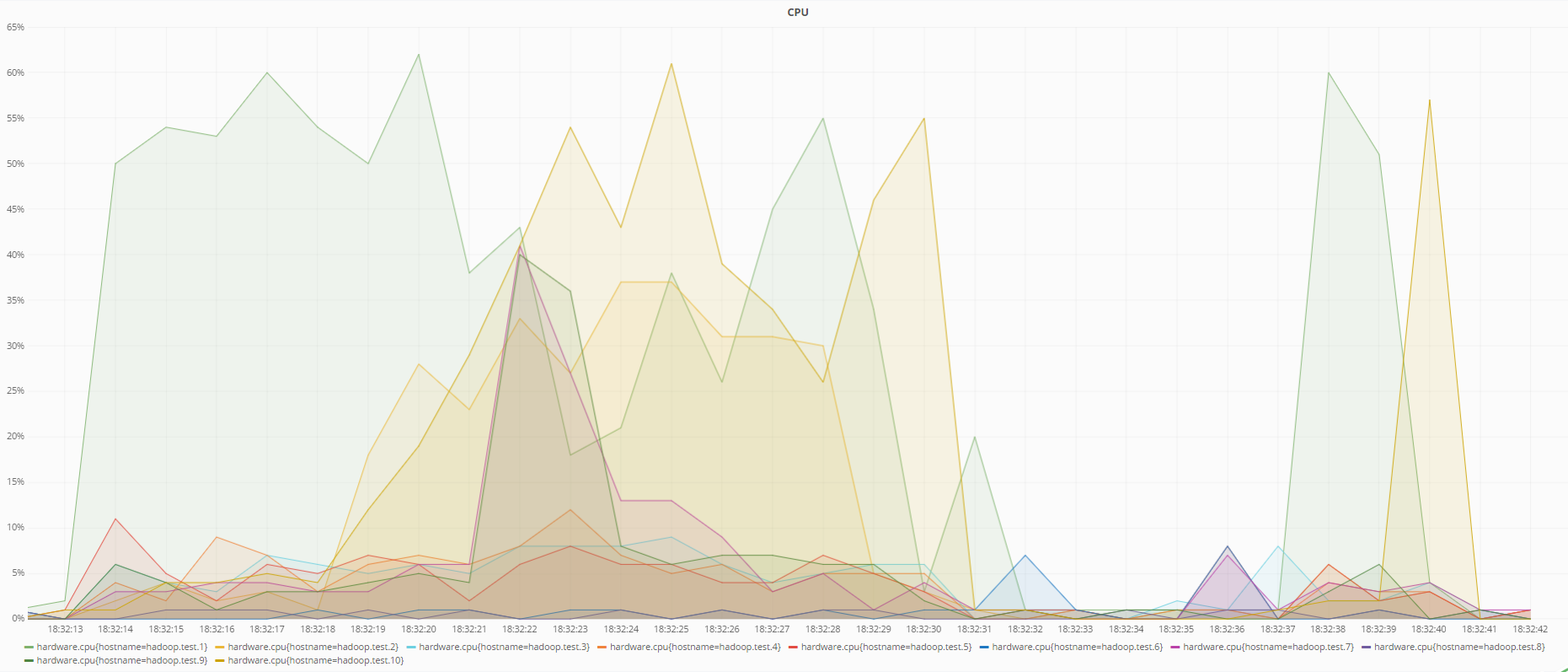
Estado do processador durante a recuperação de dados usando a codificação RS (6.3)

Estado da CPU durante a recuperação de dados usando replicação
Como pode ser visto nos gráficos, a codificação RS (6.3) carrega o processador mais do que a replicação durante a recuperação de dados, o que é lógico, porque, para recuperar dados perdidos usando códigos redundantes, é necessário calcular a matriz de redundância inversa, que consome mais recursos do que apenas sobrescrever dados de outro DataNode em caso de replicação.
Resultados do teste:
- Para taxas de transferência de dados, é melhor usar a codificação XOR (2.1) ou RS (6.3)
- Ao transmitir dados, o processador carrega menos a codificação RS (6.3) e RS (3.2)
- Ao restaurar dados, o processador é menos enfatizado pelo uso de replicação
- A maneira mais compacta de armazenar dados são as codificações RS (6.3) e XOR (2.1)
O método de armazenamento mais confiável é a codificação RS (6.3), pois permite a perda de até três máquinas sem perda de dados, e a replicação com um coeficiente de replicação de 3 suporta falhas de até 2 máquinas. XOR (2, 1) é a maneira mais confiável de armazenar dados, pois permite que você perca no máximo uma máquina.
Conclusão
Os principais objetivos do uso do sistema de arquivos distribuídos no SberTech são:
- Alta confiabilidade
- Minimizar o custo de manutenção de servidores para armazenamento de dados
- Fornecendo ferramentas de análise de dados
Com base nos resultados da análise, são feitas as seguintes conclusões:
- O HDFS 3 supera a confiabilidade em relação ao HDFS 2.
- O HDFS 3 vence minimizando os custos de manutenção do servidor, porque armazena os dados de maneira mais compacta.
- O HDFS 3 tem o mesmo conjunto de ferramentas de análise de dados que o HDFS 2.
Nesse sentido, concluiu-se que o HDFS 3 é um substituto racional para o HDFS 2.
Fontes usadas: