Oi Meu nome é Denis Kiryanov, trabalho no Sberbank e lido com os problemas do processamento de linguagem natural (PNL). Uma vez, precisamos escolher um analisador sintático para trabalhar com o idioma russo. Para fazer isso, investigamos os aspectos morfológicos e de tokenização, testamos diferentes opções e avaliamos sua aplicação. Compartilhamos nossa experiência neste post.

Preparação para seleção
Vamos começar com o básico: como isso funciona? Pegamos o texto, conduzimos a tokenização e obtemos uma série de pseudo-tokens. Os estágios da análise posterior se encaixam em uma pirâmide:
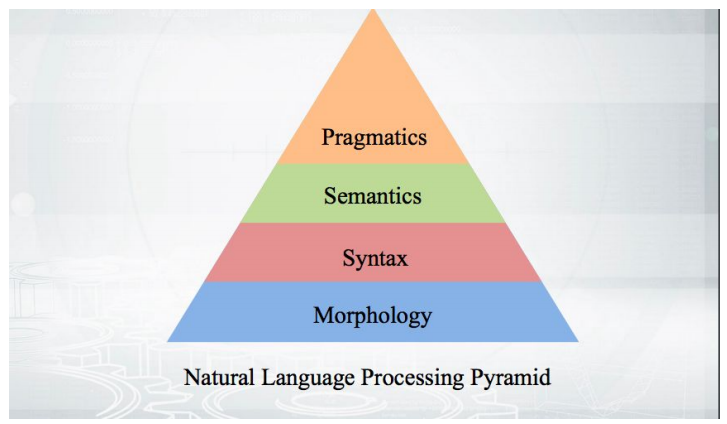
Tudo começa com a morfologia - com uma análise da forma de uma palavra e suas categorias gramaticais (gênero, caso, etc.). A morfologia é baseada na sintaxe - relações além dos limites de uma palavra, entre palavras. Os analisadores sintáticos que serão discutidos analisam o texto e fornecem a estrutura das dependências das palavras uma da outra.
Gramática de dependências e gramática dos componentes imediatos
Existem duas abordagens principais para a análise, que na teoria linguística existem em pé de igualdade.

Na primeira linha, a sentença é analisada como parte da gramática da dependência. Essa abordagem é ensinada na escola. Cada palavra em uma frase está de alguma forma conectada com outras. “Sabonetes” - predicado do qual o sujeito “mãe” depende (aqui a gramática das dependências diverge da escola, onde o predicado depende do assunto). O sujeito tem uma definição dependente de "minha". O predicado possui um complemento direto dependente "quadro". E a adição direta ao "quadro" - a definição de "sujo".
Na segunda linha, a análise está de acordo com a gramática dos próprios componentes.
Segundo ela, a frase é dividida em grupos de palavras (frases). Palavras dentro de um grupo estão mais intimamente relacionadas. As palavras “minha” e “mãe” estão mais intimamente relacionadas, “quadro” e “sujo” - também. E ainda há um "sabão" separado.
A segunda abordagem para a análise automática da língua russa é pouco aplicável, porque nela as palavras estreitamente relacionadas (membros do mesmo grupo) muitas vezes não se alinham. Teríamos que combiná-los com colchetes estranhos - em uma ou duas palavras. Portanto, na análise automática do idioma russo, é habitual trabalhar com base na gramática das dependências. Isso também é conveniente porque todos estão familiarizados com essa "estrutura" na escola.
Árvore de dependência
Podemos traduzir um conjunto de dependências em uma estrutura em árvore. O topo é a palavra "sabão", algumas palavras dependem diretamente dela, outras dependem de seus viciados. Aqui está a
definição da árvore de dependência do livro de Martin e Zhurafsky:
Árvore de dependência é um gráfico direcionado que satisfaz as seguintes restrições:- Existe um único nó raiz designado que não possui arcos recebidos.
- Com exceção do nó raiz, cada vértice possui exatamente um arco recebido.
- Há um caminho exclusivo do nó raiz para cada vértice em V.
Há um nó de nível superior - um predicado. A partir dele você pode chegar a qualquer palavra. Cada palavra depende de outra, mas apenas de uma. A árvore de dependência é mais ou menos assim:

Nesta árvore, as arestas são assinadas com algum tipo especial de relacionamento sintático. Na gramática das dependências, não apenas o fato da conexão entre as palavras é analisado, mas também a natureza dessa conexão. Por exemplo, "is taken" é quase uma forma verbal, "inventário" é o assunto de "is taken". Conseqüentemente, temos uma borda "é" em uma direção e na outra. Essas não são as mesmas conexões, são de natureza diferente, portanto devem ser distinguidas.
A seguir, consideramos casos simples em que membros de uma sentença estão presentes, não implícitos. Existem estruturas e marcas para lidar com passes. Algo aparece na árvore que não tem uma expressão superficial - uma palavra. Mas este é o assunto de outro estudo, mas ainda precisamos nos concentrar sozinhos.
Projeto Dependências Universais
Para facilitar a escolha de um analisador, voltamos nossa atenção para o projeto
Dependências Universais e o
concurso Tarefas Compartilhadas CoNLL , que ocorreu recentemente em sua estrutura.
O Universal Dependencies é um projeto para unificar a marcação de corpos sintáticos (tribanks) dentro da estrutura da gramática da dependência. Em russo, o número de tipos de links sintáticos é limitado - assunto, predicado etc. Em inglês o mesmo, mas o conjunto já é diferente. Por exemplo, aparece um artigo que também precisa ser rotulado de alguma forma. Se quiséssemos escrever um analisador mágico que pudesse lidar com todos os idiomas, teríamos problemas em comparar gramáticas diferentes rapidamente. Os heróicos criadores das Dependências Universais conseguiram concordar entre si e marcar todos os edifícios que estavam à sua disposição em um único formato. Não é muito importante como eles concordaram, o principal é que, na saída, temos um certo formato uniforme para apresentar toda a história -
mais de 100 tribanks para 60 idiomas .
Tarefa compartilhada CoNLL é uma competição entre desenvolvedores de algoritmos de análise, realizada como parte do projeto Universal Dependencies. Os organizadores pegam um certo número de tribanks e dividem cada um deles em três partes - treinamento, validação e teste. A primeira parte é fornecida aos participantes da competição para que eles treinem seus modelos nela. A segunda parte também é usada pelos participantes para avaliar a operação do algoritmo após o treinamento. Os participantes podem repetir o treinamento e a avaliação iterativamente. Em seguida, eles entregam seu melhor algoritmo aos organizadores, que o executam na parte do teste, fechados aos participantes. Os resultados dos modelos nas partes de teste dos tribanks são os resultados da competição.
Métricas de qualidade
Temos conexões entre palavras e seus tipos. Podemos avaliar se a palavra top foi encontrada corretamente - a métrica UAS (pontuação do anexo não marcado). Ou para avaliar se o vértice e o tipo de dependência foram encontrados corretamente - a métrica LAS (pontuação de anexo rotulado).

Parece que uma avaliação de precisão se implora aqui - consideramos quantas vezes obtivemos do número total de casos. Se tivermos 5 palavras e para 4 determinarmos corretamente o topo, obteremos 80%.
Mas, na verdade, avaliar o analisador em sua forma pura é problemático. Os desenvolvedores que resolvem os problemas da análise automática geralmente usam o texto bruto como entrada, que, de acordo com a pirâmide de análise, passa pelos estágios da tokenização e da análise morfológica. Os erros dessas etapas anteriores podem afetar a qualidade do analisador. Em particular, isso se aplica ao procedimento de tokenização - alocação de palavras. Se tivermos identificado as palavras de unidade erradas, não seremos mais capazes de avaliar corretamente as relações sintáticas entre elas - afinal, em nosso corpo rotulado original, as unidades eram diferentes.
Portanto, a fórmula de avaliação nesse caso é a medida f, em que precisão é o compartilhamento de acertos precisos em relação ao número total de previsões, e integridade é o compartilhamento de acertos precisos em relação ao número de links nos dados marcados.
Quando fornecermos estimativas no futuro, devemos lembrar que as métricas usadas afetam não apenas a sintaxe, mas também a qualidade da tokenização.
Língua russa na Universal Dependencies
Para que o analisador possa sintaticamente marcar sentenças que ainda não viu, ele precisa alimentar o corpus marcado para treinamento. Para o idioma russo, existem vários casos:

A segunda coluna indica o número de tokens - palavras. Quanto mais tokens, mais o corpo de treinamento e melhor o algoritmo final (se esses são bons dados). Obviamente, todas as experiências são conduzidas no SynTagRus (desenvolvido pelo IPPI RAS), no qual existem mais de um milhão de tokens. Todos os algoritmos serão treinados, o que será discutido mais adiante.
Analisadores para russo na tarefa compartilhada CoNLL
De acordo com os resultados da
competição do ano passado, os modelos treinados no mesmo SynTagRus alcançaram os seguintes indicadores LAS:

Os resultados dos analisadores para o russo são impressionantes - eles são melhores que os dos analisadores para inglês, francês e outros idiomas mais raros. Tivemos muita sorte por duas razões ao mesmo tempo. Primeiro, os algoritmos fazem um bom trabalho com o idioma russo. Em segundo lugar, temos o SynTagRus - uma caixa grande e marcada.
A propósito, a competição de 2018 já passou, mas realizamos nossa pesquisa na primavera deste ano, por isso contamos com os resultados da pista do ano passado. Olhando para o futuro, observamos que a
nova versão do UDPipe (Future) acabou sendo ainda maior este ano.
O Syntaxnet, um analisador do Google, não está na lista. O que há de errado com ele? A resposta é simples: o Syntaxnet começou apenas com o estágio da análise morfológica. Ele pegou a tokenização ideal pronta e já construiu o processamento sobre ela. Portanto, é injusto avaliá-lo em pé de igualdade com o restante - o restante dividiu em tokens com seus próprios algoritmos, e isso poderia piorar os resultados no próximo estágio da sintaxe. A amostra de 2017 da Syntaxnet tem um resultado melhor do que a lista inteira acima, mas as comparações diretas não são justas.
A tabela possui duas versões do UDPipe, em 12 e 15 lugares. As mesmas pessoas que participaram ativamente do projeto Dependências Universais estão desenvolvendo esse analisador.
As atualizações do UDPipe aparecem periodicamente (um pouco menos frequentemente, a propósito, o layout dos casos também é atualizado). Portanto, após a competição no ano passado, o UDPipe foi atualizado (eles foram confirmados para a versão 2.0 ainda não lançada; no futuro, por simplicidade, vamos nos referir a grosso modo ao commit do UDPipe 2.0 que assumimos, embora, estritamente falando, não seja assim); Obviamente, não existem atualizações na tabela de competição. O resultado do "nosso" commit é aproximadamente o sétimo lugar.
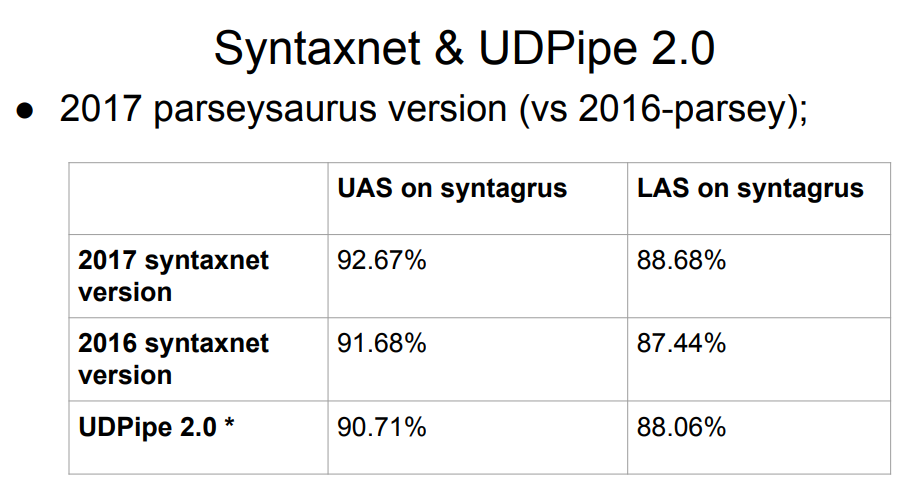
Portanto, precisamos escolher um analisador para o idioma russo. Como dados iniciais, temos a placa acima com o principal Syntaxnet e com o UDPipe 2.0 em algum lugar em 7º lugar.
Escolha um modelo
Simplificamos: começamos com o analisador com as taxas mais altas. Se algo está errado com ele, vá abaixo. Algo pode não estar certo de acordo com os seguintes critérios - talvez eles não sejam perfeitos, mas vieram até nós:
- Velocidade do trabalho . Nosso analisador deve funcionar rápido o suficiente. A sintaxe, é claro, está longe de ser o único módulo "oculto" de um sistema em tempo real; portanto, você não deve gastar mais do que uma dúzia de milissegundos nele.
- A qualidade do trabalho . No mínimo, o analisador em si é baseado em dados do idioma russo. O requisito é óbvio. Para o idioma russo, temos bons analisadores morfológicos que podem ser integrados em nossa pirâmide. Se pudermos garantir que o analisador funcione bem sem morfologia, isso nos servirá - iremos deslizar a morfologia mais tarde.
- Disponibilidade de um código de treinamento e, de preferência, de um modelo em domínio público . Se tivermos um código de treinamento, poderemos repetir os resultados do autor do modelo. Para fazer isso, eles devem estar abertos. Além disso, precisamos monitorar cuidadosamente as condições para a distribuição de casos e modelos - teremos que comprar uma licença para usá-los, se os usarmos como parte de nossos algoritmos?
- Lançar sem esforço extra . Este item é muito subjetivo, mas importante. O que isso significa? Isso significa que, se ficarmos sentados por três dias e começarmos algo, mas ele não iniciar, não poderemos selecionar esse analisador, mesmo que seja de perfeita qualidade.
Tudo o que era maior que o UDPipe 2.0 no gráfico do analisador não nos convinha. Temos um projeto Python, e alguns analisadores da lista não são escritos em Python. Para implementá-los no projeto Python, seria necessário aplicar os super esforços. Em outros casos, fomos confrontados com código-fonte fechado, desenvolvimentos acadêmicos e industriais - em geral, você não chega ao fundo.
O Star Syntaxnet merece uma história separada sobre a qualidade do trabalho. Aqui ele não nos convinha pela velocidade do trabalho. O tempo de sua resposta a algumas frases simples comuns nos chats é de 100 milissegundos. Se gastamos tanto em sintaxe, não temos tempo suficiente para mais nada. Ao mesmo tempo, o UDPipe 2.0 faz uma análise de ~ 3ms. Como resultado, a escolha caiu no UDPipe 2.0.
UDPipe 2.0
O UDPipe é um pipeline que aprende tokenização, lematização, marcação morfológica e análise gramatical de dependência. Podemos ensinar-lhe tudo isso ou algo separadamente. Por exemplo, faça outro analisador morfológico para o idioma russo. Ou treine e use o UDPipe como um tokenizador.
O UDPipe 2.0 está documentado em detalhes. Há uma
descrição da arquitetura , um
repositório com um código de treinamento , um
manual . O mais interessante são os
modelos prontos , inclusive para o idioma russo. Faça o download e execute. Também neste recurso, os parâmetros de treinamento selecionados para cada corpus de idioma foram liberados. Para cada modelo, são necessários cerca de 60 parâmetros de treinamento e, com a ajuda deles, você pode alcançar independentemente os mesmos indicadores de qualidade da tabela. Eles podem não ser ótimos, mas pelo menos podemos ter certeza de que o pipeline funcionará corretamente. Além disso, a presença de tal referência nos permite experimentar calmamente o modelo por conta própria.
Como o UDPipe 2.0 funciona
Primeiro, o texto é dividido em frases e frases em palavras. O UDPipe faz tudo isso de uma só vez com a ajuda de um módulo conjunto - uma rede neural (GRU de camada única e dupla face), que para cada personagem prevê se é a última em uma frase ou em uma palavra.
Então o etiquetador começa a trabalhar - algo que prediz as propriedades morfológicas do token: nesse caso, a palavra é, em que número. Com base nos quatro últimos caracteres de cada palavra, um marcador gera hipóteses sobre uma parte do discurso e marcações morfológicas dessa palavra e, com a ajuda de um perceptron, seleciona a melhor opção.
O UDPipe também possui um lematizador que seleciona o formulário inicial para as palavras. Ele aprende sobre o mesmo princípio pelo qual um falante não nativo poderia tentar determinar o lema de uma palavra desconhecida. Cortamos o prefixo e o final da palavra, adicionamos um "t", que está presente na forma inicial do verbo, etc. Assim, os candidatos são gerados, a partir dos quais o melhor perceptron escolhe.
O esquema de marcação morfológica (determinando o número, caso e tudo mais) e as previsões dos lemas são muito semelhantes. Eles podem ser previstos juntos, mas melhor separadamente - a morfologia do idioma russo é muito rica. Você também pode conectar sua lista de lemas.
Vamos para a parte mais interessante - o analisador. Existem várias arquiteturas de analisador de dependência. O UDPipe é uma arquitetura baseada em transição: funciona rapidamente, passando por todos os tokens uma vez em um tempo linear.
A análise sintática em uma arquitetura desse tipo começa com uma pilha (onde no início há apenas raiz) e uma configuração vazia. Existem três maneiras padrão de alterá-lo:
- LeftArc - aplicável se o segundo elemento da pilha não for raiz. Ele mantém o relacionamento entre o token na parte superior da pilha e o segundo token e também ejeta o segundo da pilha.
- RightArc é o mesmo, mas a dependência é criada de outra maneira e a dica é descartada.
- Shift - transfere a próxima palavra do buffer para a pilha.
Abaixo está um exemplo do analisador (
fonte ). Temos a frase "reserve-me o voo da manhã" e estamos nos reconectando a ele:

Aqui está o resultado:

O analisador clássico baseado em transição possui as três operações listadas acima: seta unidirecional, seta unidirecional e deslocamento. Há também uma operação de troca, nas arquiteturas básicas do analisador baseado em transição, ela não é usada, mas está incluída no UDPipe. Swap retorna o segundo elemento da pilha para o buffer para retirar o próximo elemento do buffer (se eles estiverem espaçados). Isso ajuda a pular algumas palavras e restaurar a conexão correta.
Há um bom artigo no
link da pessoa que criou a operação de troca. Vamos destacar um ponto: apesar de repetidamente passarmos pelo buffer de token inicial (ou seja, nosso tempo não é mais linear), essas operações podem ser otimizadas para que o tempo retorne muito próximo de linear. Ou seja, diante de nós não é apenas uma operação significativa do ponto de vista da linguagem, mas também uma ferramenta que não diminui muito o trabalho do analisador.
Usando o exemplo acima, mostramos as operações, como resultado das quais obtemos alguma configuração - o buffer de token e as conexões entre eles. Fornecemos essa configuração na etapa atual ao analisador baseado em transição e, com ela, deve prever a configuração na próxima etapa. Comparando os vetores de entrada e configurações em cada etapa, o modelo é treinado.
Assim, selecionamos um analisador que se encaixa em todos os nossos critérios e até entendemos como ele funciona. Prosseguimos com os experimentos.
Problemas do UDPipe
Vamos fazer uma pequena frase: "Transferir cem rublos para a mãe". O resultado faz você agarrar sua cabeça.
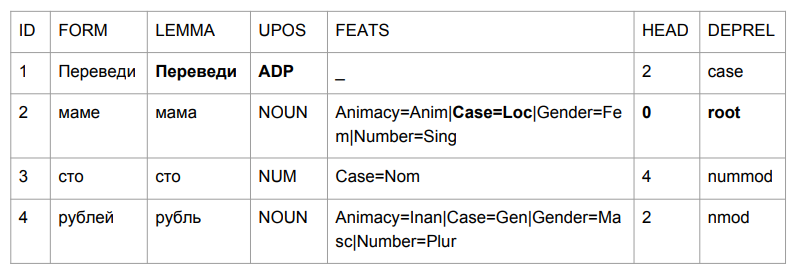
"Traduzir" acabou sendo uma desculpa, mas isso é bastante lógico. Determinamos a gramática da forma da palavra pelos últimos quatro caracteres. "Lead" é algo como "no meio", então a escolha é relativamente lógica. É mais interessante com "mãe": "mãe" estava no caso preposicional e se tornou o auge dessa frase.
Se tentarmos interpretar tudo com base nos resultados da análise, teremos algo como "no meio de uma mãe (cuja mãe? Quem é essa mãe?) Centenas de rublos". Não é bem o que era no começo. Precisamos de alguma forma lidar com isso. E nós criamos como.
Na pirâmide de análise, a sintaxe é construída sobre a morfologia, com base em tags morfológicas. Aqui está um exemplo de livro de um linguista L.V. Shcherby a este respeito:
"Cuzdra gloky shteko budlanula bokra e menino de cabelos cacheados."A análise desta proposta não causa problemas. Porque Porque nós, como etiquetadores UDPipe, observamos o final de uma palavra e entendemos a que parte do discurso ela se refere e a que forma é. A história com "traduzir" como desculpa contradiz completamente nossa intuição, mas acaba sendo lógica no momento em que tentamos fazer o mesmo com palavras desconhecidas. Uma pessoa pode pensar da mesma maneira.
Avaliaremos o etiquetador UDPipe separadamente. Se não nos convém, usaremos outro etiquetador - para criar uma análise em cima de outra marcação morfológica.
Identificação de texto sem formatação (pontuação CoNLL17 F1)- formas de ouro: 301639 ,
- upostag: 98,15% ,
- xpostag: 99,89% ,
- proezas: 93,97% ,
- alltags: 93,44% ,
- lemas: 96,68%
A qualidade morfológica do UDPipe 2.0 não é ruim. Mas para a língua russa é notavelmente melhor. O analisador Mystem (o
desenvolvimento do Yandex ) alcança melhores resultados na determinação de partes do discurso que o UDPipe. Além disso, outros analisadores são mais difíceis de implementar em um projeto python e funcionam mais lentamente com uma qualidade comparável ao Mystem. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
Nesses casos, Mystem honestamente fornece toda a cadeia:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
Mas não podemos enviar a cadeia de tubulação inteira para o UDPipe, mas precisamos especificar uma tag melhor. Como escolher? Se você não tocar em nada, eu quero pegar o primeiro, talvez funcione. Mas as tags são classificadas em ordem alfabética de acordo com os nomes em inglês; portanto, nossa escolha será quase aleatória, e algumas análises quase perdem a chance de serem as primeiras.
Existe um analisador que pode oferecer a melhor opção - Pymorphy2. Mas com uma análise da morfologia, ele é pior. Além disso, ele fornece a melhor palavra fora de contexto. O Pymorphy2 fornecerá apenas uma análise para "sem diretor", "consulte diretor" e "diretor". Não será aleatório, mas realmente o melhor em probabilidade, que na pimorfia2 foram consideradas em um corpo separado de textos. Mas uma certa porcentagem de análises incorretas dos textos de combate será garantida, simplesmente porque eles podem conter frases com diferentes formas reais: tanto "eu vejo o diretor" quanto "os diretores vieram à reunião" e "não há diretor". Uma probabilidade de análise sem contexto não nos convém.
Como obter contextualmente o melhor conjunto de tags? Usando o analisador
RNNMorph . Poucas pessoas ouviram falar dele, mas no ano passado ele venceu a competição entre analisadores morfológicos, realizada como parte da conferência Dialogue.
O RNNMorph tem seu próprio problema: não possui tokenização. Se o Mystem puder tokenizar texto não processado, o RNNMorph exigirá uma lista de tokens na entrada. Para chegar à sintaxe, primeiro você precisará usar um tokenizador externo, depois fornecer o resultado ao RNNMorph e apenas alimentar a morfologia resultante ao analisador de sintaxe.
Aqui estão as opções que temos. Não recusaremos a análise sem contexto do pymorphy2, por enquanto, sobre casos discutíveis no Mystem - de repente, ela não ficará muito atrás do RNNMorph. Embora se os compararmos puramente no nível de qualidade da marcação morfológica (dados de
MorphoRuEval-2017 ), a perda será significativa - cerca de 15%, se considerarmos a precisão de acordo com as palavras.
Em seguida, precisamos converter a saída do Mystem para o formato que o UDPipe entende - conllu. E, novamente, isso é um problema, até dois. Puramente técnico - as linhas não correspondem. E conceitual - nem sempre é completamente claro como compará-los. Diante de duas marcações diferentes dos dados do idioma, você quase certamente encontrará o problema da correspondência de tags, veja os exemplos abaixo. As respostas para a pergunta "qual tag está aqui" podem ser diferentes e, provavelmente, a resposta correta depende da tarefa. Devido a essa inconsistência, combinar sistemas de marcação não é uma tarefa fácil por si só.
Como converter? Há
russian_tagsets _
package - um pacote para Python que pode converter diferentes formatos. Não há tradução do formato de emissão Mystem para Conllu, que é aceito em Dependências universais, mas há uma tradução para conllu, por exemplo, do formato de marcação do corpus nacional do idioma russo (e vice-versa). O autor do pacote (a propósito, ele é o autor do pymorphy2) escreveu uma coisa maravilhosa diretamente na documentação: "Se você não pode usar este pacote, não o use." Ele fez isso não porque o programador krivorukov (ele é um excelente programador!), Mas porque se você precisar converter um para outro, corre o risco de ter problemas devido à inconsistência linguística das convenções de marcação.
Aqui está um exemplo. A escola recebeu a "categoria de condição" (frio, necessário). Alguns dizem que é um advérbio, outros dizem um adjetivo. Você precisa converter isso e adicionar algumas regras, mas ainda não obtém uma correspondência inequívoca entre um formato e outro.
Outro exemplo: uma promessa (alguém fez algo ou fez algo com alguém). "Petya matou alguém" ou "Petya foi morta". “Vasya tira fotos” - “Vasya tira fotos” (ou seja, “Vasya é fotografada”). Há também uma garantia medial no SynTagRus - nem sequer nos aprofundamos no que é e por quê. Mas em Mystem não é. Se você precisar, de alguma forma, levar um formato para outro, esse é um beco sem saída.
Mais ou menos honestamente, seguimos o conselho do autor do pacote russian_tagsets - não usamos seu desenvolvimento, porque não encontramos o par necessário na lista de formatos de correspondência. Como resultado, escrevemos nosso conversor personalizado de Mystem para Conllu e prosseguimos.
Conectamos o identificador de terceiros e o analisador UDPipe
Depois de todas as aventuras, pegamos três algoritmos, que foram descritos acima:
- UDPipe da linha de base
- Mym com desambiguação de tag de pymorphy2
- RNNMorph
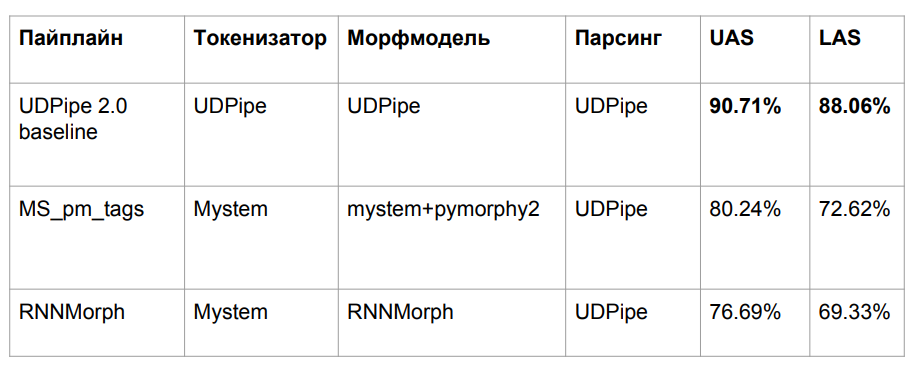
Perdemos em qualidade por uma razão bastante óbvia. Pegamos o modelo UDPipe treinado em uma morfologia, mas inserimos outra morfologia em uma entrada. O problema clássico de incompatibilidade de dados entre trem e teste é o resultado de uma queda na qualidade.
Tentamos alinhar nossas ferramentas de marcação morfológica automática com a marcação SynTagRus, que foi marcada manualmente. Como não obtivemos êxito, no caso de treinamento SynTagRus, substituiremos todas as marcações morfológicas manuais pelas obtidas com Mystem e pymorphy2 em um caso e com RNNMorph em outro. Em um caso validado marcado à mão, somos forçados a alterar a marcação manual para automática, porque "em batalha" nunca obteremos marcação manual.
Como resultado, treinamos o analisador UDPipe (apenas o analisador) com os mesmos hiperparâmetros da linha de base. O que foi responsável pela sintaxe - o ID do vértice, do qual depende o tipo de conexão - deixamos, mudamos todo o resto.
Resultados
Além disso, vou nos comparar com o Syntaxnet e outros algoritmos. Os organizadores da CoNLL Shared Task apresentaram a partição SynTagRus (train / dev / test 80/10/10). Inicialmente, pegamos outro (trem / teste 70/30), portanto os dados nem sempre coincidem conosco, embora tenham sido recebidos no mesmo caso. Além disso, tiramos a versão mais recente (de fevereiro a março) do repositório SynTagRus - essa versão é um pouco diferente daquela da competição. Os dados do que não decolou são fornecidos em artigos em que a divisão foi a mesma da competição - esses algoritmos são marcados com um asterisco na tabela.
Aqui estão os resultados finais:
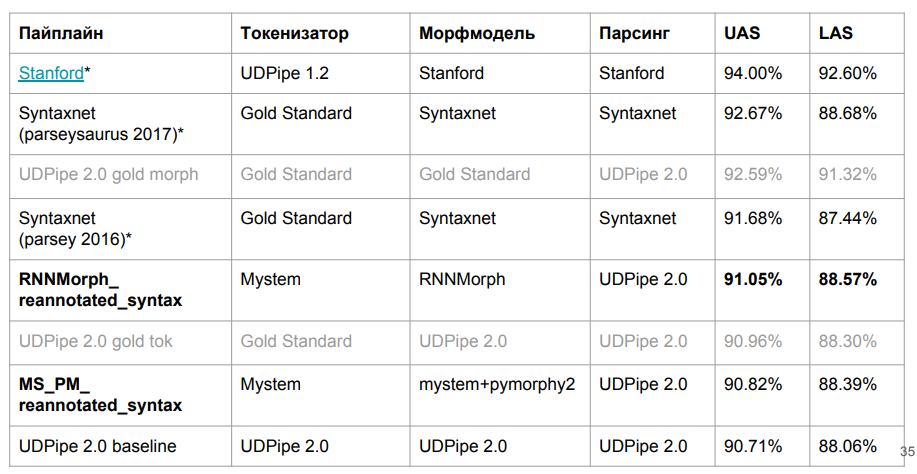
O RNNMorph realmente se mostrou melhor - não no sentido absoluto, mas no papel de uma ferramenta auxiliar para obter uma métrica comum de acordo com os resultados da análise (em comparação com Mystem + pymorphy2). Ou seja, quanto melhor a morfologia, melhor a sintaxe, mas a separação "sintática" é muito menor do que a morfológica. Observe também que não fomos muito longe do modelo de linha de base, o que significa que na morfologia realmente não havia tanto quanto esperávamos.
Eu me pergunto o quanto reside na morfologia? É possível obter uma melhoria fundamental no analisador sintático devido à morfologia ideal? Para responder a essa pergunta, dirigimos o UDPipe 2.0 em tokenização e morfologia perfeitamente calibradas (usando o padrão de marcação manual padrão). Havia uma certa margem (consulte a linha sobre Gold Morph na tabela; resulta + 1,54% de RNNMorph_reannotated_syntax) do que tínhamos, inclusive do ponto de vista de determinar corretamente o tipo de conexão. Se alguém escrever um analisador morfológico absolutamente perfeito do idioma russo, é provável que os resultados que obtemos usando um analisador sintático abstrato também cresçam. E entendemos mais ou menos o teto (pelo menos o teto para essa arquitetura e para a combinação de parâmetros que usamos para o UDPipe - é mostrado na terceira linha da tabela acima).
Curiosamente, quase alcançamos a versão Syntaxnet na métrica LAS. É claro que temos dados ligeiramente diferentes, mas, em princípio, ainda são comparáveis. A tokenização de sintaxe é "ouro" e, para nós - do Mystem. Escrevemos o invólucro mencionado acima no Mystem, mas a análise ainda acontece automaticamente; provavelmente Mystem também está errado em algum lugar. Na linha da tabela “UDPipe 2.0 gold tok”, pode ser visto que, se você usar o UDPipe e a tokenização gold padrão, ele ainda perderá um pouco o Syntaxnet-2017. Mas funciona muito mais rápido.
O que ninguém alcançou é o
analisador de Stanford . Ele foi projetado da mesma maneira que o Syntaxnet, por isso funciona por um longo tempo. No UDPipe, apenas seguimos a pilha. A arquitetura do analisador Stanford e do Syntaxnet tem um conceito diferente: primeiro eles geram um gráfico completo e, em seguida, o algoritmo trabalha para deixar o esqueleto (árvore de abrangência mínima) que será mais provável. Para fazer isso, ele faz combinações, e essa pesquisa não é mais linear, porque você passará para uma palavra mais de uma vez. Apesar de, durante muito tempo, do ponto de vista da ciência pura, pelo menos para a língua russa, ser uma arquitetura mais eficiente. Tentamos elevar esse desenvolvimento acadêmico por dois dias - infelizmente, não deu certo. Mas, com base em sua arquitetura, fica claro que não funciona rapidamente.
Quanto à nossa abordagem - embora formalmente quase não subamos por métricas, agora está tudo bem com a "mãe".
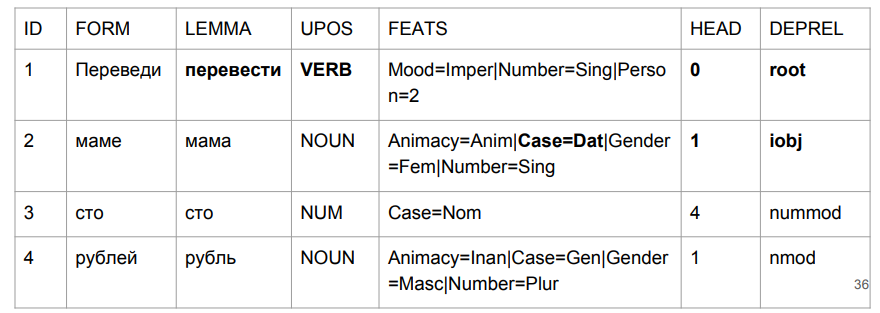
Na frase "traduzir cem rublos para a mãe", "traduzir" é realmente um verbo no clima imperativo. "Mãe" tem seu caso dativo. E o mais importante para nós é nosso rótulo (iobj), um objeto indireto (destino). Embora o crescimento nos números seja insignificante, lidamos bem com o problema com o qual a tarefa começou.
Faixa bônus: pontuação
Se retornarmos aos dados reais, a sintaxe depende da pontuação. Pegue a frase "você não pode executar misericórdia". O que exatamente não pode ser feito - “executar” ou “ter misericórdia” - depende de onde está a vírgula. Mesmo se colocarmos o linguista para marcar os dados, ele precisará de pontuação como algum tipo de ferramenta auxiliar. Ele não poderia ficar sem ela.
Vamos pegar as frases "Peter hello" e "Peter hello" e analisar sua análise pelo modelo de linha de base-UDPipe. Deixamos de lado os problemas que, de acordo com esse modelo, então:
1) "Petya" é um substantivo feminino;
2) "Petya" é (a julgar pelo conjunto de tags) a forma inicial, mas, ao mesmo tempo, seu lema não é "Petya".
É assim que o resultado muda devido à vírgula, com sua ajuda, obtemos algo semelhante à verdade.
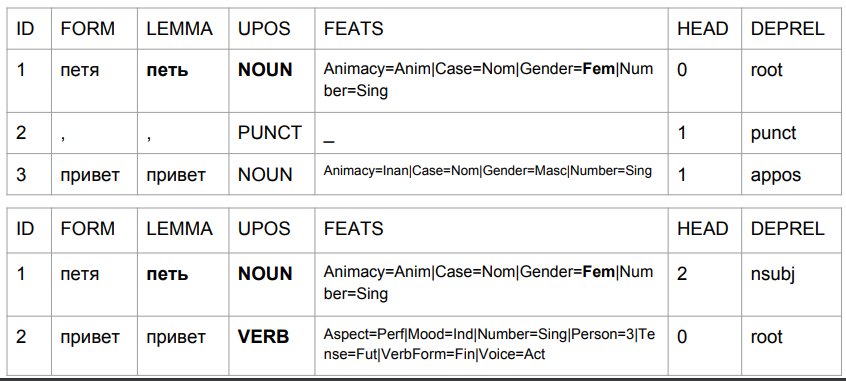
No segundo caso, "Petya" é um assunto e "olá" é um verbo. Voltar a prever o formato de uma palavra com base nos últimos quatro caracteres. Na interpretação do algoritmo, isso não é "saudações Petya", mas "saudações Petya". Digite "Petya canta" ou "Petya virá". A análise é bastante compreensível: em russo, não pode haver uma vírgula entre o sujeito e o predicado. Portanto, se a vírgula estiver, esta é a palavra "olá" e, se não houver vírgula, pode ser algo como "Petya Privet".
Nós encontraremos isso na produção com bastante frequência, porque os corretores ortográficos corrigem a ortografia, mas não a pontuação. Para piorar a situação, o usuário pode definir vírgulas incorretamente e nosso algoritmo as levará em consideração na compreensão da linguagem natural. Quais são as soluções possíveis aqui? Vemos duas opções.
A primeira opção é fazer o que costuma ser feito ao traduzir a fala em texto. Inicialmente, não há pontuação em um texto, portanto ele é restaurado por meio do modelo. A saída é um material relativamente competente em termos das regras do idioma russo, o que ajuda o analisador sintático a funcionar corretamente.
A segunda idéia é um pouco mais ousada e contradiz as lições escolares da língua russa. Envolve trabalhar sem pontuação: se de repente a entrada for pontuação, nós a removeremos de lá. Também removeremos absolutamente toda a pontuação do corpo de treinamento. Assumimos que o idioma russo exista sem pontuação. Apenas pontos para dividir em frases.
Tecnicamente, é bem simples, porque não alteramos os nós finais na árvore de sintaxe. Não podemos ter tal que o sinal de pontuação seja o topo. Este é sempre algum nó final, exceto o sinal%, que por algum motivo no SynTagRus é o vértice do número anterior (50% no SynTagRus é marcado como% - vértice e 50 - dependente).
Vamos testar usando o modelo Mystem (+ pymorphy 2).

É extremamente importante para nós não fornecer o modelo de texto de pontuação sem pontuação. Mas se sempre dermos o texto sem pontuação, estaremos na linha superior e obteremos pelo menos resultados aceitáveis. Se o texto sem pontuação e o modelo funcionar sem pontuação, com relação à pontuação ideal e ao modelo de pontuação, a queda será de apenas cerca de 3%.
O que fazer sobre isso? Podemos nos debruçar sobre esses números - obtidos usando o modelo sem pontuação e a purificação da pontuação. Ou invente algum tipo de classificador para restaurar a pontuação. Não alcançaremos números ideais (aqueles com pontuação no modelo de pontuação), porque o algoritmo de recuperação de pontuação funciona com algum erro e os números "ideais" foram calculados no SynTagRus absolutamente puro. Mas se vamos escrever um modelo que restaure a pontuação, o progresso pagará nossos custos? A resposta ainda não é óbvia.
Podemos pensar por um longo tempo sobre a arquitetura do analisador, mas devemos lembrar que, de fato, não existe um grande corpus de textos da web marcado de forma sintática. Sua existência ajudaria a resolver melhor os problemas reais. Até agora, estamos estudando o corpo de textos editados e absolutamente alfabetizados - e estamos perdendo qualidade ao obter textos personalizados em batalha, que geralmente são analfabetos.
Conclusão
Examinamos o uso de vários algoritmos de análise sintática com base na gramática de dependência, aplicada ao idioma russo. Descobriu-se que em termos de velocidade, conveniência e qualidade do trabalho, o UDPipe acabou sendo a melhor ferramenta. Seu modelo de linha de base pode ser aprimorado se os estágios da tokenização e análise morfológica forem atribuídos a outros analisadores de terceiros: esse truque permite corrigir o comportamento incorreto do etiquetador e, como resultado, do analisador em casos importantes para análise.
Também analisamos o problema da relação entre pontuação e análise e chegamos à conclusão de que, no nosso caso, é melhor remover a pontuação antes da análise sintática.
Esperamos que os pontos de aplicação discutidos em nosso artigo o ajudem a usar a análise sintática para resolver seus problemas da maneira mais eficiente possível.
O autor agradece a Nikita Kuznetsova e Natalya Filippova pela ajuda na preparação do artigo; pela assistência no estudo - Anton Alekseev, Nikita Kuznetsov, Andrei Kutuzov, Boris Orekhov e Mikhail Popov.